Towards Execution-Grounded Automated AI Research
Abstract: Automated AI research holds great potential to accelerate scientific discovery. However, current LLMs often generate plausible-looking but ineffective ideas. Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback. To investigate these, we first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. We then convert two realistic research problems - LLM pre-training and post-training - into execution environments and demonstrate that our automated executor can implement a large fraction of the ideas sampled from frontier LLMs. We analyze two methods to learn from the execution feedback: evolutionary search and reinforcement learning. Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline (69.4% vs 48.0%) on post-training, and finds a pre-training recipe that outperforms the nanoGPT baseline (19.7 minutes vs 35.9 minutes) on pre-training, all within just ten search epochs. Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends. Reinforcement learning from execution reward, on the other hand, suffers from mode collapse. It successfully improves the average reward of the ideator model but not the upper-bound, due to models converging on simple ideas. We thoroughly analyze the executed ideas and training dynamics to facilitate future efforts towards execution-grounded automated AI research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑English Summary of “Towards Execution‑Grounded Automated AI Research”
1. What is this paper about?
The paper explores a big idea: can we build an “AI researcher” that not only comes up with research ideas, but also writes the code, runs the experiments, checks the results, and then uses those results to come up with even better ideas? The authors call this “execution‑grounded” research—meaning ideas must be tested by actually running them, not just sounding smart.
2. What questions did the researchers ask?
The authors focused on a few simple questions:
- Can we automatically turn natural‑language ideas from LLMs into working code and run the experiments at scale?
- Do LLMs get better at proposing ideas if they can see the results of those experiments?
- Which way of learning from results works better: trying many variations and keeping the best ones (evolutionary search), or training the model with rewards (reinforcement learning, or RL)?
- How good are today’s top LLMs at both proposing ideas and turning them into working code?
3. How did they do it?
They built an automated “research lab” that works like a production line:
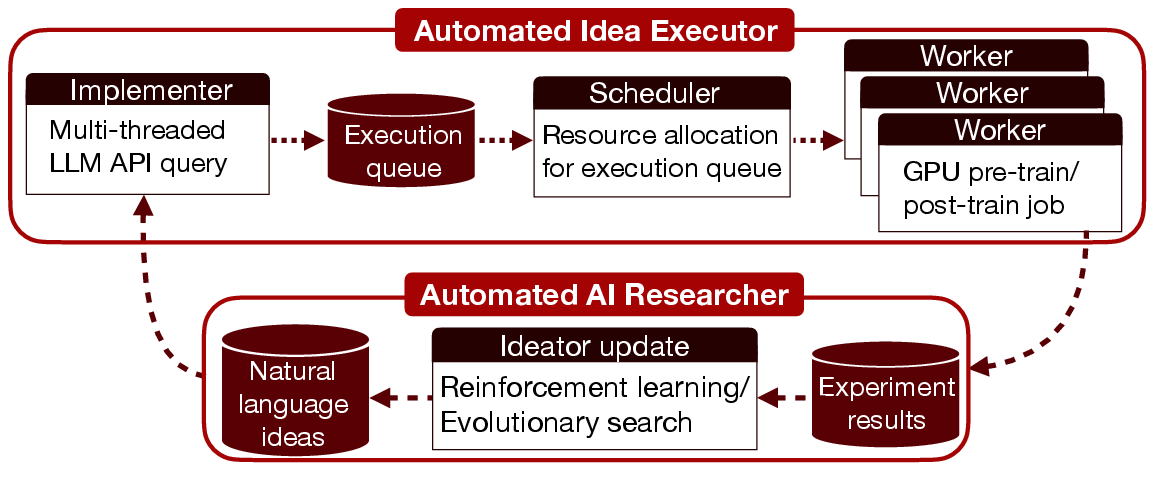
- Implementer: reads a plain‑English idea, edits the baseline code using an AI coder, and produces a ready‑to‑run code change.
- Scheduler: assigns the job to available compute.
- Worker: runs the experiment on GPUs and uploads the results (like accuracy, loss, logs).
You can think of it like a team where one robot writes code, one manages the job queue, and one runs the tests.
They tested this system on two real and challenging AI problems:
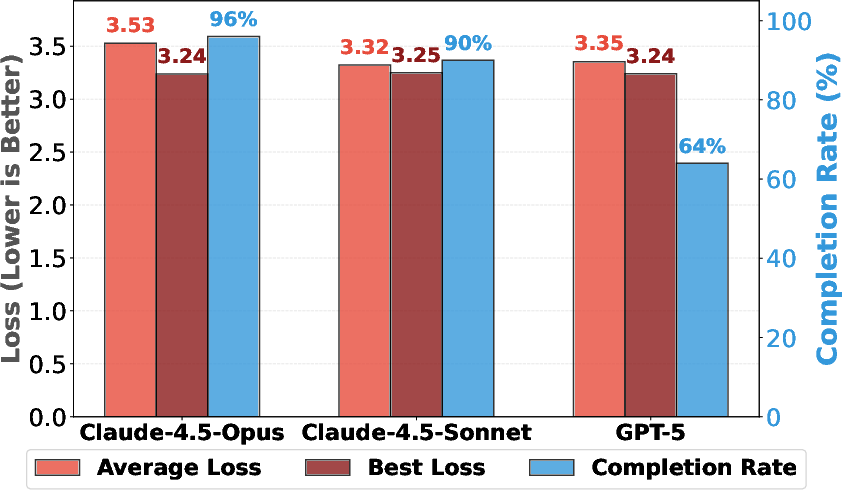
- Pre‑training speed: Train a small GPT‑2–style model faster to reach a target quality (lower “validation loss” means better). Baseline: “nanoGPT” speedrun.
- Post‑training for reasoning: Fine‑tune a 1.5B‑parameter model to solve math problems better (higher “validation accuracy” is better). Baseline: “GRPO,” a known training method.
To keep things fair, they locked evaluation settings so the models couldn’t “cheat” by changing how results are measured.
They tried two ways to improve idea quality from feedback:
- Evolutionary search: like breeding ideas—generate a batch, keep the better ones, make new variants, and repeat. It balances exploring new ideas and exploiting (refining) good ones.
- Reinforcement learning (RL): reward the model when an idea performs well, so it learns to produce more ideas like that. Here, the “reward” is the real experiment result.
