- The paper introduces a data-centric framework for Sci-LLM development, highlighting the shift from domain-adapted models to autonomous scientific agents.
- It systematically reviews over 270 datasets and 190 benchmarks to establish a unified taxonomy and reveal key paradigm shifts.
- The study outlines actionable strategies for overcoming data heterogeneity, enhancing multimodal integration, and advancing closed-loop scientific discovery.
A Data-Centric Synthesis of Scientific LLMs: From Data Foundations to Agent Frontiers
Introduction
The paper "A Survey of Scientific LLMs: From Data Foundations to Agent Frontiers" (2508.21148) presents a comprehensive, data-centric review of the development, challenges, and future directions of scientific LLMs (Sci-LLMs). The authors reframe the evolution of Sci-LLMs as a co-evolutionary process between model architectures and the underlying scientific data substrate, emphasizing the unique multimodal, cross-scale, and domain-specific challenges that distinguish scientific AI from general-purpose LLMs. The survey systematically analyzes over 270 pre-/post-training datasets and 190 evaluation benchmarks, introduces a unified taxonomy of scientific data, and outlines a paradigm shift toward agentic, closed-loop scientific discovery systems.
Evolution and Paradigm Shifts in Sci-LLMs
The development of Sci-LLMs is characterized by four major paradigm shifts:
- Transfer Learning Era (2018–2020): Early domain-adapted models (e.g., SciBERT, BioBERT) leveraged continued pre-training on scientific corpora, yielding significant gains in scientific text understanding but limited generative and synthesis capabilities.
- Scaling Era (2020–2022): The introduction of large-scale models (e.g., GPT-3, Galactica) demonstrated that parameter and data scaling could yield emergent knowledge integration, but encountered a "data wall" due to the limited size and heterogeneity of high-quality scientific corpora.
- Instruction-Following Era (2022–2024): Alignment via RLHF and instruction tuning (e.g., InstructGPT, MedPaLM-2, SciGLM) enabled more precise task adaptation. The dual drive of architectural diversity and data scaling became central, with open-source LLMs and large-scale instruction datasets driving progress.
- Agentic Science Era (2023–present): The latest paradigm introduces scientific agents—autonomous AI systems capable of hypothesis generation, experimental design, data analysis, and discovery. Multi-agent and tool-integrated systems emulate laboratory hierarchies and scientific workflows, enabling end-to-end automation and closed-loop knowledge evolution.
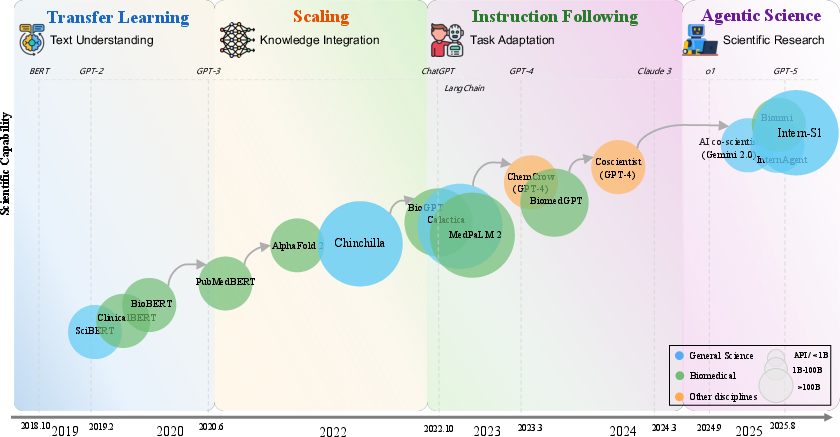
Figure 1: Evolution of Sci-LLMs reveals four paradigm shifts from 2018 to 2025, culminating in agentic systems capable of autonomous scientific research.
Taxonomy and Hierarchy of Scientific Data
The paper introduces a unified taxonomy of scientific data, encompassing:
- Textual formats: Papers, protocols, reports, and structured databases.
- Visual data: Medical imaging, microscopy, astronomical observations, and remote sensing.
