Autonomous Data Agents: A New Opportunity for Smart Data
Abstract: As data continues to grow in scale and complexity, preparing, transforming, and analyzing it remains labor-intensive, repetitive, and difficult to scale. Since data contains knowledge and AI learns knowledge from it, the alignment between AI and data is essential. However, data is often not structured in ways that are optimal for AI utilization. Moreover, an important question arises: how much knowledge can we pack into data through intensive data operations? Autonomous data agents (DataAgents), which integrate LLM reasoning with task decomposition, action reasoning and grounding, and tool calling, can autonomously interpret data task descriptions, decompose tasks into subtasks, reason over actions, ground actions into python code or tool calling, and execute operations. Unlike traditional data management and engineering tools, DataAgents dynamically plan workflows, call powerful tools, and adapt to diverse data tasks at scale. This report argues that DataAgents represent a paradigm shift toward autonomous data-to-knowledge systems. DataAgents are capable of handling collection, integration, preprocessing, selection, transformation, reweighing, augmentation, reprogramming, repairs, and retrieval. Through these capabilities, DataAgents transform complex and unstructured data into coherent and actionable knowledge. We first examine why the convergence of agentic AI and data-to-knowledge systems has emerged as a critical trend. We then define the concept of DataAgents and discuss their architectural design, training strategies, as well as the new skills and capabilities they enable. Finally, we call for concerted efforts to advance action workflow optimization, establish open datasets and benchmark ecosystems, safeguard privacy, balance efficiency with scalability, and develop trustworthy DataAgent guardrails to prevent malicious actions.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
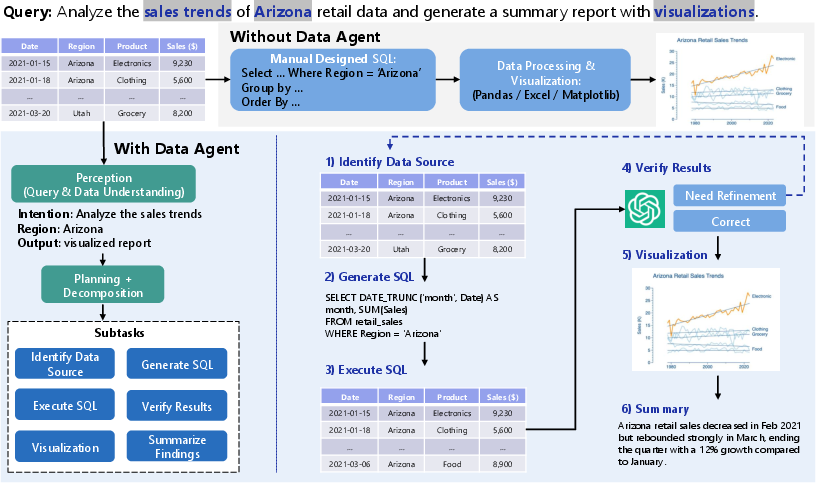
This paper introduces a new kind of smart helper for data called “Autonomous Data Agents” (DataAgents). Think of them like super-capable digital assistants that can read your request in plain language, figure out what steps are needed, write and run the right code or use the right tools, and then give you answers, charts, or cleaned-up data—mostly on their own. The big idea: turn messy data into useful knowledge with far less manual work.
What questions does the paper ask?
The paper focuses on a few simple but important questions:
- How can we make data work easier and faster by letting AI handle the repetitive parts, like cleaning, joining, and analyzing data?
- How do we get AI to not just “talk” about data, but actually plan, write code, use tools, and run complete workflows?
- What skills and safety rules do these agents need so they can do complex tasks reliably and responsibly?
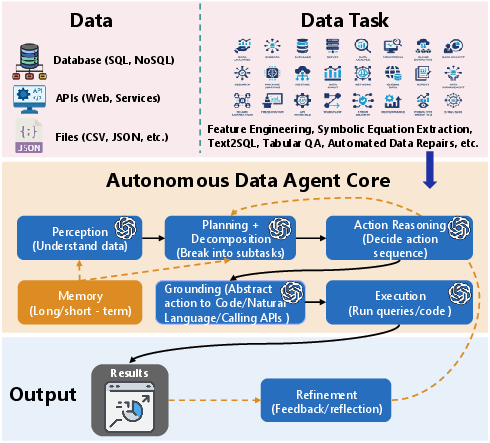
How do DataAgents work?
