CompLLM: Compression for Long Context Q&A
Abstract: LLMs face significant computational challenges when processing long contexts due to the quadratic complexity of self-attention. While soft context compression methods, which map input text to smaller latent representations, have shown promise, their real-world adoption is limited. Existing techniques typically compress the context as a single unit, which leads to quadratic compression complexity and an inability to reuse computations across queries with overlapping contexts. In this work, we introduce CompLLM, a soft compression technique designed for practical deployment. Instead of processing the context holistically, CompLLM divides it into segments and compresses each one independently. This simple design choice yields three critical properties: efficiency, as the compression step scales linearly with the context length; scalability, enabling models trained on short sequences (e.g., 1k tokens) to generalize to contexts of 100k tokens; and reusability, allowing compressed segments to be cached and reused across different queries. Our experiments show that with a 2x compression rate, at high context lengths CompLLM speeds up Time To First Token (TTFT) by up to 4x and reduces the KV cache size by 50%. Furthermore, CompLLM achieves performance comparable to that obtained with the uncompressed context, and even surpasses it on very long sequences, demonstrating its effectiveness and practical utility.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Explanation of “CompLLM: Compression for Long Context Q&A”
What is this paper about?
This paper introduces a tool called CompLLM that helps LLMs read very long documents faster and with less computer memory. It does this by “compressing” the long text into a smaller form that the model can still use to answer questions accurately.
Think of it like turning a giant textbook into a set of compact, super-informative index cards the model can read much more quickly.
What questions does the paper try to answer?
The authors focus on three big, practical goals:
- How can we make LLMs process long texts faster?
- How can we do this without losing answer quality?
- How can we reuse work we’ve already done, so we don’t have to recompress the same text over and over?
How does CompLLM work? (In simple terms)
LLMs slow down a lot as text gets longer because their “attention” system compares many parts of the text with many other parts. That can get extremely expensive when the text is very long.
