When Reasoning Meets Its Laws
Abstract: Despite the superior performance of Large Reasoning Models (LRMs), their reasoning behaviors are often counterintuitive, leading to suboptimal reasoning capabilities. To theoretically formalize the desired reasoning behaviors, this paper presents the Laws of Reasoning (LoRe), a unified framework that characterizes intrinsic reasoning patterns in LRMs. We first propose compute law with the hypothesis that the reasoning compute should scale linearly with question complexity. Beyond compute, we extend LoRe with a supplementary accuracy law. Since the question complexity is difficult to quantify in practice, we examine these hypotheses by two properties of the laws, monotonicity and compositionality. We therefore introduce LoRe-Bench, a benchmark that systematically measures these two tractable properties for large reasoning models. Evaluation shows that most reasoning models exhibit reasonable monotonicity but lack compositionality. In response, we develop an effective finetuning approach that enforces compute-law compositionality. Extensive empirical studies demonstrate that better compliance with compute laws yields consistently improved reasoning performance on multiple benchmarks, and uncovers synergistic effects across properties and laws. Project page: https://lore-project.github.io/

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching and testing “thinking rules” for AI models that solve problems step by step. These models are called Large Reasoning Models (LRMs). The authors noticed that even strong LRMs sometimes think in strange ways—for example, using more steps on easier parts of a problem than on the harder combined version. To fix this, they propose simple laws that good reasoning should follow and build tests to check whether LRMs obey these laws. They also show a training method that helps models follow the laws better and, as a result, solve problems more accurately.
Key Objectives
The paper asks three simple questions:
- Can we describe how a good AI should “think” in clear, general rules?
- Do today’s popular AI reasoning models follow these rules?
- If not, can we train them to follow the rules—and does that make them better problem-solvers?
Methods and Approach
The “Laws of Reasoning”
The authors propose two main laws that good reasoning should follow:
- Compute Law (how much the model thinks): The amount of thinking (like the number of words or steps the model writes before giving an answer) should grow roughly in proportion to how hard the question is. Analogy: If a recipe has more steps, you should spend more time cooking. More steps → more effort.
- Accuracy Law (how often the model is right): As questions get harder (more steps needed), accuracy usually drops—often quickly. Analogy: The longer the set of instructions, the easier it is to make a mistake somewhere.
Because measuring the exact “difficulty” of a question is hard, they use two easier-to-check properties as proxies:
- Monotonicity: Harder questions should make the model think more and be less accurate. Analogy: Longer chores take more time, and you’re more likely to slip up.
- Compositionality: If a task has two independent parts (like first do a sum, then do a square), the total thinking should be roughly the sum of thinking needed for each part alone; and the chance of getting both parts right should be the product of the two chances. Analogy: Cleaning your room and mowing the lawn shouldn’t overlap—doing both should take the time of each added together, and the chance you do both perfectly is the chance of each multiplied.
Benchmarks to Test the Laws
They build two tests:
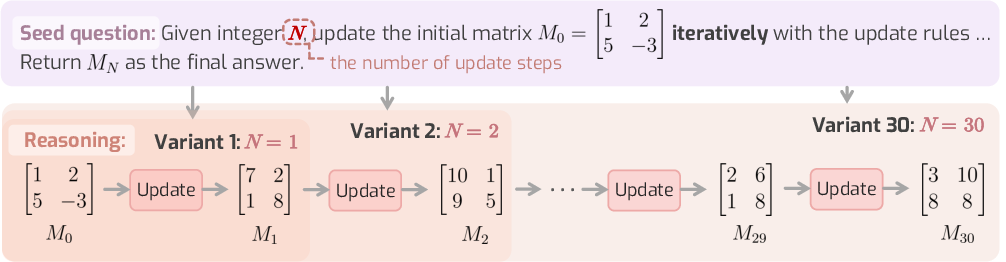
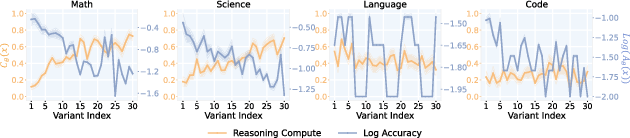
- LoRe-Mono (for monotonicity): They create sets of questions where difficulty increases in controlled steps (like repeating an operation more times). Then they measure whether models think more and get less accurate as difficulty goes up.
- LoRe-Compo (for compositionality): They pair two independent sub-questions (from different math topics) and compare the model’s thinking on each alone versus the combined question. Ideally, thinking on the combined question ≈ thinking on part 1 + part 2.
