- The paper demonstrates that conventional RLVR causes diversity collapse by enforcing mode-seeking behavior through reverse KL divergence.
- It introduces α-DPG, a novel distributional matching framework that interpolates between mass-covering and mode-seeking to achieve Pareto-optimal trade-offs on theorem-proving benchmarks.
- Empirical results on Lean workbooks reveal that tuning the α-divergence produces state-of-the-art pass@k metrics while preserving solution coverage.
Filtering as Distributional Matching: Diversity–Precision Tradeoffs in LLM Reasoning
Overview and Motivation
This paper analyzes the detrimental impact of RL-based post-training on sample diversity in LLMs for reasoning tasks, introduces an explicit distribution-matching framework grounded in verifiable reward filtering, and unifies RL-based and mass-covering approaches using the α-divergence family. The core thesis is that typical RLVR (RL from Verifiable Rewards) implicitly minimizes the reverse KL (mode-seeking) divergence relative to a filtered target, causing excessive probability concentration and loss of coverage. By shifting to explicit distributional matching and varying the divergence, the authors decouple coverage and precision and empirically achieve Pareto-optimal trade-offs for theorem-proving benchmarks.
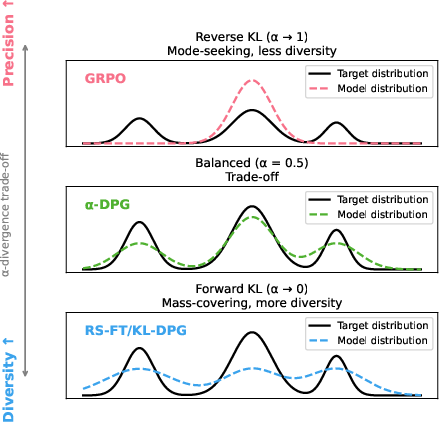
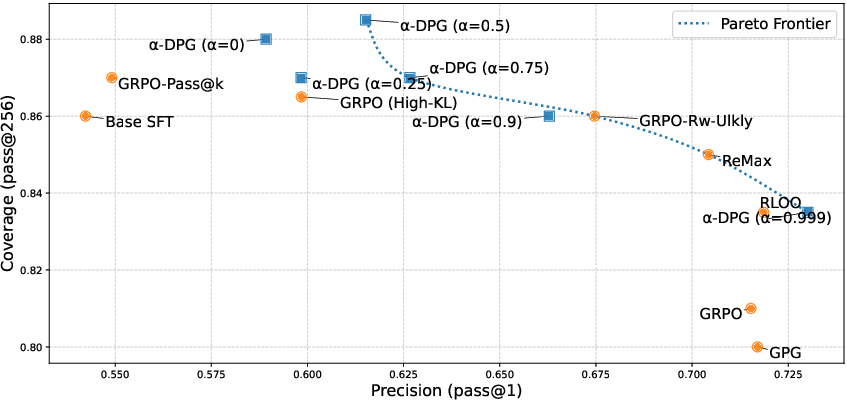
Figure 1: (Left) GRPO/PPO and policy gradient methods place mass on a narrow part of the verifier-constrained support; KL-DPG and FKL recover diversity but can assign mass to low-quality regions. α-DPG interpolates between these extremes. (Right) Models tuned by varying α trace a Pareto frontier between pass@1 (precision) and pass@256 (coverage).
Distributional Control: From RLVR to α-DPG
Distributional Perspective. Rather than optimizing for expected reward under a policy πθ, the distributional perspective defines the ideal target px(y)∝base(y∣x)v(y,x): the base LLM restricted to exactly valid solutions via a binary verifier. The autoregressive policy is then trained to minimize divergence Df(πθ,px) for some f-divergence, yielding a spectrum between mass-covering (Forward KL) and mode-seeking (Reverse KL) as α is varied.
Connection to RLVR. The canonical RLVR “regularized reward” objective is shown to be equivalent to minimizing (up to sign and rescaling) the reverse KL DKL(πθ∥px,β) for a tempered, verifier-constrained target, with the mode-seeking character increasing as KL penalty β→0. This drives mass to few high-reward regions, causing empirically verified diversity collapse.
α-DPG: Unifying and Extending Distributional Objectives
The framework generalizes both RLVR and existing mass-covering techniques via the α-divergence family, a strict generalization of KL and Hellinger distances. α=1 yields Reverse KL (RLVR; accurate but undiverse), α=0 yields Forward KL (KL-DPG; diverse but imprecise), with intermediate α furnishing a tunable balance. The pseudo-reward for policy gradient is explicit for any α and gradients are implemented using importance sampling, with variance controlled by reward clipping.
Lean Theorem-Proving Benchmark
Experiments are conducted on a challenging subset of the Lean workbook, using DeepSeek-Prover-V1.5-SFT as the base and a suite of RL and distribution-matching baselines (including GRPO, RLOO, Pass@k, ReMax, and GPG). The reward is verifier-based on Lean4 compilation.
