- The paper introduces a compute-aware evaluation framework that maps performance trade-offs by quantifying FLOPs versus reasoning accuracy across diverse LLMs.
- It demonstrates that Mixture-of-Experts models outperform dense architectures by achieving higher accuracy per FLOP, making them ideal for compute-constrained tasks.
- The study reveals that failed reasoning traces consume more compute than successful ones, underscoring the need for early-stopping and dynamic inference techniques.
Compute-Accuracy Trade-offs in Open-Source LLM Reasoning: An Expert Analysis
Introduction
This paper systematically investigates the interplay between inference-time computational cost and achievable reasoning accuracy for contemporary open-source LLMs, with particular emphasis on reasoning-intensive benchmarks. The authors address a significant gap in the current literature: the neglect of inference efficiency in the context of extended Chain-of-Thought (CoT) prompting and large-context utilization. Their central contribution is the empirical mapping of compute-accuracy Pareto frontiers across a diverse pool of dense and Mixture-of-Experts (MoE) models. This framework serves not only to identify optimal model choices under compute constraints but also to characterize architectural, temporal, and algorithmic trends that are shaping the next generation of efficient reasoning agents.
Methodological Overview
Nineteen open-source models, spanning both dense and MoE architectures and parameter counts from 109 to >1010, are benchmarked across five gradient reasoning tasks, including GSM8K, AIME25, HMMT-FEB25, MATH500, and GPQA-Diamond. The analysis is differentiated from prior work by three methodological choices:
