DAComp: Benchmarking Data Agents across the Full Data Intelligence Lifecycle
Abstract: Real-world enterprise data intelligence workflows encompass data engineering that turns raw sources into analytical-ready tables and data analysis that convert those tables into decision-oriented insights. We introduce DAComp, a benchmark of 210 tasks that mirrors these complex workflows. Data engineering (DE) tasks require repository-level engineering on industrial schemas, including designing and building multi-stage SQL pipelines from scratch and evolving existing systems under evolving requirements. Data analysis (DA) tasks pose open-ended business problems that demand strategic planning, exploratory analysis through iterative coding, interpretation of intermediate results, and the synthesis of actionable recommendations. Engineering tasks are scored through execution-based, multi-metric evaluation. Open-ended tasks are assessed by a reliable, experimentally validated LLM-judge, which is guided by hierarchical, meticulously crafted rubrics. Our experiments reveal that even state-of-the-art agents falter on DAComp. Performance on DE tasks is particularly low, with success rates under 20%, exposing a critical bottleneck in holistic pipeline orchestration, not merely code generation. Scores on DA tasks also average below 40%, highlighting profound deficiencies in open-ended reasoning and demonstrating that engineering and analysis are distinct capabilities. By clearly diagnosing these limitations, DAComp provides a rigorous and realistic testbed to drive the development of truly capable autonomous data agents for enterprise settings. Our data and code are available at https://da-comp.github.io




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DAComp, a big test (called a benchmark) for checking how well AI “data agents” can handle the entire journey of turning messy, real-world company data into useful insights. It covers two main parts:
- Data Engineering (DE): building the data pipelines and tables from raw sources.
- Data Analysis (DA): answering open-ended business questions using those tables, making charts, and writing clear reports.
DAComp includes 210 tasks that feel like real work inside a company, not just small, standalone exercises.
What questions were the researchers trying to answer?
The paper focuses on simple, practical questions:
- Can AI agents plan and build complex, multi-step data systems (not just one query)?
- Can they update and fix those systems when business needs change?
- Can they explore data, pick good methods, and turn numbers into helpful insights, charts, and recommendations?
- How should we fairly and reliably grade this kind of work, especially when there isn’t just one “right” answer?
How did they do the study?
The team built a benchmark that mirrors real company data work. Here’s how it’s organized and graded, in easy terms:
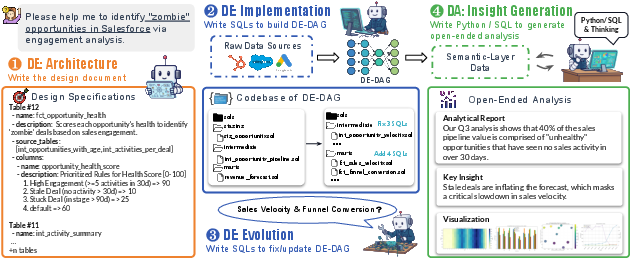
- Data Engineering tasks (DE)
- Architecture: planning the data system (like writing the blueprint).
- Implementation: building the whole pipeline from scratch (think: writing many SQL files across layers).
- Evolution: changing an existing system when requirements change (like upgrading or fixing parts).
- These are “deterministic,” meaning there is a clear, correct output. The grading runs the agent’s code and checks if each part works.
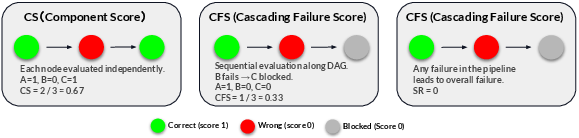
- Component Score: scores each piece on its own (like grading each step with perfect inputs).
- Cascading Failure Score: follows the pipeline in order and stops scoring downstream if an earlier step is wrong (like a chain reaction).
- Success Rate: everything must be perfect to pass (strict mode).
- Data Analysis tasks (DA)
- Agents get open-ended business questions (for example: “Why did sales drop last quarter, and what should we do?”).
