DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints
Abstract: While agent evaluation has shifted toward long-horizon tasks, most benchmarks still emphasize local, step-level reasoning rather than the global constrained optimization (e.g., time and financial budgets) that demands genuine planning ability. Meanwhile, existing LLM planning benchmarks underrepresent the active information gathering and fine-grained local constraints typical of real-world settings. To address this, we introduce DeepPlanning, a challenging benchmark for practical long-horizon agent planning. It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization. Evaluations on DeepPlanning show that even frontier agentic LLMs struggle with these problems, highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs. Error analysis further points to promising directions for improving agentic LLMs over long planning horizons. We open-source the code and data to support future research.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DeepPlanning, a set of tough, realistic challenges designed to test how well AI assistants (like smart chatbots) can plan long, complicated tasks. Instead of just answering short questions, these tasks make the AI plan multi-day trips and complex shopping lists while following strict rules like time schedules, opening hours, item availability, and total budget.
The big questions the authors asked
The authors wanted to know:
- Can AI assistants plan over many steps and days, not just one or two actions?
- Can they actively find missing information (like a museum’s opening hours) instead of guessing?
- Can they follow small, local rules (like “pick a 3-star hotel” or “choose size M”) while also keeping the whole plan consistent (no time overlaps, correct travel routes, and staying under budget)?
- Which kinds of AI models do better: those that “think step-by-step” internally or those that don’t?
How did they study it?
Building realistic practice worlds
The team built two safe, offline “practice worlds” (called sandboxes) with databases and special tools the AI can use:
- Travel Planning: The AI plans minute-by-minute itineraries across several days, including trains/flights, hotels, attractions, restaurants, travel times, and costs.
- Shopping Planning: The AI builds a shopping cart that meets user needs (brands, sizes, colors, ratings), delivery times, coupons, and budget limits.
These sandboxes are like sealed games: the AI can only use the provided tools (like “search hotel info” or “filter products by size”) to look up facts and make decisions. That keeps the tests fair and repeatable.
Creating challenging tasks step by step
Each task is built in layers to make it realistic and solvable:
- Start with a base idea (for example: travel from City A to City B or buy spring clothing).
- Add personal preferences (like “depart after 7:00 AM” or “rating above 4.7”).
- Add hidden real-world constraints that the AI must discover using tools (like “this attraction is closed on Mondays” or “coupon stacking makes the pricier cart cheaper overall”).
They tune the data so every task has one best solution, which helps with clear scoring.
Checking answers fairly
Instead of asking another AI to judge, they use rule-based checks:
- Travel Planning scores:
- Commonsense Score: Does the plan make sense? No time overlaps, obey opening hours, correct travel distances, reasonable visit durations, correct cost math, and so on.
- Personalized Score: Did it satisfy all the user’s requests?
- Composite Score: The average of the two.
- Case Accuracy: Perfect only if everything is correct.
- Shopping Planning scores:
- Match Score: How many cart items match the ground-truth list?
- Case Accuracy: Perfect only if the entire cart matches exactly.
What did they find?
Here are the main results in simple terms:
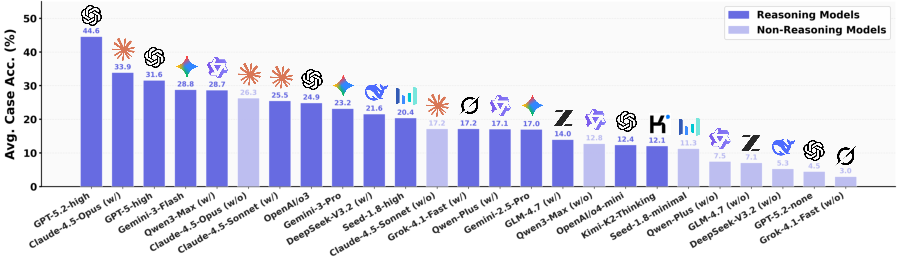
- Even top AIs struggled with full, perfect plans: Many could get parts right but failed to keep the whole trip or cart consistent. For example, the best travel model was fully correct in only about a third of cases.