CompLLM speeds things up using three ideas:
- Split and compress in pieces
- Instead of compressing the whole document at once, CompLLM splits the text into short segments (like sentences) and compresses each segment on its own.
- This makes the compression step scale roughly linearly with document length (double the text ≈ double the work), which is much better than the usual “quadratic” cost (double the text ≈ four times the work).
- Turn words into fewer, smarter “concept embeddings”
- Normally, an LLM reads “tokens” (pieces of words) turned into numbers called token embeddings.
- CompLLM learns to convert every small chunk (for example, 20 tokens) into a smaller number of “concept embeddings” (for example, 10).
- You can think of concept embeddings as compact, information-rich summaries that the LLM can read directly, just like real tokens.
- Reuse compressed pieces
- Because each segment is compressed independently, if you use the same paragraph again later (like in a different question or in a different document set), you don’t need to recompress it. You can cache (store) and reuse it.
How it learns (without getting too technical):
- The compressor is trained to make the LLM’s “inner thoughts” (its hidden activations) look the same whether the model reads the original full text or the compressed version—at least for the part needed to answer the question.
- The question itself is not compressed (it’s short and arrives live); only the long context is compressed (often available ahead of time).
- No special changes to the LLM are needed. The LLM stays the same; the compressor is a small add-on.
Key terms in everyday language:
- Token: a small piece of text (like part of a word).
- Embedding: a numeric fingerprint of a token or concept that the model understands.
- KV cache: the model’s short-term memory during reading; making it smaller saves a lot of memory.
- Quadratic cost: if you double the length, the cost becomes about four times bigger. Linear cost: double the length, about double the cost.
What did they test and what did they find?
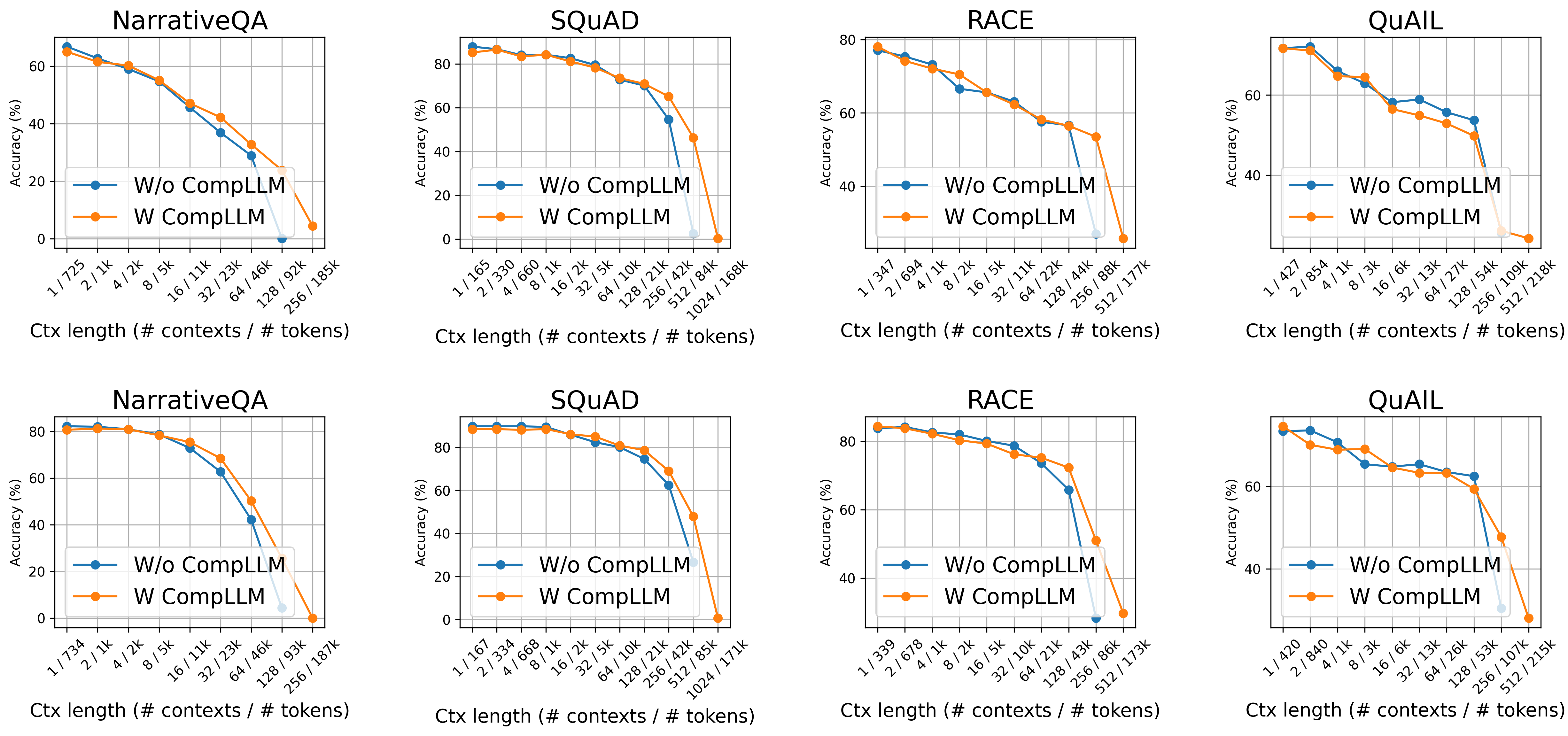
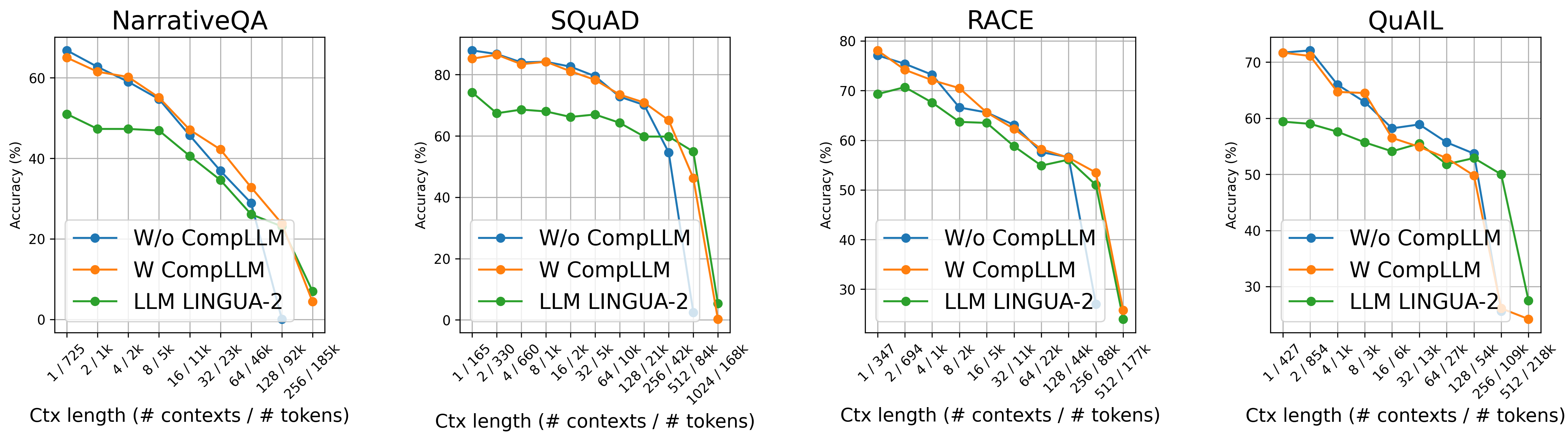
They tried CompLLM with two open LLMs (Gemma3-4B and Qwen3-4B) on several question-answering tasks with long contexts (like NarrativeQA, SQuAD, RACE, QuAIL) and on a long-context benchmark called LOFT (128k-token contexts).
