LightMem: Lightweight and Efficient Memory-Augmented Generation
Abstract: Despite their remarkable capabilities, LLMs struggle to effectively leverage historical interaction information in dynamic and complex environments. Memory systems enable LLMs to move beyond stateless interactions by introducing persistent information storage, retrieval, and utilization mechanisms. However, existing memory systems often introduce substantial time and computational overhead. To this end, we introduce a new memory system called LightMem, which strikes a balance between the performance and efficiency of memory systems. Inspired by the Atkinson-Shiffrin model of human memory, LightMem organizes memory into three complementary stages. First, cognition-inspired sensory memory rapidly filters irrelevant information through lightweight compression and groups information according to their topics. Next, topic-aware short-term memory consolidates these topic-based groups, organizing and summarizing content for more structured access. Finally, long-term memory with sleep-time update employs an offline procedure that decouples consolidation from online inference. Experiments on LongMemEval with GPT and Qwen backbones show that LightMem outperforms strong baselines in accuracy (up to 10.9% gains) while reducing token usage by up to 117x, API calls by up to 159x, and runtime by over 12x. The code is available at https://github.com/zjunlp/LightMem.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces LightMem, a smarter “memory” system for AI chatbots (LLMs, or LLMs). It helps them remember important parts of long conversations without getting slow or expensive to run. The idea is inspired by how human memory works: we quickly notice what matters, we group related things, and we strengthen long-term memories later (like during sleep).
What questions did the researchers ask?
The paper focuses on three simple questions:
- How can an AI keep the important parts of long chats while avoiding useless or repeated information?
- Can the AI organize memories by topic (like folders) instead of using fixed, clumsy chunks of text?
- Can the AI update its long-term memory “offline” (not during the conversation) to stay fast and consistent?
How does LightMem work?
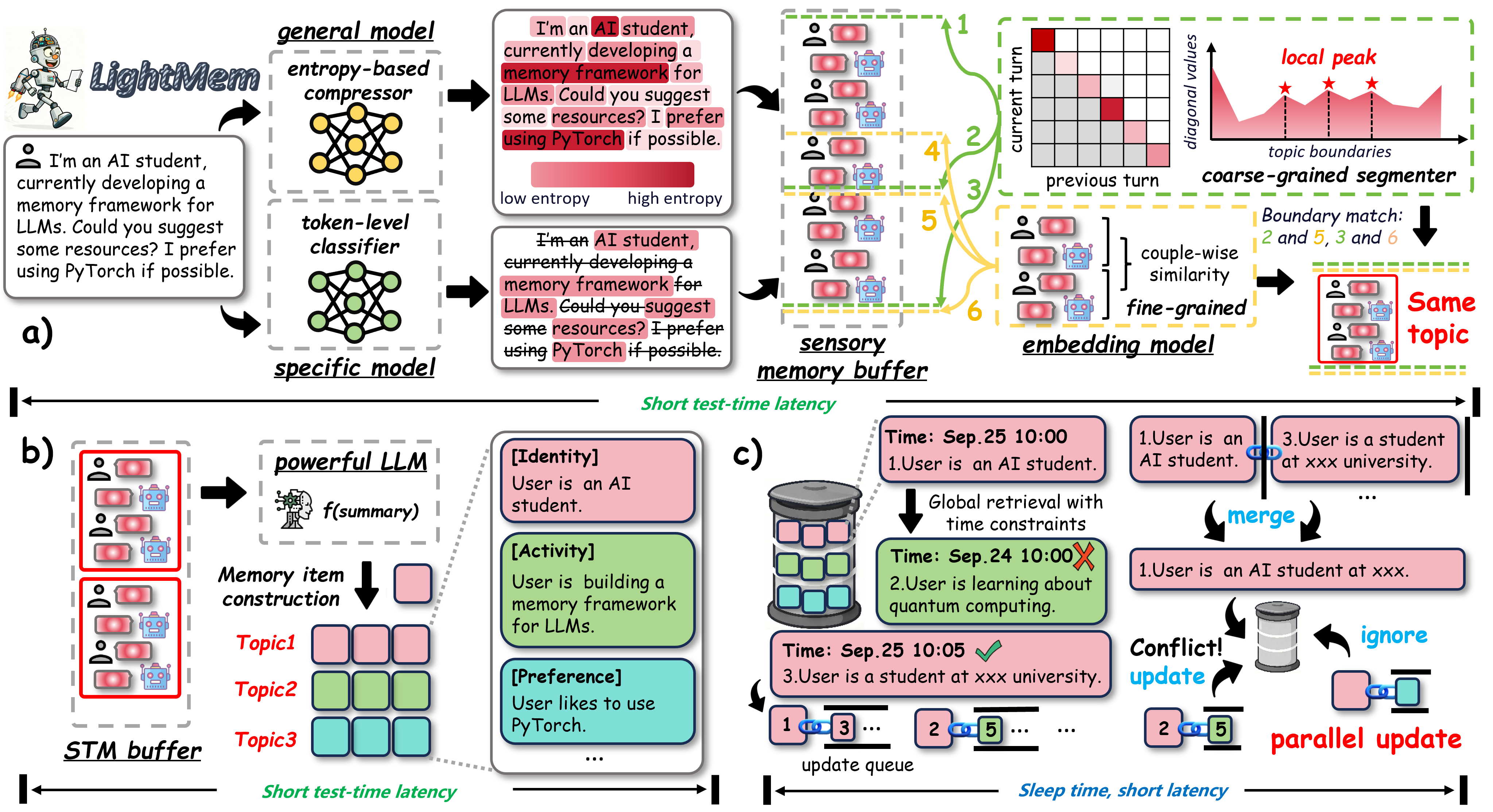
To make this easy to imagine, think of the AI as a student taking notes in class. LightMem splits memory into three stages that mirror human memory.
1) Sensory memory: quick filtering (pre-compression)
- Analogy: You highlight only the key sentences in a textbook instead of copying everything.