A Training Method to Enforce the Law
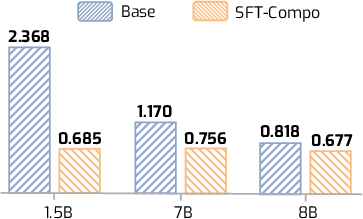
They propose a simple fine-tuning method (SFT-Compo) that shows the model examples where the combined question’s reasoning length closely matches the sum of the lengths for each part. In other words, the training data is chosen to encourage additive thinking for combined tasks.
Main Findings
- Most current LRMs pass the monotonicity test: they usually think more on harder questions and are less accurate as difficulty rises.
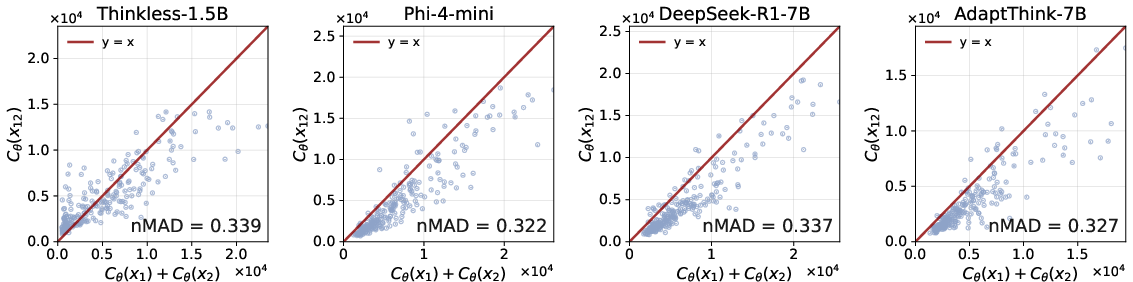
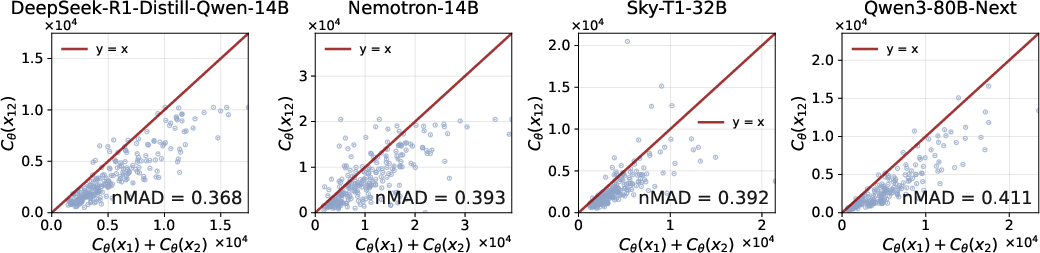
- But many fail the compositionality test: they don’t allocate the right amount of thinking to combined problems (they overthink or underthink), and the accuracy on two-part questions doesn’t behave as expected.
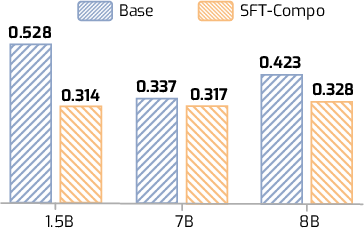
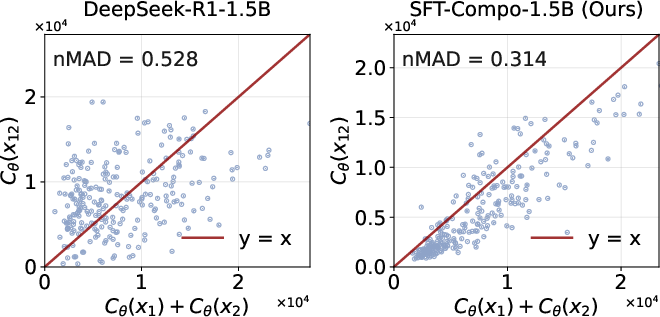
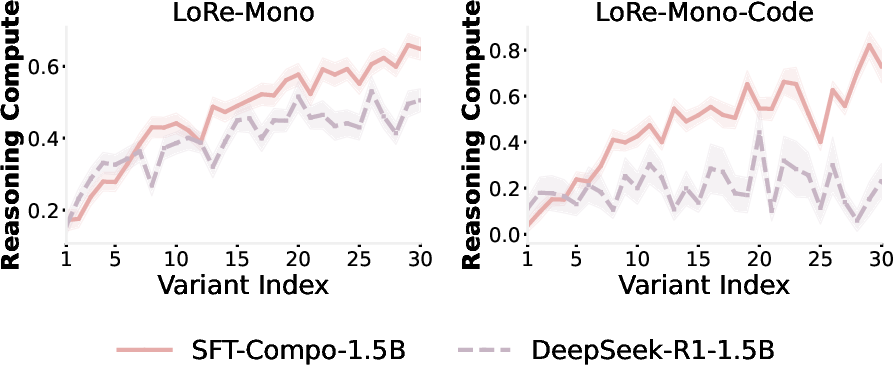
- The new training method (SFT-Compo) improves compositionality a lot: After fine-tuning, models’ thinking on combined tasks becomes much closer to the sum of the two parts.
