- The paper introduces GitTaskBench, a benchmark evaluating code agents on 54 real-world tasks using authentic GitHub repositories.
- It employs a rigorous four-step data curation and evaluation process, integrating automated scripts and human expertise.
- Results show a maximum 48.15% task pass rate, highlighting challenges in environment setup and dependency resolution for current agents.
GitTaskBench: Evaluating Code Agents on Real-World Repository-Centric Tasks
Motivation and Benchmark Design
GitTaskBench addresses a critical gap in code agent evaluation: the ability to autonomously leverage large-scale, real-world code repositories to solve practical, end-to-end tasks. Unlike prior benchmarks that focus on isolated code generation or synthetic environments, GitTaskBench systematically assesses agents on 54 authentic tasks spanning 7 modalities and 7 domains, each paired with a relevant GitHub repository and automated, human-curated evaluation harnesses. The benchmark emphasizes three dimensions: overall coding mastery (including documentation navigation and codebase reasoning), task-oriented execution (multi-turn reasoning and tool usage), and autonomous environment provisioning (dependency resolution and setup without pre-built support).
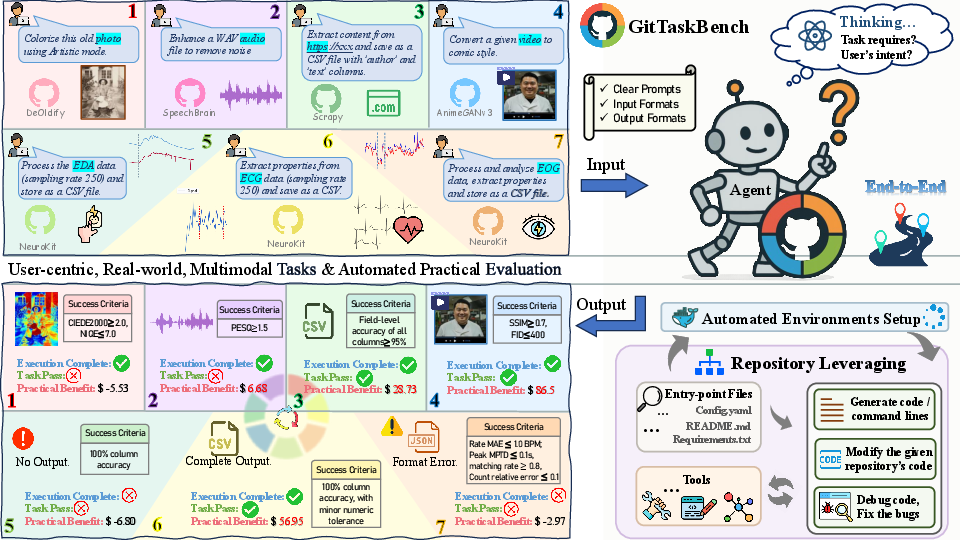
Figure 1: Overview of GitTaskBench, illustrating 7 example real-life tasks from different modalities and their evaluation criteria.
The benchmark construction follows a rigorous four-step process: domain and repository selection, completeness verification, execution framework design, and evaluation framework development. Each task is defined with explicit input-output requirements and practical success criteria, ensuring that agent performance is measured against real-world standards rather than synthetic proxies.
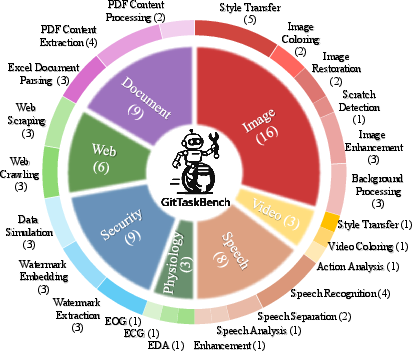
Figure 2: Overview of task domains in GitTaskBench, highlighting the diversity of modalities and application areas.
