- The paper introduces a novel framework, R-Horizon, for constructing multi-horizon benchmarks that enforce logical dependencies across sequential tasks.
- It demonstrates significant accuracy drops in LRMs as the reasoning steps increase, with models like DeepSeek-R1 and R1-Qwen showing steep performance degradation.
- Reinforcement learning with composed data improves token budget allocation and long-range reflection, offering an effective pathway to enhance LRM performance.
R-Horizon: Evaluating and Enhancing Long-Horizon Reasoning in Large Reasoning Models
Introduction
The R-Horizon framework addresses a critical gap in the evaluation and training of Large Reasoning Models (LRMs): their ability to perform long-horizon, multi-step reasoning across interdependent tasks. While recent advances in test-time scaling and Chain-of-Thought (CoT) prompting have improved LRM performance on isolated, single-horizon tasks, existing benchmarks and RL training paradigms fail to assess or incentivize reasoning over extended, logically connected problem sequences. R-Horizon introduces a systematic method for constructing multi-horizon benchmarks and training datasets by composing queries with explicit dependencies, enabling rigorous evaluation and targeted improvement of LRMs' long-horizon reasoning capabilities.
R-Horizon Data Composition Pipeline
R-Horizon constructs multi-step, interdependent reasoning tasks by filtering seed problems for key variables and composing them into dependency chains. For mathematical tasks, the pipeline extracts integer variables, identifies those critical to problem solvability, and links problems such that the solution to one becomes a required input for the next. This enforces strict sequential solving and logical dependency, amplifying the complexity of the reasoning horizon.
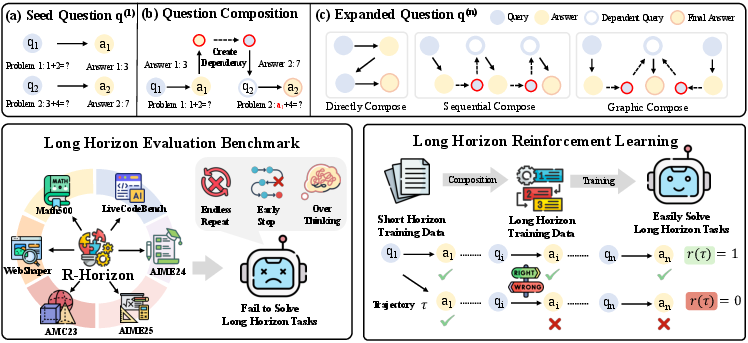
Figure 1: R-Horizon data composition pipeline for constructing long-horizon reasoning benchmarks and multi-horizon RL training data.
For code and agentic tasks, the composition is adapted to the nature of the domain, with code problems concatenated and agentic tasks decomposed into sub-questions based on structured data graphs. The resulting datasets span mathematics, code generation, and agentic web search, with variable horizon lengths.
Benchmarking Long-Horizon Reasoning
The R-Horizon benchmark comprises six datasets across mathematics (MATH500, AIME24, AIME25, AMC23), code (LiveCodeBench), and agentic tasks (WebShaper), each reconstructed to enforce multi-step dependencies. Evaluation employs an all-or-nothing metric: a response is correct only if all sub-problems are solved, with theoretical accuracy estimated as the product of atomic pass rates.
Empirical results reveal substantial performance degradation as the reasoning horizon increases. Even state-of-the-art models such as DeepSeek-R1 and Qwen3-235B-Thinking exhibit sharp drops in accuracy on composed tasks, with smaller models suffering more severe declines. For example, DeepSeek-R1's accuracy on AIME25 falls from 87.3% (n=1) to 24.6% (n=5), and R1-Qwen-7B drops from 93.6% (n=1) to 0% (n=16).