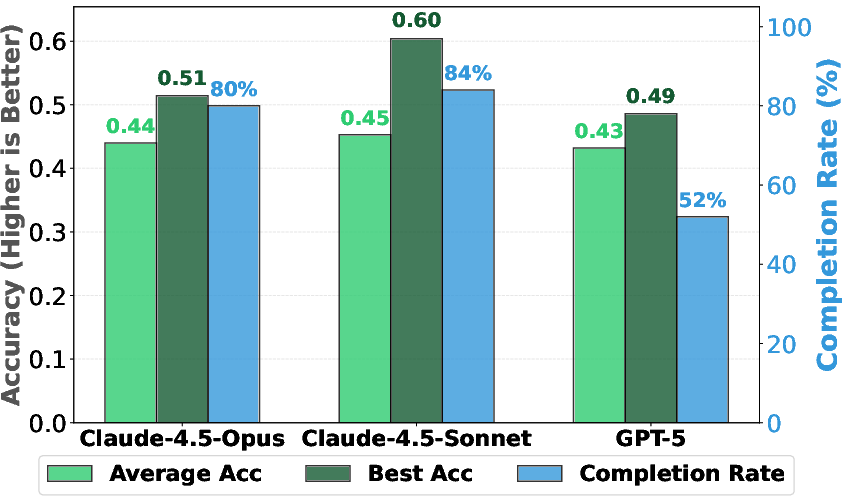
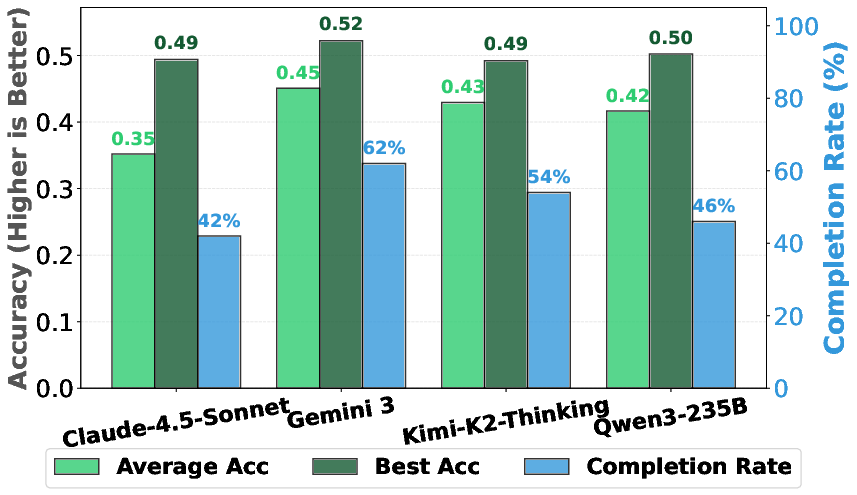
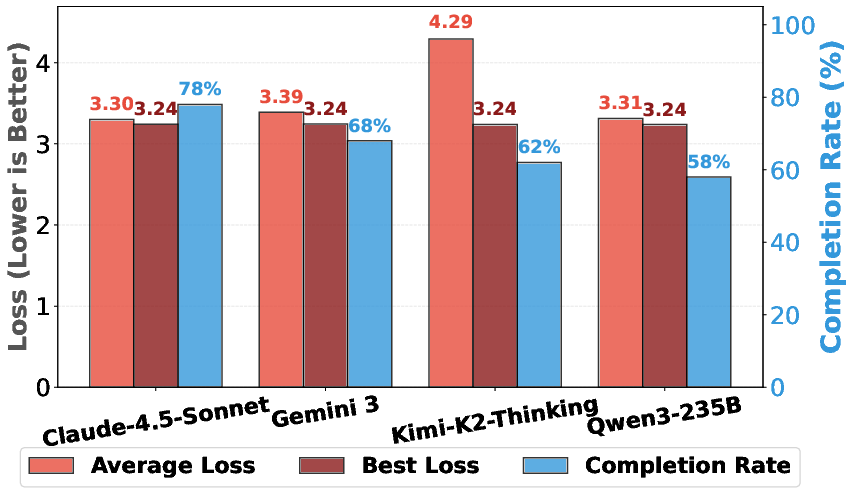
They also checked whether top LLMs can both invent ideas and implement them. Some models could successfully execute over 90% of their own sampled ideas in the pre‑training setup.
4. What did they find, and why does it matter?
Key results:
- It works end‑to‑end: Modern LLMs can propose ideas and write runnable code for tough, open‑ended problems. In many cases, the best of 50 sampled ideas already beat the starting baseline.
- Evolutionary search shines quickly:
- Post‑training (math reasoning): Their search found a method reaching 69.4% accuracy, compared to the baseline 48.0%.
- Pre‑training speed: Their search found a recipe that reached the target quality in 19.7 minutes, beating the baseline’s 35.9 minutes.
- Compared to humans: Their best post‑training result slightly beat the best student solution they had (68.8%). For pre‑training speed, top human experts are still faster (2.1 minutes), showing big headroom for improvement.
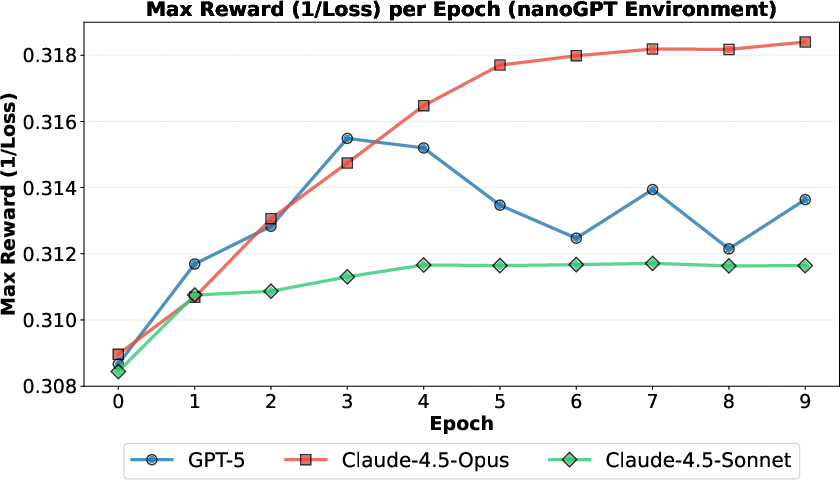
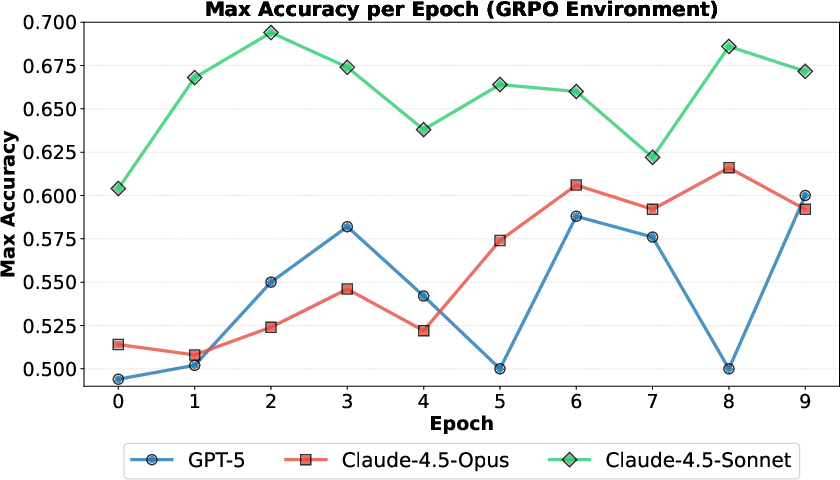
- Scaling behavior: One frontier model (Claude‑4.5‑Opus) kept improving as it searched longer; others (Claude‑4.5‑Sonnet, GPT‑5) improved early but then plateaued.
