Detailed balance in large language model-driven agents
Abstract: LLM-driven agents are emerging as a powerful new paradigm for solving complex problems. Despite the empirical success of these practices, a theoretical framework to understand and unify their macroscopic dynamics remains lacking. This Letter proposes a method based on the least action principle to estimate the underlying generative directionality of LLMs embedded within agents. By experimentally measuring the transition probabilities between LLM-generated states, we statistically discover a detailed balance in LLM-generated transitions, indicating that LLM generation may not be achieved by generally learning rule sets and strategies, but rather by implicitly learning a class of underlying potential functions that may transcend different LLM architectures and prompt templates. To our knowledge, this is the first discovery of a macroscopic physical law in LLM generative dynamics that does not depend on specific model details. This work is an attempt to establish a macroscopic dynamics theory of complex AI systems, aiming to elevate the study of AI agents from a collection of engineering practices to a science built on effective measurements that are predictable and quantifiable.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
The paper looks at how AI agents powered by LLMs behave when they generate ideas or solutions step by step. Instead of zooming in on every tiny token the model produces, the authors zoom out and study the “big-picture” flow between whole states (like a whole idea, a program snippet, or a plan). They find that these flows follow a simple, physics-like rule called detailed balance, suggesting LLMs often act like they’re moving “downhill” on an invisible landscape of what “looks good” to the model.
The main questions the paper asks
- Can we describe the way LLM-driven agents move from one idea (state) to another using a simple, general rule?
- Is there an underlying “potential function” (think: a height map) that LLMs implicitly learn, which makes them prefer some states over others?
- Do the transitions between states behave like an equilibrium system in physics, where traffic between any two states balances out in a predictable way (detailed balance)?
- Can we measure this potential function directly from data?
How they studied it (in plain language)
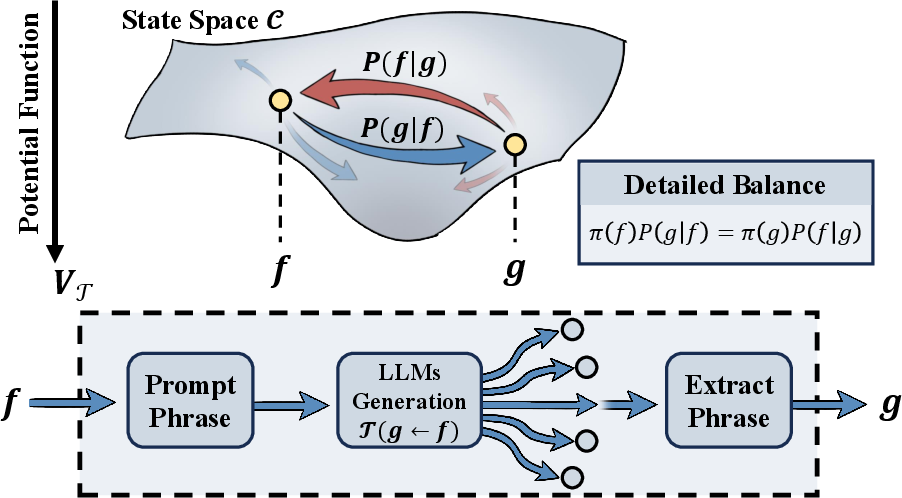
The authors treat an LLM agent like a traveler moving across a map:
- A “state” is the agent’s current situation or output, such as a specific word, code snippet, or formula.
- A “transition” is the jump from one state to the next when the LLM generates a new answer.
- They assume what happens next depends mainly on the current state (this is called a Markov process: “future depends on now, not the full past”).
They propose that LLMs are guided by an unseen “potential function,” V(state), like altitude on a map:
- Lower V = better-looking state to the LLM.
- The LLM tends to move “downhill” (toward lower V), but not always (it still explores).
To estimate this hidden map V, they use a least action principle:
- Action is a score that counts how often the agent moves “uphill” against the map’s ordering.
- They search for the V that makes the real transitions look as downhill as possible (i.e., minimizes action).