- “Thinking” helps: Models that do internal step-by-step reasoning generally beat those that don’t. This kind of careful planning reduces mistakes and wasted tool calls.
- More careful checking improves performance (but costs time): AIs that use tools more often (to verify schedules, prices, routes, and availability) perform better. However, that means more steps and higher “cost” to run.
- Different styles have trade-offs: Some models batch many tool calls at once (faster but risk missing details), while others go step-by-step (slower but more thorough). The best scores often came from very thorough checking.
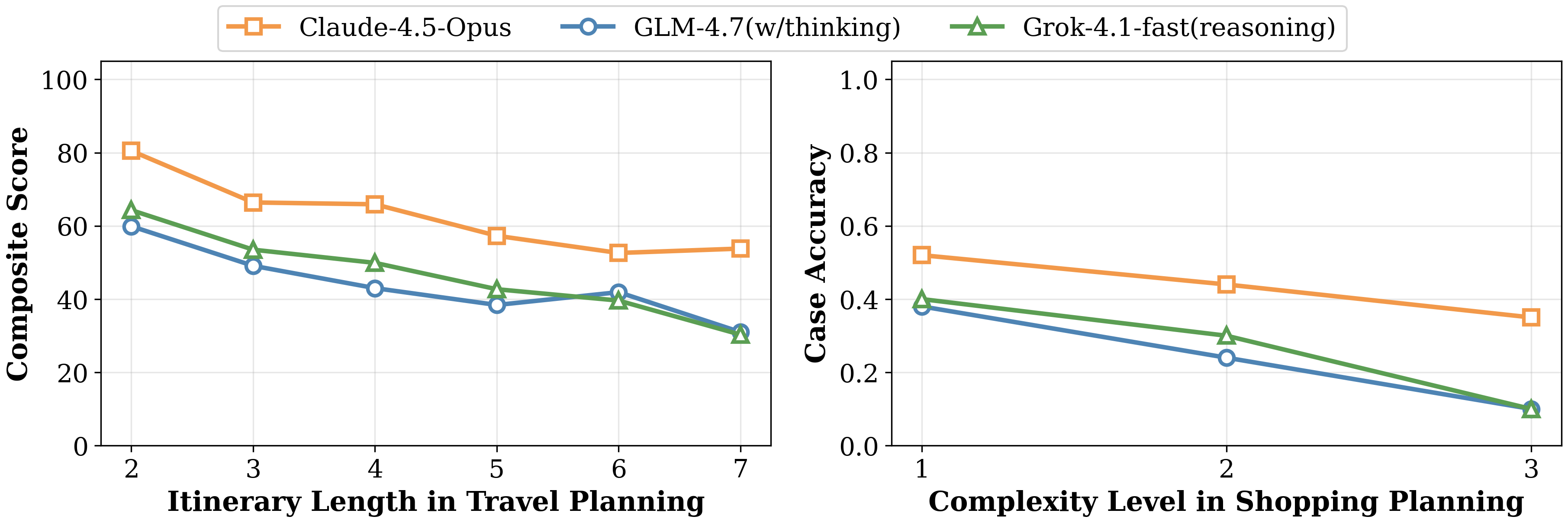
- Harder tasks make AIs stumble more: Longer trips (2 to 7 days) and more complex shopping rules (cross-item budgets and coupon timing) lead to sharper performance drops.