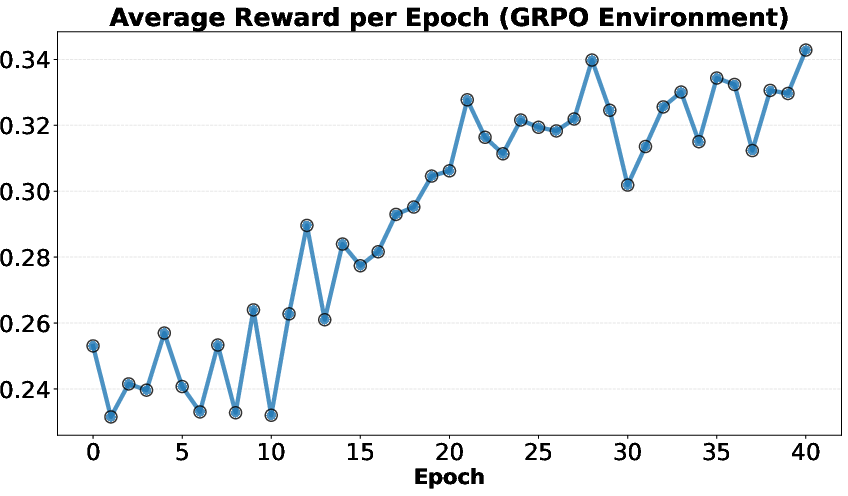
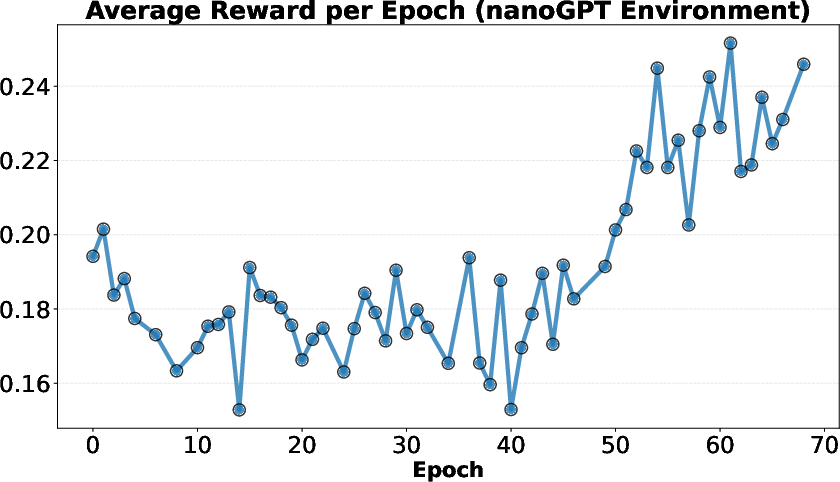
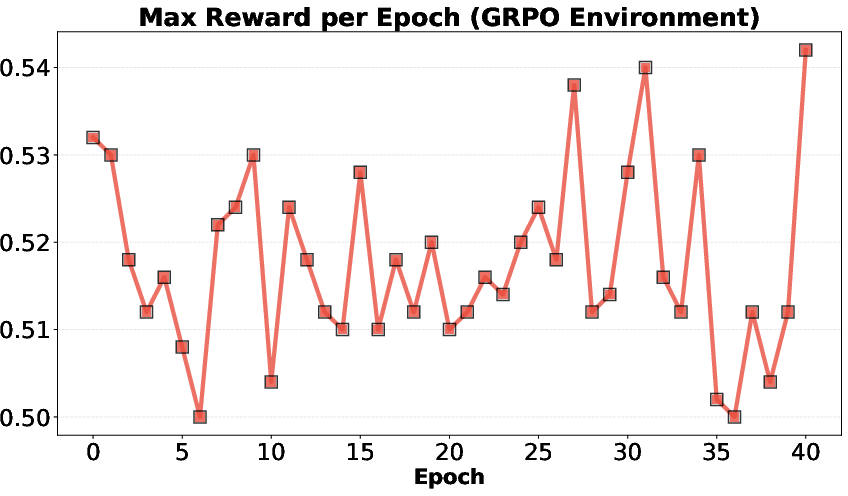
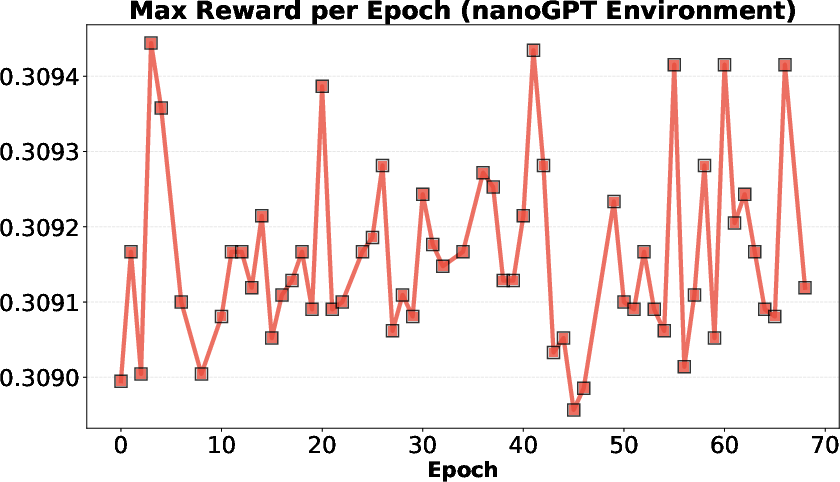
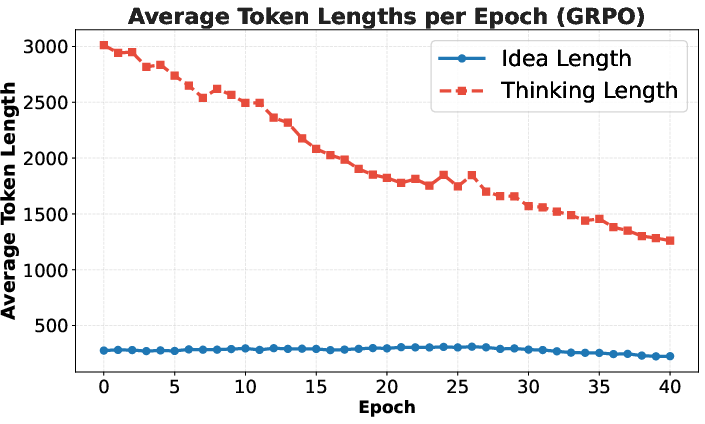
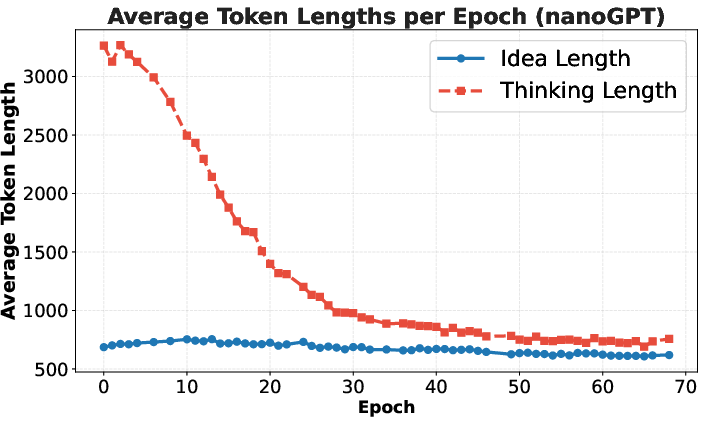
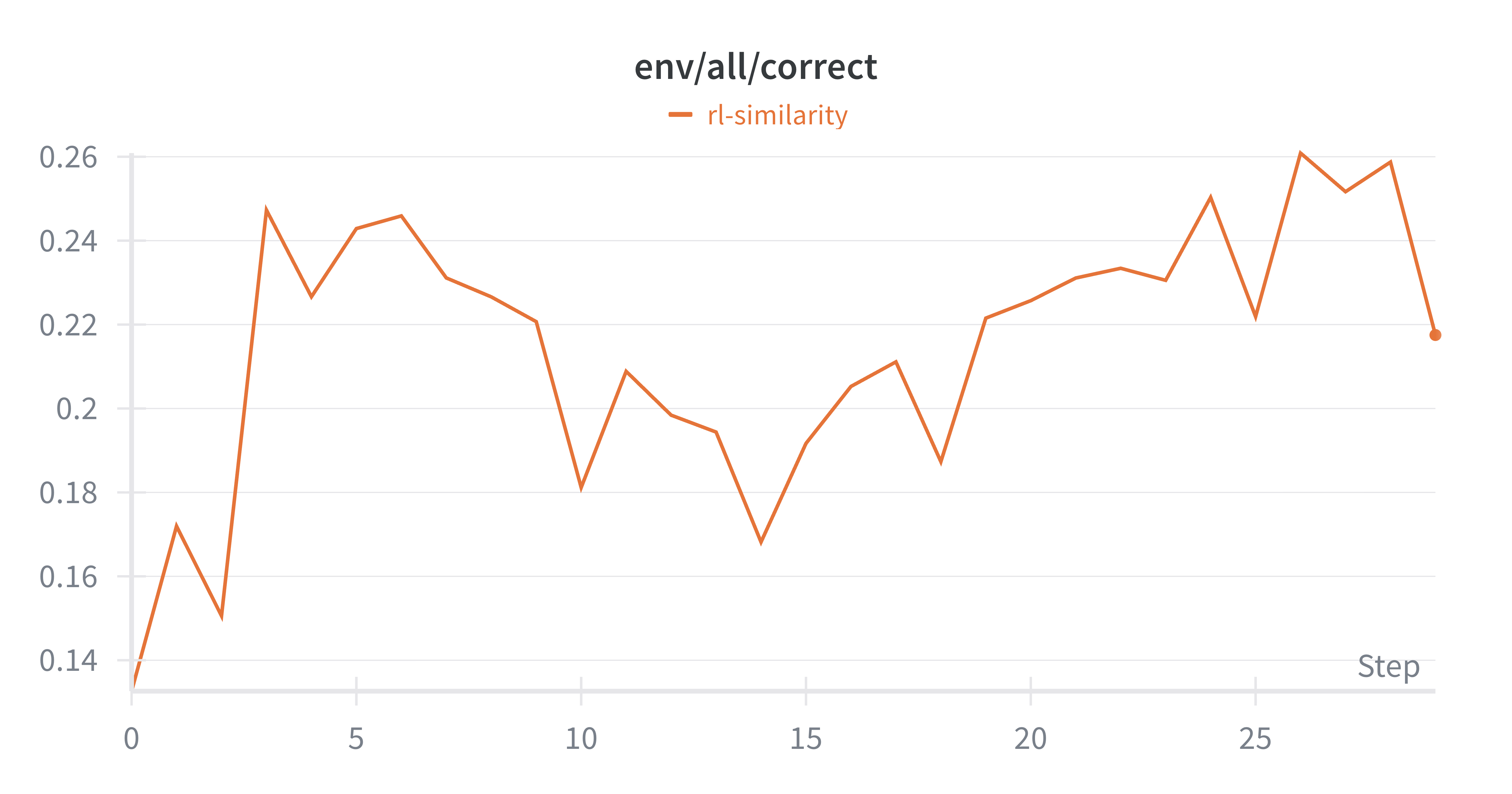
- RL had a catch: RL improved the average idea quality but not the single best idea in each round. The model started repeating a few simple, safe ideas and stopped exploring. Its “thinking” sections got shorter, and idea diversity dropped—this is called “mode collapse.”
Why this matters:
- The study shows that fully automated, execution‑driven AI research is feasible today on realistic problems.
- Evolutionary search is a strong, sample‑efficient way to turn compute into better ideas.
- Standard RL needs new tricks to keep creativity and push for breakthroughs, not just safer averages.
5. What’s the bigger impact?
This work is a first step toward AI systems that can rapidly test hundreds of ideas and learn what works—potentially speeding up scientific discovery. It also surfaces clear limits to fix next:
- Keep diversity high so the AI doesn’t fall back on easy, repetitive ideas.
- Aim for the best single idea, not just better averages—because breakthroughs drive real progress.
- Check that improvements at small scale carry over to larger models and different datasets.