- They must plan their approach, write SQL/Python, compute results, make charts, and write an understandable report.
- These are “open-ended,” meaning there can be multiple good ways to solve the problem.
- Grading uses an LLM judge with a hierarchical rubric (like a teacher’s checklist that supports different valid solution paths) plus a Good–Same–Bad comparison against baseline reports.
- The rubric checks completeness, accuracy, and insightfulness.
- The GSB check compares the agent’s final report to example reports to judge readability, depth, and visualization quality.
Think of DE like building a factory line: if an early machine is misconfigured, everything downstream breaks. Think of DA like solving a mystery: there’s no single path, but your method should be solid, your math correct, your charts clear, and your advice useful.
What did they find, and why is it important?
Key results show today’s best AI agents still struggle with realistic data work:
- Building complex pipelines is hard
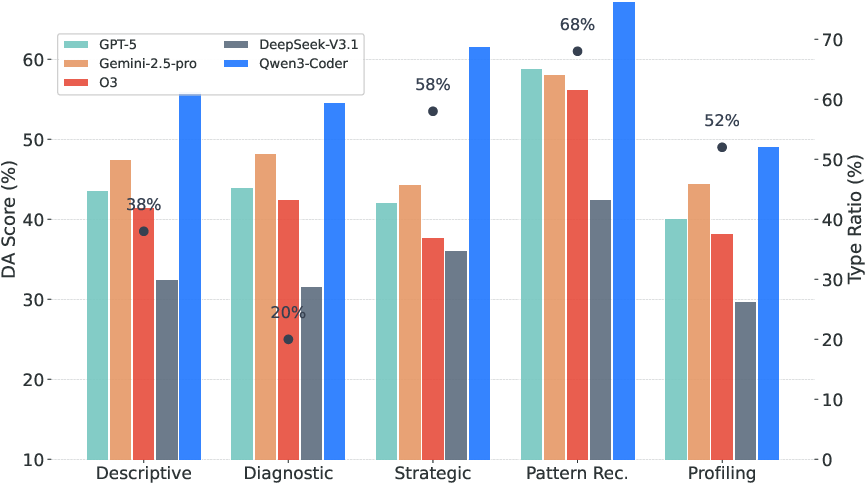
- Even top models score around the mid-40% range overall on DE.
- Strict “everything is perfect” success is under about 20%.
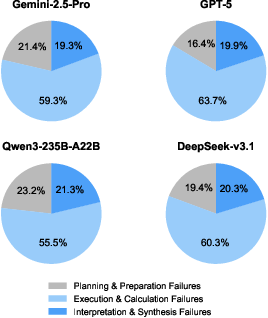
- Big problem: orchestration. Agents can often write pieces of code correctly, but connecting them into a working pipeline is where they fail.
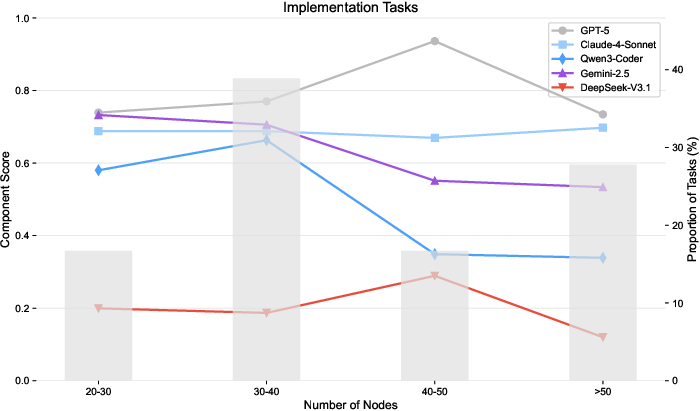
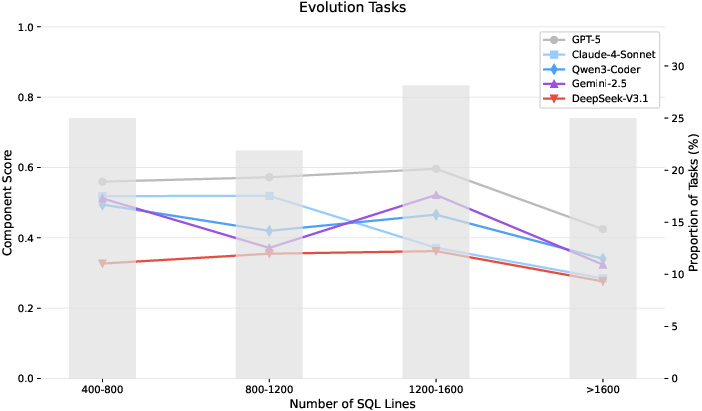
- Medium-sized edits (not tiny tweaks, not huge boilerplate) are the toughest—these often involve tricky business logic changes.
