- The paper shows that RLVR is fundamentally limited by the base model's support, preventing discovery of entirely novel correct solutions.
- The theoretical analysis formalizes that RLVR conservatively reweights towards high-reward modes, enforcing an entropy–reward tradeoff that reduces diversity.
- Empirical evidence demonstrates that while RLVR improves pass@k scores, it simultaneously shrinks the empirical support, favoring precision over exploration.
RLVR Constrained by Base Model Support
The paper "The Invisible Leash: Why RLVR May Not Escape Its Origin" (2507.14843) presents a theoretical and empirical analysis of Reinforcement Learning with Verifiable Rewards (RLVR), questioning whether it truly expands a model's reasoning boundary or merely amplifies high-reward outputs that the base model already knows. The study offers a theoretical perspective that RLVR is constrained by the base model’s support, unable to sample solutions with zero initial probability, and operates as a conservative reweighting mechanism. It identifies an entropy–reward tradeoff, where RLVR enhances precision but may narrow exploration. The empirical results validate that while RLVR improves pass@1, the shrinkage of empirical support outweighs the expansion, failing to recover correct answers previously accessible to the base model.
Theoretical Limits of RLVR
The paper formalizes the limitations of RLVR through several theoretical results. First, it introduces the concept of the support of correct completions, defining it as the set of correct completions assigned a non-zero probability by a given distribution. The central theoretical result, Theorem 2.1, states that the support of the RLVR-trained distribution is a subset of the support of the base model's distribution.
This theorem implies that if the base model assigns zero probability to a correct solution, RLVR cannot discover it. Corollary 2.2 further establishes an asymptotic sampling upper bound, showing that the pass@k score of the RLVR-trained model is upper-bounded by that of the base model as the number of samples approaches infinity. These results highlight that RLVR's optimization is confined within the initial support of the base model, preventing the discovery of truly novel solutions.
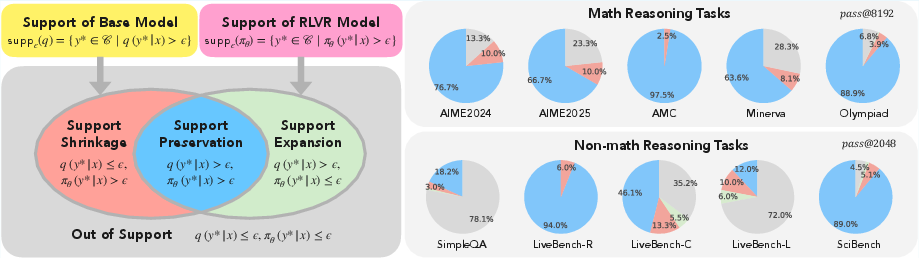
Figure 1: Empirical-support dynamics of RLVR across tasks.
To address the strictness of the support preservation theorem, the paper introduces the concept of empirical support, defined using a threshold ϵ to account for the practical limitations of softmax layers and finite sampling. Empirical-support expansion and shrinkage are defined based on whether RLVR assigns non-negligible probability to previously underrepresented completions or excludes correct solutions that were previously accessible. Theorem 2.3 provides bounds on the probability mass assigned to low-density completions, showing that RLVR tends to concentrate mass around the high-probability modes of the base model.
Variational Interpretation and Entropy Trade-off
The paper presents a variational view of the RLVR objective, revealing its conservative nature. Proposition 2.4 demonstrates that RLVR can be interpreted as a KL projection onto reward-consistent distributions, making minimal updates to the base distribution while ensuring improved performance. Corollary 2.5 examines the KL-free limit, where RLVR simplifies to a hard-filtered projection onto reward-maximizing completions, further emphasizing its reliance on the base model's distribution. Theorem 2.6 highlights the entropy–reward tradeoff, showing that RLVR tends to reduce the entropy of the answer distribution, which can improve precision but may also suppress valuable diversity. The formalization of the entropy-reward tradeoff shows the importance of balancing exploration and exploitation in RLVR, as concentrating solely on high-reward solutions can lead to a loss of diversity and potentially overlook correct solutions.
Empirical Evidence and Analysis
The paper provides empirical evidence to support its theoretical findings. The experimental setup involves using ProRL as the RLVR method, with DeepSeek-R1-Distill-Qwen-1.5B as the base model. The paper evaluates performance on various tasks, including math reasoning, logical reasoning, factual QA, and code generation. The empirical results demonstrate that RLVR primarily sharpens the distribution within the effective support of the base model. While RLVR occasionally assigns non-negligible probability mass to previously underrepresented completions, empirical-support shrinkage is more frequent.