Data Curation and Evaluation Pipeline
GitTaskBench's data curation pipeline integrates human expertise and LLM assistance to select and validate repositories. Repositories are required to be Python-based, active, and well-documented, with all dependencies and resources made self-contained for reproducibility. Completeness verification ensures that each repository is fully operational and that all required resources are accessible.
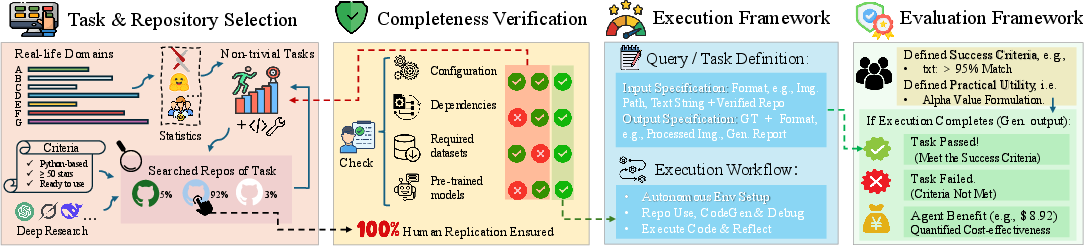
Figure 3: Overview of the GitTaskBench data curation and processing pipeline, detailing the selection, verification, and evaluation stages.
The execution framework provides agents with both the repository and a natural-language task prompt. Agents must autonomously analyze the repository, generate or modify code, set up the environment, and execute the solution in a sandbox. Automated evaluation scripts assess both execution completion (ECR) and task pass rate (TPR) using domain-specific metrics, such as CIEDE2000 for image coloring or SNR/SDR for speech separation.
Economic Value Assessment: The Alpha Metric
A novel contribution of GitTaskBench is the introduction of the alpha-value metric, which quantifies the economic benefit of agent performance by integrating task success, output quality, token cost, and prevailing human labor rates. The alpha score is defined as:
α=n1i=1∑n[(T×MV×Q)−C]
where T is task success, MV is market value, Q is output quality (human parity), and C is operational cost. This metric enables direct, interpretable comparisons between agent and human efficiency, and highlights the importance of cost-effectiveness in practical deployment.
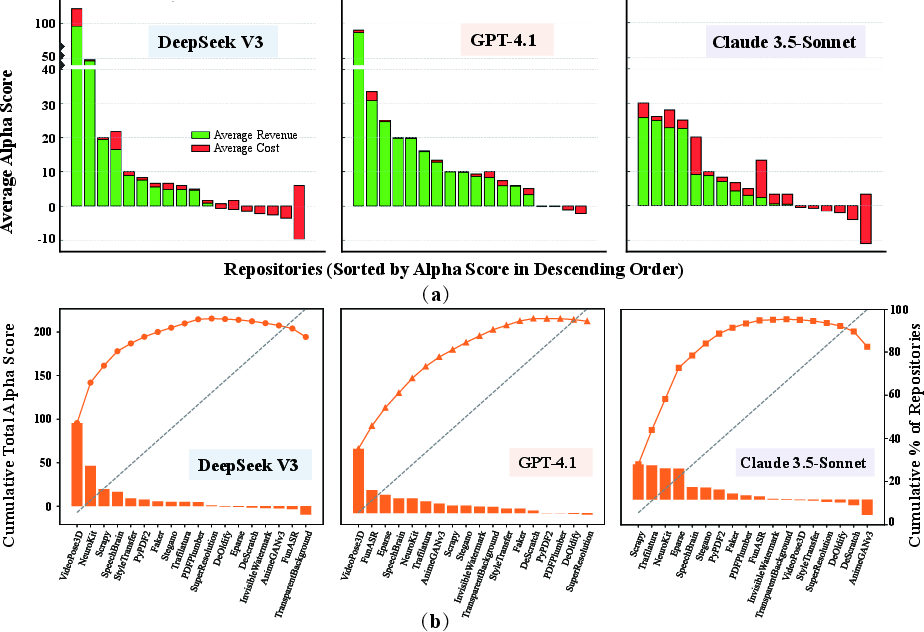
Figure 4: The α per repository (a) and Pareto curves (b), illustrating cost-benefit distributions across models and domains.
