Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Abstract: LLM applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ACE, which stands for Agentic Context Engineering. It’s a way to help AI LLMs improve themselves by building better “contexts” — the instructions, tips, examples, and facts we give the model along with each task. Instead of changing the AI’s internal settings, ACE evolves the context like a growing, well-organized playbook the model can learn from over time.
Key Objectives
The paper aims to answer three simple questions:
- How can we help AI improve by updating what we tell it (its context) instead of retraining it?
- How do we avoid two common problems: making prompts too short and generic (brevity bias) and losing important details as we rewrite prompts repeatedly (context collapse)?
- Can a structured, step-by-step system for growing and organizing context make AI agents more accurate, faster, and cheaper to run?
Methods (Explained Simply)
What is “context”?
When you use a LLM, you don’t just ask a question. You also give it instructions, examples, and facts. That package of useful information is the “context.” Think of it like a coach’s playbook given to a player before a game. The better and more detailed the playbook, the better the player performs.
The ACE framework: three roles working together
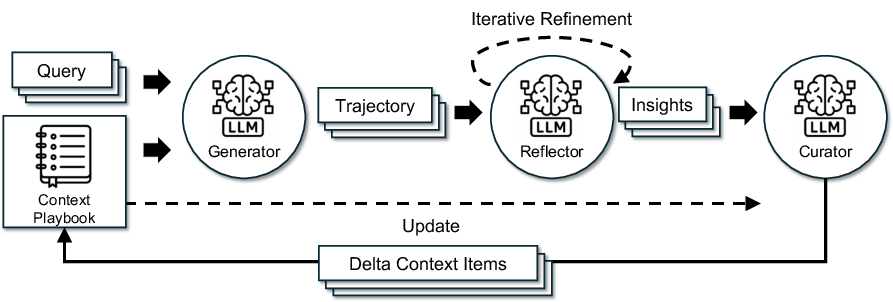
ACE treats context like a living playbook that improves over time. It uses three helper roles:
- Generator: Like a student who tries to solve problems and records what worked and what didn’t.
- Reflector: Like a teacher who reviews the student’s work, points out successes and mistakes, and writes clear lessons learned.
- Curator: Like a librarian who files those lessons neatly into the playbook, making sure everything is organized, not duplicated, and easy to find later.
This teamwork helps add useful, detailed tips without throwing away older, still-important knowledge.
Incremental “delta” updates (small, safe changes)
Instead of rewriting the whole playbook each time (which risks losing details), ACE adds small, specific notes called “bullets” to the context. Each bullet is:
- A mini lesson or strategy (for example, “Try tool X before tool Y for email tasks”).
- Tagged with metadata (like how often it helped).
These tiny updates are called “deltas.” They’re faster, cheaper, and safer than full rewrites, and they keep old, helpful info intact.
Grow-and-Refine (expand, then tidy)
ACE grows the playbook by adding new bullets as it learns, then occasionally cleans it up:
- Grow: Add fresh tips with unique IDs.
- Refine: Merge duplicates, remove repeats, and keep the most helpful versions using meaning-based comparisons (so similar tips are combined).
This keeps the context detailed but not messy, and it scales well for models that can read long inputs.
What do “labels,” “rollouts,” and “latency” mean?
- Ground-truth labels: The correct answers for training tasks (like the official solution).
- Rollouts: Each complete run of a task by the model (like trying an episode in a game).
- Latency: How long you have to wait for results (like loading time).
Main Findings
Here are the most important results, with simple reasons why they matter:
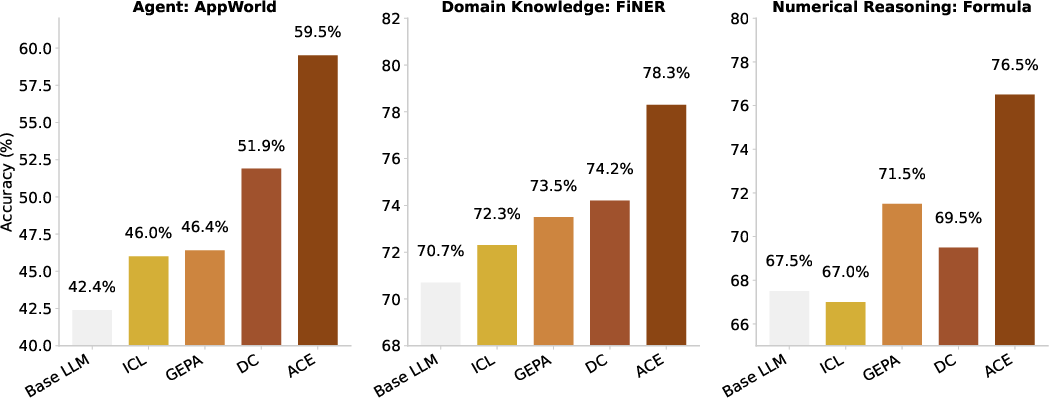
- Better accuracy on agents and finance tasks: ACE improved agent performance by about +10.6% on average and finance tasks by about +8.6% compared to strong methods. That means the AI completes tasks more reliably.