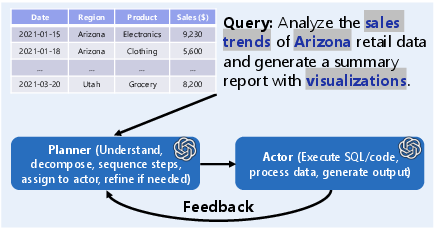
A DataAgent is like a small team in one: a planner, a thinker, and a doer that also knows how to use tools.
Here’s the basic loop, in everyday terms:
- See: It looks at your request (“Find sales trends for last quarter”) and peeks at the data (what columns exist, what the values look like).
- Plan: It breaks the big job into smaller steps (get data → clean it → analyze it → make charts → summarize).
- Do: It turns each step into real actions, like writing SQL, generating Python code, calling a database, or drawing a chart. It runs these actions, checks the results, and adjusts if something fails.
To make that happen, the agent uses a few key ideas:
- LLM: A powerful AI that understands and writes text, and can also write code from instructions.
- Task decomposition: Breaking a big task into bite-sized subtasks that are easier to do in order.
- Action grounding: Turning a plan into “real” things computers understand—like Python code, SQL queries, or tool calls—and executing them.
- Memory: Keeping track of what it already did so it doesn’t repeat mistakes and can make better next steps.
The agent’s “actions” come in a few forms:
- Use a tool: Call a database, a charting library, or a machine learning package.
- Write symbolic instructions: Generate SQL or Python code for data cleaning, feature creation, or math operations.
- Directly answer: Give a natural language summary or a simple answer when it’s enough.
Training these agents involves giving them lots of examples where an instruction is paired with:
- The data or schema,
- The step-by-step plan,
- The exact code/tool calls used,
- The results or outputs (like a cleaned table or a chart).
This style of training is called instruction tuning. For more advanced skills, they can also learn by trying actions and getting feedback on what worked.
What did the authors find or propose?
This paper is a roadmap, not just an experiment. Its main contributions are:
- A definition and vision for DataAgents as autonomous “data-to-knowledge” systems that can handle many data tasks end-to-end.
- A clear architecture: perceive (understand data and instructions), plan (break down tasks), and act (generate and run code/tools), with feedback and memory.
- Action types and reasoning methods: think-and-act loops, step-by-step reasoning, and trying different action paths to pick the best one.
- A training recipe: build datasets that include instructions, plans, code/tool calls, and outputs for skills like cleaning, feature engineering, visualization, text-to-SQL, and turning data into equations.
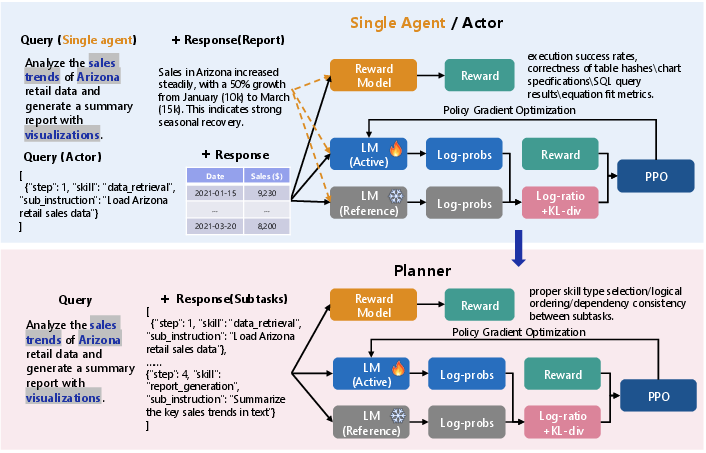
- Two design options: a single all-in-one agent, or a “planner–actor” pair where one plans and the other executes.
Why this matters: Today, much of data work is repetitive and slow. DataAgents can automate big parts of it, making it faster to get from raw data to useful answers.