- What it does: When the AI reads a message, a small helper model quickly filters out unimportant words and keeps the meaningful parts. This reduces “noise” and saves time.
- Why it helps: The AI doesn’t waste brainpower on extra words that don’t help answer questions later.
2) Short-term memory: organize by topic
- Analogy: You sort your notes into folders like “Travel plans,” “Homework,” or “Sports,” and summarize each folder.
- What it does: The system groups related messages into topics (instead of just splitting by fixed size or turns). It then writes short summaries for each topic.
- Why it helps: Organizing by topic makes it easier to find the right memory later, and summaries keep things compact and clear.
3) Long-term memory: “sleep-time” updates
- Analogy: After school, you clean up your notes—merge duplicates, fix conflicts, and make a neat summary. You do this later, not in the middle of class.
- What it does:
- During chats: the AI uses “soft updates,” which means it adds new info without trying to rewrite old memories on the spot (this avoids mistakes and keeps things fast).
- After chats (“sleep time”): it reorganizes memory offline—merging related pieces, removing duplicates, and resolving conflicts. These updates can run in parallel, so they finish faster.
- Why it helps: Decoupling updates from live conversation keeps the AI responsive and reduces errors from rushed updates.
Note on terms:
- Tokens: tiny pieces of text (like fragments of words) the AI reads or writes. Fewer tokens = cheaper and faster.
- API calls: how many times the AI is asked to process something. Fewer calls = cheaper and faster.
- Runtime: how long the whole process takes.
How did they test it?
They used a benchmark called LongMemEval, which contains very long, multi-session chat histories. The AI has to answer questions using what it “remembers” from these chats. They tested LightMem with two well-known model families (GPT and Qwen) and compared it against several strong memory systems.
What did they find, and why is it important?
Here are the main results, explained simply:
- Better answers: LightMem answered questions more accurately than other memory systems, with improvements up to about 10.9%.
- Much more efficient:
- Up to 117× fewer tokens processed (less reading/writing),
- Up to 159× fewer API calls (fewer requests to the AI),
- Over 12× faster in runtime.
- Still strong after “sleep-time” updates: Even after doing the offline cleanup, performance stays high while keeping costs low.