In short: the authors built a working “AI research loop” that runs ideas, learns from the results, and improves. Evolutionary search already delivers strong gains; RL, as usually done, tends to play it safe. With better methods to preserve exploration and diversity, automated AI research could become a powerful engine for future discoveries.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future work could act on:
- Generalization beyond current scales and datasets: No tests of whether discovered ideas transfer from 124M GPT-2 pre-training and 1.5B math post-training to larger models, different domains (e.g., code, multimodal), or other datasets and compute regimes.
- Correlation between proxy rewards and true objectives: The nanoGPT search/RL uses a fixed-time proxy reward () but only measures wall-clock time-to-target for the top solution; the correlation between the proxy and speedrun objective is unquantified, leaving potential mis-optimization.
- Overfitting to validation metrics: Effectiveness is judged by max validation accuracy (post-training) and validation loss (pre-training) in a single run; no repeated seeds, no hidden test sets, and no assessment of generalization robustness or sensitivity to random initialization.
- Statistical rigor and variance: Lack of confidence intervals, significance testing, or multiple-run averages for reported “best” results; unclear how robust the improvements are to stochasticity.
- Limited environments: Only two environments (nanoGPT speedrun, GRPO math post-training) are used; the approach’s breadth is unknown across other open-ended ML tasks (e.g., data curation, retrieval, alignment methods, RLHF variants, system-level optimizations).
- Executor–ideator coupling: Higher completion under self-execution suggests stylistic coupling between ideator and executor; the paper does not decouple or standardize executors to fairly compare ideators across a fixed implementation backbone.
- Causes of execution failures: No taxonomy or quantitative analysis of failure modes (e.g., patch conflicts, runtime errors, shape mismatches, OOM, API misuse) or how to mitigate them; no predictive modeling of executability from idea features.
- Implementer selection policy: The implementer returns the first diff that patches after up to two revisions; there is no selection among multiple viable diffs based on static checks, unit tests, linting, or predicted run success/performance.
- Lack of automated debugging loops: Workers halt on failure with no automated repair/debug cycles beyond initial patch retries; uncertain how many failures could be recovered with programmatic debugging/refinement.
- Safety and sandboxing: Executing arbitrary LLM-generated code on GPUs raises security risks; the paper does not detail sandboxing, network isolation, permissioning, or resource guardrails.
- Compute and carbon cost: RL uses group sizes that imply up to 1024 simultaneous GPUs per training epoch; there is no analysis of cost, throughput, energy, or carbon, nor methods for multi-fidelity or proxy evaluations to reduce cost.
- Multi-fidelity optimization: No use of staged or surrogate evaluations (e.g., short training, smaller models, partial datasets, learned performance predictors) to pre-screen ideas before expensive runs.
- Exploration vs exploitation design: The evolutionary schedule (batch sizes, annealing of exploitation rate, prompt context size) is not ablated; sensitivity to these choices and principled schedule design remain open.
- Comparison to stronger optimizers: Best-of-N is the only non-evolutionary baseline; no comparison against Bayesian optimization, bandit/Thompson sampling, population-based training, novelty search, or quality–diversity methods.
- RL objective misalignment: RL improves average but not max reward, yet discovery is driven by upper-tail performance; there is no tested objective explicitly targeting upper quantiles, extreme-value optimization, or reward distributions rather than means.
- Preventing diversity collapse: RL exhibits mode collapse to easy-to-implement ideas; initial remedies (length reward, similarity penalty, prompt replay) were inconclusive and early-stopped; principled mechanisms (e.g., novelty bonuses, entropy/QLD regularizers, population-based RL, Pareto multi-objective for novelty–quality–executability) are untested.
- Richer rewards from trajectories: Rewards are scalar outcomes only; the system logs rich metadata (training curves, runtime stats, errors), but there is no learning from intermediate signals (e.g., training dynamics, gradient norms, overfitting indicators) or structured credit assignment for partial progress.
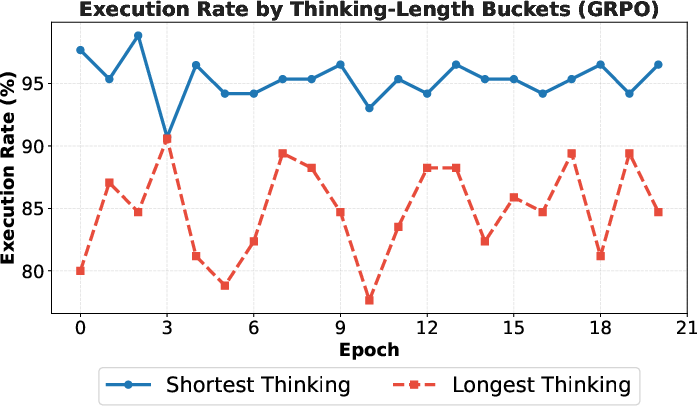
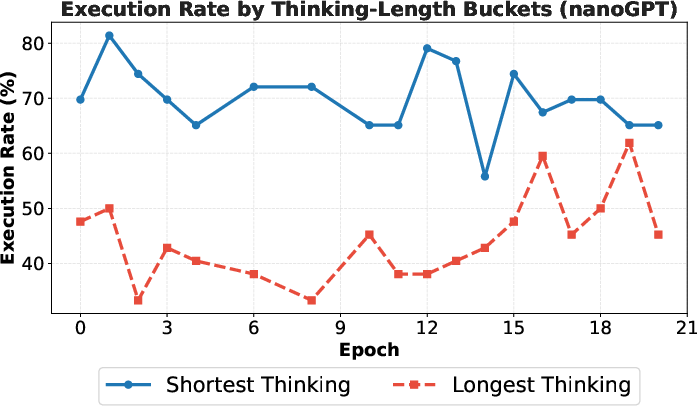
- Idea complexity vs executability: Longer “thinking” correlates with lower execution rates, but complexity metrics are not quantified; can models be encouraged to propose complex yet implementable ideas via complexity-aware rewards or staged implementation plans?
- Role of thinking traces: Only the final idea is executed; the impact of passing structured plans or code-aware rationales to the implementer is untested; could chain-of-code or tool-augmented reasoning improve executability and performance?
- Fairness of evaluation manipulations: Some high-scoring pre-training ideas (e.g., EMA of parameters) may alter effective evaluation; although inference safeguards are described, the scope of permissible training-time changes vs evaluation-time effects is not fully audited for “reward hacking.”
- Novelty and attribution: The system can rediscover papers, but novelty is not quantified; there is no mechanism to detect near-duplicates, attribute inspirations, or prioritize genuinely novel contributions.
- LLM-judge reliability: Classification of “hyper-parameter” vs “algorithmic” ideas relies on an LLM-judge without reported calibration, agreement with humans, or error analysis; taxonomy and labeling quality remain uncertain.