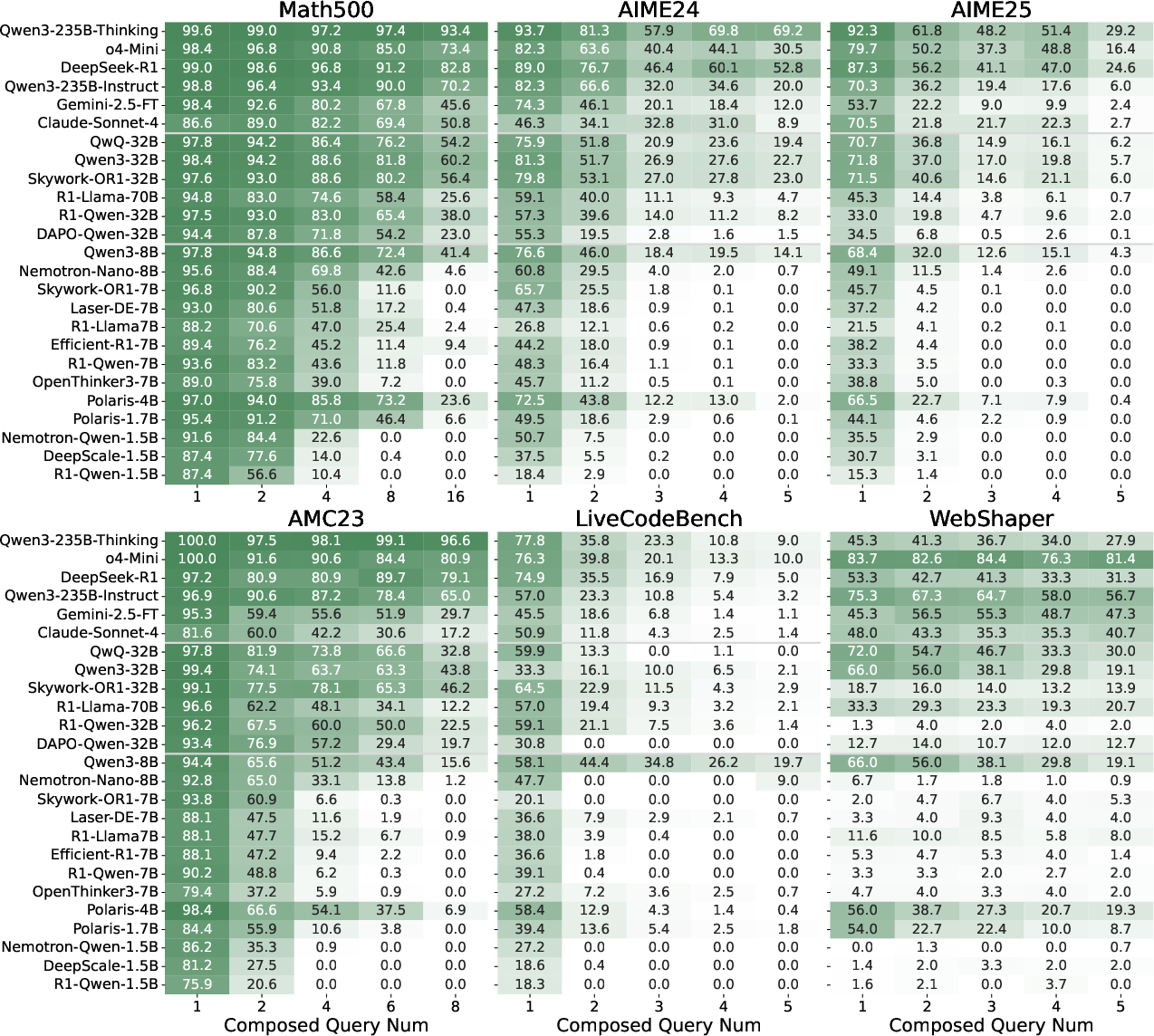
Figure 2: Evaluation results of R-Horizon Benchmark showing accuracy degradation with increasing reasoning horizon.
This degradation is consistent across task types and model scales, with code and agentic tasks exhibiting even steeper declines. The gap between actual and theoretical accuracy widens with horizon length, indicating that LRMs' effective reasoning length is limited and that they struggle to maintain performance as logical dependencies accumulate.
Error Analysis and Reasoning Dynamics
Detailed error analysis categorizes model failures into problem reasoning errors, dependency reasoning errors, early stops, and output truncation. As the number of queries increases, problem reasoning errors dominate, and dependency errors rise, though remain a minority. Premature termination and output truncation also become more frequent, reflecting models' inability to sustain coherent reasoning over long horizons.
