Cognitive Foundations for Reasoning and Their Manifestation in LLMs
Abstract: LLMs solve complex problems yet fail on simpler variants, suggesting they achieve correct outputs through mechanisms fundamentally different from human reasoning. We synthesize cognitive science research into a taxonomy of 28 cognitive elements spanning computational constraints, meta-cognitive controls, knowledge representations, and transformation operations, then analyze their behavioral manifestations in reasoning traces. We propose a fine-grained cognitive evaluation framework and conduct the first large-scale analysis of 170K traces from 17 models across text, vision, and audio modalities, alongside 54 human think-aloud traces, which we make publicly available. Our analysis reveals systematic structural differences: humans employ hierarchical nesting and meta-cognitive monitoring while models rely on shallow forward chaining, with divergence most pronounced on ill-structured problems. Meta-analysis of 1,598 LLM reasoning papers reveals the research community concentrates on easily quantifiable behaviors (sequential organization: 55%, decomposition: 60%) while neglecting meta-cognitive controls (self-awareness: 16%, evaluation: 8%) that correlate with success. Models possess behavioral repertoires associated with success but fail to deploy them spontaneously. Leveraging these patterns, we develop test-time reasoning guidance that automatically scaffold successful structures, improving performance by up to 60% on complex problems. By bridging cognitive science and LLM research, we establish a foundation for developing models that reason through principled cognitive mechanisms rather than brittle spurious reasoning shortcuts or memorization, opening new directions for both improving model capabilities and testing theories of human cognition at scale.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores how people think through problems (reasoning) and compares that to how LLMs—computer programs that read and write text—“think.” The authors build a clear map of the mental building blocks people use when reasoning and check whether LLMs show those same building blocks in their step-by-step thoughts. They also test a way to guide LLMs to reason more like successful human problem-solvers.
What questions does the paper ask?
The researchers focus on simple, practical questions:
- What are the key parts of human reasoning (like planning, checking your work, and using cause-and-effect)?
- Do LLMs use these parts in their own step-by-step thinking?
- Which reasoning behaviors actually lead to correct answers?
- Can we help LLMs do better by nudging them to use the right reasoning patterns, especially on messy, open-ended problems?
How did they study it?
To make the comparison fair and meaningful, the authors created a “reasoning toolbox”: a taxonomy (organized list) of 28 elements grouped into four easy-to-understand categories. Think of it like four drawers in a toolbox:
- Reasoning invariants (rules that should always hold): e.g., staying consistent, building complex ideas from simple parts.
- Meta-cognitive controls (self-management while thinking): e.g., noticing what you don’t know, choosing a strategy, checking progress.
- Reasoning representations (how you organize information): e.g., steps in order, parts within parts (hierarchies), cause-and-effect, time, space.
- Reasoning operations (moves you use while thinking): e.g., breaking a big problem into pieces, verifying each step, working backward from a goal, restarting when stuck.
They used this toolbox to analyze:
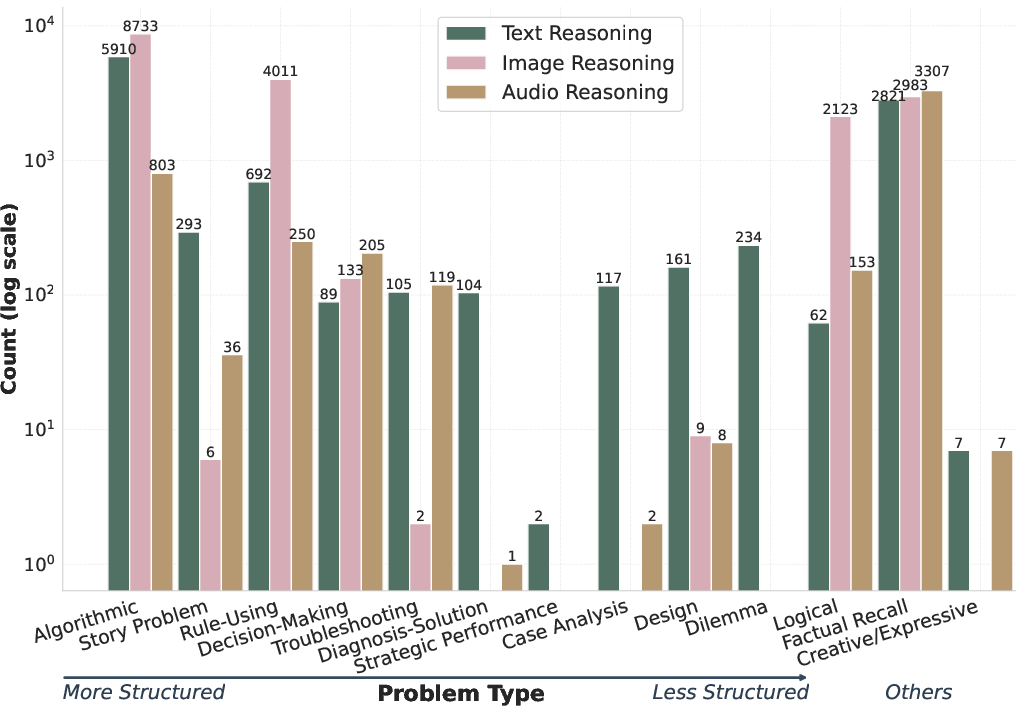
- 170,000 “reasoning traces” from 17 different models across text, vision, and audio. A reasoning trace is the model’s written “thinking process,” similar to showing your work in math.
- 54 “think-aloud” traces from humans (people saying their thoughts out loud while solving problems).
- A meta-analysis (big overview) of 1,598 research papers on LLM reasoning to see what the field focuses on.