- Higher pipeline layers break more often
- Early “staging” steps (cleaning data) are easier.
- “Core” and “marts” layers (where business metrics and integrations happen) are much more error-prone and cause most failures.
- Open-ended analysis exposes other weaknesses
- Average scores are commonly below ~40–50%.
- Agents frequently struggle with planning, calculation accuracy, and turning results into clear, insightful explanations and charts.
- Models that are good at code or math sometimes produce unreadable reports or weak recommendations—getting the numbers right isn’t enough.
- The grading method is reliable
- Their LLM judge (with detailed rubrics and GSB comparisons) aligns well with human experts and produces stable rankings across different judge models and settings.
- This matters because open-ended tasks need trustworthy, fair scoring.
Overall, these findings reveal that engineering and analysis are separate skill sets: generating correct code snippets is very different from orchestrating entire systems or producing high-quality, decision-ready analytics.
What does this mean for the future?
DAComp gives researchers and companies a realistic way to test and improve AI data agents. It points to what needs to get better:
- Planning and orchestration: building and maintaining multi-step pipelines that survive changes.
- Robust reasoning: choosing sound methods for open-ended questions and sticking to them.
- Clear communication: turning numbers into charts and plain-language insights people can act on.
If future agents improve on DAComp, we’ll get closer to reliable assistants that can handle the full data lifecycle—helping teams move faster from raw data to smart decisions. The benchmark (including a Chinese version) is publicly available, so the community can build and compare better systems over time.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper:
- Data realism gap: DE tasks rely on large-scale synthetic data and curated public schemas; the benchmark does not include proprietary, messy, or privacy-constrained enterprise data (e.g., PII, compliance constraints, domain-specific idiosyncrasies).
- Limited domain coverage: The 73 SaaS schemas may not represent high-stakes verticals (healthcare, finance, manufacturing) where regulatory logic, auditing, and risk controls are critical.
- Missing ingestion and upstream ETL complexity: Tasks start from analysis-ready or warehouse-ingested data; they omit real ingestion from APIs/files/streams, schema discovery, messy file formats, and external system integration.
- Narrow tech stack: The benchmark centers on SQL/Python; it does not assess pipelines on distributed engines (Spark/Flink), lakehouse storage, message buses (Kafka), or cloud-native orchestration (Airflow/Dagster) and their failure modes.
- SQL dialect generality is unclear: It is not specified whether multiple SQL dialects and warehouse-specific features (e.g., BigQuery, Snowflake, Databricks SQL, Postgres) are covered or whether cross-dialect portability is evaluated.
- Orchestration realism gaps: CI/CD, code review workflows, environment provisioning, credentials and secrets, permissioning, rollback/backfill strategies, and incremental/idempotent models are not part of the evaluation.
- Performance, cost, and scalability not measured: DE evaluation focuses on correctness; it does not capture runtime, resource usage, cost efficiency, or scalability under realistic data volumes.