- Works even without correct answers (labels): ACE can learn from “execution feedback” (what happens during a run, like whether a piece of code works) and still improve. This is useful when correct answers aren’t available.
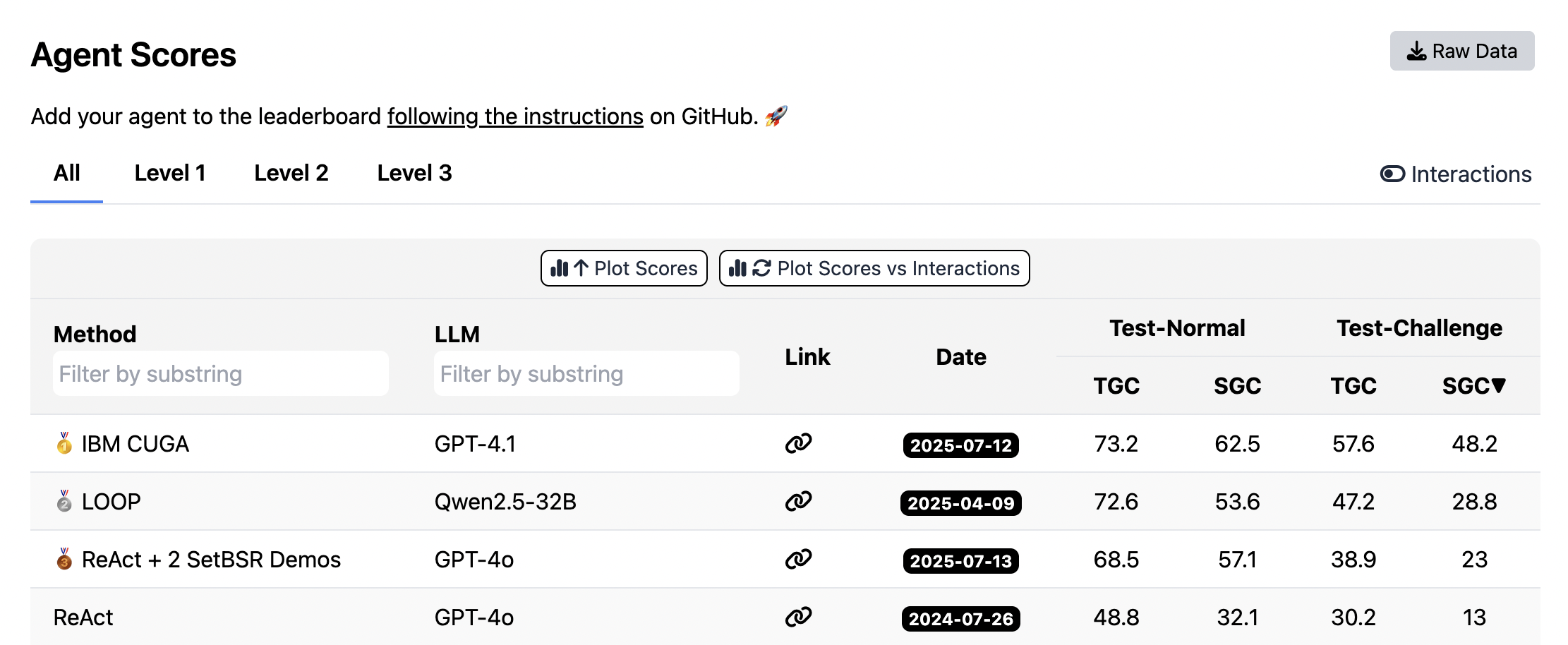
- Competes with top systems using smaller models: On the AppWorld leaderboard, ACE matched a top production agent on average and did even better on the harder test split — while using a smaller, open-source model. This suggests smart context engineering can beat brute-force model size.