Why this matters and what could happen next
If DataAgents become common:
- Teams could get insights much faster, with fewer tedious steps.
- Non-experts could ask for complex analyses in plain language and get reliable results.
- Data quality would improve because agents could consistently clean and prepare data before analysis.
The authors also warn about important challenges to tackle:
- Building shared datasets and benchmarks to test these agents fairly.
- Privacy and safety: preventing agents from leaking sensitive data or doing harmful actions.
- Efficiency and scale: keeping costs reasonable when tasks and data are large.
- Guardrails: rules and checks so the agent doesn’t make dangerous or misleading changes.
In short, DataAgents aim to make data “think, speak, and act”—turning raw information into decisions and discoveries with less human effort and more reliability.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, crafted to guide future research and implementation.
- Lack of empirical evaluation: no quantitative benchmarks, baselines, or ablations demonstrating DataAgents’ effectiveness vs. traditional pipelines, RL-only approaches, or LLM-only solutions across diverse data tasks.
- Missing standardized metrics: no clear definitions or measures for task decomposition quality (e.g., plan correctness, dependency fidelity), action reasoning accuracy, grounding success rates, tool-call reliability, latency, and end-to-end task success.
- Benchmark ecosystem gap: absence of open, reproducible datasets and sandboxes simulating realistic enterprise environments (heterogeneous schemas, large-scale tables, streaming data, access constraints) for systematic evaluation.
- Scalability and efficiency not characterized: no analysis of compute cost, inference latency, memory footprint, and throughput under large datasets (billions of rows), complex schemas, or multi-modal inputs.
- Token and context limitations: no strategy for handling data beyond LLM/VLM context windows (schema summarization, chunking, sampling policies, adaptive views) without sacrificing accuracy or safety.
- Cost-aware planning gap: no method for optimizing plans under resource budgets (e.g., tool invocation costs, data transfer overheads, API rate limits) or balancing accuracy vs. compute/time constraints.
- Action selection policy uncertainty: no principled mechanism for deciding when to use direct generation vs. symbolic expressions vs. tool calls, or how to switch/fallback among them at runtime.
- Grounding robustness unresolved: no formal verification/validation of generated code/SQL/tool calls (static typing, schema-aware checks, unit tests, sandbox dry-runs) to prevent runtime errors or unsafe operations.
- Error handling and recovery: no framework for detecting, classifying, and mitigating errors (schema mismatch, type errors, API failures, integrity constraints) and avoiding cascading failures in long action chains.
- Data integrity and transactional safety: no guarantees for idempotency, rollback, ACID compliance, and change management when agents modify data; no “dry-run” or “read-only” modes to prevent harmful writes.
- Privacy and security guardrails unspecified: no concrete mechanisms for access control (RBAC/ABAC), least-privilege tool use, secret management, PII redaction, differential privacy, or secure memory handling to prevent leakage.
- Adversarial resilience open: no defenses against prompt injection, tool-call abuse, data poisoning, SQL injection, or malicious code generation; no red-team evaluations or attack surfaces analysis.
- Trust and auditability: no specifications for provenance tracking, reproducible runs, version pinning (tools/libraries/models), audit logs, and explainable action rationales to meet compliance requirements.
- Memory management gaps: no algorithms for relevance-driven retrieval, summarization, forgetting, and cross-task transfer; no evaluation of memory-induced privacy risks or drift/contamination.
- Multi-modal data handling: the proposed JSON “infobox” idea lacks evidence of scalability, schema standardization, semantic consistency, and performance across mixed modalities (tables, texts, images, time series, graphs).
- Streaming and real-time constraints: no approach for continuous data ingestion, online updates, windowed analytics, and low-latency planning/execution under streaming workloads.
- Tool ecosystem standardization: no common interface/spec for tool capability descriptions, argument schemas, version constraints, allow-lists/deny-lists, and safe execution contracts across Python/SQL/APIs.
- Workflow optimization not operationalized: no algorithms for end-to-end action workflow optimization (graph pruning, step reordering under dependencies, parallelization, caching of intermediate artifacts).