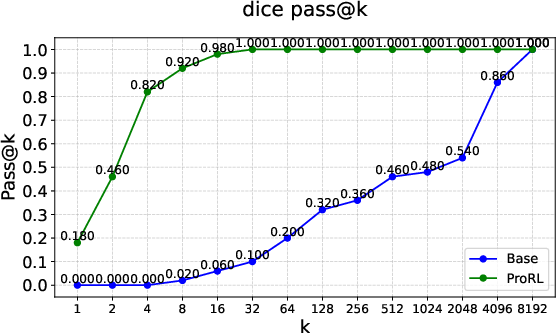
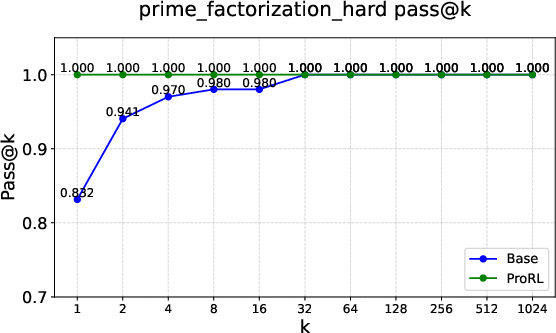
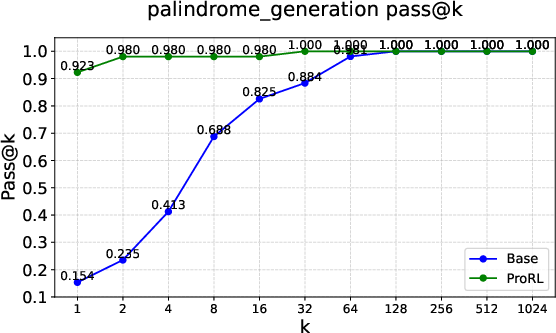
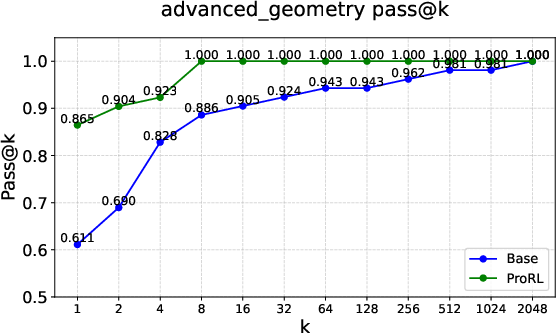
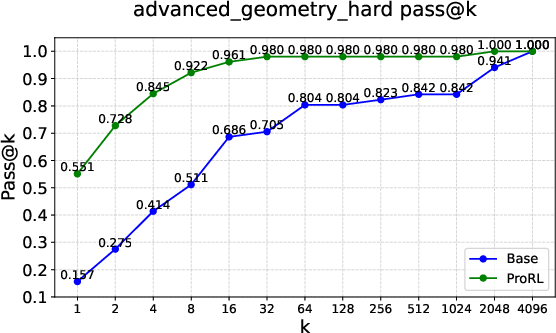
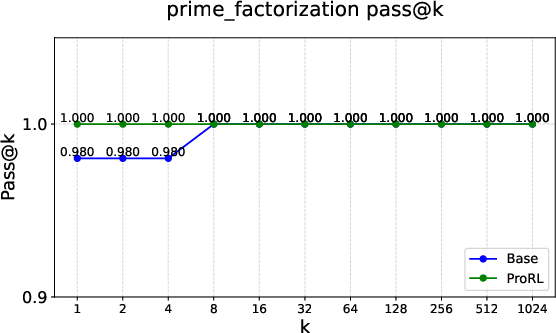
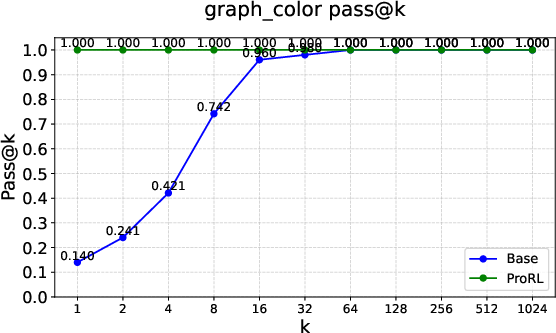
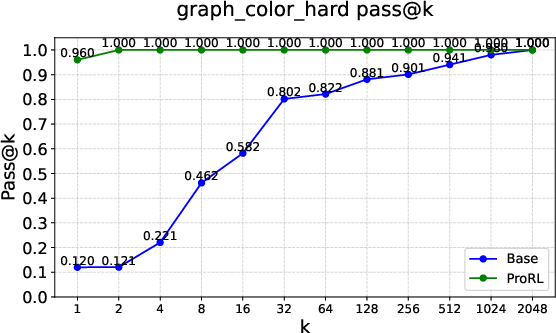
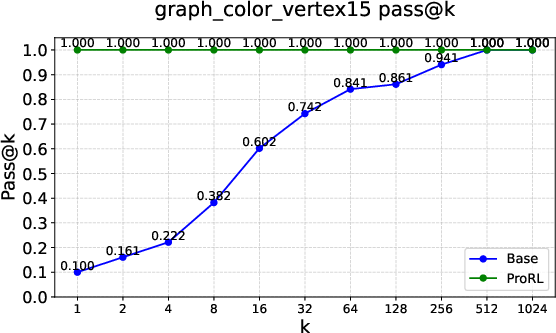
Figure 2: Pass@k curves on tasks like Graph Coloring, Palindrome Generation, and Advanced Geometry, illustrating RLVRâs typical \textcolor{blue}{empirical-support preservation}.
