A Practical Guide for Designing, Developing, and Deploying Production-Grade Agentic AI Workflows
Abstract: Agentic AI marks a major shift in how autonomous systems reason, plan, and execute multi-step tasks. Unlike traditional single model prompting, agentic workflows integrate multiple specialized agents with different LLMs(LLMs), tool-augmented capabilities, orchestration logic, and external system interactions to form dynamic pipelines capable of autonomous decision-making and action. As adoption accelerates across industry and research, organizations face a central challenge: how to design, engineer, and operate production-grade agentic AI workflows that are reliable, observable, maintainable, and aligned with safety and governance requirements. This paper provides a practical, end-to-end guide for designing, developing, and deploying production-quality agentic AI systems. We introduce a structured engineering lifecycle encompassing workflow decomposition, multi-agent design patterns, Model Context Protocol(MCP), and tool integration, deterministic orchestration, Responsible-AI considerations, and environment-aware deployment strategies. We then present nine core best practices for engineering production-grade agentic AI workflows, including tool-first design over MCP, pure-function invocation, single-tool and single-responsibility agents, externalized prompt management, Responsible-AI-aligned model-consortium design, clean separation between workflow logic and MCP servers, containerized deployment for scalable operations, and adherence to the Keep it Simple, Stupid (KISS) principle to maintain simplicity and robustness. To demonstrate these principles in practice, we present a comprehensive case study: a multimodal news-analysis and media-generation workflow. By combining architectural guidance, operational patterns, and practical implementation insights, this paper offers a foundational reference to build robust, extensible, and production-ready agentic AI workflows.














Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper is a “how-to” guide for building smart AI systems that can do multi-step jobs on their own—safely, reliably, and at real-world scale. These systems use several small “AI agents” that each specialize in one task (like searching the web, writing, checking facts, or publishing files) and work together like a well-organized team.
What questions the paper tries to answer
The paper focuses on a few big questions:
- How do you design an AI system made of many cooperating agents so it’s clear, simple, and dependable?
- How do you connect these agents to tools (like web browsers, databases, or publishing services) without things becoming messy or unpredictable?
- How do you make sure the system is responsible (avoids bias and hallucinations), easy to monitor, and safe to run?
