Power Aware Dynamic Reallocation For Inference
Abstract: Disaggregation has emerged as a powerful strategy for optimizing LLM inference by separating compute-intensive prefill and memory-bound decode phases across specialized GPUs. This separation improves utilization and throughput under fixed hardware capacity. However, as model and cluster scales grow, power, rather than compute, has become the dominant limiter of overall performance and cost efficiency. In this paper, we propose RAPID, a power-aware disaggregated inference framework that jointly manages GPU roles and power budgets to sustain goodput within strict power caps. RAPID utilizes static and dynamic power reallocation in addition to GPU reallocation to improve performance under fixed power bounds. RAPID improves overall performance and application consistency beyond what is achievable in current disaggregation solutions, resulting in up to a 2x improvement in SLO attainment at peak load when compared to a static assignment without an increase in complexity or cost.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI servers run LLMs faster and more efficiently when electricity is limited. The authors introduce a system called RAPID that smartly splits LLM work across different GPUs and shifts power between them so more requests finish on time without using extra hardware or breaking a strict power cap.
Key Objectives and Questions
The paper asks:
- How can we get more useful AI work done when the main limit isn’t hardware, but electricity?
- Can splitting LLM tasks into two parts (prefill and decode) and managing their power differently help more requests meet their speed targets?
- Can we adjust GPU roles and power on the fly to handle changing traffic and keep performance steady?
How the System Works (Methods)
What are LLM “prefill” and “decode”?
Think of a busy kitchen:
- Prefill is like “prepping” the meal: it’s heavy compute work (reading the whole prompt and setting up internal state).