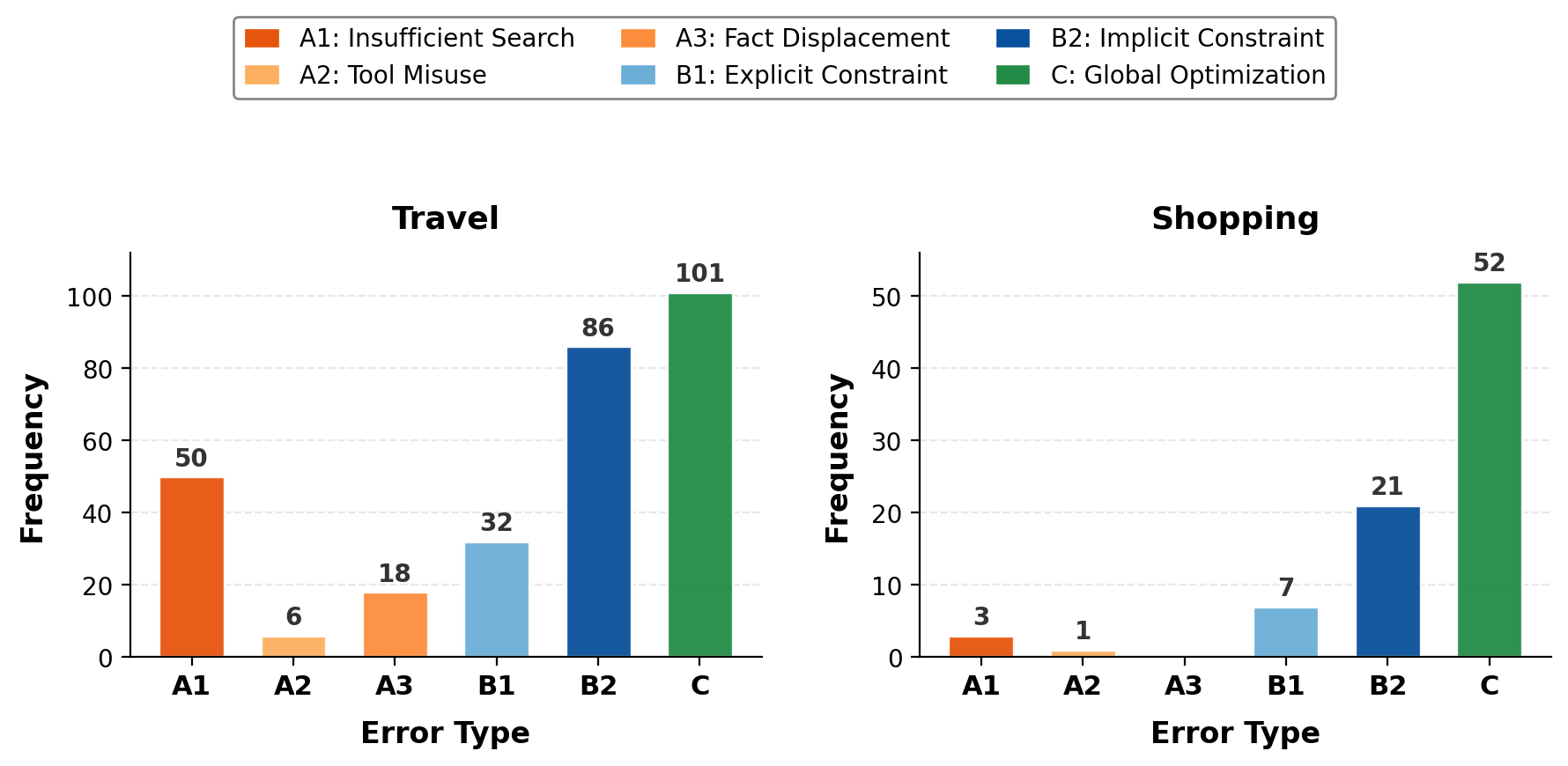
- Common failure patterns:
- Information acquisition: Not looking up something essential, using the wrong tool, or misreporting retrieved facts.
- Local reasoning: Ignoring a specific user rule or missing an implicit limit (like no seats left on a flight).
- Global optimization: Putting correct pieces together badly—like overlapping times, breaking the budget, or choosing a non-optimal cart after coupons.
Why does this matter?
If we want AI assistants to be truly helpful in real life—planning trips, buying things, organizing events—they must do more than follow simple instructions. They need to:
- Actively gather the right information,
- Carefully follow detailed rules at each step,
- Keep the entire plan consistent over time, location, and money,
- Backtrack and fix mistakes when something doesn’t fit.
DeepPlanning gives researchers a realistic, measurable way to test and improve these skills. By open-sourcing the code and data, the paper helps the community build better planning AIs that are reliable over many steps and days.