They mainly used a 2× compression rate (cut the number of input embeddings in half). Here are the main results:
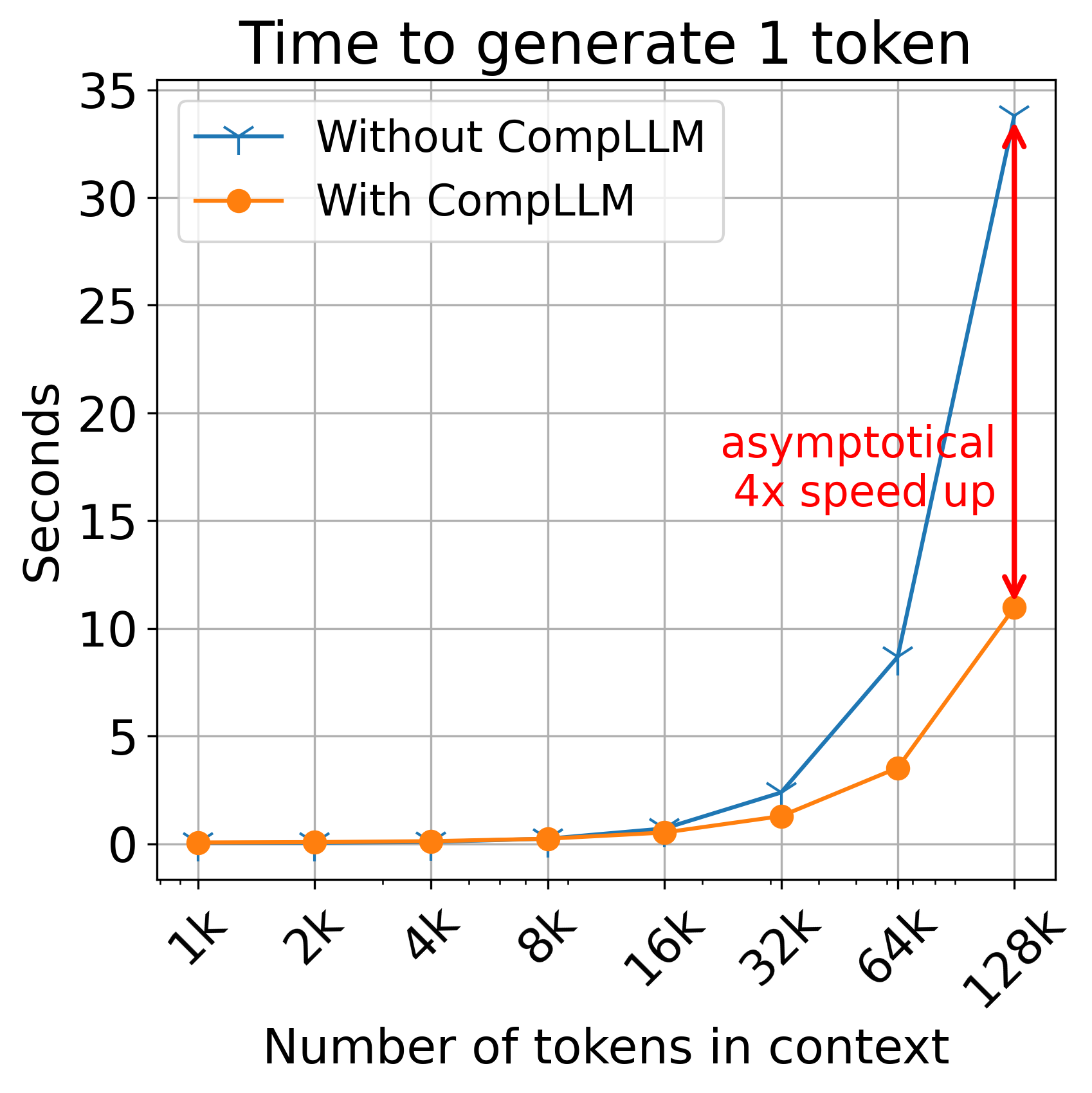
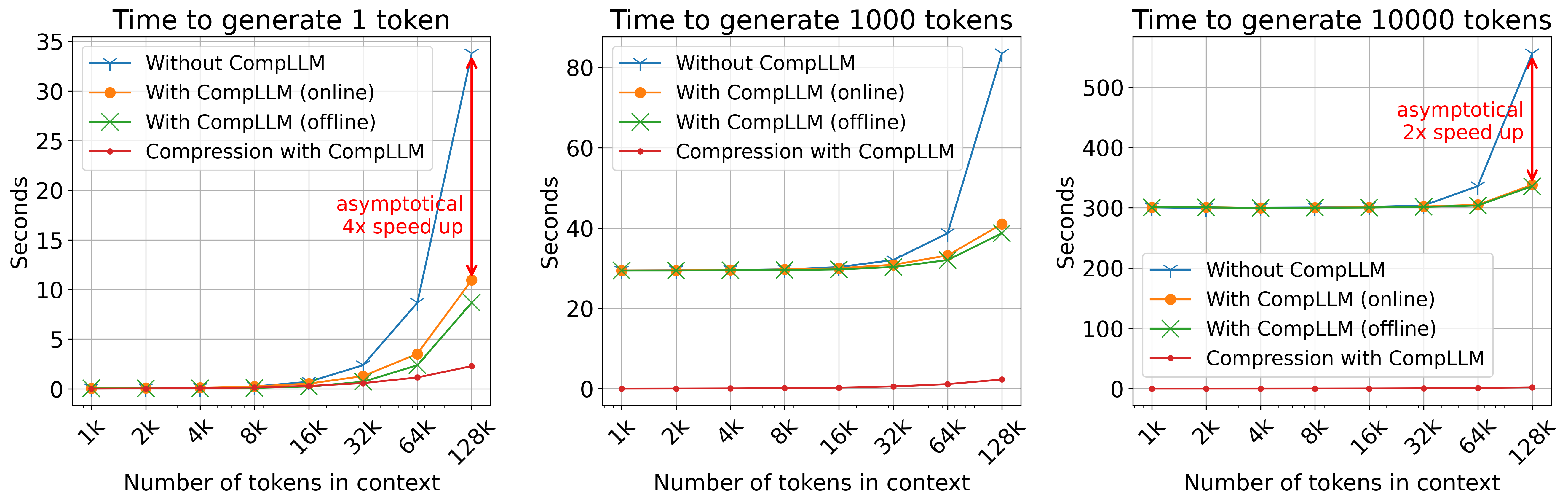
- Faster start time: Time To First Token (TTFT) was up to 4× faster on long inputs.
