- The paper introduces a disaggregated inference framework that partitions LLM serving into a prefill and decode stage to optimize GPU resource utilization.
- It demonstrates that deploying heterogeneous GPUs with specialized strengths enhances throughput, reduces latency, and efficiently manages VRAM.
- A two-step optimization algorithm jointly configures parallel strategies and P-D ratios, validated by comprehensive simulation under varied QPS demands.
Disaggregated Prefill and Decoding Inference System for LLM Serving on Multi-Vendor GPUs
Introduction
The inference system of LLMs is pivotal in achieving rapid and accurate responses in user applications. With the proliferation of model sizes, balancing computational requirements and VRAM consumption becomes increasingly challenging. This paper introduces a novel disaggregated inference framework that leverages heterogeneous GPU resources across multiple vendors to optimize resource utilization and minimize costs.
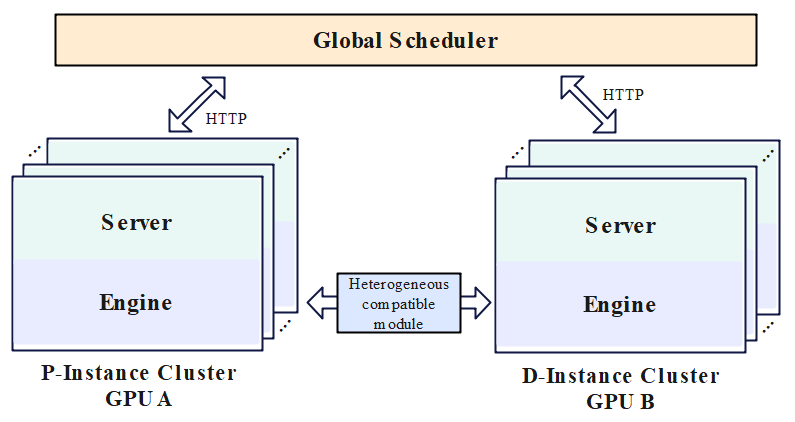
Figure 1: System architecture.
System Design
This paper proposes a P-D disaggregated inference system that effectively partitions the inference process into a prefill stage and a decode stage. Prefill focuses on the generation of the first token, which demands significant computational power, while decode manages the subsequent token generation and is intensive in VRAM usage. By deploying GPUs with specific strengths—as illustrated, GPUs with higher computational power serve the prefill stage, whereas GPUs excelling in memory access capabilities handle the decode stage—the system enhances efficiency and resource utilization.
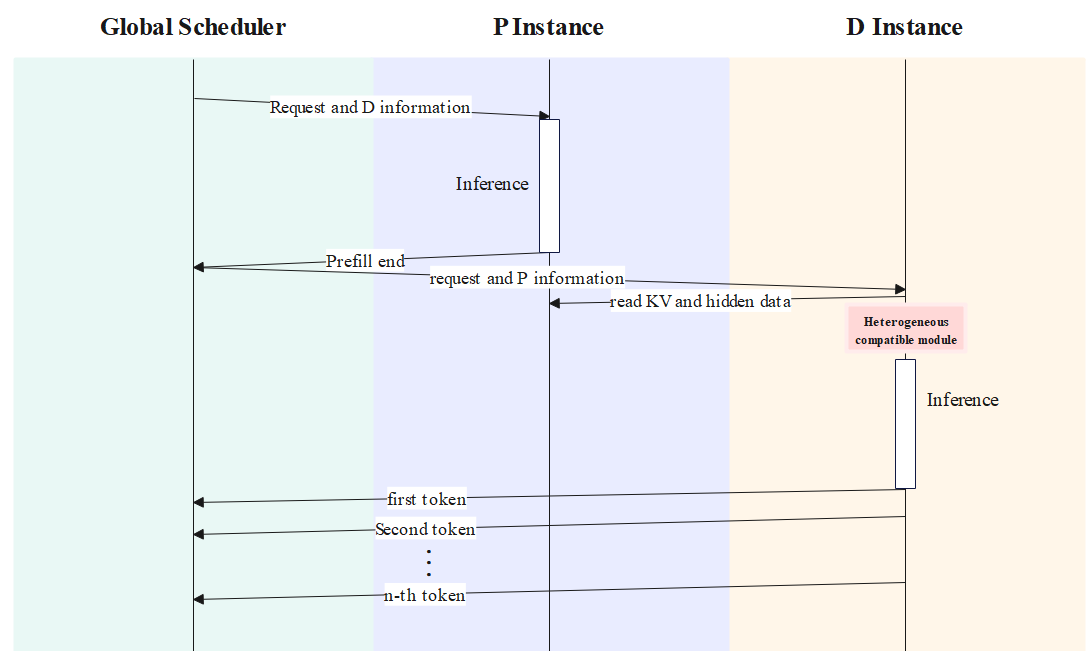
Figure 2: Workflow of P-D disaggregated Inference System.
Heterogeneous Compatible Transmission Module
To facilitate data interchange between diverse GPU architectures, a heterogeneous compatible transmission module is designed. This module tackles the disparity in VRAM management across different GPU vendors. It executes operations such as layout conversion, aligning block sizes, and managing parallel strategies to ensure inter-GPU compatibility. The alignment system aligns parallel strategies between varied GPUs, optimizing data transfer processes critical in asynchronous computing environments.