- Smarter organization:
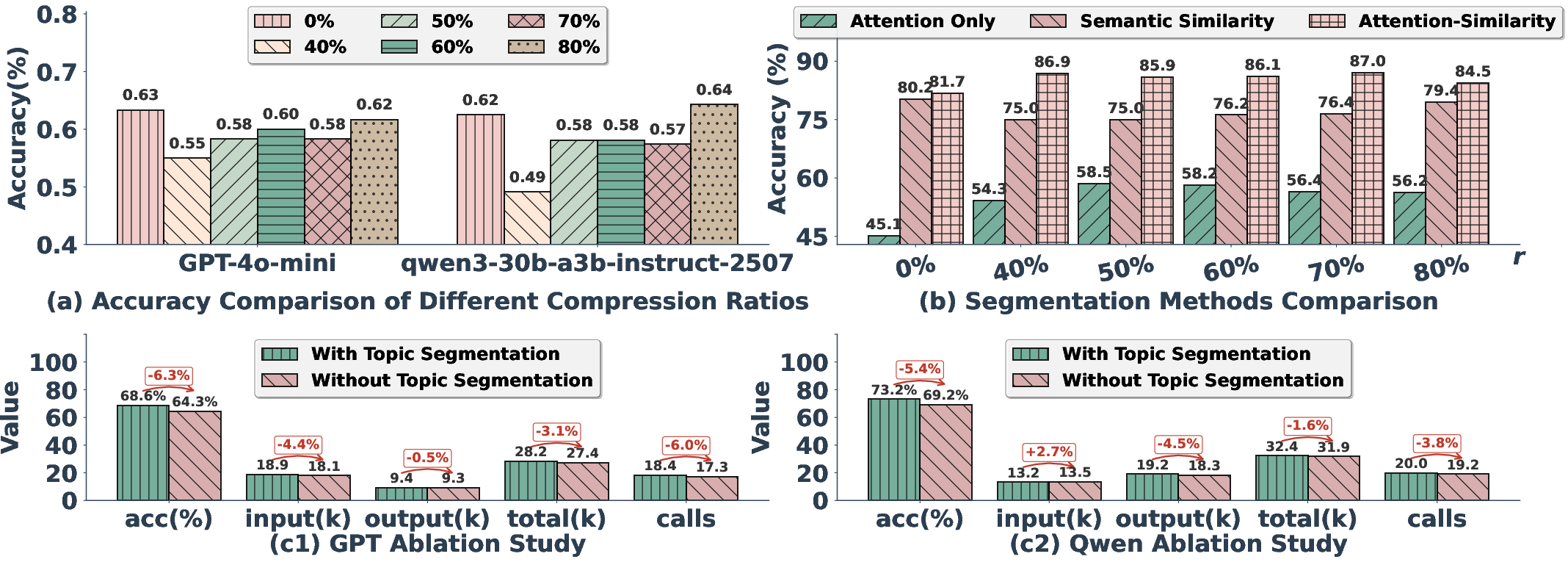
- The topic grouping method (using attention + similarity) found topic breaks with over 80% accuracy.
- Removing topic segmentation made the system faster but hurt accuracy by about 5–6%, showing that structure matters.
Why it matters:
- AI helpers often lose track in long chats (“lost in the middle” problem). LightMem keeps the important context without slowing everything down. This makes AI assistants more useful, cheaper to run, and more reliable over time.
What could this mean in the future?
- More reliable long-term assistants: AI chatbots could remember your preferences and past conversations without getting confused or too costly.
- Lower costs and faster responses: Useful for apps, tutors, and customer support that handle many long conversations.
- Safer updates: Doing big memory changes offline reduces mistakes like accidentally deleting important facts.
- Responsible use needed: Storing conversations can include sensitive info. Systems using LightMem should include strong privacy protections and user control.
The authors also suggest future steps like speeding up offline updates even more, using knowledge graphs for complex reasoning, and extending the system to handle images and audio—not just text.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity beyond LongMemEval-S: no tests on other long-horizon, real-world logs, multi-document streams, or agentic tasks (tool use, planning, continual learning), limiting generalization claims.
- Evaluation scope restricted to QA: no end-to-end agent benchmarks (e.g., task completion, planning success, personalization) to validate memory utility in interactive settings.
- Limited backbone diversity: results only on GPT-4o-mini and Qwen3-30B-A3B; missing smaller/larger models, open-weight baselines, and multilingual models to assess robustness and portability.
- LLM-as-judge dependency: accuracy relies on GPT-4o-mini judgments; no human evaluation, gold-answer EM/F1, or cross-judge agreement to quantify evaluation bias.
- Missing statistical rigor: no variance, confidence intervals, or significance tests; unclear sensitivity to random seeds and run-to-run variability.