- Less memory: KV cache size was cut by about 50%.
- Similar or better answers: Quality stayed about the same for short contexts—and often got better for very long contexts.
- Why better? With fewer, more meaningful embeddings, the model’s attention isn’t “diluted” by tons of extra tokens.
- Works at huge lengths: Even though they trained on relatively short inputs (like ~1–2k tokens), the system worked well on contexts as long as 100k+ tokens.
- Reusable compression: Compressed segments can be stored and reused across questions and tasks (super helpful for things like RAG systems and coding assistants).
They also compared to a popular “hard” compression method (LLMLingua-2) and found CompLLM competitive or better at many context lengths, while keeping the same speed/memory advantages.
Why does this matter?
- It makes LLMs more practical for real-world tasks that involve huge amounts of text, like:
- Reading large codebases for coding assistants
- Answering questions about long research papers or legal documents
- Web agents processing long web pages
- RAG systems that fetch lots of documents
- It reduces costs: faster responses and lower memory use mean less compute time and energy.
- It’s easy to plug in: no changes to the LLM’s core are required, and you can turn it off for short texts where compression isn’t worth it.
Any limitations?
- CompLLM focuses on meaning, not exact character-level details. It’s not ideal for tasks like counting letters, spotting typos, or anything that needs exact text shape.
- But you can always skip compression for those special cases.
What could come next?
The authors suggest:
- Adapting the compression rate to the input (hard parts get less compression, easy parts more).
- Trying different compressor designs and larger models.
- Training with plain text at massive scale.
- Applying it to code, where reusing compressed files could be very powerful.
Bottom line
CompLLM is a practical way to make LLMs handle very long texts faster and cheaper while keeping answer quality high. By compressing text segment-by-segment into smart “concept embeddings,” it speeds up the most expensive parts of processing, saves memory, scales to huge contexts, and lets you reuse work you’ve already done. It’s a promising step toward more efficient, real-world LLM applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper that future researchers could address.
- Generalization across model scales and architectures: results are reported only for Gemma3-4B and Qwen3-4B; it is unclear how CompLLM behaves with larger (e.g., 7B–70B), smaller (sub-1B), multimodal, or long-context-tuned models, and with different attention types (e.g., sliding-window, Mamba, or hybrid).
- Tokenizer and language coverage: segmentation and training are English-centric (NLTK Punkt, English datasets); the impact on multilingual tokenizers, non-Latin scripts, agglutinative languages, and code/mathematical tokenizers is not evaluated.
- Segment size and segmentation strategy: only S=20 and sentence-based segmentation are used; there is no ablation on segment length, segmentation heuristics (token-based vs sentence vs semantic), or dynamic segmentation decisions, nor their effect on cross-sentence dependencies.
- Cross-segment dependencies: compressing segments independently may weaken global coherence (e.g., coreference, discourse relations, long-range logic); the paper lacks quantitative tests on tasks requiring global reasoning across distant segments.
- Positional encoding treatment: the method does not describe how positions are assigned to CEs, how positional signals are aggregated within segments, or how relative/rotary encodings are preserved after compression; the impact on order-sensitive tasks remains unknown.
- Fixed compression rate (C=2) only: the trade-offs between accuracy, speed, and memory for different C values are not characterized; scaling laws with model size, embedding dimensionality, and sequence length are absent.
- Training objective design: distillation matches hidden states only on answer tokens across layers; no ablation studies on layer weighting, matching on question/context tokens, alternative objectives (e.g., KL on logits, contrastive alignment), or joint losses are reported.
- Teacher-generated answers as supervision: training uses model-generated answers rather than ground truth, which can propagate teacher errors and biases; the sensitivity of CompLLM to noisy labels is unassessed.
- Domain generalization: evaluations focus on narrative QA, SQuAD, RACE, QuAIL, and LOFT; tasks like coding, math reasoning, tabular QA, HTML reasoning, scientific QA, and structured data are not covered.
- Faithfulness and hallucination: claims of improved quality due to reduced attention dilution are not backed by fidelity metrics (e.g., factual consistency, attribution) or error-type analyses; the impact on hallucination rates is unknown.
- Safety and robustness: feeding “unseen” continuous embeddings directly to the LLM could introduce distribution shifts or adversarial surfaces; there is no robustness analysis (e.g., adversarial CEs, perturbations, toxic content resilience).
- Interoperability with inference optimizations: interactions with paged attention, speculative decoding, flash attention variants, vLLM, continuous batching, or caching strategies are not empirically studied.
- Hardware and deployment variability: speedups are shown on a single B200 GPU; performance across diverse hardware (consumer GPUs, TPUs, CPUs), quantization levels, and batch sizes is not characterized.
