LLM-I: LLMs are Naturally Interleaved Multimodal Creators
Abstract: We propose LLM-Interleaved (LLM-I), a flexible and dynamic framework that reframes interleaved image-text generation as a tool-use problem. LLM-I is designed to overcome the "one-tool" bottleneck of current unified models, which are limited to synthetic imagery and struggle with tasks requiring factual grounding or programmatic precision. Our framework empowers a central LLM or MLLM agent to intelligently orchestrate a diverse toolkit of specialized visual tools, including online image search, diffusion-based generation, code execution, and image editing. The agent is trained to select and apply these tools proficiently via a Reinforcement Learning (RL) framework that features a hybrid reward system combining rule-based logic with judgments from LLM and MLLM evaluators. Trained on a diverse new dataset using four different model backbones, LLM-I demonstrates state-of-the-art performance, outperforming existing methods by a large margin across four benchmarks. We also introduce a novel test-time scaling strategy that provides further performance gains. Project Page: https://github.com/ByteDance-BandAI/LLM-I.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for AI to create combined stories made of text and images, where the text and pictures appear in a back‑and‑forth sequence (interleaved). Instead of making the AI do everything inside one giant model, the authors treat the AI like a smart “project manager” that knows when to call the right tool for the job—like searching for a real photo, generating a creative picture, making a chart with code, or editing an image. They call this framework LLM‑Interleaved (LLM‑I).
What questions were the researchers asking?
In simple terms, they asked:
- Can an AI do a better job creating mixed text-and-image stories if it learns to use different visual tools, instead of relying on just one?
- Can we train the AI to decide which tool to use, when to use it, and how many images to include?
- Will this tool‑using approach make the results more accurate, more informative, and better aligned with the text?
How did they do it?
The agent and its toolbox
Think of the AI like a writer making a blog post or report. A good writer doesn’t draw every picture from scratch. They:
- Search online for real photos,
- Use a graphics program to create charts,
- Generate creative art if needed,
- Edit images to highlight something important.
LLM‑I does the same, using four tools:
- Online image search (to find real, factual photos, like a picture of the Eiffel Tower)
- Diffusion-based image generation (to create new, imaginative images that don’t exist in real life)
- Code execution (to make accurate charts and graphs from data using Python)
- Image editing (to modify an existing image—crop it, add annotations, change colors, etc.)
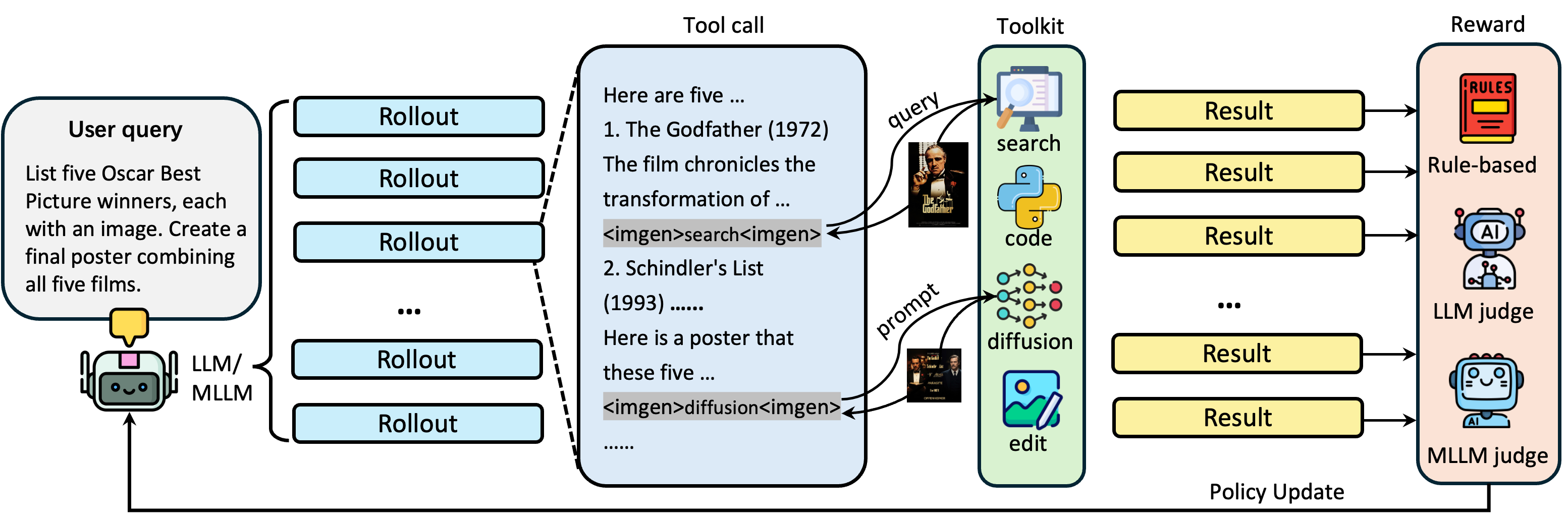
How the agent calls tools
When the AI writes its response, it inserts a special “tag” wherever an image should appear. This tag tells the system which tool to use and what to do. It looks like this:
1 2 3 |
<imgen>{"source":"search | diffusion | code | edit",
"description":"short title",
"params":{ ... }}</imgen> |
- For “search”,
paramsincludes aqueryfor the web image search. - For “diffusion”,
paramsincludes apromptdescribing the image to generate. - For “code”,
paramsincludescodethat draws a chart or visualization. - For “edit”,
paramsincludes which previous image to edit (by index) and an editprompt.