In short
DeepPlanning is a tough test for AI planning in travel and shopping. It shows that even advanced AIs still struggle with long, rule-heavy tasks that need careful information gathering and global consistency. The benchmark offers a clear path for improving AI planning: stronger explicit reasoning, smarter tool use (including parallel and thorough checks), and better ways to keep whole plans consistent and correct.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a valuable benchmark for long-horizon planning, but several aspects remain underexplored or uncertain. The following concrete gaps can guide future research:
- Domain coverage and regional bias
- Benchmark spans only travel and shopping; it is unclear how findings transfer to other high-stakes, constrained domains (e.g., healthcare scheduling, logistics, finance, education timetabling).
- Travel data emphasizes Chinese cities; generalization to other geographies, mobility patterns, regulatory norms, and cultural preferences is not assessed.
- Cross-domain transfer (training/tuning on one domain, testing on another) is not evaluated.
- Data realism and task generation
- Shopping data are synthetic with engineered coupon/stock rules; robustness to real e-commerce ecosystems (messy attributes, dynamic stock, inconsistent seller metadata) is unknown.
- Tasks are reverse-generated to enforce a unique optimal solution; in reality, many near-optimal plans exist—effects of relaxing uniqueness and evaluating ε-optimality/top-k solutions are untested.
- Distribution shift from synthesized queries to real user requests (colloquialisms, ambiguity, contradictory preferences) is acknowledged but not quantified or mitigated.
- No tasks include noisy/incomplete/contradictory database entries, which are pervasive in the wild.
- Environment dynamics and grounding
- Offline, deterministic sandboxes remove web/noise/grounding issues; how models perform with live, partially observed, non-deterministic environments (changing prices, delays, closures) is unknown.
- Tool failures, API latency, rate limits, and stale/incorrect responses are not simulated; resilience to such conditions is unmeasured.
- No evaluation of rapid environment drift (e.g., last-minute flight cancellation) and the agent’s ability to replan under changing states.
- Tooling assumptions and robustness
- Agents interact with a fixed, well-documented tool schema; robustness to evolving schemas, missing tools, argument schema changes, and ambiguous tool descriptions is not tested.
- Impact of tool noise (e.g., low-precision coordinates, mismatched place names, duplicate entities) and argument-level errors is not systematically studied.
- Parallel tool use is inferred from interaction patterns, but the sandbox appears sequential; benefits and pitfalls of true concurrency (latency-aware scheduling, batching, speculative execution) remain open.
- Evaluation methodology and metrics
- Travel evaluation depends on LLM-based parsing (Qwen-Plus-2507); parser error rates, bias across models, and sensitivity analyses are not reported.
- Case Accuracy is binary and may penalize near-feasible plans; metrics for optimality gap, constraint violation severity, and repairability (plan-fix success rate) are absent.
- Uniqueness-based gold carts/plans can penalize semantically equivalent alternatives; matching criteria beyond exact identity (e.g., equivalence classes, goal satisfaction) are not explored.
- Cost is proxied by tool calls and turns; token-level cost, wall-clock latency, and compute/energy usage are not measured.
- Variance across runs and statistical significance tests are not provided; per-task difficulty calibration and score reliability are unclear.
- Cross-lingual performance (ZH vs EN) is averaged; differences in parsing, tool call behavior, and constraints satisfaction by language are not analyzed.
- Interaction design and user modeling
- Tasks are single-turn; agents cannot ask clarifying questions or negotiate trade-offs with users. How multi-turn interaction affects plan quality and efficiency is untested.
- User models are shallow (static constraints, occasional user profile queries); no modeling of heterogeneous group preferences, accessibility needs, or evolving preferences over time.
- No evaluation of agents’ ability to elicit missing information (e.g., sizes, budget flexibility) via targeted questions vs. over-assuming defaults.
- Planning competence diagnostics
- Backtracking, global consistency checks, and replanning are discussed qualitatively but not directly measured; no metrics for error detection latency, rollback depth, or plan-repair efficiency.
- Failure mode taxonomy is based on 140 cases from one model; multi-model, multi-annotator studies with agreement statistics and larger samples are needed.
- Lack of ablations on prompt design, memory mechanisms, and tool-calling policies that could clarify which components most affect long-horizon success.