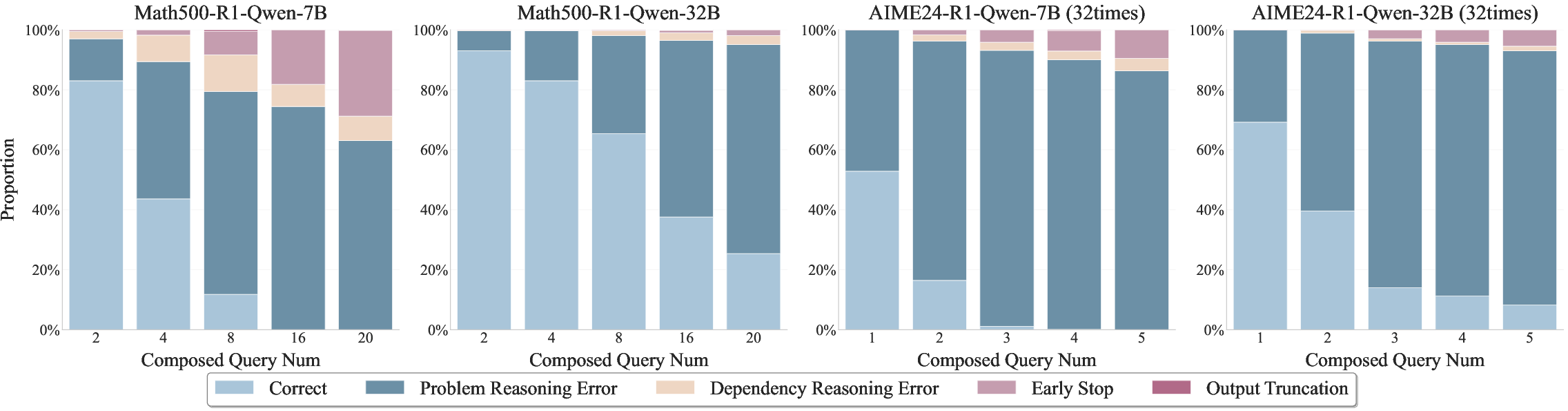
Figure 3: Error type distribution across different query numbers, highlighting the prevalence of reasoning and dependency errors as horizon increases.
Analysis of error positions shows that larger models can reason over longer contexts, but each has a distinct boundary beyond which accuracy collapses. Reflection analysis demonstrates that while reflection frequency increases with horizon length, most reflections remain localized; long-range reflection is rare, indicating that LRMs do not effectively revisit earlier steps to correct errors.
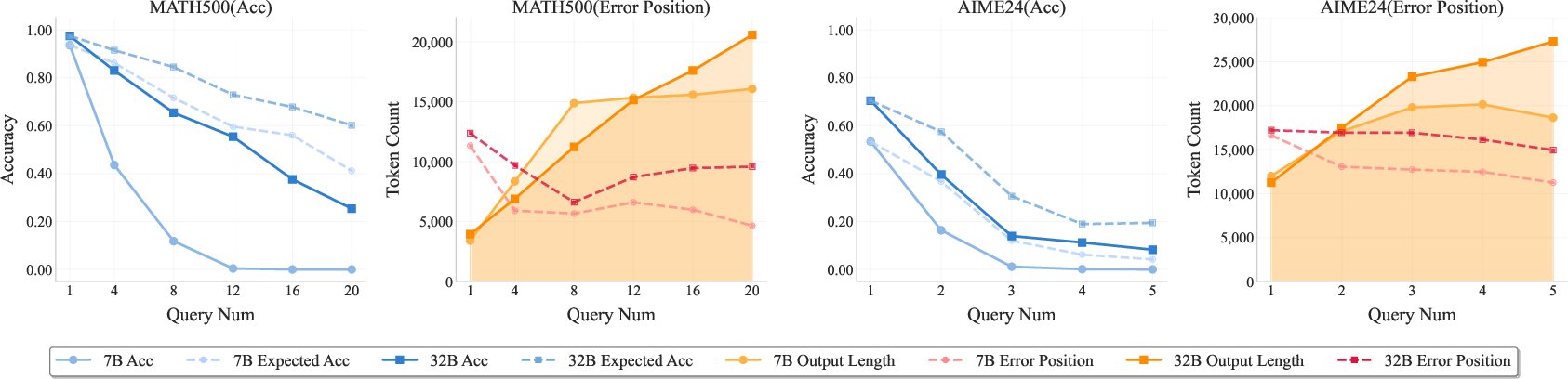
Figure 4: Accuracy and error position analysis for R1-Qwen-7B and R1-Qwen-32B, illustrating model-specific reasoning boundaries.