A parser reads these tags, runs the right tool, and replaces the tag with the actual image in the final document.
Training with rewards (Reinforcement Learning)
They use Reinforcement Learning (RL), which is like giving points to the AI when it does things well. LLM‑I gets three kinds of rewards:
- Rule-based reward: Did it follow the rules? For example, if the task says “exactly 2 images”, did it include exactly two? Did it format the tags correctly?
- LLM judge: A separate LLM scores how well the text flows and whether the tool calls (tags) make sense in the story.
- MLLM judge: A multimodal model (one that understands both text and images) checks if the images look good, match the surrounding text, and help achieve the goal of the task.
The final score is a mix of all three. Importantly, image quality only counts if the AI first followed the basic rules (like the right number of images). This keeps the AI from “cheating” by skipping images to avoid mistakes.
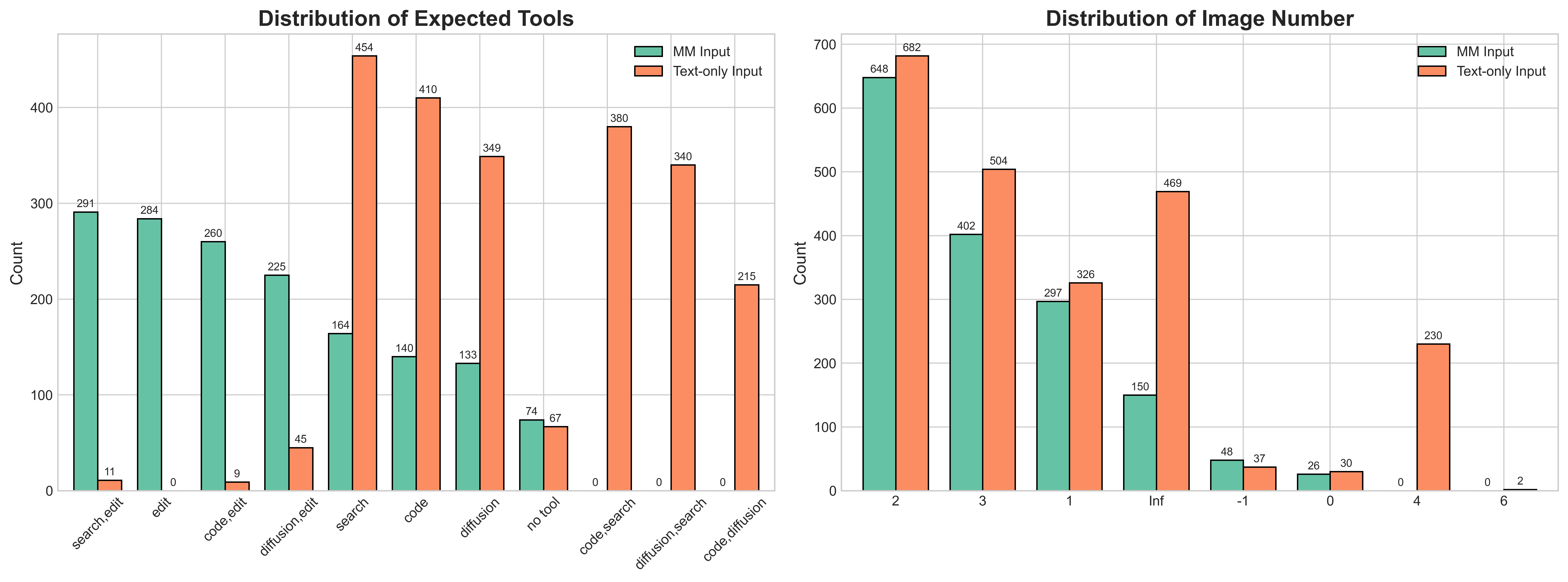
A training dataset designed for tool use
They built a dataset of around 4,000 examples where the prompts strongly imply which tool and how many images should be used—but without saying it directly. This forces the AI to think and choose. The data includes both text-only inputs and cases with input images (so the edit tool gets used). All samples are checked with strong validators to ensure quality.
