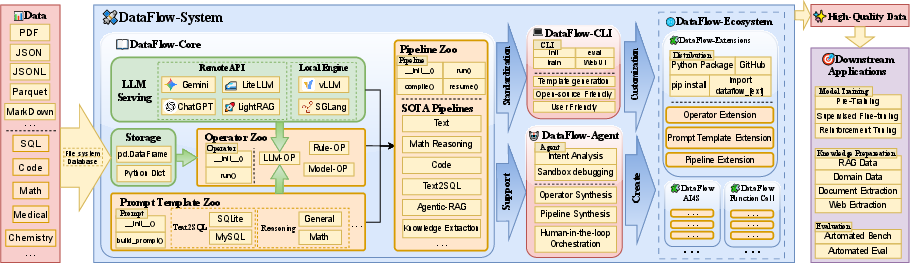
DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
Abstract: The rapidly growing demand for high-quality data in LLMs has intensified the need for scalable, reliable, and semantically rich data preparation pipelines. However, current practices remain dominated by ad-hoc scripts and loosely specified workflows, which lack principled abstractions, hinder reproducibility, and offer limited support for model-in-the-loop data generation. To address these challenges, we present DataFlow, a unified and extensible LLM-driven data preparation framework. DataFlow is designed with system-level abstractions that enable modular, reusable, and composable data transformations, and provides a PyTorch-style pipeline construction API for building debuggable and optimizable dataflows. The framework consists of nearly 200 reusable operators and six domain-general pipelines spanning text, mathematical reasoning, code, Text-to-SQL, agentic RAG, and large-scale knowledge extraction. To further improve usability, we introduce DataFlow-Agent, which automatically translates natural-language specifications into executable pipelines via operator synthesis, pipeline planning, and iterative verification. Across six representative use cases, DataFlow consistently improves downstream LLM performance. Our math, code, and text pipelines outperform curated human datasets and specialized synthetic baselines, achieving up to +3\% execution accuracy in Text-to-SQL over SynSQL, +7\% average improvements on code benchmarks, and 1--3 point gains on MATH, GSM8K, and AIME. Moreover, a unified 10K-sample dataset produced by DataFlow enables base models to surpass counterparts trained on 1M Infinity-Instruct data. These results demonstrate that DataFlow provides a practical and high-performance substrate for reliable, reproducible, and scalable LLM data preparation, and establishes a system-level foundation for future data-centric AI development.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces DataFlow, a new system that helps people build high‑quality datasets for training and improving LLMs, like ChatGPT. Think of DataFlow as a smart, organized “assembly line” for data: it can create new examples, check their quality, fix problems, and automatically build the whole workflow from a simple description. The goal is to make data preparation easier, more reliable, and more powerful, especially when using AI to generate and refine data.
What are the paper’s main objectives?
The paper focuses on solving these problems in simple terms:
- Make data preparation clear and repeatable, instead of messy scripts that are hard to reuse.
- Put AI “in the loop,” so LLMs can help create and improve training data, not just consume it.
- Provide a set of building blocks (called “operators”) that can be combined to build any data workflow, like Lego pieces.
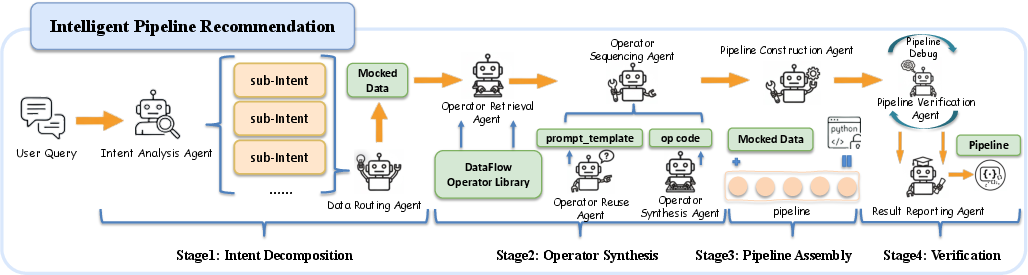
- Let a helper agent (DataFlow‑Agent) turn plain English instructions into a working pipeline, then test and fix it automatically.