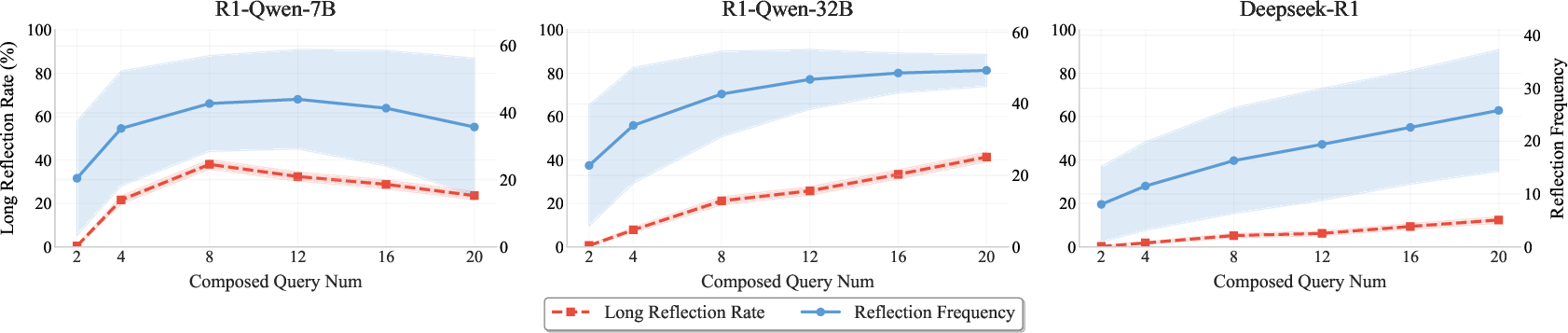
Figure 5: Reflection analysis on MATH500, showing limited long-range reflection in multi-horizon reasoning.
Thinking budget allocation analysis reveals that models disproportionately allocate tokens to early problems, failing to distribute reasoning effort according to horizon or problem difficulty. Even advanced models like DeepSeek-R1 do not adaptively manage their token budget across multi-step tasks.
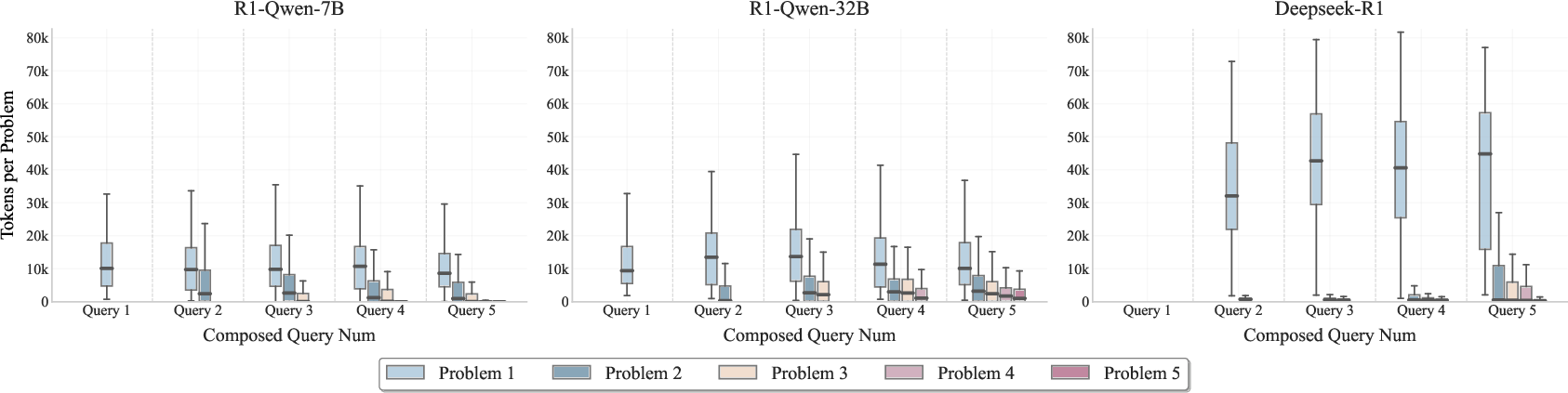
Figure 6: Thinking budget allocation for different query configurations across models on AIME24.