They also built “test-time reasoning guidance,” which is like giving an LLM a step-by-step strategy before it starts thinking—for example: “First check what you know, then build a hierarchy, then break the problem into parts.”
What did they find, and why is it important?
Here are the main takeaways, explained simply:
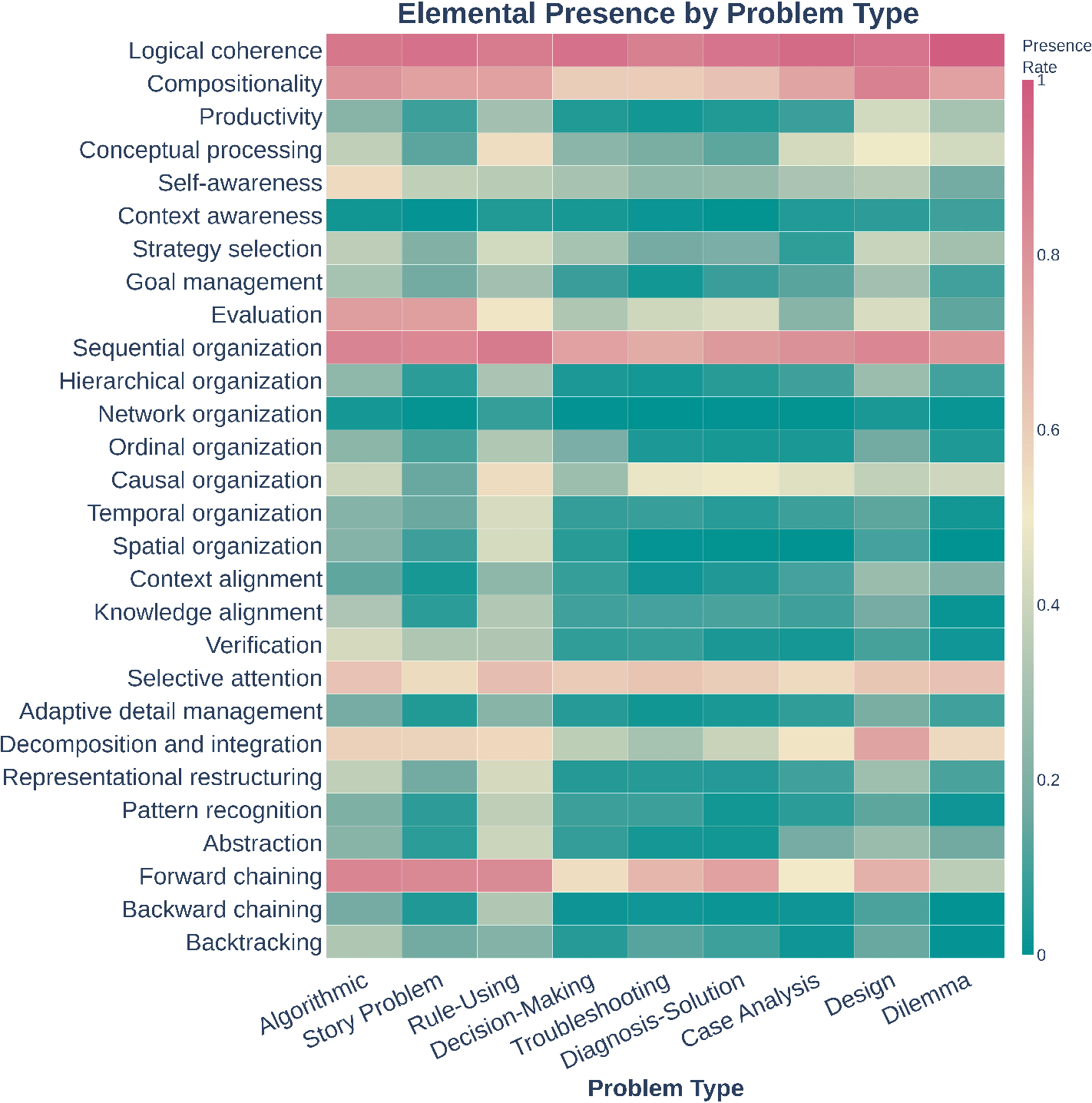
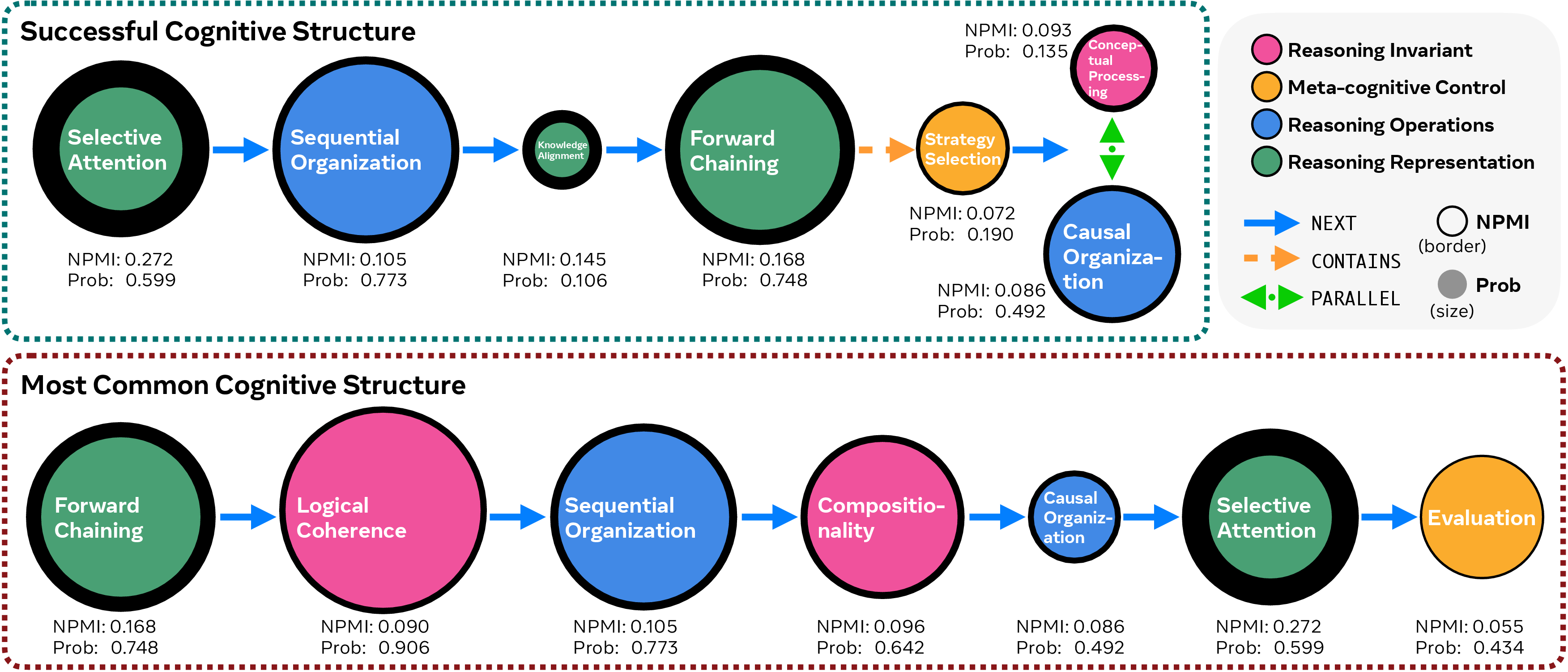
- Humans vs. LLMs use different thinking structures:
- Humans often use hierarchies (big problem → parts → subparts), watch themselves think (self-awareness), and evaluate as they go (quality checks).
- LLMs often do shallow “forward chaining” (step-by-step from known facts toward an answer) without much self-monitoring, especially on messy problems.
