- The paper introduces inference disaggregation to optimize throughput and interactivity in AI deployments at datacenter scale.
- It evaluates various model partitioning strategies and dynamic rate matching to manage diverse workloads and traffic patterns.
- The study demonstrates significant benefits for prefill-heavy and large models, while detailing critical bandwidth and latency trade-offs.
A Pragmatic Analysis of Inference Disaggregation in Large-Scale AI Deployments
Inference disaggregation, separating inference serving into distinct phases, is proposed as a promising approach to enhance the scalability and throughput-interactivity trade-offs in large-scale AI deployments. This paper, "Beyond the Buzz: A Pragmatic Take on Inference Disaggregation," investigates the practical challenges and benefits of disaggregated serving at a datacenter scale, analyzing its efficacy across diverse workloads, traffic patterns, and hardware configurations.
Inference Disaggregation: Concept and Deployment Challenges
Inference disaggregation refers to splitting inference computations into separate phases with distinct compute characteristics, usually dividing the prefill and decode phases in autoregressive LLMs. This separation permits tailored optimization strategies for each phase, potentially enhancing throughput and interactivity. Despite its potential, effective deployment of disaggregated serving faces challenges due to the complexity of system-level coordination and the optimization search space.
The study utilizes an extensive analysis of design points across varied workloads to evaluate the efficiency of disaggregated serving and provides actionable insights for optimizing deployments. The analysis indicates that disaggregation is most beneficial for prefill-heavy traffic and larger models, underscoring the importance of dynamic rate matching and elastic scaling for achieving optimal performance.
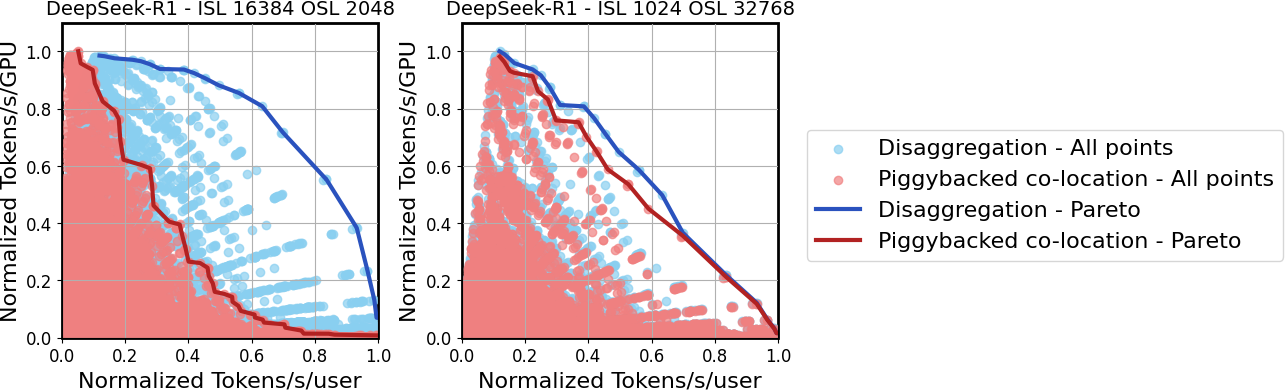
Figure 1: Throughput–interactivity Pareto frontier for DeepSeek-R1 under various traffic patterns.
Design Space Exploration for Disaggregated Serving
Achieving optimal performance in disaggregated serving requires strategic decisions in model partitioning and rate matching. The study examines parallelism strategies, including Tensor Parallelism (TP), Expert Parallelism (EP), Pipeline Parallelism (PP), and Chunked Pipeline Parallelism (CPP), to determine the optimal configuration for maximizing throughput and interactivity.
Model partitioning involves assessing the performance impact of different parallelism schemes under diverse batch sizes and architectures, and exploring the sensitivity to traffic characteristics and latency constraints. The effectiveness of context chunking in co-located serving, particularly under generation-heavy traffic, is highlighted as a significant factor influencing performance.