- If such a V exists and works well, it means the agent’s behavior follows a consistent ordering—like gravity pulling a ball downhill.
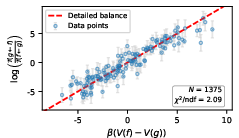
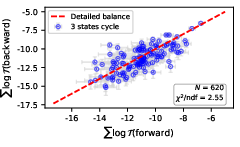
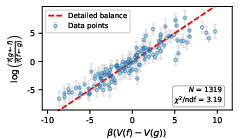
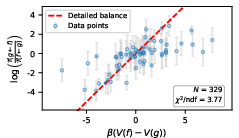
They also test a physics-like property called detailed balance:
- In a calm, balanced system, the “traffic” from A to B matches the traffic from B to A when weighted correctly by V.
- A simple check: if you walk around any loop and come back to where you started, your total altitude change should be zero. They test this with the measured transitions.
What they did in experiments
They ran two kinds of tests to measure real transitions and check for detailed balance.
- A word game (short reasoning)
- Task: Given a word whose letter values add to 100 (like WIZARDS), generate a new word whose letters also add to 100.
- They repeatedly prompted different models and counted how often each model moved from word A to word B.
- Findings:
- Some models quickly focused on a few words (strong exploitation), while another explored many words (strong exploration).
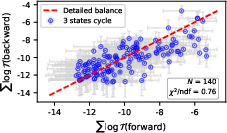
- For the more exploratory model, they tested closed loops between words. The loop sums were approximately zero—evidence for detailed balance.
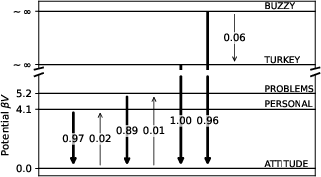
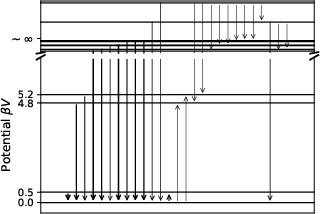
- For more convergent models, behavior looked like “low temperature” physics: the model gets trapped in a few best-looking states, which mirrors how particles settle into low-energy spots.
- A symbolic fitting agent (long reasoning chain)
- States were small math-like expressions (e.g., param1 * tanh(param2 * x) + param3).
- They recorded over 50,000 transitions across thousands of states.
- They again found that detailed balance mostly held across many state pairs.
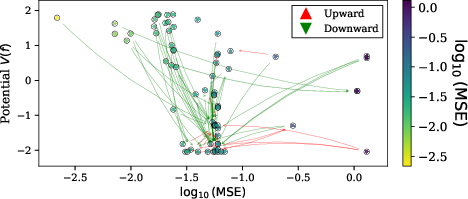
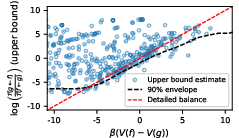
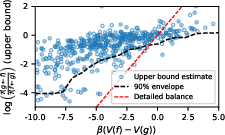
- Using the least action method, they estimated the hidden potential V for each state.
- They also searched for a human-readable formula for V that depends on features like expression complexity or structure. The resulting V predicted that most high-probability transitions go “downhill” (toward lower potential), matching the idea of an internal preference landscape.
The main findings and why they matter
- LLM-driven agents often behave as if they’re moving on an invisible “quality landscape” (the potential function V), preferring to move toward states the model internally sees as better.
- The measured transitions largely satisfy detailed balance, a hallmark of equilibrium systems in physics. That’s surprising because LLMs are complex and diverse—but at a coarse level, their behavior looks simple and orderly.
- This suggests LLMs may not just learn sets of rules or fixed strategies. Instead, they may learn a broad scoring function that ranks states by how promising they seem. Different models and prompts can still share this macroscopic behavior.
- Practically, knowing V helps explain why models get “stuck” (low-temperature traps) and how to tune exploration vs. exploitation. It could guide the design of prompts, search strategies, or “temperatures” to avoid getting stuck and to improve diversity.