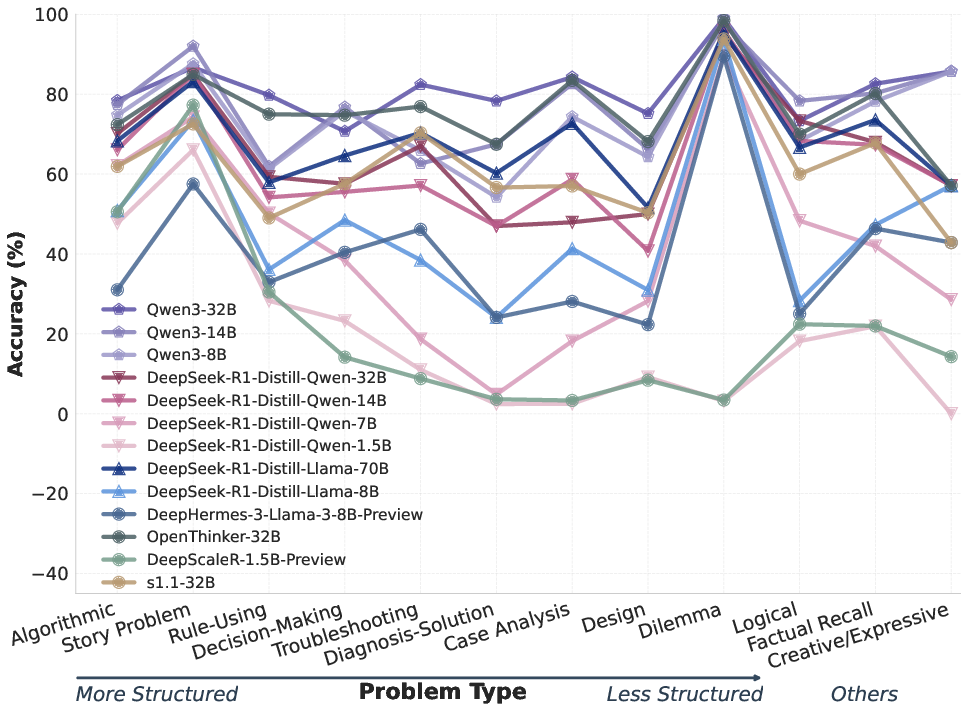
- Messy problems are hard for LLMs:
- “Well-structured” problems (clear steps, easy to check) are easier for models.
- “Ill-structured” problems (open-ended dilemmas, complex diagnosis, tricky multi-part tasks) are where LLMs struggle most—they don’t naturally switch strategies or build good internal structures.
- The research community mostly measures the easy stuff:
- Many papers focus on things that are simple to count, like doing steps in order (55%) or breaking problems into parts (60%).
- Far fewer papers study meta-cognitive skills like self-awareness (16%) or evaluation (8%), even though these are strongly linked to success.