- Symbolic representations: Molecular strings (SMILES, SELFIES), crystallographic files, mathematical equations.
- Structured data: Tables, relational databases, ontologies, and knowledge graphs.
- Time-series data: EEG, fMRI, astronomical light curves, climate records.
- Multi-omics integration: Genomics, transcriptomics, proteomics, metabolomics, and beyond.
This taxonomy is mapped onto a hierarchical model of scientific knowledge, spanning factual (raw data), theoretical (laws and principles), methodological/technological (tools and protocols), modeling/simulation (computational models), and insight (discoveries) levels.
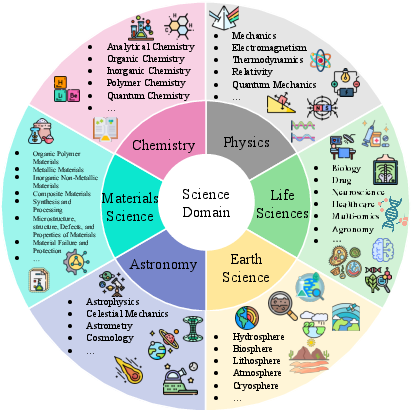
Figure 2: Six main scientific domains covered in this survey, illustrating the breadth of Sci-LLM applications.
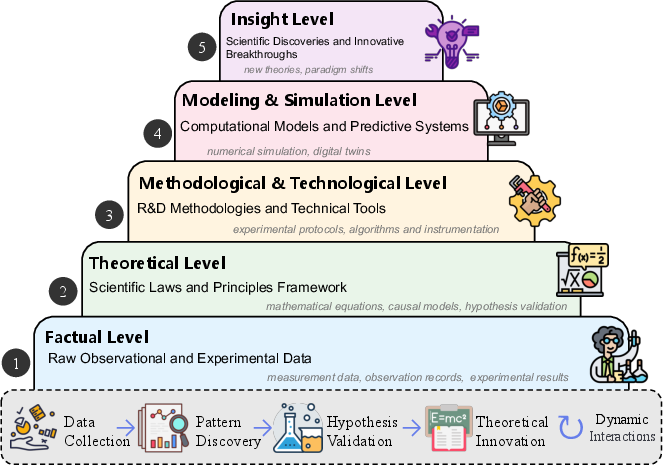
Figure 3: Hierarchical structure of scientific knowledge, from raw data to insight, with iterative feedback cycles.
Data Foundations: Pre-training, Post-training, and Evaluation
Pre-training Data
Scientific pre-training corpora are highly heterogeneous, spanning simulation outputs, experimental measurements, structured databases, and literature. The scale and diversity of these datasets are critical for domain-aware reasoning, but modality imbalance and lack of standardization persist. For example, Intern-S1 dedicates 2.5T tokens to scientific domains, yet most models remain text-centric due to the scarcity of high-quality multimodal data.