What this could mean going forward
- Toward a science of AI agents: If many LLM systems share these macroscopic laws, we can predict and steer their behavior more reliably, not just tweak prompts by trial and error.
- Better control: Estimating V can help:
- Keep agents from getting trapped in a few repetitive states.
- Balance stability (exploitation) and discovery (exploration).
- Compare or combine different LLMs using a shared, measurable framework.
- New tools from physics: Ideas from equilibrium and near-equilibrium systems could help diagnose overfitting, tune generation processes, and design safer, more robust AI agents.
In short, the paper shows that beneath the complexity of LLMs, there might be a simple “downhill” rule that explains a lot of their big-picture behavior—and we can measure it. This turns the study of LLM agents from a collection of tricks into something more like a measurable science.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that the paper leaves open, focusing on what is missing, uncertain, or unexplored, and framed to guide future research.
- Conditions for detailed balance: Precisely characterize when LLM-agent transitions satisfy detailed balance (e.g., assumptions on stationarity, reversibility, ergodicity, decoding policy, and agent architecture). Define necessary and sufficient conditions and identify classes of tasks or agents where detailed balance provably fails.
- Markov and time-homogeneity assumptions: Test and formalize whether the coarse-grained agent states truly render the process Markovian and time-homogeneous, especially with memory, tool calls, external environment feedback, and multi-step reasoning.
- Equilibrium distribution and currents: Estimate the equilibrium distribution π(f) and directly measure probability currents J(f→g) = π(f)P(g|f) − π(g)P(f|g) to assess departures from equilibrium beyond triplet tests; provide methods to infer π(f) under sparse sampling.
- Statistical validation rigor: Replace visual scatter validations with formal hypothesis tests (confidence intervals, goodness-of-fit, effect sizes, model comparison), quantify systematic vs. sampling errors, and report power analyses to guard against selection bias (e.g., excluding pairs with rare reverse transitions).
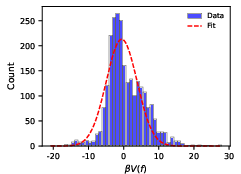
- β estimation and interpretation: Develop principled procedures to estimate β, calibrate its scale, and relate it to LLM decoding parameters (e.g., temperature, top-k, top-p) and exploration-exploitation behavior. Clarify whether β is model/task-specific or universal.
- Choice of penalty function K(x): Justify the selection of K(x)=exp(−βx/2), compare alternatives (e.g., hinge, quadratic, logistic), and analyze sensitivity of inferred V and detailed balance tests to K’s form and convexity.
- Identifiability and uniqueness of the potential V: Characterize gauge freedoms (e.g., additive constants, monotone transforms), uniqueness conditions given a sparse directed graph, and regularization needed to avoid degenerate or ill-posed solutions.
- Handling irreversibility and sparse graphs: Provide methods to estimate V when many transitions are one-directional or unobserved (zero or near-zero reverse probabilities), including techniques for partial reversibility, imputation, or robust optimization under missing edges.
- Coarse-graining adequacy: Formalize criteria for state definitions that preserve or induce detailed balance under coarse-graining; study how different state abstractions (string-level vs. expression-level vs. tool/trace-level) alter equilibrium properties.
- Generality across tasks and domains: Extend experiments beyond toy word-sum and symbolic fitting to diverse, realistic tasks (e.g., multi-step QA, coding, planning, embodied control, multimodal reasoning) and evaluate whether detailed balance persists.
- Robustness across models and settings: Systematically vary LLM architectures, training regimes (e.g., RLHF), prompts, system prompts, decoding strategies, and temperatures; test open-source checkpoints to assess reproducibility and independence from proprietary systems.
- Non-stationarity over time: Investigate whether transition kernels drift across a generation run (e.g., due to internal state accumulation, context changes, memory updates) and how such non-stationarity affects equilibrium claims and V estimation.