Experimental Results and Analysis
Experiments were conducted across three agent frameworks (OpenHands, SWE-Agent, Aider) and multiple advanced LLMs (GPT-4o, GPT-4.1, Claude 3.5/3.7, Gemini-2.5-pro, DeepSeek-V3, Qwen3, Llama3.3). The best-performing system, OpenHands+Claude 3.7, achieved only 48.15% task pass rate, underscoring the persistent difficulty of repository-centric task solving. Notably, agents excelled in textual tasks (e.g., document parsing) but struggled with multimodal, model-based tasks (e.g., image restoration, speech separation), which require deeper codebase comprehension and robust environment management.
Hyperparameter sensitivity analysis revealed that increasing timeout and interaction rounds significantly improved success rates, but also increased token usage and cost. This highlights the trade-off between computational resources and agent effectiveness.
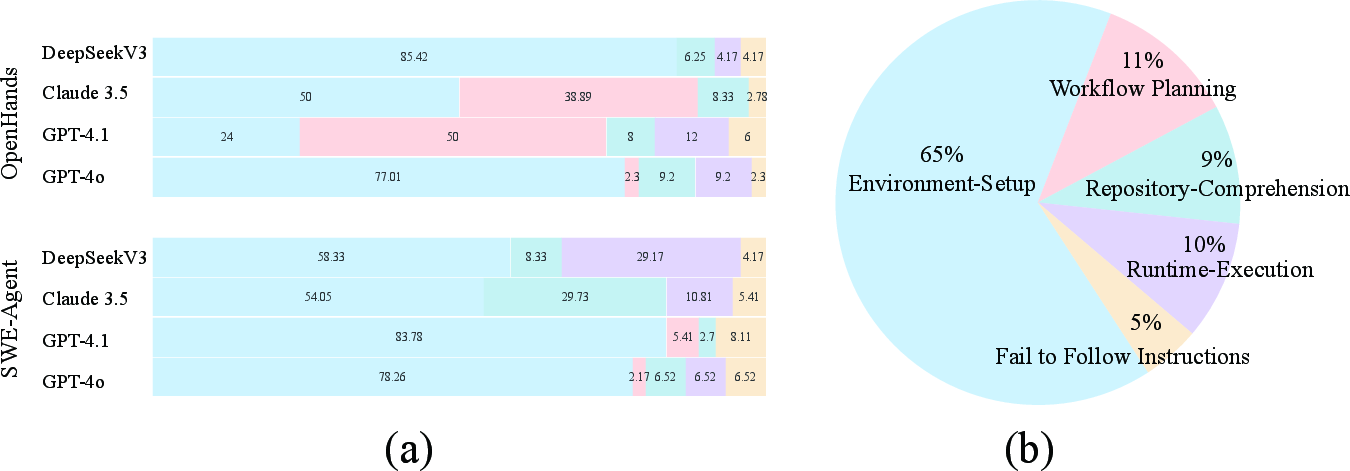
Figure 5: Distribution of errors per agent (a) and overall error statistics (b), showing that environment setup errors dominate failure modes.
Error analysis identified five primary failure types: environment setup (65.04% of failures), workflow planning, repository comprehension, runtime execution, and instruction non-compliance. Environment setup errors—such as dependency conflicts and missing system libraries—were the most prevalent, indicating that robust workflow management and automated dependency resolution are critical bottlenecks for real-world agent deployment.
Resource Efficiency and Scaling
Analysis of token usage versus repository size demonstrated that effective agents do not require exhaustive codebase reading. Instead, strategic exploration of documentation and key files enables efficient task completion, with input token costs not scaling linearly with repository size.
