- The paper introduces APEX, a benchmark that evaluates AI on economically valuable knowledge work using expert-designed prompts and precise rubrics.
- It employs 200 real-world cases across domains like law, medicine, and investment banking, with multi-judge evaluations ensuring objective scoring.
- Results reveal substantial performance gaps between closed-source and open-source models, underscoring the need for further advances in AI deployment.
The AI Productivity Index (APEX): Benchmarking Economically Valuable Knowledge Work
Motivation and Benchmark Design
The AI Productivity Index (APEX) addresses a critical gap in AI evaluation: the lack of benchmarks that directly measure the ability of frontier models to perform economically valuable knowledge work. Existing benchmarks predominantly focus on abstract reasoning, academic knowledge, or synthetic tasks, which do not reflect the complexity or value of real-world professional outputs. APEX-v1.0 is constructed to rigorously assess model performance on tasks that are representative of high-value roles in investment banking, management consulting, law, and primary medical care.
The benchmark comprises 200 cases, each designed and reviewed by domain experts with substantial industry experience. Each case includes a prompt that mirrors a real-world task, a set of evidence sources (up to 100,000 tokens), and a detailed rubric of objective, discrete criteria for evaluation. This design ensures high fidelity to actual workflows and the economic value of the outputs.
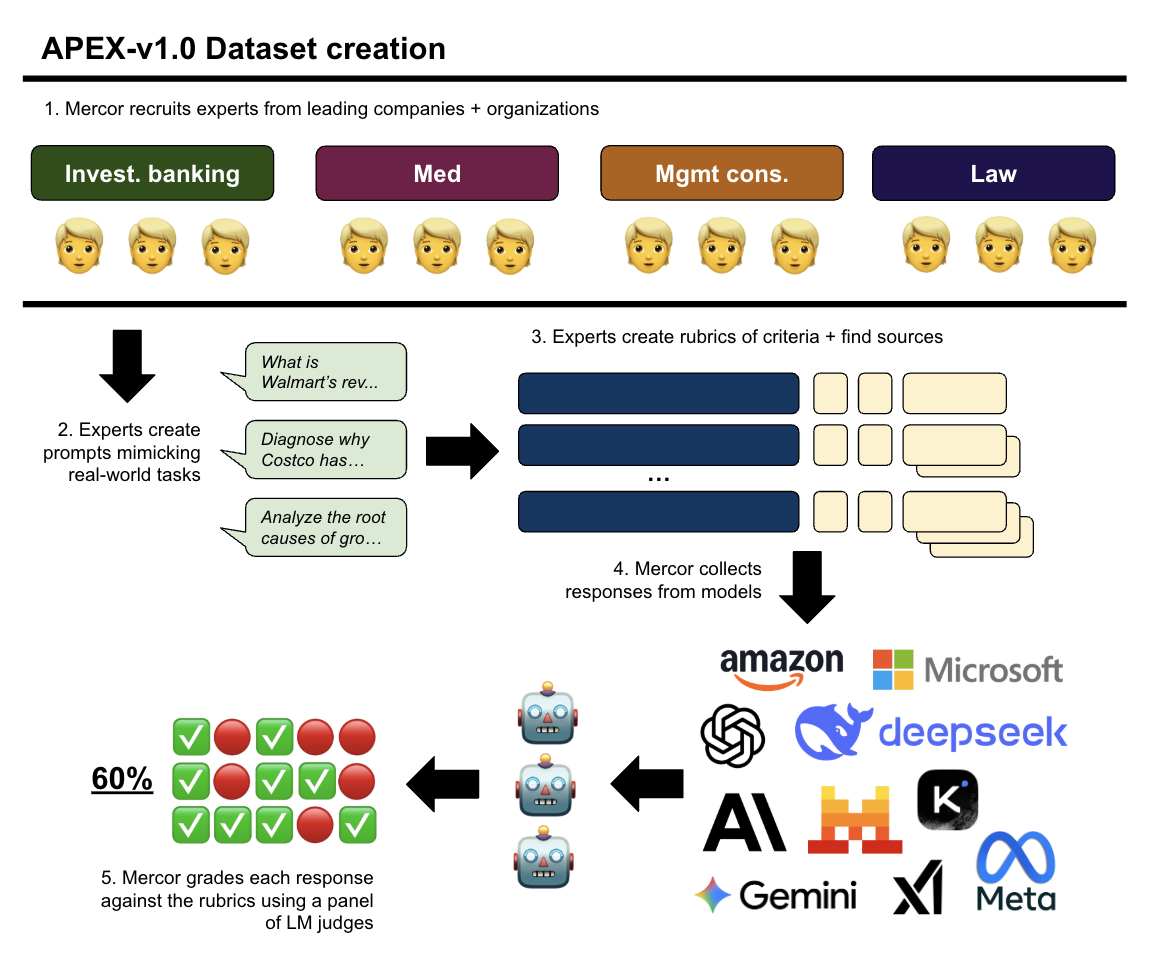
Figure 1: The APEX-v1.0 creation workflow, emphasizing expert involvement and multi-stage quality control.