- Better compositionality leads to better performance: Models trained with SFT-Compo get higher scores on several math and science benchmarks (like GSM8K, MATH500, AIME, AMC, and OlympiadBench).
- Bonus synergy: Improving compositionality also helps monotonicity and even improves how accuracy behaves on combined questions. In short, following one law tends to help with the others.
Why It’s Important
- It’s not enough for an AI to be smart—it should think in a sensible way. If a model overthinks easy parts or underthinks hard ones, it wastes effort and makes more mistakes.
- Clear laws give us simple targets: Designers can check if models follow the laws and train them to do better.
- The approach is practical: The tests (LoRe-Mono and LoRe-Compo) are easy to run, and the training method is straightforward yet effective.
Implications and Impact
- More reliable problem-solving: Models that allocate thinking according to difficulty and combine tasks sensibly are more dependable.
- Better training strategies: The laws guide how we build datasets and choose examples for fine-tuning.
- Generalizable improvements: Enforcing these laws doesn’t just help in one place—it improves multiple aspects of reasoning at once.
- Long-term: As AI is used for tougher real-world tasks (science, engineering, planning), these laws can help ensure the AI thinks efficiently, saves time, and reduces mistakes.
In short, this paper gives simple, human-like “rules of thinking” for AI models, shows how to test them, and proves that training models to follow these rules makes them better at solving problems.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. These items are intended to guide future research directions.
- Specify the exact “certain conditions” under which compute/accuracy monotonicity and compositionality imply the linear compute law and exponential accuracy law; formalize and empirically validate these assumptions on real tasks, not just synthetic constructions.
- Develop practical estimators or proxies for question complexity κ(x) beyond monotonicity/compositionality, and validate their calibration; investigate whether κ(x) can be predicted from input/task features or learned via a verifier/solver model.
- Rigorously test the accuracy law’s independence assumption (stepwise error independence) and its exponential decay form using tasks with known step counts; quantify and model correlated errors, self-correction, and redundancy in reasoning chains.
- Replace reasoning-token length as the sole compute metric with model-agnostic measures of actual computation (e.g., FLOPs, KV-cache operations, time-to-solution); assess sensitivity of results to tokenization scheme, language, and model architecture.
- Quantify the dependence of αθ (compute scaling constant) and λθ (accuracy decay rate) on decoding strategies (temperature, top-p, sampling vs. greedy), and report how conclusions change across decoding regimes.
- Measure and report truncation rates under the fixed maximum generation lengths (e.g., 10k–20k tokens), and analyze how truncation biases compute and accuracy estimates—especially for high-complexity questions and composite prompts.
- Strengthen the independence operationalization: move beyond coarse subject labels to fine-grained, validated concept sets per question; provide automated concept tagging and overlap detection to ensure true independence in compositions.
- Test compositionality beyond math-only LoRe-Compo: create cross-domain compositions (e.g., math + code, science + language) and intra-domain concept-disjoint pairs; examine whether additivity holds across domains and modalities.
- Study the effect of connector prompt c and order (Q1→Q2 vs. Q2→Q1) on compute and accuracy compositionality; evaluate robustness to varying connector styles, instructions, and prompt scaffolding.
- Expand LoRe-Mono beyond repeated-operation templates to include more natural problems with heterogeneous steps; assess whether monotonicity holds without per-question compute normalization and in non-synthetic datasets.
- Report statistical uncertainty (confidence intervals, significance tests) for Spearman correlations and nMAD metrics; assess stability across random seeds, numbers of samples per question, and dataset subsampling.
- Analyze failure modes of compositionality: categorize when models overthink sub-questions, underthink composites, or fuse steps in non-additive ways; provide qualitative error taxonomies and diagnostic tools.