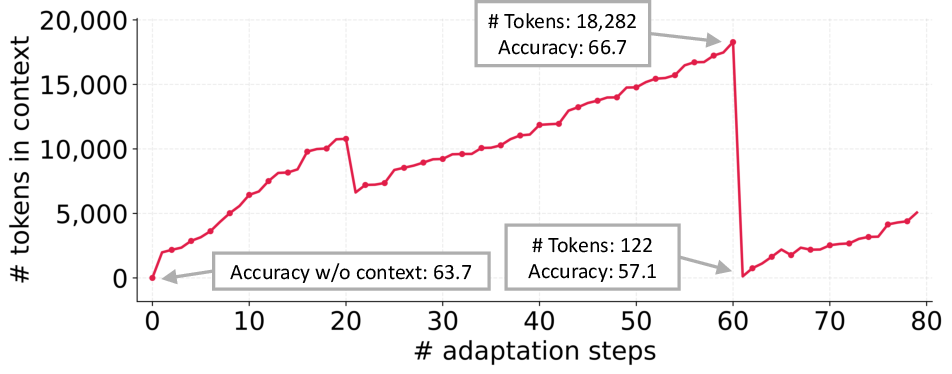
- Much faster and cheaper to adapt: ACE reduced adaptation wait time by up to around 82–92% in the examples shown and lowered cost (like token usage) significantly. Small updates (deltas) and smart merging keep things efficient.
Why this is important: AI teams can get big gains without expensive retraining, and they can understand and edit the playbook because it’s written in human-friendly language.
Implications and Impact
- Self-improving AI, made practical: ACE shows a path for AI systems that keep learning after deployment by collecting lessons from their own attempts and folding them into a better context. This is cheaper and easier than retraining.
- More reliable agents in real apps: Detailed, evolving playbooks help agents use tools better, avoid common mistakes, and handle tricky, domain-specific tasks (like finance or law).
- Human-friendly and safe to update: Because contexts are readable, teams can inspect, fix, or remove outdated or risky information. This helps with responsible AI and compliance.
- Limitations: ACE still needs meaningful feedback (like “did the code run?” or “was the answer correct?”). If feedback is noisy or missing, the playbook can pick up wrong lessons. So high-quality signals are important for the best results.
In short, ACE turns AI context into a growing, well-organized playbook. By adding small, smart updates over time — and keeping all the useful details — AI models get more accurate, faster, and cheaper to run without heavy retraining.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The following list distills what remains missing, uncertain, or unexplored in the paper and can guide future research:
- Generalization beyond the evaluated settings: no empirical validation on other domains (e.g., legal, medical, scientific RAG, complex coding tasks like SWE-Agent/WebArena) or multi-modal contexts (images, tables, logs).
- Dependence on the base LLM: the framework uses the same open-source model (DeepSeek-V3.1) for all roles; effects of stronger or specialized models per role (Generator vs Reflector vs Curator), or enabling chain-of-thought vs “non-thinking” modes, are not studied.
- Retrieval and selection mechanics for bullets are under-specified: the exact ranking function, top-k selection strategy, gating rules, and how the Generator identifies “useful/misleading” bullets are not detailed or evaluated.
- De-duplication design is vague: the embedding model choice, similarity thresholds, false merge/false duplicate rates, and domain-specific impact on dedup errors are not specified or analyzed.
- Conflict resolution among bullets is not addressed: how contradictory or outdated entries are detected, reconciled, or versioned remains unclear.
- Bullet lifecycle policies lack detail: criteria for promotion/demotion, aging/decay, pruning, and harmfulness counters (thresholds, cooldowns) are not defined or empirically validated.
- Grow-and-refine trade-offs are unquantified: proactive vs lazy refinement impacts on accuracy, latency, and memory size are not measured across regimes or domains.
- Long-context scalability and retrieval cost are not characterized: no curves for performance vs context size, retrieval latency vs bullet count, or memory growth dynamics over long horizons.
