- The paper introduces a modular reference architecture enabling LLM agents to interactively query complex workflow provenance.
- It details a domain-agnostic evaluation methodology with prompt engineering and RAG strategies, comparing performance across multiple LLMs.
- The study demonstrates scalability and adaptability in real-world workflows while highlighting challenges in complex graph-based provenance queries.
LLM Agents for Interactive Workflow Provenance: Reference Architecture and Evaluation Methodology
Introduction and Motivation
This paper presents a comprehensive reference architecture and evaluation methodology for deploying LLM agents to enable interactive querying and analysis of workflow provenance data in distributed scientific computing environments. The motivation stems from the increasing complexity and scale of scientific workflows operating across the Edge, Cloud, and High Performance Computing (HPC) continuum, where provenance data—metadata describing the lineage, execution, and context of workflow tasks—becomes both voluminous and semantically intricate. Traditional approaches relying on custom scripts, structured queries, or static dashboards are insufficient for exploratory, real-time, and flexible data interaction. The proposed agentic architecture leverages LLMs, prompt engineering, and Retrieval-Augmented Generation (RAG) to bridge the gap between users and complex provenance databases, supporting natural language interaction, live monitoring, and advanced analytics.
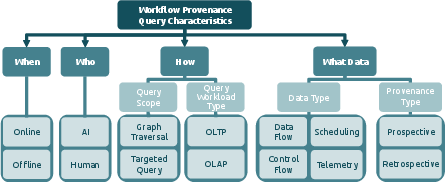
Figure 1: Taxonomy of workflow provenance query characteristics used to define query classes.
Reference Architecture for Provenance-Aware LLM Agents
The architecture is modular and loosely coupled, designed for scalability and interoperability across heterogeneous infrastructures. Provenance capture is achieved via two mechanisms: non-intrusive observability adapters (e.g., RabbitMQ, MLflow, file systems) and direct code instrumentation (e.g., Python decorators for Dask, PyTorch). Provenance messages are buffered and streamed asynchronously to a central hub using publish-subscribe protocols (Redis, Kafka, Mofka), minimizing interference with HPC workloads. The architecture supports multiple backend DBMSs (MongoDB, LMDB, Neo4j) and exposes a language-agnostic Query API for programmatic, dashboard, or natural language access.
A key innovation is the dynamic dataflow schema, incrementally inferred at runtime from live provenance streams, summarizing workflow structure, parameters, outputs, and semantic relationships. This schema is maintained in-memory by the agent's Context Manager and used to condition LLM prompts, enabling effective query translation and reasoning without requiring access to raw provenance records. This approach is particularly advantageous for privacy-preserving deployments and for workflows with rapidly evolving schemas.
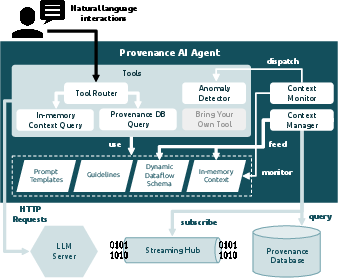
Figure 2: Provenance AI Agent Design.
Evaluation Methodology: Prompt Engineering and RAG Strategies
The evaluation methodology is domain-agnostic and system-independent, focusing on the design of RAG pipelines and prompt engineering to assess LLM performance across diverse provenance query classes. The process is iterative, comprising:
Experimental Results: Synthetic and Real-World Workflows
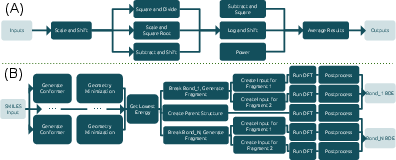
The agent was implemented atop the Flowcept infrastructure using Python MCP SDK, with GUI and API interfaces. Two workflows were used for evaluation:
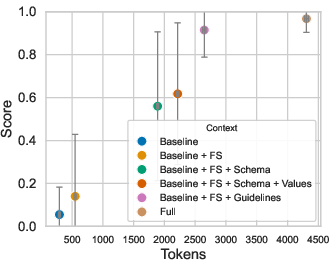
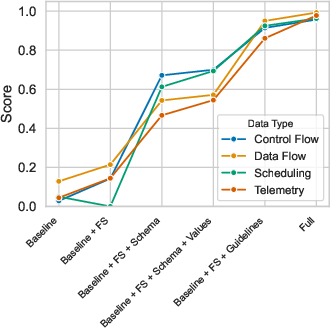
LLMs evaluated included LLaMA 3 (8B, 70B), GPT-4, Gemini 2.5, and Claude Opus 4. Prompts were incrementally enriched with context components (role, job, DataFrame format, few-shot examples, schema, domain values, guidelines). Query accuracy was assessed using LLM-as-a-judge (GPT and Claude), with each query executed multiple times to mitigate stochasticity.