The paper includes a perplexity analysis that reinforces the support constraints, showing that RLVR exhibits higher perplexity when evaluated against external reasoning traces outside the base model's support. Additionally, the paper examines the entropy dynamics of RLVR, quantifying changes in the output distribution using token-level and answer-level entropy metrics. The results indicate that RLVR consistently improves accuracy while reducing answer-level entropy, suggesting a collapse onto fewer distinct solutions. Interestingly, token-level entropy exhibits more varied behavior, highlighting a decoupling between local uncertainty and global diversity.
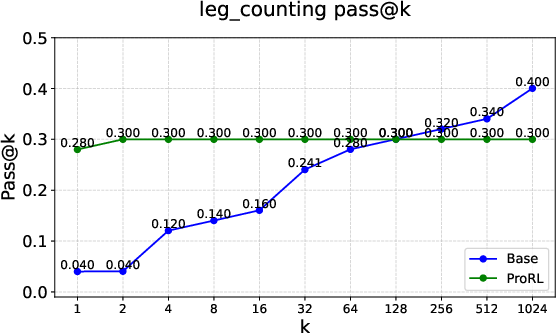
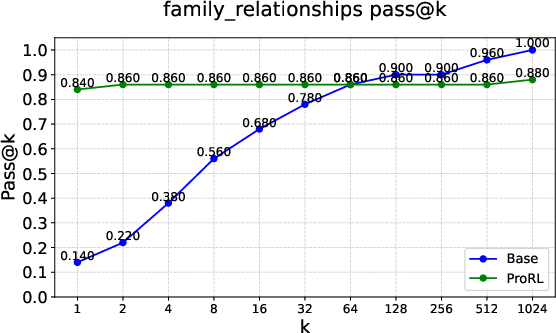
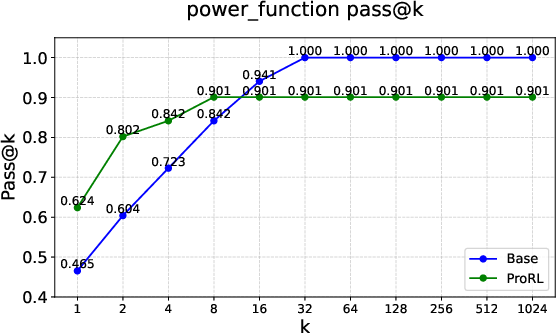
Figure 3: Examples of \textcolor{red}{empirical-support shrinkage} on Reasoning Gym tasks such as Leg Counting, Family Relationships, and Power Function.
Conclusion
The paper provides a comprehensive theoretical and empirical analysis of RLVR, revealing its limitations in expanding the reasoning horizons of LLMs. The study emphasizes that RLVR primarily acts as a conservative sampling reweighting mechanism, improving precision but largely preserving the support of the base model. The findings suggest that to expand reasoning capabilities beyond the base model’s scope, RLVR must be coupled with explicit exploration strategies or off-policy mechanisms that seed probability mass into underrepresented regions of the solution space.
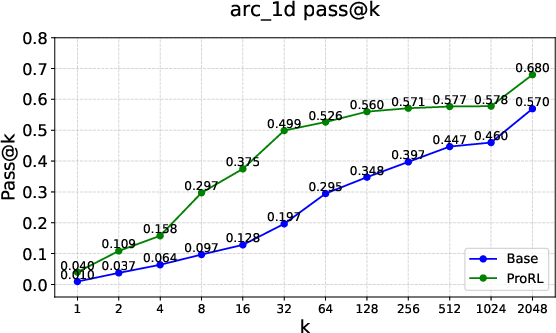
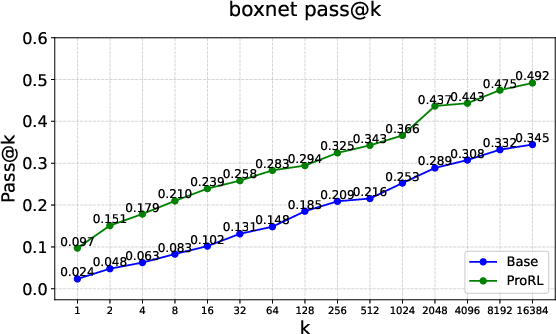
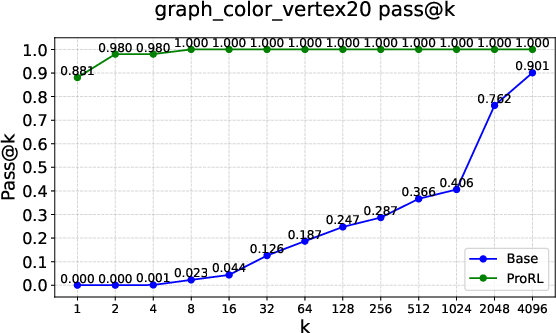
Figure 4: Rare instances of \textcolor{MyGreen}{empirical-support expansion} under RLVR, as seen in Boxnet, Dice, and Arc 1D tasks.