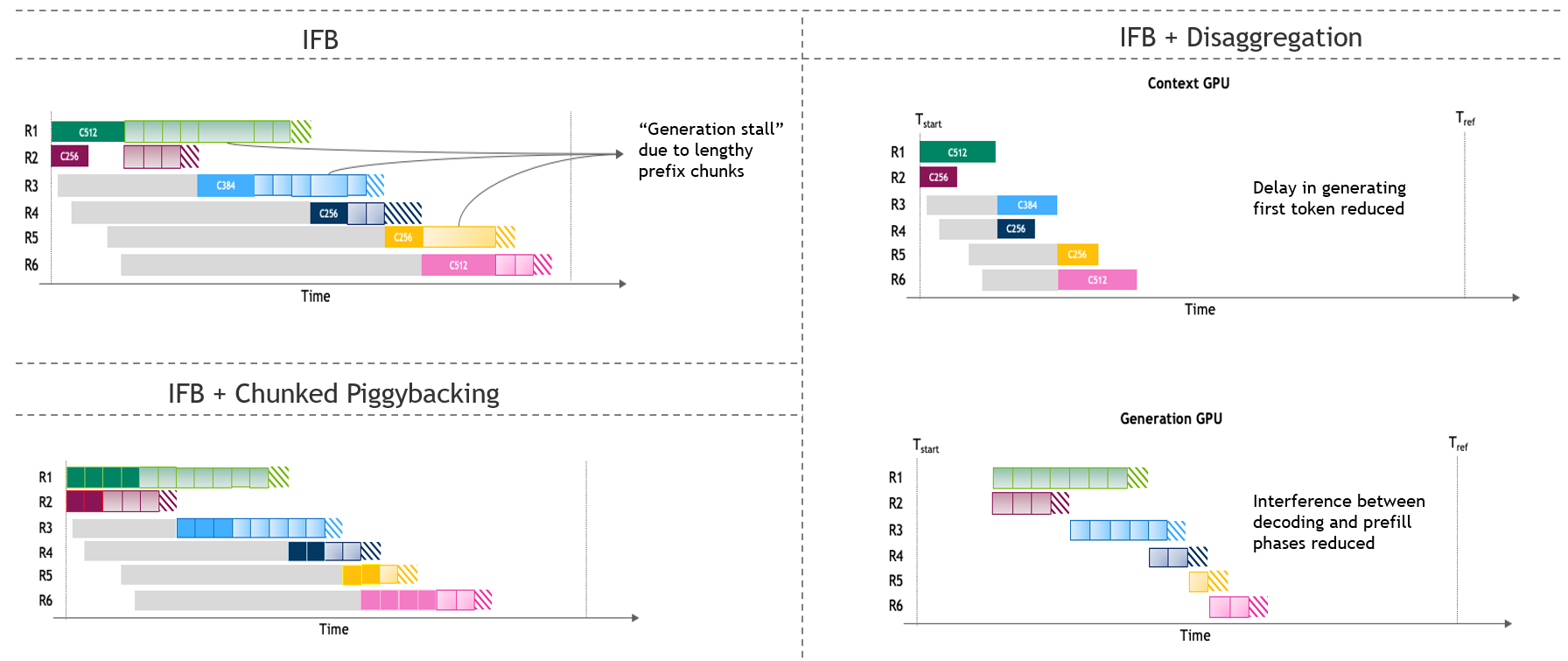
Figure 2: Visualization of co-located vs. disaggregated inference serving, showing request processing dynamics.
The real-world implementation of disaggregated serving requires considering latency metrics defined by service-level agreements (SLAs), specifically First Token Latency (FTL) and Token-to-Token Latency (TTL). The paper details how FTL impacts prefill performance and how dynamic rate matching is crucial for balancing throughput between different phases, allowing adjustments tailored to specific model sizes and latency targets.
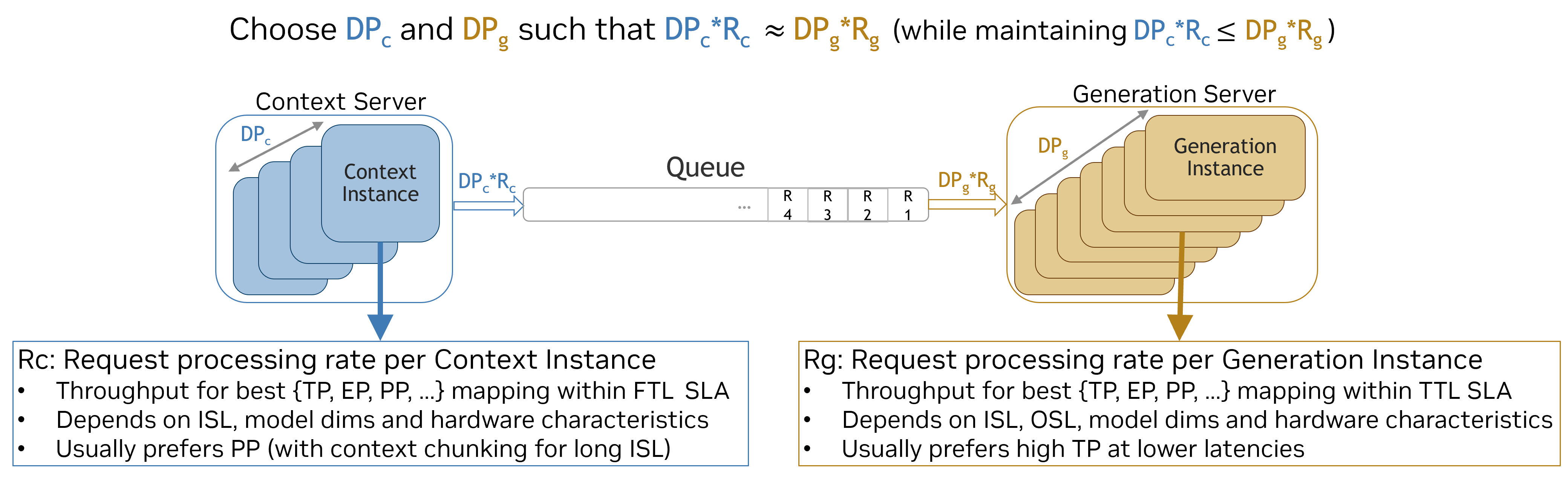
Figure 3: Optimal rate matching dynamically adapts Ctx:Gen ratio to deliver Pareto optimal performance.