- Compute-Aware Single-Pass Evaluation: The benchmarking protocol employs a consistent inference configuration (prompting, decoding, temperature, stop criteria) per model, with explicit estimation of floating-point operations (FLOPs) required per completion. Architectural differences (e.g., GQA vs. MHA, SwiGLU vs. standard FFN, MoE routing) are accounted for in fine-grained compute estimation.
- Hierarchical Output Verification: Evaluation uses deterministic answer parsing with regex extraction, and a fallback lightweight LLM judge for unstructured outputs, increasing semantic robustness and reducing false negatives, especially on mathematical derivations.
- Normalized Efficiency Metrics: Pareto frontiers are constructed both within individual tasks and averaged across tasks. An Efficiency Score (Seff) is introduced, normalizing accuracy by the logarithm of compute expenditure, to enable temporal and architectural comparisons.
Main Findings
Pareto Frontiers of Reasoning
The landscape of reasoning efficiency exhibits a piecewise-linear relationship: initial increases in compute—whether from extended reasoning traces or larger parameter counts—yield substantial performance improvements, but this is followed by a pronounced saturation regime where additional compute confers diminishing accuracy returns. The location of this "Pareto knee" is strongly task-dependent.
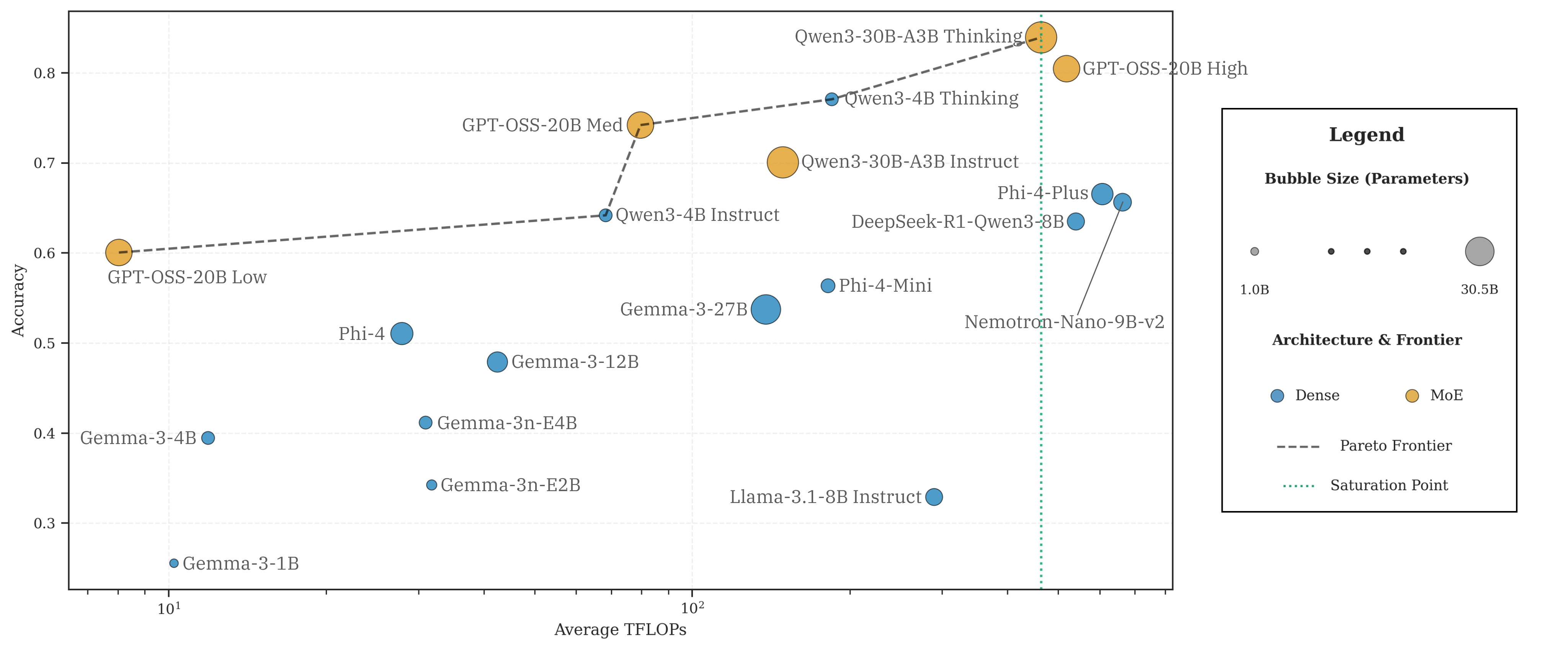