- End-to-end latency accounting: the compressor’s wall-clock overhead, memory footprint, and scheduling in real pipelines (including offline/online compression) lack a detailed cost model and break-even analysis.
- CE caching and reusability mechanics: the storage format, versioning, invalidation when base LLM or LoRA changes, retrieval/indexing costs, and memory trade-offs for large repositories of precomputed CEs are unspecified.
- Mixed embeddings compatibility: the pipeline mixes CEs (context) with TEs (question), but potential distribution mismatches, calibration issues, or attention biases from mixing representations are not analyzed.
- Impact on KV cache dynamics: while KV cache is reduced by ~2× for context, the net memory impact including compressor runtime, CE storage, and question tokens is not fully quantified; layer-wise KV behavior with CEs is not examined.
- Long-output regimes: complexity analysis assumes N >> T; empirical evaluation for very long generation (e.g., T ≥ N) and multi-turn dialogues/conversations with history compression is limited.
- Applicability beyond QA: the approach is not tested on summarization, translation, retrieval-augmented generation with dynamic retrieval, tool use, or agentic long-horizon tasks.
- Comparative baselines: a thorough head-to-head against leading soft compressors (e.g., ICAE, InContextFormer, KV-distillation methods) under matched deployment constraints is missing; only LLMLingua-2 is compared.
- Evaluation rigor: open-ended results rely on LLM-as-a-judge without human validation, confidence intervals, statistical significance, or error bars; reproducibility details (seeds, variance across runs) are limited.
- CE interpretability and stability: there is no probing of what CEs encode, their stability across runs/datasets, or whether CEs are transferable across LLMs or tasks; mechanisms for auditing compressed content are absent.
- EOS-token trick design: using appended EOS token outputs as CE sources may be brittle; alternative designs (learned concept tokens, encoder-only compressors, pooling mechanisms) are not compared.
- Structured/format-sensitive tasks: the limitation section notes poor performance on non-semantic tasks (typos, counting), but the boundary conditions (e.g., exact string matching, numeric tables, code diffs) are not quantified.
- RAG pipeline integration: how CE reusability fits with retrieval indices, deduplication, chunking policies, and ranking is not detailed; whether CEs themselves can serve retrieval or re-ranking is unexplored.
- Question compression: questions are left uncompressed by design; scenarios with long or multi-part queries (e.g., agentic chains, complex instructions) are not considered.
- API and platform support: most closed LLM APIs do not accept custom continuous embeddings; practical paths to adoption (server modifications, standardized CE interfaces) are not addressed.
- Data segmentation robustness: sentence segmentation with Punkt is brittle for noisy text, code, HTML, or multilingual content; the impact of segmentation errors on CE quality and downstream accuracy is unknown.
- Energy consumption: the paper claims potential energy/FLOPs reductions but provides no measurements of power, throughput-per-watt, or carbon impact.
- Theoretical guarantees: there are no formal bounds on information preservation, cross-segment dependency loss, or worst-case degradation under segment-wise compression.
- Continual and incremental updates: how to incrementally compress updated documents/codebases and maintain CE caches without full recompute is not formalized.
- Model tuning vs frozen LLM: the generator LLM remains frozen; whether modest fine-tuning of the LLM to better accept CEs improves performance or robustness is not investigated.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging CompLLM’s segment-wise soft compression, linear-time compression, and reusable caches to improve latency and memory use without modifying the base LLM.
- Long-context Retrieval-Augmented Generation (RAG) with reusable compressed document stores
- Sectors: software, enterprise search, customer support, legal, finance, healthcare, education
- What: Pre-compress document repositories into concept embeddings (CEs), cache by segment, and serve queries by retrieving CEs instead of raw tokens. Achieves up to 4x TTFT speedup and ~2x KV cache reduction at long contexts.
- Tools/workflows: CE preprocessor service, CE cache/key–value store indexed by segment hashes, retrieval pipeline that assembles CE segments + uncompressed question, fallback to uncompressed for short prompts, vLLM/paged-attention compatible inference.
- Assumptions/dependencies: Access to an open-source base LLM (e.g., Gemma3/Qwen) that accepts CEs; compressor trained for the target LLM; tasks primarily semantic (not exact formatting/character-level); documents available for offline compression.
- Large codebase assistants with incremental CE caching
- Sectors: software engineering, DevOps
- What: Compress source files per segment, cache CEs, and update only modified segments on file changes. Reuse CEs across refactors, tests, and multi-file queries to reduce TTFT and GPU memory.
- Tools/workflows: IDE plugin + background CE compressor, git hook for incremental recompression, CE cache keyed by file path + segment hash, retrieval layer that selects relevant CE segments.
- Assumptions/dependencies: Domain adaptation may be required for optimal code semantics; fallback to uncompressed mode for exact token-level tasks (e.g., syntax/format checks).
- Web agents and crawlers that handle long HTML pages
- Sectors: software, robotics (web automation)
- What: Compress webpage segments (DOM sections) into CEs for reasoning and reuse across sessions/agents. Enables faster first-token responses and reduced memory footprint for complex pages.
- Tools/workflows: Headless browser + DOM-to-segment mapping, CE cache per URL/section, agent framework integration to assemble CEs + query.