- Robustness to change and drift: Beyond single “evolution” steps, the benchmark does not stress-test schema drift across time, late-arriving data, null/missing-edge cases, or backfill/partition logic.
- Fault tolerance and recovery: No assessment of checkpointing, retries, partial failures, or resilient recovery strategies common in production pipelines.
- Data governance scope is narrow: While staging-layer cleaning is categorized, broader governance (lineage auditing, access control, SLAs/SLOs, data contracts enforcement across services) is not evaluated.
- Maintainability and code quality: DE scoring ignores code style, modularity, documentation, test coverage, and maintainability, which drive real-world engineering sustainability.
- DE-Architecture evaluability: Architecture tasks are LLM-judged; there is no programmatic check that proposed specs are implementable, complete, and consistent when compiled into a working DAG.
- Open-ended DA coverage gaps: Tasks emphasize descriptive/diagnostic work; forecasting, causal inference, experiment design/A-B testing, uplift modeling, and decision-making under uncertainty are largely absent.
- Actionability measurement: DA “recommendations” are judged qualitatively; the benchmark does not measure downstream business impact, policy uplift, or counterfactual value of recommendations.
- Visualization verification: Visualization quality is judged textually via rubric/GSB; there is no automated check that plots execute, encode the correct data, or meet accessibility/interpretability standards.
- LLM-judge dependence and bias: The evaluation relies on LLMs-as-judge (primarily Gemini-2.5-Flash); although validated, risks remain around judge bias, family preference, prompt gaming, and drift over time.
- Judge validation scope: Reliability studies use a relatively small sample (e.g., 50 examples for certain analyses); cross-lingual (zh) judge reliability is not established at the same depth as English.
- Baseline anchoring in GSB: GSB compares outputs against baselines produced by LLMs; this can embed model-specific biases and constrain acceptable stylistic/structural variation.
- Path enumeration coverage: Hierarchical rubrics attempt to cover multiple solution paths, but completeness is unverifiable; novel but valid strategies may still be penalized despite soft constraints.
- Reproducibility across runs: While some stochastic stability is reported, comprehensive sensitivity to sampling seeds, tool latency, or token budgets across all tasks and models is not provided.
- Contamination risk: Since tasks derive from permissively licensed public assets, the potential for pretraining leakage into model weights is not assessed; no data contamination audit is reported.
- Tooling constraints: Experiments rely on OpenHands and a custom DA-Agent; the impact of richer tools (schema search, lineage browsers, unit-test generators, auto-profilers, retrieval over docs) is not explored.
- Single-agent vs. collaborative setups: Multi-agent collaboration, planner-critic loops, and human-in-the-loop interventions (which are common in enterprise practice) are not benchmarked.
- Long-context and memory: The role of repository size, retrieval quality, and memory mechanisms (vector DBs, code awareness) on DE orchestration performance is not systematically ablated.
- Security and safety: The benchmark excludes assessments of secret handling, least-privilege access, destructive query safeguards, and compliance checks (e.g., GDPR, HIPAA).
- Temporal realism: “Evolution” simulates one-off requirement changes; longitudinal maintenance (months of layered changes, deprecations, and cross-team contract negotiations) is not represented.
- Multilingual breadth: Beyond English and Chinese, multilingual task variants (e.g., code/comments/specs in other languages) and cross-lingual transfer are not evaluated.
- Human baselines and effort: There is no human expert baseline for time-to-solution, error rates, or quality, nor any cost/effort comparison between humans and agents.
- Leaderboard comparability: Differences in model context windows, tool access, rate limits, or cost budgets are not normalized; their effect on performance is not analyzed.
- Task difficulty calibration: While some node-level and layer-level analyses are provided, a formal, per-task difficulty index (to enable stratified benchmarking and progress tracking) is not released.
- Dataset growth plan: It is unclear how the benchmark will expand or rotate hidden test splits to prevent overfitting and ensure long-term benchmark vitality.