- Scalability and complexity
- Travel tasks max out at 7 days; scalability to longer itineraries (e.g., 10–14 days), multi-city tours, and complex multi-leg constraints remains unknown.
- Shopping tasks do not explore large candidate sets (e.g., hundreds of items) or budget-sized baskets typical of enterprise procurement; performance under larger combinatorial spaces is unreported.
- Tool-call cap (400) may bind for some models; the rate of cap hits and impact on failure rates are not disclosed.
- Generalization and robustness
- Robustness to tool schema changes, new tools, and unseen categories (zero-shot tool generalization) is not examined.
- Transfer to new constraints (e.g., carbon footprint limits, accessibility, dietary restrictions) and new objective functions (multi-objective trade-offs) is untested.
- Sensitivity to adversarial or contradictory constraints and to data poisoning in the sandbox is unexplored.
- Comparative baselines and integrations
- No comparison to hybrid architectures that integrate formal planners/optimizers (e.g., CP-SAT, MILP, PDDL planners) as verifiers or co-solvers.
- Absence of ablations on reasoning settings (e.g., scratchpad length, planning horizon, tree-of-thought breadth) to disentangle “thinking” from other confounds across vendors.
- Effects of memory (episodic/working) and tool-use curricula or fine-tuning on long-horizon reliability are not explored.
- Fairness, safety, and ethics
- Plans are not evaluated for safety (e.g., unsafe transit times/areas, over-tight schedules), fairness (group trade-offs), or accessibility (mobility constraints).
- Privacy risks in using user profiles and handling PII in planning workflows are not discussed.
- Reproducibility and overfitting risk
- Public release of all tasks may encourage overfitting; no hidden test set or evaluation server to track generalization over time.
- Provider model versions evolve; reproducibility of results under model drift is not addressed, nor are mechanisms for version pinning and regression tests.
- Open design questions
- How to define and measure “global optimality” in settings with multiple acceptable solutions and latent user utilities?
- What is the right mix of internal reasoning vs. external tool calls to optimize accuracy/latency/cost under realistic constraints?
- Which curricula or training signals best teach agents to detect inconsistencies early, backtrack effectively, and verify constraints at scale?
- How to standardize parser-free, fully structured outputs without sacrificing model-agnostic evaluation?
Practical Applications
Immediate Applications
Below are applications that can be deployed now or with modest integration effort, derived directly from the benchmark, its tool schemas, evaluation methodology, and empirical findings.
- Industry — Travel/OTAs
- Use case: Pre-deployment QA for travel-planning agents (multi-day itineraries with minute-level scheduling, budget summaries).
- Tools/products/workflows: Integrate the DeepPlanning travel sandbox and rule-based checker as a “Plan Linter” microservice that validates time feasibility, opening hours, transport continuity, and budget before an itinerary is shown to users.
- Assumptions/dependencies: Mapping from internal tool APIs to DeepPlanning tool schemas; parsing pipeline from natural-language plans to structured format; data freshness alignment (offline benchmark vs live inventory).
- Industry — E-commerce
- Use case: Coupon- and budget-aware shopping cart optimization for agentic shopping assistants.
- Tools/products/workflows: Adopt the shopping sandbox and validators to test “Cart Optimizer” agents that balance brand/size preferences, shipping times, stock constraints, and coupon stacking, and to measure exact cart-match rates before production rollout.
- Assumptions/dependencies: Alignment of coupon logic and stock levels between benchmark and platform; mapping to internal product catalogs; guardrails for malformed tool arguments.
- Industry — LLM Platforms and Agent Orchestration
- Use case: Model selection and inference-mode tuning based on planning performance.
- Tools/products/workflows: Benchmark-in-the-loop selection that compares “reasoning” vs “non-reasoning” modes; auto-tuning of tool-call budgets; orchestration strategies (sequential vs parallel bundling) guided by cost–performance curves observed in DeepPlanning.
- Assumptions/dependencies: Access to model variants with different “thinking” settings; telemetry to measure tool invocations and turns; cost constraints for higher tool-call counts.
- Industry — MLOps/Quality Engineering
- Use case: Regression testing suites for long-horizon agent releases.