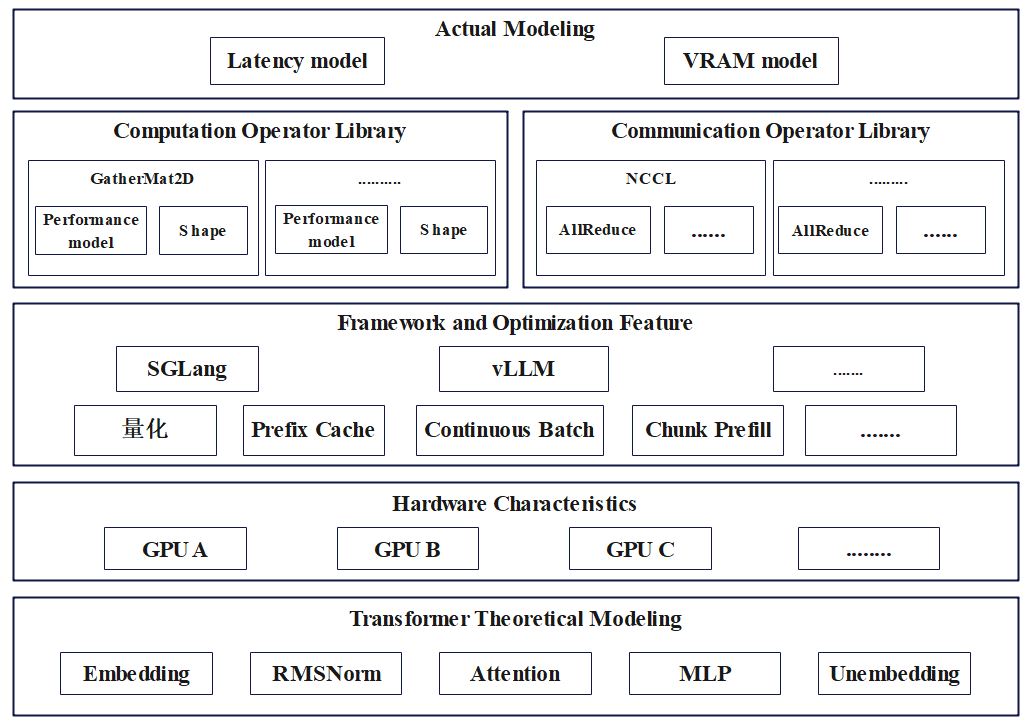
Figure 3: VRAM Management Alignment.
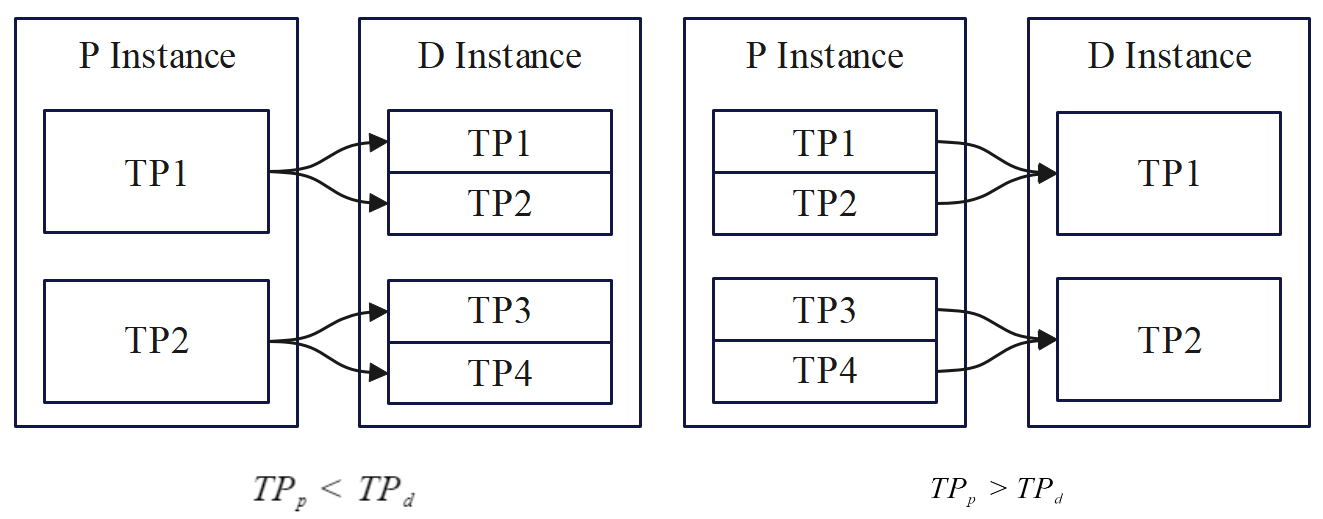
Figure 4: Heterogeneous Parallel Strategy Alignment.
Joint Optimization of Parallel Strategy and P-D Ratio
The optimization of deployment strategies is addressed through a two-step algorithm that calculates ideal configurations for the system's parallel strategies and the ratio of P to D instances. This method maximizes throughput while adhering to constraints on time and VRAM capacity, ensuring efficient handling of high QPS user demands.
Simulator Design
The simulator builds a comprehensive system model that integrates transformer structures, hardware features, and framework optimizations. By simulating various operational scenarios, the simulator aids in refining the joint optimization algorithm, ensuring robust model performance across diverse inference contexts.