- In SFT-Compo, the selection objective uses only length-matching; investigate richer alignment signals (e.g., structural matching between r12 and [r1; r2], step-level segmentation, explicit “solve Q1 then Q2” markers) to enforce logical, not just length, compositionality.
- Conduct ablations on teacher-model reliance: compare SFT-Compo using student-generated vs. teacher-generated chains, varying K, dataset size, and selection strategies; quantify how much gains are due to distillation vs. compositional enforcement.
- Measure the net compute cost of SFT-Compo at test time: does enforcing compositionality increase or decrease average reasoning tokens, latency, or energy usage; characterize performance–compute trade-offs.
- Provide causal evidence for the reported “synergistic effects” (compute compositionality improving monotonicity and accuracy compositionality), e.g., via controlled interventions, mediation analysis, or instrumented training experiments.
- Estimate and empirically validate the overhead term o(κ): quantify the fraction of “introductory and transition tokens” across complexity levels, and test the sublinear claim across models and tasks.
- Extend the laws to dependent compositions: characterize expected sub-additivity or super-additivity when sub-questions share concepts or intermediate results; define and test generalized compositionality bounds under overlap.
- Explore multi-turn and interactive settings (tool use, external memory, code execution), and multimodal reasoning (vision, speech): do the proposed laws and properties hold when reasoning involves actions or cross-modal integration?
- Evaluate on larger, more diverse models (including closed-source LRMs like o1) and broader benchmarks; assess generalization across families, sizes, and training paradigms.
- Control for temperature differences across model families (e.g., 0.6 vs. 0.8) to remove confounds in cross-model comparisons; standardize decoding or report per-decoder analyses.
- Provide stronger reproducibility evidence for independence and complexity construction (e.g., audits for periodicity/shortcuts in LoRe-Mono, public concept annotations for LoRe-Compo, connector variants).
- Investigate automatic test-time compute allocation using the laws (e.g., estimate κ(x) and set target compute Cθ(x) ≈ αθ κ(x)); compare law-guided controllers to heuristic methods (e.g., early stopping, draft-and-verify).
- Study whether enforcing compositionality affects robustness (adversarial prompts, paraphrases), hallucination rates, and calibration; report safety and reliability implications of longer or more structured CoT.
- Examine whether improved benchmarks performance arises from better compositionality vs. simply longer reasoning; disentangle effects by matching compute budgets or using compute-controlled evaluation.
Practical Applications
Overview
The paper introduces the Laws of Reasoning (LoRe)—a principled framework linking task complexity to model reasoning compute and accuracy—together with LoRe-Bench (LoRe-Mono for monotonicity and LoRe-Compo for compositionality) and SFT-Compo, a simple supervised fine-tuning recipe that enforces compute-law compositionality. Empirically, enforcing compositionality improves general reasoning across diverse benchmarks and yields synergistic gains in monotonicity and accuracy compositionality. Below are practical applications, organized by time horizon.
Immediate Applications
The following applications can be deployed now using the paper’s metrics, benchmarks, and SFT-Compo recipe with existing LRM infrastructures.
- Bolded items are application names; italic text indicates the primary sector(s). Each item includes a short description, candidate tools/workflows, and feasibility notes.
- Bolded applications use LoRe-Bench to measure monotonicity/compositionality; “SFT-Compo” denotes the paper’s compositionality-enforcing fine-tuning.
- States dependencies such as data access, labels, teacher model availability, and model/control access.
- Reasoning Compute and Accuracy refer to the definitions in the paper; compositionality is measured by normalized MAD (nMAD), monotonicity via Spearman correlations.
Immediate Applications
- Reasoning Compliance and Regression Suite for Model Release QA
- Sector: software, MLOps, foundation model providers
- What: Add LoRe-Mono (monotonicity) and LoRe-Compo (compositionality) gates to pre-release checks. Fail deployment if compute compositionality deviation (nMAD) exceeds a policy threshold or if monotonicity correlations fall below target.
- Tools/workflows: LoRe-Bench integration in CI; dashboards tracking Spearman and nMAD; automated alerts; per-domain regression curves.
- Dependencies/assumptions: Repeated sampling for stable estimates; stable decoding settings; access to long context windows; domain-wise concept labels (for independence) or subject tags.
- SFT-Compo Fine-Tuning Package to Upgrade Existing Reasoning Models
- Sector: software, education, codex-style assistants, open-source models
- What: Apply SFT-Compo to existing LRMs (1.5B–8B+) to improve compute compositionality and overall Pass@1 on GSM8K, MATH-like, and exam-style benchmarks.