- Tools/products/workflows: Continuous evaluation pipelines using the rule-based commonsense and personalized scores; failure clustering by the provided error taxonomy (information acquisition, local constraints, global optimization).
- Assumptions/dependencies: CI integration; reproducible sandboxes; consistency of parsing models (e.g., Qwen-Plus-2507 or equivalent) for structured evaluation.
- Academia — Benchmarking and Methods Research
- Use case: Controlled, reproducible experiments on planning reliability, tool-use strategies, and the effect of internal reasoning.
- Tools/products/workflows: Use DeepPlanning’s layered task generation and verifiable scoring to study explicit reasoning traces, backtracking, and parallel tool use; create curricula that incrementally increase task complexity (more days; more cross-item constraints).
- Assumptions/dependencies: Availability of the open-source code/data; transparent reporting of evaluation metrics; acceptance of sandboxes as suitable proxies for live environments.
- Policy — Procurement and Vendor Evaluation
- Use case: Comparative audits of agentic planning capabilities for government or enterprise procurement.
- Tools/products/workflows: Adopt standardized, verifiable benchmarks (commonsense score, case accuracy) to set minimum performance thresholds for tools deployed in travel advisory or e-commerce assistance.
- Assumptions/dependencies: Agreement on domain-relevant scenarios and metrics; disclosure of model inference settings; recognized audit processes.
- Daily Life — End-User Applications
- Use case: “Verify my plan” button in travel apps and “Optimize my cart” button in shopping apps.
- Tools/products/workflows: Client-side or server-side validation services that detect time overlaps, infeasible transfers, budget overruns, or suboptimal coupon combinations and propose automatic fixes.
- Assumptions/dependencies: User consent for data use; reliable mapping from free-text plans to structured validators; localized opening hours and inventory data.
Long-Term Applications
Below are applications that require further research, scaling, or product development (e.g., broader domain coverage, live data integration, multi-turn interaction, or stronger planning architectures).
- Cross-Domain Planning Benchmarks and Planners
- Sectors: Healthcare (appointment and procedure scheduling), Education (course timetabling), Logistics (multi-stop routing), Finance (multi-month budget planning), Energy (maintenance and shift scheduling).
- Use case: Extend the layered task-generation pipeline and rule-based evaluation to new domains with holistic constraints (time, cost, resource coupling).
- Tools/products/workflows: Domain-specific sandboxes, tool schemas (e.g., hospital availability APIs, warehouse inventory, grid schedules), and verifiable constraint checkers analogous to DeepPlanning.
- Assumptions/dependencies: High-quality domain data and APIs; subject-matter validation to ensure realistic constraints; privacy and compliance (HIPAA, FERPA, SOC2).
- Robust Global Consistency and Backtracking in Agent Architectures
- Sector: Software/AI platforms
- Use case: Agents that maintain global plan invariants (no overlaps, feasible dependencies) and systematically backtrack when local decisions break global constraints.
- Tools/products/workflows: Plan-as-code representations; constraint-solver integration (MILP/CP-SAT); global consistency checkers; structured backtracking policies; plan repair strategies.
- Assumptions/dependencies: Hybrid neuro-symbolic architectures; engineering to bridge LLM tool calls and solvers; latency and cost management for iterative verification loops.
- Parallel Tool-Orchestration and Efficiency Optimization
- Sector: Agent orchestration/MLOps
- Use case: Intelligent bundling of tool calls (parallel where safe; sequential where verification is essential) to optimize the effectiveness–efficiency frontier.
- Tools/products/workflows: Orchestration schedulers; DAG-based tool pipelines; adaptive policies that switch between parallel and sequential modes based on uncertainty and task complexity.
- Assumptions/dependencies: Tool-call concurrency support; robust error handling; cost-aware policies; monitoring to avoid race conditions and stale reads.
- Training and Curriculum Learning for Planning Reliability
- Sector: AI research/education
- Use case: Systematic training regimes that introduce implicit constraints, combinatorial coupon rules, and multi-day horizon effects to improve planning robustness.
- Tools/products/workflows: Synthetic data generation using DeepPlanning’s reverse-generation approach; staged curricula; reinforcement learning with verifiable rewards from rule-based checkers.