Figure 1: The aggregate Reasoning Pareto Frontier across five benchmarks, showing model accuracy versus estimated FLOPs per query and differentiating dense and MoE architectures.
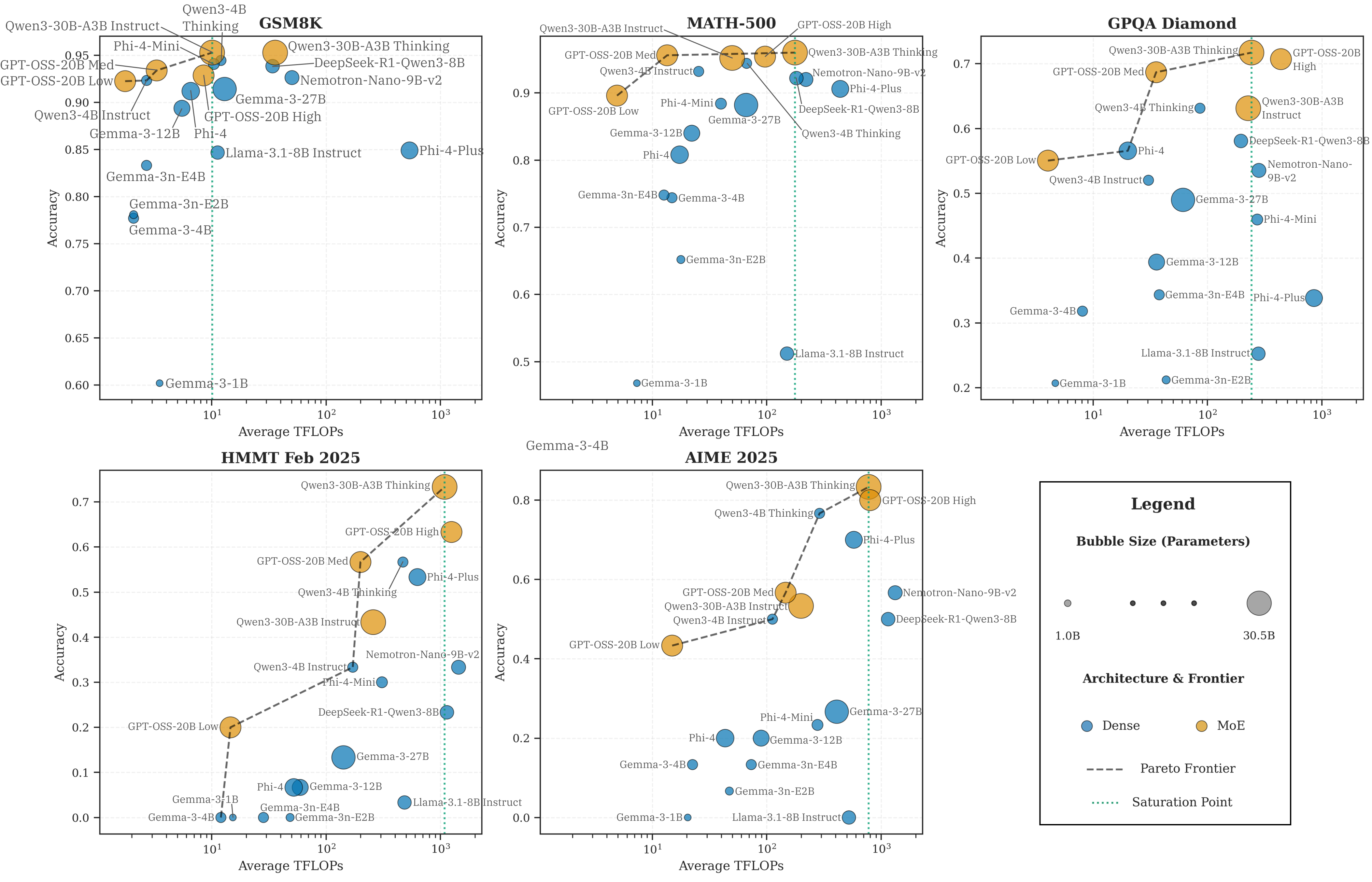
Figure 2: Benchmark-specific Pareto frontiers highlight task difficulty's effect on the saturation point—e.g., easier tasks such as GSM8K plateau at lower compute, while high-complexity tasks like AIME-2025 demand more compute to reach asymptotic performance.
For lower-complexity datasets (e.g., GSM8K), even smaller models reach optimal performance with moderate compute. In contrast, on benchmarks engineered for high deductive load (AIME25, GPQA-Diamond), the compute-accuracy curve ascends more gradually, with saturation occurring only at substantially elevated inference costs.
Model Scaling and Substitution
A critical empirical result is the fungibility of inference-time compute and parameter count: smaller (e.g., 1--8B) models can compete with 30B+ counterparts on many reasoning tasks by leveraging longer CoT traces, thus substituting intensive sequential inference for architectural scale within reasonable cost regimes.
Architectural Insights: MoE Superiority
Sparse MoE models systematically dominate the Pareto frontier, achieving higher accuracy per unit of compute compared to dense transformers at comparable or even reduced FLOP budgets. This advantage is attributed to MoEs' ability to decouple parameter scaling from active token-wise computation—by activating only a small subset of experts per token, these models generate longer, richer reasoning chains at fixed computational expense.