- Decode is like “plating” one bite at a time: it’s memory-heavy and generates tokens step by step.
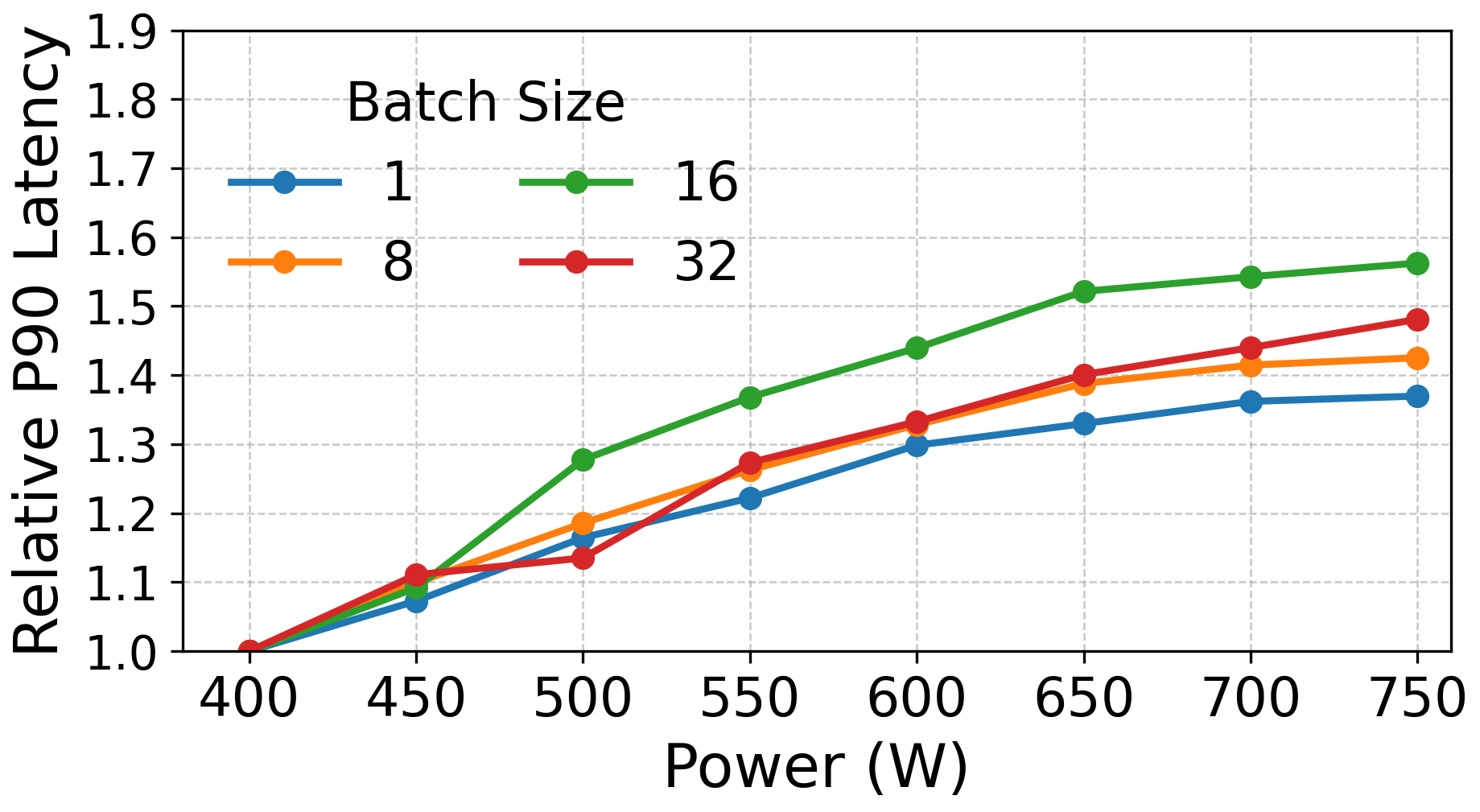
These two phases need different kinds of effort—prefill benefits a lot from more compute and power; decode needs fast memory and doesn’t speed up much past a certain power level.
What is “disaggregation”?
Disaggregation means running prefill and decode on separate groups of GPUs. This avoids them getting in each other’s way and lets you tune each group for what it does best.
What is a “power cap” and why does it matter?
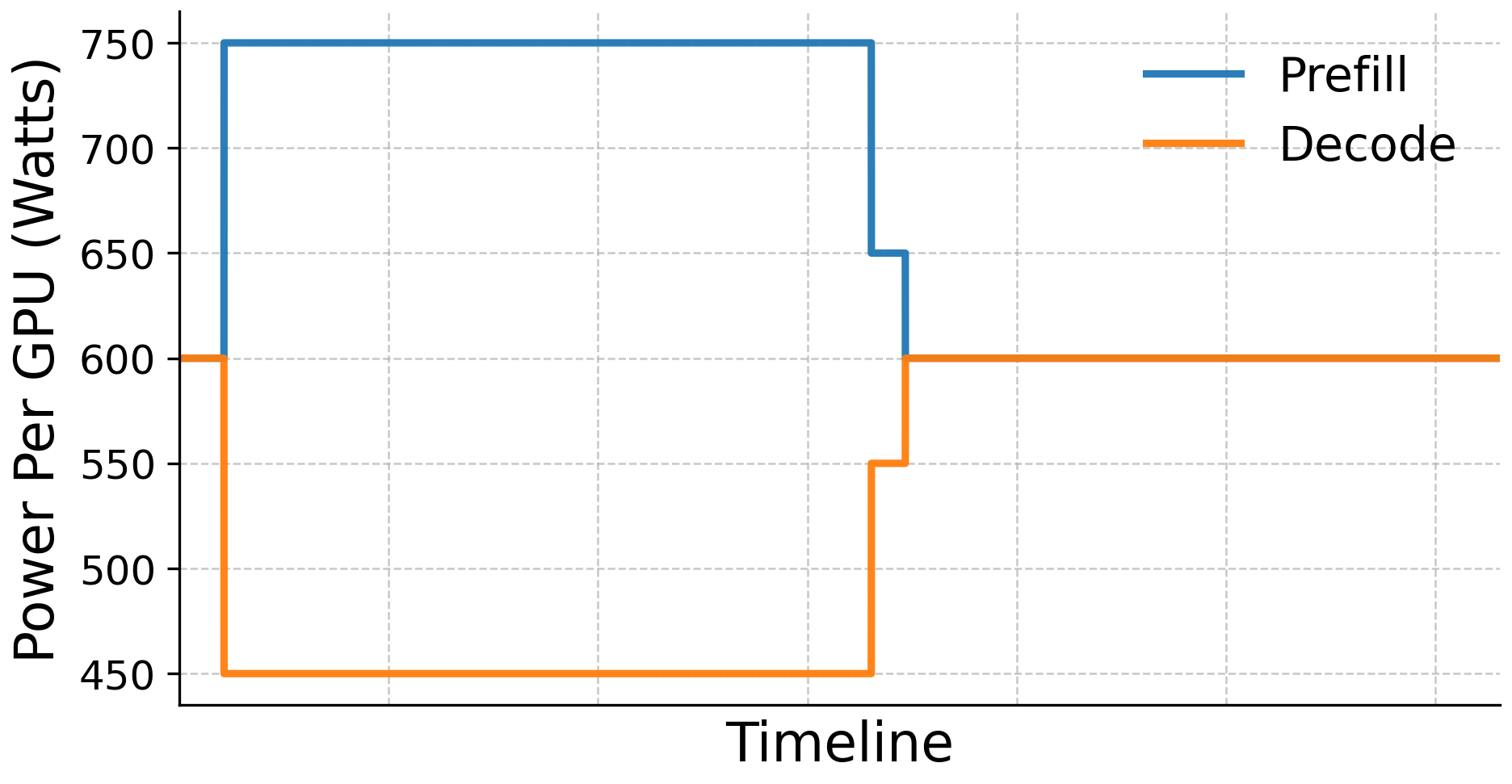
Data centers often have a strict limit on available electricity. A power cap is like a maximum “electricity budget.” RAPID respects this budget but distributes power unevenly:
- More power to prefill GPUs (they speed up a lot when powered higher),
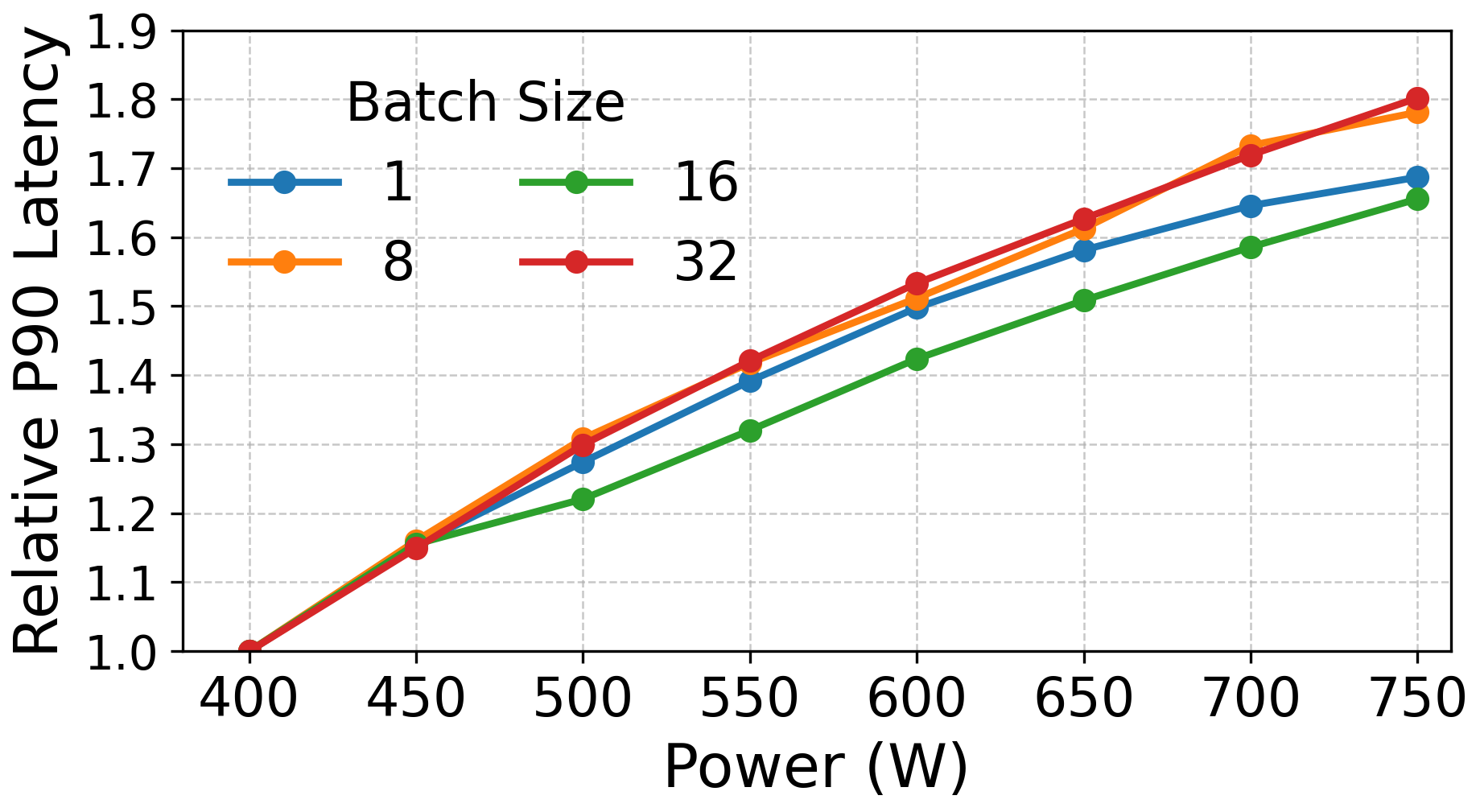
- Less power to decode GPUs (they don’t gain much beyond about 600W in the tested setup).
What are SLOs, TTFT, TPOT, and goodput?
- SLOs (Service Level Objectives) are promises about speed, like “first token should appear within 1 second.”
- TTFT (Time To First Token) is how long it takes to start responding.
- TPOT (Time Per Output Token) is the average time to produce each token after the first.
- Goodput counts how many requests meet both TTFT and TPOT targets—it’s “useful throughput,” not just raw speed.
What does RAPID do?
RAPID has two modes:
- Static mode: Decide up-front how many GPUs do prefill vs decode, and set their power levels (for example, 4 prefill GPUs at 750W, 4 decode GPUs at 450W).
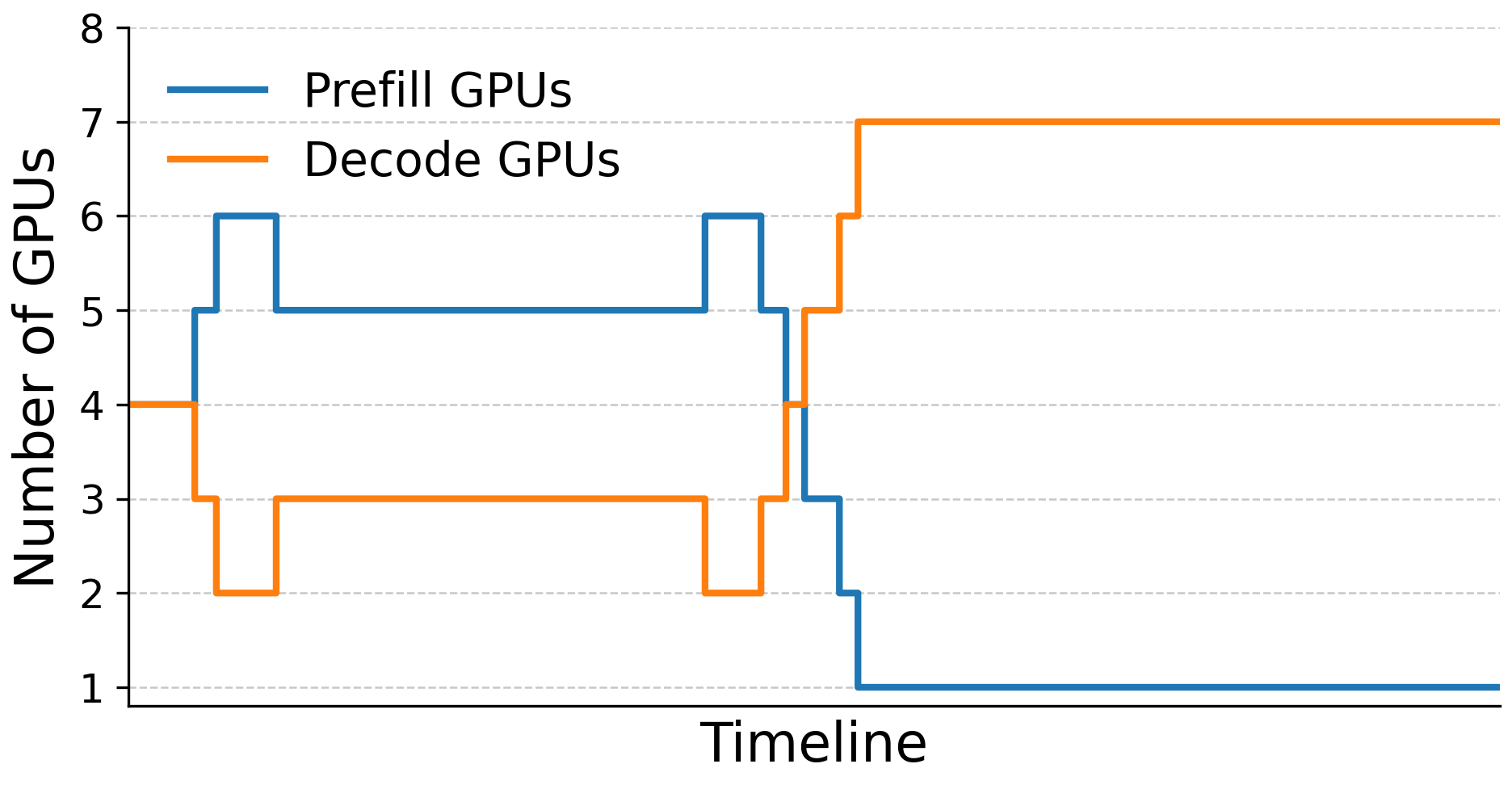
- Dynamic mode: Continuously watch the system and:
- Move power between prefill and decode GPUs,
- Reassign GPUs from one role to the other,
- Do both at once,
- to keep TTFT and TPOT within targets while staying under the node’s total power cap.
In simple terms: RAPID is like a smart manager who moves chefs and plugs between stations depending on the rush, so orders arrive on time without exceeding the kitchen’s energy limit.