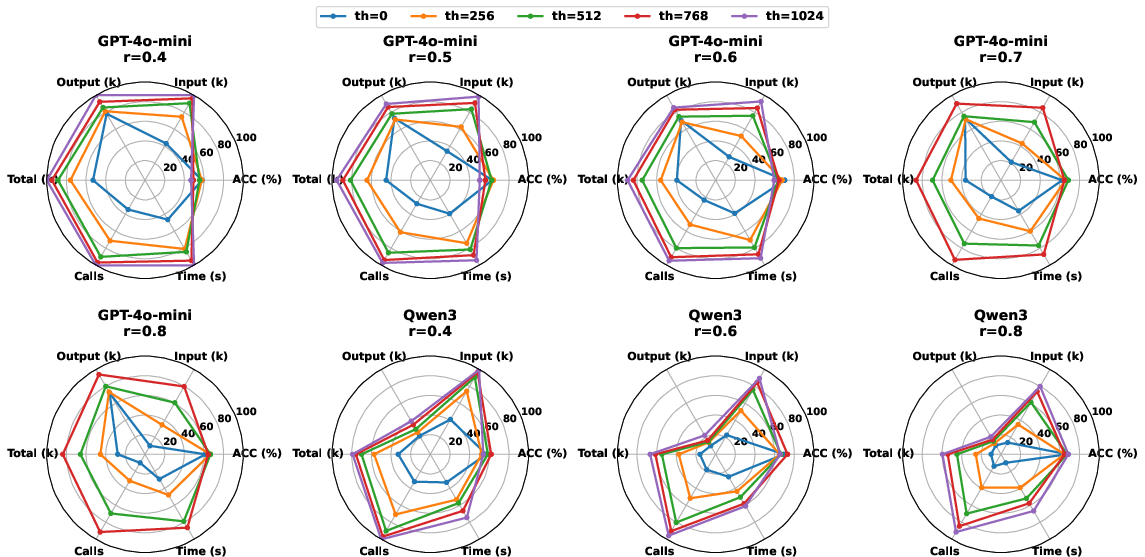
- Compression adaptivity: compression ratio r and STM threshold th are tuned offline; no mechanism for online/adaptive control based on task difficulty, model uncertainty, or downstream performance signals.
- Compression fidelity under stress: no tests on adversarial/edge cases where crucial details are sparse, rare, or cross-turn; no quantitative measures of semantic loss or induced hallucinations.
- Alternative compressors untested: LLMLingua-2 chosen by default; missing head-to-head comparisons with other compressors (e.g., ICS compression, token-level pruning, instruction-aware compressors) and generative compression variants.
- Ambiguity in cross-entropy retention variant: the proposed token retention based on cross-entropy references “true token labels,” which are unavailable at inference; implementation details and practicality are unclear.
- Topic segmentation ground truth: “session boundaries” are used as gold labels, which may not align with human-perceived topics; no evaluation on human-annotated topic datasets or non-dialog domains.
- Segmentation generality: segmentation tailored to dialogue turns and 512-token buffers; unclear performance on longer contexts, streaming logs, narrative text, code, or multi-document settings.
- Embedding model dependency: the embedding model used for similarity is unspecified; no ablation on different embedders or domains (multilingual, code) to quantify sensitivity and failure modes.
- Retrieval details under-specified: indexing, retrieval ranking, and cross-topic retrieval strategy are not detailed; memory recall/precision and retrieval latency/throughput are not measured.
- Memory growth and footprint: soft updates append entries without immediate pruning; no analysis of memory size growth, storage limits, compaction strategies, or long-term retrieval degradation.
- Forgetting and conflict resolution quality: offline “sleep-time” update is efficiency-focused; no quantitative evaluation of conflict handling, contradiction resolution, deduplication, or temporal consistency.
- Update correctness benchmarks missing: no datasets with controlled, evolving facts (additions, corrections, contradictions) to assess update fidelity, stability, and information preservation.
- Temporal update constraint design: only later timestamps can update earlier entries; lacks study of scenarios requiring back-propagated corrections, versioning, or bidirectional reconciliation.
- Parallel update consistency: offline parallel updates assume independent queues; no concurrency control, transactional guarantees, or analysis of race conditions across interdependent entries.
- Sleep-time scheduling: no policy for when to trigger offline updates (time, load, memory pressure); trade-offs between staleness, latency, and cost remain unexplored.