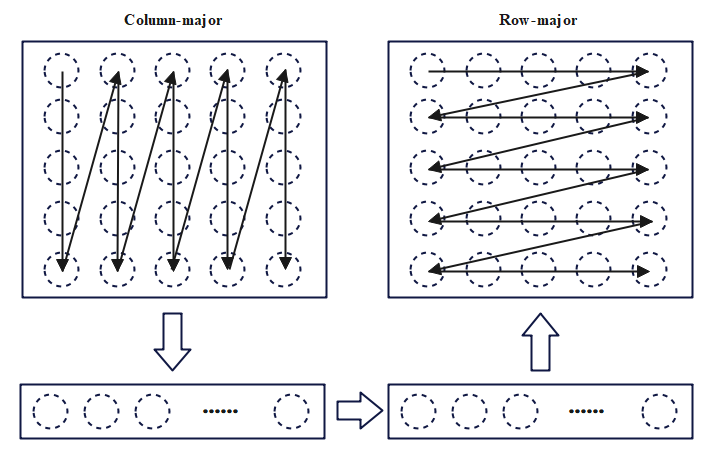
Figure 5: Simulator Model.
Extensive evaluations demonstrate that the P-D disaggregated inference system significantly enhances computational throughput and reduces latency:
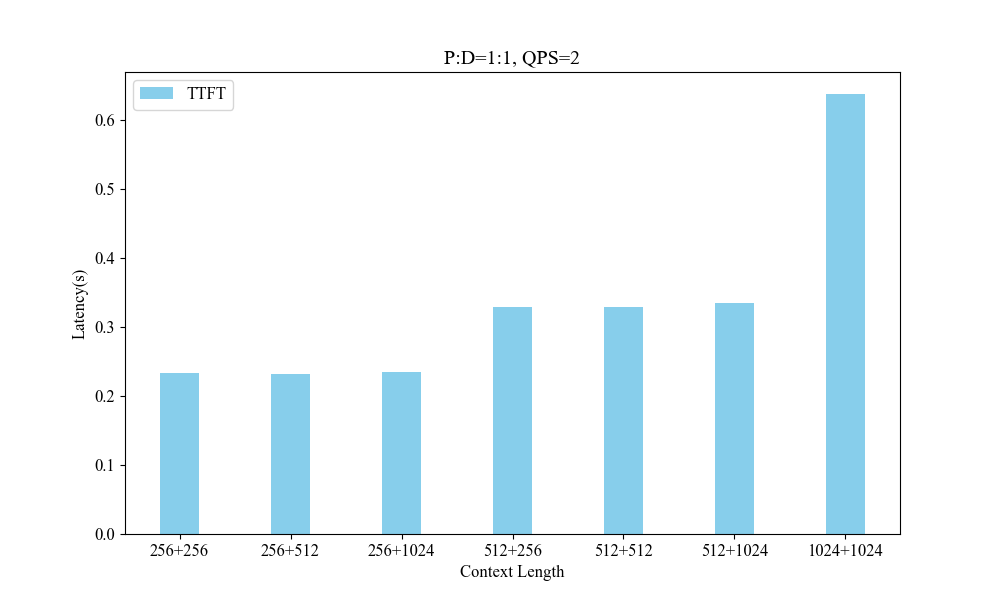