- No formal guarantees against “context collapse”: ACE’s prevention of collapse is argued empirically; stability, convergence, and monotonicity properties are not theoretically analyzed.
- Robustness to noisy or adversarial feedback is limited: when ground-truth or reliable execution signals are absent, performance degrades; mechanisms for detecting/mitigating memory poisoning, spurious signals, or adversarial traces are not proposed or tested.
- Security and attack resilience are unaddressed: risks from prompt injection, tool output manipulation, or malicious environment traces (e.g., API misuse) are not evaluated.
- Privacy and compliance considerations are missing: policies for handling sensitive or regulated data in contexts (redaction, anonymization, audit logs, consent) are not described or measured.
- Evaluation protocol raises leakage concerns: online adaptation occurs sequentially on the test split; potential optimism or overfitting to the test distribution is not discussed or controlled (e.g., held-out online streams).
- Statistical rigor is limited: no confidence intervals, significance tests, or robustness across seeds are reported for the main results and ablations.
- Metric alignment for finance tasks is questionable: FiNER typically uses token-level F1; the use of accuracy may misrepresent performance—alternative metrics and error analyses are not provided.
- Baseline coverage is incomplete: comparisons omit recent adaptive memory systems (e.g., A-MEM, Agent Workflow Memory), RL-based methods (e.g., GRPO variants), and strong RAG pipelines or program-of-thought approaches.
- Agent backbone dependence is unclear: results are tied to ReAct; portability to other agent frameworks (plan-and-execute, toolformer-style, hierarchical planners) is untested.
- Serving-layer assumptions lack empirical validation: claims about KV-cache reuse/compression reducing long-context cost are not backed by throughput/memory benchmarks across hardware and model sizes.
- Parallel merging and concurrency are not evaluated: consistency under asynchronous updates, race conditions, and distributed deployment (multi-agents sharing/updating contexts) remain open.
- Human-in-the-loop curation is not integrated: when and how to involve domain experts, cost-benefit trade-offs, and workflows for manual review or corrective editing are not explored.
- Hyperparameter sensitivity is unexplored: effects of reflector refinement rounds (set to 5), number of epochs, delta size, batch size, dedup threshold, and retrieval hyperparameters are not studied.
- Catastrophic interference and generalization across tasks are unmeasured: how contexts learned for one task affect others (positive transfer vs interference), and strategies for task-scoped or modular playbooks are not investigated.
- Label-free adaptation remains fragile in finance: alternative signal sources (self-consistency, numerical verifiers, confidence calibration) for supervising updates without GT labels are not proposed or benchmarked.
- Adaptation granularity is fixed at batch size = 1: impacts of larger batches, prioritization policies (e.g., hardest-first, uncertainty-based), and active selection are not analyzed.
- Cost analysis lacks normalization: latency and dollar costs are reported without hardware/serving configuration details, provider pricing variability, or sensitivity to context size and traffic patterns.
- Long-horizon behavior is uncharacterized: performance and memory growth over hundreds/thousands of adaptation steps, saturation/plateau effects, and maintenance overhead are not documented.
- Offline-to-online transfer is only partially explored: the generality of “offline warmup” benefits across domains/tasks, and principled schedules for alternating offline/online phases are not established.
- Reuse and portability of contexts are untested: how playbooks transfer across related organizations, environments, or versions (tool/API changes), including versioning and compatibility, is not examined.
- Multi-modal and structured artifacts in bullets are not addressed: handling of code, JSON, tables, and schema-aware retrieval/tokenization is unspecified and unevaluated.
- Integration with RAG is open: combining ACE’s evolving playbooks with retrieval of external documents (routing, fusion, conflict handling) remains unexplored.
- Safety/ethics of accumulated artifacts are not considered: licensing of code snippets, copyrighted content, and responsible use policies for shared contexts are not discussed.
Glossary
- ACE (Agentic Context Engineering): A framework that treats LLM contexts as evolving playbooks, accumulating and organizing strategies through generation, reflection, and curation. "We present ACE (Agentic Context Engineering), a framework for scalable and efficient context adaptation in both offline ( system prompt optimization) and online ( test-time memory adaptation) scenarios."
- agentic architecture: A system design where specialized roles (e.g., Generator, Reflector, Curator) collaborate to adapt and improve contexts. "ACE adopts an agentic architecture with three specialized components: a Generator, a Reflector, and a Curator."