- Decision-theoretic planning gap: no use of uncertainty quantification, confidence calibration, or expected utility to guide branching, exploration vs. exploitation (e.g., MCTS parameters), or plan revision.
- Reward design and RFT details missing: no concrete reinforcement signals, verifiers, or offline/online RFT setup; no discussion of simulated environments vs. real systems, safety in RL, or human-in-the-loop reward shaping.
- Generalization and domain adaptation: no methodology for transferring skills across domains (healthcare, finance, ecommerce), handling schema variability, or curriculum learning for complex, composite tasks.
- Comparative analysis of reasoning methods: no head-to-head comparison of ReAct, CoT, MCTS, hierarchical planners, or dual-agent vs. single-agent designs on real data tasks with actionable insights.
- Human oversight workflows: no design for approval gates, exception handling, interventions, and mixed-initiative collaboration; unclear escalation mechanisms when agent confidence is low or actions are high-risk.
- Software engineering and ops: no guidance on CI/CD for agents, sandboxing, resource quotas, concurrency control, scheduling, environment reproducibility, and test suites for generated pipelines.
- Reliability and stability under drift: no strategies for monitoring data/task drift, recalibrating policies, or preventing degradation of long-term agent performance and memory contamination.
- Multilingual and accessibility concerns: no exploration of non-English task descriptions, localized schemas/labels, or cross-lingual tool invocation challenges.
- Economic and environmental costs: no modeling of ROI, carbon footprint, or cost-benefit analysis of agent-mediated pipelines vs. conventional engineering approaches.
- Collaboration among agents: multi-agent coordination, specialization, communication protocols, conflict resolution, and shared memory/blackboard architectures remain unaddressed.
- Formal guarantees: no theoretical analysis or bounds on plan correctness, action safety, convergence of reasoning loops, or worst-case behavior under adversarial or degenerate inputs.
- Ethical and governance frameworks: unclear policies for responsible use, fairness in data operations (e.g., reweighting/augmentation), consent and legal compliance (HIPAA/GDPR), and stakeholder accountability.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can be implemented today with the DataAgents capabilities described in the paper. Each item notes sector relevance, likely tools/workflows, and key dependencies.
- Autonomous data cleaning and preprocessing assistant (sectors: healthcare, finance, retail, manufacturing)
- What it does: Interprets natural-language cleaning requests, plans subtasks, and grounds actions into executable Python/SQL to fix missing values, outliers, duplicates, type inconsistencies.
- Tools/workflows: Pandas/PySpark, scikit-learn preprocessors, Great Expectations for data quality checks, ReAct-style loops for error handling.
- Assumptions/dependencies: Secure tool access, schema visibility, sandboxed execution, governance to prevent destructive writes, human-in-the-loop review for critical datasets.
- Text-to-SQL copilot for BI and analytics (sectors: software/SaaS, finance, operations, public sector)
- What it does: Converts ambiguous business questions into validated SQL, plans joins/aggregations, and runs queries against Snowflake/BigQuery/Redshift.
- Tools/workflows: Text-to-SQL models (Spider/WikiSQL-style tuning), database connectors, role-based access control guardrails, execution trace logging.
- Assumptions/dependencies: Accurate schema metadata, permissions management, query cost controls, safe read-only defaults.
- Auto exploratory data analysis and visualization generator (sectors: all)
- What it does: Profiles datasets, generates summaries and charts, and composes reproducible code + narrative reports from plain-language prompts.
- Tools/workflows: Pandas Profiling, Matplotlib/Plotly, chart QA, JSON “infobox” context representation, single- or dual-agent plans (planner-actor).
- Assumptions/dependencies: Chart correctness and labeling validation, appropriate defaults for binning/aggregation, versioned artifacts for reproducibility.
- Feature engineering/generation agent for MLOps (sectors: fraud detection, marketing analytics, clinical prediction, risk scoring)
- What it does: Plans and executes feature selection, transformation, and crossing (ratios, interactions, binnings), evaluates with cross-validation, and checks for leakage.
- Tools/workflows: FEAST feature store, scikit-learn, AutoFE/generative FE sequences, code grounding with error handling, experiment tracking (MLflow).