- Scaling trends across models: Sonnet and GPT-5 saturate early while Opus scales; the causes (model size, sampling parameters, search scaffold, implementer differences) are not probed via controlled ablations.
- Cross-executor robustness: Execution rates drop when ideas are executed by a different model (e.g., Sonnet ideas executed by GPT-5); how to make ideas executor-agnostic is unresolved.
- Resource-aware scheduling: The scheduler is described but unoptimized; there is no study of scheduling policies, preemption, prioritization (e.g., optimistic allocation to high-promise ideas), or fairness/cost-aware sampling.
- Large refactors and multi-file changes: Diff-based patching may limit large or multi-step refactors; there is no iterative multi-PR or branch strategy to support complex architectural changes.
- Reproducibility and seeds: Prompts, sampling temperatures, seeds, and code versions affect outcomes; the paper does not provide seed-robustness studies or standardized reproducibility protocols for end-to-end runs.
- Transfer learning for ideation: RL is trained on a single prompt per environment; there is no multi-task or meta-learning setup to generalize ideation policies across tasks/environments.
- Human-in-the-loop strategies: No experiments on mixed-initiative workflows (e.g., human triage, veto, or repair) to improve sample efficiency, safety, or novelty.
- Benchmark leakage and contamination: Frontier models may have been trained on related repositories/papers; the system does not assess contamination or adjust claims about originality accordingly.
- Metric design for quality–novelty–impact: The optimization is single-metric (accuracy/loss), ignoring novelty, interpretability, reproducibility, or implementation cost; multi-objective definitions and Pareto evaluation are left open.
Glossary
- Advantage (policy gradient): In policy-gradient RL, the advantage estimates how much better an action is than a baseline, shaping the weight of updates. "Instead of using absolute advantage magnitude, weight samples by how far their rank differs from their expected rank under uniform distribution."
- Annealing schedule: A predefined schedule that gradually adjusts a parameter (e.g., exploration/exploitation rate) over training epochs. "annealing schedule for "
- Automated idea executor: A system that converts natural-language ideas into code, runs experiments, and returns measurable performance as feedback. "we design and build a high-throughput automated idea executor that can implement hundreds of model-generated ideas and execute them in parallel"
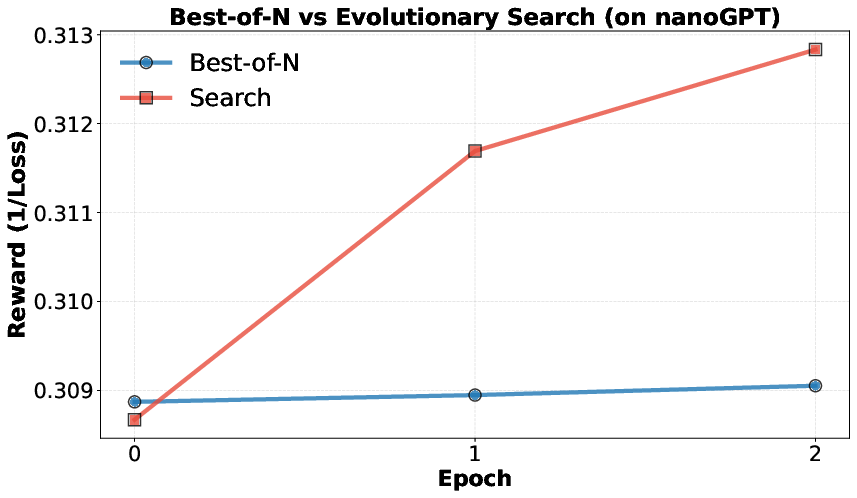
- Best-of-N: A selection strategy that samples N candidates and picks the best outcome without learning from intermediate feedback. "evolutionary search significantly outperforms best-of-N under the same sampling budget."
- Code diff: A patch that specifies changes to a codebase, used to apply model-proposed modifications automatically. "obtain a diff file that can be patched into the corresponding baseline codebase."
- EMA (Exponential Moving Average): A smoothing technique that maintains a running average (e.g., of parameters or metrics) with exponentially decaying weights. "applying exponential moving average of intermediate checkpoints during validation"
- Executor model: The model responsible for implementing and running ideas (i.e., code execution), potentially different from the ideator. "we fix the executor model to be GPT-5 and use different ideator models to sample ideas."
- Execution grounding: Conditioning idea generation on actual implementation and experimental feedback to avoid speculative, unverifiable proposals. "Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback."
- Execution-guided search: A search procedure that leverages execution results as feedback to guide subsequent idea generation and selection. "Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline"
- Evolutionary search: A black-box optimization method that iteratively samples, evaluates, and mutates candidates without gradient updates. "Evolutionary search is a traditional optimization method without the need for gradient updates."
- FineWeb corpus: A large web-text dataset used for LLM pre-training and benchmarking. "pre-train a 124M GPT-2 model on the FineWeb corpus"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm variant (related to PPO) that uses group-based baselines and ratios to stabilize updates. "the baseline is an implementation of the GRPO algorithm"
- Group-average baseline: In policy gradient methods, a variance-reduction baseline equal to the average reward (or advantage) within a sampled group. "using vanilla policy gradient with the group-average baseline"
- Ideator model: The model tasked with generating research ideas to be implemented and evaluated. "improve the average reward of the ideator model"
- Importance reweighting: Adjusting sample contributions using likelihood ratios to correct for distribution shift between behavior and target policies. "without importance reweighting or clipping"
- Importance sampling ratio: The ratio of target-policy to behavior-policy probabilities used to reweight off-policy samples. "Instead of directly using the (importance sampling) ratio, ..."
- LayerNorm: A neural network normalization technique applied across feature dimensions of a layer's activations. "replacing RMSNorm with LayerNorm"
- Mode collapse: A failure mode where generated outputs lose diversity and concentrate on a few patterns. "Reinforcement learning from execution reward, on the other hand, suffers from mode collapse."
- nanoGPT: A compact GPT-2-style training codebase/benchmark used for speedrun-style pre-training experiments. "In the nanoGPT environment, we provide a baseline codebase adapted from the nanoGPT speedrun"
- Open-weight models: Foundation models whose parameters are publicly released for use and finetuning. "frontier open-weight models like Kimi-K2-Thinking and Qwen3-235B-A22B"
- pass@k: A metric measuring the probability of success within k attempts (commonly used in code and reasoning benchmarks). "where the pass@k performance stagnates or even decreases after RL"
- Policy gradient: A family of RL methods that directly optimize the expected reward by estimating gradients with respect to policy parameters. "using vanilla policy gradient with the group-average baseline"
- Post-training: Finetuning or alignment stages after base pre-training to improve downstream performance or behavior. "two realistic research problems -- LLM pre-training and post-training"
- Pre-training: Large-scale initial training of a model on broad corpora before task-specific finetuning. "two realistic research problems -- LLM pre-training and post-training"
- Reciprocal-of-loss reward: A reward shaping choice using the inverse of validation loss, turning lower loss into higher reward. "we introduce a proxy reward equal to the reciprocal of the validation loss ()"
- Reinforcement learning from verifiable rewards: RL that uses deterministic, programmatically checkable rewards (e.g., accuracy, unit tests) as signals. "similar to typical RL from verifiable rewards."