- AppWorld: A benchmark suite for autonomous LLM agents with tasks involving APIs, code generation, and environment interaction. "AppWorld~\citep{trivedi2024appworld} is a suite of autonomous agent tasks involving API understanding, code generation, and environment interaction."
- bayesian optimization: A sample-efficient optimization strategy used to tune prompts and demonstrations by modeling performance and selecting promising configurations. "MIPROv2 is a popular prompt optimizer for LLM applications that works by jointly optimizing system instructions and in-context demonstrations via bayesian optimization."
- brevity bias: The tendency of prompt optimization to collapse toward short, generic instructions, omitting domain-specific details. "A recurring limitation of context adaptation methods is brevity bias: the tendency of optimization to collapse toward short, generic prompts."
- context adaptation: Improving LLM behavior by constructing or modifying inputs (contexts) rather than changing model weights. "Context adaptation (or context engineering) refers to methods that improve model behavior by constructing or modifying inputs to an LLM, rather than altering its weights."
- Context collapse: A failure mode where iterative rewriting compresses accumulated context into shorter, less informative summaries, eroding performance. "we observe a phenomenon we call context collapse, which arises when an LLM is tasked with fully rewriting the accumulated context at each adaptation step."
- context-efficient inference: Serving techniques that reduce cost and latency when using long prompts, e.g., KV cache reuse. "context-efficient inference such as KV cache reuse~\citep{gim2024prompt, yao2025cacheblend} are making context-based approaches increasingly practical for deployment."
- Curator: The ACE role that integrates extracted lessons into structured updates and merges them into the context. "The Curator then synthesizes these lessons into compact delta entries, which are merged deterministically into the existing context by lightweight, non-LLM logic."
- delta context: A compact set of localized context updates (bullets) produced incrementally instead of full prompt rewrites. "ACE incrementally produces compact delta contexts: small sets of candidate bullets distilled by the Reflector and integrated by the Curator."
- Dynamic Cheatsheet: A test-time learning method that accumulates strategies in adaptive external memory to improve LLM performance. "Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks..."
- execution traces: Recorded details of model reasoning, tool calls, and intermediate outputs used to diagnose errors and refine prompts. "It collects execution traces (reasoning, tool calls, intermediate outputs) and applies natural-language reflection to diagnose errors, assign credit, and propose prompt updates."
- FiNER: A financial analysis benchmark requiring fine-grained entity labeling in XBRL documents. "FiNER requires labeling tokens in XBRL financial documents with one of 139 fine-grained entity types, a key step for financial information extraction in regulated domains."
- Formula: A financial reasoning benchmark focusing on extracting values from XBRL filings and computing answers to queries. "Formula focuses on extracting values from structured XBRL filings and performing computations to answer financial queries"
- Generator: The ACE role that produces reasoning trajectories for queries, surfacing strategies and pitfalls. "the workflow begins with the Generator producing reasoning trajectories for new queries"
- GEPA (Genetic-Pareto): A reflective prompt evolution method that uses genetic Pareto search over prompts informed by execution feedback. "GEPA (Genetic-Pareto) is a sample-efficient prompt optimizer based on reflective prompt evolution."
- In-Context Learning (ICL): Supplying demonstrations within the prompt so the model infers task format and outputs without weight updates. "In-Context Learning (ICL) provides the model with task demonstrations in the input prompt (few-shot or many-shot)."
- KV cache reuse: Reusing previously computed key-value attention states to reduce inference cost with long contexts. "context-efficient inference such as KV cache reuse"
- long-context LLMs: Models capable of handling very long input sequences, enabling richer, detail-preserving contexts. "advances in long-context LLMs~\citep{peng2023yarn}"
- long-horizon: Refers to tasks or applications requiring sustained, scalable context growth and reasoning over extended sequences. "As contexts grow, this approach provides the scalability needed for long-horizon or domain-intensive applications."
- MIPROv2: A prompt optimization method that jointly tunes system instructions and demonstrations using Bayesian optimization. "MIPROv2 is a popular prompt optimizer for LLM applications that works by jointly optimizing system instructions and in-context demonstrations via bayesian optimization."
- monolithic rewriting: Replacing the entire context with a single rewrite, which can cause collapse and information loss. "Monolithic rewriting of context by an LLM can collapse it into shorter, less informative summaries, leading to sharp performance drops."