Glossary
- Analytical depth: A qualitative evaluation dimension assessing how thoroughly the analysis explores causes, relationships, and implications beyond surface-level results. "Analytical depth"
- Cascading Failure Score (CFS): An execution-based metric that measures end-to-end pipeline integrity by invalidating a node’s score when any upstream dependency is incorrect. "Cascading Failure Score (CFS)"
- Component Score (CS): A partial-credit, execution-based metric that evaluates each DAG node in isolation using gold upstream inputs. "Component Score (CS)"
- Core layer: The intermediate pipeline layer where complex business logic and entity integration occur. "the intermediate (core) layer"
- Data Contract: A formal engineering specification capturing the full DAG, schemas, and semantics for a pipeline. "(e.g., a Data Contract)"
- Data governance: The discipline and processes that ensure data quality, consistency, integrity, and compliance across an organization. "a central topic in data governance"
- Data intelligence: The enterprise process of transforming raw and fragmented data into actionable insights. "Data intelligence, the process of transforming raw and fragmented data into actionable insights,"
- Data lineage: The end-to-end tracing of data origins and transformations through a pipeline to its outputs. "global data lineage"
- DE-Architecture: A task type focused on planning high-level engineering specifications for data systems. "DE-Architecture tasks focus on the high-level planning of detailed engineering specifications."
- DE-Evolution: A task type requiring modification of existing repositories to satisfy new requirements. "DE-Evolution tasks challenge them to modify existing systems in response to new requirements"
- DE-Implementation: A task type requiring agents to build multi-stage data pipelines and repositories from scratch. "DE-Implementation tasks require agents to build multi-stage data pipelines from scratch"
- Deterministic tasks: Tasks with a single correct output, enabling objective execution-based evaluation. "For deterministic \dei and \dee tasks, we adopt an execution-based method"
- Directed Acyclic Graph (DAG): A directed graph with no cycles, used to represent dependency structure in data workflows. "generating a DAG on complex enterprise schemas."
- Execution-based evaluation: An assessment approach that runs generated code and checks outputs against ground truth repositories or data. "Execution-based evaluation for deterministic tasks."
- Good–Same–Bad (GSB) score: A comparative evaluation that classifies outputs as better, equivalent, or worse relative to baseline reports. "GoodâSameâBad (GSB) score"
- Hierarchical rubric: A structured rubric that decomposes a question into requirements, sub-requirements, and multiple valid solution paths. "The hierarchical rubric assesses the first three"
- Intraclass Correlation Coefficient (ICC): A statistical reliability metric quantifying agreement between raters or judges. "ICC(A,1)"
- Kendall’s tau-b (τ_b): A nonparametric rank correlation coefficient measuring the concordance between two orderings. "Rank Corr. ()"
- LLM judge: A LLM used to evaluate open-ended outputs according to rubrics and comparative criteria. "assessed by an LLM judge"
- Mart layer: The final analytical layer containing business-ready, aggregated tables (data marts). "the marts layer remains highly challenging."
- Multi-stage SQL pipeline: A layered series of dependent SQL transformations forming a complete data workflow. "multi-stage SQL pipelines from scratch"
- Repository-level data engineering: Engineering that spans a full codebase, coordinating multi-file pipelines, dependencies, and evolving requirements. "repository-level data engineering (DE)"
- Semantic layer: A curated, analysis-ready abstraction providing consistent metrics and entities for downstream analysis. "analysis-ready data (semantic layer)"
- Staging layer: The initial pipeline layer focused on cleaning, validating, and standardizing raw inputs. "The staging layer involves data cleaning operations"
- Success Rate (SR): A strict metric requiring every component in a task to be correct for the task to pass. "Success Rate (SR)"
- Text-to-SQL: The task of generating SQL queries directly from natural-language questions. "text-to-SQL"
- Weighted Cohen’s kappa (κ_w): An agreement statistic that weights the severity of disagreements between raters. "()"
Practical Applications
Immediate Applications
Below are practical, deployable applications that leverage DAComp’s findings, methods, and assets to improve current data intelligence practices.