Pareto Frontier and Empirical Trade-offs
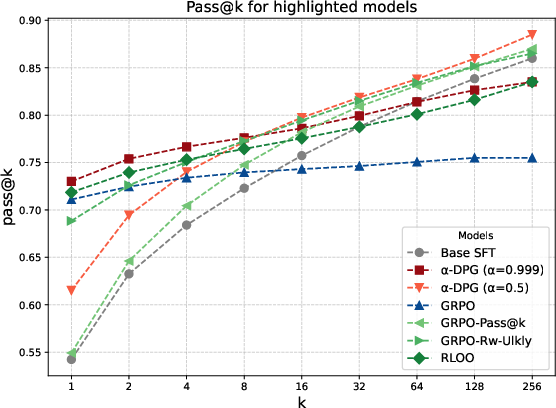
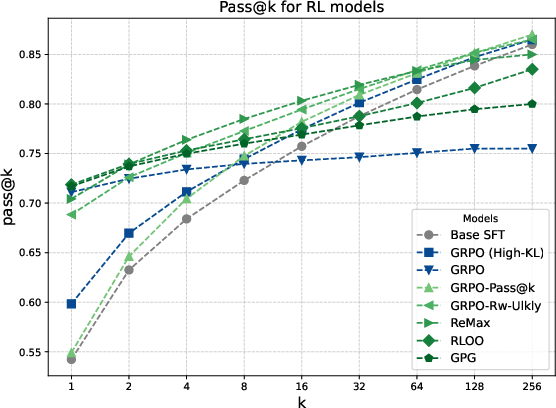
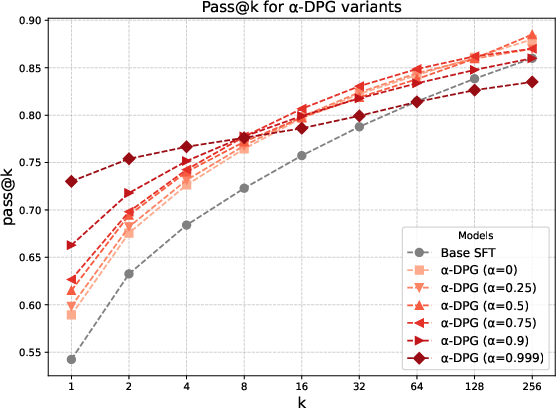
Figure 2: pass@k curves for Base, dr-GRPO, RLOO, and α-DPG at various α. High α prioritizes pass@1; lower values increase pass@k, especially at larger k.
α-DPG achieves Pareto-optimality: no other method outperforms it simultaneously in both pass@1 and pass@256. High α (∼0.999) achieves strong pass@1 but restricted coverage; α≈0.5 yields state-of-the-art pass@256, indicating that significant coverage gains are purely a function of divergence choice, not only model structure.
Mode-Seeking Effects and Difficulty Transition
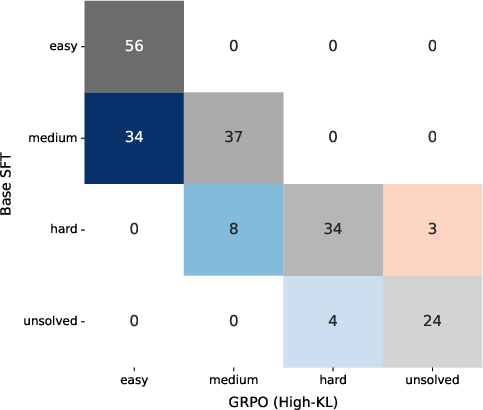
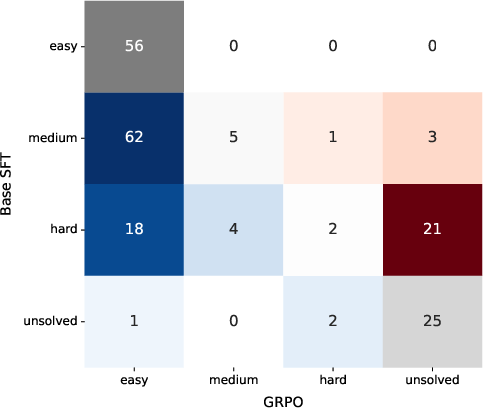
Figure 3: Training with high α (mode-seeking) or GRPO polarizes the distribution, making many “medium” problems easy but causing some hard cases to become unsolved. Lower α and higher KL maintain solvability at the cost of less sample-efficiency improvement for easy cases.
Diversity pruning (mode-seeking) is directly observable in difficulty transition matrices: hard problems are increasingly mapped to the unsolved region as more probability mass is assigned to a subregion of support.