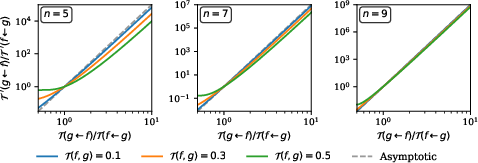
- Loop tests beyond triplets: Analyze larger cycles and global constraints (e.g., cycle space basis of the graph) to more sensitively detect violations of detailed balance; quantify how triplet-only tests may miss subtle nonequilibrium currents.
- Performance relevance of V: Establish causal links between the potential function and task performance (accuracy, solution quality, diversity). Show predictive or control utility (e.g., whether following low-V gradients improves outcomes or exploration).
- Practical control via V: Demonstrate algorithms that use estimated V or action values to steer generation (e.g., avoiding low-temperature trapping, balancing exploration/safety), with quantitative gains and ablations.
- Learning interpretable V functions: Provide feature engineering, training routines, cross-validation, and out-of-sample generalization analyses for interpretable V models (e.g., the 49-parameter IdeaSearch-derived function). Quantify overfitting and feature importance reliability.
- Scaling to large/continuous state spaces: Develop sampling, approximation, and online estimation techniques to infer V in very large or continuous spaces where pairwise transition measurement is infeasible.
- Measure selection and weighting: Justify choices of measures Df,Dg and observation weighting (e.g., visitation frequency vs. uniform), and study how these choices affect V and detailed balance claims.
- Alternative explanations: Separate effects of decoding biases, token-level priors, training corpus statistics, and prompt engineering from inferred “potential learning.” Use ablations to test whether strategy-set learning can mimic observed balance.
- Near-equilibrium theory: Quantify deviations from equilibrium (e.g., entropy production, fluctuation theorems) and relate them to model quality (overfitting/underfitting), agent design, and task characteristics.
- Boundary and failure cases: Identify concrete scenarios where detailed balance demonstrably breaks (e.g., adversarial prompts, dynamic tools, online learning agents), and map the boundary between equilibrium-like and nonequilibrium regimes.
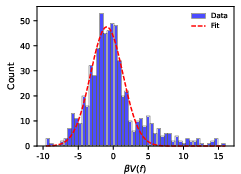
- Data preprocessing and thresholds: Document and analyze the impact of filtering criteria (e.g., “valid words”), transition thresholds (e.g., T(g|f)>0.05), and exclusion rules (e.g., |V(f)−V(g)| > log N) on conclusions and possible biases.
- Reproducibility toolkit: Provide standardized experimental protocols, open implementations, and benchmarks to reproduce detailed balance tests across tasks and models, including power/sample-size guidelines.
- Theoretical derivation completeness: Supply full proofs and conditions for the equivalence between the variational principle and least action under different K, and clarify the link from Eq. (minV) to detailed balance beyond special cases.
Practical Applications
Practical Applications of “Detailed balance in LLM-driven agents”
Below is a structured set of practical, real-world applications derived from the paper’s findings, methods, and innovations. Each item indicates sector relevance, potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed now using the paper’s open-source code and straightforward instrumentation of existing agents.
- Potential-based observability for LLM agents (software, MLOps)
- What: Add “equilibrium adherence” and potential-tracking telemetry to agent frameworks (e.g., LangChain, AutoGen, bespoke orchestration).
- How: Log state transitions; estimate transition kernels T(g|f); compute the least-action potential V; monitor closed-loop detailed-balance residuals.
- Tools/workflows:
- Equilibrium Monitor SDK built on the provided GitHub repo and HF datasets.
- A dashboard showing per-agent metrics: potential trend, loop residuals, attractor states, exploration/exploitation balance.
- Assumptions/dependencies: Stationary task setting over the logging window; consistent state parsing; sufficient sampling to estimate T(g|f); coarse-grained states defined and stable.
- Stuck-run detection and “thermostat” recovery (software, productivity assistants)
- What: Detect low-temperature trapping (rapid convergence to a few states) and auto-trigger “reheating” (increase randomness, broaden tools/memory).
- How: Watch for sharp potential decreases and narrow state distributions; programmatically raise β-equivalents via prompt variation, temperature, sampling strategies, or diversify tools/memories.