- Summary faithfulness: STM summaries feed LTM, but no factual consistency metrics (e.g., factuality audits, faithfulness scores) or human evaluations to detect summarization drift/hallucination.
- Exclusion of QA/retrieval costs: efficiency results focus on memory operations; end-to-end latency and token costs (including retrieval and answer generation) are not reported, limiting practical cost claims.
- Baseline tuning fairness: unclear if baselines were tuned with equal budget/effort (e.g., r/th analogs, compressor usage); risk of unfair comparisons not addressed.
- Hardware and deployment constraints: runtime measured on unspecified hardware; no profiling under CPU-only, edge/mobile, or memory-constrained setups to validate “lightweight” claims.
- Robustness and security: no evaluation of memory poisoning, prompt attacks, or noisy user inputs; lacks defenses (e.g., anomaly detection, provenance tracking, trust scores) and their efficacy.
- Privacy and compliance: while risks are acknowledged, no concrete privacy mechanisms (e.g., encryption at rest, selective redaction, data retention policies, differential privacy) or their impact on performance.
- Multilingual and multimodal coverage: no experiments on non-English text, code, or multimodal inputs; unclear how compression/segmentation/update mechanisms transfer to these modalities.
- Hyperparameter sensitivity: values for k and n in the update queues, similarity thresholds, and segmentation thresholds are not ablated; stability and best-practice guidance are missing.
- Memory representation choices: LTM stores {topic, summary embedding, raw turns}; no study of richer structures (e.g., events, entities, relations) or their effect on retrieval and reasoning.
- KG integration left future: the proposed knowledge-graph memory is not instantiated; open questions on how to map LightMem entries to KG nodes/edges and handle graph updates efficiently.
- Code/reproducibility ambiguity: the abstract says code is available, while the reproducibility statement says it will be released; exact artifacts, configs, and seeds are not provided.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating LightMem’s sensory pre-compression, topic-aware short-term memory, and sleep-time (offline, parallel) long-term updates into existing LLM agent workflows.
- Customer support chatbots with efficient long-term memory (Sector: software, CX)
- Action: Wrap existing bots with a LightMem middleware to pre-compress transcripts, segment by topic, and schedule nightly parallel consolidation to cut token cost and latency without losing context.
- Tools/Workflows: Vector DB (e.g., Milvus, Pinecone), embedding service, LLMLingua-2 for compression, cron/Airflow for sleep-time updates; framework integration (LangChain/LlamaIndex).
- Assumptions/Dependencies: Accurate timestamps, quality embeddings, sufficient off-peak compute; privacy and consent governance for storing conversations.
- CRM and sales assistants with persistent, low-cost personalization (Sector: software, marketing/CRM)
- Action: Store compressed, topic-grouped buyer interactions to personalize outreach (preferences, constraints, past objections) while minimizing API calls.
- Tools/Workflows: Topic index {topic, sum_i, user_i, model_i}, similarity-based retrieval for live calls; nightly de-duplication and abstraction.
- Assumptions/Dependencies: Data minimization and consent; calibration of compression ratio r and STM threshold th to maintain accuracy.
- IT helpdesk and internal enterprise assistants (Sector: software, operations)
- Action: Maintain long-horizon memory of tickets, resolutions, and policies with sleep-time reconciliation to remove outdated entries and unify duplicates.
- Tools/Workflows: “Soft insert” at test time, offline parallel updates, retrieval of nearest relevant entries for consistency.
- Assumptions/Dependencies: Access to historical logs; robust update queues; audit trails for change control.
- Educational tutors tracking student progress across sessions (Sector: education)
- Action: Use topic-aware STM to summarize learning sessions and store durable progress markers (skills mastered, misconceptions) for personalized lesson planning.
- Tools/Workflows: Automated topic segmentation per session; nightly consolidation; retrieval for adaptive exercises.
- Assumptions/Dependencies: Student data consent; parameter tuning (r, th) per curriculum length and pacing.
- Clinical conversation memory for telehealth and digital scribes (Sector: healthcare)
- Action: Pre-compress and segment patient-provider dialogues to preserve salient longitudinal context across visits, with offline consolidation to reduce real-time latency.
- Tools/Workflows: EHR-integrated vector DB; secure, encrypted storage; policy-based forgetting.
- Assumptions/Dependencies: HIPAA/GDPR compliance; strong PHI governance; domain-specific prompts and medical taxonomies.