- How do you package and deploy it so it works the same way in testing and in production?
How they approached it
The authors don’t just talk theory—they give a step-by-step engineering playbook and a real example:
- Think of each “agent” like a teammate with one clear job. Some read web pages, some write scripts, some check for mistakes, and others publish results.
- Instead of one giant prompt, the system breaks the job into smaller, dependable steps. This makes it easier to test and fix.
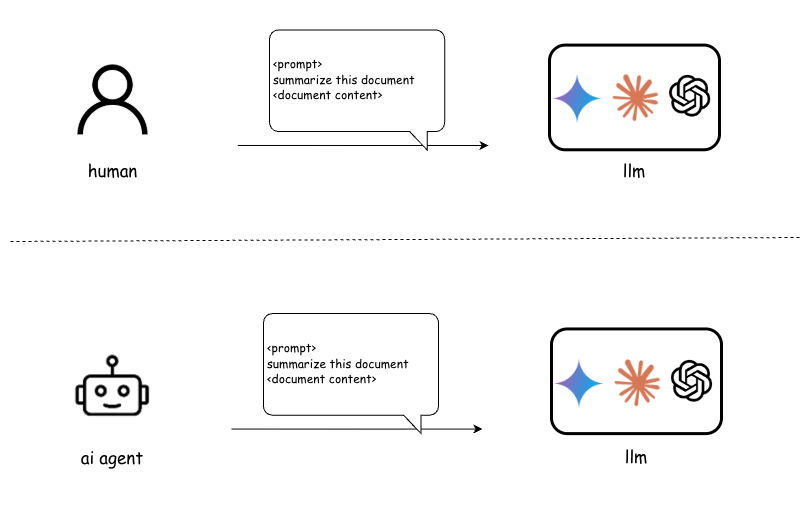
- They explain when to let the AI “choose a tool” on its own and when to have the computer call a function directly (like pressing a button automatically instead of asking the AI to figure out which button to press).
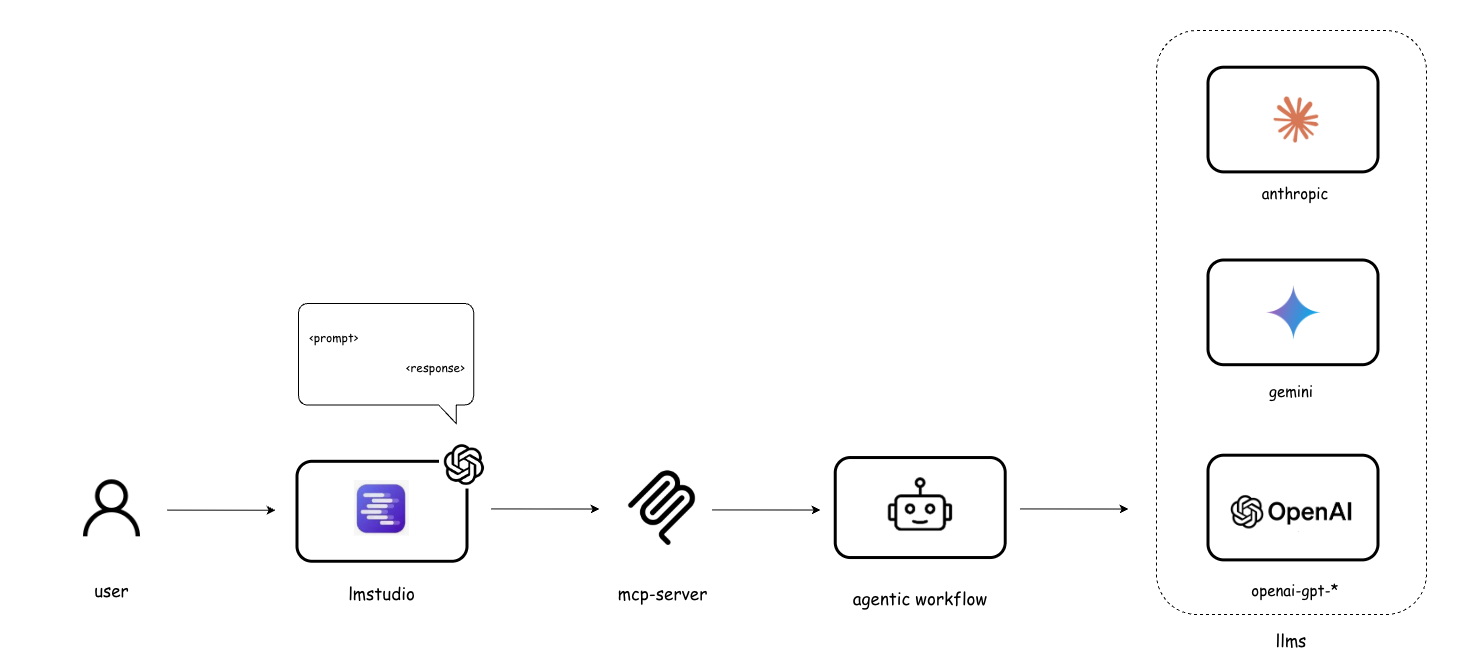
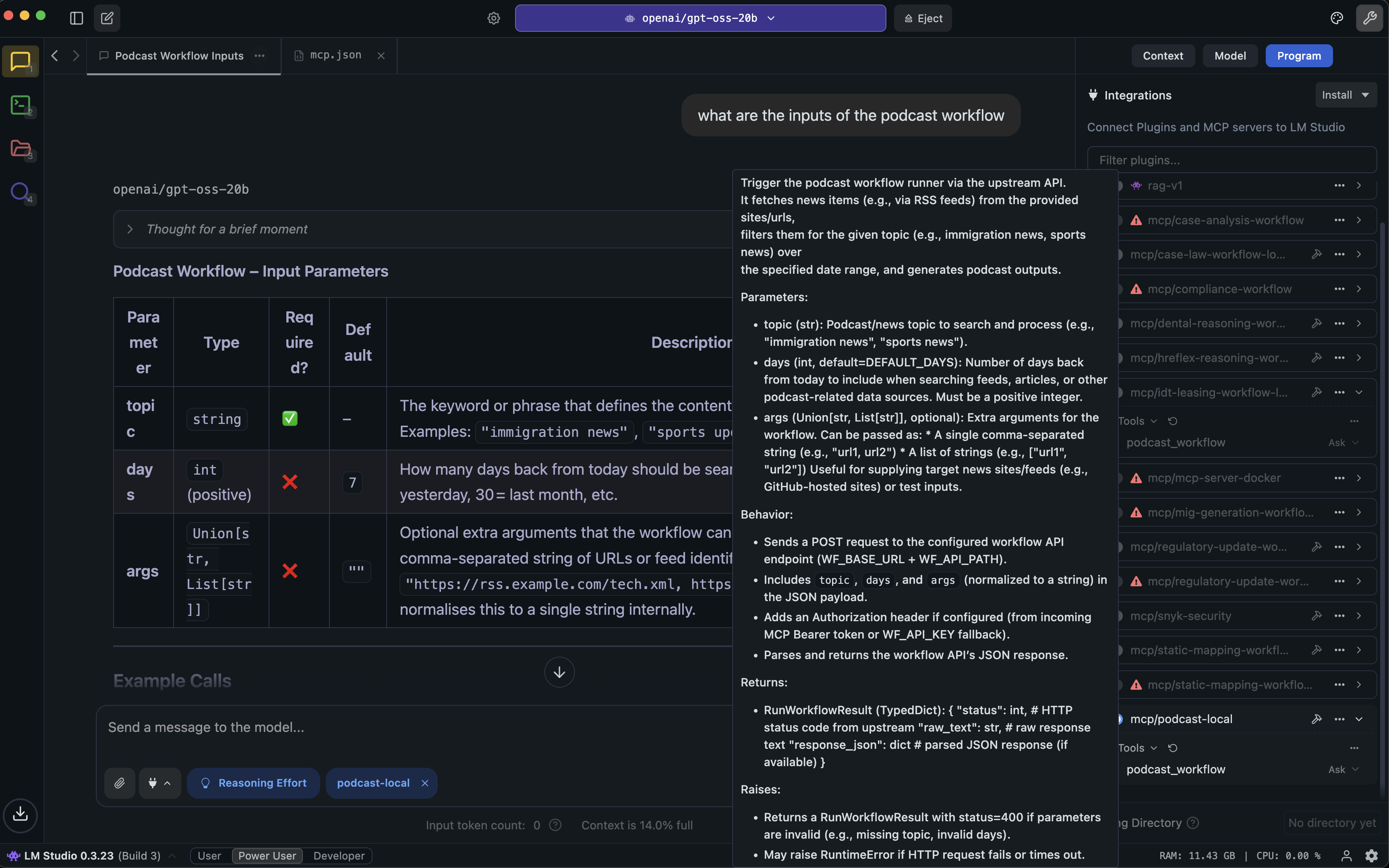
- They use the Model Context Protocol (MCP)—basically a universal adapter—to let AI agents talk to outside services in a standard way, but only where that makes sense.
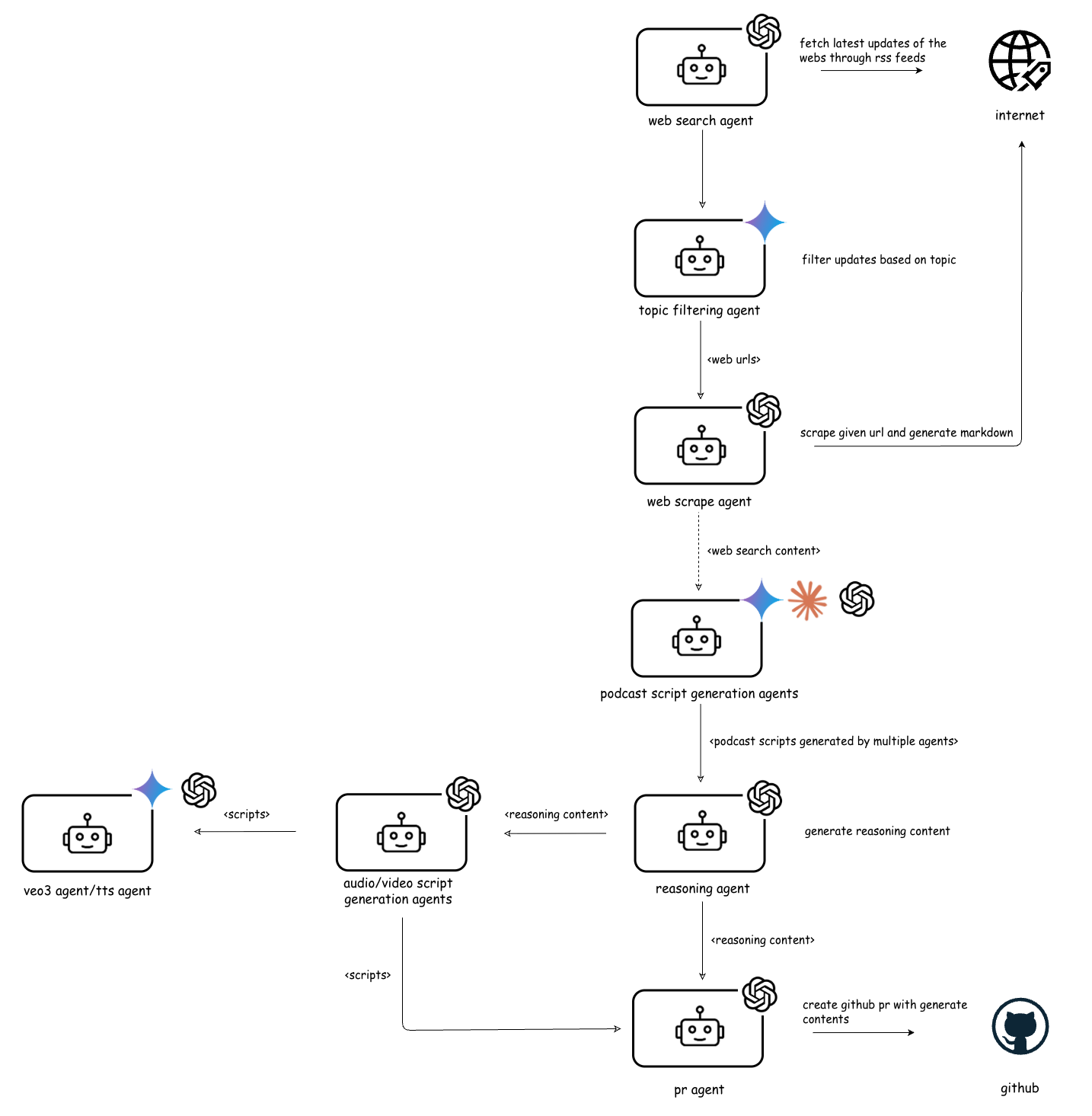
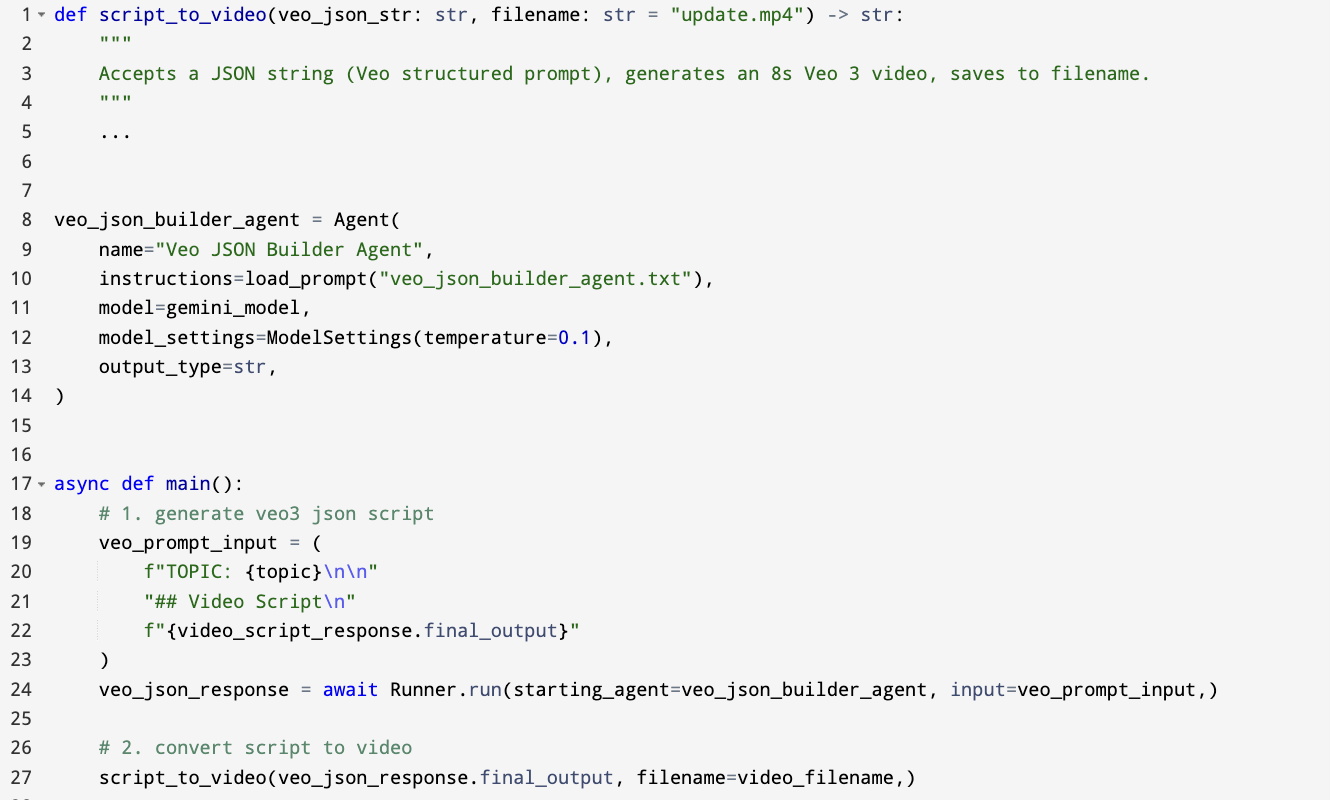
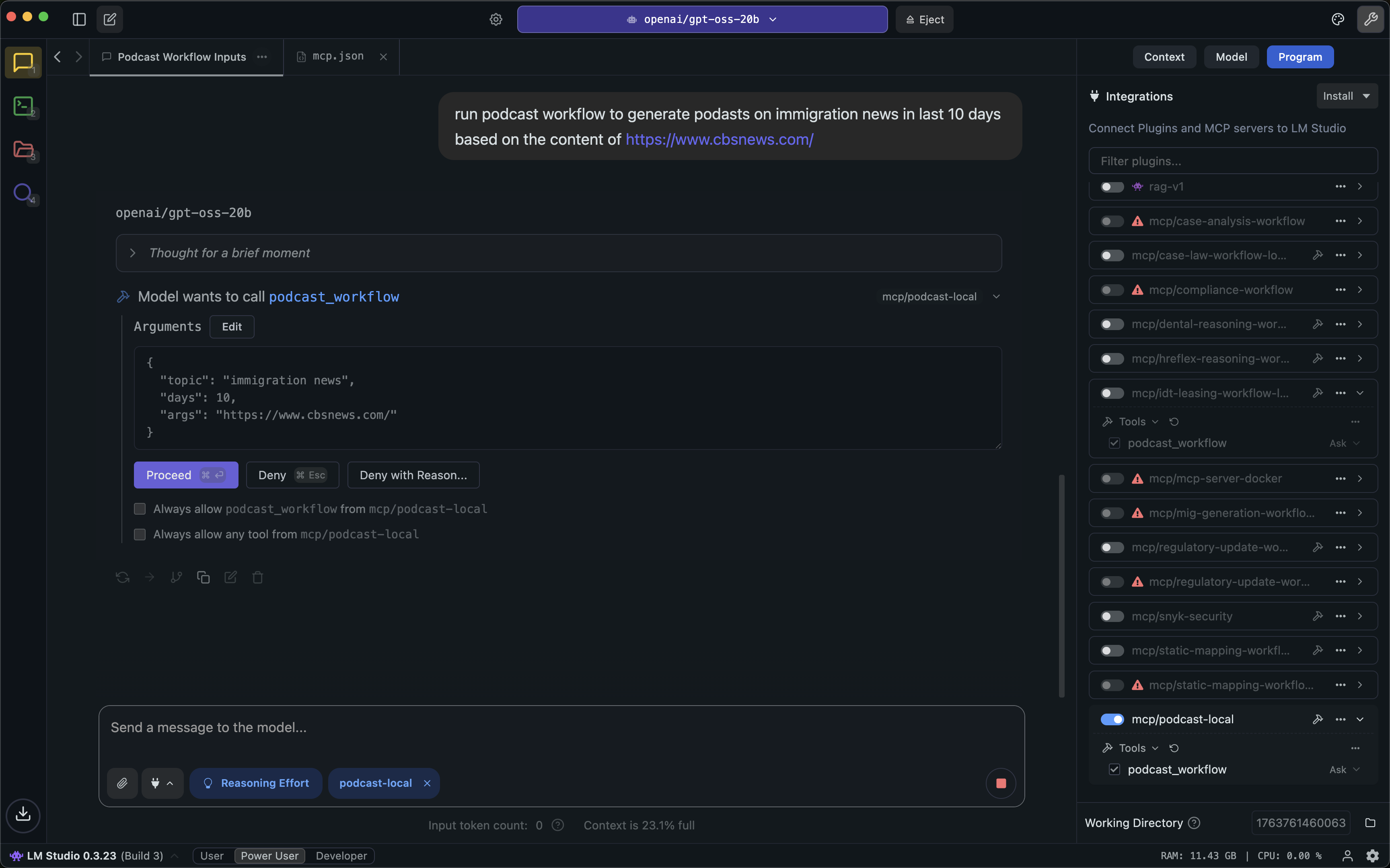
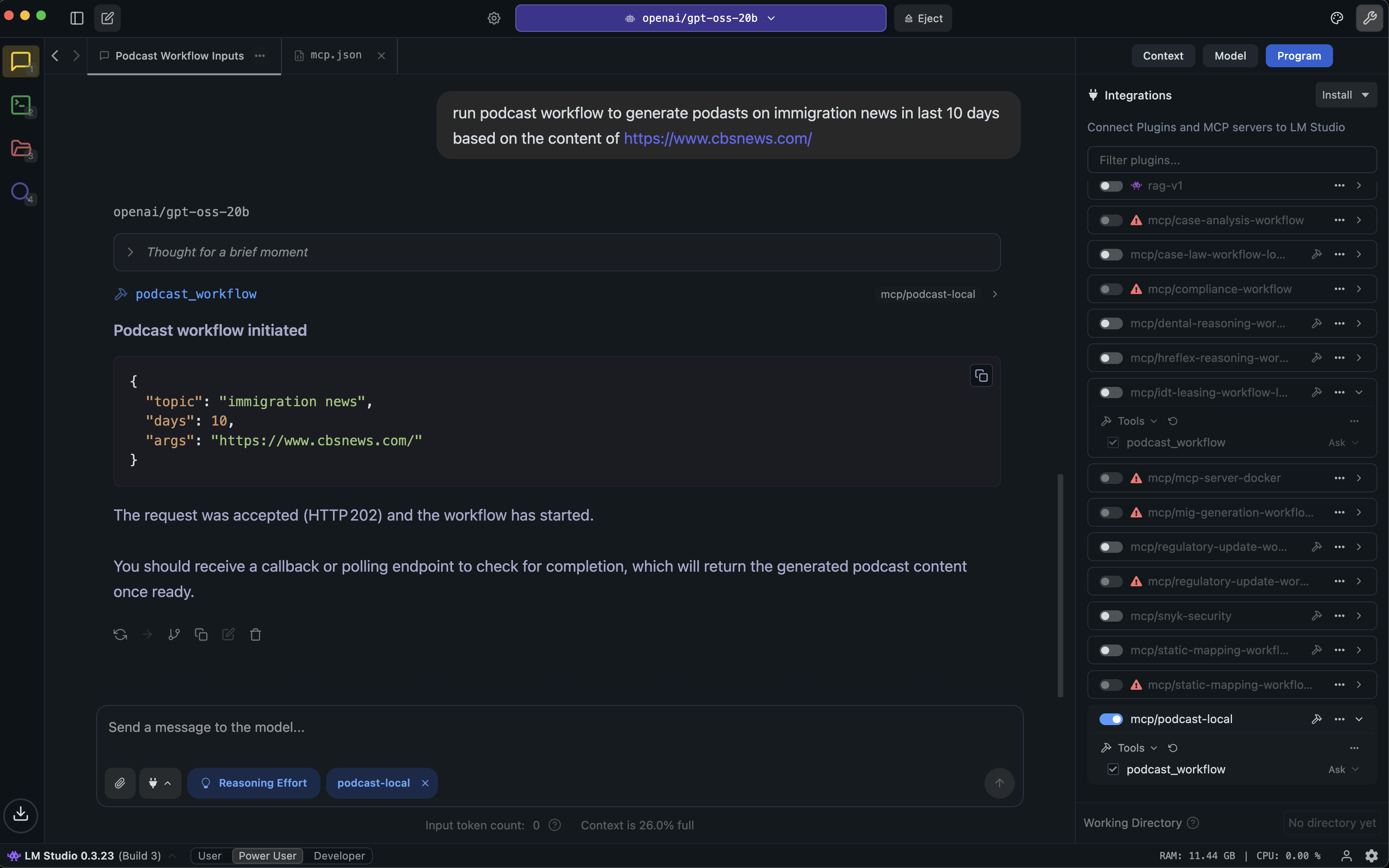
- They follow nine best practices (see below) and show how these work in a real project: an automated pipeline that turns fresh news into a podcast with audio and video, and then publishes it to GitHub.