Reinforcement Learning with R-Horizon Data
To address the lack of long-horizon reasoning in RL training, R-Horizon is used to generate composed training data for RL with verified rewards (RLVR), employing Group Relative Policy Optimization (GRPO). Training with composed queries and all-correct reward functions yields significant improvements in both multi-horizon and single-horizon task performance. For instance, training R1-Qwen-7B with 2-query composed data improves AIME24 (n=2) accuracy by +17.4 and single-problem accuracy by +7.5.
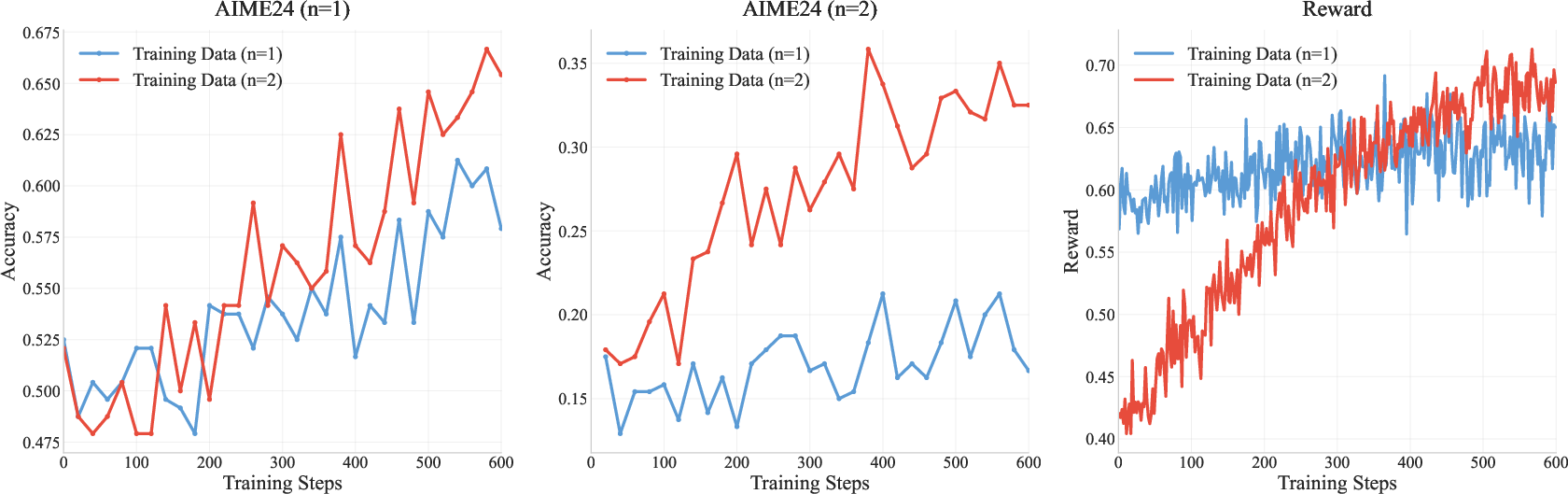
Figure 7: Training curves comparing single and composed data on AIME24, demonstrating accelerated improvement with composed data.