- Industry — Vendor benchmarking and procurement
- Use case: Require AI data agent vendors to report DAComp-DE/DA scores in RFPs and pilots to quantify repository-level orchestration and open-ended analysis capabilities.
- Sector: Software, finance, retail, healthcare.
- Tools/products/workflows: “DAComp Certification” badges; automated leaderboard dashboards; procurement scorecards combining CS/CFS/SR and DA rubric scores.
- Assumptions/dependencies: Access to DAComp tasks and evaluation scripts; standardized environments (e.g., dbt/Snowflake/Databricks); consistent LLM judge settings.
- Industry — Change management gating in data engineering
- Use case: Gate production ETL/mart changes behind DAComp-style execution tests (CS → CFS → SR) to prevent cascading failures and dependency breakage.
- Sector: Finance, e-commerce, ad-tech, logistics.
- Tools/products/workflows: “Orchestration Stress Test Harness” that simulates staging/core/mart survival; pre-merge checks; CI/CD hooks with repo-level DAG validation.
- Assumptions/dependencies: CI integration, representative synthetic data, alignment with in-house schema/DAG tooling.
- Industry — AgentOps for data pipelines
- Use case: Monitor agent interaction patterns (turn distribution stability) and failure taxonomies (dependency errors, SQL omission) to diagnose and improve agent reliability.
- Sector: Software, data platform teams.
- Tools/products/workflows: AgentOps dashboards with error sunbursts, turn variance monitors, node-level performance by file size/edit type; alerting on core-layer failures.
- Assumptions/dependencies: Logging of agent actions; mapping to DAComp’s error taxonomy; access to orchestration traces.
- Academia — Curriculum and assessment for data engineering and analysis
- Use case: Teach DAG design (staging/core/mart), data contracts, multi-stage SQL pipelines, and open-ended analysis with hierarchical rubrics; grade student reports and code automatically.
- Sector: Education.
- Tools/products/workflows: Course labs using DAComp-DE implementations and DA hierarchical rubrics; rubric-based grading assistants; assignments on medium-scale edits and visualization.
- Assumptions/dependencies: Student access to compute and databases; adoption of LLM judge; institutional acceptance of multi-path rubric scoring.
- Academia — Research baselines for agentic data systems
- Use case: Compare planning vs orchestration vs open-ended reasoning; reproduce error distributions; study medium-scale edit difficulty; evaluate cross-language performance via DAComp-zh.
- Sector: Academia, AI research.
- Tools/products/workflows: Benchmark suites; controlled ablations; public leaderboards; reproducible OpenHands/DA-Agent baselines.
- Assumptions/dependencies: Availability of model APIs; compute budgets; adherence to DAComp scoring protocols.
- Policy — Internal AI governance and risk controls
- Use case: Adopt DAComp metrics as risk indicators for autonomous data agents (e.g., minimum CFS/SR thresholds, visualization/readability requirements for reports used in decisions).
- Sector: Regulated industries (finance, healthcare, energy).
- Tools/products/workflows: AI risk registers referencing DAComp dimensions; deployment gates by task type (Implementation/Evolution vs Analysis); audit trails of rubric/GSB scores.
- Assumptions/dependencies: Policy frameworks accepting LLM-judge evaluations; mapping scores to risk tiers; human-in-the-loop review mandates.
- Daily life — Improving BI report quality and clarity
- Use case: Use DA hierarchical rubrics to structure prompts and self-critique BI dashboards and ad-hoc analyses for small businesses and teams.
- Sector: SMB, operations, marketing.
- Tools/products/workflows: “Rubric-Assisted Analytics” prompt templates; lightweight LLM judge to critique completeness/accuracy/insightfulness and visualization choices.
- Assumptions/dependencies: Access to analysis-ready data; BI tools (e.g., Power BI/Tableau); LLM judge availability.