- Tools/workflows:
- A “LLM thermostat” module that modulates temperature/prompts/memory breadth when equilibrium signals indicate trapping.
- Assumptions/dependencies: Valid mapping between β and controllable model settings (temperature, sampling diversity); reliable state labeling; minimal exogenous drift.
- Model selection by exploration–exploitation profile (software, research)
- What: Choose models according to measured convergence (Claude/Gemini) versus exploration (GPT-5 Nano) for task needs.
- How: Run a short pilot; estimate potential distribution and transition diversity; match to scenario (e.g., stable coding vs. creative ideation).
- Tools/workflows:
- A “profile-first” evaluation card including number of distinct states discovered per 20k steps, entropy of transitions, loop residuals.
- Assumptions/dependencies: Sufficiently representative pilot tasks; consistent agent wrapping across models.
- Potential-guided caching, routing, and pruning (software engineering, code generation)
- What: Cache “attractor” states (low V) and prune high-V states to reduce cost and latency in repeated workflows like code synthesis, plan refinement, or document drafting.
- How: Maintain a state-indexed cache keyed by V; reuse proven low-V states; deprioritize or throttle high-V branches unless exploration is requested.
- Tools/workflows:
- A “Potential Cache” for state memories; router that biases toward lower-V states for efficiency; optional exploration toggles for diversity tasks.
- Assumptions/dependencies: Stable mapping from V to utility in the given task; reliable state normalization across sessions.
- New evaluation metrics and benchmarks (academia, model evaluation)
- What: Add detailed-balance checks (closed-loop residuals) and potential-consistency measures to model/agent evaluation suites.
- How: Construct transition graphs from logs; verify log-sum ratios across triplets; report equilibrium-adherence indices.
- Tools/workflows:
- “DetailedBalanceBench” add-on for existing benchmarks; scripts for loop detection and residual analysis.
- Assumptions/dependencies: Adequate bi-directional sampling; fixed prompt templates during evaluation; robust statistical error handling.
- Interpretable feature discovery for agent cognition (academia, interpretability)
- What: Use IdeaSearch-style workflows to learn functional forms mapping states to potential V, revealing salient features (complexity, syntactic validity, domain patterns).
- How: Minimize the action using parametric forms; analyze learned coefficients to quantify which state features drive agent “global ordering.”
- Tools/workflows:
- IdeaSearchFitter integrated with least-action objective; reporting of top features and their weights; model cards documenting cognitive biases.
- Assumptions/dependencies: Sufficiently expressive feature library; avoidance of string-level overfitting; stable feature extraction across states.
- Safety and reliability auditing via equilibrium adherence (policy, AI governance)
- What: Require agents in sensitive domains to log state transitions and report equilibrium/detailed-balance adherence as a health metric.
- How: Auditors review loop residual statistics; flag non-stationarity or extreme deviations that may indicate brittle strategies or manipulation.
- Tools/workflows:
- An “Equilibrium Adherence Index” included in compliance reports and monitoring guidelines.
- Assumptions/dependencies: Stationary task framing; regulated logging and privacy-preserving state representations; clear thresholds for acceptable deviations.
- Course modules and demos in physics-of-AI (education)
- What: Classroom labs replicating the paper’s experiments to teach macroscopic laws in AI dynamics.
- How: Students build transition graphs; verify detailed balance on toy tasks; interpret potentials; test exploration controls.
- Tools/workflows:
- Packaged notebooks with data and code; lab instructions using word-sum or symbolic-fitting tasks.
- Assumptions/dependencies: Access to LLM APIs; simplified state definitions suitable for coursework.
- Portfolio and strategy ideation assistants with exploration controls (finance, product)
- What: Use potential-tracking to ensure ideation assistants don’t collapse to a few strategies; inject exploration when trapping occurs.
- How: Monitor state diversity and potential trends; schedule exploration episodes; enforce minimal diversity thresholds in generated plans.
- Tools/workflows:
- “Strategy Exploration Governor” integrated with planning agents; telemetry on diversity and equilibrium signals.