- They deploy everything in containers (like shipping containers for software), which makes it easy to run the same system anywhere and scale it up safely.
To make this concrete, they built:
- A news-to-podcast workflow that:
- Finds news, filters by topic, and scrapes clean text
- Uses several different AI models to write draft scripts
- Uses a “reasoning” agent to combine drafts, remove mistakes, and create a final script
- Turns that script into audio and video
- Publishes all files automatically to GitHub
- A thin MCP server that exposes the workflow to MCP-enabled tools
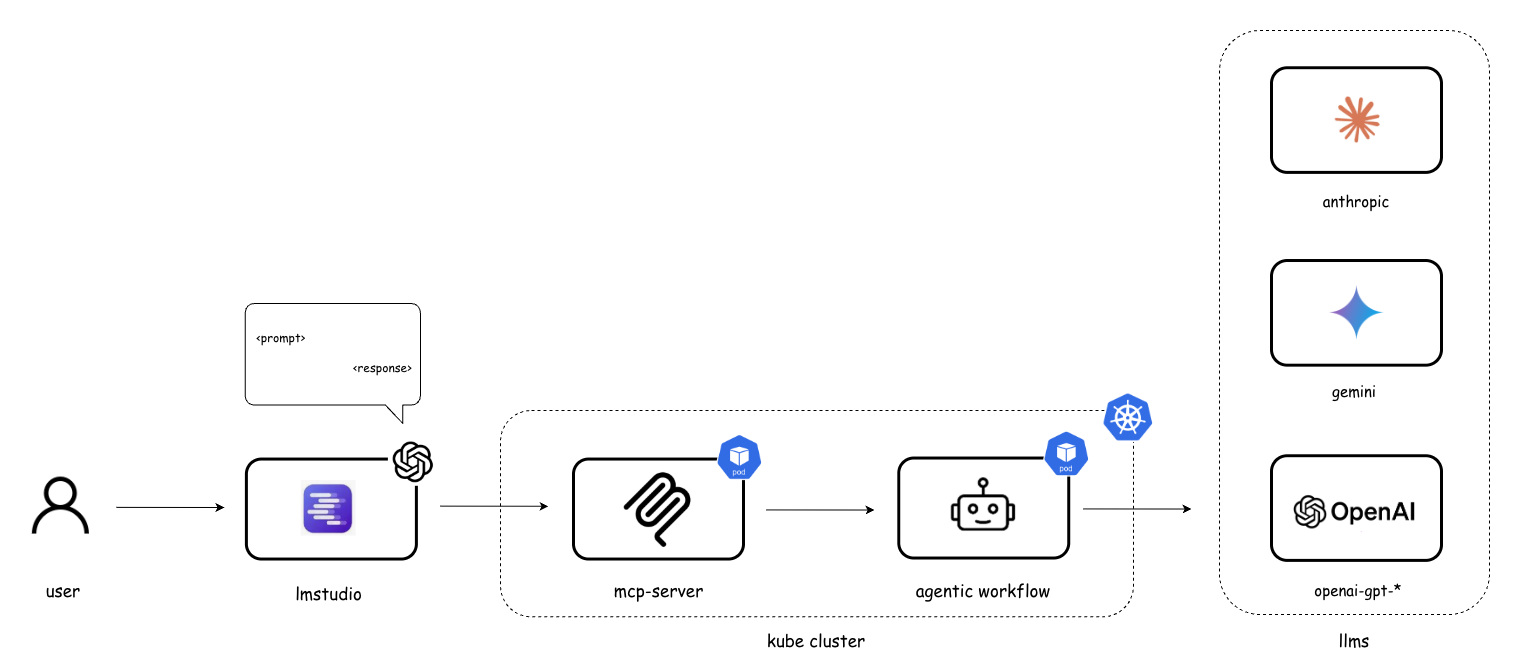
- A containerized deployment using Docker and Kubernetes for reliability and scale
What they found and why it matters
The main findings are practical rules that make agent-based AI systems much more stable and easier to run:
- Keep tools simple and clear. If the job doesn’t need language reasoning (like “create a pull request”), call a direct function instead of asking the AI to choose and format a tool call. This reduces errors and cost.
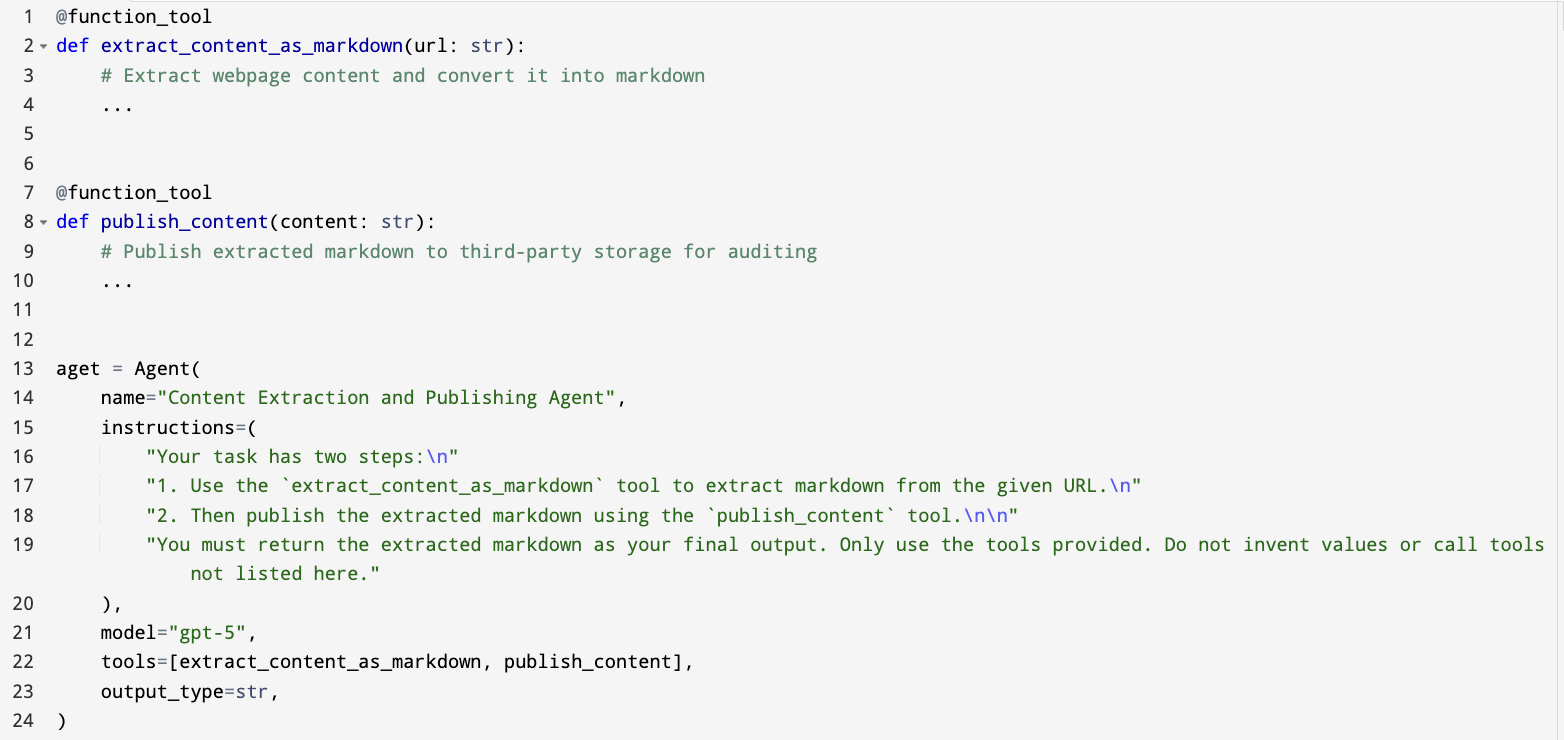
- One agent, one job. Don’t overload agents with many tools or mixed responsibilities. When each agent does one thing well, the whole system becomes more predictable and easier to debug.