- Tools/workflows: Triplet construction (x1, x2, x1⊕x2); teacher sampling (K≈8); selection of correct triple that minimizes |len(r1)+len(r2)−len(r12)|; 3.9K+ pairs SFT; evaluation on LoRe-Compo and task benchmarks.
- Dependencies/assumptions: Access to model weights; teacher model for sampling correct chains; domain taxonomy to approximate independence; license compliance.
- Adaptive Reasoning-Budget Controller for Inference Cost and Latency
- Sector: software, enterprise AI platforms, contact centers
- What: A controller allocates token budgets proportional to estimated complexity and enforces additivity for composite requests. It reduces overthinking on simple tasks and flags underthinking on complex ones.
- Tools/workflows: Lightweight complexity estimators; budget policy mapping complexity→max reasoning tokens; early-stop/continue heuristics; composite-task checker that compares observed compute vs. additive expectation.
- Dependencies/assumptions: Reliable complexity proxy (e.g., structural features, task templates, or learned estimator); controllable decoding; latency/cost SLAs.
- Human-in-the-Loop Escalation Policies Based on Accuracy Law
- Sector: healthcare (non-diagnostic support), finance (analyst copilot), legal ops, customer support
- What: Use the accuracy law’s exponential decay with complexity to trigger human review/secondary model routing when predicted complexity crosses a threshold.
- Tools/workflows: Complexity scoring; risk thresholding; escalations to specialists; explainability panel showing why escalation happened.
- Dependencies/assumptions: Valid complexity proxy for the domain; calibrated mapping from complexity to expected error; domain safety policies.
- Curriculum and Assessment Design for Math/Logic Tutoring Systems
- Sector: education technology
- What: Generate graded problem sets with guaranteed complexity ordering (LoRe-Mono) and compose independent subproblems to assess compositional mastery. Apply SFT-Compo to tutoring LRMs to reduce hallucinations on multi-part tasks.
- Tools/workflows: Programmatic variant generation; per-lesson monotonicity curves for compute and log-accuracy; remediation plans when compositionality is weak.
- Dependencies/assumptions: Correctness-verifiable tasks; concept taxonomies; privacy-safe student data handling.
- Code Assistant Reliability across Composite Tasks
- Sector: software engineering
- What: Evaluate and enforce compute additivity on composite coding tasks (e.g., write parser + add unit tests). Flag anomalies where the model allocates too little/too much reasoning to the composite relative to parts.
- Tools/workflows: LoRe-Compo-style triplets for code domains; IDE plugin with “compositionality deviation” badge; SFT-Compo for code models.
- Dependencies/assumptions: Clear decomposition into independent subtasks; sufficient teacher samples; controlled decoding lengths.
- Procurement/RFP Metric for “Reasoning Quality”
- Sector: enterprise buyers, government tech procurement
- What: Include LoRe metrics (monotonicity Spearman, nMAD for compositionality) and “reasoning cost per complexity unit” in RFPs to compare vendors beyond raw accuracy.
- Tools/workflows: Standardized LoRe-Bench suite in vendor evaluation; scoring rubric and thresholds.
- Dependencies/assumptions: Agreement on domain taxonomy and independence criteria; reproducible sampling protocols.
- Model Monitoring: Drift and Anomaly Detection in Reasoning Behavior
- Sector: MLOps, observability platforms
- What: Monitor production requests for monotonicity violations (e.g., compute increases on simpler variants) and compositionality deviations across composite tickets; trigger rollbacks or re-tuning.
- Tools/workflows: Online collectors computing rolling Spearman and nMAD; feature store for complexity proxies; alarms and explainers.
- Dependencies/assumptions: Access to anonymized prompts/telemetry; stable task distributions; privacy/PII compliance.
- Authoring Tools for LoRe-Compliant Data Curation
- Sector: data operations, LLM training shops
- What: Create data pipelines that generate complexity-ordered variants (LoRe-Mono) and independent pairings (LoRe-Compo) for new domains (science QA, business analytics).
- Tools/workflows: Template authoring UI; concept tagging; independence validator; programmatic generator; unit tests for shortcuts (e.g., periodicity checks).
- Dependencies/assumptions: Domain experts for concept sets; validator coverage; compute for large-scale generation.