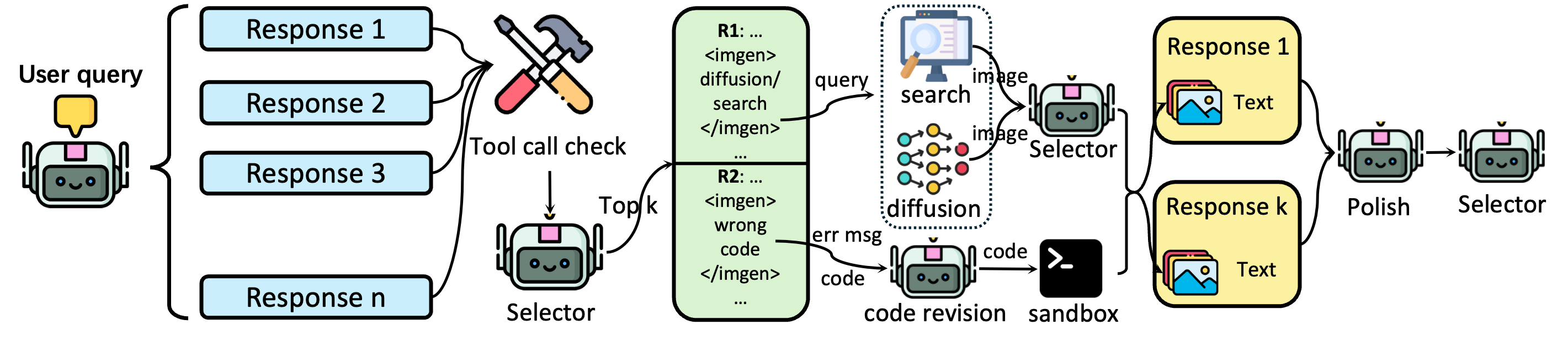
Test-time scaling (trying multiple answers, picking the best)
To make results even better, they add a “test-time scaling” process:
- The AI writes several complete answers with tool calls.
- Broken tool calls are filtered out.
- A selector model picks the top candidates.
- For each candidate, they improve images (e.g., try both search and diffusion and pick the better match) and fix code if it fails (by retrying with helpful error feedback).
- A polisher model cleans up the final text-and-image flow.
- The best polished answer is returned.
This is like drafting multiple versions of a report, repairing any broken parts, and choosing the best one.
What did they find and why is it important?
- The tool‑using agent (LLM‑I) beat other methods on several benchmarks, including tough tests that require real photos, precise charts, and good text‑image alignment. In short, it set new state‑of‑the‑art performance.
- It was very good at using tools correctly (near‑perfect tool success in some setups), and the test‑time scaling made it even better—sometimes enough to beat much larger models.
- When they removed parts of the reward system, performance dropped, especially without the rule-based reward (the AI would start to ignore image requirements). This shows each reward plays an important role.
- When they forced the AI to use only one tool (like only search or only diffusion), performance got worse. Having the full toolbox—and knowing which tool to pick—is crucial.
Why this matters:
- Many real tasks need different kinds of images: real photos (for facts), generated art (for creativity), and charts (for data). A single “all-in-one” image model can’t handle all of these equally well.
- LLM‑I’s “proficient tool user” approach creates smarter, more useful multimodal reports that are accurate, creative, and aligned with the text.
What does this mean for the future?
This work shows that LLMs can naturally act like thoughtful creators when given the right tools and training. Instead of trying to shove every skill into one giant model, we can build AI agents that:
- Decide which specialized tool to use,
- Adapt to new tools without retraining everything,
- Produce richer, more reliable text-and-image content.
This could improve many applications:
- Homework help and study guides with correct charts and real photos,
- News explainers that mix trusted images with clear visuals,
- Professional reports that combine data analysis, diagrams, and narrative.
Overall, LLM‑I points to a future where AI is less like a “know‑it‑all” and more like a great teammate—one that reasons well and uses the right tools to get the job done.
Knowledge Gaps
Below is a concise, actionable list of the paper’s knowledge gaps, limitations, and open questions that future work could address.
- Dataset scale and diversity: Only ~4k RL training items; unclear if this is sufficient for robust tool selection and interleaved generation across diverse domains and styles.
- Synthetic prompt bias: Prompts are auto-generated (Gemini 2.5 Pro) and may encode biases, simplifying assumptions, or narrow instructional styles; limited evidence of human-authored or user-sourced instructions.
- Language coverage: All data and evaluations appear English-centric; generalization to non-English or code-mixed inputs is untested.
- Modality scope: Framework is text–image only; extension to video, audio, 3D, or interactive visualizations is not demonstrated or evaluated.
- Toolset coverage: Only four tool types (search, diffusion, code, edit); unclear how easily the agent scales to new tools (OCR, diagramming, rendering engines, GIS, C2PA provenance checks, retrieval-augmented captioners) without retraining.