- Assumptions/dependencies: Non-adversarial market drift during measurement; careful separation of ideation from execution; domain guardrails for risk.
Long-Term Applications
These require further research, scaling, or development to mature, often including formal safety proofs, multi-agent generalization, and robust non-stationary handling.
- Lyapunov-style guarantees for agent safety (robotics, healthcare, autonomous systems)
- What: Treat V as a Lyapunov-like function to formalize stability (prefer transitions that reduce “risk potential”), supporting certificates for safe operation.
- How: Derive or learn domain-specific potentials with constraints; verify monotone decrease along control policies; integrate with tool-use and memory modules.
- Tools/products:
- “Potential-Certified Controllers” for LLM-based planners; safety case documentation aligned with ISO/IEC standards.
- Assumptions/dependencies: High-fidelity state abstractions; domain-specific constraints; validated mapping from V to real-world safety; rigorous verification pipelines.
- Equilibrium regularization as a training objective (software, foundational models)
- What: Incorporate potential/detailed-balance adherence into training or fine-tuning to reduce brittle strategy learning and improve generalization.
- How: Penalize loop residuals or action values; shape prompts/memory to nudge toward consistent potentials; combine with RLHF/RLAIF-style signals.
- Tools/products:
- “Equilibrium-Regularized Fine-Tuning” recipes; open benchmarks tracking generalization and overfitting via equilibrium metrics.
- Assumptions/dependencies: Differentiable proxies for transition estimates; scalable data collection; alignment with existing training pipelines.
- Adaptive β-schedules and potential shaping for controlled diversity (software, creative industries)
- What: Systematically modulate β-equivalents over task phases to balance exploration/exploitation and avoid premature convergence.
- How: Learn phase-wise schedules; apply entropy constraints; introduce “potential shaping” to guide agents toward desired regions (e.g., novelty zones).
- Tools/products:
- “LLM Thermostat Planner” with phase-aware β schedules; policy engines for exploration quotas.
- Assumptions/dependencies: Reliable correlation between β and agent behavior under varied architectures; robust non-stationary handling across long tasks.
- Multi-agent thermodynamics for coordination (enterprise workflows, operations research)
- What: Extend detailed balance and least-action potentials to multi-agent systems (e.g., teams of LLM tools) to predict coordination patterns and avoid deadlocks.
- How: Model shared state spaces; estimate inter-agent transitions; design potentials that minimize global action (coordination cost).
- Tools/products:
- “Thermo-Coordinated Orchestrators” optimizing multi-agent pipelines; diagnostic analytics for global equilibrium deviations.
- Assumptions/dependencies: Coherent shared state definitions; tractable estimation of cross-agent kernels; manageable combinatorial complexity.
- Overfitting and brittleness diagnostics via equilibrium deviation (academia, safety)
- What: Use measured violations of detailed balance and rising action/loop residuals as signals of overfitting or brittle prompt-tool strategies.
- How: Longitudinal monitoring during training/fine-tuning; correlate deviations with failure modes (hallucinations, narrow strategy sets).
- Tools/products:
- “Equilibrium Deviation Index” integrated into training dashboards; research protocols to tie deviation patterns to generalization errors.
- Assumptions/dependencies: Stable evaluation tasks; careful control of external confounders; large-scale empirical validation.
- Domain-specific potentials for decision support (healthcare, policy)
- What: Learn clinically-informed or policy-aware potentials to steer reasoning toward safe, evidence-based states while maintaining exploration for rare cases.
- How: Embed domain ontologies and constraints into potential estimation; validate with expert review; combine with tool calls and memory audits.
- Tools/products:
- “Guideline-Aligned Potential Shapers” for clinical assistants; policy-planning agents with constraint-aware potentials.
- Assumptions/dependencies: Expert-curated state features; strict compliance and auditing; proven mapping from potential to decision quality.
- New theoretical foundations for macroscopic AI dynamics (academia)
- What: Build a general science of LLM generative dynamics using equilibrium, near-equilibrium, and coarse-graining tools.
- How: Formalize conditions for detailed balance in agent spaces; study deviations and phase transitions; connect to information bottlenecks and representation learning.