- Prove that data made with DataFlow can boost model performance and often beats much larger, human‑made or synthetic datasets.
How did the researchers build and test it?
Think of DataFlow like a well‑organized kitchen:
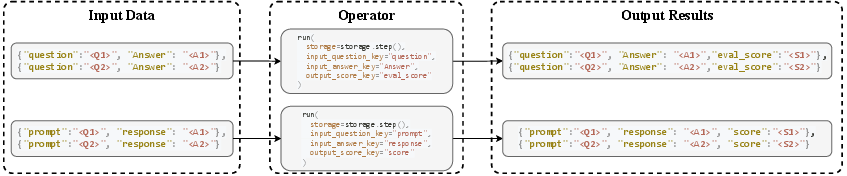
- The “storage” is like a shared spreadsheet where every recipe step reads and writes the data it needs.
- The “operators” are the individual cooking steps (generate, evaluate, filter, refine).
- The “prompt templates” are fill‑in‑the‑blank instructions for the LLM so it knows exactly what to do each step.
- The “pipeline” is the full recipe—an ordered list of operators that turns raw ingredients (data) into a finished dish (a clean, high‑quality dataset).
- The “serving API” is a friendly waiter that can talk to many different LLMs (local or online) using the same request style.
To make these ideas easy to use, the system:
- Uses a PyTorch‑style programming interface, which developers find familiar and easy to debug.
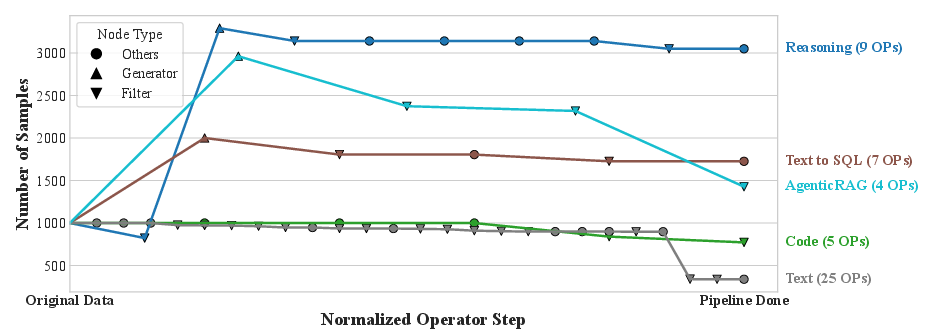
- Includes nearly 200 reusable operators and 6 ready‑to‑use pipelines for common tasks: text, math, code, Text‑to‑SQL, agentic RAG (AI systems that search documents before answering), and large‑scale question‑answer data from web/PDFs.
- Follows a simple pattern in most workflows:
- Generate: create new examples or fields (like making a question and an answer).
- Evaluate: score or label them (is the answer correct? how hard is the problem?).
- Filter: remove low‑quality items (throw away mistakes).
- Refine: fix or clean the remaining items (rewrite unclear text, remove noise).
DataFlow also has DataFlow‑Agent, a helper AI that:
- Reads a natural‑language goal like “Create a math dataset with harder problems.”
- Picks or builds the right operators.
- Connects them into a working pipeline.
- Runs tests, debugs errors, and outputs a verified workflow.
What did they find and why is it important?
Across several tasks, DataFlow made better training data and improved model performance:
- Text‑to‑SQL: +3% execution accuracy compared to a strong baseline (SynSQL), using far fewer examples.
- Code: +7% average improvement over popular public code instruction datasets.
- Math: 1–3 point gains on well‑known benchmarks (MATH, GSM8K, AIME).
- Data efficiency: A small, high‑quality 10,000‑sample dataset (DataFlow‑Instruct‑10K) trained base models to outperform models trained on 1,000,000 samples from Infinity‑Instruct. In other words, better data beats more data.
This matters because:
- It shows that carefully synthesized and refined data can beat larger but noisier datasets.
- It proves that standardized, modular workflows make data preparation more reliable and reproducible.
