- The paper introduces a scalable memory system that dynamically extracts and consolidates salient information to maintain extended conversational coherence.
- It details two variants – a natural language memory approach and a graph-based model for enhanced relational reasoning – validated on the LOCOMO dataset.
- Experimental results demonstrate improved accuracy and computational efficiency over baseline systems, suggesting a robust solution for long-term AI interactions.
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0 introduces a scalable architecture that effectively addresses the limitations faced by LLMs due to their fixed context windows. By implementing dynamic extraction and consolidation of salient information, Mem0 enhances AI agents' ability to maintain conversational coherence across extended interactions. This paper proposes two variants: Mem0, which uses natural language memory representations, and an enhanced variant with a graph-based structure for capturing complex relational data.
Challenge in Memory Systems
LLMs face difficulties maintaining long-term conversational coherence due to finite context windows, which diminish the ability to retain and utilize information across sessions. This problem becomes evident in scenarios requiring extensive history, where relevant information could be buried under volumes of unrelated data or outside the context limits. Consequently, AI systems suffer from repetitive and sometimes contradictory suggestions, negatively impacting user experience.

Figure 1: Illustration of memory importance in AI agents, highlighting differences between systems with and without persistent memory.
To tackle these issues, Mem0 introduces advanced memory-centric architectures that emulate human-like cognitive processes, retaining essential information while discarding irrelevant details. This not only enhances response relevance but also optimizes computational efficiency.
Architecture Overview
Mem0 System
Mem0 consists of an extraction phase and an update phase, both leveraging LLMs for semantic processing. The extraction phase retrieves conversation summaries and recent dialogue snippets to form comprehensive memory prompts for extracting salient facts. In the update phase, the system evaluates these facts against existing memories using a tool-call mechanism, deciding on operations like ADD, UPDATE, DELETE, or NOOP based on semantic relationships.
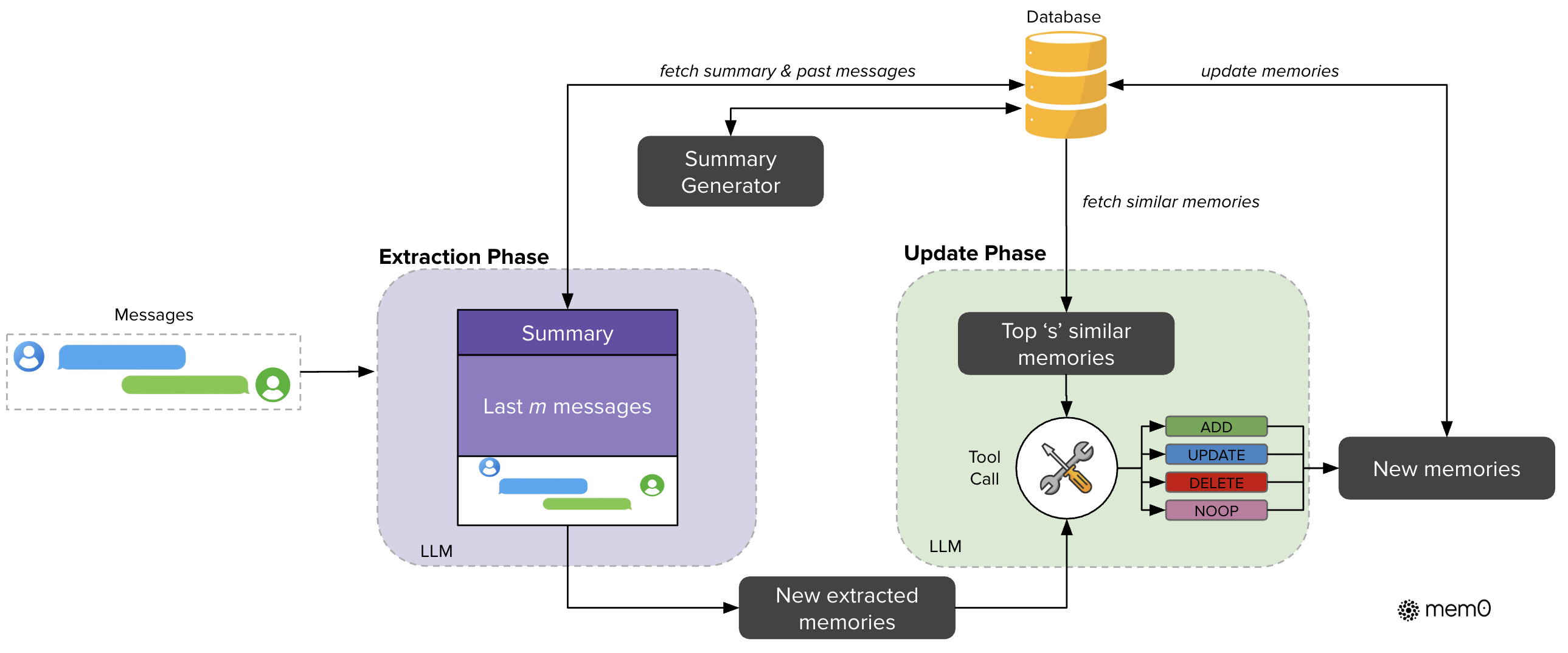
Figure 2: Architectural overview of the Mem0 system showing extraction and update phases.