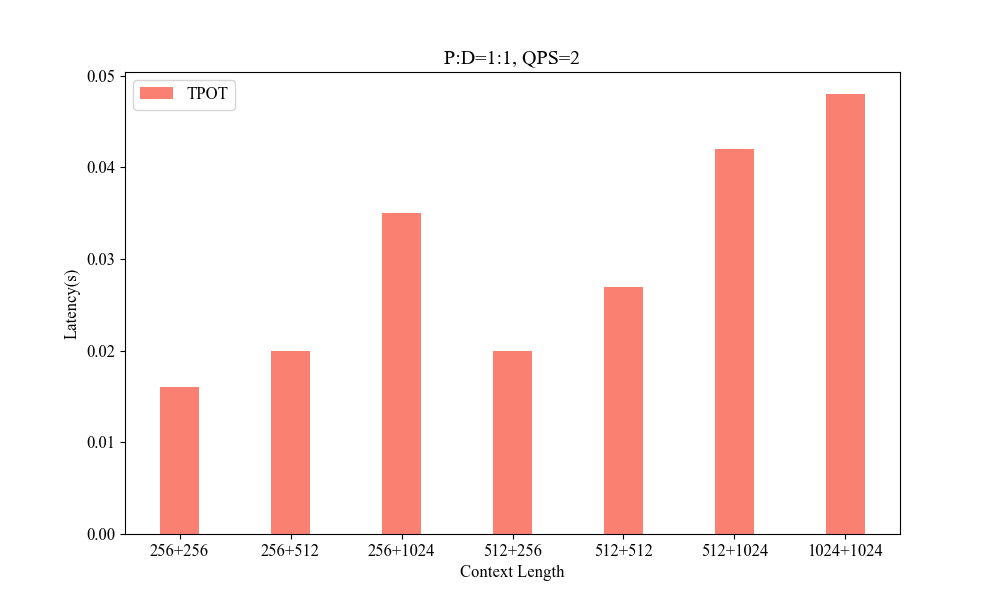
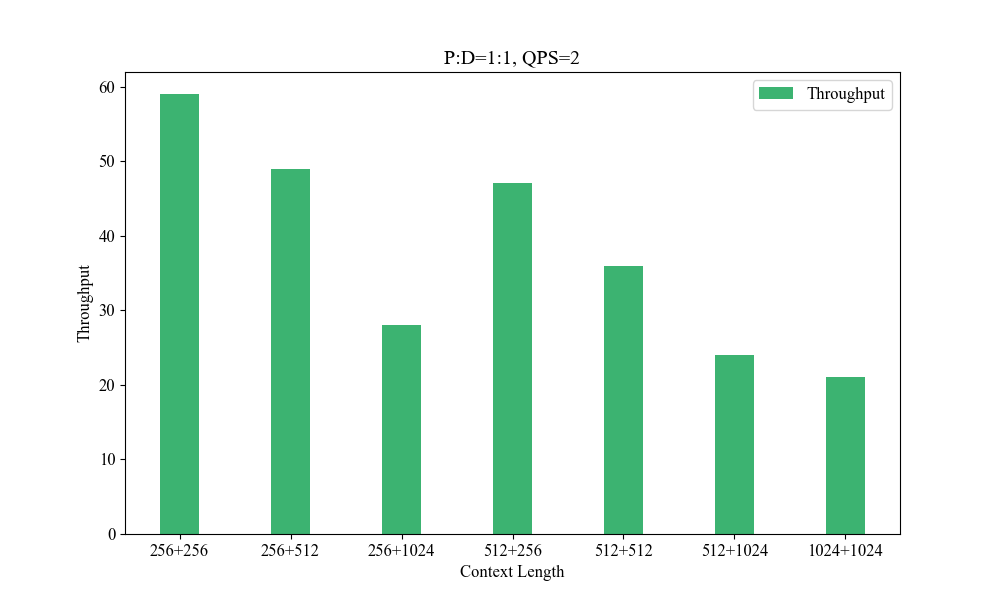
Figure 6: Influence of Different Context Lengths.
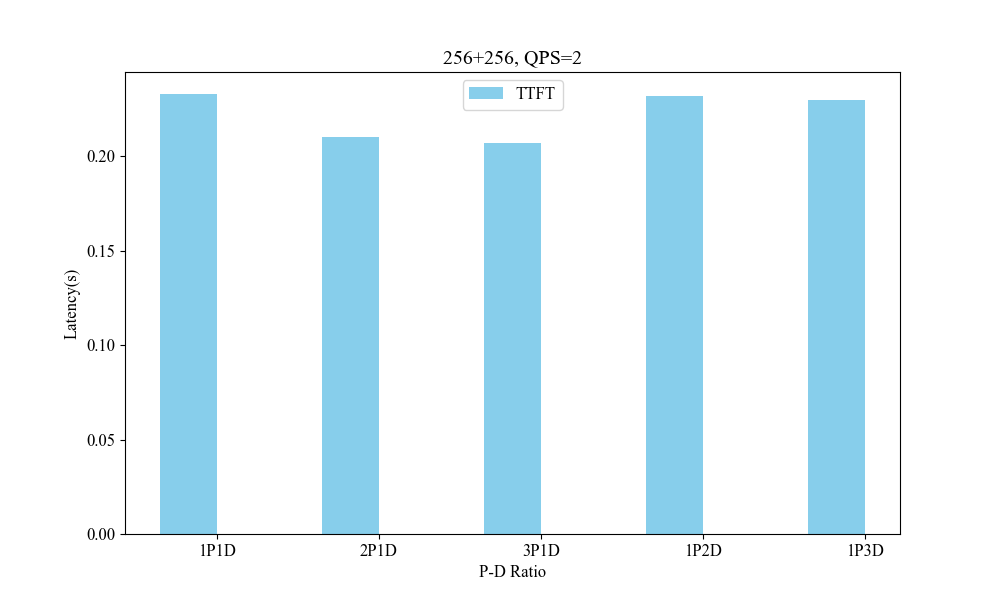
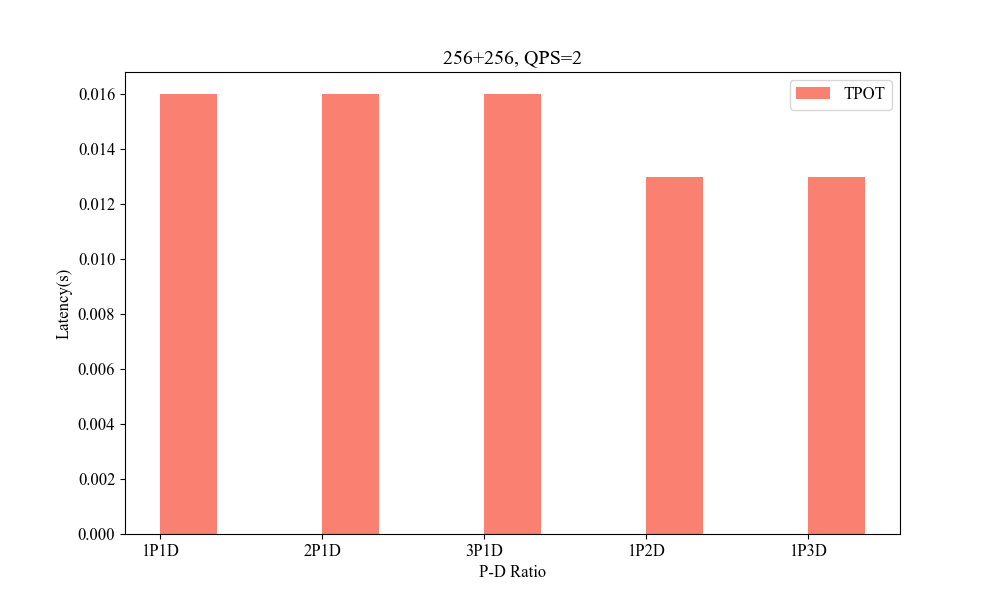
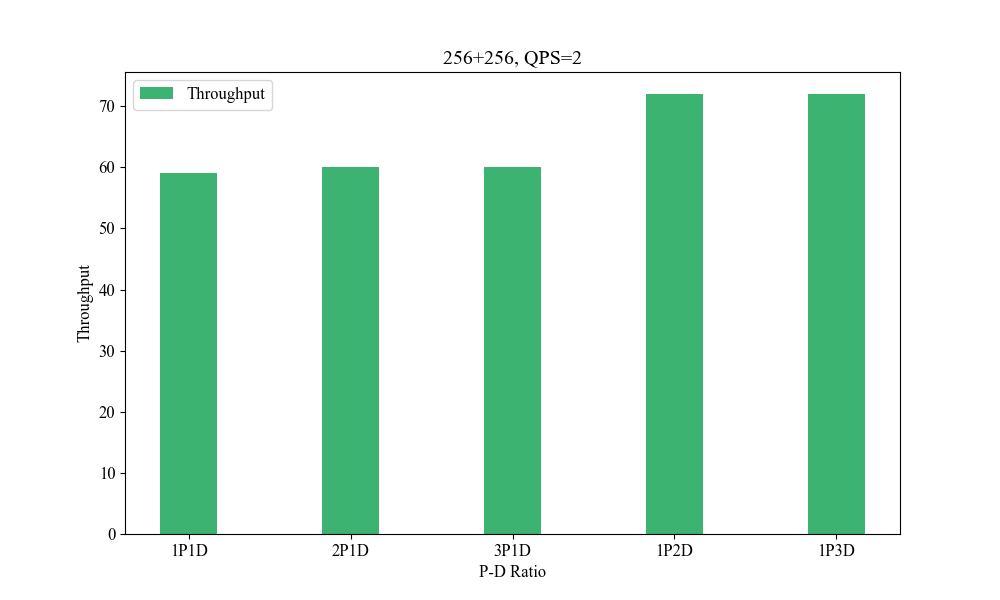
Figure 7: Influence of P-D Ratio(256+256, QPS2).