- Assumptions/dependencies: Access to compute for RL and self-play; careful control to prevent overfitting to synthetic distributions; mechanisms to generalize to real-world tasks.
- Multi-Turn, Personalized Agent Interactions
- Sector: Consumer software
- Use case: Agents that proactively acquire missing user attributes (e.g., clothing sizes, dietary restrictions, mobility constraints) and iteratively adjust plans.
- Tools/products/workflows: Dialogue policies for information gathering; user-profile management; memory systems; consent- and privacy-preserving personalization.
- Assumptions/dependencies: Policy-compliant data storage; preference elicitation UX; language and cultural localization; live environment availability checks.
- Standards, Certification, and Consumer Protection
- Sector: Policy/regulation
- Use case: Sector-specific certification for planning agents (minimum case-accuracy thresholds; transparent reporting of reasoning mode and tool-call limits).
- Tools/products/workflows: Benchmark-based disclosure templates; independent test labs; standardized audit trails for agent tool calls and plan changes.
- Assumptions/dependencies: Regulatory buy-in; harmonization across markets; procedures to update tests as environments and coupons/policies change.
- Enterprise “Planning Reliability” SDKs
- Sector: Software
- Use case: Developer kits that ship with constraint validators, error taxonomies, plan parsers, and instrumentation to measure plan fragility.
- Tools/products/workflows: Reusable libraries for commonsense checks (time, budget, feasibility), JSON plan schemas, telemetry dashboards for tool use vs success, and automated failure categorization.
- Assumptions/dependencies: Vendor-neutral interfaces; compatibility with diverse LLMs; maintenance of domain-specific rules and data connectors.
Noted Assumptions and Dependencies Across Applications
- Data realism and freshness: Benchmark sandboxes use curated data; live deployments require up-to-date inventories, opening hours, and transport schedules.
- Domain coverage: Current benchmark focuses on travel and shopping; cross-domain generalization needs new sandboxes and verified tool APIs.
- Interaction scope: Tasks are single-turn in the benchmark; real-world agents often need multi-turn clarifications and iterative planning.
- Parsing and verification: Structured plan parsing (e.g., via Qwen-Plus-2507 or equivalents) must be robust; rule-based checkers must reflect local policies and constraints.
- Cost/performance: High planning reliability currently correlates with more tool calls; practical deployments need budgeted orchestration and caching strategies.
- Privacy/compliance: Personalized planning depends on secure handling of user attributes and adherence to regional regulations.
Glossary
- Agentic LLMs: LLMs explicitly designed to act as agents, coordinating tools and multi-step decisions to accomplish complex goals. "Evaluations on {DeepPlanning} show that even frontier agentic LLMs struggle with these problems, highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs."
- Agentic tool use: An LLM capability to autonomously select and invoke external tools to gather information or execute actions as part of a plan. "Agentic tool use has emerged as a fundamental capability for LLMs, extending their utility far beyond parametric knowledge."
- Backtracking: Systematically revising or undoing steps in a plan to recover from errors or constraint violations. "However, these benchmarks largely emphasize complex instruction following rather than deliberative, multi-step planning, and thus fail to rigorously assess LLMs' ability to verify plans and backtrack under global resource constraints."
- Case Accuracy: A strict, case-level metric indicating whether a solution perfectly satisfies all required checks for a task. "Case Accuracy. This metric is a stricter, case-level measure of performance."
- Combinatorial optimization: Selecting the best combination of items or decisions under constraints to minimize or maximize an objective. "Challenges lies in the combinatorial optimization across user needs, product attributes, coupon applicability, and budget."
- Commonsense Score: A rule-based metric evaluating the real-world feasibility of a plan across dimensions like time, cost, and route consistency. "Commonsense Score. We evaluate agents' ability to produce a real-world feasible plan along eight dimensions spanning 21 checkpoints, including route consistency, sandbox compliance, itinerary structure, time feasibility, business hours compliance, duration rationality, cost calculation accuracy, and activity diversity."
- Composite Score: A holistic metric computed as the average of constraint-level scores to summarize overall plan quality. "Composite Score. This metric provides a holistic evaluation of agent performance on Travel Planning."