- Consumer Assistant “Thinking Budget” Slider with Guardrails
- Sector: daily life, productivity apps
- What: Expose a UI control for reasoning depth that auto-adjusts to task complexity; warnings when composite queries likely exceed reliability thresholds; optional “split and solve” workflow.
- Tools/workflows: Complexity-to-budget mapping; composite task detection; additivity checker; explanation of trade-offs (cost vs. accuracy).
- Dependencies/assumptions: Reliable complexity signals; controllable reasoning length; user consent for longer generations.
Long-Term Applications
These require further research, scaling, or standardization, but are natural extensions of this work.
- Sector tags and feasibility dependencies are noted as above.
Long-Term Applications
- “LoRe Certified” Standards and Audits for Trustworthy Reasoning
- Sector: policy/regulation, certification bodies, enterprise governance
- What: Establish certification criteria around monotonicity/compositionality and publish “reasoning compliance” labels similar to safety or privacy seals.
- Tools/workflows: Standardized LoRe test suites per domain; third-party auditors; public scorecards.
- Dependencies/assumptions: Cross-industry consensus on metrics/thresholds; reproducible protocols; regulatory adoption.
- Agentic Systems with Compositional Compute Budgets
- Sector: robotics, autonomous agents, multi-tool orchestrators
- What: Plan agents that decompose goals into independent subgoals and allocate compute additively, using LoRe laws to schedule planning/search depth and terminate early when safe.
- Tools/workflows: Task graph builder with independence checks; compute allocator; dynamic re-planning when deviations occur.
- Dependencies/assumptions: Reliable subgoal independence detection; sound complexity estimation; real-time controls; safety validation.
- Safety-Critical Decision Support with Complexity-Aware Risk Calibration
- Sector: healthcare (clinician decision support), finance (risk), legal tech
- What: Use accuracy law to forecast error probability for multi-step decisions; embed LoRe gates that enforce human oversight at predicted risk thresholds; document compute-vs-risk rationale for audits.
- Tools/workflows: Complexity and error calibrators; oversight routing; post-hoc reasonability checks; audit trails.
- Dependencies/assumptions: Domain-aligned complexity models; strict validation; regulatory clearance; data governance.
- Cost-To-Quality Optimizers for Enterprise AI
- Sector: cloud AI platforms, FinOps
- What: Optimize token spend by matching compute to complexity, predicting diminishing returns via accuracy decay; allocate model sizes/ensembles per complexity class.
- Tools/workflows: Complexity routing to light vs. heavy models; budget-aware early-stopping; per-tenant cost-control policies.
- Dependencies/assumptions: Robust complexity predictors; access to multiple models; acceptance of variable latency.
- AutoML Objectives that Optimize LoRe Properties
- Sector: model training platforms
- What: Incorporate compositionality and monotonicity into training objectives (e.g., multi-objective SFT/LLM pretraining) to produce models with predictable scaling.
- Tools/workflows: Loss terms for compositional compute; curriculum that increases complexity and tests additivity; selection pressure based on LoRe scores.
- Dependencies/assumptions: Stable optimization of multi-objective losses; scalable LoRe data generation; compute budgets.
- Domain-General Independence Discovery and Concept Taxonomies
- Sector: foundational research, industry labs
- What: Learn or mine concept sets automatically and detect independence needed for compositionality training/evaluation beyond math and code (e.g., medical reasoning, causal inference).
- Tools/workflows: Concept discovery models; graph mining; causal/structural checks; human-in-the-loop validation.
- Dependencies/assumptions: High-quality labeled corpora; reliable proxy tasks; annotation budgets.
- Multimodal LoRe: Vision/Action + Language Reasoning Laws
- Sector: robotics, AR/VR, autonomous systems
- What: Extend compute/accuracy laws to multimodal policies (perception→planning→action), enforcing additive compute across independent sensory or task channels.
- Tools/workflows: Multimodal LoRe-Bench; compositional triplets spanning modalities; SFT-Compo variants for vision/text/action traces.
- Dependencies/assumptions: Long-context training for multimodal traces; verifiable correctness criteria; synchronized logs.
- Public Sector Procurement and Oversight Using LoRe Metrics
- Sector: government, public services
- What: Adopt LoRe-based thresholds for citizen-facing AI (tax, benefits, education) to ensure predictable behavior on composite and complex tasks before deployment at scale.
- Tools/workflows: Policy templates; red-team exercises focused on LoRe violations; continuous compliance monitoring.
- Dependencies/assumptions: Policy uptake; transparency from vendors; privacy and equity impact assessments.