- It demonstrates that automation (via the agent) can save time and reduce human effort while keeping quality high.
Why this research matters
In simple terms, DataFlow is a well‑built toolbox for the data side of AI. It helps teams:
- Build powerful datasets quickly and consistently, even across different domains like math, code, and databases.
- Share and reuse workflows, making research more open and repeatable.
- Use smaller, smarter datasets to reach or beat results that once required massive data budgets.
- Keep the LLM “in the loop,” so AI helps make better AI.
Big picture: As AI gets more capable, good data becomes even more important. DataFlow offers a practical foundation for data‑centric AI—making it easier to create the right data, not just more data, and pushing models to perform better with less.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is phrased to guide actionable follow-up work.
- Scalability characterization is missing: no empirical throughput/latency benchmarks across dataset sizes, operator mixes, or LLM backends (local vs API), and no multi-node/multi-GPU experiments to validate claims of scalable execution.
- Default storage backend may not scale: the system relies on a Pandas-based tabular store; there is no demonstrated support for streaming, out-of-core processing, Arrow-based columns, or distributed storage (e.g., Ray, Spark, Dask, databases) on very large corpora.
- Lack of performance comparison with existing systems: no head-to-head, controlled benchmarks (same tasks, models, and hardware) against NeMo Curator or Data-Juicer to quantify speed, cost, and quality differences.
- Absent cost–quality trade-off analysis: token/compute budgets per operator stage, cost breakdown by backend (vLLM/SGLang vs API), and marginal gains of each stage/operator are not reported; no guidance on optimizing pipelines under budget constraints.
- No ablation studies per operator category: the contribution of generate/evaluate/filter/refine stages (and specific operators/templates) to final quality is not quantified.
- Robustness to backend variability is untested: the paper does not assess how different LLMs (sizes/vendors) affect pipeline outputs, structured output reliability (JSON schema conformance), or error-handling strategies for non-deterministic/invalid model outputs.
- Caching and memoization are unspecified: there is no description of prompt-level caching, result reuse across runs, or de-duplication of LLM calls to control cost and latency.
- Fault tolerance and recovery details are missing: while “resume” is mentioned, there is no systematic treatment of checkpointing granularity, idempotency, retries/rate-limits, partial failure recovery, or long-running job management.
- Scheduling and optimization are undeveloped: beyond static validation in compile(), there is no pipeline optimizer for batching across operators, operator fusion, dynamic routing, adaptive stopping, or LLM selection to minimize cost/time.
- Data lineage and provenance tracking are underspecified: how per-sample metadata (LLM version, prompts/templates, seeds, hyperparameters, operator versions) are recorded for reproducibility, auditing, and rollback is not detailed.
- Dataset contamination and dedup strategies are unclear: the paper lacks methods and audits for preventing overlap with evaluation sets, cross-source/semantic deduplication, and leakage checks—especially critical for code/math/SQL benchmarks.
- Safety, bias, and PII handling are not evaluated: there is no systematic safety or privacy filtering protocol, no toxicity/bias analysis of synthesized data, and no PII detection/removal evaluation—despite reliance on LLM generation.
- Legal and licensing compliance is unaddressed: ingestion from web, PDFs, code repos, and SQL logs raises copyright/license/privacy questions; policies and tooling for compliance are not described.
- Multilingual and cross-domain generalization is untested: operators/prompts appear English-centric; there is no evaluation or guidance for multilingual pipelines or domain adaptation beyond the listed six use cases.
- Multimodality support is minimal: the framework largely treats non-text inputs by converting to text; there is no evaluation of image/PDF-to-text conversion quality or its impact on downstream datasets.
- Data model limitations for complex structures: tabular rows may not capture nested/multi-turn dialogues, tool traces, or function-calling artifacts; schema and storage strategies for hierarchical or graph-structured data are not specified.
- Observability and MLOps integration are missing: no discussion of logging, metrics, dashboards, pipeline visualization, error tracing, or integration with experiment trackers (e.g., MLflow, Weights & Biases).
- Interoperability with downstream training stacks is unclear: export formats, dataset cards, HF Datasets/Arrow compatibility, and handoff contracts to training pipelines are not specified.