- Reward hacking: Exploiting loopholes in the evaluation or environment to inflate reward without genuine improvement. "To avoid any possible reward hacking, we freeze all evaluation hyper-parameters"
- Rollout: A sampled sequence/output from a policy used for evaluation and learning in RL. "Each rollout is a thinking trace followed by the natural language idea."
- RMSNorm: A normalization method using root-mean-square statistics instead of mean/variance as in LayerNorm. "replacing RMSNorm with LayerNorm"
- Scaling trend: The observed improvement in performance as model size, compute, or search effort increases. "Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends."
- Search scaffold: A structured orchestration (prompts, loops, selection rules) that organizes iterative idea generation and evaluation. "We develop an evolutionary search scaffold on top of frontier LLMs"
- Self-execution: A setting where an LLM executes its own proposed ideas (acts as both ideator and executor). "Self-Execution (GRPO)"
- Thinking trace: The model’s intermediate reasoning or chain-of-thought prior to producing the final idea or answer. "models would generate a thinking trace, followed by the natural language idea"
- Token-level reward attribution: Assigning credit or weights to individual tokens based on their contribution to outcomes, to guide learning. "Implement token-level reward attribution by using attention weights to identify which input tokens contributed most to correct answers"
- wandb: An experiment tracking and artifact logging service (Weights & Biases) used to store metrics and metadata. "another cloud bucket (wandb)"
Practical Applications
Immediate Applications
The following applications can be deployed today based on the paper’s findings and released environments. Each bullet notes sector relevance, potential tools/products/workflows, and assumptions/dependencies that impact feasibility.
- Execution‑grounded evolutionary search for LLM training pipelines
- Sector: software/AI, MLOps
- What to do: Integrate the Implementer–Scheduler–Worker stack to run execution‑guided evolutionary search on pre‑training/post‑training recipes; use exploitation/exploration prompts to generate and implement idea variants; select top performers by validation metrics.
- Tools/workflows: Claude/GPT/Qwen ideator+executor, wandb logging, cloud/HPC GPUs, nanoGPT and GRPO baseline codebases, diff‑patch implementation prompts, annealed exploration schedule.
- Assumptions/dependencies: Access to robust code‑execution LLMs and GPU clusters; sandboxing to safely run untrusted code; frozen evaluation hyperparameters to prevent reward hacking; cost controls for parallel execution.
- Post‑training optimization for domain‑specific tasks (e.g., math, coding, instruction following)
- Sector: software/AI
- What to do: Apply execution‑guided search to improve GRPO (or RLHF/RLAIF analogs) for a target domain; treat validation accuracy as reward and iterate on algorithmic updates and hyperparameters.
- Tools/workflows: GRPO baseline, group‑based evaluation pipelines, curated domain datasets, automated diff generation and patching.
- Assumptions/dependencies: Stable benchmarks and tightly controlled validation; guardrails against leaking labels or changing validation code.
- Pre‑training recipe acceleration under fixed budgets
- Sector: software/AI, cloud
- What to do: Optimize pre‑training speed/quality tradeoffs (e.g., target loss in fixed clock time) via execution‑guided search using nanoGPT‑style setups; port top ideas (e.g., EMA usage, architecture tweaks) to production pipelines.
- Tools/workflows: Fixed wall‑clock budgeting, reciprocal‑of‑loss proxy rewards, inference function that prevents future‑token leakage, batch search with 50–80 ideas/epoch.
- Assumptions/dependencies: Dataset licensing (e.g., FineWeb), reproducible evaluation, careful proxy reward selection to avoid overfitting to speed rather than generalization.
- Research CI/CD: “Idea‑diff testing” as a pre‑merge gate
- Sector: MLOps, software engineering
- What to do: Augment PR workflows with automatic idea‑to‑diff generation, patchability checks, small‑scale benchmark runs, and pass/fail thresholds on validation metrics before merging experimental changes.
- Tools/workflows: Implementer API, diff patch logs, job scheduler, isolated workers; automatic artifact/metadata capture (idea content, code changes, logs).
- Assumptions/dependencies: Compute quotas, secure code sandboxing, reproducible mini‑benchmarks.
- Model procurement and benchmarking service for ideation/execution capability
- Sector: AI evaluation, enterprise procurement
- What to do: Evaluate candidate LLMs on completion rate, average performance, and best‑of‑N performance in the provided environments; select models for code‑execution tasks based on empirical readiness.
- Tools/workflows: Fixed executor (e.g., GPT‑5) vs self‑execution comparisons, standardized prompts and metrics, longitudinal scaling curves.
- Assumptions/dependencies: API access to proprietary models; fair, identical prompts and context budgets; transparent reporting.
- Course/lab infrastructure for automated AI research
- Sector: education
- What to do: Use the open‑sourced environments and executor as hands‑on assignments/labs (e.g., CS336‑style), letting students/teams submit natural‑language ideas that auto‑implement and run at scale; track accuracy/loss, execution rates, and best solutions.
- Tools/workflows: GitHub repo, course‑managed GPU queues, wandb dashboards, idea trajectory archiving.
- Assumptions/dependencies: Institutional compute budgets; strict evaluation separation; academic policies for code safety.
- Governance and test‑harness standards to reduce reward hacking
- Sector: policy, compliance, AI safety
- What to do: Adopt frozen validation pipelines, isolate evaluation code from executor access, and deploy token‑by‑token inference functions to prevent leakage; mandate execution‑grounded claims in internal reviews.
- Tools/workflows: Compliance checklists, code isolation patterns, reproducible evaluation harnesses.
- Assumptions/dependencies: Organizational buy‑in; security reviews for running LLM‑generated code.
- Cluster throughput optimization for research experiments
- Sector: HPC operations, energy/IT
- What to do: Deploy the Scheduler design to batch, allocate, and monitor large numbers of short‑to‑medium experiments; prioritize high‑value runs based on evolving search rewards.
- Tools/workflows: Job queueing, resource estimation, throttling, failure handling and retries; cost/energy monitoring.
- Assumptions/dependencies: Admin access to cluster; robust telemetry; safe containerization and micro‑VM isolation for untrusted runs.