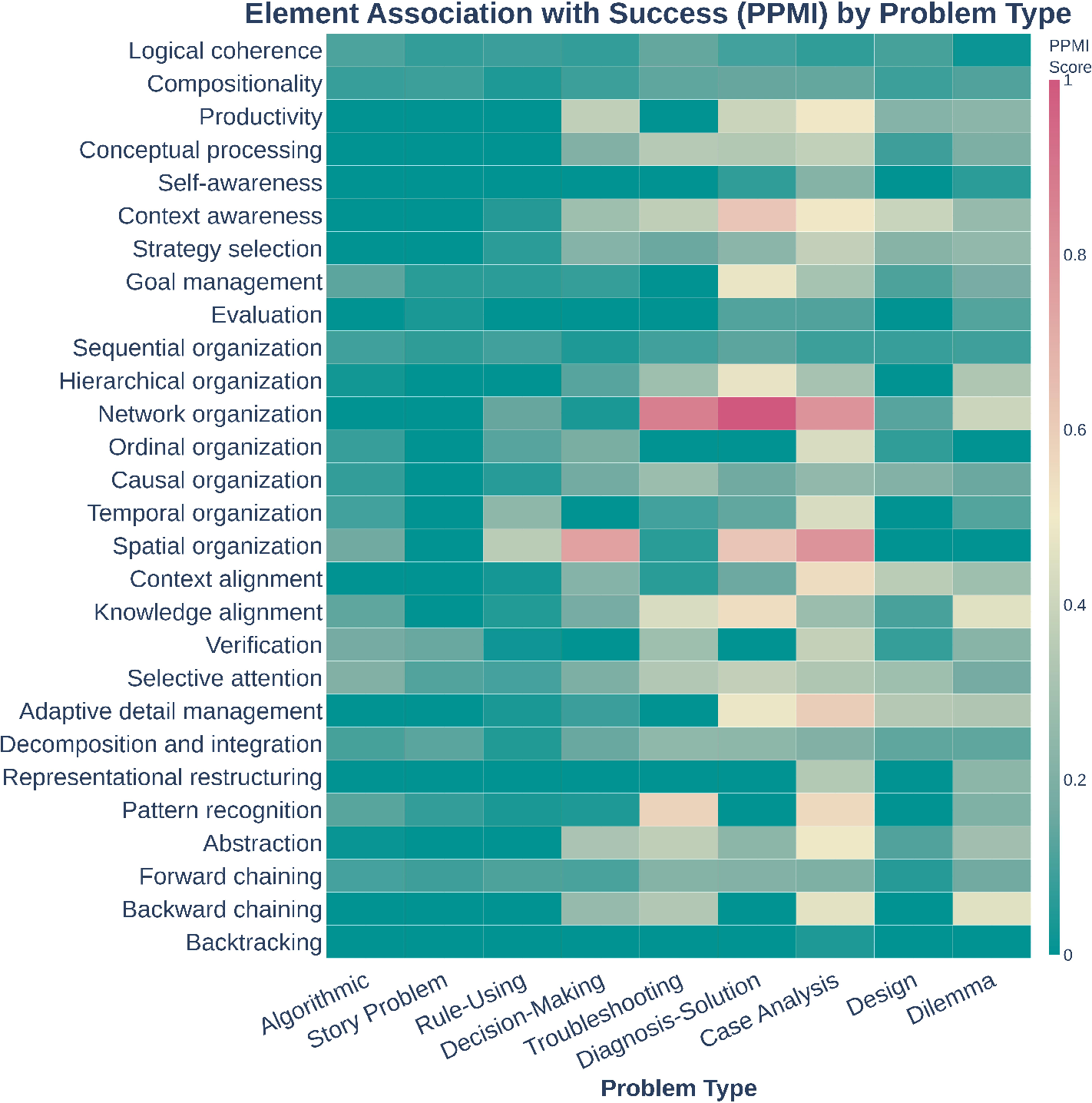
- LLMs have the right tools but don’t use them when needed:
- Models sometimes show helpful behaviors (like planning or backtracking), but they don’t consistently choose them at the right time.
- Guidance helps a lot:
- When the authors guided models with a good reasoning structure (for example: “Start with self-awareness, then build a hierarchy, then decompose the problem”), performance improved by up to about 60–67% on complex, ill-structured problems.
- This suggests models have “hidden” abilities that we can unlock by steering their thinking.
What does this mean going forward?
This work gives a shared, practical language for talking about reasoning in both humans and AI. It shows that:
- Checking only final answers isn’t enough—we need to examine the thinking process.
- Teaching models meta-cognitive skills (like noticing when they’re confused and choosing a better strategy) can make a big difference.
- Better evaluation can push the field to study what actually matters for robust reasoning, not just what’s easiest to measure.
- With the right guidance, LLMs can move away from brittle shortcuts (like memorization) and toward more thoughtful, reliable problem-solving.
In short, by connecting cognitive science (how people think) with AI research (how models “think”), this paper lays groundwork for AI that reasons in a more principled, human-like way—and helps test theories of human cognition at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of what remains missing, uncertain, or unexplored in the paper, formulated as concrete and actionable directions for future research.
- Taxonomy validity and completeness: Empirically test whether the proposed 28 cognitive elements are sufficient, non-overlapping, and necessary across diverse domains (STEM, legal, medical), tasks (planning, diagnosis, synthesis), and modalities; identify missing elements (e.g., probabilistic calibration, tool-use orchestration, memory management) and refine definitions where elements bleed into one another.
- Operationalization of invariants: Develop and validate rigorous, model-agnostic metrics for logical coherence, compositionality, productivity, and conceptual processing that go beyond qualitative trace interpretation and can be reliably computed at scale.
- Annotation reliability and bias: Report and improve inter-annotator agreement on span-level element labels; quantify annotation drift across tasks and models; release detailed guidelines and disagreement analyses to support reproducibility and external validation.
- Causal inference vs correlation: Establish whether specific cognitive elements causally improve outcomes (not just correlate) using randomized interventions, counterfactual prompts, and do-operator style ablations (e.g., selectively adding/removing “evaluation” or “self-awareness” steps).
- Length and format confounds: Control for token budget, verbosity, and formatting (e.g., structured headings) when attributing performance gains to cognitive guidance, to rule out improvements caused by longer outputs or templated structure rather than genuine cognitive processes.
- Generalization of scaffolding: Test whether the proposed test-time reasoning guidance transfers zero-shot to unseen domains, tasks, and modalities without task-specific tuning; measure degradation on out-of-distribution problems and under adversarial prompts.