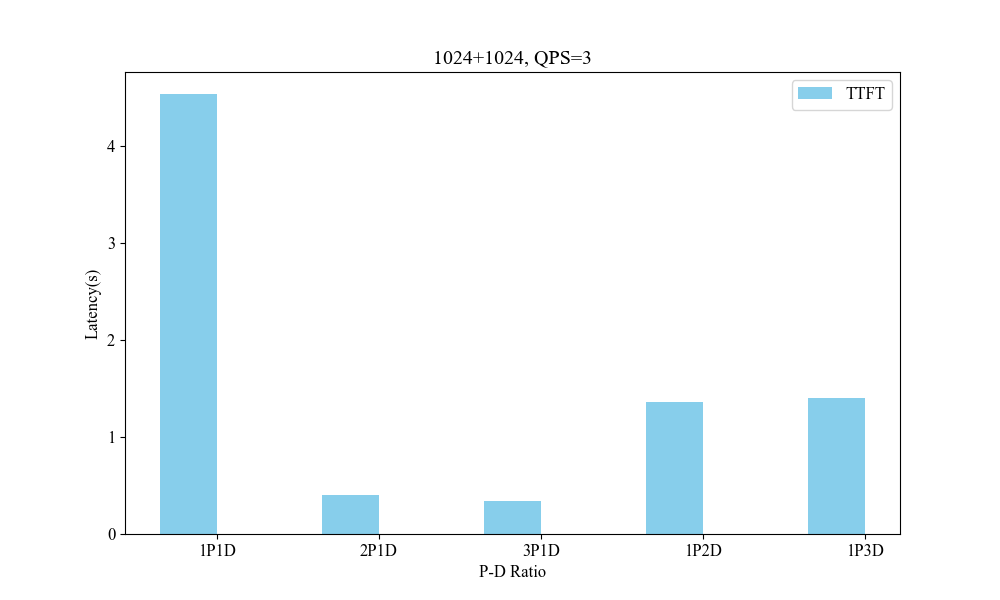
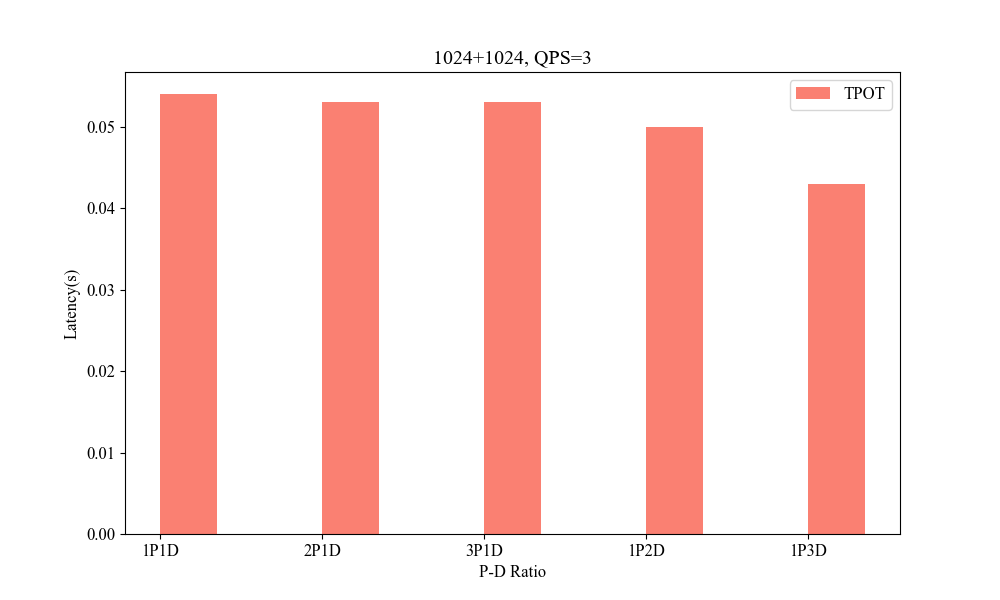
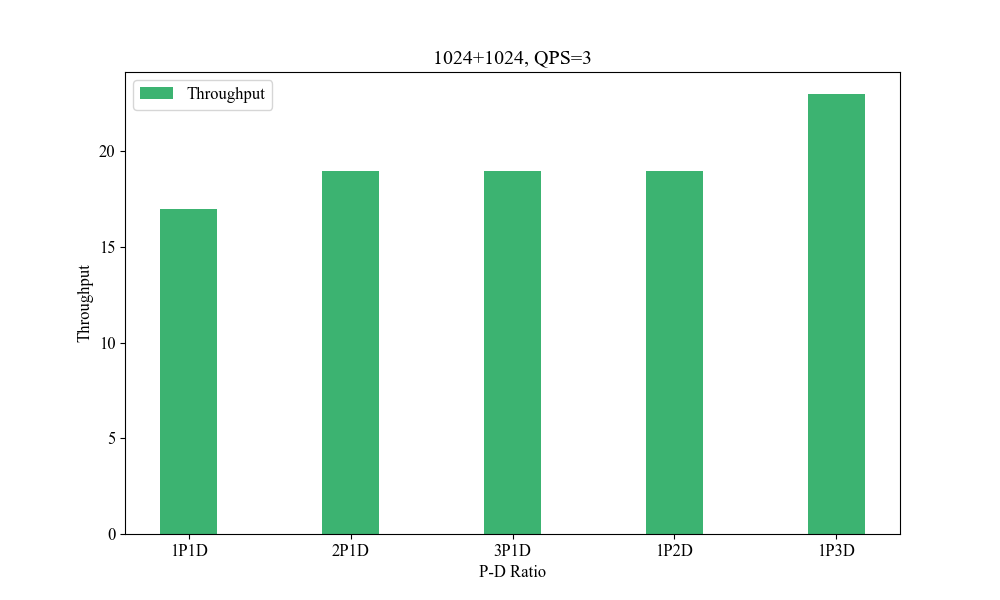
Figure 8: Influence of P-D Ratio(1024+1024, QPS3).
Performance metrics indicate the system's superior handling of varied context lengths and