Graph-based Memory Representation (Enhanced Mem0)
The enhanced Mem0 augments the memory extraction process with a graph-based representation, capturing entities and relationships as directed graphs. This structure allows for deeper relational reasoning, crucial for navigating complex conversational queries that involve interconnected data.
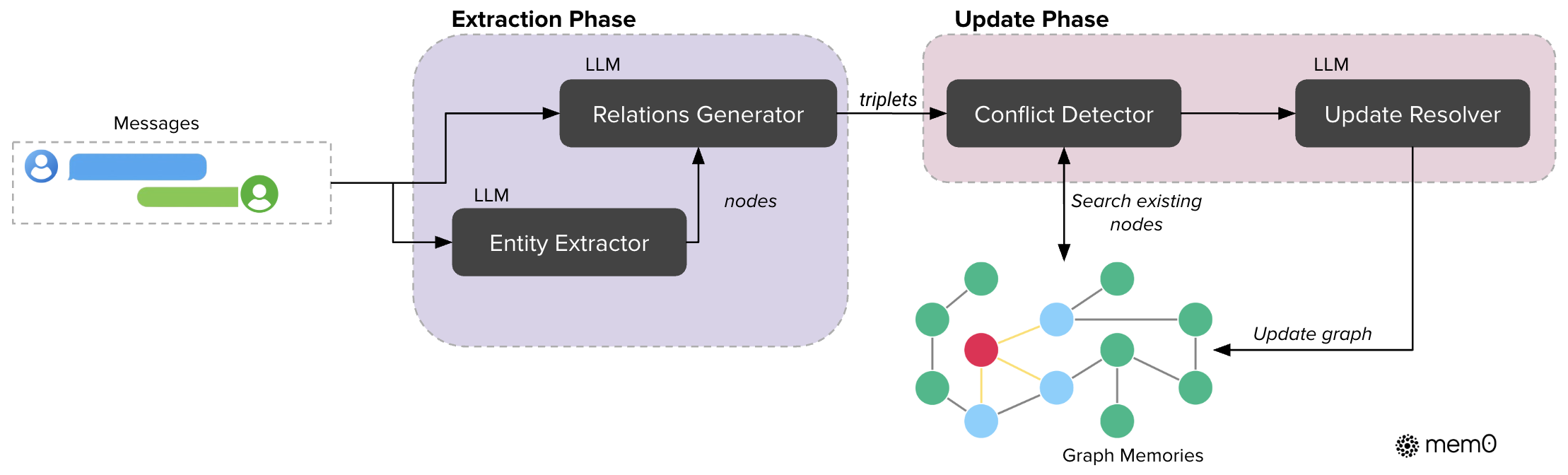
Figure 3: Graph-based memory architecture of Mem0 showcasing entity extraction and update phases.
This graph-centric model supports hierarchical memory architectures, providing explicit relational links that aid multi-hop and temporal reasoning tasks, thus improving overall conversational coherence.
Experimental Evaluation
The efficacy of Mem0 and its graph-based variant was rigorously evaluated against multiple baselines using the LOCOMO dataset. These experiments covered diverse question types, including single-hop, multi-hop, open-domain, and temporal queries. Mem0 consistently outperformed other memory systems in accuracy and computational efficiency, proving its capability in both single-turn and complex integrative tasks. The graph-based variant further enhanced performance in tasks requiring complex relational reasoning.