Implementation details (simplified)
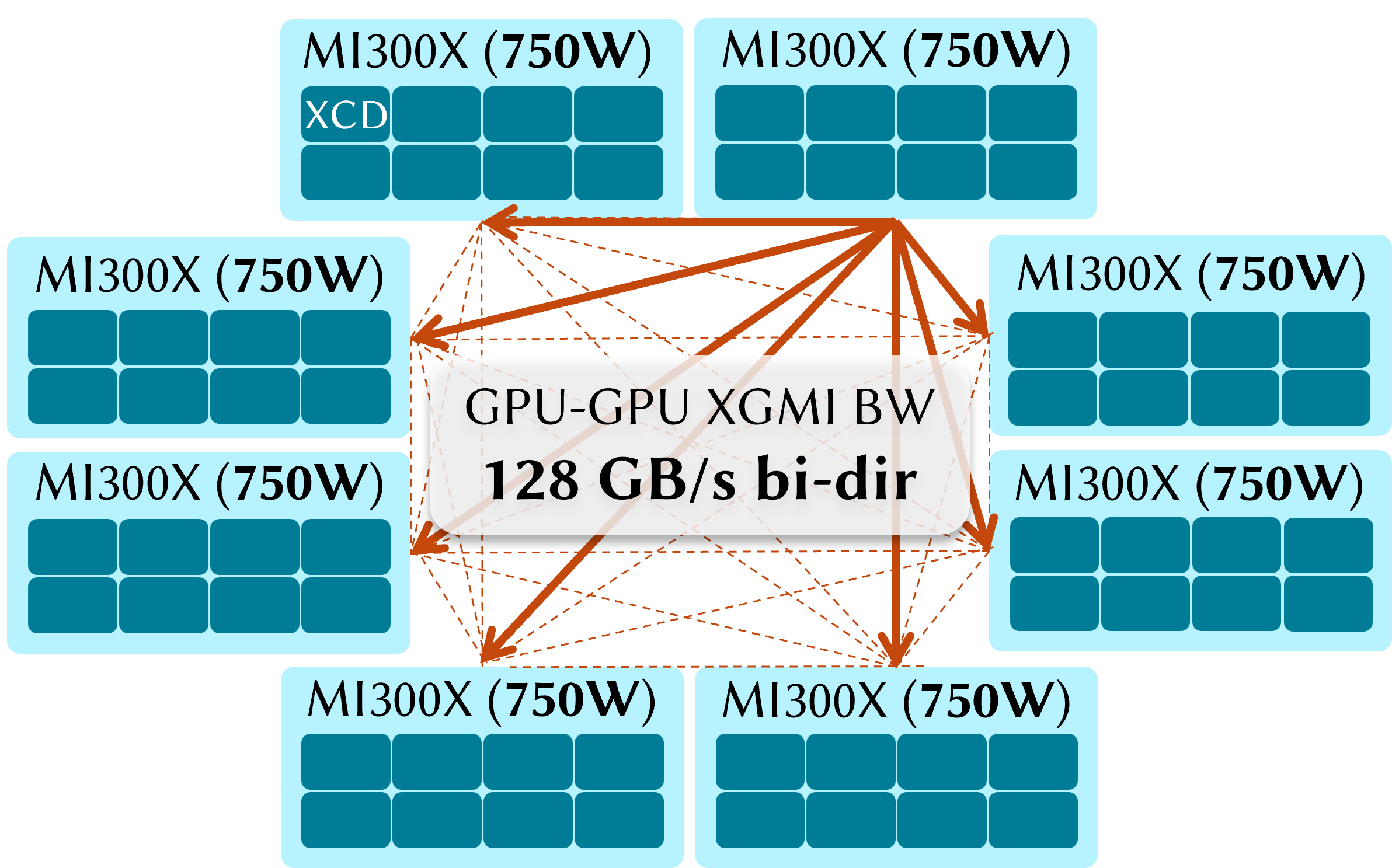
- Tested on an 8-GPU AMD MI300X node running the Llama-3.1-8B model.
- Built on the vLLM serving framework, extended to support multi-GPU disaggregation.
- Uses fast GPU-to-GPU data transfer so the decode stage can quickly pull what prefill produced.
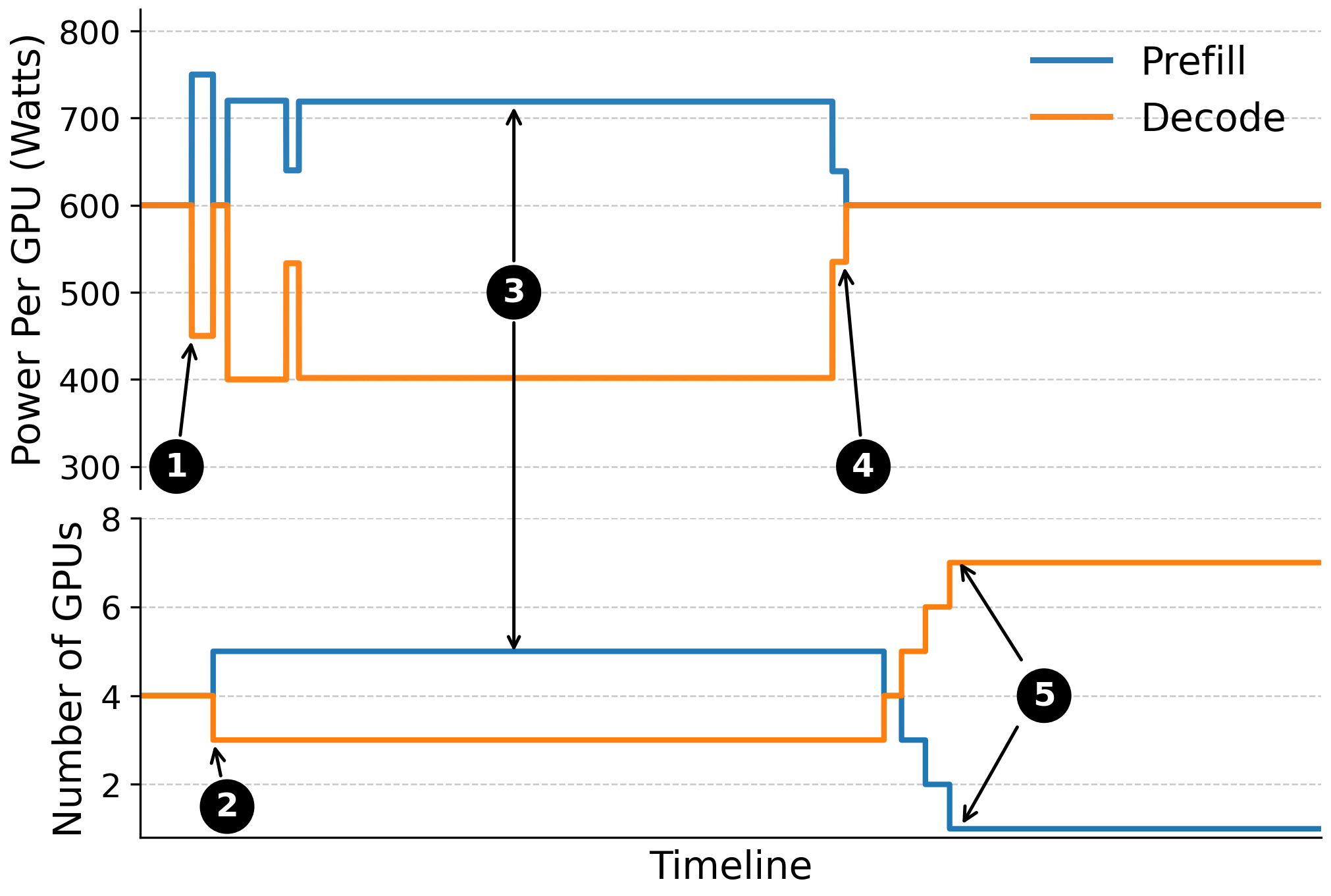
- Adjusts power using AMD’s tools; shifting power is faster than moving GPUs, so RAPID does power shifts first and GPU role changes second.
Main Findings and Why They Matter
- Non-uniform power helps a lot.
- Giving more power to prefill GPUs (e.g., 750W) and less to decode GPUs (e.g., 450W) can match the speed of a higher-power setup but within a tighter power budget.
- This boosts “compute per watt” (more useful work for the same electricity).
- In tests, RAPID improved goodput and QPS per watt compared to “everyone gets the same power” setups.
- Prefill benefits more from extra power than decode.
- Prefill speeds up significantly as power increases.
- Decode gains flatten around ~600W in the tested system, so adding power above that doesn’t help much.