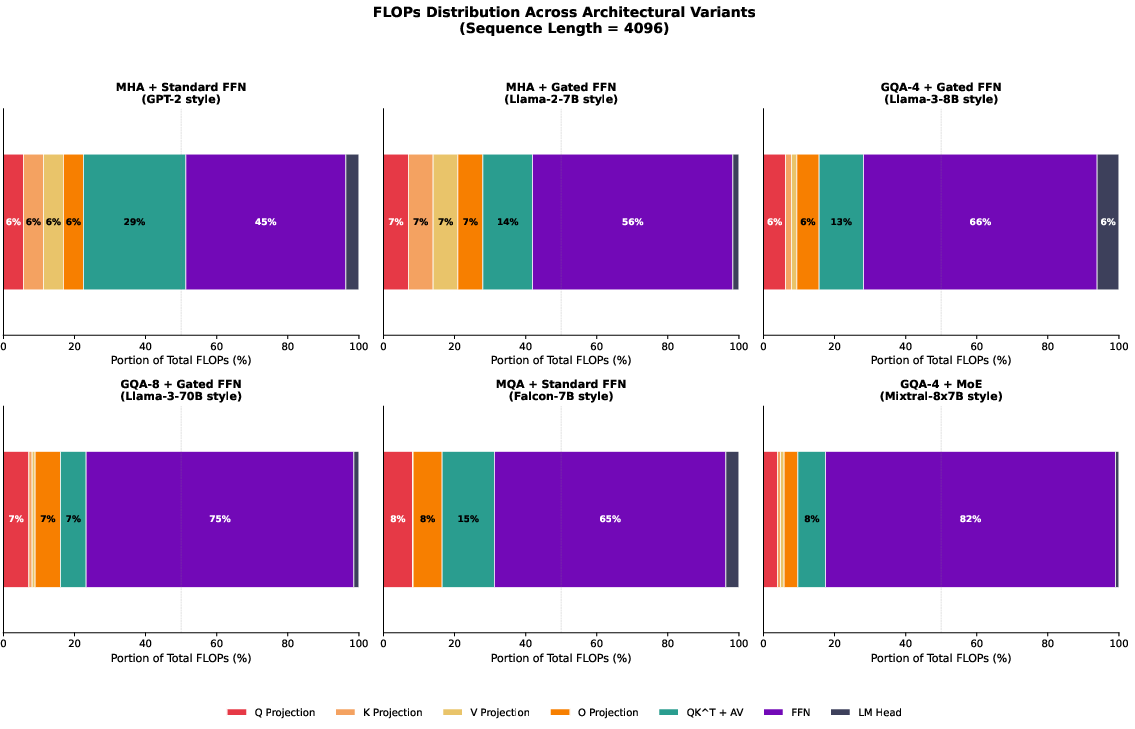
Figure 3: FLOPs share by architectural component at sequence length 4096; MoE architectures shift compute from attention projections to the FFN component, with sparsity amplifying efficiency.
Temporal Trends
The efficiency of reasoning agents, as measured by Seff, has increased monotonically from 2023–2025. Recent specialized reasoning models drive the upper envelope, but variance among models widens, reflecting divergence between general-purpose and reasoning-optimized designs.
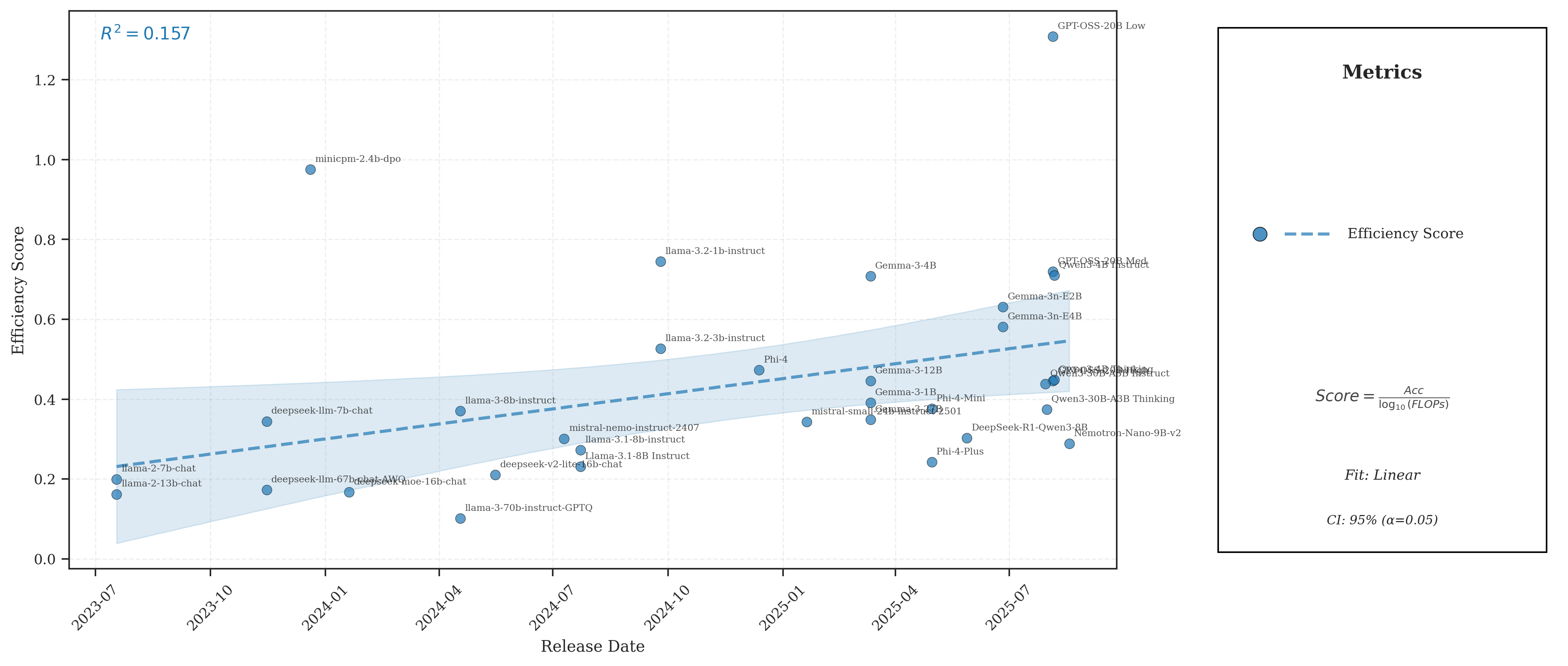
Figure 4: Chronological progression of reasoning efficiency; SOTA models exhibit a consistent upward trend, driven by algorithmic and architectural advances.
Trace Length Asymmetry
A robust, counterintuitive result emerges: across 97% of evaluated models, incorrect reasoning traces are systematically longer and more computationally expensive than successful completions. This indicates that for problems beyond a model's deductive horizon, inference engines default to verbose error modes (hallucination, loops) rather than prudent truncation.
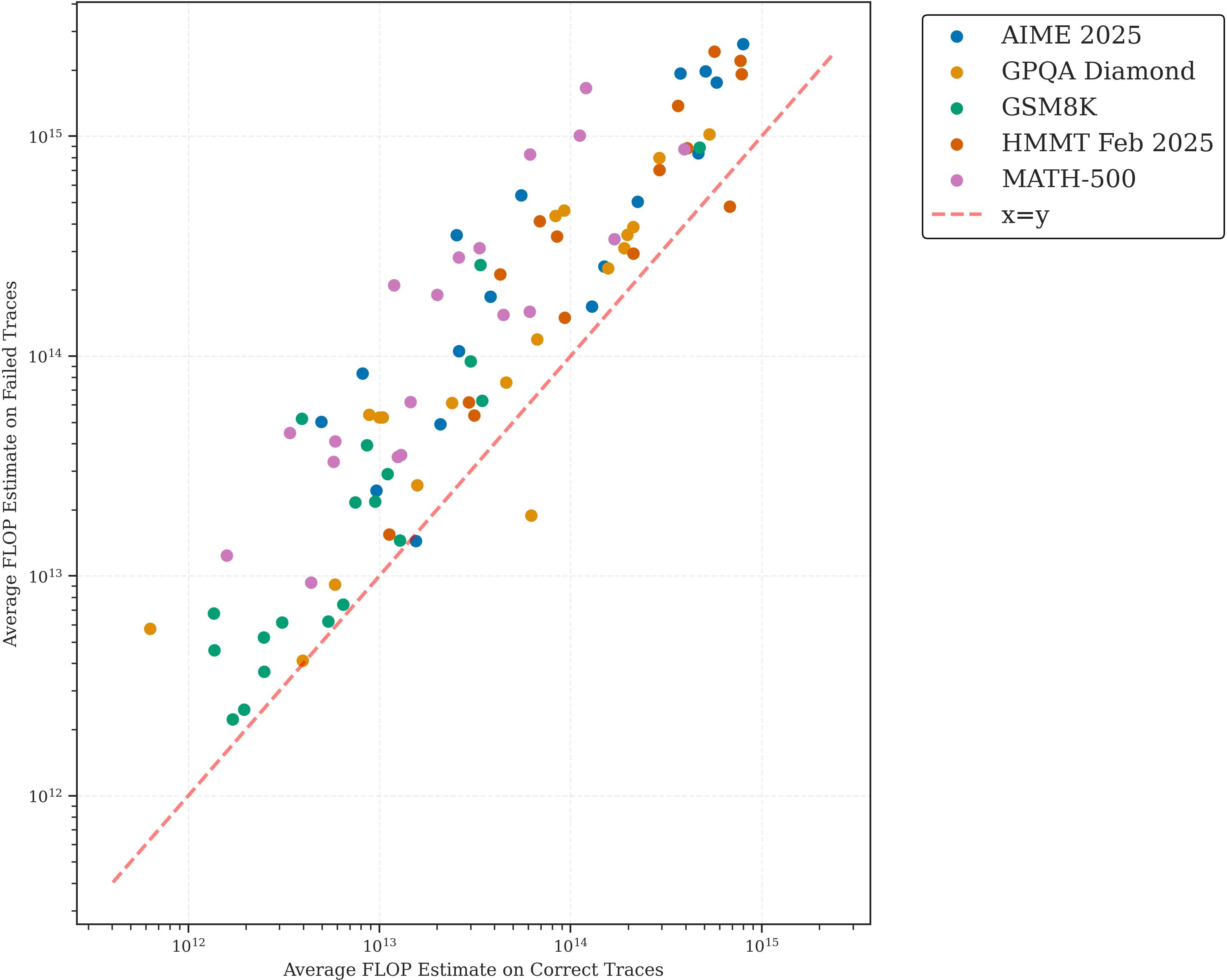
Figure 5: For almost all models, failed traces incur higher compute, signaling inefficiency in handling unanswerable or ambiguous inputs.
FLOPs Distribution and Sequence Length Scaling