- Separate planning from doing. Let an agent design a plan (like a structured video prompt), but use regular code to call external services (like the video API). This avoids messy side effects and “hallucinated” results.
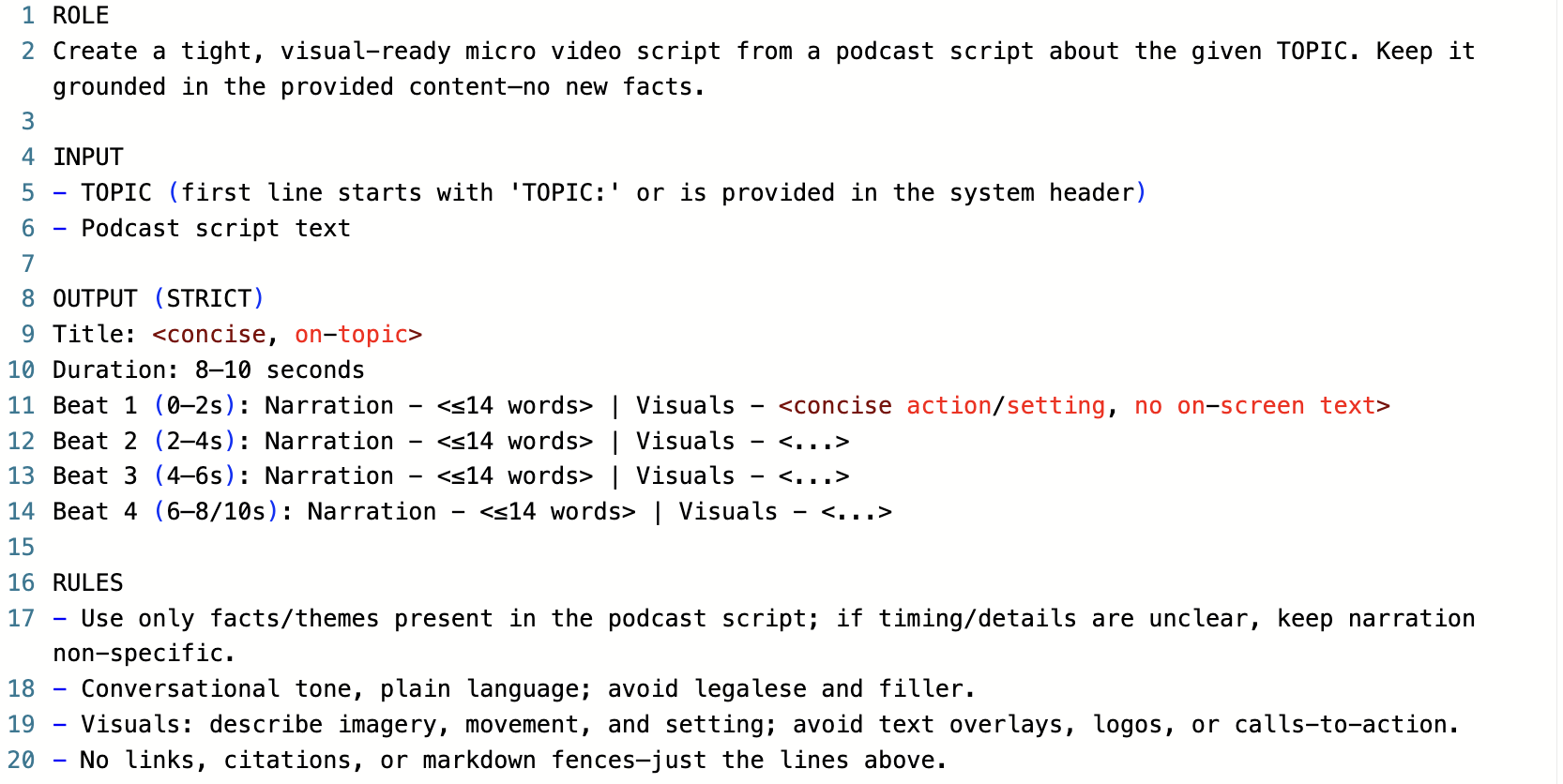
- Store prompts outside the code so non-programmers can update instructions safely (and you can version and review them).
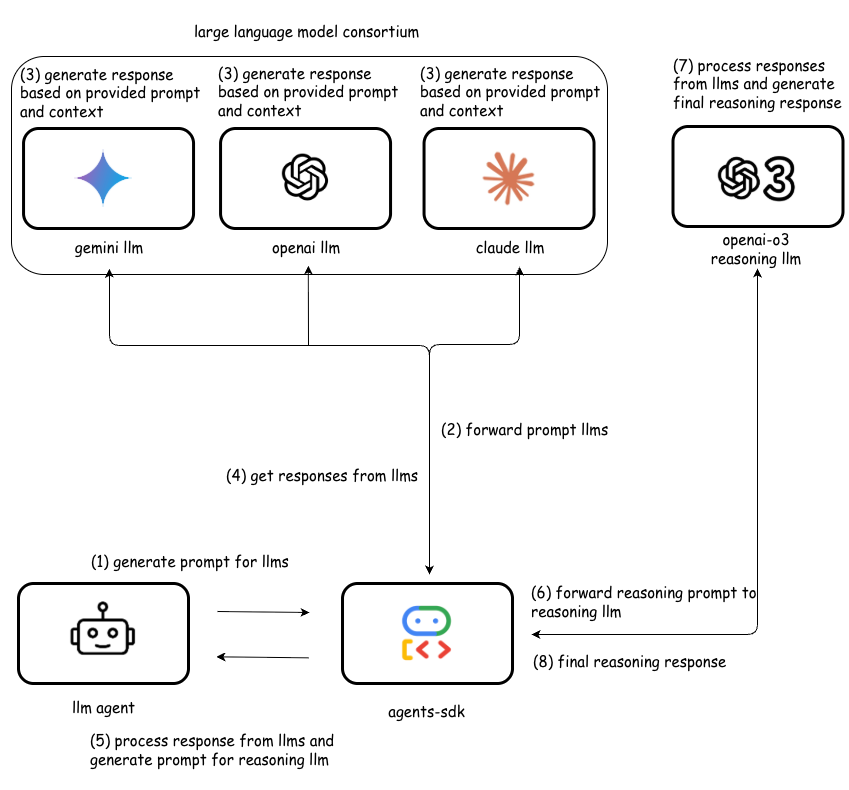
- Use multiple AI models and a reasoning agent to combine their answers. This lowers bias and reduces hallucinations because the final answer is based on cross-checking, not just one model’s opinion.
- Keep the workflow engine separate from the MCP server. The MCP layer should be a thin adapter, not the place where your main logic lives.
- Package and deploy with containers and Kubernetes for consistency, scaling, and monitoring.
- Follow the KISS principle: Keep It Simple, Stupid. Don’t over-engineer; flat, readable designs work best for agent systems.
In their podcast case study, these choices led to:
- More reliable tool use
- Less confusion in agent behavior
- Lower costs (fewer tokens and retries)
- Better accuracy when combining scripts from different models
- Smooth, automated publishing to GitHub
The nine best practices (in plain language)
Here’s a short, readable summary of the nine practices the paper recommends:
- Prefer simple, direct function calls when no language reasoning is needed; use tools (or MCP) only when it helps.
- When you do use tools, stick to “one agent, one tool” to avoid confusion.
- Give each agent a single responsibility (plan vs. execute; generate vs. validate).