- Software engineering copilots with project memory (Sector: software)
- Action: Persist compressed summaries of design decisions, PR discussions, and incidents; retrieve topic-constrained context to guide coding suggestions and reviews.
- Tools/Workflows: Repo-linked memory entries keyed by topic; nightly merge of overlapping decisions and incident lessons.
- Assumptions/Dependencies: Access to org repos and issue trackers; consistency with codebase versions.
- Meeting assistants and knowledge management (Sector: enterprise software)
- Action: Compress and segment meetings and threads to generate accurate topic summaries and reduce chunking overhead in dynamic, evolving team knowledge.
- Tools/Workflows: Automated “meeting memory” pipeline with semantic segmentation; parallel update jobs for versioned notes.
- Assumptions/Dependencies: High-quality diarization/turn metadata; robust similarity thresholds.
- Public service/citizen service bots with retention schedules (Sector: policy, government)
- Action: Implement memory with configurable retention, consent prompts, and nightly redaction/forgetting to maintain compliance and reduce infrastructure costs.
- Tools/Workflows: Policy-aware update queues; automatic de-identification during sleep-time.
- Assumptions/Dependencies: Legal frameworks for consent, auditability, and right-to-be-forgotten.
- Personal AI assistants and journaling apps (Sector: daily life, consumer software)
- Action: Compress chats, emails, and notes; maintain topic-oriented memories for reminders, task continuity, and goal tracking with reduced subscription/API spend.
- Tools/Workflows: On-device compression; cloud sleep-time updates; lightweight embeddings for mobile retrieval.
- Assumptions/Dependencies: On-device storage and encryption; user opt-in and transparency.
- Edge/mobile assistants with tight token budgets (Sector: mobile/edge computing)
- Action: Use LLMLingua-2 compression and topic segmentation to reduce bandwidth and inference costs; offload consolidation to the cloud during off-peak hours.
- Tools/Workflows: Hybrid edge-cloud pipeline; batched sleep-time updates.
- Assumptions/Dependencies: Reliable connectivity, low-tariff scheduling; small memory footprint on device.
- Ops for cost and performance tuning (Sector: engineering operations)
- Action: Introduce a “LightMem auto-tuning” loop to adjust r and th per workload, optimizing accuracy vs. cost based on telemetry (token usage, API calls, latency).
- Tools/Workflows: A/B testing with LongMemEval-like harness; cost dashboards; runtime triggers for buffer flushes.
- Assumptions/Dependencies: Representative traffic patterns; monitoring and alerting for drift.
- Compliance-aware memory pipelines (Sector: cross-sector governance)
- Action: Use soft updates to avoid irreversible loss, then perform policy-constrained merges/deletions offline; include PII redaction and conflict resolution rules.
- Tools/Workflows: Policy engine integrated into sleep-time update; audit logs and immutable snapshots for oversight.
- Assumptions/Dependencies: Clear organizational policies, data classification, and governance tooling.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or integration with additional modalities and structures.
- Multimodal memory for embodied and robotic agents (Sector: robotics, XR)
- Vision/audio/text streams compressed and segmented into coherent episodes; offline consolidation improves task transfer and safety.
- Dependencies: Robust cross-modal embeddings; segmentation beyond text (e.g., event boundaries in video/audio); real-time constraints.
- Knowledge graph-integrated memory for multi-hop reasoning (Sector: software, healthcare, finance)
- Convert topic summaries into entities/relations; sleep-time updates maintain graph consistency and support interpretable retrieval.
- Dependencies: Entity linking, relation extraction, ontology alignment; scalable KG backends; domain schemas.
- Parametric–nonparametric synergy (Sector: LLM systems)
- Learn policies that gate when to rely on internal model weights vs. external memory; train adapters using memory footprints.
- Dependencies: Joint training objectives; retrieval-aware decoding; evaluation frameworks for memory reliance.
- Task-aware adaptive compression and segmentation (Sector: all sectors)
- Automatically tune r and topic boundaries per task/query distribution via RL or bandit optimization to maximize QA accuracy and minimize cost.
- Dependencies: Online learning signals; guardrails against over-compression; robust feedback loops.
- Privacy-preserving, compliance-first memory (Sector: policy, healthcare, finance)
- Differential privacy, homomorphic encryption, or secure enclaves for sleep-time updates; standardized consent and retention protocols.