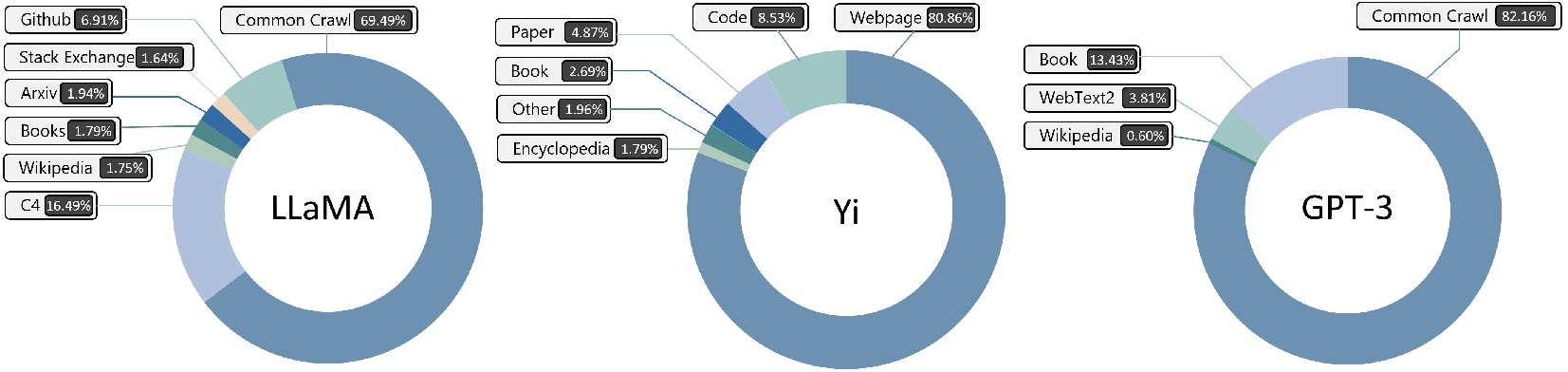
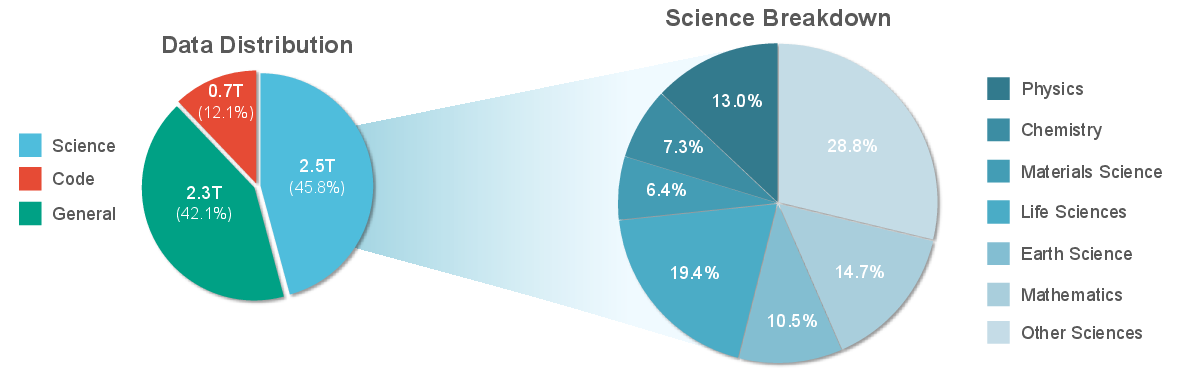
Figure 4: Pre-training dataset mixture of LLaMA, Yi, and GPT-3, highlighting the relative scarcity of scientific data.
Post-training Data
Post-training aligns models with scientific problem-solving styles via instruction tuning, chain-of-thought (CoT) supervision, and multimodal alignment. However, scientific content remains a small fraction of instruction-tuning datasets (e.g., Cambrian-7M: 2.9% science-specific). Domain-specific biases and cross-domain imbalances are prevalent, limiting generalization.
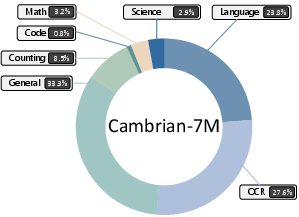
Figure 5: Composition of the Cambrian-7M instruction tuning dataset, with science-specific data as a minority.
