LFM2 Technical Report
Abstract: We present LFM2, a family of Liquid Foundation Models designed for efficient on-device deployment and strong task capabilities. Using hardware-in-the-loop architecture search under edge latency and memory constraints, we obtain a compact hybrid backbone that combines gated short convolutions with a small number of grouped query attention blocks, delivering up to 2x faster prefill and decode on CPUs compared to similarly sized models. The LFM2 family covers 350M-8.3B parameters, including dense models (350M, 700M, 1.2B, 2.6B) and a mixture-of-experts variant (8.3B total, 1.5B active), all with 32K context length. LFM2's training pipeline includes a tempered, decoupled Top-K knowledge distillation objective that avoids support mismatch; curriculum learning with difficulty-ordered data; and a three-stage post-training recipe of supervised fine-tuning, length-normalized preference optimization, and model merging. Pre-trained on 10-12T tokens, LFM2 models achieve strong results across diverse benchmarks; for example, LFM2-2.6B reaches 79.56% on IFEval and 82.41% on GSM8K. We further build multimodal and retrieval variants: LFM2-VL for vision-language tasks, LFM2-Audio for speech, and LFM2-ColBERT for retrieval. LFM2-VL supports tunable accuracy-latency tradeoffs via token-efficient visual processing, while LFM2-Audio separates audio input and output pathways to enable real-time speech-to-speech interaction competitive with models 3x larger. LFM2-ColBERT provides a low-latency encoder for queries and documents, enabling high-performance retrieval across multiple languages. All models are released with open weights and deployment packages for ExecuTorch, llama.cpp, and vLLM, making LFM2 a practical base for edge applications that need fast, memory-efficient inference and strong task capabilities.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LFM2: Fast, Smart AI That Can Run On Your Phone
What is this paper about?
This paper introduces LFM2, a family of small but powerful AI models built to run directly on everyday devices like phones, tablets, and laptops. The main goal is to make AI that is:
- fast to respond,
- careful with memory and battery,
- still good at many tasks (like following instructions, solving math problems, understanding images or audio, and retrieving information),
- and easy for developers to use.
What questions did the researchers ask?
In simple terms, they asked:
- How can we design small AI models that feel fast on real devices without losing too much accuracy?
- What model parts (the “brain wiring”) give the best mix of speed, memory use, and quality?
- How can we train small models to learn from bigger, better ones efficiently?
- Can we make versions that also understand images, speech, and search across documents?
- Can we release them with everything needed so people can actually use them on devices?
How did they do it?
To build LFM2, the team “co-designed” the AI with the hardware it runs on. Imagine building a race car while constantly test-driving it on the actual track. That’s what they did: they searched for model designs while measuring real speed and memory on phones and laptops.