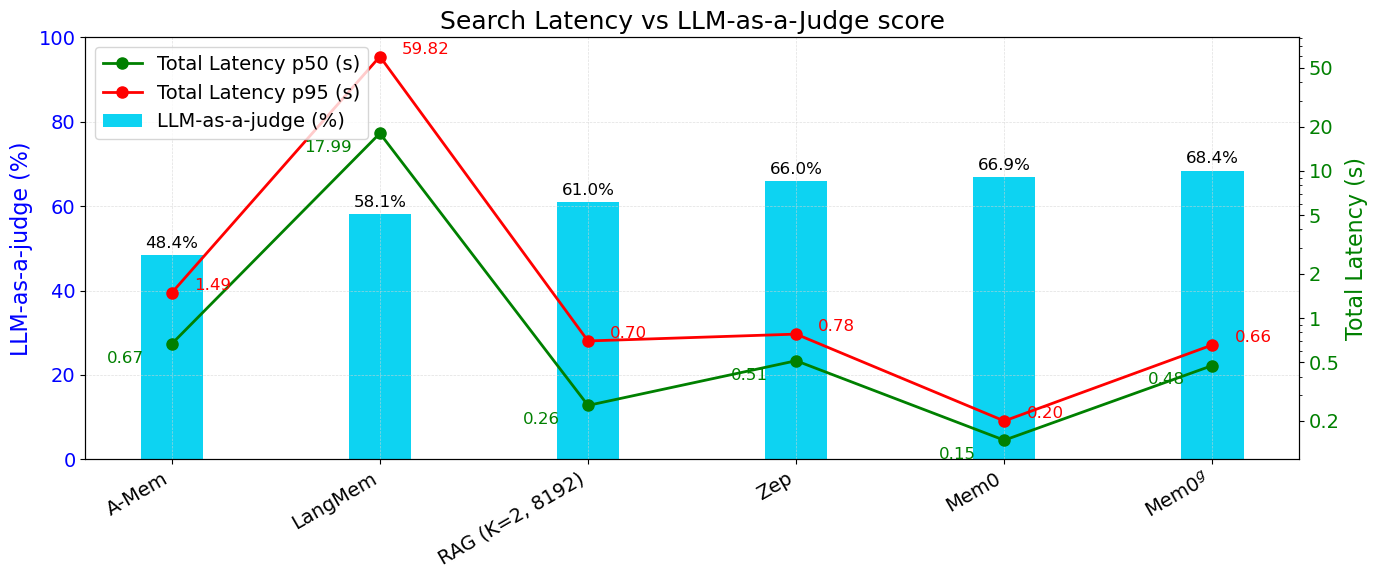
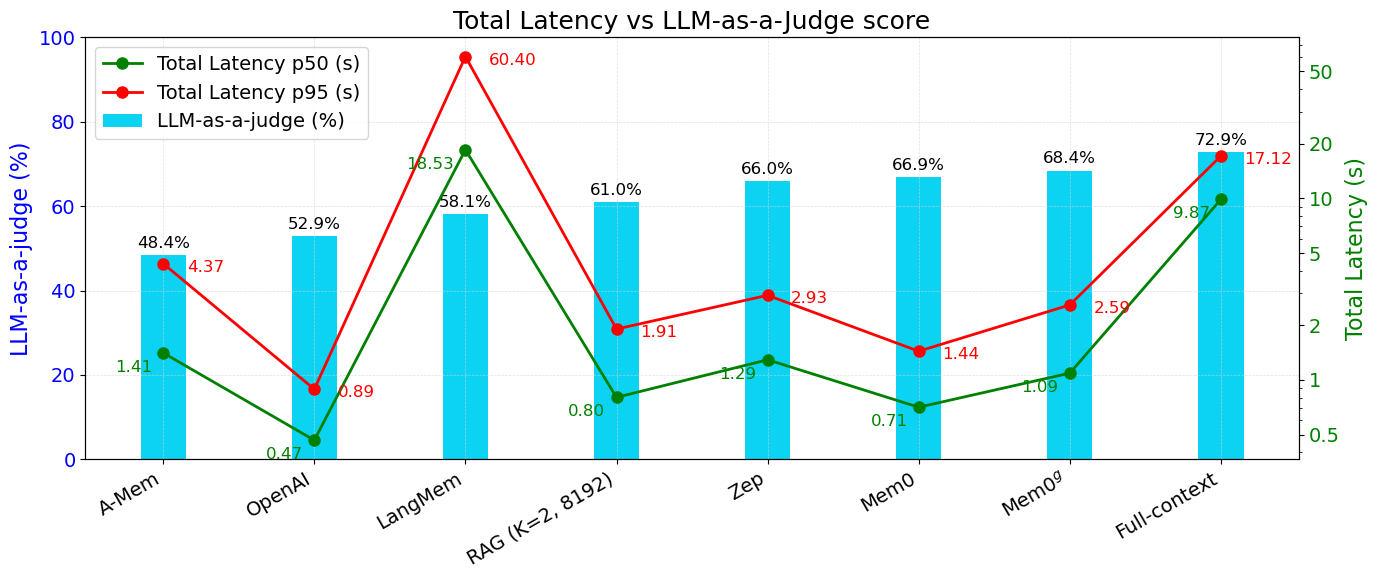
Figure 4: Latency comparison across different memory methods, including Mem0 and other baselines.
Implications and Future Directions
Mem0’s architecture represents a substantial advancement in memory systems for AI agents, offering significant improvements in conversational coherence and computational efficiency. Future developments could focus on refining graph operations to enhance the retrieval processes and integrating this memory architecture into multimodal interaction systems. The ability to cultivate reliable, context-rich AI agents holds promise for applications in personal tutoring, healthcare, and personalized assistance.
Conclusion
Mem0 and its variants lay the groundwork for the next generation of conversational AI agents that can maintain consistent dialogues over extended periods. By dynamically capturing and structuring memory, these systems alleviate inherent limitations of fixed context windows and offer a scalable solution for real-world AI deployments. The research highlighted here not only underscores the importance of integrating persistent memory mechanisms in AI systems but also paves the way for more robust and effective LLM-driven agents capable of long-term personalized interaction.