- Assumptions/dependencies: Clear target labels, evaluation metrics, leakage checks, reproducible pipelines, domain oversight for interpretability.
- Data augmentation agent across modalities (sectors: NLP/CV product teams, tabular modeling in fintech/insurtech)
- What it does: Applies modality-appropriate augmentation (SMOTE, noise injection, backtranslation, Albumentations), logs parameters and artifacts.
- Tools/workflows: Albumentations, imbalanced-learn (SMOTE), Text augmentation libraries, JSON task specs for parameterization.
- Assumptions/dependencies: Distributional alignment to production data, licensing/compliance for augmented content, risk of label drift monitored.
- Data QA/testing agent (sectors: enterprise data engineering, BI)
- What it does: Auto-generates data quality tests, detects schema anomalies, validates transformations and aggregations, and writes documentation/data dictionaries.
- Tools/workflows: Great Expectations, dbt tests, lineage capture, audit log instrumentation, natural-language doc generation.
- Assumptions/dependencies: Stable schemas, clear data contracts, automated CI/CD gates for data tests, access to metadata catalogs.
- Report and dashboard generation copilot (sectors: SMBs, operations teams, finance planning, sales ops)
- What it does: Produces end-to-end weekly/monthly reports from instructions (query, clean, analyze, visualize, summarize), including anomaly flags (e.g., >20% drops).
- Tools/workflows: Planner-actor loops, database/API calling, charting libraries, templated narratives, export tools (CSV/Parquet/PDF).
- Assumptions/dependencies: Reliable source-of-truth data, human approval workflow for decisions, guardrails for alert thresholds.
- Academic reproducible notebooks with action traces (sectors: academia, data science education)
- What it does: Automatically structures multi-step analysis as executable trace blocks (plan → code → observation), enabling reproducibility and grading.
- Tools/workflows: Jupyter/VS Code extensions, structured JSON plans, code execution sandboxes, artifact hashes for verification.
- Assumptions/dependencies: Deterministic environments, dataset snapshots, policy for student privacy and plagiarism detection.
- Automated data cataloging and lineage documentation (sectors: enterprise data governance)
- What it does: Extracts schema, generates data dictionaries, lineage graphs, and policy-compliant documentation from operational logs and prompts.
- Tools/workflows: Connectors to warehouses/lakes, metadata APIs, LLM-based doc generation with review queues.
- Assumptions/dependencies: Access to metadata stores, governance policies for approvals, versioning of catalog entries.
- Daily-life personal data agent (sectors: consumer productivity)
- What it does: Analyzes personal finance CSVs, fitness logs, or home energy usage, creating summaries, charts, and budget/goal recommendations.
- Tools/workflows: Local CSV tooling, visualization, privacy-preserving local execution, simple instruction tuning for personal tasks.
- Assumptions/dependencies: Client-side privacy, secure credential storage, clear disclaimer on advisory limits.
- Healthcare admissions and resource planning assistant (sectors: healthcare providers)
- What it does: Cleans and aggregates admissions data, runs time-series forecasts, and proposes allocations (beds/staffing) with supporting visualizations.
- Tools/workflows: Forecasting libraries (Prophet, ARIMA), HIPAA-compliant data handling, scenario comparisons, plan decomposition to subtasks.
- Assumptions/dependencies: De-identification, clinical oversight, integration with hospital information systems, conservative alerting thresholds.
- Log analysis and alerting copilot (sectors: software/platform operations)
- What it does: Reads telemetry/logs, detects anomalies/outliers, suggests remediation runbooks, and drafts incident reports.
- Tools/workflows: ELK/Splunk connectors, anomaly detection tool calls, ReAct loops for triage, alerting via Jira/Slack integrations.
- Assumptions/dependencies: Access controls, false-positive minimization, structured postmortem templates, ops review.
Long-Term Applications
Below are forward-looking applications that build on the paper’s architecture, training strategies, and guardrail agenda; they require further research, scaling, or policy development before broad deployment.