- multi-epoch adaptation: Revisiting queries across multiple epochs to progressively strengthen and refine the context. "ACE further supports multi-epoch adaptation, where the same queries are revisited to progressively strengthen the context."
- non-LLM logic: Deterministic, lightweight merging and deduplication steps performed without invoking an LLM. "merged deterministically into the existing context by lightweight, non-LLM logic."
- pass@1 accuracy: The proportion of exact-match answers on the first attempt, used for evaluation. "evaluated on the test split with pass@1 accuracy."
- ReAct: An agent prompting framework combining reasoning and action with tool use to solve tasks. "we follow the official ReAct~\citep{yao2023react} implementation released by the benchmark authors"
- Reflector: The ACE role that critiques reasoning traces to extract lessons and propose refinements. "The Reflector critiques these traces to extract lessons, optionally refining them across multiple iterations."
- Scenario Goal Completion (SGC): An AppWorld metric measuring completion of scenario-level goals. "report Task Goal Completion (TGC) and Scenario Goal Completion (SGC) on both the test-normal and test-challenge splits."
- semantic embeddings: Vector representations used to compare and de-duplicate bullets semantically. "A de-duplication step then prunes redundancy by comparing bullets via semantic embeddings."
- system prompt optimization: Offline process of refining the base instructions that guide downstream tasks. "offline ( system prompt optimization)"
- Task Goal Completion (TGC): An AppWorld metric measuring completion of task-level goals. "report Task Goal Completion (TGC) and Scenario Goal Completion (SGC) on both the test-normal and test-challenge splits."
- test-time memory adaptation: Online process where the context (memory) is updated after each sample during inference. "online ( test-time memory adaptation)"
- XBRL (eXtensible Business Reporting Language): A standardized language for structured financial reporting used in benchmarks. "rely on the eXtensible Business Reporting Language (XBRL)."
Practical Applications
Overview
This paper introduces ACE (Agentic Context Engineering), a framework that treats prompts, instructions, and retrieved evidence as evolving, structured “playbooks.” ACE uses three roles—Generator, Reflector, Curator—and two core mechanisms—incremental delta updates and grow-and-refine—to prevent brevity bias and context collapse while enabling both offline (system prompt) and online (agent memory) adaptation. It delivers higher accuracy and lower latency/cost across agentic and domain-specific tasks, often without labeled supervision by leveraging execution feedback.
Below are concrete, real-world applications derived from the paper’s findings and methods, grouped by deployment horizon. Each item includes sector links, potential tools/workflows/products, and assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed now with current long-context LLMs and standard serving stacks.
- Agent performance tuning for API and software agents
- Sector: Software/DevTools; Automation
- What: Use ACE to build an evolving agent playbook that captures tool-use patterns, API quirks, and recurring failure modes for agents built on ReAct- or toolformer-style workflows.
- Tools/Workflows: ACE SDK (Generator/Reflector/Curator services), Delta Context API, Curator Merge Engine, Grow-and-Refine Scheduler, KV cache reuse.
- Dependencies: Long-context LLMs; actionable execution feedback (e.g., tool call success/failure, code run results); access to agent traces; basic embedding infra for de-duplication.
- Enterprise customer support copilots with adaptive knowledge
- Sector: Customer Support; CX Platforms
- What: Turn conversation logs into curated bullets (known intents, escalation triggers, policy responses, disallowed claims) to continuously refine bot behavior without retraining.
- Tools/Workflows: Context Memory Store (with per-intent bullets), Feedback Adapters for CRM/chat logs, Human-in-the-loop curation UI, Prompt CMS for versioning and rollback.
- Dependencies: Data governance/PII redaction; human review gates; stable routing to tools/KB; preference for cost-efficient long-context serving.
- Financial document extraction and reasoning assistants
- Sector: Finance/FinTech; RegTech
- What: Build XBRL- and filing-specific playbooks covering entity types, formula patterns, and edge cases; use execution checks (calculators, rule validators) as feedback to refine bullets.
- Tools/Workflows: Finance Playbook Templates, Validator Hooks (spreadsheet/extractor checks), Offline warmup on training filings, Online refinement during analyst use.
- Dependencies: Access to filings and schema updates; reliable validators or labeled splits; compliance/audit logging.