- Industry — Analytics QA for decision support
- Use case: Evaluate analyst/agent-produced reports via GSB (Readability, Analytical Depth, Visualization) against baseline artifacts; flag weak analyses before executive consumption.
- Sector: Enterprise analytics/BI.
- Tools/products/workflows: Report QA gates; baseline library of comparable analyses; automated feedback loops to revise reports.
- Assumptions/dependencies: Alignment of baselines to business context; acceptance of LLM-based subjective dimensions; data security controls.
- Industry — Localization and cross-market adoption
- Use case: Deploy DAComp-zh to validate agent performance in Chinese enterprise contexts; ensure multilingual analysis and engineering quality.
- Sector: Multinational enterprises, APAC market.
- Tools/products/workflows: Dual-language evaluation pipelines; cross-lingual scorecards; localization QA for documentation/code/comments.
- Assumptions/dependencies: Accurate translation/context; LLM competency; local data governance.
- Industry — Pre-migration simulation with synthetic data
- Use case: Use large, relationally consistent synthetic datasets to test schema changes, data quality constraints, and downstream mart impacts before real-world migrations.
- Sector: Data platform migrations (cloud DWs).
- Tools/products/workflows: “Synthetic Data Sandbox” with staged transformations; anomaly detection checks aligned to DAComp staging categories (validity, consistency, integrity/uniqueness).
- Assumptions/dependencies: Synthetic data realism suffices; coverage of business logic; integration with ETL tooling.
- Industry — Visualization selection assistants
- Use case: Adopt DAComp’s visualization scoring as heuristics to auto-select and generate charts for specific analytical questions.
- Sector: BI tooling, product analytics.
- Tools/products/workflows: Chart recommendation engines; visualization linting tools; templates with justified chart types.
- Assumptions/dependencies: Mapping rubric items to chart taxonomy; robust data typing and aggregation.
- Academia/Industry — Methodological diversity evaluation
- Use case: Apply hierarchical rubric “multi-path” scoring to other open-ended tasks (e.g., strategic analyses, product experiments) to reward valid alternative methods.
- Sector: Research, product analytics.
- Tools/products/workflows: “Rubric Studio” for path enumeration and item weighting; validity checks via anchor values and methodology-based soft constraints.
- Assumptions/dependencies: Expert rubric construction; judge validation; baseline reports for GSB.
Long-Term Applications
The following applications require further research, scaling, or development to reach production reliability.
- Industry — Autonomous data engineer agents
- Use case: Agents plan, implement, and evolve multi-stage pipelines with high SR, handling dependencies and medium-scale edits reliably.
- Sector: Software/data platforms, finance, e-commerce.
- Tools/products/workflows: Multi-agent systems dividing architecture/planning, implementation, and QA; dependency-aware memory; DAG-level consistency checkers.
- Assumptions/dependencies: Advances in orchestration capabilities, long-range dependency handling, codebase awareness, and robust guardrails.
- Industry — Closed-loop analytics agents for decision-making
- Use case: Agents not only compute accurate metrics but synthesize insights, recommend actions, and produce executive-ready reports with consistent readability and depth.
- Sector: Product analytics, operations, marketing, healthcare quality.
- Tools/products/workflows: Continuous “Plan–Execute–Interpret–Revise” loops; auto-report generation with visualization rationale; human-in-the-loop approvals.
- Assumptions/dependencies: Improved qualitative reasoning; calibrated GSB scoring; alignment to organizational decision processes.
- Policy/Standards — Certification frameworks for AI data agents
- Use case: Regulators or industry consortia define DAComp-like certification (minimum CFS/SR, DA rubric thresholds) for autonomous changes to enterprise data systems.
- Sector: Finance, healthcare, energy, public sector.
- Tools/products/workflows: ISO-style standards; external audits; standard test suites and reference schemas.
- Assumptions/dependencies: Regulatory buy-in; reproducible, unbiased judges; sector-specific schema extensions.