- Fully autonomous data-to-knowledge systems (“DataAgent Orchestrator”) (sectors: cross-industry)
- What it could do: End-to-end planning, execution, reflection, and verification across complex, multi-hop workflows (collection → integration → analysis → reporting) with minimal human intervention.
- Tools/workflows: Planner-actor ecosystems, memory management, ReAct + MCTS reasoning, closed-loop validation, enterprise orchestration.
- Assumptions/dependencies: Robust guardrails and formal verification, comprehensive benchmarks, organizational trust and change management.
- Privacy-preserving, federated DataAgents (sectors: healthcare, finance, public sector)
- What it could do: Execute data tasks across silos with differential privacy/federated learning, secure tool calls, and policy-aligned action gating.
- Tools/workflows: Secure enclaves, federated connectors, DP noise mechanisms, policy-aware planner.
- Assumptions/dependencies: Regulatory alignment (HIPAA/GDPR), secure infrastructure, measurable privacy budgets, multi-party agreements.
- Multimodal DataAgents using unified JSON “infobox” (sectors: smart cities, robotics, media analytics)
- What it could do: Integrate tables/time-series/text/images/videos via a unified representation; reason across modalities for richer insights.
- Tools/workflows: VLM-augmented planners, multimodal perception, cross-modal grounding and execution.
- Assumptions/dependencies: Mature VLMs, reliable data synchronization, consistent metadata standards.
- Workflow optimization via RL/MCTS for ETL and analytics (sectors: data engineering, operations research)
- What it could do: Learn optimal transformation/join/aggregation sequences under cost, latency, and accuracy constraints; self-tune pipelines.
- Tools/workflows: RL policy learning on logs, Monte Carlo tree search over pipeline actions, reward shaping and verifiers.
- Assumptions/dependencies: High-quality execution logs, stable reward functions, safe exploration in production.
- Open benchmark ecosystem and datasets for DataAgents (sectors: academia, standards bodies)
- What it could do: Establish standardized multi-skill, multi-step tasks (decomposition, grounding, tool calling) with reproducible evaluation.
- Tools/workflows: “DataBench” suites, task repositories, execution trace validation harnesses, leaderboards.
- Assumptions/dependencies: Community buy-in, clear metrics beyond accuracy (robustness, cost, safety), funding and maintenance.
- Trustworthy guardrails and formal verification for agent actions (sectors: all regulated industries)
- What it could do: Prevent malicious/unsafe actions, verify code/tool calls, ensure compliance and auditability across steps.
- Tools/workflows: Policy engines, static/dynamic code analysis, counterfactual safety checks, provenance tracking.
- Assumptions/dependencies: Specification of allowed actions, scalable verification, transparent audit trails accepted by regulators.
- Autonomous feature programming and reprogramming (sectors: predictive modeling at scale)
- What it could do: Continually refine feature sets as data drifts; auto-retire/introduce features with interpretability guarantees.
- Tools/workflows: Generative feature search with RFT, leakage detection, explainability modules, feature-store governance.
- Assumptions/dependencies: Robust drift detection, compute budgets, human oversight for clinical/financial models.
- Real-time streaming/IoT DataAgents at the edge (sectors: energy, manufacturing, transportation)
- What it could do: Low-latency perception, planning, and action grounding for streaming data; on-device privacy and resilience.
- Tools/workflows: Stream processors (Kafka/Flink), lightweight LLMs/VLMs, edge accelerators, online learning.
- Assumptions/dependencies: Efficient models, deterministic fail-safes, constrained resources management.
- Cross-organizational data integration with consent and policy (sectors: supply chain, public health)
- What it could do: Automate compliant data exchanges, lineage tracking, and multi-party analytics under shared policies.
- Tools/workflows: Consent registries, data clean rooms, policy-aware planners, lineage and retention automation.
- Assumptions/dependencies: Legal frameworks, trust infrastructure, standardized policy vocabularies.
- DataAgents as enterprise “digital workers” (sectors: HR, finance operations, compliance)
- What it could do: Execute recurring data tasks (reports, reconciliations, audits), interact with users via natural language, and maintain process memory.
- Tools/workflows: Role-based planners, memory management across tasks, secure tool calling, workflow orchestration.