Here are the key ideas, explained with everyday analogies:
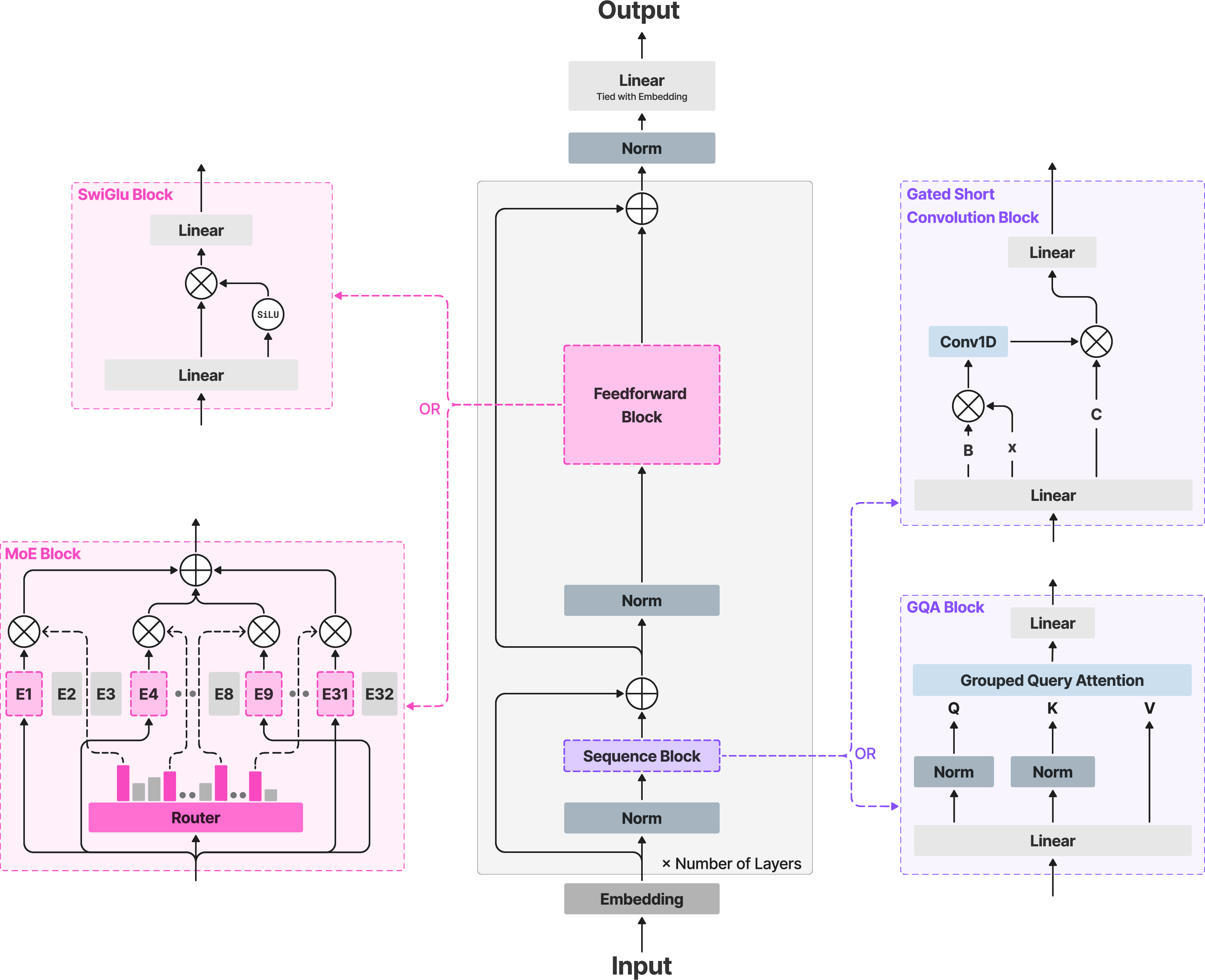
- A smarter backbone (the model’s main structure)
- Mostly short-range “conversations” with occasional long-range “shout-outs”
- Short, gated convolutions: Think of reading a sentence and focusing on nearby words very quickly.
- A few attention layers (grouped-query attention, or GQA): Now and then, the model “looks up” to connect far-apart ideas. Grouping reuses memory so it’s lighter-weight.
- This mix turned out to be fast and accurate on real devices.
- A “mixture-of-experts” option (MoE)
- Like a team of specialists: for each token (piece of text), the model picks a few experts to consult instead of all of them. That keeps it fast while boosting quality.
- Training that helps small models act big
- Huge pre-training: They trained on 10–12 trillion tokens (massive amounts of text) and taught the models to handle very long inputs (up to 32,000 tokens).
- Knowledge distillation (teacher–student learning): A larger model teaches the smaller one by sharing its top guesses. The team used a safer, improved method (decoupled Top-K) so the student learns well even when it only sees the teacher’s “top answers,” avoiding math issues that can cause bad learning signals.
- Curriculum learning: Start with easier questions, then gradually move to harder ones—like leveling up in a video game.
- Post-training in three steps:
- 1) Supervised fine-tuning: Teach the model to chat properly and follow instructions.
- 2) Preference alignment: Nudge the model to prefer helpful, high-quality answers (they normalize for length so it doesn’t just favor short replies).
- 3) Model merging: Combine the strengths of several versions to get a more robust final model.
- Multimodal and retrieval versions
- LFM2-VL (vision–language): Understands images + text with adjustable speed/accuracy trade-offs (fewer image tokens = faster).
- LFM2-Audio: Can listen and talk (speech-to-speech or speech-to-text) with very low delay, competing with models about 3× larger.
- LFM2-ColBERT: A fast search model for finding the right documents or answers in multiple languages.
- Built for real use
- The models come with open weights and deployment packs for popular runtimes like ExecuTorch, llama.cpp, and vLLM, plus quantized versions that are extra small and fast.
What did they find?
- Speed and memory wins on real devices:
- On CPUs (like in phones and laptops), LFM2 models are often up to about 2× faster than similar-sized models at both “prefill” (reading your prompt) and “decode” (generating answers).
- They’re designed to keep time-to-first-token short (the time until the first word appears) and keep latency stable.
- Strong accuracy for their size:
- They tested on many benchmarks. For example, the LFM2-2.6B model scored about 79.56% on IFEval (instruction following) and 82.41% on GSM8K (grade-school math word problems).
- The MoE model (LFM2-8B-A1B) has 8.3B total parameters but only uses about 1.5B of them at a time—achieving quality similar to 3–4B models while keeping the “cost per token” low.