- Negative impacts and trade-offs: Quantify cases where cognitive scaffolding harms performance (e.g., overthinking simple tasks, added latency/cost, increased hallucination or misplaced confidence) and characterize the speed–accuracy–cost trade-offs.
- Model coverage and baseline diversity: Expand beyond reasoning-tuned or instruction-tuned models to include base models, small models, multilingual models, and different architectures (e.g., Mamba, state-space models) to disentangle training effects from architectural biases.
- Modality breadth and rigor: Provide stronger coverage and evaluation for non-text modalities—especially vision tasks that require spatial reasoning with ground-truth structure, and audio tasks beyond transcription—ensuring element detection is meaningful and not text-only.
- Human comparison scale and diversity: Increase the number and diversity of human think-aloud traces (expertise levels, cultures, languages, neurodiversity, task familiarity); assess how think-aloud protocols themselves alter cognitive processes compared to natural reasoning.
- Expertise effects: Explicitly compare novices vs experts to determine which cognitive elements (e.g., abstraction, representational restructuring) differentiate expert reasoning and whether LLMs can be guided to emulate those patterns.
- Task taxonomy clarity: Precisely define “well-structured” vs “ill-structured” problems, quantify verification difficulty, and ensure balanced coverage across types; measure sensitivity of results to alternative task categorizations.
- Structural representation details: Fully specify and open-source the “novel structural representation” used to encode element sequences (graph or grammar, metrics for nesting/dependency), and validate it against independent structural analyses (e.g., plan hierarchies, causal graphs).
- Measurement granularity: Distinguish micro-level (token/step) vs macro-level (episode/plan) element presence; test whether local element usage aggregates into global reasoning structures predictive of success.
- Meta-cognitive detection fidelity: Validate methods for detecting meta-cognitive elements (self-awareness, evaluation, strategy selection) to ensure they reflect genuine monitoring/control rather than superficial markers (e.g., “I will now evaluate…”).
- Specification gaming risks: Assess whether models learn to mimic the surface form of desired cognitive elements (e.g., adding evaluation statements) without substantive process changes; create process-level adversarial tests to detect mimicry.
- Process vs outcome metrics: Introduce benchmarks where outcome-only evaluation is insufficient (e.g., hidden intermediate checks), forcing reliance on process quality; measure alignment between process metrics and final correctness.
- Cross-lingual generalization: Evaluate whether the taxonomy, detection methods, and guidance interventions transfer to non-English languages (including morphologically rich and low-resource languages) and multilingual models.
- Multi-agent reasoning and social context: Test context-awareness and goal management in multi-agent scenarios (cooperation, negotiation, theory of mind) to probe social metacognition beyond single-agent tasks.
- Tool use and external memory: Investigate how cognitive elements interact with tools (retrieval, calculators, planners) and memory mechanisms (scratchpads, episodic memory), including when and how meta-cognitive controls trigger tool invocation.
- Training-time interventions: Move beyond test-time prompting to study whether process-level elements can be induced via training (e.g., process-supervised RLHF, curriculum learning, architectural planning modules) and compare their durability vs prompt-only guidance.
- Scaling laws for cognitive elements: Quantitatively map which elements emerge with model scale vs fine-tuning vs specialized training, and identify thresholds where meta-cognitive controls and representational restructuring reliably appear.
- Robustness under uncertainty: Evaluate element deployment under noisy inputs, ambiguous objectives, shifting constraints, and partial observability to assess whether meta-cognitive controls trigger appropriate adaptation.
- Benchmarks and standardized protocols: Create standardized, open benchmarks with ground-truth process annotations and agreed-upon scoring for cognitive elements to enable rigorous, comparable evaluation across labs and models.
- Meta-analysis methodology transparency: Release detailed coding criteria, rater procedures, and reliability stats for the 1,598-paper meta-analysis; assess sensitivity to sampling windows, domains, and paper types to validate claims about research focus distribution.
- Human–LLM gap quantification: Provide effect sizes for structural differences (e.g., hierarchical nesting depth, frequency of backward chaining) and test whether targeted interventions narrow these gaps measurably across problem types.
- Downstream impacts: Study whether improved cognitive processes reduce hallucinations, improve calibration, and enhance user trust, and whether they translate into better real-world task performance (e.g., clinical reasoning, legal analysis).
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s taxonomy, datasets, code, and the demonstrated test-time reasoning guidance that scaffolds meta-cognitive and structural reasoning patterns.
- Cognitively scaffolded prompting for complex tasks (software, customer support, legal, operations)
- Use case: Wrap LLMs with prompts that enforce sequences like self-awareness → hierarchical representation → decomposition → evaluation on ill-structured problems (e.g., incident postmortems, policy analyses, legal memos, complex customer escalations).
- Tools/workflows: “Reasoning Guidance” prompt library; task-type detectors to select scaffolds; integration into LangChain/LlamaIndex as middleware; parameterized templates per domain.
- Assumptions/dependencies: Model must expose or reliably simulate reasoning traces; latency and token costs may rise; benefits most pronounced on ill-structured tasks (as reported up to ~60–66.7% improvement).
- Cognitive-process auditing and QA for LLM outputs (AI governance, compliance, safety)
- Use case: Evaluate whether outputs exhibit the 28 cognitive elements correlated with success (e.g., meta-cognitive evaluation, hierarchical organization), not just final accuracy.
- Tools/workflows: Annotation toolkit and metrics from the released code/data; dashboards that visualize the presence/sequence of cognitive elements; “Cognitive Element Scorecards.”
- Assumptions/dependencies: Requires access to model traces or generated “think-aloud”; automated classifiers may need domain calibration; auditing complements but does not replace outcome validation.