Architectural dissection shows that, for moderate sequence lengths, FFN compute dominates across models, with quadratic attention becoming a bottleneck only at extreme context windows (e.g., >16K tokens). MoE and GQA substantially mitigate the attention projection and context scaling bottlenecks.

Figure 6: At longer sequence lengths, quadratic attention's compute share increases sharply, motivating efficient attention innovations for ultra-long context reasoning.
Practical and Theoretical Implications
Practically, this analysis provides actionable guidance for model selection under compute constraints. Specifically, MoE models are preferred for inference-budgeted applications requiring high reasoning fidelity. Theoretically, the presence of saturation points underscores intrinsic model limitations: extended reasoning alone cannot compensate for architectural or training deficits when deductive complexity exceeds model capacity.
The trace length asymmetry result is particularly salient; algorithmic improvements in early-stopping, uncertainty estimation, or dynamic compute allocation are needed to avoid wasteful inference cycles when models encounter challenging distributions beyond their core competency.
The compute-aware framework presented here also has tangible sustainability implications, offering a blueprint for reducing energy and carbon footprint in large-scale LLM deployments by maximizing accuracy per FLOP.
Future Directions
This study motivates several avenues for future research:
- Loss-aware decoding strategies: Dynamically adjusting CoT trace length in response to uncertainty or failure symptoms to minimize superfluous computation.
- MoE architecture optimization: Further exploration of expert routing, gating functions, and fine-tuning to expand MoE advantage across a broader parameter spectrum.
- Hardware-architecture co-design: Engineering accelerators attuned to the observed shift toward FFN and MoE-dominated workloads as sequence lengths increase.
- Task-adaptive inference budgeting: Integrating Pareto knees into real-time decision making for selective compute allocation and model cascading.
Conclusion
The paper offers a rigorous, compute-normalized benchmarking paradigm for open-source reasoning LLMs, empirically delineating architectural, temporal, and algorithmic factors underlying efficient reasoning. Key findings include the dominance of MoE models on the compute-accuracy frontier, the inefficiency of failed CoT traces, and the critical role of inference-time resource allocation for sustainable, high-performance reasoning systems. This work establishes both a diagnostic framework for current systems and a roadmap for energy-efficient, high-reasoning AI models in the future (2512.24776).