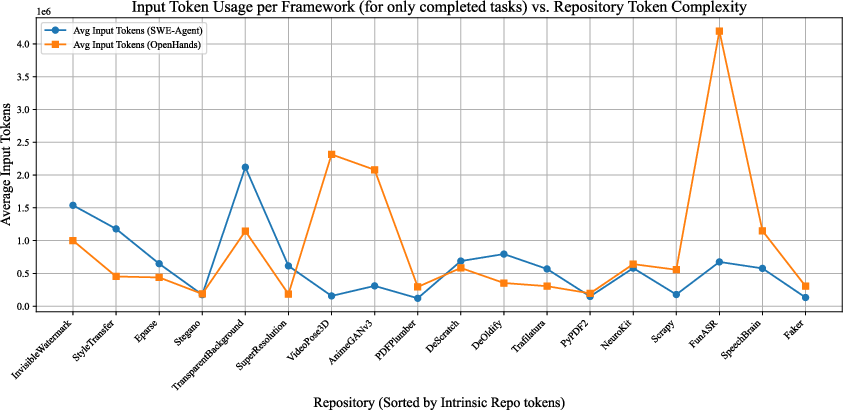
Figure 6: Relationship between repository size and input token usage for each framework, showing efficient resource utilization for process-successful tasks.
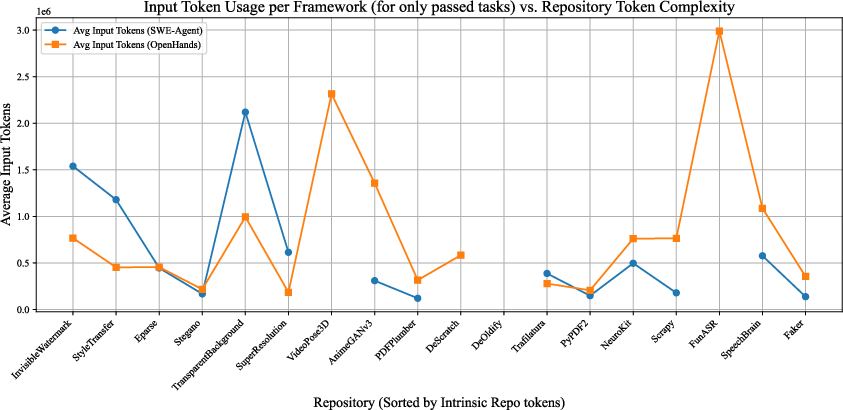
Figure 7: Input token usage per framework versus repository size for result-successful tasks, confirming non-linear scaling.
Implications and Future Directions
GitTaskBench establishes a new standard for evaluating code agents in realistic, repository-aware scenarios. The benchmark's emphasis on practical success criteria, economic value assessment, and detailed error analysis provides actionable insights for both agent development and deployment. The strong numerical result—less than 50% task pass rate for the best system—contradicts claims of near-human parity in code agent capabilities and highlights the need for advances in environment management, codebase reasoning, and workflow orchestration.
Practically, the alpha metric enables organizations to make informed decisions about agent deployment based on cost-benefit analysis, rather than technical metrics alone. Theoretically, GitTaskBench motivates research into agentic reasoning, tool integration, and autonomous software engineering workflows.
Future work should expand the benchmark to cover more domains, increase model coverage, and introduce live updates to track progress. Advances in agent frameworks should focus on robust dependency management, deeper repository comprehension, and adaptive workflow planning to address the identified bottlenecks.
Conclusion
GitTaskBench provides a comprehensive, user-centric benchmark for evaluating code agents on real-world, repository-leveraging tasks. Its rigorous design, practical evaluation criteria, and economic value assessment set a high bar for future research in autonomous software engineering. The benchmark reveals substantial challenges in current agent capabilities and offers a clear roadmap for both practical improvements and theoretical exploration in AI-driven code automation.