- Zero-/few-shot tool addition: No experiment showing the agent can operationalize a previously unseen tool from schema-only or minimal demonstrations.
- Factual grounding of retrieved images: No metric validating that retrieved images truly depict the claimed entities/events, nor source attribution or citation evaluation.
- Copyright and licensing: No discussion of licensing, usage rights, or attribution for web images; unclear handling of watermarks and content provenance.
- Safety filters: Absent evaluation of NSFW/violent content filtering for both retrieved and generated images; no toxicity or sensitive content audits.
- Deepfake/edit risks: Image editing capability could enable harmful manipulations; no safeguards, watermarking, or provenance-preserving mechanisms are described.
- Privacy and data leakage: Web queries may expose sensitive user data; code execution may risk data exfiltration; sandbox egress policies and privacy protections are unspecified.
- Code sandbox security: Limited details on sandbox isolation, time/memory limits, filesystem/network egress, package trust, and mitigation of adversarial inputs and infinite loops.
- Parser robustness: The system relies on a custom <imgen>{...}</imgen> tag and parsing; resilience to malformed tags, prompt injection, or adversarial schema deviations is untested.
- Tool-call failure modes: Aside from code auto-repair, no systematic analysis of failure recovery for search (dead links, outages), diffusion (time-outs), or edit tools; no retry/backoff policies evaluated.
- Determinism and reproducibility: Online search and diffusion are non-deterministic; no caching/seeding strategy is reported; repeatability of benchmark scores over time is uncertain.
- Judge bias and circularity: Rewards depend on LLM/MM-LLM judges (Qwen-family) closely related to the fine-tuned backbones, risking bias, gaming, or family-overlap advantages; rating rubric prompt transparency and inter-judge consistency are not reported.
- Reward design sensitivity: Fixed weights (w_rule, w_llm, w_mllm) and penalty factor α=0.3 are not ablated; robustness to these hyperparameters is unknown.
- Reward formula clarity: The piecewise definition of R_rule appears malformed/ambiguous in the text; exact implementation details (e.g., under-generation partial credit) need clarification.
- Multiplicative gating effect: R_mllm is multiplied by R_rule; this may suppress learning signal for image-text quality when image count is incorrect; alternatives (e.g., soft gating, curriculum) are unexplored.
- Sample efficiency and variance: Training steps, run-to-run variance, and compute costs for RL with external judges/tools are not reported; stability across seeds is unknown.
- Test-time scaling confounds: Selector/polisher uses a strong external MLLM (Qwen2.5-VL-72B); improvements may largely stem from this bigger model rather than the base agent; fairness and ablations across different selectors are missing.
- Cost–quality trade-offs: Only coarse latency is reported; no systematic Pareto analysis of k, number of candidates, image samples per tool, or judge calls versus quality and cost.
- Human evaluation rigor: Human eval details (annotator count, expertise, inter-annotator agreement, confidence intervals) are absent; the sample size for human eval is unclear.
- LLMI-Bench scale and generality: The new benchmark has only 30 samples; potential overfitting and limited coverage of real-world variability; protocols to prevent tuning to these items are not described.
- Objective criteria reliability: LLMI-Bench uses GPT-4o to score per-rule; robustness of these rule checks, false positives/negatives, and sensitivity to prompt phrasing are not audited.
- Baseline transparency: Inclusion of “GPT-5 wTool” lacks methodological transparency; details on configuration, toolset parity, and evaluation settings are insufficient for fair comparison.
- Attribution and citations in outputs: Retrieved images’ URLs, metadata, or citations are not embedded in the generated reports; transparency and traceability are lacking.
- Time-sensitive knowledge: How the system handles recency (e.g., breaking events) and contradicting sources is not evaluated; no temporal grounding metrics are provided.
- Multi-image consistency: Limited analysis of entity/style consistency across multiple images in a sequence, especially for narratives requiring persistent characters or scenes.
- Control over aesthetics and layout: No evaluation of stylistic control (e.g., consistent color palettes, design systems) or document-level layout constraints and pagination.
- Robustness to adversarial prompts: No tests for prompt injection, tool-parameter attacks (e.g., escaping JSON), or image-based attacks against MLLM judges.
- Generalization across tool APIs: The approach is coupled to specific APIs (SERP, Seedream 3.0, Seededit 3.0); portability to alternative providers and API schema drift is untested.
- Multi-turn interaction: The framework is single-pass with embedded tags; it does not support iterative, user-in-the-loop refinement or revision workflows typical for report authoring.
- Error analysis: Limited breakdown of common failure modes (wrong tool choice, incorrect image counts, misaligned edits, faulty charts); actionable diagnostics are missing.
- Broader impacts and sustainability: No discussion of environmental cost of RL with external tool/judge calls, nor cost-aware training/inference policies.