- Dependencies: Cryptographic primitives at scale; regulatory acceptance and audits; performance overhead management.
- Healthcare longitudinal copilots integrated with EHR (Sector: healthcare)
- Durable patient context across institutions and visits, with explainable updates and conflict resolution; supports continuity of care.
- Dependencies: Interoperability (FHIR), medical QA validation, clinical workflow integration, liability considerations.
- Financial advisory and contact center memory with auditability (Sector: finance)
- Retain compliant histories of client interactions with versioned, explainable updates and audit trails; support model risk management.
- Dependencies: Regulatory sign-off (e.g., SEC/FINRA), robust lineage and logging, stress testing.
- Cross-course and institution-scale educational memory (Sector: education)
- Long-term, cross-curriculum memory for learners with explainable profiles; program-level analytics and personalization.
- Dependencies: Institutional data integration, FERPA/GDPR compliance, fairness monitoring.
- Multi-agent systems with coordinated memory (Sector: autonomous systems, operations)
- Shared memory pools and sleep-time synchronization across agents to reduce duplication and inconsistencies.
- Dependencies: Consistency protocols, conflict resolution across agents, version control for memory states.
- Energy-aware compute scheduling for memory maintenance (Sector: energy, cloud operations)
- Shift offline updates to low-carbon or low-cost grid windows; spot instances and autoscaling for consolidation jobs.
- Dependencies: Predictive scheduling; cloud ops integration; SLAs to avoid user-facing impacts.
- LightMem orchestration products (Sector: software tooling)
- Turn LightMem into an SDK/middleware with “OP-update” orchestration, policy engines, and dashboards for cost/accuracy monitoring.
- Dependencies: Productization, enterprise integrations, security hardening.
- Benchmarks and evaluation standards for dynamic memory (Sector: academia, standards)
- Extend LongMemEval with multimodal and domain-specific tasks; standardize metrics (accuracy vs. cost vs. latency, consistency).
- Dependencies: Community consensus, dataset curation, open-source tooling.
Notes on Assumptions and Dependencies (Cross-Cutting)
- Performance generalization: Reported gains were shown on GPT-4o-mini and Qwen3-30B; domain/task transfer should be validated.
- Quality gating: Embedding quality, similarity thresholds, and topic segmentation accuracy critically affect retrieval and updates.
- Parameter sensitivity: Compression ratio (r) and STM threshold (th) are workload-dependent; auto-tuning is recommended.
- Infrastructure: Requires vector databases, schedulers for sleep-time updates, and secure storage; parallel offline updates presume independence of queues and sufficient throughput.
- Ethics and privacy: Consent, minimization, retention, access controls, and right-to-be-forgotten policies must be implemented, especially for sensitive sectors.
- Observability: Audit logs and evaluation prompts (LLM-as-judge) are needed to monitor accuracy, drift, and unintended forgetting/merging.
Glossary
- Attention-based boundaries: Topic segmentation points identified from attention patterns. "attention-based boundaries "
- Attention matrix: A matrix of attention scores capturing relationships (e.g., between turns). "We construct a turn-level attention matrix ."
- Attention sinks: Degradation where attention mass concentrates, diluting useful signals. "To mitigate attention sinks and dilution in attention-based methods, we compute semantic similarity..."
- AtkinsonâShiffrin human memory model: A three-stage human memory framework (sensory, short-term, long-term). "Following the AtkinsonâShiffrin human memory model~\citep{atkinson1968human}"
- Chunking strategies: Methods to split documents into smaller retrievable units in RAG. "Existing chunking strategies include rule-based methods creating fixed-size segments"
- Compression ratio (r): The fraction of tokens retained after compression. "Let be the raw input tokens, the model, and the compression ratio."
- Context window: The maximum token span an LLM can attend to at once. "the size of the sensory memory buffer matches the model's context window length, which is 512 tokens."
- Cross-entropy: A loss/measure comparing predicted vs. true distributions, used for token filtering. "based on the cross-entropy between the modelâs predicted distribution and the true token labels"
- Embedding model: A model that maps text into vectors for similarity and retrieval. "We use the compression model and an embedding model to compute attention matrices and semantic similarities, respectively."
- Forgetting policy: Rules specifying when and how to discard outdated/conflicting memory. " specifies the update or forgetting policy."