- Model selection and routing by cognitive profile (MLOps, platform teams)
- Use case: Route tasks to models that exhibit stronger meta-cognitive controls or hierarchical reasoning on similar problem structures; avoid models that over-rely on shallow forward chaining for ill-structured tasks.
- Tools/workflows: Cognitive profiling benchmarks built from the released corpus; per-task routers; A/B evaluation harnesses.
- Assumptions/dependencies: Profiles must be built and maintained; performance differs by modality and domain; routing adds system complexity.
- Reasoning-aware UX for transparency and user trust (product, HCI)
- Use case: Interfaces that surface meta-cognitive steps (self-assessment, evaluation) and structural representations (hierarchies, causal chains) to help users inspect and steer reasoning.
- Tools/workflows: “Think-aloud” modes with structured sections; interactive toggles for plan vs. exploration; error-check prompts.
- Assumptions/dependencies: Must balance verbosity with usability; risk of users over-trusting articulated but incorrect reasoning.
- Education: meta-cognitive tutoring and study aids (education, edtech)
- Use case: Tutor prompts guiding students through goal management, decomposition, verification, and representational restructuring for math proofs, science explanations, or writing.
- Tools/workflows: Lesson templates aligned to the taxonomy; formative assessment rubrics capturing cognitive elements; student-facing reasoning checklists.
- Assumptions/dependencies: Nontrivial to align with curricula and assessments; domain calibration needed to avoid confabulation; human-in-the-loop essential.
- Root-cause analysis and decision support (IT ops, engineering, finance, risk)
- Use case: Enforce backward chaining and evaluation to derive prerequisites for failures or risks; integrate causal and temporal organization when analyzing logs or market events.
- Tools/workflows: Structured RCA templates; causal/temporal graph builders; verification checklists tailored to domain criteria.
- Assumptions/dependencies: Requires domain data and criteria for verification; LLM is advisory, not authoritative; ensure data governance.
- Content creation with cognitive controls (marketing, research, journalism)
- Use case: Prompt workflows that ensure goal management and evaluation while moving between abstraction and adaptive detail management for reports, whitepapers, and narratives.
- Tools/workflows: Draft-to-structure pipelines; “conceptual-first” writing modes; meta-review passes for logical coherence and compositionality.
- Assumptions/dependencies: Gains depend on adherence to scaffolds; human editorial oversight remains crucial.
- Healthcare documentation and non-clinical triage (healthcare IT)
- Use case: Use hierarchical and causal structures to organize clinical notes and triage summaries; meta-cognitive evaluation to flag uncertainty and missing information.
- Tools/workflows: Documentation templates; uncertainty statements and information gaps; structured symptom-to-differential representations.
- Assumptions/dependencies: Not for autonomous diagnosis; must comply with regulations; validated workflows and clinician review mandatory.
- Policy analysis memos and stakeholder briefings (public sector, NGOs)
- Use case: Structure analyses with context awareness, strategy selection, causal/temporal reasoning; explicitly evaluate trade-offs and assumptions.
- Tools/workflows: Policy memo scaffolds; bias/assumption trackers; goal management and options appraisal sections.
- Assumptions/dependencies: Data quality and stakeholder input are critical; ensure transparency about model limitations.
- Personal assistants with better planning and self-checks (daily life)
- Use case: Travel planning, home projects, budgeting with explicit self-awareness (“what info is missing?”), hierarchical decomposition, and verification steps.
- Tools/workflows: “Plan → Build → Evaluate” routines; checklists for constraints/preferences; backtracking when constraints change.
- Assumptions/dependencies: Users must tolerate more structured interactions; ensure privacy and data handling.
- Research reproducibility and benchmarking (academia)
- Use case: Use released corpus (170K traces) and taxonomy to study how training regimes affect cognitive profiles; test hypotheses about human-LLM differences.
- Tools/workflows: Span-level annotation scripts; structural sequence analysis; cross-modal comparisons.
- Assumptions/dependencies: Requires careful experimental design; annotation reliability and construct validity must be monitored.
- Prompt libraries and SDKs for structured reasoning (software)
- Use case: Package “cognitive scaffolds” for common task families (diagnosis, design, planning, evaluation) and ship as SDK extensions.
- Tools/workflows: Open-source libraries; integration guides; recipes per sector; CI checks to enforce scaffold usage on designated tasks.
- Assumptions/dependencies: Maintenance burden; prompts must adapt to model updates; cost/latency trade-offs.
Long-Term Applications
These applications require further research, scaling, validation, or productization beyond the current test-time guidance and analysis framework.
- Architectural meta-reasoning modules (AI systems, agents)
- Use case: Integrate explicit meta-cognitive controllers (self-awareness, strategy selection, evaluation) as trainable modules rather than relying solely on prompting.
- Tools/workflows: Multi-objective training with process-level rewards; memory and planning components; hierarchical policy learners.
- Assumptions/dependencies: Needs new datasets with process labels; stability and safety evaluation; potential shifts in model architectures.
- Standards and certifications for cognitive-process quality (policy, governance)
- Use case: Regulatory or industry standards that require documented cognitive-process audits (beyond accuracy) before deployment in sensitive contexts.
- Tools/workflows: Benchmark suites focused on meta-cognition; certification protocols; third-party auditors and reporting formats.
- Assumptions/dependencies: Consensus across regulators and industry; validated metrics; compatibility with confidentiality constraints.
- Training curricula aligned to the taxonomy (ML training, edtech for models)
- Use case: Create datasets and objectives that teach models to deploy underused but success-correlated elements (evaluation, self-awareness, backward chaining).
- Tools/workflows: Synthetic data generation with labeled cognitive steps; reinforcement learning from process feedback; contrastive training on ill-structured problems.