Glossary
- Agentic planner: An LLM/MLLM configured to plan and decide how to use external tools during generation. "we introduce a flexible and dynamic framework where an LLM or MLLM serves as an agentic planner."
- Autoregressive: A modeling approach that generates outputs one token at a time conditioned on previous tokens. "integrate an autoregressive model with a diffusion model"
- Clipping ratios: Bounds used in policy-gradient RL to stabilize updates by limiting the magnitude of policy changes. "For GSPO, the clipping ratios are set to 3e-4 (low) and 4e-4 (high)."
- Cosine learning rate scheduler: A schedule that decays the learning rate following a cosine curve. "we use a batch size of 32 with a cosine learning rate scheduler where the initial learning is set to 1e-6, minimum learning rate ratio is set to 0.01, and the warm-up step is 5."
- Cross-modal consistency: The degree to which outputs (e.g., text and images) across different modalities remain semantically coherent. "requiring high-fidelity text and images with strict cross-modal consistency."
- DAPO: A value-free reinforcement learning algorithm used to fine-tune LLMs without an explicit value model. "value-free alternatives like GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical} and DAPO~\citep{yu2025dapoopensourcellmreinforcement}."
- Diffusion-based generation: Image synthesis using diffusion models that iteratively denoise random noise to produce images. "Diffusion-based Generation: Selected for tasks requiring the creative synthesis of novel or abstract concepts, or complex compositions that do not exist in reality."
- End-to-end models: Architectures that learn to handle all sub-tasks jointly within a single system. "unified, end-to-end models~\citep{xie2025show, zhou2025transfusion, deng2025emerging} that handle both multimodal understanding and generation within a single, integrated framework."
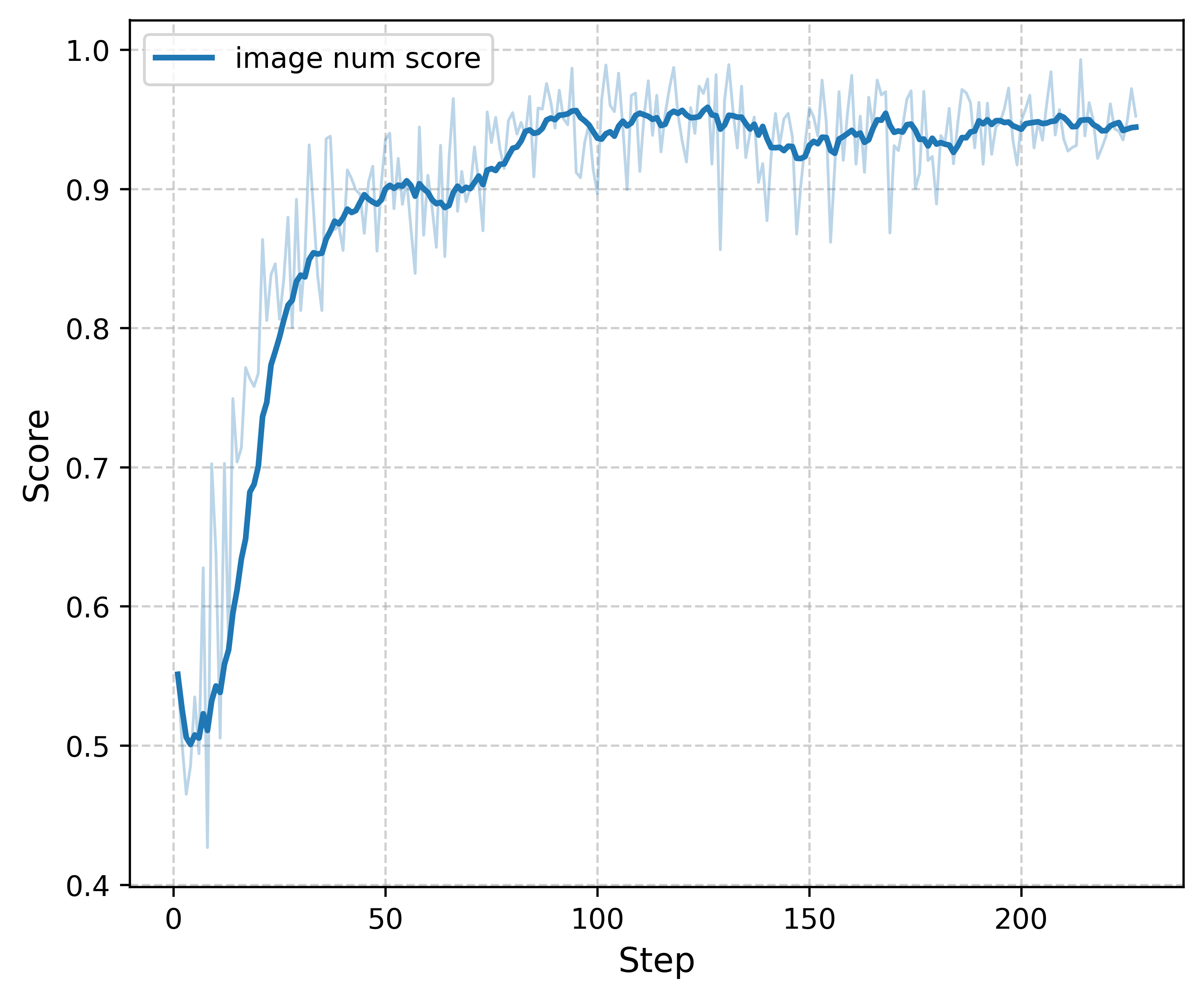
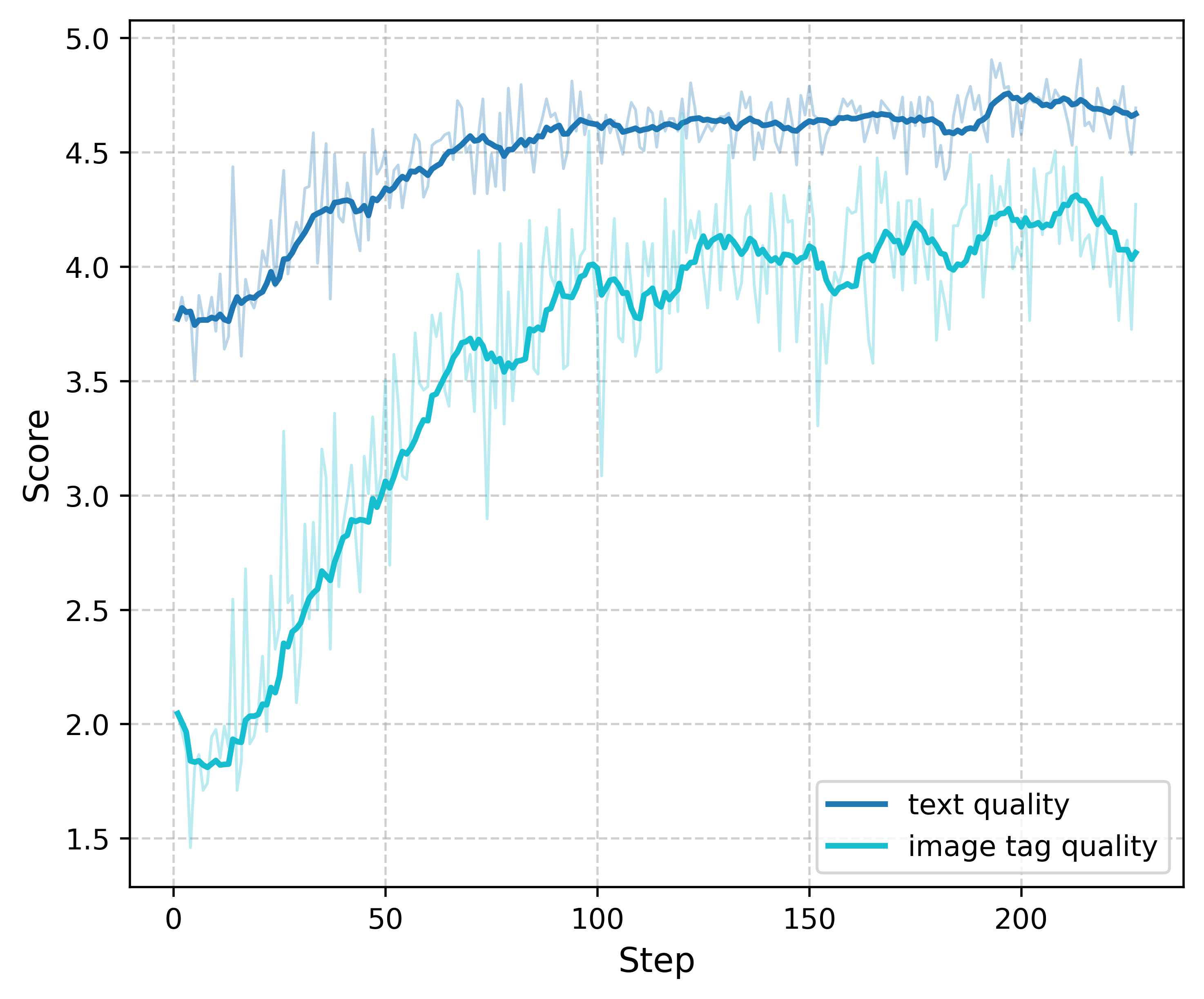
- F1 score (Tool F1 score): The harmonic mean of precision and recall; here used to evaluate tool-selection accuracy. "Tool F1 score curve during RL training."