- Assumptions/dependencies: Job design and oversight, escalation paths, union/regulatory acceptance, performance SLAs.
- High-fidelity synthetic data generation and curation (sectors: model training, privacy-conscious analytics)
- What it could do: Create balanced, privacy-respecting synthetic datasets with documented generation parameters and utility metrics.
- Tools/workflows: Generative models with DP, utility/fidelity scoring, auditability of synthetic pipelines.
- Assumptions/dependencies: Reliable fidelity metrics, downstream validation, synthetic-to-real generalization monitoring.
- Adaptive learning analytics agents for education (sectors: edtech, K–12, higher education)
- What it could do: Analyze gradebooks, engagement logs, and content; provide individualized insights and interventions at scale.
- Tools/workflows: Multi-skill decomposition (preprocess → aggregate → visualize → recommend), policy-aligned guardrails (FERPA).
- Assumptions/dependencies: Pedagogical validation, privacy-by-design, teacher oversight loops.
- Government statistical reporting and anomaly detection (sectors: public sector statistics)
- What it could do: Automate data preparation and trend analyses for official statistics; flag irregularities with transparent methods.
- Tools/workflows: Plan decomposition with verifiable steps, open audit trails, reproducible artifact stores.
- Assumptions/dependencies: Transparency standards, public auditability, conservative thresholds to avoid misreporting.
- Regulatory reporting and model risk agents in finance (sectors: banking, insurance)
- What it could do: Compile regulatory reports, validate data pipelines, document model changes, and track risk metrics.
- Tools/workflows: Policy-aware planning, lineage capture, explainable feature transformations, compliance dashboards.
- Assumptions/dependencies: Regulator-approved audit mechanisms, robust documentation standards, safe rollback procedures.
Glossary
- Action grounding: Mapping high-level agent decisions to concrete, executable operations (e.g., code, queries, or API calls). "action grounding refers to the process of mapping an abstract action (derived from task decomposition and reasoning) to concrete, executable operations in the real-world environment or tools."
- Agentic AI: AI systems designed to plan, reason, and act autonomously toward goals, beyond reactive text generation. "we first examine why the convergence of agentic AI and data-to-knowledge systems has emerged as a critical trend."
- Autonomous Data Agents (DataAgents): Goal-driven AI systems that combine LLM reasoning, task planning, tool use, and execution for end-to-end data workflows. "Autonomous data agents (DataAgents), which integrate LLM reasoning with task decomposition, action reasoning and grounding, and tool calling, can autonomously interpret data task descriptions, decompose tasks into subtasks, reason over actions, ground actions into python code or tool calling, and execute operations."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step reasoning to decompose and solve multi-step tasks. "CoT Prompting Based Task Decomposition prompts the LLM to generate step-by-step reasoning traces."
- CodeAct: An approach that grounds agent actions by generating and executing code as a unified interface, with built-in error handling. "the CodeAct consolidates agent actions into executable code (e.g., Python) as a unified space, enabling grounding of diverse tasks like data analysis"
- Data knowledgization: The process of transforming data into actionable knowledge through automated operations and reasoning. "automate data-related tasks for better data knowledgization."
- Data-to-equation: Mapping data to analytical or symbolic model forms (e.g., via symbolic regression) with interpretable parameters. "Data-to-equation examples can be generated from physics, engineering, and regression datasets with known analytical forms"
- Data-to-knowledge systems: Architectures that convert complex data into coherent, actionable insights through autonomous pipelines. "DataAgents represent a paradigm shift toward autonomous data-to-knowledge systems."
- Direct generation: Producing final results entirely within the model without calling external tools. "Direct generation as actions. When the agent directly produces the end output without intermediate tool invocation"
- Embedding space: A continuous vector space where discrete entities (e.g., features or operations) are represented for optimization. "continuous optimization in embedding space under an encoding-optimization-decoding framework."
- Encoding-optimization-decoding framework: A formulation that encodes tasks into representations, optimizes in a latent space, and decodes actions or solutions. "under an encoding-optimization-decoding framework."
- Feature crossing: Creating new features by combining existing ones through interactions, ratios, or nonlinear transforms. "making decisions to perform feature crossing, or composing data pipelines, by interacting with the environment and receiving feedback."