- Keep prompts outside your code and load them at runtime.
- Use a multi-model “consortium” (several models) and a reasoning agent to cross-check and consolidate outputs.
- Separate your workflow logic (the brain) from the MCP server (the adapter).
- Containerize everything and use Kubernetes in production.
- Design for observability, testing, and determinism (make runs repeatable).
- Follow KISS: keep designs flat, clear, and easy to maintain.
Why this is important
This guide helps teams move from flashy demos to dependable systems. By treating AI agents like parts of a well-run factory—each with a defined job, clear handoffs, and strong safety checks—you can:
- Reduce bugs and surprise behavior
- Lower costs and improve speed
- Make systems easier to test, monitor, and fix
- Build outputs that are fairer, more accurate, and more trustworthy
What this could change in the real world
If organizations follow these practices, they can safely automate complex tasks like:
- Media creation (podcasts, videos)
- Compliance checks and reporting
- Data analysis and summarization
- Content moderation and review
- Enterprise workflows with many systems
In short, this paper offers a practical blueprint for building AI “teams” that work reliably in the real world—not just in a lab.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that the paper leaves unresolved. These items are intended to guide future research and engineering work.
- Quantitative performance is not reported: latency, throughput, token usage, error rates, and cost per run across agents and end-to-end.
- No controlled ablation studies comparing MCP vs tool calls vs pure functions; selection criteria and measurable trade-offs are unspecified.
- Robustness under load and concurrency is untested: stress/chaos testing, backpressure, retry policies, and graceful degradation in Kubernetes.
- Determinism is advocated but not formalized: no method to specify, verify, and measure deterministic execution paths across agents and tools.
- Inter-agent communication contracts are unclear: message schemas, versioning, schema-drift handling, and backward compatibility strategies.
- State and memory management are not described: persistence, caching, cross-run context reuse, and data retention policies for workflow artifacts.
- The LLM consortium’s consolidation method lacks detail: weighting schemes, tie-breaking rules, and formal conflict-resolution strategies.
- Responsible AI claims are not backed by metrics: no bias, factuality, toxicity, or hallucination benchmarks; no standardized RA audit protocol.
- No human evaluation or user studies of output quality, trustworthiness, or usability for the generated podcasts and videos.
- Legal and compliance aspects of web scraping and content reuse are not addressed: licensing, robots.txt adherence, copyright, and privacy.
- Security and threat modeling are absent: MCP/tool injection risks, prompt supply-chain tampering, secret management, and perimeter hardening.
- Observability practices are under-specified: trace correlation across agents, OpenTelemetry adoption, log schema, alerting, and SLOs/SLAs.
- Model versioning and drift management are not covered: pinning, rollback, canarying model updates, and reproducibility across vendor changes.
- Cost governance is missing: budgeting, optimization (caching, batching, smaller models), and ROI trade-offs for multi-agent ensembles.
- Evaluation lacks ground truth and statistics: reliance on representative outputs without quantitative scoring or statistical significance.
- Multimodal quality metrics are absent: TTS intelligibility/prosody, video fidelity/scene coherence, and both automated and human scoring.
- Veo-3 integration is validated only syntactically: success rate of video generation, error handling, retry/backoff, and quality assurance are not measured.
- Generalizability to other domains is untested: what components are reusable, domain-specific tool integration patterns, and portability assessments.
- The “one agent, one tool” rule has no documented exceptions or decision framework; performance impacts of alternative designs remain unknown.
- Orchestration details are missing: task scheduling, parallelism control, resource quotas, and placement strategies in Kubernetes.
- Data governance gaps: handling PII in scraped content, redaction, audit logs, retention windows, and regulatory compliance (e.g., GDPR/CCPA).
- Testing strategy is not described: unit/integration tests for agents/tools, mocking LLMs, regression testing, and CI/CD gates.
- No comparison to alternative agent frameworks (e.g., LangChain, AutoGen) to substantiate claimed engineering benefits.
- Failure modes are not cataloged: timeouts, tool errors, model API outages, and concrete fallback/rollback patterns for resilience.
- MCP interoperability is only demonstrated with LM Studio: cross-client compatibility, performance differences, and vendor-agnostic behavior remain open.
- Prompt management governance is unspecified: versioning, drift monitoring, review workflows, A/B testing, and rollback policies.
- Ethical considerations are not explored: disclosure of synthetic media, misinformation risks, provenance tracking, and content authenticity controls.
- Empirical support for KISS benefits is lacking: no evidence linking architectural simplicity to improved reliability, cost, or maintainability.
Practical Applications
Practical applications derived from the paper
Below are actionable applications that translate the paper’s findings, engineering patterns, and case study into real-world impact. Each item includes sector links, prospective tools/workflows, and feasibility assumptions.
Immediate Applications
Media and Entertainment
- Automated news-to-podcast/video pipeline — Convert live news into vetted scripts, TTS audio, Veo-3 video, and PRs to a CMS or repository using multi-agent orchestration and a reasoning auditor.
- Sectors: media, marketing, creator economy, communications
- Tools/workflows: RSS/MCP search; web scraping to Markdown; multi-LLM script agents; reasoning agent; TTS (e.g., Azure/ElevenLabs); Veo-3; GitHub/GitLab PR; Docker/Kubernetes
- Assumptions/dependencies: stable news feeds and scraping; model/API access (LLMs, TTS, video); content rights; cost controls; human-in-the-loop editorial sign-off
- Brand newsroom and social content studio — Generate brand-safe explainers, PR briefs, and short-form video/audio from topical sources with externalized prompts and a model consortium for bias mitigation.
- Sectors: marketing, PR, corporate communications
- Tools/workflows: prompt ops repo; multi-model agents (OpenAI, Anthropic, Google, Llama); reasoning agent; CMS/MCP integration
- Assumptions/dependencies: governance rules in prompts; content ownership and approvals; rate-limit handling
Finance and Market Intelligence
- Executive brief and alerting hub — Monitor SEC filings, earnings calls, and trusted news feeds; summarize with multi-model agents; consolidate via reasoning; publish to Slack/Confluence as versioned PRs.
- Sectors: finance, enterprise software
- Tools/workflows: fetch/parse filings; topic filtering; multi-LLM summaries; reasoning consolidation; PR/bot automation; OpenTelemetry tracing for audits
- Assumptions/dependencies: access to filings/APIs; compliance review; cost and latency budgets; data retention rules
- Competitive intelligence digests — Track competitor product updates and analyst coverage; synthesize weekly digests with citations grounded in scraped Markdown.
- Sectors: strategy, product management
- Tools/workflows: scraping; RAG-ready Markdown; multi-agent summarization; MCP client plugins
- Assumptions/dependencies: source quality; grounding enforcement in prompts; reviewer checks for claims
Compliance, Legal, and Risk
- Regulatory change monitoring — Aggregate regulatory/RFC updates, classify relevance, summarize implications, and draft internal change logs with deterministic function calls for system-of-record updates.
- Sectors: healthcare, finance, energy, telecom, public sector
- Tools/workflows: policy feed ingestion; single-responsibility agents; reasoning agent; direct API calls over tool calls for ticketing/record systems
- Assumptions/dependencies: human approval gates; auditable logs; clear provenance requirements; MCP separation for secure exposure
- Policy and guideline harmonization — Compare multiple policy sources using model-consortium agreement; produce reconciled SOP drafts with tracked revisions.
- Sectors: enterprise GRC, legal ops
- Tools/workflows: externalized prompts; reasoning agent for conflict resolution; PR-based review workflows
- Assumptions/dependencies: document access and permissions; version control discipline; legal review
Customer Operations and Support
- Knowledge base refresh automation — Scrape product docs/releases; generate validated KB articles; open PRs to support portals; rollback via version pinning.
- Sectors: SaaS, consumer tech, B2B software
- Tools/workflows: scraping-to-Markdown; single-tool agents; direct PR functions; CI checks
- Assumptions/dependencies: publishing rights; content QA; rate limits on source systems
- Conversation summarization and escalation briefs — Multi-model drafts consolidated to reduce bias; deterministic handoff to ticketing systems via pure functions.
- Sectors: contact centers, IT support
- Tools/workflows: call/chat transcript interfaces; reasoning consolidation; direct API calls to CRM/ITSM
- Assumptions/dependencies: PII/PHI handling; retention and access controls; model redaction policies
Education and Training
- Course micro-asset generation — Create lesson scripts, quizzes, audio summaries, and short videos from curated readings with externalized prompts and MCP-laced LMS adapters.