its flexibility in adjusting P-D ratios to optimize processing speed and resource utilization.
Influence of Heterogeneous P-D Strategies
Deploying heterogeneous GPU architectures across different vendors distinctly impacts system performance, allowing for bespoke enhancements that accommodate larger-scale demands without the constraints of inner-system homogeneity.
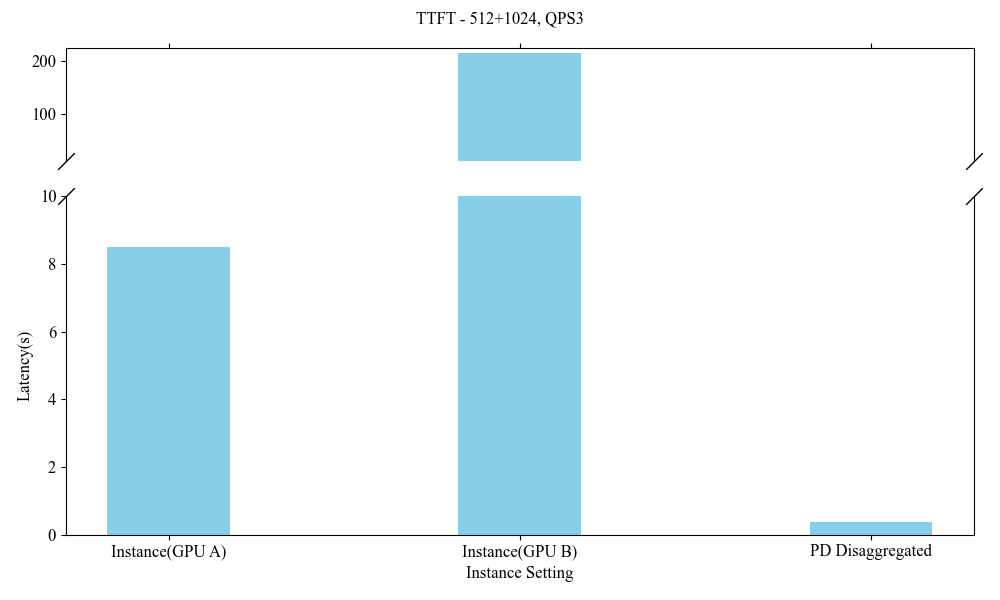
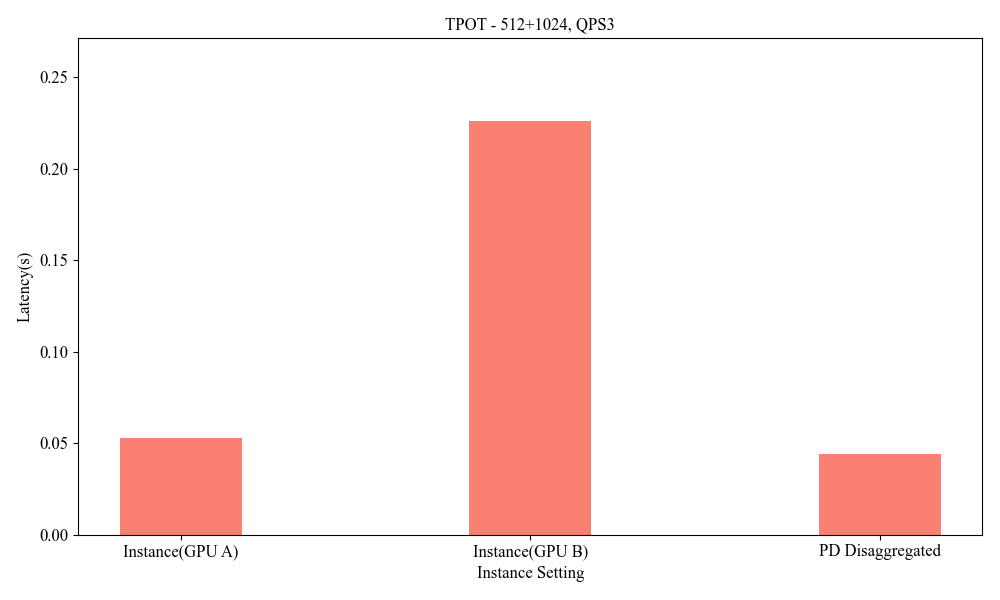
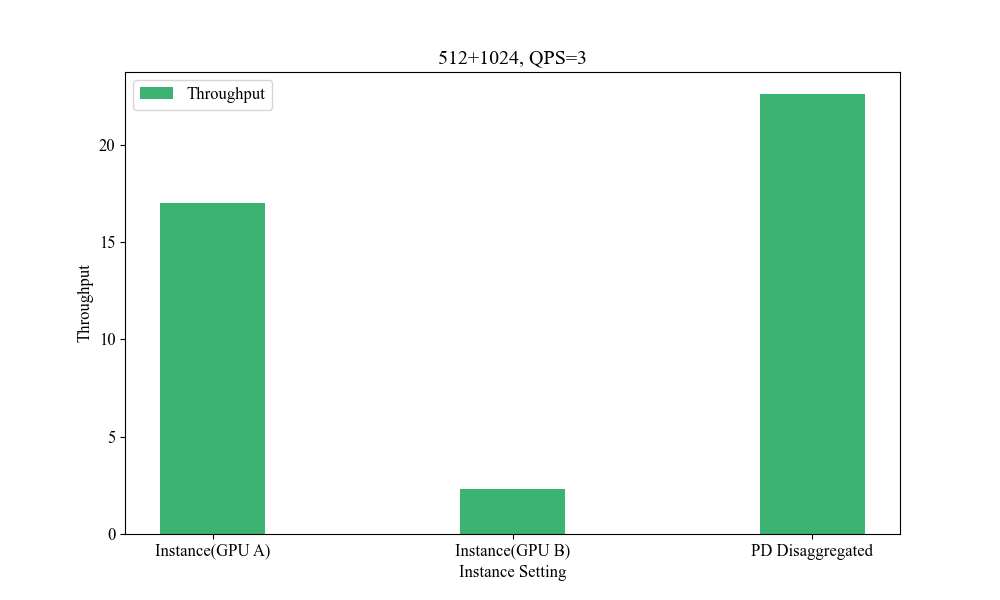
Figure 9: Influence of Heterogeneous P-D(512+1024, QPS3).