- Academia — Training data and reward models for orchestration
- Use case: Use DAComp error taxonomies and turn patterns to create reward models that penalize dependency errors and cascading failures; RL for pipeline survival.
- Sector: AI/ML research.
- Tools/products/workflows: Orchestration-focused RL datasets; survival-rate-based rewards; curriculum learning emphasizing core/mart complexity.
- Assumptions/dependencies: Stable access to agent traces; safe RL in code environments; scalable evaluation.
- Industry — Data platform co-pilots integrated with DW vendors
- Use case: Snowflake/BigQuery/Databricks-native agents validated on DAComp, offering “safe edits” mode and simulated impact analysis before commit.
- Sector: Cloud data platforms.
- Tools/products/workflows: Managed “Agent QA” services; pre-commit orchestration checks; schema drift monitoring.
- Assumptions/dependencies: Vendor partnerships; secure repository access; sandboxing and rollback mechanisms.
- Healthcare/Finance — Domain-specific agents for compliance-heavy pipelines
- Use case: Agents manage claims aggregation, risk models, and audit-ready marts with strict lineage and reproducibility guarantees.
- Sector: Healthcare, finance.
- Tools/products/workflows: Compliance-aware DAGs; lineage proofs; audit bundles including rubric and GSB assessments of analytic outputs.
- Assumptions/dependencies: Domain ontologies; privacy/PII handling; regulator-specific constraints.
- Education — Agentic data engineering and analysis degree tracks
- Use case: New specializations focusing on repository-level agent design, orchestration testing, and multi-path evaluation frameworks.
- Sector: Higher education.
- Tools/products/workflows: Capstone projects on DAComp; faculty tooling for rubric construction; lab infrastructure for agent evaluations at scale.
- Assumptions/dependencies: Institutional curriculum redesign; sustained model access; funding for compute.
- Industry — Marketplace of certified data agents
- Use case: Organizations select pre-tested agents with published DAComp scores and sector-specific schemas; compare on medium-scale edit competence and core-layer survival.
- Sector: Software, consulting.
- Tools/products/workflows: Agent registries; sector benchmark packs; SLA clauses tied to DAComp metrics.
- Assumptions/dependencies: Standardized scoring across environments; anti-gaming protocols; continual re-validation.
- Robotics/IoT/Energy — Extension to multimodal data intelligence
- Use case: Agents handle sensor/time-series pipelines, anomaly detection, and policy-driven analytics with DAComp-like orchestration evaluation.
- Sector: Energy, manufacturing, smart cities.
- Tools/products/workflows: Multimodal DAGs; streaming core/marts; visualization QA for operational dashboards.
- Assumptions/dependencies: Benchmarks extended to time-series and event data; streaming evaluation metrics; domain-specific rubrics.
- Daily life — Consumer-grade personal data intelligence assistants
- Use case: Agents manage household finances, health metrics, and energy usage, building repeatable pipelines and interpretable reports with recommended actions.
- Sector: Consumer apps.
- Tools/products/workflows: Auto-ingest and clean personal data; explainable insights; chart selection justified by rubric criteria.
- Assumptions/dependencies: Safe local data processing; privacy-preserving models; simple schema templates.
- Cross-language — Multilingual analytics and engineering at parity
- Use case: Achieve DAComp-zh equivalent performance across languages for global organizations; consistent readability/visualization quality in localized reports.
- Sector: Multinational enterprises.
- Tools/products/workflows: Cross-lingual model training; bilingual rubrics and baselines; language-sensitive visualization norms.
- Assumptions/dependencies: High-quality multilingual LLMs; localized domain data; cross-market validation.
These applications draw directly from DAComp’s core contributions: full-lifecycle, repo-level engineering tasks; open-ended analysis with hierarchical, multi-path rubrics; validated LLM-judge methodology; and granular failure diagnostics that expose real bottlenecks in orchestration, dependency management, and insightful synthesis.
Collections
Sign up for free to add this paper to one or more collections.