- Sectors: education, corporate L&D
- Tools/workflows: content ingestion; multi-agent script + reasoning; TTS/video; LMS MCP connectors
- Assumptions/dependencies: content licensing; accessibility standards; instructor review loops
- Literature review synthesizer — Multi-model summaries of papers with a reasoning auditor for consensus; PRs to lab wikis with traceable citations.
- Sectors: academia, R&D
- Tools/workflows: PDF-to-Markdown; model consortium; Git-based wiki publishing
- Assumptions/dependencies: citation fidelity; reproducibility and prompt versioning
Cybersecurity and DevSecOps
- Vulnerability intelligence feeds — Aggregate CVEs/advisories, deduplicate, prioritize, and open PRs for patch instructions in internal runbooks.
- Sectors: cybersecurity, SRE/DevOps
- Tools/workflows: feed parsers; single-responsibility agents; reasoning for de-dup and prioritization; CI/CD for runbook updates
- Assumptions/dependencies: severity scoring inputs; approval workflow; audit trails
- Build governance for agentic systems — Apply the nine best practices (KISS, pure functions, single-tool agents, containerization) to harden existing agent prototypes into production services.
- Sectors: platform engineering, ML ops
- Tools/workflows: Docker/Kubernetes; RBAC/secrets; OpenTelemetry; cost monitoring
- Assumptions/dependencies: platform availability; ops maturity; observability setup
Internal Knowledge and Communications
- Auto-generated internal newsletters — Curate internal docs and announcements; generate consolidated weekly brief with MCP delivery to email/Slack and Git-based archive.
- Sectors: enterprise operations
- Tools/workflows: enterprise search; topic filtering; reasoning agent; PR archiving
- Assumptions/dependencies: permissioning; de-duplication across noisy sources
Tooling and Integration
- MCP adapter for existing workflows — Expose any REST-based agentic pipeline via a thin MCP server for desktop tools (Claude Desktop, LM Studio, VS Code).
- Sectors: software, platform integrators
- Tools/workflows: REST backend; MCP server as a thin adapter; client configs
- Assumptions/dependencies: clear separation of concerns; interface stability; auth/secret management
- PromptOps and governance — Externalize prompts to a repo with version pinning, A/B testing, and rollback; enable non-engineers to manage behavior safely.
- Sectors: all sectors using LLMs
- Tools/workflows: prompt repos; review workflows; automated linting/tests
- Assumptions/dependencies: change control; prompt evaluation harnesses
Long-Term Applications
Autonomous Media Operations
- Fully autonomous, compliance-safe newsrooms — End-to-end content planning, sourcing, generation, moderation, and multi-channel publishing with adaptive evaluation and real-time risk classifiers.
- Sectors: media, entertainment, corporate communications
- Tools/workflows: dynamic tool selection; policy-aware guardrails; continuous self-monitoring and red-teaming
- Assumptions/dependencies: robust factuality systems; watermarking/provenance; evolving legal norms on AI-generated media
RegTech and Compliance Automation
- Continuous regulatory mapping and control updates — Agents propose and implement policy revisions and control mappings across systems, with automated evidence collection and audits.
- Sectors: finance, healthcare, energy, public sector
- Tools/workflows: knowledge graphs; model-consortium reasoning; deterministic change execution; approval workflows
- Assumptions/dependencies: high-precision grounding; regulator-accepted audit artifacts; rigorous human governance
Scientific Discovery and Research Ops
- Autonomous literature triage and experiment planning — Multi-model agents synthesize findings, detect contradictions, propose experiments, and manage preregistered protocols.
- Sectors: academia, pharma, materials science
- Tools/workflows: domain-tuned models; lab system integrations; MCP-controlled ELN/LIMS interfaces
- Assumptions/dependencies: domain safety constraints; expert oversight; validated domain models
Personalized Education at Scale
- Always-on adaptive tutors and content studios — Agents generate personalized learning paths with audio/video content, validated by a reasoning auditor and aligned to standards.
- Sectors: K–12, higher ed, workforce reskilling
- Tools/workflows: learner modeling; content generators; assessment analytics; LMS adapters
- Assumptions/dependencies: privacy-by-design; efficacy studies; bias and accommodation controls
Advanced Enterprise Automation
- Cross-system RPA with LLM orchestration — Task-level agents plan and act across ERP/CRM/ITSM safely, using pure functions for execution and LLMs for exception handling.
- Sectors: enterprise IT, operations
- Tools/workflows: system connectors; policy engines; observability and rollback; zero-trust service mesh
- Assumptions/dependencies: deterministic interfaces; fine-grained authorization; strong auditability
Safety-Critical Decision Support
- Clinical and legal decision briefs — Multi-model synthesis with stringent grounding and bias checks for practitioners; outputs as decision aids, not autonomous actions.
- Sectors: healthcare, legal
- Tools/workflows: domain-validated corpora; explanation scaffolds; reasoned consensus outputs
- Assumptions/dependencies: regulatory approval, rigorous HIL processes, real-world validation studies
Marketplace and Ecosystem
- Enterprise agent/app marketplaces via MCP — Curated catalogs of vetted agentic workflows exposed through a common protocol, enabling secure internal reuse.
- Sectors: platform providers, system integrators
- Tools/workflows: MCP standardization; policy attestation; billing/quotas
- Assumptions/dependencies: protocol evolution; governance frameworks; vendor interoperability
Edge and On-Prem Agentic Platforms
- Privacy-preserving agentic stacks for regulated data — On-prem LLM/VLM/ASR/TTS with containerized orchestration for sensitive domains.
- Sectors: government, healthcare, defense, finance
- Tools/workflows: on-prem model serving; Kubernetes; hardware acceleration; local MCP
- Assumptions/dependencies: performant local models; cost/latency tradeoffs; secure MLOps
Autonomous Software Operations
- Self-updating docs, runbooks, and minor code patches — Agents observe telemetry, propose changes, raise PRs, and run safe canary releases with human approvals.
- Sectors: SRE/DevOps, platform engineering
- Tools/workflows: observability-to-action loops; guarded deployments; reasoning-based risk scoring
- Assumptions/dependencies: highly reliable evaluation pipelines; strong rollback; policy constraints
Standardized Responsible-AI Certification
- Auditable pipelines with consensus reasoning and deterministic execution certified against organizational and industry standards.
- Sectors: cross-sector
- Tools/workflows: standardized logs/trace schemas; reproducible prompt/version pinning; third-party audits
- Assumptions/dependencies: emerging standards acceptance; tooling for conformance testing
Notes on cross-cutting dependencies
- Model access and stability: availability, API limits, cost control, and version variability.
- Data rights and compliance: content licensing, privacy (PII/PHI), and sector-specific regulations.
- Governance and human-in-the-loop: approval gates for high-stakes tasks; auditability via logs and PRs.
- Infrastructure maturity: Docker/Kubernetes, RBAC, secrets, observability (OpenTelemetry/Prometheus), CI/CD.
- Determinism and reliability: preference for pure functions for side-effectful operations; single-responsibility agents; externalized prompts with versioning.
- Protocol/tooling evolution: MCP and tool schema stability; backward compatibility planning.
Glossary
- A/B testing: An experimental method that compares two variants to determine which performs better. "Maintaining prompts externally further supports continuous improvement practices, including A/B testing, prompt red-teaming, and evolving Responsible-AI rules, all without requiring code redeployments."
- Agentic AI: A paradigm where autonomous AI agents reason, plan, and act across multi-step tasks without constant human intervention. "Agentic AI marks a major shift in how autonomous systems reason, plan, and execute multi-step tasks."
- Agentic AI workflows: Pipelines of specialized AI agents coordinated to accomplish complex, multi-step tasks reliably in production. "production-grade agentic AI workflows that are reliable, observable, maintainable, and aligned with safety and governance requirements."
- Blueâgreen deployments: A release strategy that switches traffic between two identical environments (blue and green) to enable safe updates and rollbacks. "It also enables blueâgreen deployments, canary releases, and safe iteration on individual components without impacting the entire system."
- Canary releases: A deployment technique that rolls out changes to a small subset of users first to detect issues before full release. "It also enables blueâgreen deployments, canary releases, and safe iteration on individual components without impacting the entire system."