- Agent reliability is unquantified: the DataFlow-Agent’s success rate in translating intent to valid pipelines, frequency and types of failures, number/cost of debugging iterations, and comparisons to manual pipelines are not reported.
- Agent code synthesis safety is not addressed: executing generated operators raises sandboxing, permissioning, and supply-chain risks; there are no controls for untrusted code, dependency management, or security audits.
- Quality of synthesized operators is not benchmarked: beyond “unit-level debugging,” there are no functional/efficiency benchmarks, robustness checks, or regression tests for newly generated operators/templates.
- Reproducibility of agent-generated pipelines is uncertain: non-determinism across runs (varying LLM outputs) and mechanisms to fix seeds, lock operator/template versions, and serialize the final DAG for exact reruns are not documented.
- Human-in-the-loop workflows are missing: guidelines and tooling for human review, rejection sampling, red-teaming, or quality assurance checkpoints within pipelines are not described.
- Statistical rigor of reported gains is unclear: there are no confidence intervals, significance tests, or sensitivity analyses (e.g., seeds, model variants) for the performance improvements claimed.
- Baseline fairness and coverage are limited: comparisons focus on select datasets and baselines; broader, standardized benchmarks and matched training/eval settings across multiple base models are not provided.
- Maintenance and API stability are unspecified: versioning policies for operators/templates, backward compatibility guarantees for extensions, and strategies to manage ecosystem churn are not discussed.
- Prompt and parameter optimization is unexplored: there is no methodology for systematic prompt tuning (e.g., bandits, Bayesian optimization), automatic operator hyperparameter search, or meta-optimization across pipelines.
- Guidelines for when to use the agent versus manual scripting are absent: decision criteria, productivity analysis, and recommended workflows for different user profiles are not provided.
- Quantitative evaluation of knowledge-extraction/refinement correctness is thin: methods to detect/mitigate hallucinations, assess factuality, and verify extracted QA pairs (especially for web/PDF pipelines) are not detailed.
- Resource utilization on local backends is unreported: GPU/CPU/memory profiles, batching efficiency, and contention across operators/LLM engines are not measured or tuned.
- Dataset release documentation lacks detail: dataset licenses, provenance, filtering steps, and known limitations/biases of DataFlow-Instruct-10K are not fully specified for downstream consumers.
Glossary
- Agentic RAG: Retrieval-Augmented Generation workflows that use autonomous agent behaviors (planning, tool use) to construct or refine data. "agentic RAG-style data"
- Chain-of-thought generation: Technique where a model produces explicit step-by-step reasoning to improve problem solving and supervision quality. "chain-of-thought generation"
- DataFlow-Agent: A multi-agent orchestration layer that translates natural-language specifications into executable, verified data pipelines. "DataFlow-Agent composes executable pipelines from natural-language intent, lowering the barrier to building scalable and semantically rich LLM-driven workflows."
- Directed Acyclic Graph (DAG): A graph with directed edges and no cycles, used to represent pipeline steps and their dependencies for correct execution order. "Directed Acyclic Graph (DAG) structure ready for processing."