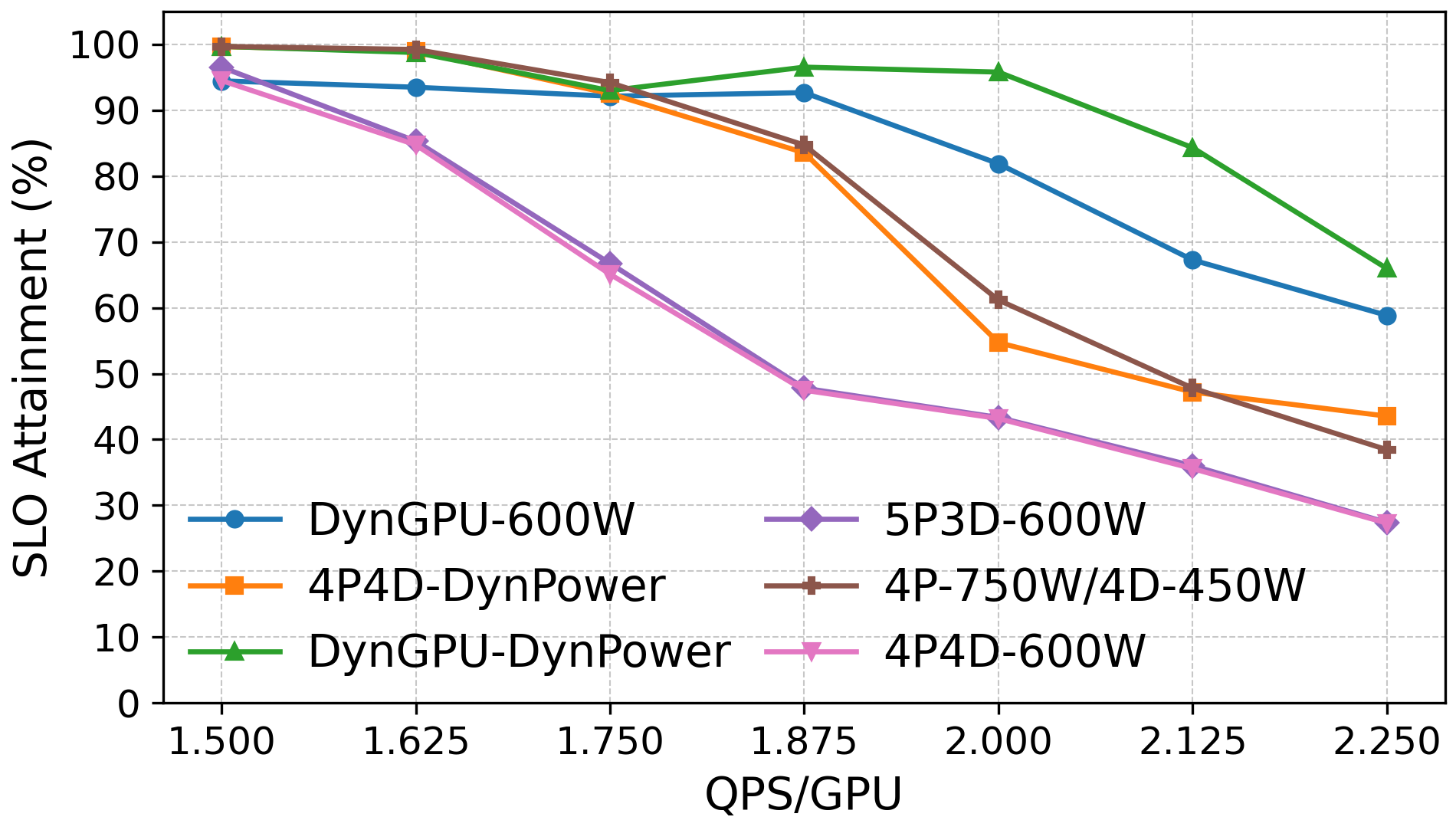
- Dynamic reallocation beats fixed setups when traffic changes.
- In a mixed workload (some long prompts needing strong prefill, then many shorter outputs stressing decode), RAPID’s dynamic mode:
- First shifts power to prefill,
- Then reassigns GPUs to prefill,
- Later, shifts power back to decode and moves more GPUs to decode,
- This kept more requests within SLOs than any static configuration.
- In a mixed workload (some long prompts needing strong prefill, then many shorter outputs stressing decode), RAPID’s dynamic mode:
- Better consistency under strict power caps.
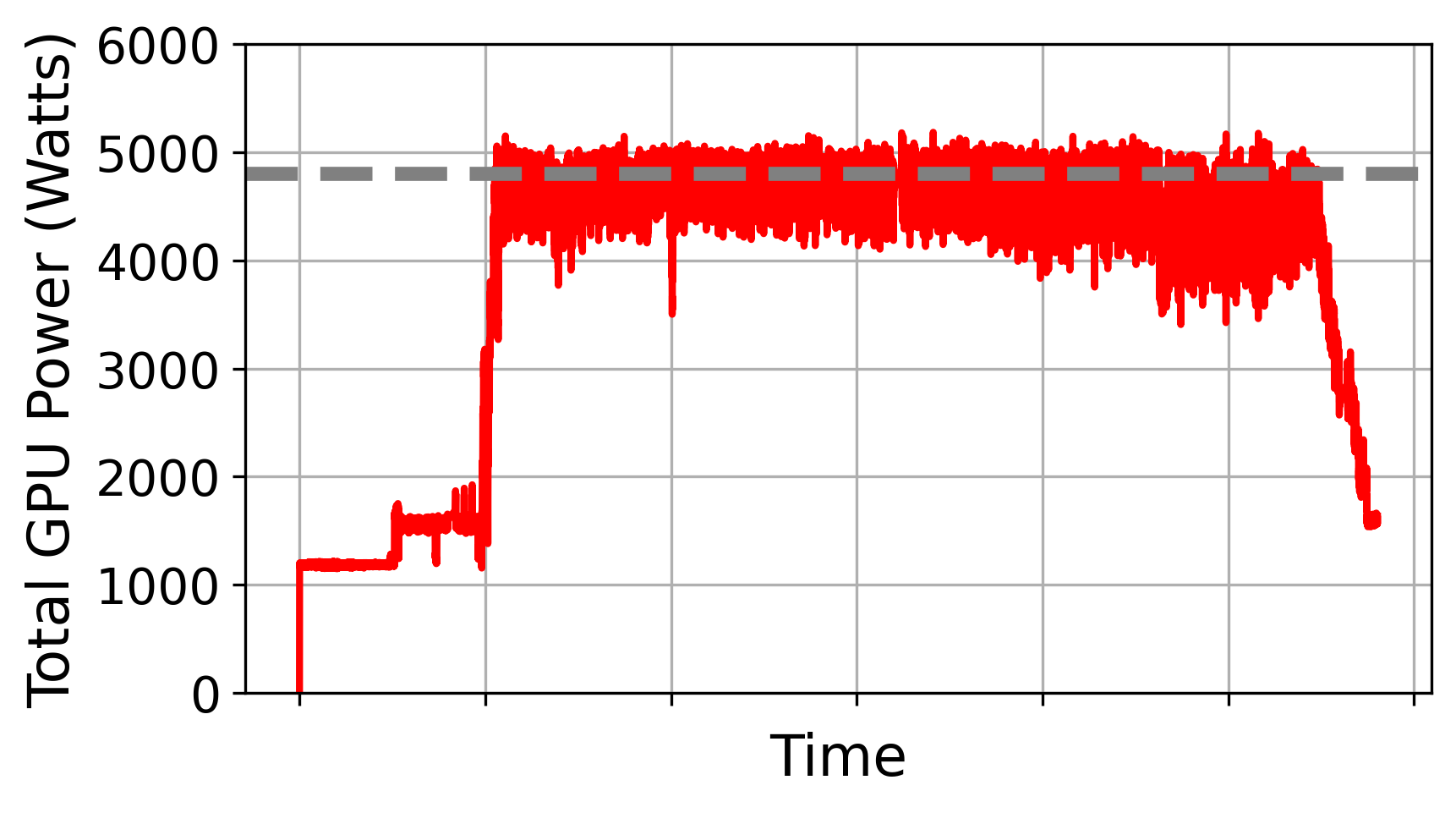
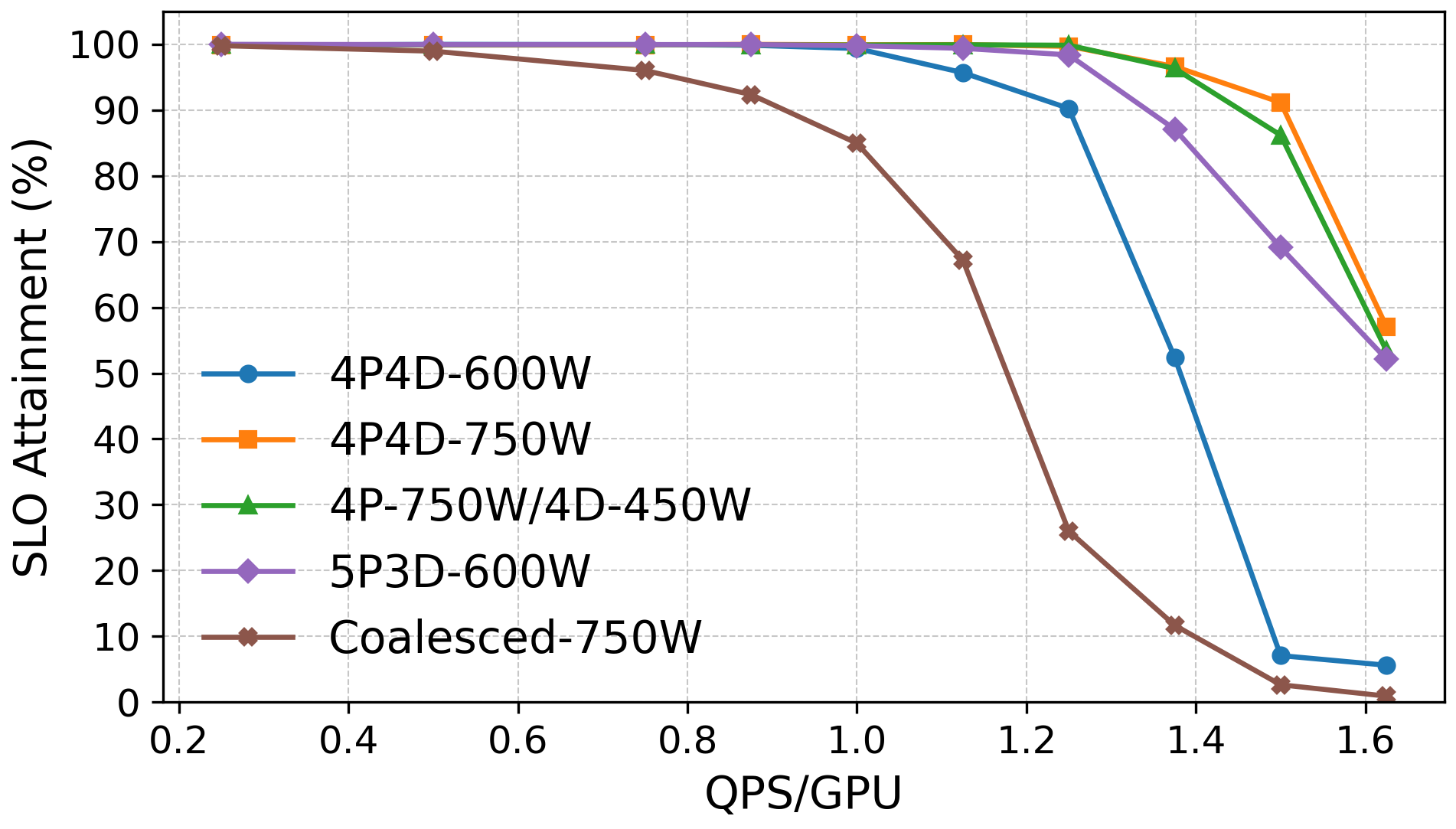
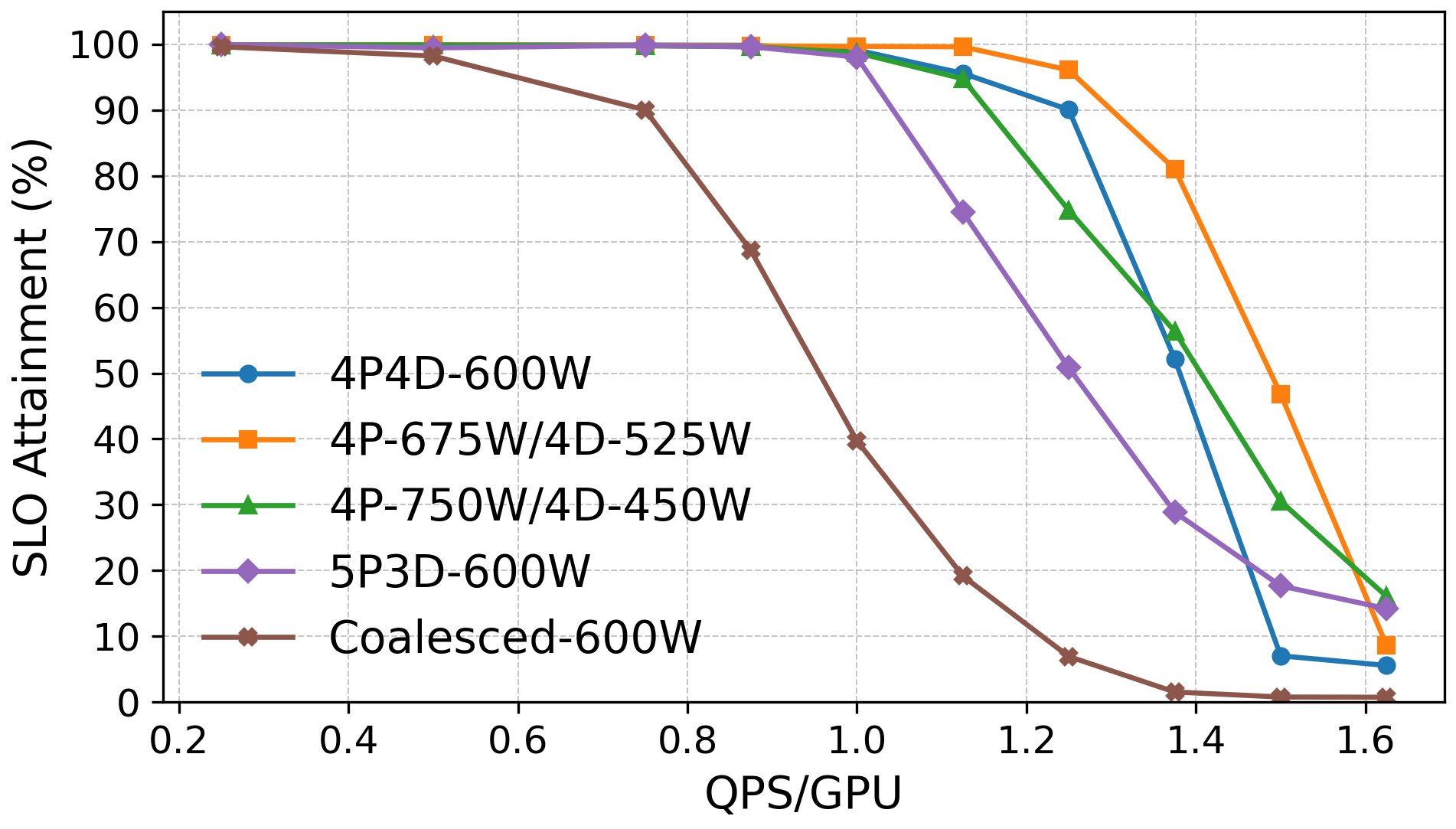
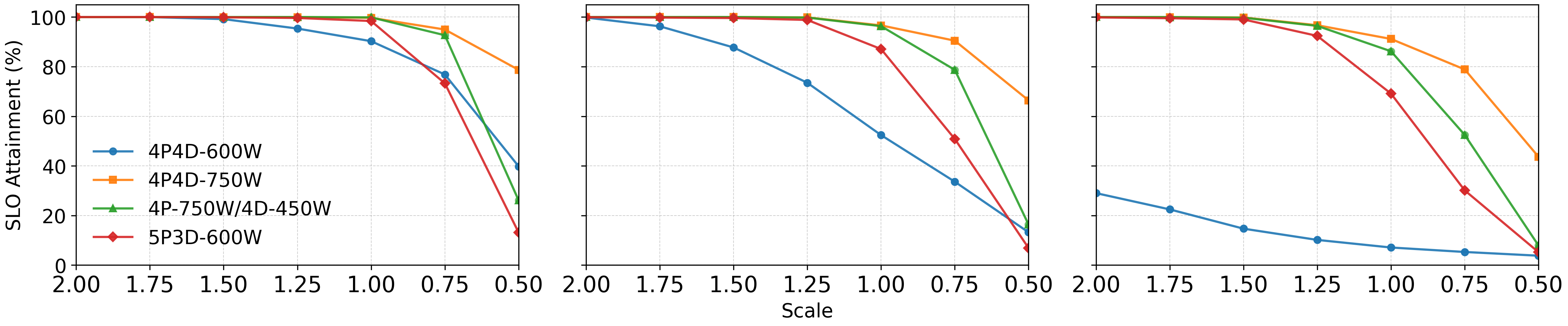
- With a 4800W cap on total GPU power, RAPID maintained higher SLO attainment, sometimes up to about 2x improvement at peak load compared to static assignment, without adding hardware cost or complexity.
Overall, RAPID helps when you cannot just “plug in more GPUs” because the power grid or building limits you. It squeezes more performance out of the same electricity by matching power to each phase’s needs and adjusting in real time.
Implications and Impact
- For data centers with tight electricity limits (a growing reality), RAPID can deliver more reliable AI service without breaking power budgets.
- It improves energy efficiency and reduces costs by increasing useful work per watt.
- It’s especially helpful for companies running smaller, tunable models on limited on-prem hardware.
- The ideas can scale from one node to larger racks, and can complement other power management strategies.
- In the bigger picture, smarter power-aware serving can make AI more sustainable and easier to deploy where power is scarce.
In short: RAPID makes AI servers smarter about electricity. By splitting tasks and dynamically shifting power and GPU roles, it keeps response times steady and handles busy periods better—all while staying within a strict energy budget.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of gaps, uncertainties, and unexplored aspects that future work could address to strengthen, generalize, and operationalize RAPID.
- Generality beyond single-GPU models: The evaluation is limited to TP=1 (Llama‑3.1‑8B on a single GPU per request). It remains unclear how RAPID behaves with multi-GPU models (tensor/pipeline parallelism), where KV-cache partitioning, inter-layer dependencies, and cross-GPU synchronization may alter both power sensitivity and reallocation overheads.
- Rack-scale and cross-node disaggregation: The implementation and measurements are intra-node (XGMI). There is no evidence on how KV-cache transfer latency, fabric contention, and power orchestration behave at rack scale (e.g., Helios with 72 GPUs), especially under mixed-traffic bursts and multi-tenant interference.