- RAG/Agent stack optimization via ContextOps
- Sector: Enterprise Software; Data Platforms
- What: Replace monolithic prompt rewrites with delta updates; manage retrieval prompts, routing rules, and tool schemas as bullets; prune redundancies over time.
- Tools/Workflows: ContextOps pipeline (delta merges, semantic de-dup), Prompt Caching with KV reuse, Observability dashboards for accuracy/cost/latency.
- Dependencies: Serving infra that supports KV cache reuse; embedding service; telemetry to attribute gains to context changes.
- Incident response runbooks and SRE playbooks that self-improve
- Sector: IT/Ops; SRE
- What: Convert postmortems and on-call notes into structured bullets (signatures, mitigations, “gotchas”) that get updated after every incident or drill.
- Tools/Workflows: Incident Feedback Adapter (from tickets/logs), Curator rules for severity-based prioritization, Runbook Retriever integrated in chat/CLI.
- Dependencies: High-quality incident metadata; change control and approvals; access control by team/product.
- Continuous prompt/memory tuning for software QA (test generation and triage)
- Sector: Software QA; DevOps
- What: Reflect over failing tests and flaky patterns to add bullets that constrain generation and improve coverage; ingest CI results as execution feedback.
- Tools/Workflows: CI Feedback Adapter (test outcomes, coverage), Sandboxed execution for verification, “Failure pattern” bullet types with counters.
- Dependencies: Deterministic test oracles; sandbox infra; repository access; policy to avoid test leakage on public models.
- Sales and marketing assistants with brand-safe evolving contexts
- Sector: GTM; Marketing
- What: Maintain bullets for tone, style, claims substantiation, and region-specific compliance; refine based on approval outcomes and campaign analytics.
- Tools/Workflows: Brand Policy Bullets, Approval Feedback Adapter, A/B Context Gates, Context versioning per campaign/segment.
- Dependencies: Human approvals; compliance and brand governance; content moderation.
- Course- and cohort-specific tutors that learn from homework cycles
- Sector: Education/EdTech
- What: Build playbooks of problem-solving tactics, common misconceptions, and course-specific notation; refine based on solution checking and instructor feedback.
- Tools/Workflows: Offline warmup with historical assignments, On-policy online adaptation per cohort, Misconception bullets with counters, Safety rails against over-helping.
- Dependencies: Access to problem sets/solutions; academic integrity controls; reliable graders or auto-checkers.
- Public sector assistants for forms and benefits navigation
- Sector: Government/Policy; Civic Tech
- What: Evolve contexts with updated eligibility rules, document requirements, and regional exceptions using delta updates as policies change.
- Tools/Workflows: Policy Diff Adapter (watchdogs over official bulletins), Audit-ready Context Ledger, Role-based retrieval (case worker vs. citizen).
- Dependencies: Timely access to authoritative policy updates; privacy and security; auditability and version control.
- Cost- and latency-optimized agent deployment
- Sector: MLOps; Platform Engineering
- What: Adopt incremental updates and non-LLM merging to cut adaptation rollouts, latency, and token spend for production agents without sacrificing accuracy.
- Tools/Workflows: Batch delta generation, Parallel merges, KV cache priming, Cost/latency observability tied to context versions.
- Dependencies: Integration with existing serving/routing; capacity planning for long contexts; SLO-aware adaptation schedules.
Long-Term Applications
These require further research, scaling, policy clarity, or infrastructure maturity before broad deployment.
- Safety-critical assistants in healthcare and law with certified evolving playbooks
- Sector: Healthcare; Legal
- What: Encode validated heuristics, contraindications, and jurisdiction-specific rules; self-improve from verified outcomes and expert review.
- Tools/Workflows: Expert-in-the-loop Reflector panels, Clinical/Legal Validator Hooks, Adverse event feedback integration, “Certified bullet” status and provenance.
- Dependencies: Regulatory approvals, gold-standard validators, rigorous audit trails, liability framework.
- Standardized “context artifact” format and marketplaces
- Sector: AI Tooling; Ecosystem
- What: Portable, model-agnostic playbooks (akin to packages) for domains; marketplaces for licensing, rating, and updating community-maintained contexts.
- Tools/Workflows: Open context schema (IDs, counters, provenance), Signing and trust scores, Compatibility checks across model families.