- Extract–Transform–Load (ETL): A data engineering process that ingests data from sources, transforms it, and loads it into storage or systems. "Extract–Transform–Load (ETL)"
- Factory Method pattern: An object-oriented design pattern that separates object creation from usage, enabling deferred construction and flexible instantiation. "Factory Method pattern"
- Generate–Evaluate–Filter–Refine paradigm: A pipeline design pattern that synthesizes candidates, scores them, filters low-quality items, and applies targeted improvements. "generate–evaluate–filter–refine paradigm"
- HuggingFace Datasets: A library for standardized dataset storage, loading, and processing in machine learning workflows. "Ray and HuggingFace Datasets"
- Instruction tuning: Fine-tuning LLMs on curated instruction–response data to improve instruction-following behavior. "instruction tuning, chain-of-thought generation, or function calling"
- LangGraph: A framework for building stateful, graph-structured LLM agent systems and workflows. "Built on LangGraph"
- LLM serving: An abstraction layer to issue inference requests to local or API-based LLM backends uniformly. "LLM serving"
- Model-in-the-loop: A workflow design where LLMs are invoked inside data preparation steps to generate, refine, or evaluate data. "model-in-the-loop data generation"
- Prompt template: A parameterized prompt specification used to render inputs and constraints consistently across operators. "prompt templates"
- PyTorch-style pipeline construction API: A programming interface that mirrors PyTorch’s module/forward pattern for building debuggable, composable data pipelines. "PyTorch-style pipeline construction API"
- RAPIDS: NVIDIA’s GPU-accelerated libraries for data processing and analytics, integrated for scalable curation workflows. "Dask/RAPIDS"
- Ray: A distributed execution framework used to scale data processing and pipeline operations. "Ray and HuggingFace Datasets"
- SGLang: A high-throughput local inference engine for serving LLMs efficiently. "SGLang"
- Semantic deduplication: Removing near-duplicate items based on meaning rather than exact text matches. "semantic-level deduplication"
- Text-to-SQL: The task of converting natural language questions into executable SQL queries. "Text-to-SQL"
- Tokenization: Splitting text into tokens (words, subwords, or characters) as a basis for LLM processing. "tokenization, language detection, document segmentation, semantic deduplication, or safety filtering"
- Topological scheduling: Ordering operator execution based on dependency constraints in a DAG to ensure valid dataflow. "topological scheduling"
- User-Defined Functions (UDFs): Custom functions supplied by users to extend data processing systems with bespoke logic. "User-Defined Functions (UDFs)"
- vLLM: An optimized local LLM inference engine designed for high throughput and efficient serving. "vLLM"
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging DataFlow’s existing operators, pipelines, API, and the DataFlow-Agent.
- Unified, reproducible LLM data pipelines for enterprise model teams
- Sector: Software, MLOps, Data Engineering
- Tools/products/workflows: PyTorch-style “pipeline-as-code” workflows using DataFlow’s generate–evaluate–filter–refine operators; CLI scaffolding for internal operator libraries; storage abstraction for dataset versioning
- Immediate Impact: Replace ad‑hoc scripts with deterministic, debuggable, and shareable pipelines across teams and models
- Assumptions/dependencies: Python ecosystem adoption; access to local LLM serving (vLLM/SGLang) or API providers; basic GPU/CPU capacity; developer buy-in for code-first workflows
- High-quality code instruction synthesis for code assistants
- Sector: Software, Developer Tools
- Tools/products/workflows: DataFlow code pipeline to create code tasks, solutions, and evaluations; prompt templates for language-specific tasks; dataset aggregation for fine-tuning
- Immediate Impact: Measurable performance gains (+7% average reported in the paper) on code benchmarks for code copilots or teaching models
- Assumptions/dependencies: Access to code corpora; accurate evaluator/refiner operators; legal review for licensing of source code
- Natural language analytics via Text-to-SQL training
- Sector: Finance, Retail, BI/Analytics, Data Platforms
- Tools/products/workflows: Text-to-SQL pipeline to synthesize question–SQL pairs, evaluate execution accuracy, and filter incorrect SQL; training custom NL-to-SQL assistants for enterprise schemas