- Assumptions/dependencies: Costly data creation; avoiding overfitting to visible processes; balancing performance vs. verbosity.
- Process-aware multi-agent collaboration (software, robotics, operations)
- Use case: Agents with complementary cognitive profiles (e.g., one excels at abstraction, another at verification) coordinate via explicit goal management and representational alignment.
- Tools/workflows: Role-based cognitive protocols; shared causal/spatial models; negotiation via meta-cognitive signals.
- Assumptions/dependencies: Complex orchestration; emergent behavior needs safety controls; evaluation at scale.
- Causal and hierarchical knowledge integration (“Reasoning OS”) (knowledge engineering, enterprise AI)
- Use case: Combine LLMs with knowledge graphs and simulators to ground causal, temporal, and spatial representations; enable robust reasoning operations (backward chaining, verification).
- Tools/workflows: Hybrid pipelines (symbolic + neural); graph stores; simulators for verification; representational restructuring modules.
- Assumptions/dependencies: Data engineering overhead; domain knowledge maintenance; latency constraints.
- Healthcare decision support with embedded cognitive controls (healthcare)
- Use case: Clinical support systems that perform explicit goal management, verification against guidelines, and admit uncertainty, improving safety in complex cases.
- Tools/workflows: Guideline-aware reasoning templates; uncertainty calibration; human-in-the-loop triage and review.
- Assumptions/dependencies: Rigorous clinical validation; liability and ethics frameworks; integration with EHRs.
- Intelligent tutoring systems that measure and coach meta-cognition (education)
- Use case: Tutors that assess students’ use of cognitive elements (decomposition, evaluation, abstraction) and coach improvements.
- Tools/workflows: Process analytics; personalized feedback loops; curriculum-aligned scaffolds per subject.
- Assumptions/dependencies: Longitudinal validation; fairness and accessibility; integration with classroom practices.
- Safety-critical reasoning guarantees via process constraints (aviation, autonomy, energy)
- Use case: Enforce reasoning invariants (coherence, compositionality) and verification operations before allowing actions; formal checks on process traces.
- Tools/workflows: Runtime monitors; formal methods overlays; structured fail-safes and backtracking protocols.
- Assumptions/dependencies: Strong validation; performance trade-offs; regulators may require explainability and logs.
- Human cognition research at scale using LLMs as probes (academia, cognitive science)
- Use case: Test cognitive theories by inducing or inhibiting elements (e.g., representation switching), comparing model-human patterns across tasks and modalities.
- Tools/workflows: Experimental platforms; cross-modal trace comparison; structural sequence analytics.
- Assumptions/dependencies: Careful interpretation to avoid anthropomorphism; robust experimental controls.
- Adaptive enterprise workflows that auto-select reasoning structures (enterprise software)
- Use case: Systems detect problem type (well- vs. ill-structured) and dynamically enforce the most predictive reasoning structure for that class.
- Tools/workflows: Task classifiers; scaffold routers; performance telemetry tied to cognitive element presence.
- Assumptions/dependencies: Ongoing monitoring; domain drift; change management and user training.
- Trust and explainability interfaces grounded in cognitive elements (HCI, product)
- Use case: Users inspect and edit reasoning structures (hierarchies, causal chains), not just text; systems highlight where meta-cognitive evaluation changed the plan.
- Tools/workflows: Visual structure editors; explanation layers; “what-if” backtracking tools.
- Assumptions/dependencies: Requires robust structure extraction; potential cognitive load for users; accessibility considerations.
- Domain-specific cognitive element libraries (legal, finance, engineering)
- Use case: Tailored scaffolds mapping domain norms to the taxonomy (e.g., legal issue spotting → hierarchical decomposition; finance risk analysis → causal/temporal org + verification).
- Tools/workflows: Sector templates; audit checklists; integration with domain data and compliance tooling.
- Assumptions/dependencies: Domain expert participation; continuous updates to reflect regulation and best practices.
Glossary
- Abstraction: Generalizing from specific instances to derive broader principles or concepts. "abstraction extracts a principle for future builds."
- ACT-R: A cognitive architecture that models human cognition using production systems. "like ACT-R \citep{newell1972human}."
- Adaptive detail mgmt.: Adjusting the granularity of representation to match task demands. "Adaptive detail management adjusts granularity based on task demands \citep{Rosch1978-ROSPOC-8}."
- Analogical transfer: Applying knowledge from one domain to another by mapping structural similarities. "including analogical transfer \citep{gentner1983structure,holyoak1989analogical}"
- Backtracking: Revisiting earlier steps to correct errors or explore alternatives after hitting a dead-end. "backtracking when a design fails."
- Backward chaining: Reasoning from a goal backward to the necessary prerequisites. "only 8\% study backward chaining (e.g. reverse engineering the solution from the answer)."
- Bayesian approaches: Framing reasoning as probabilistic inference under uncertainty. "Bayesian approaches reframed rationality as probabilistic inference under uncertainty"
- Causal inference: Determining cause–effect relationships from data or observations. "causal inference \citep{sloman2009causal,gopnik2004theory}"
- Causal organization: Structuring knowledge by cause–effect relations to enable explanation and intervention. "Causal organization connects elements through causeâeffect relations \citep{heider1958psychology}."