- Factual grounding: Ensuring outputs are anchored in real-world facts or data. "ill-suited for tasks that require factual grounding such as real-world images"
- GRPO: A value-free RL method for fine-tuning LLMs that removes the need for a learned value function. "value-free alternatives like GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical}"
- GSPO: An RL algorithm (for MoE models) used to fine-tune policies, related to PPO-style optimization. "For MoE model, we use GSPO~\citep{zheng2025group} as the RL algorithm"
- Hybrid reward system: A composite RL reward combining rule-based checks with LLM/MLLM judgments. "a Reinforcement Learning (RL) framework that features a hybrid reward system combining rule-based logic with judgments from LLM and MLLM evaluators."
- Image editing: Automated modification of images (e.g., crop, color adjust, annotate) via an editing tool. "Image Editing: Engaged to perform modifications on existing visual content, whether inputted, retrieved or generated."
- Image num constraint: A rule specifying how many images should be generated or whether they are allowed/required. "A critical feature of this dataset is the annotation of each prompt with an image num constraint."
- Interleaved image-text generation: Producing an alternating sequence of text and images that form a coherent narrative. "A key frontier is interleaved image-text generation~\citep{ge2024seed, tian2024mminterleavedinterleavedimagetextgenerative, xie2025show, zhou2025opening, xia2025mmie,chen2025interleaved}: producing a coherent, alternating sequence of text and images from a single prompt."
- LLM judge: An external LLM used to score text quality and tool-use logic during RL. "The second component R_llm leverages an external LLM as a judge to assess the quality of the language and the logic of the tool invocation."
- Mixture-of-Experts (MoE): A model architecture that routes inputs to a subset of specialized expert subnetworks. "For MoE model, we use GSPO~\citep{zheng2025group} as the RL algorithm"
- MLLM (Multimodal LLM): A large model that can process and reason over multiple modalities (e.g., text and images). "The third reward component R_mllm employs an MLLM to evaluate the final interleaved output."
- Multimodal alignment: How well different modalities (text, image) correspond semantically. "we investigate how RL can be used to improve multimodal alignment, the ability to intelligently use tools, and the overall quality of generated reports."
- Out-of-domain (OOD): Data or tasks that differ from the distribution seen during training. "three out-of-domain (OOD) benchmarks."
- Polishing (stage): A post-processing step that refines and improves coherence of the generated multimodal response. "the k refined interleaved multimodal responses are passed to an MLLM for polishing."
- Proximal Policy Optimization (PPO): A popular RL algorithm that stabilizes policy updates via clipping. "While Proximal Policy Optimization (PPO)~\citep{schulman2017proximalpolicyoptimizationalgorithms} is the most common algorithm for fine-tuning LLMs"
- Reinforcement Learning (RL): A learning paradigm where an agent learns to act via rewards and penalties. "We develope a Reinforcement Learning (RL) framework that incorporates a hybrid reward design"
- Reward hacking: Exploiting imperfections in the reward signal to achieve high scores without truly solving the task. "to counteract the agent's potential aversion to more error-prone tools during RL (a form of reward hacking)"