Dataset Construction and Quality Control
Expert recruitment and vetting are central to APEX's construction. Experts were selected based on years of experience at top-tier institutions and their ability to create high-quality prompts and rubrics. The rubric for each prompt decomposes the notion of "quality" into granular, testable units, analogous to unit tests in software engineering. This approach enables precise, scalable, and objective evaluation of model outputs.
Quality control is multi-layered: prompts and rubrics undergo iterative review, and only those meeting stringent standards are included. The dataset is balanced across domains, with each case requiring substantial reasoning and synthesis, and the mean prompt length and rubric complexity varying by domain to reflect real-world task diversity.

Figure 2: Example of a law rubric, illustrating the granularity and objectivity of the evaluation criteria.
Evaluation Protocol and Model Scoring
APEX-v1.0 evaluates 23 frontier models (13 closed-source, 10 open-source) released in 2024–2025. Each model is tested on all 200 cases, with three independent completions per prompt to account for stochasticity. Responses are scored using a panel of three LM judges (o3, Gemini 2.5 Pro, Sonnet 4), each independently grading every criterion as Pass/Fail. The final score for each response is the percentage of criteria passed, using the median score across runs for robustness.
The LM judge panel demonstrates high internal consistency (≥99.4%), strong inter-judge agreement (81.2% full agreement), and 89% agreement with human expert grades. Biases among judges are mitigated by majority voting, and the panel approach reduces the risk of self-preference or systematic over/under-grading.
GPT 5 (Thinking = High) achieves the highest mean score (64.2%), followed by Grok 4 (61.3%) and Gemini 2.5 Flash (60.4%). The best open-source model, Qwen 3 235B, ranks seventh overall (59.8%). The performance gap between the top and bottom models is substantial: Phi 4 Multimodal scores only 20.7%. The Kruskal-Wallis test confirms that these differences are statistically significant (p<10−5).
Figure 3: Mean scores of all evaluated models on APEX-v1.0, highlighting the performance gap between top closed-source and open-source models.
Domain-Specific Trends
Performance varies by domain: law is the easiest (mean 56.9%), followed by management consulting (52.6%), investment banking (47.6%), and medicine (47.5%). GPT 5 (Thinking = High) leads in all domains, but the absolute scores indicate that even the best models are far from expert-level performance, especially in medicine and investment banking.
Pairwise and Correlation Analysis
Pairwise win rates further differentiate models: GPT 5 (Thinking = High) wins 77.5% of head-to-head comparisons, while Phi 4 Multimodal wins only 4.3%. Correlation analysis reveals that models from the same provider are highly correlated (e.g., o3 and o3 Pro: 0.93), but the best-performing model (GPT 5) is only moderately correlated with others (mean 0.65), indicating some orthogonality in its strengths.
Figure 4: Pairwise win rates across all models, providing a robust comparative ranking.
Figure 5: Pairwise correlation matrix, showing intra-family and inter-family performance similarities.
Response Length and Scoring
There is no substantial relationship between response length and score (R2=0.02), mitigating concerns about "scattergunning" (overly verbose answers passing more criteria). However, qualitative review notes that some high-scoring models (e.g., Qwen 3 235B, DeepSeek R1) tend to produce lengthy, sometimes repetitive outputs.