- Dependencies: Interoperability standards, IP/licensing models, governance for quality and safety.
- Organizational ContextOps: CI/CD for contexts
- Sector: MLOps; Enterprise IT
- What: Treat contexts like code—versioning, review, testing, canarying, rollback; AB testing of context variants; policy guardrails.
- Tools/Workflows: Context CI pipelines, Unit/integration tests for prompts, Drift detectors, Release checklists.
- Dependencies: Culture and process adoption, tooling integration with existing DevOps, reliable evaluation harnesses.
- Selective unlearning and dynamic compliance
- Sector: Privacy/Compliance; Governance
- What: Remove or downweight bullets containing personal data or deprecated policies; encode evolving legal mandates (GDPR/CCPA) as high-priority bullets.
- Tools/Workflows: PII scanners and retention policies, Unlearning API for context stores, Compliance audit dashboards.
- Dependencies: Robust PII detection, legal review workflows, alignment with retention/deletion requirements.
- Multi-agent shared memory with access control
- Sector: Enterprise Collaboration; Knowledge Management
- What: Teams of agents share a partitioned, role-based context; resolve conflicts and redundancies across departments and tasks.
- Tools/Workflows: Namespaced bullet stores, Conflict resolution policies, Cross-agent feedback routers.
- Dependencies: Fine-grained access control, identity/permissions, organizational buy-in.
- Robotics and edge adaptation with on-device playbooks
- Sector: Robotics; IoT/Edge
- What: Robots/edge agents learn environment- and device-specific heuristics as bullets; refine via sensor/effectuator feedback loops.
- Tools/Workflows: Lightweight on-device Curator, Periodic cloud sync for grow-and-refine, Safety interlocks.
- Dependencies: Efficient long-context models on edge, robust local validators, strict safety envelopes.
- Weak-signal learning and self-verification at scale
- Sector: Applied AI Research; Platform
- What: Develop robust reflectors that can learn from noisy proxies (heuristics, simulations, consistency checks) when labels/execution signals are scarce.
- Tools/Workflows: Ensembled verifiers, Simulation-in-the-loop feedback, Consistency-based reflection.
- Dependencies: Strong verifiers or ensembles, calibrated uncertainty, scalable simulation environments.
- Knowledge-to-weights distillation (prompt-to-parameter transfer)
- Sector: Model Training; Optimization
- What: Periodically distill mature contexts into adapter weights (e.g., LoRA) to compress latency/cost while keeping the context as a safety net.
- Tools/Workflows: Distillation pipelines from context-conditioned traces, Hybrid serving (weights + minimal context), Regression tests.
- Dependencies: Compute budgets, reliable teacher signals, IP considerations for embedded knowledge.
- Regulator-reviewed playbooks and certification pathways
- Sector: Policy/Governance
- What: Define certification criteria for domain playbooks (coverage, error bounds, provenance) that underpin regulated AI services.
- Tools/Workflows: Standard evaluation suites, Provenance tracking, Third-party audits.
- Dependencies: Standards bodies’ engagement, shared benchmarks, legal frameworks for certification.
- Benchmarks and reproducibility for dynamic adaptation
- Sector: Academia; Open Science
- What: Establish community benchmarks for online adaptation, context collapse prevention, and cost/latency trade-offs with shared logs and seeds.
- Tools/Workflows: Open datasets with execution traces, Leaderboards separating offline/online settings, Standardized metrics for collapse and brevity bias.
- Dependencies: Data sharing agreements, privacy safeguards, sustained maintainer support.
Notes on cross-cutting assumptions from the paper:
- High-quality feedback is pivotal. ACE thrives on reliable execution signals (e.g., code run success/failure, validator checks). In low-signal settings, both ACE and similar adaptive methods can degrade.
- Long-context serving overhead is mitigated but not zero. Gains depend on KV cache reuse, compression, and caching infrastructure being in place.
- Human-in-the-loop curation improves safety in sensitive domains. Expert review, approvals, and governance are necessary for healthcare, legal, and public sector deployments.
- Base model competence matters. The paper holds Generator/Reflector/Curator to the same model for fairness; stronger specialized reflectors/curators may further improve results but change cost/architecture trade-offs.
Collections
Sign up for free to add this paper to one or more collections.