- “Research Copilot” productization for R&D teams
- Sector: software/AI products
- What to build: A managed SaaS that ingests natural‑language ideas and returns validated metrics plus code diffs; supports search scaffolds (explore/exploit), experiment tracking, and artifact retrieval.
- Tools/workflows: API endpoints for idea submission, automated diff application, run orchestration, dashboards for best‑of‑N and scaling curves.
- Assumptions/dependencies: Reliability SLAs for execution; legal and IP policies for model‑generated code; usage‑based pricing.
- Immediate training‑strategy guidance: prefer evolutionary search over standard RL for upper‑bound discovery
- Sector: research strategy, AI training
- What to do: Use execution‑guided evolutionary search when aiming for breakthrough ideas; caution against GRPO‑style RL for ideation where diversity and upper‑tail performance matter (mean improves, max stagnates).
- Tools/workflows: Exploit/explore schedules, novelty prompts, curated trajectory context; optional diversity penalties and length rewards (pilot).
- Assumptions/dependencies: Acceptance that upper‑bound innovation differs from average‑quality optimization; willingness to invest in parallel search runs.
Long‑Term Applications
The following applications require further research, scaling, algorithmic advances, or broader adoption.
- Autonomous, execution‑grounded AI research agents across domains
- Sector: cross‑disciplinary science (computational biology, materials, energy systems, robotics)
- Vision: Agents that propose ideas, implement code, run simulations/experiments, and learn from execution feedback to discover novel algorithms or designs.
- Tools/workflows: Domain‑specific environments with high‑fidelity simulators, adapters for non‑ML tasks, multi‑objective rewards (effectiveness, stability, generalization).
- Assumptions/dependencies: Availability of realistic simulators and verified benchmarks; safe, sandboxed execution; domain data licensing.
- Upper‑tail‑aware RL for innovation (diversity‑preserving, novelty‑seeking objectives)
- Sector: AI research methods
- Vision: RL algorithms that improve max reward (not just average) via exploration bonuses, novelty search, entropy regularization, mixture‑of‑policies, or bandit‑style upper‑confidence bounds; richer execution signals than scalar rewards.
- Tools/workflows: Tail‑focused objectives, diversity metrics, trajectory‑level rewards, curriculum over complexity; off‑policy replay with novelty prioritization.
- Assumptions/dependencies: Reliable credit assignment from complex multi‑step executions; scalable training with large groups; careful avoidance of mode collapse.
- Generalization and scalability promotion pipelines
- Sector: AI/ML engineering
- Vision: Automatic “promotion” of promising ideas to larger models/datasets and cross‑domain tests; integrate out‑of‑distribution checks to ensure real‑world viability.
- Tools/workflows: Multi‑stage gates (small‑scale → medium‑scale → full‑scale), cross‑dataset validation, variance reporting, robustness metrics.
- Assumptions/dependencies: Significant compute budgets; rigorous statistical protocols; data governance.
- Compute‑to‑discovery platforms and budget governance
- Sector: finance/operations, enterprise IT
- Vision: Products that let organizations strategically convert GPU budgets into validated discoveries; dashboards for ROI per experiment, energy cost, and risk.
- Tools/workflows: Experiment marketplaces, quota management, cost‑aware schedulers, auto‑stopping for poor performers.
- Assumptions/dependencies: Clear value attribution; compliance with sustainability/energy policies; procurement alignment.
- Standardized, execution‑grounded evaluation frameworks for AI claims
- Sector: policy/regulation, standards bodies
- Vision: Regulatory or industry standards requiring execution‑based evidence for AI performance claims (preventing “paper‑only” hype).
- Tools/workflows: Certification suites, audit trails of trajectories, reproducibility checks, public registries of executed claims.
- Assumptions/dependencies: Broad stakeholder consensus; legal frameworks for auditing model‑generated code; privacy/data rights.
- Organization‑wide “idea memory” and retrieval over executed trajectories
- Sector: enterprise software/knowledge management
- Vision: A knowledge graph of ideas, diffs, outcomes, and contexts; enable retrieval‑augmented ideation that builds on past executed ideas.
- Tools/workflows: Vector databases, graph stores, idea normalization, similarity search, lineage tracking.
- Assumptions/dependencies: IP ownership/attribution for model‑generated ideas; data security; consistent metadata standards.
- Secure execution of untrusted, LLM‑generated code at scale
- Sector: cybersecurity, DevSecOps
- Vision: Hardened execution environments (micro‑VMs, seccomp profiles, network isolation) to safely run high‑volume experiments.
- Tools/workflows: Policy engines, dynamic sandboxing, supply‑chain scanning for dependencies, anomaly detection on runs.
- Assumptions/dependencies: Acceptable overhead vs throughput; red‑team testing; incident response procedures.
- Democratized cloud research labs for SMEs and independent researchers
- Sector: cloud services, education
- Vision: Pay‑per‑experiment services offering execution‑grounded ideation for smaller budgets; “bring your dataset” pathways and template environments.
- Tools/workflows: Usage‑based pricing, low‑cost GPU tiers, curated starter environments (NLP, vision, tabular).
- Assumptions/dependencies: Cost efficiency; simple onboarding; fair use and data licensing.
- Energy‑aware scheduling and sustainability optimization
- Sector: energy, IT sustainability
- Vision: Schedulers that minimize energy/CO2 per discovery via time‑of‑day shifting, hardware heterogeneity, and workload consolidation.
- Tools/workflows: Energy telemetry, carbon accounting, policy‑driven job routing.
- Assumptions/dependencies: Access to accurate energy metrics; organizational sustainability targets.
- Legal/IP frameworks for model‑generated research outputs
- Sector: legal/policy
- Vision: Clear ownership, licensing, and attribution practices for ideas and code diffs produced by LLMs; norms for sharing trajectories and crediting contributions.
- Tools/workflows: Contributor license agreements adapted to AI generation, internal policies, provenance tracking.
- Assumptions/dependencies: Evolving legal interpretations; cross‑jurisdiction harmonization.
Notes on feasibility and scope across applications:
- Strong dependencies on large‑scale GPU resources and reliable code‑execution LLMs; costs and throughput are central constraints.
- Security and governance are prerequisite: sandbox untrusted code, freeze evaluation paths, and log detailed trajectories to avoid reward hacking.
- Current methods excel at improving average performance; upper‑bound discovery benefits more from evolutionary search than GRPO‑style RL, which tends to mode‑collapse—algorithmic advances are needed for long‑term RL viability.
- Generalizability beyond the tested environments (nanoGPT, GRPO on MATH) requires explicit scaling and cross‑dataset validation before production deployment.
Collections
Sign up for free to add this paper to one or more collections.