- Personalized Learning Systems with Complexity-Calibrated Progression
- Sector: education
- What: Student models that tune reasoning depth to problem difficulty and explain expected accuracy trade-offs; adaptive curricula that manage cognitive load via compositional scaffolding.
- Tools/workflows: Learner complexity profiles; per-topic compositional practice; mastery gating using LoRe metrics.
- Dependencies/assumptions: Valid complexity measures for pedagogy; robust evaluation of learning outcomes; accessibility requirements.
- Software Supply Chain “Composable Reliability” Guarantees
- Sector: software, DevSecOps
- What: Declare and test guarantees that model-driven tools behave predictably when tasks are composed (e.g., code generation + verification + deployment).
- Tools/workflows: LoRe Compositional SLAs; pre-merge checks; integration tests measuring compute additivity and accuracy multiplicativity.
- Dependencies/assumptions: Clear task decomposition; automation-friendly independence criteria; developer adoption.
Cross-Cutting Assumptions and Dependencies
- Independence assumption: Compositionality depends on sub-questions being independent; operationalized via disjoint concept sets or subject labels. Mis-specification reduces validity.
- Complexity estimation: Practical systems need proxies (task structure, length, entity count, graph features, learned predictors). Calibration is domain-specific.
- Access and control: SFT-Compo requires model fine-tuning access, teacher sampling, and long-context decoding. Inference controllers need control over token budgets/decoding.
- Data and privacy: Benchmarks and monitoring require prompt/output sampling; ensure PII handling and compliance.
- Compute and cost: LoRe evaluations use multiple samples per prompt; training and monitoring incur non-trivial compute.
- Generalization limits: Paper focuses on text reasoning; extensions to multimodal and real-time systems require additional validation and domain-specific verifiers.
These applications translate the paper’s theoretical laws, evaluation benchmarks, and SFT-Compo method into actionable tools and policies that improve reliability, cost control, and safety of reasoning-centric AI systems across sectors.
Glossary
- Accuracy Law: A hypothesis that a model’s accuracy decays exponentially as question complexity increases. "we introduce the complementary accuracy law, which posits that overall accuracy should decay exponentially with increasing complexity."
- Accuracy-Complexity Compositionality: The property that the accuracy for a composite of independent questions equals the product of their individual accuracies. "For , if and are independent, their composite exhibits multiplicative accuracy:"
- Accuracy-Complexity Monotonicity: The property that accuracy does not increase as complexity increases. "For , the reasoning accuracy is monotonically non-increasing with complexity:"
- Autoregressive: A modeling approach where outputs (tokens) are generated sequentially, each conditioned on previous outputs. "Let denote an autoregressive large reasoning model."
- Binary verifier: A function that checks whether a candidate solution sequence is valid, returning 1 if valid and 0 otherwise. "Let be a binary verifier that accepts if and only if is a valid solution sequence for ."
- Chain-of-Thought (CoT): A technique where models produce intermediate reasoning steps before answers, often used for training and evaluation. "This is primarily because researchers generally overlook the high variability of Chain-of-Thought (CoT) data during the training phase."
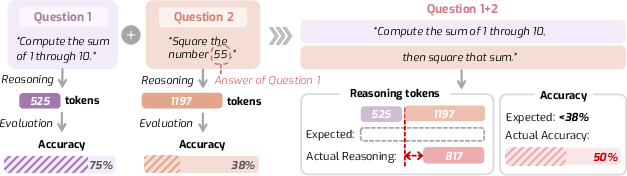
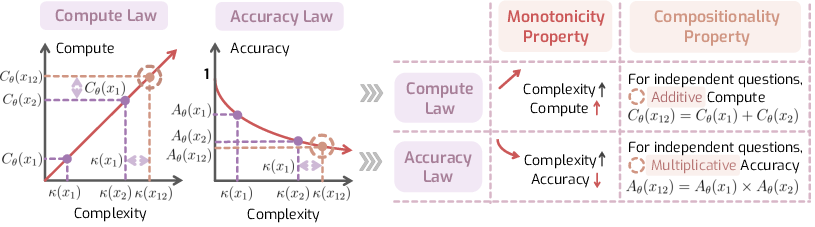
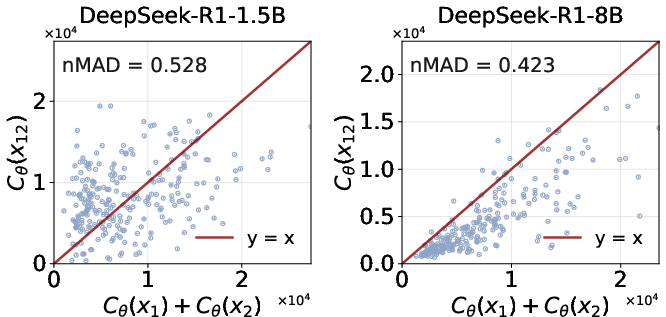
- Compositionality: The principle that reasoning about a composite problem should correspond to combining reasoning about its independent parts. "Evaluation shows that most reasoning models exhibit reasonable monotonicity but lack compositionality."