Diversity–Coverage Correlation
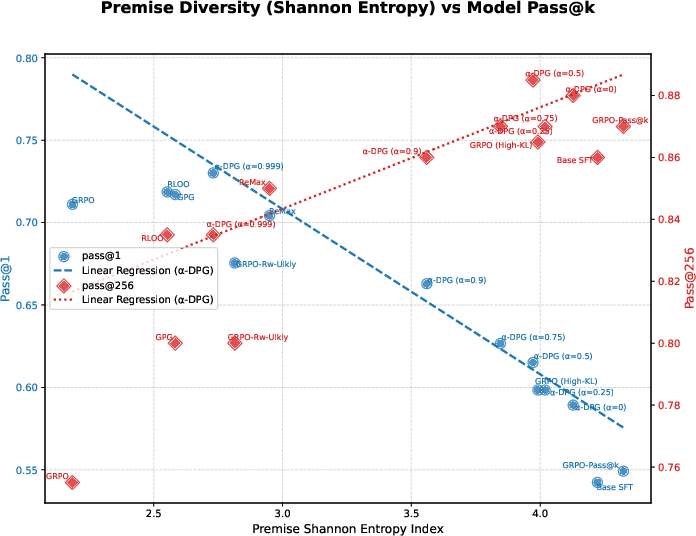
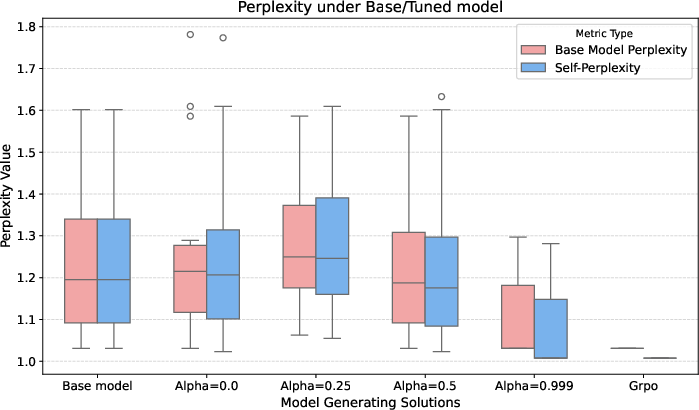
Figure 4: (Left) Premise diversity (by Shannon index) has a clear positive correlation with pass@256, but is anticorrelated with pass@1. (Right) Perplexity (under the base SFT model) for generated solutions: all methods, regardless of divergence, mainly sample from already likely regions.
Coverage gains are directly explained by increased solution path diversity, as measured by entropy and Simpson/Gini-Simpson indices over tactics and premises. Moreover, all plausible solutions are already present in the SFT base model, confirming that post-training merely reweights support.
Generalization to Mathematical Reasoning and Model Variants
The α-DPG methodology is robust to changes in dataset and model. On Minerva-level-5 with Qwen-2.5-Math-1.5B and with Kimina-Prover-Distill, the same coverage–precision trade-offs are observed: optimal α continue to outperform both mass-covering and mode-seeking extremes in pass@k for large k, and the effect holds even with substantial domain or support shift.
Theoretical Implications
This work provides a formal and practical resolution to recent debates on whether RLVR or its variants can create genuinely new solution modes. Evidence indicates that reverse KL-based methods cannot synthesize modes outside the verifier-filtered base distribution; they simply amplify high-reward regions and truncate others. The results illustrate that diversity collapse is inherent to the mode-seeking divergence, not to the concept of correctness filtering.
Additionally, the functional dependence of the α-divergence on the ratio of supports is carefully decomposed theoretically (see Appendix), showing a divergence that is infinite when the policy predicts where p has no support (hard constraint), but smooth and tunable when using lower α (softer constraint).
Practical Recommendations and Future Directions
Practically, the optimal policy for reasoning tasks requiring both correctness and broad solution coverage can be obtained only by tuning the divergence. RLVR alone is strictly suboptimal for large-scale solution search; α-DPG or other mass-covering divergences are necessary for efficient use of inference compute.
The authors suggest curriculum schedules over α, improved estimator precision for large sequence spaces, and integration with online distillation as future research directions. Clipping and scaling design successfully suppress variance, but further scaling studies are warranted.
Conclusion
Explicit distributional matching with verifiable filtering, combined with the continuous tuning of the α-divergence, provides a principled and empirically validated remedy to diversity collapse in LLM reasoning post-training. The framework not only encompasses all prior approaches (RLVR, KL-DPG, RS-FT, Pass@k, etc.) but delivers new state-of-the-art results in pass@k at high k by directly controlling the precision-diversity trade-off. The core insight is that controlling the type of divergence, not the introduction of new solution mass, is the central axis for improving practical coverage and efficient exploration in LLM-based reasoning.