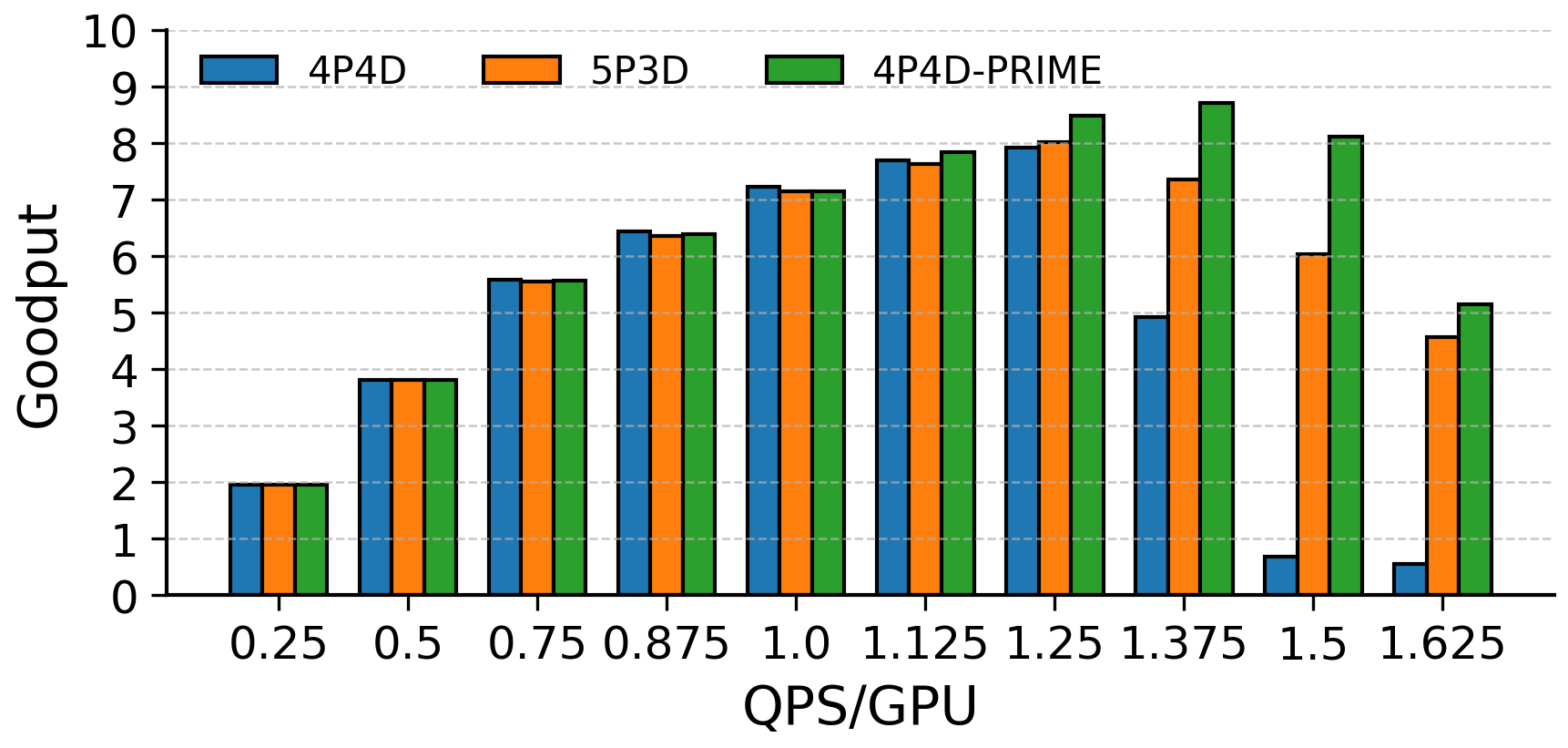
- Baseline comparability: Results are compared mainly to coalesced vLLM and simple disaggregation variants (4P4D, 5P3D). A direct, apples-to-apples comparison with public implementations (e.g., DistServe, WindServe, Splitwise) under identical workloads and power caps is missing.
- Algorithmic stability and parameter sensitivity: The dynamic scheduler uses heuristic thresholds (e.g., THRESHOLD, MIN_TIME, COOLDOWN) without sensitivity analysis, stability proofs, or systematic tuning methodology. How robust is RAPID to oscillations, measurement noise, or workload non-stationarity?
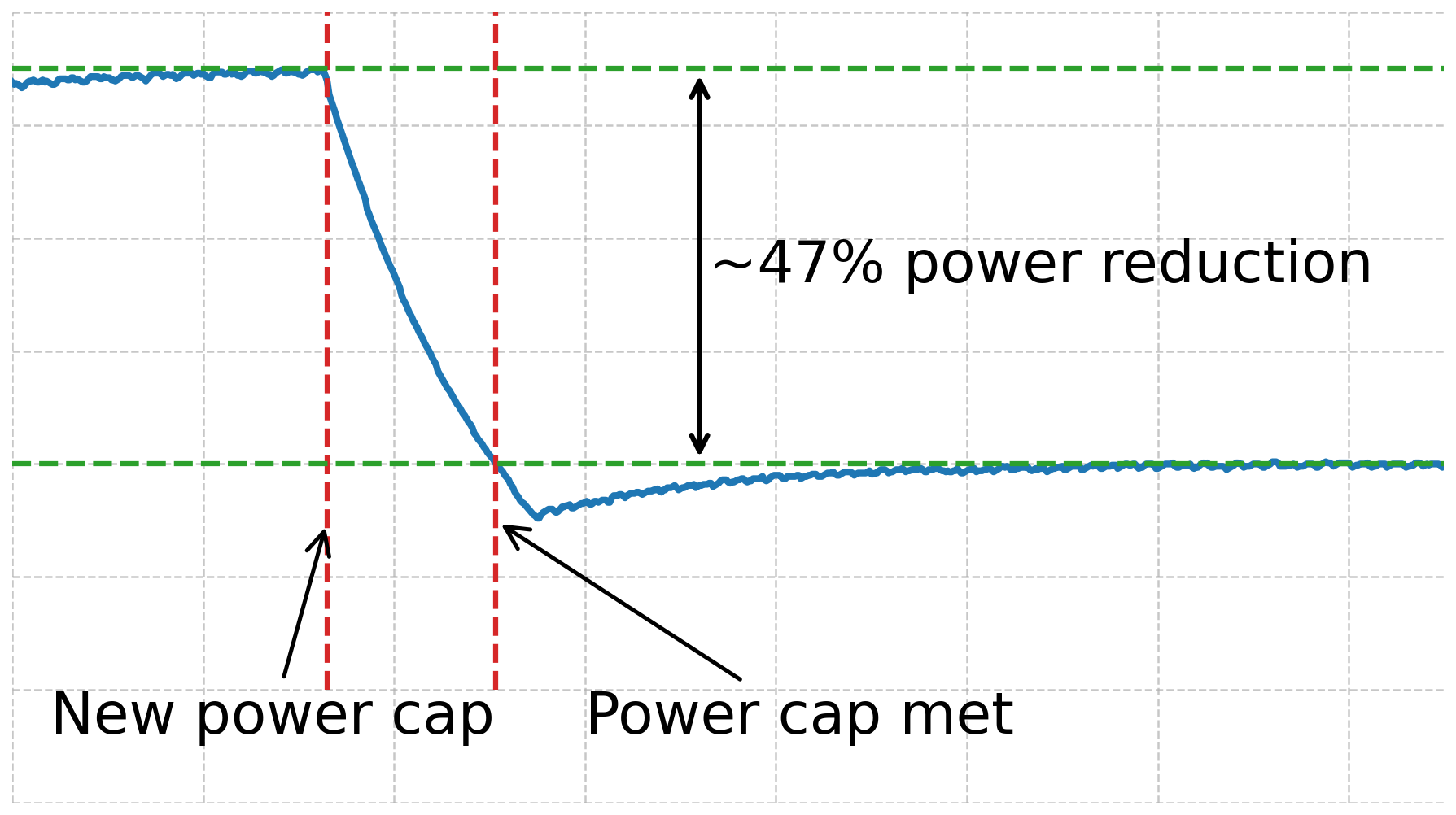
- Control-loop design under cap transition latency: Power-cap changes require “hundreds of milliseconds” to take effect, but the controller’s timing, hysteresis, and safety margins are not formally derived. What control strategies (e.g., PID, model predictive control) best account for cap-settling times across different step sizes and thermal states?
- Predictive vs. reactive scheduling: The paper favors purely observation-driven control. It leaves open whether token-level predictors, SLO-aware forecasting, or queueing-theoretic models can improve responsiveness and reduce unneeded moves in volatile traffic.
- Power telemetry and actuation portability: RAPID relies on AMD SMI for per-GPU power capping. It is unclear how portable the approach is to other vendors (e.g., NVIDIA) and whether differences in firmware behavior, API granularity, and cap effectiveness change outcomes.
- Decode-phase power scaling model: The claim that decode performance saturates above ~600 W is empirical and MI300X-specific. A general microarchitectural model explaining the decode phase’s memory-bound scaling plateau—and its variability across architectures and workloads—is absent.
- KV-cache transfer overhead characterization: Bulk KV transfers are claimed to be “not significant” intra-node; there is no quantified breakdown across context lengths, batch sizes, and concurrent flows, nor an evaluation of alternative strategies (streaming vs bulk, compression, prioritization).
- Safety under strict power budgets: The implementation ensures “reduce source power before raising sink power,” but lacks formal guarantees against transient budget exceedance under concurrent operations, delayed firmware response, or measurement jitter.
- Thermal dynamics and aging: Frequent power shifting may induce thermal cycling. The impact on hardware reliability, performance drift, and SLO attainment over long runs and varied ambient conditions is unexplored.
- System power accounting: QPS/W uses average provisioned GPU power and assumes GPUs are ~60% of node power. There is no validation against wall-plug measurements, nor accounting for dynamic CPU/NIC power, cooling variability, and power delivery losses under reallocation.
- Overheads of GPU role migration: GPU role changes require draining work and take 2–5 s. The throughput and tail-latency impacts of such migrations under bursty traffic are not quantified; policies to minimize disruption (e.g., staged migration, shadow workers) remain unexplored.
- Multi-tenant fairness and SLO tiers: The scheduler tracks aggregate TTFT/TPOT and queue lengths, but does not model per-tenant priorities, tiered SLOs, admission control, or fairness, which are essential in production serving.
- Admission control and overload management: The system reacts by moving power/GPUs; it does not explore throttling, request shaping, or proactive batching changes as complementary levers when SLOs are unattainable under tight power caps.