- Compute Law: A hypothesis that the amount of reasoning compute scales linearly with question complexity. "we present the central compute law, with a hypothesis that the reasoning budget should scale proportionally with question complexity."
- Compute-Complexity Compositionality: The property that compute for a composite of independent questions is approximately the sum of their individual computes. "For , if and are independent, their composite exhibits additive compute:"
- Compute-Complexity Monotonicity: The property that compute does not decrease as complexity increases. "For , the reasoning compute is monotonically non-decreasing with complexity:"
- Decay rate: The parameter governing the exponential decrease of accuracy with complexity in the accuracy law. "Equivalently, , where is the decay rate."
- Decoding strategy: The fixed method used by a model to generate outputs (e.g., sampling or greedy), assumed constant in analyses. "We assume a fixed decoding strategy by default"
- Decoding temperature: A parameter controlling the randomness of sampling during generation. "with a fixed decoding temperature (0.6 for the DeepSeek family and 0.8 for the Phi-4 family from their technical reports)"
- Independence (of questions): A condition where two questions’ complexities add under composition, implying no overlapping reasoning. "For , and are independent if the complexity of their composition is additive, i.e., "
- Large Reasoning Models (LRMs): Foundation models specialized for multi-step reasoning. "Large Reasoning Models (LRMs) such as OpenAI o1~\citep{OpenAIO1_24} have demonstrated unprecedented progress in approaching human-like reasoning capabilities."
- LoRe-Bench: A benchmark suite designed to evaluate monotonicity and compositionality in LRMs. "we introduce LoRe-Bench, a two-fold benchmark that leverages two tractable properties, monotonicity and compositionality, to examine LRMs."
- LoRe-Compo: A benchmark evaluating compositionality via paired independent math problems and their composition. "We build LoRe-Compo from MATH500~\citep{MATH500_24}, where each question is labeled by subject (e.g., Algebra, Geometry)."
- LoRe-Mono: A synthetic benchmark with controlled complexity increases to test monotonicity of compute and accuracy. "we construct LoRe-Mono, a synthetic benchmark where questions are carefully curated and validated to follow known complexity orderings"
- Mean Absolute Deviation (MAD): A scale-dependent metric used to measure deviation from additive or multiplicative compositionality. "We therefore quantify the degree to which a model follows this property using the mean absolute deviation ():"
- Normalized MAD (nMAD): A scale-normalized version of MAD to enable fair comparison across different scales. "To address this, we adopt the Normalized MAD ():"
- Pass@1: The probability that the first sampled solution is correct; a standard accuracy metric in reasoning benchmarks. "All numbers report Pass@1 accuracy (\%) computed over 8 sampled outputs."
- Reasoning accuracy: The probability that the model’s final answer matches the ground truth when reasoning and answering. "The reasoning accuracy is defined as the probability that the model, when generating a reasoning chain and an answer given input , produces a final answer that matches the ground truth."
- Reasoning compute: The expected number of reasoning tokens generated by the model for a question. "The reasoning compute on question is defined as the expected number of reasoning tokens generated by the model"
- Spearman correlation coefficient: A nonparametric measure of rank correlation used to assess monotonic relationships. "We use the Spearman correlation coefficients "
- Sublinear term (small-o): An asymptotic term that grows slower than linearly and becomes negligible relative to complexity. "o(\kappa(x)) denotes a small systematic overhead that is sublinear, i.e., when ."
- Thinking-then-answering paradigm: A generation approach where models first produce reasoning chains and then final answers. "LRMs adopts the thinking-then-answering paradigm~\citep{DeepSeekR125, Phi4-Reasoning, Gemini25}"
- Unit-cost primitive step: A single transition of a deterministic Turing machine used to measure computational complexity. "Let a unit-cost primitive step denote a single valid transition of a fixed deterministic Turing machine"
Collections
Sign up for free to add this paper to one or more collections.