- Environment Constraint Injection: A task-generation technique that adds implicit, environment-driven constraints discoverable only via tool use. "Environment Constraint Injection."
- Function-calling agents: LLM agents configured to call external tools/APIs via structured function calls during execution. "All models are instantiated as function-calling agents, with tools specified in the OpenAI tool schema format, and a maximum of 400 tool calls allowed per task."
- Global consistency checking: Verifying that a multi-step plan remains logically coherent across time, budget, and dependencies. "agents still lack robust global consistency checking and backtracking for long-horizon, tightly coupled tasks."
- Global constrained optimization: Optimizing an overall solution subject to holistic constraints (e.g., total time or budget) that span the entire task. "Practical scenarios often impose global constrained optimization requirements, where constraints such as total time budgets, cumulative financial costs, and cross-subtask dependencies restrict the entire solution space rather than any single step."
- Grounding limitations: Performance limits due to challenges in aligning an agent’s actions or understanding with real-world data and environments. "where performance is fundamentally constrained by grounding limitations."
- Layered Task Generation: A staged, solution-centric process for constructing tasks by progressively adding constraints. "Figure \ref{fig:framework} highlights the central stage, Layered Task Generation, to aid understanding."
- Local Constrained Reasoning: Reasoning within sub-tasks to satisfy explicit and implicit constraints, such as filters or availability checks. "It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization."
- Long-horizon: Refers to tasks or planning that span many steps or extended time, requiring sustained reasoning and verification. "Recently, evaluation of agents has shifted from short-horizon, tool-centric benchmarks~\citep{li-etal-2023-api,qin2024toolllm,patil2025the} toward long-horizon, user-centric tasks~\citep{qian2025userbench,andrews2025scaling,he2025vitabench}."
- Offline sandbox: A controlled, self-contained environment (backed by fixed databases and tools) for reproducible agent evaluation. "It supports reproducible, easy-to-verify evaluation via offline sandboxes and rule-based checkers."
- OpenAI tool schema: A standardized format for specifying tools/functions that LLM agents can call. "with tools specified in the OpenAI tool schema format"
- Parallel tool use: Invoking multiple tools efficiently (often in a single turn) to accelerate information gathering or plan verification. "highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs."
- Parametric knowledge: Information encoded in a model’s parameters (learned during training) rather than gathered externally at inference. "Agentic tool use has emerged as a fundamental capability for LLMs, extending their utility far beyond parametric knowledge."
- Personalized Constraint Injection: Adding user-specific, task-level requirements during generation to tailor the planning problem. "Personalized Constraint Injection."
- Personalized Score: A binary metric indicating whether all user-specific constraints are satisfied by the final plan. "Personalized Score. We use this metric to evaluate agents' ability to satisfy user-specific requirements stated in the query."
- Proactive Information Acquisition: Actively seeking and retrieving necessary state information from tools and the environment to inform planning. "It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization."
- Reverse-generation process: Creating tasks by starting from a solution and adding constraints to ensure uniqueness and verifiability. "We adopt a solution-centric, reverse-generation process to construct complex agent planning tasks by progressively adding constraints:"
- Rule-based scoring: Automated, code-driven evaluation using deterministic checks rather than LLM judgments. "and then apply the following metrics for rule-based scoring:"
- Semantic search: Retrieving items based on meaning-level similarity to a natural language query rather than exact keyword matching. "Handles open-ended queries by performing a semantic search on product information to retrieve an initial set of relevant items."
- Temporal planning tasks: Planning problems that explicitly involve timing, durations, and scheduling over time. "While efforts exist to benchmark LLMs on classical~\citep{valmeekam2023planbench,stechly2025on} and temporal planning tasks~\citep{zhang-etal-2024-timearena,ding-etal-2025-tcp}, these settings are simplified and abstract away the complex information acquisition process inherent to reality."
- Tool Misuse: An error pattern where the agent selects an inappropriate tool or supplies malformed arguments. "A2: Tool Misuse involves selecting inappropriate tools or providing malformed arguments (e.g., coordinate precision mismatches)."
Collections
Sign up for free to add this paper to one or more collections.