- Tools/products:
- Open corpora of transition graphs; standardized evaluation suites; theory-driven design patterns for agents.
- Assumptions/dependencies: Broad participation across labs; consensus on state-space definitions; reproducible measurement protocols.
Cross-Cutting Assumptions and Dependencies
To make the above applications feasible and reliable:
- State-space design must be explicit, coarse-grained, and stable across runs, with deterministic parsing from logs.
- Task stationarity over the measurement window is crucial; fast-changing environments will degrade detailed-balance estimates.
- Sufficient sampling is needed to estimate T(g|f) and loop residuals; bi-directional transitions must be observed for closed-loop checks.
- The choice of convex K(x) and the effective β must be matched to model settings (temperature, sampling strategy) and may vary by architecture.
- External tool calls, memory modules, and prompt templates can shift the effective dynamics; instrumentation should capture those changes.
- Interpretability-driven potential models should avoid string-level overfitting, favoring structural and semantic features aligned with domain goals.
These applications turn the paper’s central insight—LLM agents often exhibit detailed balance in a coarse-grained state space—into actionable observability, control, safety, and evaluation capabilities across sectors.
Glossary
- Action: A functional that aggregates how much observed transitions violate an assumed ordering, used to quantify global behavior. "we weight by the transition kernel and define the action as the global average violation:"
- Closed path: A loop in the transition graph that starts and ends at the same state, used to test balance conditions. "Specifically, considering a closed path ,"
- Coarse-grained: A macroscopic description that abstracts away fine-grained generative details. "which is coarse-grained compared to the complete generation sequence of LLMs"
- Convex function: A function with the property that line segments lie above its graph, used here to penalize violations in ordering. "In this Letter, we choose as the convex function describing the violation of the given state transition from to in the ordering of the scalar function ."
- Detailed balance: A symmetry of transitions in equilibrium where forward and reverse flows between any two states balance. "we statistically discover a detailed balance in LLM-generated transitions"
- Equilibrium condition: The stationarity requirement that net weighted flow into and out of any state is zero under the chosen penalty. "the equilibrium condition Eq.~\eqref{eq:minV} is almost equivalent to the detailed balance condition Eq.~\eqref{eq:detailed balance}."
- Equilibrium distribution: The stationary probability distribution over states in an equilibrium system. "where denotes the equilibrium distribution of the system at state "
- Equilibrium system: A system whose dynamics satisfy detailed balance, exhibiting time-reversible macroscopic behavior. "if describes the transition of an equilibrium system"
- Exploration-exploitation trade-off: The balance between searching new states and favoring known high-quality states in generative dynamics. "This difference reflects the exploration-exploitation trade-off in LLM generative dynamics"
- Least action principle: The principle that the realized dynamics minimize the action, yielding governing equations. "This Letter proposes a method based on the least action principle to estimate the underlying generative directionality of LLMs embedded within agents."
- Low-temperature trapping phenomenon: A physical effect where systems get stuck in low-energy minima due to suppressed fluctuations. "This behavior is similar to the low-temperature trapping phenomenon in physical systems"
- Lyapunov function: A scalar function that decreases along trajectories, certifying ordered or stable dynamics. "in this case, serves as a Lyapunov function"
- Markov transition process: A stochastic process where the next state depends only on the current state via defined transition probabilities. "viewing it as a Markov transition process in its state space"
- Measure (on the state space): A mathematical object that defines how to integrate or sum over states. "where are measures on the state space."
- Potential function: A scalar scoring function over states that encodes directionality or “quality” guiding transitions. "indicating that LLM generation may not be achieved by generally learning rule sets and strategies, but rather by implicitly learning an underlying potential function"
- Transition kernel: The conditional probability of moving from one state to another in a Markov process. "with a transition kernel "
- Variational principle: The condition that a functional is stationary under small variations, used to derive equilibrium relations. "The variational principle is equivalent to the least action principle under the condition that is a convex function."
Collections
Sign up for free to add this paper to one or more collections.