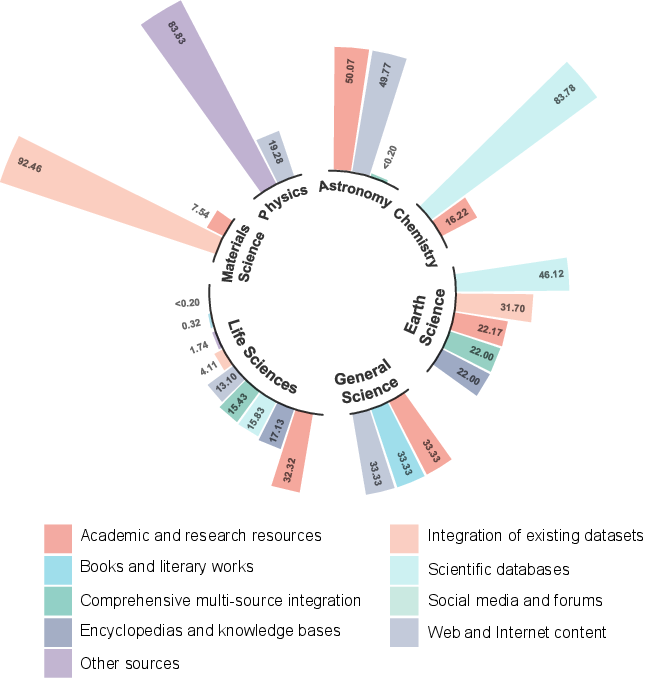
Figure 6: Source distribution of post-training corpora, showing domain-specific biases and cross-domain imbalance.
Evaluation Data
Evaluation benchmarks have evolved from static, exam-style QA to process- and discovery-oriented assessments. However, most domains rely on a single dominant source type, and headline scores often reflect proficiency with one writing style or data type rather than robust, cross-domain scientific reasoning.
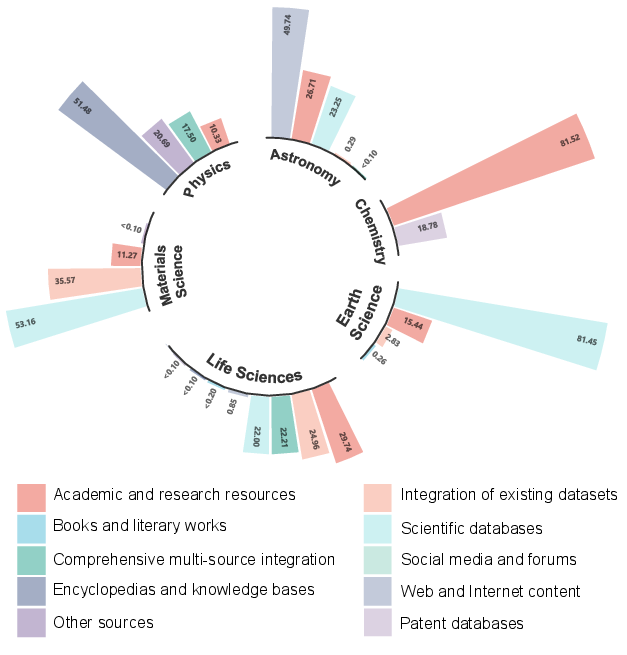
Figure 7: Source distribution of evaluation corpora, highlighting the need for broader, more heterogeneous evaluation suites.
Model Architectures and Scaling Trends
The Sci-LLM landscape is dominated by open-source, general-purpose families (LLaMA, Qwen), with most models in the 7B–13B parameter range due to deployment constraints (privacy, latency, cost). Multimodal Sci-MLLMs remain a minority, reflecting the dominance of text-based sources and the high cost of multimodal supervision.
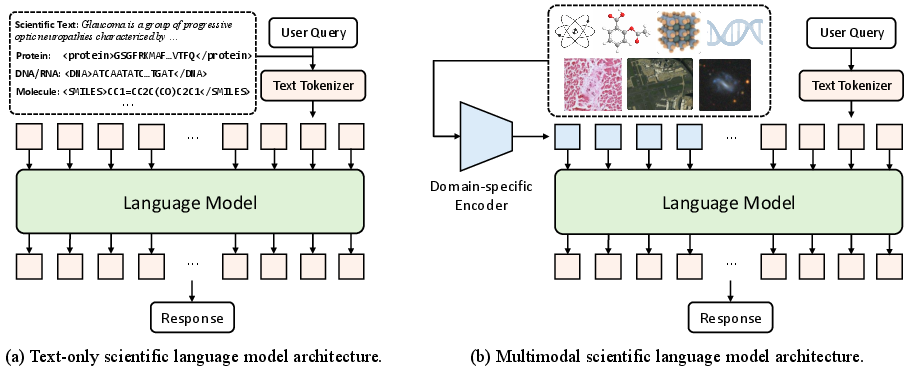
Figure 8: Common model architectures for scientific LLMs: text-only (left) and multimodal (right) pipelines.