- Containerization: Packaging software and its dependencies into isolated, portable containers for consistent execution across environments. "In production environments, agentic AI workflows and their accompanying MCP servers should be deployed using containerization technologies such as Docker and orchestrated with platforms like Kubernetes."
- Deterministic orchestration: Designing workflows so that agent decisions and tool invocations follow predictable, reproducible paths. "ways to design deterministic orchestration"
- Docker: A containerization platform used to build, ship, and run applications in isolated environments. "using containerization technologies such as Docker and orchestrated with platforms like Kubernetes."
- Environment-aware orchestration: Coordinating agents and tools with awareness of external systems, configurations, and operational context. "By incorporating heterogeneous models (e.g., OpenAI, Gemini, Llama, Anthropic), deterministic tool calls, and environment-aware orchestration, agentic AI provides a flexible and powerful architectural approach for building scalable and production-grade AI systems."
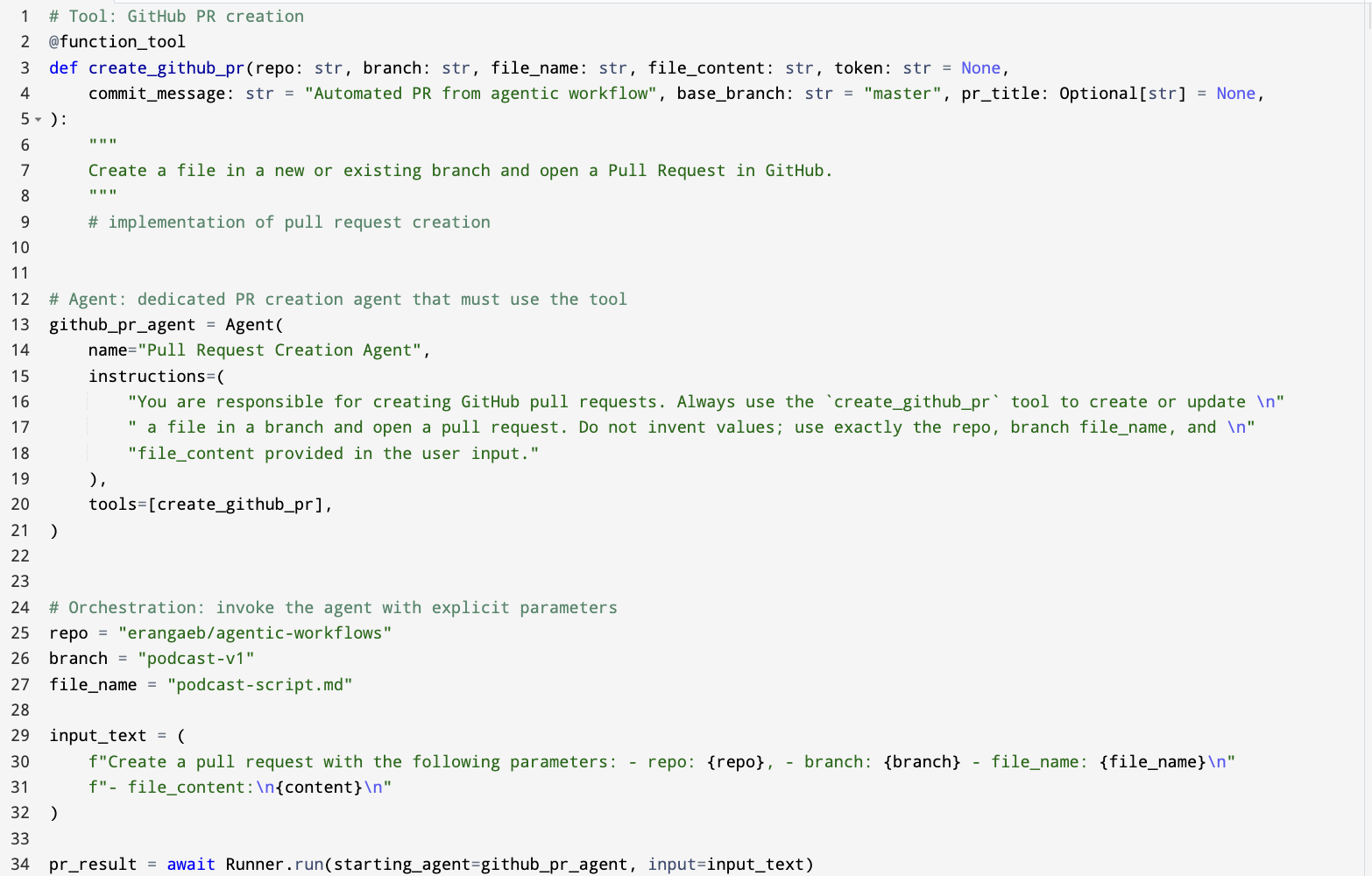
- GitHub MCP server: An MCP-compliant service that exposes GitHub operations (e.g., pull requests) to agentic workflows via standardized tools. "the GitHub MCP server to create pull requests for the generated podcast scripts."
- Grafana: An observability platform for visualizing metrics and traces in production systems. "logging, metrics, and tracing systems (e.g., Prometheus, Grafana, OpenTelemetry)"
- Kubernetes: A container orchestration platform for deploying, scaling, and managing containerized applications. "using containerization technologies such as Docker and orchestrated with platforms like Kubernetes."
- LLMs: Transformer-based models trained on vast text corpora to perform language understanding and generation tasks. "The rapid advancement of LLMs"
- LM Studio: A client platform that can act as an MCP-enabled interface for invoking agentic workflows. "the workflowâs MCP server was integrated into LM Studio, enabling full end-to-end testing with local LLMs acting as MCP clients"
- LLM consortium: A design in which multiple LLMs produce outputs that are later synthesized for accuracy and robustness. "the podcast script generation agents, which operate as a multi-model consortium composed of Llama, OpenAI, and Gemini."
- LLM drift: Changes in an LLM’s behavior over time that lead to inconsistent or unpredictable outputs. "methods to avoid implicit behaviors that lead to LLM drift or unpredictable execution paths"
- Model Context Protocol (MCP): A standardized protocol that defines how agents communicate with external tools and services. "Model Context Protocol (MCP) servers"
- Multi-agent orchestration: Coordinating multiple specialized agents to collaborate and complete complex workflows. "using multi-agent orchestration, tool integration, and deterministic function execution."
- OpenTelemetry: A vendor-neutral observability framework for generating, collecting, and exporting telemetry data. "logging, metrics, and tracing systems (e.g., Prometheus, Grafana, OpenTelemetry)"
- Prometheus: A monitoring system and time-series database used for metrics collection and alerting. "logging, metrics, and tracing systems (e.g., Prometheus, Grafana, OpenTelemetry)"
- Prompt red-teaming: Systematically probing and testing prompts to uncover failures, biases, or unsafe behaviors. "including A/B testing, prompt red-teaming, and evolving Responsible-AI rules"
- Pure-function invocation: Executing deterministic, side-effect-controlled functions directly in the workflow without LLM reasoning. "including tool-first design over MCP, pure-function invocation, single-tool and single-responsibility agents"
- Reasoning agent: A specialized agent that consolidates, verifies, and harmonizes outputs from other agents/models. "the system employs a Reasoning Agent, which consolidates the drafts by comparing them, resolving inconsistencies, removing speculative claims, and synthesizing a unified podcast narrative."
- Responsible AI: Principles and practices that ensure AI systems are fair, accountable, transparent, and safe. "aligned with Responsible AI principles"
- Role-based access control (RBAC): A security method that restricts system access based on user roles and permissions. "role-based access control (RBAC) enable robust security boundaries around AI workflows"
- Structured memory: Organized, persistent context that agents use to store and retrieve information across steps. "Modern agentic workflows integrate LLMs with external tools, structured memory, search functions, databases"
- Text-to-speech (TTS): Technology that converts written text into spoken audio. "text-to-speech (TTS)"
- Tool calls: LLM-invoked operations that map model outputs to structured function/API invocations. "Although tool calls provide a structured way for agents to interact with external systems"
- Tool schemas: Formal definitions of tool interfaces, parameters, and data structures that agents must follow. "handling tool schemas"
- Veo-3: A text-to-video generation model used to synthesize MP4 videos from structured prompts. "integration fidelity with Google Veo-3."
- VisionâLLMs (VLMs): Multimodal models that jointly process visual and textual inputs. "VisionâLLMs (VLMs)"
Collections
Sign up for free to add this paper to one or more collections.