- Assumptions/dependencies: HTML segmentation quality impacts CE fidelity; tasks should be semantic rather than pixel/character-level.
- Enterprise knowledge base Q&A and internal search
- Sectors: enterprise software, HR, compliance, operations
- What: Pre-compress manuals, policies, and wikis to serve employee queries with lower latency and VRAM usage. Reuse CE segments across repeated queries and multi-document comparisons.
- Tools/workflows: CE indexing pipeline, permission-aware CE stores, retrieval policies (CE + question), live metrics for TTFT and cache usage.
- Assumptions/dependencies: Proper access control at segment level; compressor alignment to the organization’s LLM stack.
- Legal e-discovery and document review
- Sectors: legal
- What: Compress discovery corpora and case files to enable faster cross-referencing and long-context reasoning while reducing infrastructure costs.
- Tools/workflows: Document segmentation policies (by paragraph/section), CE cache per matter, comparison workflows that reuse CEs for recurring documents.
- Assumptions/dependencies: Semantic focus; fallback to uncompressed mode for exact citations/format-sensitive tasks.
- Financial and market analysis over large filings
- Sectors: finance
- What: Compress 10-K/10-Q filings, earnings call transcripts, and research notes; enable faster multi-document Q&A and comparisons (e.g., company A vs. B vs. C) by reusing CE caches.
- Tools/workflows: CE pipeline integrated with filing ingestion, retrieval orchestration for multi-document analysis.
- Assumptions/dependencies: Emphasis on semantic understanding; exact numbers/tables may require hybrid workflows (structured extraction + CE-based reasoning).
- Healthcare knowledge retrieval from long clinical notes
- Sectors: healthcare
- What: Offline compression of longitudinal records and clinical notes to support provider queries with reduced latency and memory footprint.
- Tools/workflows: HIPAA-compliant CE caches, segment-level access controls, audit trails.
- Assumptions/dependencies: Clinical validation required; char-level tasks (e.g., exact medication string matching) may need non-compressed fallback.
- Education: course material Q&A and study aids
- Sectors: education
- What: Compress textbooks/lecture notes to enable students to query long materials on modest hardware with faster responses.
- Tools/workflows: CE cache per course, LMS integration, retrieval + reasoning over CEs with uncompressed questions.
- Assumptions/dependencies: Semantic comprehension prioritized; exact string/notation checks may need fallback.
- Inference cost and capacity optimization for LLM service providers
- Sectors: cloud/inference platforms, energy
- What: Integrate CompLLM in inference servers to reduce TTFT, KV cache memory, and FLOPs; increase concurrent session capacity per GPU.
- Tools/workflows: Microservice for CE compression (offline/online), autoscaling policies, instrumentation for TTFT and VRAM.
- Assumptions/dependencies: Works best with open-source LLMs or vendor stacks that accept custom embeddings; benefits grow with context length.
- Personal knowledge management (PKM) and note apps
- Sectors: consumer software
- What: Compress long personal documents, journals, and PDFs for local LLM Q&A with faster first-token responses on laptops.
- Tools/workflows: Desktop CE compressor, CE stores per notebook, hybrid retrieval (CEs + original text).
- Assumptions/dependencies: Local models required; exact text queries may need fallback.
Long-Term Applications
These applications require further research, scaling, or ecosystem development (e.g., higher compression rates, domain-specific training, standardized tooling).
- Adaptive compression rates and content-aware segmenting
- Sectors: software, AI tooling
- What: Dynamically adjust compression per sentence/segment (complex content gets lower C; simple/repetitive gets higher C) to optimize accuracy vs. speed/memory.
- Dependencies: New compressor training objectives, difficulty estimators, possibly RL or curriculum learning.
- High-rate compression for ultra-long contexts (C > 2) and “CE memory stores”
- Sectors: cloud platforms, enterprise
- What: Represent entire corpora (e.g., 100k+ tokens per query) via compact CE sequences; enable “always-on” long-context reasoning.
- Dependencies: Larger models or specialized compressors, domain-specific training, robust evaluation on LOFT-like benchmarks.
- Standardized CE formats and “CE databases” integrated into retrieval frameworks
- Sectors: software infrastructure
- What: Build CE-first stores akin to vector DBs, with APIs to fetch CE segments for direct feeding into LLMs.
- Dependencies: Community standards for CE serialization, indexing, compatibility across models.
- Cross-model and closed-model compatibility
- Sectors: AI platforms
- What: Compress once, run across different LLMs (including closed APIs) without re-training; or introduce vendor support for CE ingestion.
- Dependencies: Model-agnostic compressor research; API changes for closed models to accept non-token embeddings.
- Edge and mobile long-context apps
- Sectors: consumer/enterprise mobility
- What: On-device LLMs handling large contexts via CEs for field operations, offline study, and local analytics.
- Dependencies: Efficient compressor models on mobile hardware; energy-aware scheduling; domain adaptation.
- Multi-agent systems sharing CE caches
- Sectors: software, robotics
- What: Agents co-operate using shared CE representations of common corpora, reducing duplication and accelerating group reasoning.
- Dependencies: Synchronization protocols, CE cache coherence, privacy/permissions.
- Healthcare-grade validation and regulatory adoption
- Sectors: healthcare, policy
- What: Clinical-grade studies showing safety/effectiveness of compressed long-context reasoning (e.g., EHR summarization), leading to guideline inclusion.