- Granularity: The segmentation level at which data is processed (turn/session/topic). "processed at a chosen level of granularity"
- Incremental Dialogue Turn Feeding: An evaluation setting where dialogue turns arrive and are processed sequentially. "Incremental Dialogue Turn Feeding setting"
- In-context learning capability: An LLM’s ability to leverage provided context for improved performance. "may even negatively affect the modelâs in-context learning capability"
- Key–Value (KV) caches: Stored activations that accelerate inference/update by reusing computed states. "pre-computed keyâvalue (KV) caches."
- Knowledge graphs: Structured graph representations used to store and organize long-term memory. "vector databases or knowledge graphs"
- LLMLingua-2: A lightweight prompt compression model used to filter tokens. "we use LLMLingua-2~\citep{pan2024llmlingua} as our compression model ."
- LLM judge: Using an LLM to evaluate the correctness of answers. "evaluation is conducted with GPT-4o-mini as an LLM judge"
- Local maxima: Peaks in a sequence used to detect boundaries. " are identified as local maxima in the sequence "
- Long-term memory (LTM): Durable storage that is reorganized via updating, abstraction, and forgetting. "long-term memory (LTM) provides durable storage"
- LongMemEval: A benchmark dataset for evaluating LLM memory in long dialogues. "We use the well-known dataset LongMemEval"
- Lost in the middle problem: LLMs’ difficulty attending to information in the middle of long contexts. "due to fixed context windows and the ``lost in the middle'' problem"
- Memory bank: The repository of stored memory entries. "where denotes the existing memory bank"
- Multimodal memory: Memory mechanisms that span textual, visual, and auditory information. "We further plan to develop a multimodal memory mechanism"
- Offline parallel update: Performing memory updates in parallel during offline phases to reduce latency. "Offline Parallel Update."
- Oscillatory activity: Rhythmic brain activity during sleep that aids memory consolidation. "oscillatory activity during sleep facilitates the integration and consolidation of memory systems."
- Parametric–Nonparametric Synergy: Combining internal model parameters with external memory structures for flexible knowledge use. "ParametricâNonparametric Synergy."
- Percentile threshold: A cutoff based on percentile used to retain high-information tokens. ""
- Pre-attentive feature extraction: Fast filtering and feature processing before focused attention. "rapid pre-attentive feature extraction and filtering"
- Pre-compression: Early-stage reduction of input tokens to remove redundancy before memory processing. "serving as a form of pre-compression"
- Read-after-write/write-after-read constraints: Ordering constraints that force sequential updates and limit parallelism. "(read-after-write/write-after-read)"
- Retrieval-Augmented Generation (RAG): Augmenting generation with retrieved external documents. "Retrieval-Augmented Generation (RAG) systems rely on chunking extrernal documents"
- Semantic similarity: A measure of meaning-based closeness used for grouping and updates. "compute semantic similarity between adjacent turns"
- Sensory memory: A brief pre-filtering stage that retains raw inputs and performs pre-compression. "sensory memory pre-filters incoming stimuli"
- Short-term memory (STM): Transient storage supporting active processing of recent information. "short-term memory (STM), where information and interaction sequences are preserved"
- Similarity-based boundaries: Topic segmentation points where adjacent segments are dissimilar. "similarity-based boundaries "
- Sleep-time update: Offline consolidation and reorganization of memory during designated “sleep” periods. "long-term memory with sleep-time update employs an offline procedure"
- Soft updates: Lightweight insertions into LTM without immediate consolidation. "LightMem directly inserts them into LTM with soft updates"
- Sub-diagonal elements: Entries immediately below the main diagonal in a matrix, used for consecutive-turn attention. "the sub-diagonal elements of "
- Summary process: Memory distillation and summarization operations tracked for efficiency. "the Summary process as memory distillation and summarization operations"
- Topic segmentation: Dividing dialogue into coherent topic-based segments for memory construction. "Topic Segmentation Submodule."
- Top-k: Selecting the k most similar candidates for updates or retrieval. "selecting the top- most similar candidates"
- Update queue: A ranked list of candidates that may update a given memory entry. "we compute an update queue for every entry in LTM."
- Vector databases: Datastores for embeddings enabling fast similarity search and retrieval. "vector databases or knowledge graphs"
Collections
Sign up for free to add this paper to one or more collections.