- Rule-based reward: A deterministic reward component enforcing explicit constraints (e.g., image count, tag format). "The first component is a deterministic, rule-based reward R_rule that enforces adherence to generation constraints"
- Sandboxed environment: A restricted execution environment for safely running untrusted code. "which is then re-executed in a sandboxed environment until a valid visualization is obtained"
- Selector model: A model used to rank candidate responses and choose the best one. "a selector model (an LLM/MLLM) evaluates their overall quality and relevance to the prompt"
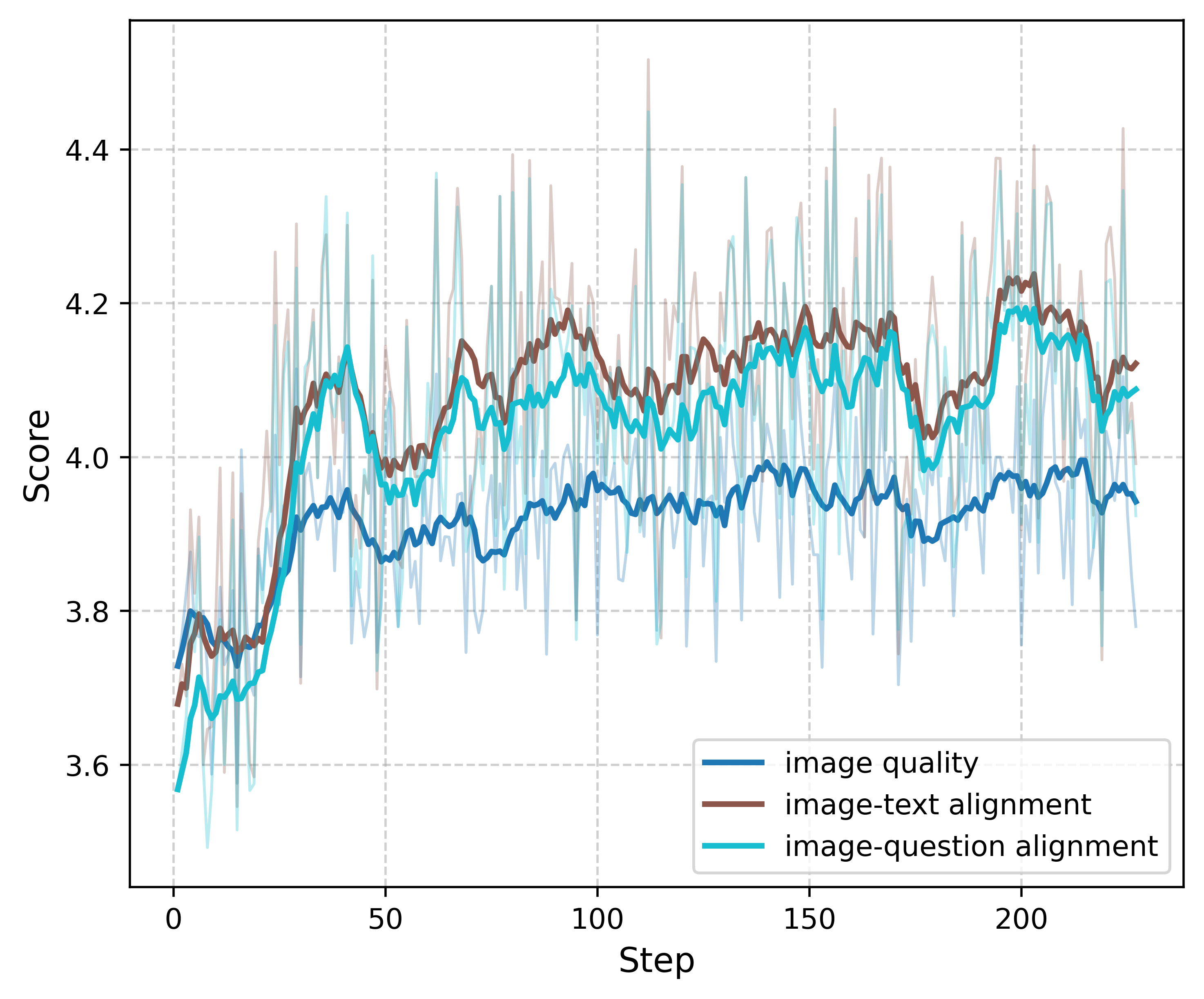
- Semantic alignment: The correctness of meaning correspondence between image and surrounding text. "strong semantic alignment between each image and its accompanying text."
- Semantic gap: Mismatch between an LLM’s textual intent and a diffusion model’s image interpretation. "it often suffers from a 'semantic gap'"
- Stochastic sampling: Randomized decoding (e.g., temperature/top-k) to generate diverse candidate outputs. "the model first generates multiple complete candidate responses through stochastic sampling."
- Structured <imgen> tag: A JSON-like placeholder in outputs that encodes tool calls and parameters for image generation. "The core of our framework is the structured tag, <imgen>{...}"
- Test-time scaling: Improving performance by expending extra computation at inference (e.g., multiple candidates, selection). "we introduce a test-time scaling~\citep{snell2025scaling, muennighoff2025s1simpletesttimescaling} paradigm"
- Token-level loss: An objective computed per token rather than only at the sequence level. "Following \citet{yu2025dapoopensourcellmreinforcement}, we use the token-level loss."
- Tool invocation framework: The mechanism that lets the model decide when and how to call external tools. "we design a robust and flexible tool invocation framework."
- Tool-augmented system: A modeling approach that extends capabilities by integrating external tools. "A tool-augmented system can be easily updated with new capabilities by simply adding a new tool to its repertoire"
- Top-k selection: Choosing the k highest-scoring candidates for subsequent refinement or evaluation. "selecting the top-k most promising responses for further enhancement."
- Unified multimodal models: Single models trained to both understand and generate across modalities. "unified multimodal models that either integrate an autoregressive model with a diffusion model"
- Value-free alternatives: RL methods that avoid training an explicit value function (critic). "its reliance on a value model has spurred the popularity of value-free alternatives like GRPO"
- Value model: The critic in actor-critic RL estimating expected returns to guide learning. "its reliance on a value model has spurred the popularity of value-free alternatives"
- Visual tokens: Learnable embeddings that represent images (or parts of images) within a text-generation pipeline. "optimize a set of learnable visual tokens that serve as input for a diffusion-based image decoder"
- Warm-up step: Initial training phase where the learning rate ramps up from a low value. "the warm-up step is 5."
Collections
Sign up for free to add this paper to one or more collections.