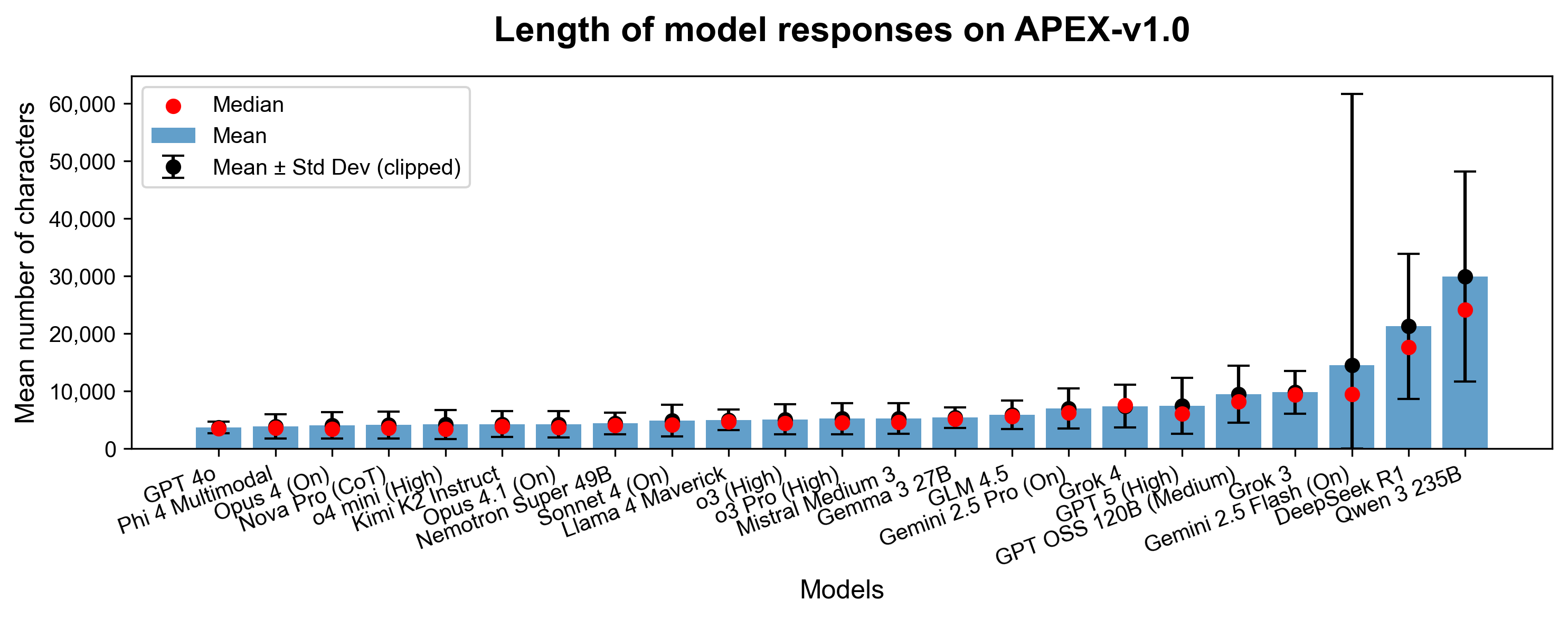
Figure 6: Distribution of response lengths by model, illustrating the diversity in output verbosity.
Open-Source vs. Closed-Source
Closed-source models outperform open-source models by 9.4 percentage points on mean score and 15 percentage points on pairwise win rate. Notably, Qwen 3 235B and DeepSeek R1 are competitive with mid-tier closed-source models, but the overall gap remains significant.
Model Scaling and "Thinking" Settings
More powerful or expensive models within a family do not always outperform their smaller counterparts. For example, Opus 4 underperforms Sonnet 4, and o3 Pro offers only marginal gains over o3. Models with "thinking" enabled perform better on average, but this is confounded by recency and closed-source status.
Limitations
- Measurement Error: Despite rigorous quality control, rubric construction and LM judging introduce potential for error, especially in complex domains like medicine.
- No Negative Criteria: The rubric does not penalize hallucinations or irrelevant content, so high scores do not guarantee factual correctness or conciseness.
- Real-World Value Alignment: APEX scores may not linearly correlate with real-world utility; a model scoring 60% may be functionally inadequate for production use.
- Saturation and Contamination: As models improve, risk of overfitting or contamination increases, though the heldout nature of APEX mitigates this.
Implications and Future Directions
APEX-v1.0 establishes a new standard for evaluating AI models on economically valuable knowledge work. The results demonstrate that, despite rapid progress, even the best models are not yet substitutes for domain experts in high-stakes professional settings. The benchmark's design—granular rubrics, expert-authored prompts, and rigorous quality control—enables fine-grained analysis of model strengths and weaknesses.
Future expansions will broaden domain coverage (e.g., software engineering, teaching, insurance), incorporate tool use and multi-turn workflows, and introduce fine-grained tagging for loss analysis. Integrating cost, latency, and real-world deployment constraints will further enhance the benchmark's relevance.
Conclusion
The AI Productivity Index (APEX) provides a rigorous, expert-driven framework for measuring the economic utility of frontier AI models. The benchmark reveals substantial gaps between current model performance and expert-level outputs in high-value domains. APEX's methodology—objective rubrics, expert curation, and robust LM judging—sets a precedent for future benchmarks targeting real-world impact. Continued development and expansion of APEX will be essential for tracking progress toward economically meaningful AI deployment and for guiding both research and productization in the field.