- Workload representativeness: LongBench is truncated to 8K input tokens and Sonnet uses Poisson arrivals. Real-world arrival processes (heavy-tailed inter-arrivals, diurnal patterns), longer contexts (32–128K), and diverse output length distributions are not evaluated.
- Dynamic batching interactions: vLLM batching decisions under power caps and stage-specific queues may affect TTFT/TPOT. How do batch size, padding policies, and chunked prefill interact with power-aware disaggregation?
- Parameter auto-tuning: The paper empirically identifies configurations (e.g., 4P‑750W/4D‑450W), but does not provide an automated method to discover optimal splits and power budgets per SLO target and workload class.
- Integration with power oversubscription: RAPID is positioned as complementary to oversubscription but provides no experimental evidence or coordination policies for combining node-level RAPID with rack-level oversubscription controllers.
- Failure handling and resilience: There is no discussion of error paths (GPU resets, KV-transfer failures), degraded-mode operation, or failover strategies under strict power limits.
- Impact on numerical accuracy/determinism: Frequency/power changes can alter timing and potentially interact with non-deterministic kernels. Any effect on output consistency or quality is not studied.
- Heterogeneous hardware pools: RAPID creates heterogeneity via power capping on identical GPUs. It does not examine mixed GPU pools (e.g., MI300X + older GPUs) or the scheduling implications of hardware heterogeneity across phases.
- Resource coupling beyond power: Memory bandwidth caps, SM clock domains, and interconnect contention are not directly controlled. How should RAPID coordinate multi-dimensional resource controls (clocks, memory freq, interconnect QoS) alongside power?
- KV-cache ring buffer sizing and backpressure: The ring buffer size (32) and its impact on throughput, memory footprint, and head-of-line blocking under large contexts and bursts are not analyzed or tuned.
- Metrics breadth: Goodput (SLO attainment) is the primary metric; richer breakdowns (P95/P99 TTFT/TPOT, per-stage utilization, queueing delays, energy per token) would help diagnose bottlenecks and generalize findings.
- Security and isolation: Direct GPU-GPU IPC and shared ring buffers raise questions about isolation in multi-tenant settings; access control and isolation mechanisms are not discussed.
- Cost modeling: While Compute/W is emphasized, the paper does not convert gains into TCO or $/token metrics, leaving economic implications under different power tariffs and cap regimes unexplored.
- Scheduling granularity: RAPID reallocates at sub-second intervals (power) and 2–5 s (GPUs). The optimal granularity, its dependence on workload volatility, and the trade-off between responsiveness and stability are unquantified.
- SLO detection methodology: The dynamic controller references TTFT/TPOT “metrics” but does not specify if it uses P90, P95, or per-request signals. The implications of using tail vs. mean metrics for control decisions merit evaluation.
- Generalization across models: Only Llama‑3.1‑8B is tested. Whether conclusions hold across architectures (e.g., Mixtral, Qwen), quantization levels, and decoder sizes is unknown.
- Coordination with batching and token-generation policies: The interplay between power-aware phase allocation and strategies like speculative decoding, chunked prefill variants, or attention optimizations (e.g., paged attention) is not explored.
Glossary
- amd-smi: AMD's System Management Interface command-line tool used to monitor and control GPU settings including power caps. Example: "Effectiveness of power cap initiated by amd-smi command."
- Backpressure: Accumulation of work when upstream processing outruns downstream capacity, increasing delays. Example: "creating backpressure and increasing queuing delay."
- Chunked prefill: Technique that splits prompt processing into chunks to improve throughput or memory usage. Example: "using chunked prefill"
- Compute/GigaWatts: A macro-scale efficiency metric expressing compute delivered per gigawatt of power. Example: "or Compute/GigaWatts"
- Compute/W: Compute-per-watt; an efficiency metric relating performance to power consumption. Example: "deliver the best Compute/W."
- Decode: The memory-bound, token-by-token generation phase of LLM inference. Example: "Prefill is more compute-intensive and requires higher power than the decode phase which is memory-intensive."
- Disaggregation: Separating prefill and decode phases across distinct hardware pools to reduce interference and optimize utilization. Example: "Disaggregation has emerged as a powerful strategy for optimizing LLM inference by separating compute-intensive prefill and memory-bound decode phases across specialized GPUs."
- Dynamic power shifting: Reallocating power budgets between GPUs at runtime to meet performance or power constraints. Example: "RAPID supports not only heterogeneous power allocation for GPUs within a node, but also dynamic power shifting between GPUs on the node."
- GPU heterogeneity: Non-uniform GPU capabilities created via differing power/frequency caps to fit workload needs. Example: "GPU heterogeneity can be created through explicit control of power and frequency limits across GPUs within a node."
- Goodput: Throughput of requests that meet specified SLOs, emphasizing latency targets over raw throughput. Example: "We evaluate performance using goodput and SLO attainment (described in Section~\ref{sec:exp-setup}), which measure the number of requests completed within latency targets"
- Head-of-line blocking: Long-running operations delaying subsequent tasks in a queue, increasing tail latency. Example: "to avoid head-of-line blocking and improve throughput under bursty workloads"
- Heterogeneous power allocation: Uneven distribution of power caps across GPUs tailored to their roles or phases. Example: "RAPID supports not only heterogeneous power allocation for GPUs within a node"
- HIP IPC: AMD ROCm interprocess communication enabling direct GPU-to-GPU memory sharing. Example: "using HIP IPC and XGMI"
- Hysteresis: Control strategy that delays reactive changes to avoid oscillation under noisy signals. Example: "This mechanism acts as a form of implicit hysteresis"
- KV-cache: Cached key/value tensors from the attention mechanism, reused during decode to avoid recomputation. Example: "transfer of the KV-cache."
- Power capping: Enforcing maximum power limits per GPU to fit within a system or facility power budget. Example: "Power capping each GPU within a node enables the provisioning of more systems within a fixed data center power budget."
- Power delivery network (PDN): Hardware circuitry that supplies and regulates power to a GPU card. Example: "maximum rating, which is determined by the power delivery network and thermal limits."
- Power oversubscription: Provisioning more devices than guaranteed power by relying on non-coincident peaks and throttling when necessary. Example: "Power oversubscription takes advantage of the difference between actual and provisioned power to add more devices to a fixed power budget"
- Prefill: The compute-intensive phase that processes the prompt and builds the KV-cache before decode. Example: "Prefill is more compute-intensive and requires higher power than the decode phase which is memory-intensive."
- QPS (Queries per second): Measure of request arrival rate or load per GPU or system. Example: "as a function of queries per second (QPS) per GPU"
- QPS/Watt: Requests-per-second per watt; a performance-per-power metric. Example: "compute capability per provisioned power using QPS/Watt as a metric of goodness"
- Queuing delay: Time a request spends waiting in a queue prior to execution. Example: "Queuing delay remains mostly negligible"
- Rack-scale: System design and management at the rack level, coordinating many GPUs via a high-bandwidth interconnect. Example: "either at the node level as the paper currently analyzes, or at the rack scale"
- Ring buffer: Circular buffer structure used for efficient, lock-minimized producer–consumer data transfer. Example: "We implement a persistent ring buffer shared across GPUs for KV and hidden state transfer."
- SLO (Service Level Objective): Formal performance targets (e.g., latency) guaranteed by a service. Example: "LLM services have internal metrics that describe service level objectives (SLOs)"
- SLO attainment: Percentage of requests satisfying both TTFT and TPOT SLOs, used to assess service quality. Example: "We evaluate performance using goodput and SLO attainment"
- Tail latency: High-percentile latency (e.g., P90/P99) that characterizes worst-case response times. Example: "reduce tail latency in phase-disaggregated serving"
- Tensor parallelism (TP): Model-parallel technique that splits tensor computations across GPUs. Example: "with tensor parallelism of 1 (TP=1)."
- Thermal limits: Temperature-based constraints that cap a device’s sustained power and performance. Example: "maximum rating, which is determined by the power delivery network and thermal limits."
- TPOT (Time per output token): Average time to generate each token during the decode phase. Example: "time-per-output-token (TPOT)"
- TTFT (Time to first token): Time from request arrival to the generation of the first output token. Example: "time-to-first-token (TTFT)"
- vLLM: High-performance LLM serving framework used to implement and evaluate RAPID. Example: "RAPID is implemented on top of the vLLM 0.8.4 framework"
- XGMI: AMD’s high-speed interconnect enabling fast GPU-to-GPU communication within a node. Example: "using HIP IPC and XGMI"
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, leveraging the paper’s RAPID framework (power-aware disaggregation of LLM inference), its implementation atop vLLM, and the demonstrated behavior of prefill vs. decode under power caps.
- Power-aware LLM serving for on-prem enterprise deployments
- Sectors: software, enterprise IT, finance, healthcare, education
- What: Deploy small-to-mid LLMs (e.g., Llama-3.1-8B) on 8-GPU AMD MI300X nodes with disaggregation (prefill vs. decode) and non-uniform power caps (e.g., 750W prefill, 450–600W decode) to increase goodput and SLO attainment under fixed power budgets.
- Tools/workflows: vLLM 0.8.4 with RAPID’s scheduler; AMD SMI for GPU power capping; monitoring TTFT/TPOT and queue lengths; SLO-aware control loop for dynamic power/GPU role shifting.
- Assumptions/dependencies: Models fit per GPU; reliable power capping via AMD SMI; high-bandwidth intra-node interconnect (XGMI/HIP IPC) for KV-cache transfer; SLO metrics defined (TTFT/TPOT); workloads exhibit typical prefill/decode asymmetry.