- Immediate Impact: Improved execution accuracy (+3% over strong baselines with <0.1M examples), enabling reliable BI chat interfaces
- Assumptions/dependencies: Access to database schemas and logs; sandboxed SQL execution for evaluation; data governance controls
- Agentic RAG knowledge base construction from PDFs and web data
- Sector: Enterprise Search, Knowledge Management, Customer Support
- Tools/products/workflows: Large-scale QA extraction pipeline over PDFs/web; agentic orchestration to build validated QA datasets; downstream RAG tuning
- Immediate Impact: Rapidly bootstrap internal QA knowledge bases for chatbots and support desks
- Assumptions/dependencies: Document ingestion/normalization; PII/safety filtering; storage and indexing infrastructure
- Data-efficient instruction tuning for small labs and startups
- Sector: Startups, Academia, Nonprofits
- Tools/products/workflows: Use DataFlow-Instruct-10K to fine-tune base models (e.g., Qwen2/Qwen2.5) with high-quality mixtures (text, math, code)
- Immediate Impact: Achieve performance comparable to training on vastly larger corpora, reducing costs and time-to-market
- Assumptions/dependencies: Availability of suitable base models; modest compute budgets; alignment with target task distribution
- Math problem generation with difficulty grading for education platforms
- Sector: Education, EdTech
- Tools/products/workflows: Math pipeline for generating, evaluating, and filtering problems; difficulty scoring operators for adaptive curricula
- Immediate Impact: Produce curricula and practice sets with controlled difficulty for tutoring systems
- Assumptions/dependencies: Reliable math evaluators; alignment to curricular standards; guardrails against error propagation
- Compliance-ready data quality gates
- Sector: Legal/Policy, Trust & Safety, Compliance
- Tools/products/workflows: Filtering operators for toxicity, privacy, and domain restrictions; evaluation logs for audits
- Immediate Impact: Reduce risk by enforcing safety filters and audit trails on training corpora and synthetic data production
- Assumptions/dependencies: Coverage and precision of safety filters; governance processes for exceptions and escalations
- Automated pipeline construction from natural-language specs
- Sector: Data Engineering, Research Labs
- Tools/products/workflows: DataFlow-Agent (LangGraph-based) to translate intent into verified DAG pipelines; operator synthesis where gaps exist
- Immediate Impact: Faster iteration for new data recipes and domain ports; lower barrier for non-experts
- Assumptions/dependencies: Agent reliability; sandboxed execution for verification; RAG context quality and operator docs
- ETL modernization for unstructured text
- Sector: Data Platforms, Content Operations
- Tools/products/workflows: Replace UDF-heavy Spark/Dask/Hadoop steps with LLM-driven operators (language detection, deduplication, refinement)
- Immediate Impact: Reduce engineering overhead for semantic cleaning, token-level operations, and LLM-in-the-loop tasks
- Assumptions/dependencies: Migration willingness; throughput tuning; fallback paths for structured ETL where needed
- Localization and multilingual data preparation
- Sector: Media, Global Support, Localization Services
- Tools/products/workflows: Prompt-template switching for multilingual generation/refinement; language identification and segmentation operators
- Immediate Impact: Quickly generate, refine, and evaluate multilingual instruction sets and QA corpora
- Assumptions/dependencies: Templates for target languages; cultural/linguistic correctness; evaluation for non-English outputs
- Academic reproducibility and benchmarking
- Sector: Academia, Open-Source Research
- Tools/products/workflows: Share pipelines (operators + templates + keys) and datasets as first-class artifacts; CLI scaffolding for extensions
- Immediate Impact: Transparent, reproducible data curation recipes and unified comparison of methods
- Assumptions/dependencies: Community adoption; standard dataset licenses; long-term maintenance of extensions
- Dataset governance with operator-level provenance
- Sector: MLOps, Data Governance
- Tools/products/workflows: Key-level dependency graphs; compile-time validation; checkpointing and resumption
- Immediate Impact: Traceable provenance for each sample and field; easier audits and incident response
- Assumptions/dependencies: Logging/monitoring integration; alignment with internal compliance frameworks
Long-Term Applications
These applications require further research, scaling, or development (e.g., multi-modal support, distributed backends, regulatory standards).