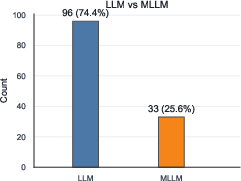
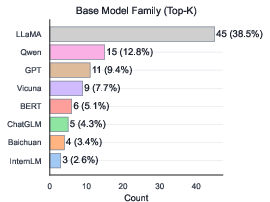
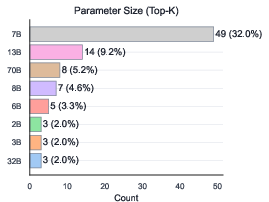
Figure 9: LLM vs MLLM ratio, illustrating the predominance of text-only models.
Key Challenges in Scientific AI
- Interpretability: Scientific reasoning requires transparent, stepwise explanations. CoT prompting and domain-specific reasoning traces are essential but challenging to scale and validate.
- Cross-scale and Multimodal Integration: Scientific data spans multiple scales and modalities. Current models struggle with seamless integration and cross-modal reasoning.
- Dynamic Knowledge Evolution: Static training corpora lead to knowledge staleness. Continuous knowledge injection, automated updating, and version control are critical for maintaining scientific relevance.
- Data Quality and Traceability: Incomplete metadata, lack of provenance, and inconsistent standards undermine reproducibility and trust.
- Data Latency and AI-Readiness: Delays in data publication and lack of standardized, machine-readable formats hinder real-time scientific reasoning and model updating.
The Shift Toward Agentic, Closed-Loop Scientific Discovery
The survey outlines a paradigm shift toward closed-loop systems where Sci-LLM-based agents autonomously experiment, validate, and contribute to a living, evolving knowledge base. These agents integrate with scientific tools, databases, and laboratory equipment, orchestrating end-to-end workflows from hypothesis generation to experimental validation.
(Figure 1, rightmost phase)
Figure 1: The latest paradigm introduces scientific agents—AI systems capable of autonomously conducting scientific research.
(Figure 3, bottom panel)
Figure 3: Iterative cycle linking knowledge levels through data collection, pattern recognition, hypothesis testing, and theory development.
Implications and Future Directions
Practical Implications
- Data-centric model development: Progress in Sci-LLMs is increasingly bottlenecked by data quality, diversity, and AI-readiness rather than model architecture alone.
- Multimodal and cross-domain integration: Future models must natively support heterogeneous data types and cross-scale reasoning, necessitating new architectures and training pipelines.
- Agentic systems: The transition to agentic, tool-using Sci-LLMs will require robust operating system-level protocols for tool orchestration, provenance tracking, and safety.
Theoretical Implications
- Epistemological alignment: The hierarchical model of scientific knowledge provides a principled framework for organizing data, training objectives, and evaluation metrics.
- Hybrid neural-symbolic reasoning: Integrating symbolic reasoning modules and constraint satisfaction systems is essential for scientific validity and interpretability.
Future Developments
- Automated, standardized data pipelines: Automated data cleaning, enrichment, and versioning will be critical for scalable, reproducible Sci-LLM development.
- Comprehensive evaluation frameworks: Benchmarks must evolve to assess reasoning depth, multimodal integration, and process-oriented scientific discovery.
- Sustainable data sharing and governance: Decentralized, transparent data ecosystems with robust privacy and compliance mechanisms are needed to support global, collaborative scientific AI.
Conclusion
This survey establishes a consolidated reference and roadmap for the development of trustworthy, continually evolving Sci-LLMs. By reframing model progress as a function of data foundations and agentic frontiers, the paper highlights persistent challenges in data quality, representation, and knowledge updating, while outlining actionable strategies for building AI systems that function as true partners in accelerating scientific discovery. The transition from static, text-centric models to autonomous, multimodal scientific agents marks a critical inflection point in the integration of AI and scientific research.