- Cognitive dissonance: Psychological tension from holding contradictory beliefs or information. "a form of cognitive dissonance unprecedented in human cognition"
- Cognitive load theory: A theory explaining how working memory limitations affect learning and problem solving. "Cognitive load theory demonstrates that working memory limitations create severe bottlenecks"
- Compositionality: Building complex ideas from simpler components via systematic combination rules. "Compositionality enables building complex ideas from simpler components"
- Conceptual processing: Operating over abstract semantic relations rather than surface forms or linguistic tokens. "Conceptual processing operates over abstract semantic relations rather than surface forms"
- Context alignment: Selecting representational schemas suited to the problem and situation. "Context alignment chooses organizational schemas fitting the problem"
- Context awareness: Perceiving and adapting to situational demands, constraints, and social factors. "Context awareness perceives and responds to situational demands"
- Decomposition and integration: Breaking problems into subproblems and synthesizing subsolutions into a whole. "Decomposition and integration break problems into subproblems and synthesize solutions"
- Dual-Process Theory: A framework distinguishing fast, intuitive processes from slow, deliberative reasoning. "Dual-Process Theory distinguished fast, intuitive processing from slow, deliberative reasoning"
- Evaluation: Meta-cognitive assessment of progress, quality, and efficiency during reasoning. "Evaluation monitors progress and triggers adaptation when needed."
- Expert system architectures: AI systems that apply rules to facts to reach conclusions in a domain. "expert system architectures"
- Forward chaining: Reasoning from known facts toward conclusions or goals by applying rules iteratively. "Forward chaining reasons from known facts toward goals \citep{huys2012bonsai}."
- Frames and schemas: Structured templates encoding stereotyped knowledge about common situations. "frames and schemas"
- Goal management: Establishing, maintaining, sequencing, and adjusting goals during problem solving. "Goal management directs the response through structured sub-goals."
- Hierarchical organization: Nesting concepts in parent–child relationships to decompose complexity. "Hierarchical organization nests concepts in parentâchild relationships \citep{galanter1960plans}."
- Ill-structured problems: Problems with ambiguous goals, constraints, or verification criteria. "ill-structured problems"
- Knowledge alignment: Mapping problems onto domain-specific structures and relations. "Knowledge alignment maps problems onto domain-specific schemas"
- Language of Thought Hypothesis: The theory that thinking is a computational process over compositional mental representations. "Language of Thought Hypothesis proposed that thinking is a computational process operating over compositional representations"
- Marr's levels of analysis: A framework separating computational, algorithmic/representational, and implementation levels. "Marr's \citeyearpar{marr1982vision} levels of analysis"
- Means-ends analysis: A problem-solving strategy that creates subgoals to reduce the difference between current and goal states. "means-ends analysis"
- Mental Models Theory: The view that reasoning constructs and manipulates semantic simulations of the world. "Mental Models Theory proposed that reasoning constructs and manipulates semantic simulations of the world"
- Meta-analysis: A systematic aggregation and analysis of results across multiple studies. "Meta-analysis of 1,598 LLM reasoning papers"
- Meta-cognitive controls: Higher-order functions that select, monitor, and adapt reasoning strategies. "Meta-cognitive controls select and monitor processes"
- Meta-cognitive monitoring: Ongoing oversight of one’s reasoning to detect errors and guide adjustments. "meta-cognitive monitoring"
- Network organization: Linking concepts through multiple relationship types beyond hierarchical trees. "Network organization captures this richer connectivity"
- Ordinal organization: Arranging elements by rank or relative order, such as best to worst. "Ordinal organization allows ranking them from best to worst"
- Pattern recognition: Detecting recurring structures or templates across contexts to guide reasoning. "Pattern recognition detects recurring structures"
- Productivity: The capacity to generate infinitely many novel thoughts from finite primitives. "Productivity extends compositionality by enabling the generation of infinitely many novel thoughts from finite primitives"
- Production systems: Rule-based structures (If–Then) representing procedural knowledge for reasoning. "Production systems represent procedural knowledge via a set of If-Then rules."
- Prototype theory: A theory in which categories are represented by their most typical or central member. "Prototype theory \citep{rosch1975cognitive, rosch1975family} represents categories by their most typical member"
- Reasoning invariants: Fundamental properties that must hold for valid reasoning across steps. "Reasoning invariants specify computational goals"
- Representational flexibility: The ability to shift and reconfigure mental representations to suit task demands. "representational flexibility \citep{ohlsson1992information,knoblich1999constraint}"
- Representational restructuring: Reframing the problem to alter its representation and enable new insights. "Representational restructuring reframes problems for new insight"
- Sequential organization: Ordering steps explicitly when sequence affects outcomes. "Sequential organization orders steps where sequence matters \citep{skinner1953}."
- Self-awareness: Assessing one’s knowledge, capabilities, and task solvability. "Self-awareness stands as the foundation: the capacity to assess one's own knowledge state"
- Semantic network theories: Models of knowledge as nodes connected by typed relations (e.g., hierarchical, associative). "Semantic network theories model human knowledge as nodes connected by typed relations"
- Spatial organization: Structuring elements by geometric relations like adjacency, orientation, and containment. "Spatial organization structures elements geometrically"
- Strategy selection: Choosing an approach suited to the current task and context. "the child engages in \Metacognitive{strategy selection}, choosing an approach suited to task demands"
- Systematicity: The property of a cognitive system to entertain related sets of thoughts given others. "systematicity, the capacity to entertain a set of thoughts"
- Temporal organization: Ordering events by before–after relations to constrain planning and explanation. "Temporal organization orders events by beforeâafter relations \citep{ebbinghaus1885gedachtnis}."
- Test-time reasoning guidance: Prompting or scaffolding cognitive structures at inference to improve performance. "we introduce test-time reasoning guidance"
- Think-aloud traces: Verbalized records of a reasoner’s step-by-step thought process. "54 human think-aloud reasoning traces"
- Verification: Checking reasoning steps against criteria for consistency, plausibility, and correctness. "Verification checks intermediate inferences for consistency, plausibility, and coherence with known facts"
- Working memory limitations: Capacity constraints that create bottlenecks in processing complex or poorly structured information. "working memory limitations create severe bottlenecks"
Collections
Sign up for free to add this paper to one or more collections.