- Energy-optimized LLM API operations with SLO guarantees
- Sectors: cloud platforms, consumer-facing AI services, customer support
- What: Improve SLA compliance (TTFT/TPOT) and throughput per watt during traffic spikes by reallocating power from decode to prefill under queue pressure; revert when decode SLOs are threatened.
- Tools/workflows: RAPID’s reactive scheduler running sub-second power reallocation and 2–5s GPU role reassignments; dashboards tracking goodput and QPS/W; SLO-tied autoscaling.
- Assumptions/dependencies: Stable firmware response times to power capping (hundreds of ms); decode performance benefits plateau ~600W; prefill benefits strongly from 600–750W.
- Cost and capacity uplift under municipal or facility power caps
- Sectors: data centers (colocation, edge), enterprise on-prem, telecom edge sites
- What: Increase request handling capacity under immutable node power budgets (e.g., 4.8kW GPU budget) by non-uniform power allocation to prefill; achieve higher QPS/W and up to ~2× SLO attainment at peak load vs. static assignment.
- Tools/workflows: Node-level power budgeting; per-phase GPU pools; non-uniform power caps; capacity planning based on QPS/W rather than raw FLOPs.
- Assumptions/dependencies: Accurate measurement of GPU power draw; decode bound workloads don’t benefit substantially beyond ~600W; KV-cache transfers don’t dominate latency.
- On-prem healthcare NLP and privacy-preserving inference
- Sectors: healthcare
- What: Serve clinical NLP and RAG workloads inside hospital data centers with strict power limits, while meeting latency SLOs for interactive use (clinician queries).
- Tools/workflows: vLLM-based RAPID deployment; non-uniform GPU power caps; clinical latency SLOs tuned to task; TTFT/TPOT monitoring.
- Assumptions/dependencies: Compliance and security constraints require on-prem; small models adequate for clinical intents; node-level disaggregation suffices.
- Financial services assistants under branch or HQ power constraints
- Sectors: finance
- What: Run in-house LLM assistants for analysts and customer support with SLO compliance during market events without exceeding branch data center power envelopes.
- Tools/workflows: RAPID scheduler; decode/prefill pool sizing; SLO-tiered workloads with prioritized latency.
- Assumptions/dependencies: Intermittent burstiness; predictable decode-heavy vs. prefill-heavy phases.
- Edge and telco sites hosting small LLMs
- Sectors: telecom, edge computing
- What: Deploy small LLMs near users (base stations, MEC nodes) with dynamic power reallocation to handle bursty prompts while respecting tight power budgets.
- Tools/workflows: Static non-uniform caps with dynamic adjustments; prefill-biased power during bursts; decode-limited power during steady-state chat.
- Assumptions/dependencies: Adequate HBM capacity; high-bandwidth intra-node links; AMD SMI or equivalent power interfaces available.
- Academic experimentation and teaching in ML systems
- Sectors: academia
- What: Use RAPID as a lab framework to study SLO-aware scheduling, queue-based control, energy efficiency (QPS/W), and disaggregation impacts on TTFT/TPOT.
- Tools/workflows: vLLM + AMD SMI; LongBench and synthetic Sonnet-like workloads; curriculum modules comparing reactive vs. predictive schedulers.
- Assumptions/dependencies: Access to multi-GPU AMD nodes; reproducible datasets and SLO configurations.
- MLOps runbooks for SLO-aware power/GPU management
- Sectors: software, DevOps/MLOps
- What: Create operational playbooks that codify when to move power vs. when to reassign GPU roles based on queue length thresholds, SLO violations, and cooldown timers (as per Algorithm 1).
- Tools/workflows: TTFT/TPOT and queue telemetry; stepwise actions (power shift first, then GPU role migration); cooldown/hysteresis to prevent oscillation.
- Assumptions/dependencies: Sufficient observability; robust integration with AMD SMI; careful tuning of thresholds.
- “Green mode” product tier for LLM APIs
- Sectors: cloud platforms, SaaS
- What: Offer a pricing tier that maximizes QPS/W under a capped power envelope by power-aware disaggregation and dynamic role management.
- Tools/workflows: Per-tenant SLOs; power budgets per node; goodput-based admission control; reporting of energy efficiency metrics.
- Assumptions/dependencies: Tenant workloads compatible with disaggregated serving; transparency into power telemetry.
Long-Term Applications
The following applications require additional research, scaling, vendor support, or hardware co-design beyond the node-level setup and single-GPU models analyzed in the paper.
- Rack-scale power-aware disaggregation and scheduling
- Sectors: hyperscale cloud, large enterprise data centers
- What: Extend RAPID to racks (e.g., AMD Helios) with tens to hundreds of GPUs, enforcing rack-level power budgets and dynamic power/GPU role allocation across nodes.
- Tools/products: Kubernetes operators for power-aware LLM serving; rack-level power orchestrators; fabric-aware KV-cache movement protocols.
- Assumptions/dependencies: Low-latency, high-bandwidth fabrics between GPUs; reliable multi-node power capping; scalable queue/scheduler telemetry.
- Cross-vendor support and standardization of power capping APIs
- Sectors: hardware vendors, cloud platforms
- What: Develop unified, reliable power capping and telemetry APIs across AMD, NVIDIA, and other accelerators to enable RAPID-like control loops in heterogeneous fleets.
- Tools/products: Open standard for GPU power control; driver/firmware enhancements; SLO-and-power-aware serving libraries.
- Assumptions/dependencies: Vendor cooperation; deterministic power cap response times; secure interfaces for multi-tenant environments.
- Predictive SLO- and power-aware scheduling
- Sectors: software, ML systems research
- What: Combine reactive control (queue/SLO signals) with predictive models (arrival forecasting, token length estimation) to preemptively shift power/GPU roles and reduce tail latency.
- Tools/workflows: Lightweight predictors integrated into vLLM; hybrid schedulers; simulation frameworks to tune hysteresis and cooldown parameters.
- Assumptions/dependencies: Accurate forecasting under real traffic; avoiding overfitting and instability; maintaining safety under power limits.
- Integration with demand-response energy markets and grid signals
- Sectors: energy, data center operations
- What: Dynamically adjust LLM inference power envelopes in response to real-time grid constraints or pricing, preserving SLOs for premium tiers while throttling non-critical workloads.
- Tools/products: Energy-aware schedulers; market signal adapters; SLO-tiered admission control; reporting audit trails for compliance.
- Assumptions/dependencies: APIs from utilities; robust multi-tenant prioritization; legal/regulatory frameworks for adaptive loads.
- Hardware-software co-design for prefill acceleration and power provisioning
- Sectors: semiconductors, systems
- What: Pair specialized prefill accelerators (e.g., CPX-like designs) with RAPID’s scheduler to exploit prefill’s stronger scaling with power, improving end-to-end SLO attainment and QPS/W.
- Tools/products: Heterogeneous nodes (prefill-optimized + decode-optimized devices); power delivery tuned per role; KV-cache movement acceleration.
- Assumptions/dependencies: New hardware SKUs; validated interop; cost-benefit vs. general-purpose GPUs.
- Multi-GPU model support (TP>1) and MoE systems under power caps
- Sectors: advanced LLM deployments
- What: Apply power-aware disaggregation to larger models requiring tensor/pipeline parallelism and mixture-of-experts, coordinating per-stage power budgets and expert activation.
- Tools/workflows: Cross-GPU KV-cache orchestration; expert routing aware of power budgets; stage-level power caps; TP/PP-aware schedulers.
- Assumptions/dependencies: Efficient multi-GPU KV-cache transfers; stable performance modeling across more complex topologies.
- Market and policy frameworks for energy-efficient AI SLAs
- Sectors: policy, standards bodies, cloud marketplaces
- What: Define and adopt metrics such as goodput per watt (QPS/W), TTFT/TPOT SLOs, and “Compute/GW” as purchasable service qualities; incentivize energy-aware serving.
- Tools/products: SLA contracts referencing energy efficiency; compliance reporting; certification programs.
- Assumptions/dependencies: Agreement on metrics; robust measurement methods; stakeholder buy-in.
- End-to-end MLOps platforms with “RAPID Operator”
- Sectors: software tooling, DevOps
- What: Deliver a turnkey Kubernetes operator that manages GPU role assignment, non-uniform power capping, SLO telemetry, and dynamic adjustments, with APIs for tenants.
- Tools/products: RAPID Operator; SLO/energy dashboards; alerting and automated mitigation playbooks.
- Assumptions/dependencies: Mature integrations with cluster schedulers, GPU drivers, observability stacks.
- Energy-aware multi-tenant isolation and pricing
- Sectors: cloud/SaaS
- What: Implement tenant isolation policies that enforce per-tenant power budgets and price tiers based on SLO attainment under caps, aligning cost to energy efficiency.
- Tools/workflows: Per-tenant power caps; goodput-based billing; fairness controls under bursty loads.
- Assumptions/dependencies: Accurate attribution of power use; strong isolation; customer acceptance.
- Standardization of disaggregation metrics and KV-cache transport protocols
- Sectors: standards bodies, systems research
- What: Establish common metrics (TTFT, TPOT, goodput) and best practices for bulk KV-cache movement within nodes and across racks to ensure portability and comparability.
- Tools/products: Reference benchmarks; protocol specs for KV-cache sharing; test suites.
- Assumptions/dependencies: Community consensus; fabric support; maintenance of open-source baselines.
Collections
Sign up for free to add this paper to one or more collections.