- Closed-loop self-improving training systems
- Sector: Foundation Model Training, MLOps
- Tools/products/workflows: Tight integration of DataFlow pipelines with training/evaluation to iteratively generate, score, and select new data (“train–analyze–synthesize” loops)
- Development Path: Automated curriculum shaping, data feedback controllers, continuous data refresh
- Assumptions/dependencies: Robust evaluation metrics; stable training APIs; significant compute budgets
- Multi-modal unified data preparation (text, image, audio, video)
- Sector: Healthcare Imaging, Autonomous Driving, Media
- Tools/products/workflows: Extend operator abstractions and templates to multi-modal inputs; modality-aware compilation and validation
- Development Path: Cross-modal generation, filtering, and alignment operators; scalable storage backends for large artifacts
- Assumptions/dependencies: Model availability; standardized representations; domain-specific evaluators
- Regulator-recognized synthetic data governance
- Sector: Policy, Public Sector, RegTech
- Tools/products/workflows: Standardized pipelines for auditable synthetic data generation and refinement; certification of procedural transparency
- Development Path: Collaboration with standards bodies; policy-compliant templates; consensus on evaluation criteria
- Assumptions/dependencies: Legal frameworks for synthetic data; documented risk controls; third-party audits
- Clinical knowledge extraction and QA building with strong de-identification
- Sector: Healthcare
- Tools/products/workflows: PDF/EMR ingestion, de-identification refiners, clinical QA evaluators; specialized domain templates
- Development Path: Domain operators for clinical ontologies, safety filters tuned to medical contexts
- Assumptions/dependencies: HIPAA/GDPR compliance; access to clinical corpora; rigorous human-in-the-loop validation
- Finance-grade Text-to-SQL and narrative synthesis for analysts
- Sector: Finance, FinOps
- Tools/products/workflows: Domain-specific SQL templates (vendor dialects), transaction narrative generators, risk filters
- Development Path: Integration with governance workflows, data masking, dialect-specific evaluators
- Assumptions/dependencies: Data privacy and audit controls; accurate execution environments; buy-in from risk/compliance teams
- Secure coding datasets and defensive model fine-tuning
- Sector: Cybersecurity, Software
- Tools/products/workflows: Pipelines that generate and evaluate secure coding examples (e.g., input validation, crypto hygiene), vulnerability-focused evaluators
- Development Path: Security-specific scoring operators; code execution sandboxes; community benchmarks
- Assumptions/dependencies: High-fidelity evaluators; access to secure coding corpora; legal review for exploit content
- Continual RAG data refresh with agentic orchestration
- Sector: Enterprise Knowledge, Customer Support
- Tools/products/workflows: Scheduled pipelines for scraping, QA synthesis, filtering, and RAG index updates; drift detection
- Development Path: Incremental compilation/resumption; knowledge change monitors; automated policy gates
- Assumptions/dependencies: Stable document pipelines; change-tracking infra; cost controls for continual LLM usage
- Operator and template marketplaces (DataFlow-Extensions ecosystem)
- Sector: Platform Economy, OSS
- Tools/products/workflows: Curated registries of domain operators/templates; quality signals and governance
- Development Path: Incentives for maintainers, compatibility checks, semantic versioning
- Assumptions/dependencies: Community scale; funding or stewardship; security vetting of packages
- Distributed storage and execution for trillion-token corpora
- Sector: Cloud Platforms, Big Data
- Tools/products/workflows: Database/object-store backends; distributed operator scheduling; GPU-aware batching
- Development Path: Ray/Dask/DB integrations; execution graphs with locality and caching
- Assumptions/dependencies: Significant engineering; cost-effective infrastructure; reliability SLAs
- IDE-level pipeline design assistants
- Sector: Developer Tools
- Tools/products/workflows: Language-server plugins for operator autocompletion, key-binding validation, and compile-time hints
- Development Path: Advanced static analysis; prompt template wizards; inline agent assistance
- Assumptions/dependencies: IDE ecosystem integration; user acceptance; documentation standards
- Public-sector data portals powered by automated QA extraction
- Sector: Government, Civic Tech
- Tools/products/workflows: Pipelines to turn regulations, reports, and FAQs into verified QA datasets and searchable knowledge bases
- Development Path: Policy-aware templates; multilingual support; public audit logs
- Assumptions/dependencies: Open-data mandates; accessibility requirements; community feedback loops
- Safety and hallucination control via advanced refine–evaluate loops
- Sector: Trust & Safety, AI Ethics
- Tools/products/workflows: Specialized operators to detect/mitigate hallucinations, factuality scoring, and safety refiners during data synthesis
- Development Path: Benchmarks for factuality; calibrated evaluators; hybrid human–AI review
- Assumptions/dependencies: Reliable metrics; domain knowledge; organizational commitment to safety processes
Collections
Sign up for free to add this paper to one or more collections.