- Dependencies: Clinical trials, bias/safety evaluations, interoperability with health IT standards.
- Sustainability and policy for green AI
- Sectors: energy, policy
- What: Adopt CompLLM-like compression in procurement and platform policies to reduce energy/FLOPs for long-context tasks at scale.
- Dependencies: Measurement frameworks for energy savings, standard reporting, stakeholder alignment.
- IDE-native code assistants with CE-first design
- Sectors: software engineering
- What: End-to-end workflows where code indexing, retrieval, and reasoning center on CE stores; instant re-use on refactors.
- Dependencies: Domain-specific compressor training, integration with build systems, robust fallback for exact syntax or formatting tasks.
- Multimodal extension (text + structure/tables/code/HTML)
- Sectors: software, data analytics
- What: Extend segment-wise compression to structured or multimodal inputs to improve retrieval and reasoning across formats.
- Dependencies: New architectures, alignment losses for each modality, careful evaluation to avoid losing critical structure.
Cross-cutting assumptions and dependencies
- Base LLM compatibility: The target LLM must accept concept embeddings in the same latent space as token embeddings; CompLLM is trained per model.
- Task characteristics: CompLLM prioritizes semantic content; tasks requiring exact character-level fidelity (typo finding, letter counts, exact string matching) may need fallback to the uncompressed pipeline.
- Segmentation quality: Sentence/segment boundaries affect CE quality; domain-specific segmentation (code blocks, HTML sections) improves outcomes.
- Offline availability: Many gains rely on pre-compressing contexts offline and caching; workflows should support incremental recompression when content changes.
- Evaluation at scale: Benefits grow with context length; for small contexts, compression overhead may outweigh gains—pipelines should auto-disable CompLLM for short prompts.
Glossary
- Adam optimizer: A stochastic optimization algorithm commonly used to train deep neural networks by adapting learning rates per parameter. "We use an Adam optimizer with a learning rate of 0.0001, and we train with a batch size of 4 until convergence."
- Attention dilution: The phenomenon where too many context tokens can weaken attention focus and degrade performance. "We hypothesize that this happens because having fewer tokens reduces attention dilution;"
- Autoregressive: A generation process where each new token is produced conditioned on all previously generated tokens. "corresponds to producing new tokens in an autoregressive manner."
- Beam search: A heuristic decoding algorithm that maintains multiple candidate sequences to improve generation quality. "beam search \citep{freitag2017beam},"
- BERT-like encoder: A transformer encoder architecture similar to BERT used for contextual text representation. "LLMLingua-2 \citep{pan2024llmlingua2} uses a BERT-like encoder \citep{Devlin_2019_BERT}, which compresses sentences independently from each other."
- BFloat16: A 16-bit floating-point format that preserves dynamic range similar to FP32, used to speed up training/inference. "We used Gemma3-4B on a B200 GPU using BFloat16 and PyTorch compile function."
- Chain of thought: A prompting technique that encourages models to generate intermediate reasoning steps. "chain of thought \citep{wei_2022_chainOfThought},"
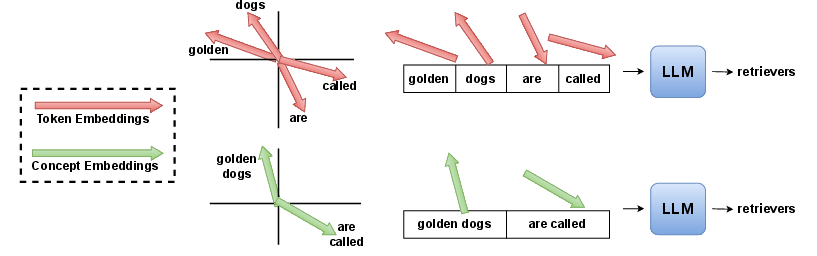
- Concept Embeddings (CEs): Continuous vectors, not tied to specific tokens, that encode compressed context information and can be fed directly to the LLM. "We instead rely on the existence of other embeddings, which we call Concept Embeddings (CEs, conceptualized in \Cref{fig:CE_conceptualization}), which exist in the same latent space of TEs and can be directly fed to the LLM, despite being completely unseen at training time."
- Compression rate: The factor by which the input sequence is reduced in length during compression. "Unless otherwise specified, we use a compression rate of ."
- Decoder-only LLM: A transformer architecture that uses only decoder blocks for autoregressive generation. "note that multiple architectures can satisfy this basic constraint (like encoder-only LLMs, decoder-only LLMs, MLPs, etc. )."
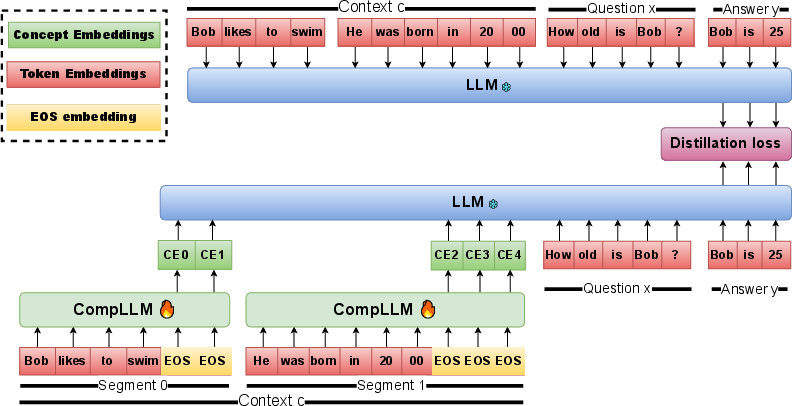
- Distillation: A training strategy where a student model learns to match internal or output behavior of a teacher model. "Instead of matching output distributions, we distill by matching hidden activations on the answer segment, which provides a denser and richer signal than output distributions."