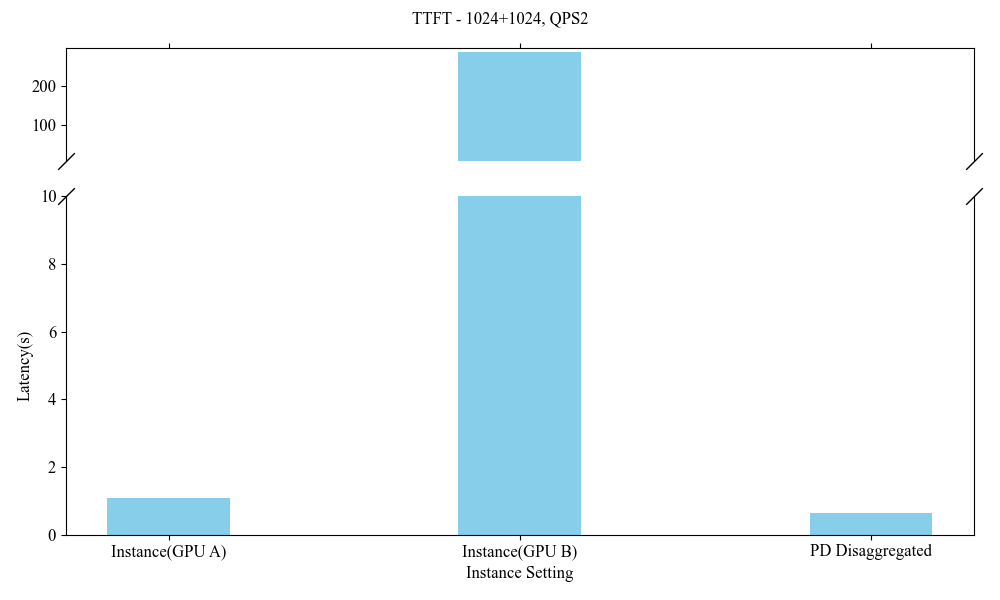
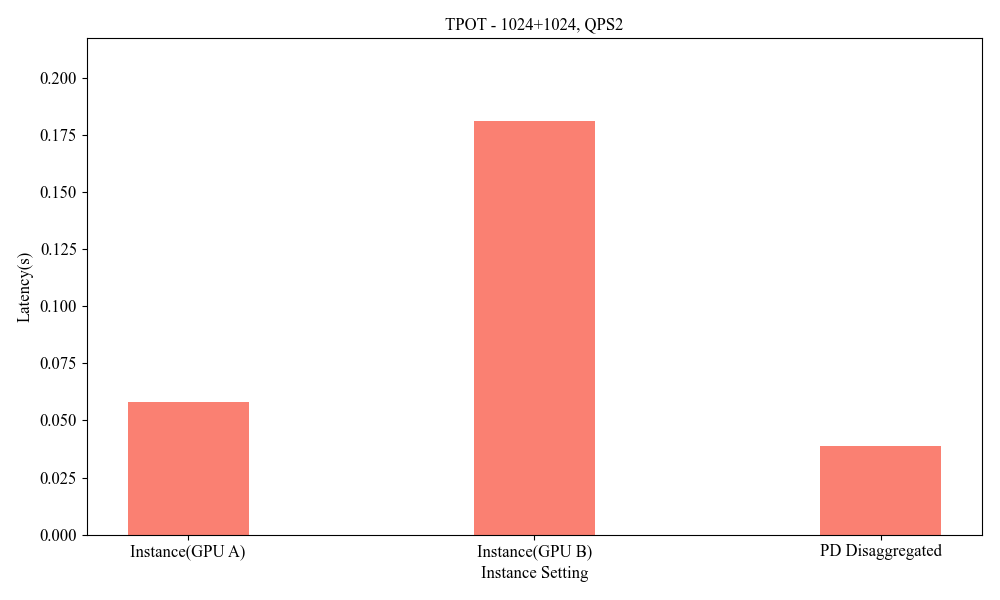
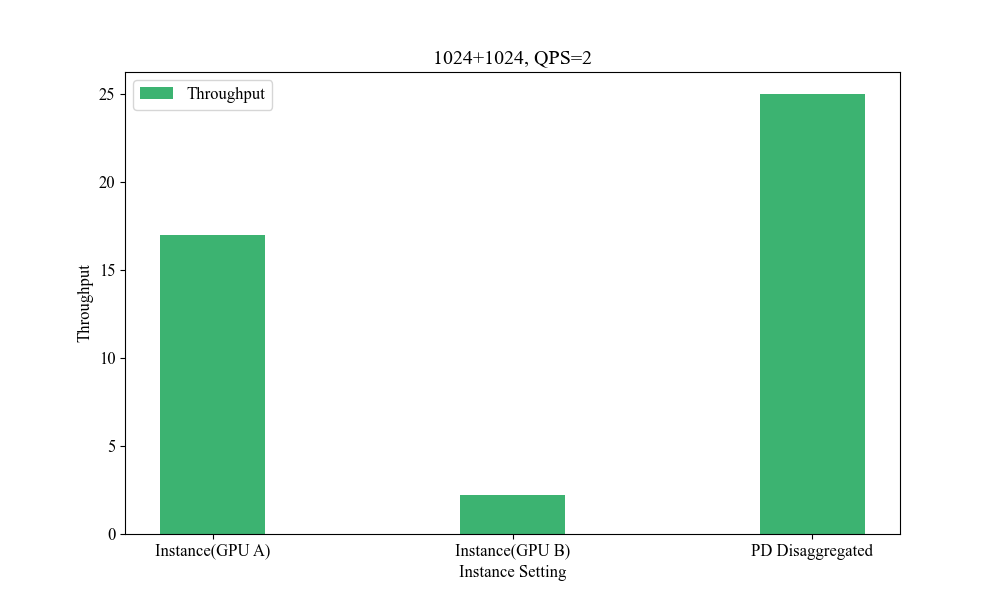
Figure 10: Influence of Heterogeneous P-D(1024+1024, QPS2).
Conclusion
The paper provides compelling evidence that a heterogeneous P-D disaggregated inference framework offers tangible benefits in LLM deployment scenarios. It effectively leverages diverse GPU architecture capabilities to maximize throughput, reduce latency, and minimize infrastructure costs, paving the way for more efficient and adaptable LLM applications across various industries. Future work will focus on refining transmission latencies and optimizing parallel computing strategies to further enhance system capabilities.