Increasing the number of composed queries further enhances models' ability to handle longer reasoning horizons, and using all-correct rewards outperforms last-only rewards in multi-step scenarios. Training dynamics show that models trained with composed data learn to allocate tokens more efficiently and engage in longer-range reflection, mitigating overthinking and promoting robust reasoning.
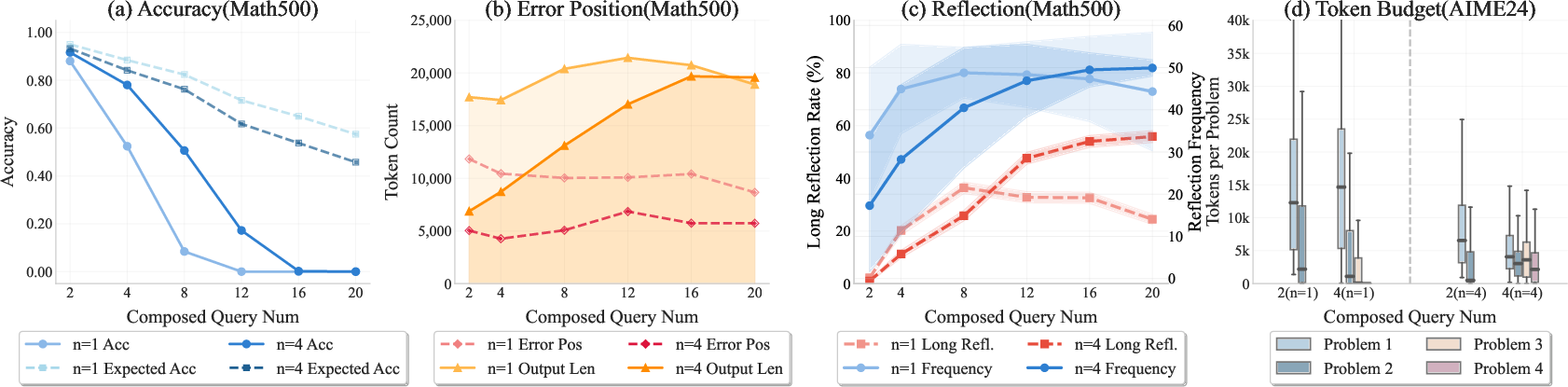
Figure 8: Analysis of RL effects with single and composed datasets: performance, error position, reflection, and token budget allocation.
Ablation and Case Study
Ablation studies confirm that sequential dependencies amplify reasoning difficulty beyond mere concatenation of independent problems. Evaluation metric analysis reveals anomalous cases where models produce correct final answers despite errors in preceding steps, likely due to data contamination. Difficulty ordering experiments show that powerful models benefit from hard-to-easy ordering, allocating more budget to difficult problems, while smaller models do not.
Case studies demonstrate that models trained with R-Horizon data consume fewer tokens per problem, avoid excessive allocation to individual steps, and successfully solve all problems in multi-horizon tasks, in contrast to models trained on single-problem data.
Implications and Future Directions
R-Horizon exposes fundamental limitations in current LRM architectures and training paradigms: restricted effective reasoning length, poor thinking budget allocation, and localized reflection. The framework provides a scalable, controllable, and low-cost paradigm for both evaluating and enhancing long-horizon reasoning. The strong empirical gains from RL training with composed data suggest that future LRM development should incorporate multi-horizon reasoning benchmarks and training regimes to achieve robust, generalizable reasoning capabilities.
Theoretically, R-Horizon motivates research into architectural modifications (e.g., memory augmentation, hierarchical planning) and adaptive inference strategies to extend reasoning boundaries. Practically, it enables the synthesis of complex, real-world evaluation scenarios and the design of reward functions that incentivize global coherence and error correction across extended reasoning trajectories.
Conclusion
R-Horizon establishes a rigorous methodology for constructing, evaluating, and improving long-horizon reasoning in LRMs. By transforming isolated tasks into logically interdependent sequences, it reveals critical failure modes and provides actionable pathways for model enhancement via RL. The framework sets a new standard for reasoning evaluation and training, with broad implications for the development of AI systems capable of sustained, multi-step logical inference.