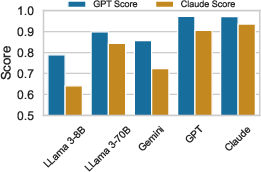
Figure 5: Scores assigned by two different judges.
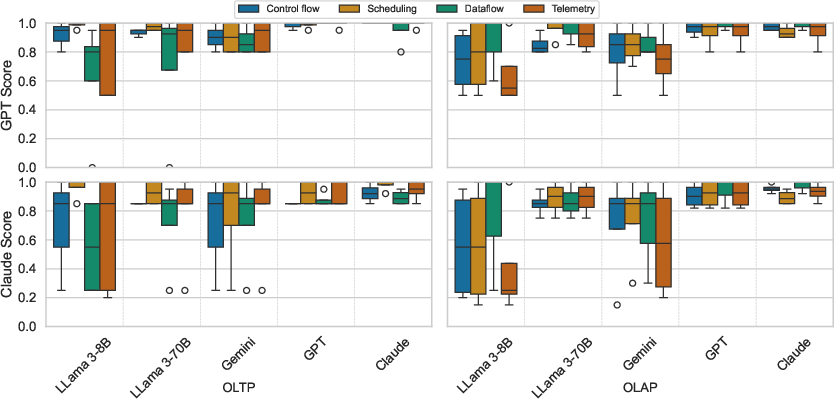
Figure 6: Different LLMs' performance in different query classes.
Key Findings
Live Interaction and Real-Time Analytics
A live demonstration on the Frontier supercomputer showcased the agent's ability to support real-time, natural language interaction with the chemistry workflow. The agent responded to queries with tables, plots, and summaries, inferring units and domain concepts, and supporting hypothesis validation and monitoring. While most queries were answered correctly, some edge cases (e.g., ambiguous atom counts, custom visualizations) revealed limitations in semantic inference and prompt adaptation.
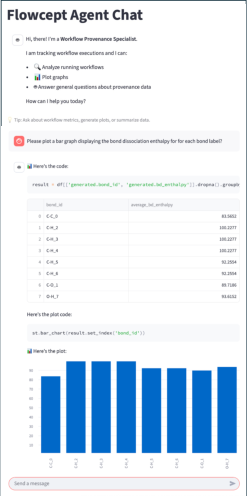
Figure 9: Live interaction with the chemistry workflow. The user interacts in natural language and receives responses, including plots, tabular results, and summarized text.
Implications, Limitations, and Future Directions
Practical Implications
- Accelerated Data-to-Insights: The agentic approach reduces the barrier to exploratory provenance analysis, anomaly detection, and monitoring, facilitating scientific discovery in complex ECH workflows.
- Modularity and Extensibility: Separation of concerns enables easy integration of new tools, scaling, and adaptation to diverse workflows and provenance systems.
- Privacy and Efficiency: Metadata-driven schema conditioning avoids raw data exposure and context window overflow, supporting secure and efficient deployment.
Theoretical Implications
- Schema-Driven Reasoning: Dynamic dataflow schemas enable LLMs to reason over workflow structure and semantics, supporting generalization and adaptability.
- Evaluation Methodology: LLM-as-a-judge provides scalable, nuanced assessment of agent performance, though human oversight remains necessary to mitigate bias and hallucination.
Limitations
- Graph-Based Provenance Queries: Deep causal analysis over persistent databases remains challenging; current DataFrame-centric logic is insufficient for multi-hop graph traversals.
- Semantic Quality Dependency: Agent performance depends on the intentionality and descriptiveness of workflow code; poor variable naming or lack of annotations can hinder inference.
- No Universal LLM: No single model excels across all query classes, motivating research into adaptive LLM routing and ensemble methods.
Future Work
- Dynamic Semantic Enrichment: Automated inference of domain semantics from code and data to improve agent reasoning.
- Feedback-Driven Prompt Tuning: Integration of auto-fixer agents for runtime correction and guideline adaptation.
- Scalable Graph Querying: Extension of architecture to support complex graph traversals and causal analysis in provenance databases.
- Extreme-Scale Workflows: Migration to high-performance in-memory buffers (e.g., Polars) for massive provenance data.
Conclusion
This work establishes a robust foundation for interactive, provenance-aware LLM agents in scientific workflows. By leveraging modular architecture, dynamic schema conditioning, and iterative prompt engineering, the agent enables accurate, scalable, and generalizable interaction with complex provenance data. The approach is validated across synthetic and real-world workflows, demonstrating high accuracy and adaptability. Open challenges remain in semantic enrichment, scalable graph querying, and adaptive LLM selection, but the proposed methodology and architecture provide a clear path forward for intelligent workflow analysis and accelerated scientific discovery.