- Instruction tuning: Supervised fine-tuning that aligns models to follow natural-language instructions across tasks. "instruction tuning aims to align pre-trained LLMs with diverse data operation tasks by conditioning them on task instructions"
- LLMs: Foundation models trained on massive text corpora with strong reasoning and language capabilities. "generative AI and LLMs have demonstrated their broad world knowledge, structured data understanding, and instruction-following proficiency"
- Long-term memory (in agents): Persistent memory of action trajectories across tasks to inform future decisions. "Long-term memory is historical action trajectories across tasks."
- LLM-Planner: A few-shot method that leverages LLMs to produce executable plans and actions from natural language. "For instance, LLM-Planner, is a few-shot grounding approach that leverages LLMs to generate executable plans and actions from natural language"
- Memory management (in agents): Mechanisms for tracking context and past interactions to guide next actions coherently. "Memory management refers to how DataAgents with LLM as reasoning core keep track of context and past interactions within a high-level task and across subtasks."
- Monte Carlo Tree Search: A simulation-based search algorithm balancing exploration and exploitation to select optimal action sequences. "selecting optimal subtask paths through search algorithms like Monte Carlo Tree Search, effective for exploratory data tasks with multiple pathways."
- Mutual information: A statistic quantifying the dependence between variables, often used to gauge feature relevance. "The agent evaluates feature importance using mutual information, correlation coefficients, or model weights"
- ReAct (Reasoning and Acting): A method that interleaves thought generation with action execution and observation in iterative loops. "Reasoning and Acting (ReAct), which interleaves reasoning (generating thoughts about a target subtask) with action execution and observation"
- Reinforcement-based Fine-Tuning (RFT): Fine-tuning with reinforcement signals to enhance planning, tool use, and adaptive execution. "reinforcement-based fine-tuning (RFT) is necessary to further enhance the reasoning and operational capabilities of the agents."
- Reinforcement intelligence: Learning strategies to optimize actions (e.g., querying or transforming data) under task-specific objectives. "reinforcement intelligence can learn optimal strategies for querying, transforming, and analyzing data under a targeted task"
- Reinforcement learning (RL): Learning optimal policies through interaction with an environment and feedback signals. "Reinforcement learning can learn optimal policies for selecting features, transforming data, making decisions to perform feature crossing, or composing data pipelines"
- Self-reflection (in agents): Mechanisms for agents to critique and adjust their reasoning or actions based on feedback. "self-reflection mechanisms (e.g., linguistic feedback) to adjust action sequences based on real-time observations"
- Short-term memory (in agents): Immediate context of recent actions within a subtask to avoid redundancy or conflicts. "Short-term memory is the most recent actions within a single subtask."
- SMOTE: A synthetic sampling technique to balance imbalanced tabular datasets by generating new minority-class samples. "tabular (e.g., SMOTE, noise injection) modalities."
- Symbolic expressions (as actions): Declarative representations like SQL, code, or transformation specs that are executed by systems. "Symbolic expressions as actions. A symbolic expression action is defined as when the agent generates formal symbolic declarative representations"
- Tabular data QA: Question answering over tables, requiring structured data understanding and reasoning. "tabular data QA"
- Text-to-SQL: Translating natural language queries into executable SQL statements over given schemas. "Text-to-SQL training data can be drawn from established benchmarks such as Spider and WikiSQL"
- Tool calling (as actions): Invoking external tools or APIs with parameters to perform data operations. "A tool calling action is defined as the action that the agent prepare valid inputs (e.g., arguments) and invoke an external tool (e.g., pandas, sklearn, or SQL engines) to complete the work"
- Visual LLMs (VLMs): Models that jointly process visual data and text for multimodal understanding. "VLMs have enhanced agents in processing images and videos."
- WebAgents: Agents that automate web-based tasks, now being adapted to data workflows. "WebAgents automate web-related tasks, but there is increasing interest in transferring the WebAgent concept to data to automate data-related tasks for better data knowledgization."
Collections
Sign up for free to add this paper to one or more collections.