- Embeddings table: The parameter matrix mapping discrete token IDs to continuous embedding vectors. "an LLM can be fed one of roughly 200k Token Embeddings (TEs), i.e the vectors contained in the embeddings table:"
- Encoder-only LLM: A transformer architecture using only encoder blocks, typically for bidirectional representation learning. "note that multiple architectures can satisfy this basic constraint (like encoder-only LLMs, decoder-only LLMs, MLPs, etc. )."
- End-of-Sequence (EOS) token: A special token indicating the end of a sequence, often repurposed here as placeholders for compressed outputs. "we append embeddings corresponding to EOS tokens, whose corresponding outputs are used as the CEs,"
- Hidden activations: Intermediate representations computed within model layers. "we distill by matching hidden activations on the answer segment,"
- Instruction-tuned LLM: A LLM fine-tuned to follow natural-language instructions. "Consider an instruction-tuned LLM $p_{\mathrm{LLM}(y \mid c, x)$"
- Key-Value (KV) cache: Stored key and value vectors from prior tokens used to speed up attention during generation. "methods that compress the input into a key-value (KV) cache \citep{li_2025_500xcompressor}, which has dimension ,"
- KV cache prefill cost: The initial computational cost to compute the cache over the prompt before generation. "The first is the KV cache prefill cost, incurred when computing the first forward pass over the input tokens,"
- Latent embeddings: Continuous vectors representing compressed or abstracted information rather than direct token indices. "Soft compression is achieved in two different ways: (A) by compressing text into latent embeddings ( -dimensional embeddings,"
- Latent space: A high-dimensional continuous vector space where inputs are embedded for modeling. "compresses the prompt into a high-dimensional latent space"
- LLM-as-a-judge: An evaluation approach where an LLM scores or judges outputs rather than using traditional metrics. "For open-ended Q{paper_content}A, we compute evaluation with the LLM-as-a-judge approach;"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that injects low-rank adapters into model layers. "we take inspiration from \citet{ge2024incontext}, by attaching a LoRA \citep{hu_2022_lora} to the same LLM used for generation;"
- Long-Context Frontiers (LOFT): A benchmark suite designed to stress-test long-context capabilities of LLMs. "The Long-Context Frontiers benchmark (LOFT) \citep{Lee2024LOFT} is a recent benchmarks designed to assess LLMs' performance on long context tasks"
- Next token prediction: The iterative process of generating tokens one by one conditioned on previous context. "The second component is the next token prediction cost,"
- NLTK Punkt tokenizer: A rule-based sentence tokenizer from the NLTK library. "We split the text into sentences/segments using the NLTK Punkt tokenizer \citep{kiss_2006_punkt},"
- Paged attention: A memory-management technique for attention that enables efficient handling of long sequences. "paged attention \citep{kwon_2023_vLLM},"
- Perceiver-like architecture: A model design inspired by the Perceiver that uses cross-attention to compress inputs into latent arrays. "which uses a perceiver-like architecture \citep{jaegle2021perceiver} to compress the context,"
- PyTorch compile: A PyTorch facility that compiles models for optimized execution. "We used Gemma3-4B on a B200 GPU using BFloat16 and PyTorch compile function."
- Quadratic complexity: Computational cost that scales with the square of input size, typical of standard self-attention. "Due to the quadratic complexity of the transformer"
- RAG (Retrieval-Augmented Generation): A paradigm where retrieved documents are incorporated into the prompt to aid generation. "RAG \citep{lewis_2020_rag},"
- Regex matching: A pattern-matching technique using regular expressions, here for evaluating multiple choice answers. "for multiple choice Q{paper_content}A, we evaluate with regex matching,"
- Self-attention: The mechanism by which transformers compute contextualized token representations by attending over the sequence. "quadratic complexity of self-attention."
- Smooth-L1 loss: A loss function combining L1 and L2 behavior for robustness, used here to match hidden states. "We minimize a Smooth- loss per layer,"
- Teacher hidden states: Internal layer representations from a reference (teacher) model used as targets in distillation. "let be the teacher hidden states at layer restricted to ;"
- Time To First Token (TTFT): The latency to produce the first generated token, closely tied to prefill time. "The leftmost plot shows the time taken to generate 1 token, commonly known as Time To First Token (TTFT):"
- Token Embeddings (TEs): Learned vectors corresponding to vocabulary tokens used as inputs to the LLM. "an LLM can be fed one of roughly 200k Token Embeddings (TEs), i.e the vectors contained in the embeddings table:"
- Token pruning: A hard compression technique that removes less informative tokens to shorten prompts. "either through means of token pruning \citep{jiang2023llmlingua, pan2024llmlingua2}"
Collections
Sign up for free to add this paper to one or more collections.