The paper emphasizes the dependence of performance gains on the underlying model architecture, size, and traffic patterns. Larger models gain significantly from disaggregation due to a more extensive parallelization search space, while traffic sensitivity analysis reveals that prefill-heavy scenarios benefit most from this approach.
Deployment Strategies and Challenges
Deployment considerations include addressing bandwidth requirements for transferring KV cache between GPUs during disaggregated serving. The paper analytically derives the bandwidth demands to ensure KV cache transfer does not become a bottleneck, accounting for factors like model scale and traffic patterns.
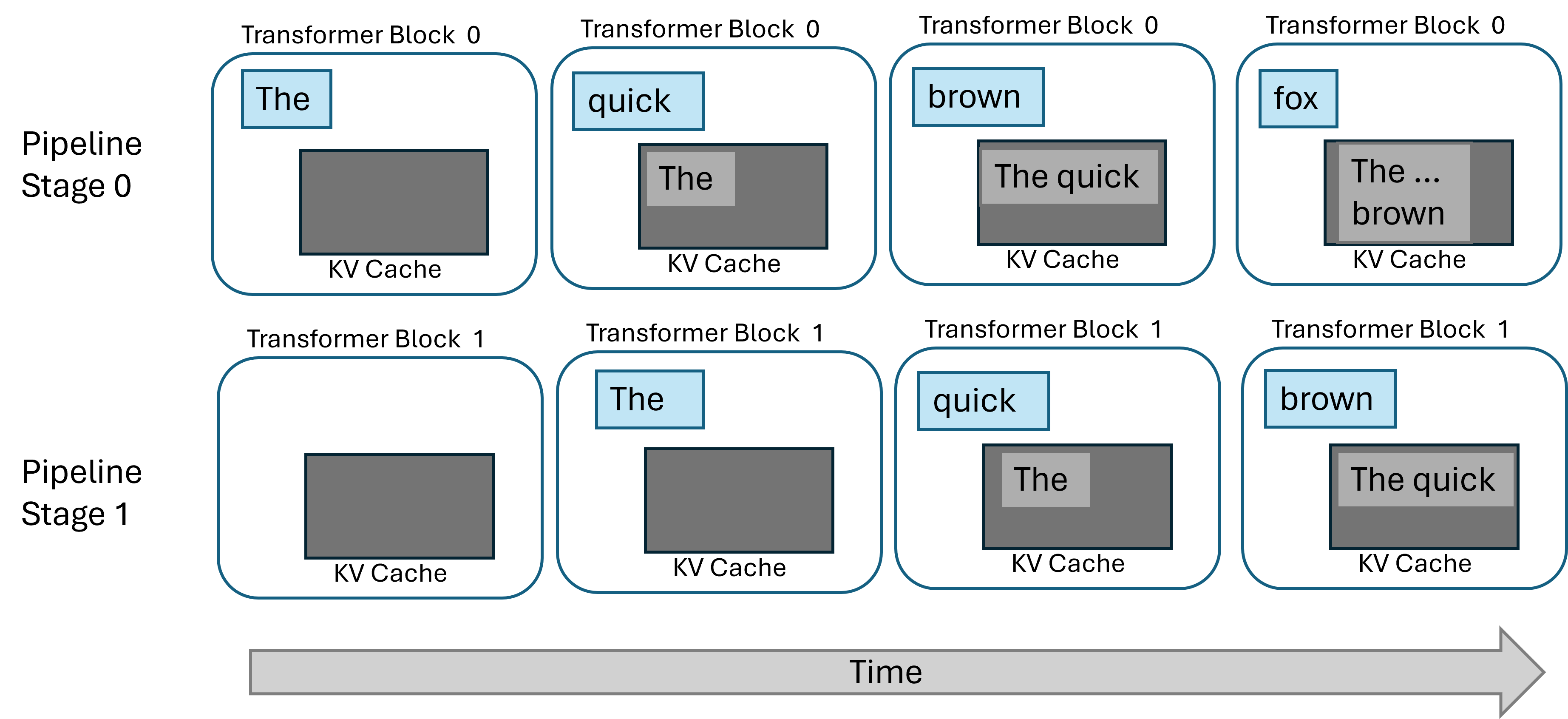
Figure 4: Bandwidth requirements for KV cache transfer across different TTL constraints.
The implications of model scale and architectural sensitivity on serving modalities are critical, as they dictate the configuration of serving setups in real-world datacenter environments.
Conclusion
This study provides a systematic exploration of disaggregated inference and its capabilities in large-scale deployments. The key findings demonstrate that optimal configurations are highly dependent on specific conditions such as model size, traffic patterns, and latency requirements. While disaggregation offers substantial benefits under prefill-heavy and large-model scenarios, it is less effective for smaller models or decode-heavy traffic. These insights guide practitioners in implementing efficient and scalable AI inference serving solutions at scale.