- Long inputs:
- All models support 32K tokens of context, so they can handle long documents or multi-turn chats without forgetting earlier parts.
- Multimodal and retrieval models are practical:
- LFM2-VL can trade a little accuracy for a lot of speed on-device by using fewer visual tokens.
- LFM2-Audio supports real-time speech assistants and translation with low delay.
- LFM2-ColBERT provides fast, high-quality search across languages.
Why does this matter?
- Better on-device AI: Faster, smaller, and more private—your data can stay on your device, and the assistant still feels responsive.
- Real-world ready: Works well on everyday hardware, not just big servers, which makes it more accessible and energy-efficient.
- Flexible: Text, images, audio, and retrieval are all covered, so developers can build many kinds of apps—voice assistants, local copilots, reading and summarizing documents, tool use, and more.
- Open and practical: Open weights and ready-to-use deployment packages make it easier for the community to build, test, and improve on top of LFM2.
In short, LFM2 shows how careful design, training, and testing on actual devices can produce small AI models that are fast, capable, and ready for real-world use—right in your pocket.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored in the paper, phrased concretely to guide future research:
- Architecture search transparency and reproducibility: the search heuristic, candidate pool size, sampling strategy, training budget per candidate, and hypervolume computation details are not provided; release of the search code, candidate logs, and ablation results would enable replication.
- Missing ablations on block choices: no systematic comparison of gated short convolution alone vs. hybrid blocks (SSM/linear-attention/conv) under matched quality–latency–memory budgets across tasks; quantify how many global GQA layers are minimally necessary at each scale and why.
- Convolution design specifics: kernel size is fixed at k=3, but dilation/stride, causal padding, and boundary handling are not analyzed; ablate k and dilation choices against both speed and long-context quality.
- Attention configuration sensitivity: GQA groups (KV group=8) and head size (64) are fixed across sizes; study how varying group count, head size, and QK-Norm interact with throughput, memory, and retrieval-heavy benchmarks.
- RoPE + QK-Norm interplay at 32K: the stability and accuracy of RoPE with QK-Norm at 32K context are asserted but not empirically characterized across long-context tasks (needle-in-a-haystack, long-question answering, long code).
- KV-cache memory reduction claims lack numbers: peak memory (RSS) measurements during prefill/decode at 4K and 32K contexts are referenced but not reported; include exact MB/GB, allocator details, and variance across devices.
- TTFT and p50/p95 latency are not reported: while measured, tables only present throughput; provide TTFT and latency distributions (p50/p95) with confidence intervals for standardized prompts.
- Energy/thermal behavior on-device: no measurements of power draw, energy per token, or thermal throttling on smartphones/laptops; include instrumentation-based energy metrics and temperature under sustained workloads.
- NPU and heterogeneous accelerator results are absent: claims of “heterogeneous NPUs” are unaccompanied by on-device NPU benchmarks or kernel support; evaluate identical prompts on Android/iOS NPUs and common edge NPUs.
- Batch size effects: only batch=1 is considered; quantify latency/throughput and memory scaling for small batches (2–8) to support multi-agent or background tasks on-device.
- Quantization breadth: evaluation is limited to llama.cpp Q4_0; compare AWQ, GPTQ, Q8_0, int8 weight-only, fp8/bf16 paths, and per-channel quantizers for speed–quality–memory trade-offs, and report accuracy deltas.
- Cross-runtime portability: results are shown for llama.cpp only; provide parity checks across ExecuTorch and vLLM CPU backends and detail any kernel or graph compilation differences affecting performance.
- MoE on CPU is under-optimized: authors note “still room for large improvements” but do not quantify routing overheads, cache locality, or thread-level load balancing; provide profiling and kernels that minimize per-token expert dispatch overhead.
- MoE stability and routing analysis: normalized sigmoid router with adaptive biases is used, but load balancing statistics, expert utilization entropy, and failure modes (expert collapse) are not reported; include these diagnostics and mitigation ablations.
- Pre-training data transparency: the exact sources and license status for proprietary and licensed data are not enumerated; publish dataset lists, language/share breakdowns, and licensing terms for reproducibility audits.
- Decontamination parameters: semantic deduplication and decontamination are described, but similarity thresholds, embedding models, and n-gram window sizes are not specified; provide these to enable faithful reproduction.
- Multilingual coverage and evaluation: multilingual share is 20% across seven languages, but comprehensive multilingual benchmarks (e.g., XNLI, FLORES-200, multilingual math/code) and per-language accuracies are not reported; add per-language tables and error analyses.
- Code performance and FIM efficacy: the MoE model uses heavier code data and FIM (50%), yet no coding benchmark results (e.g., HumanEval, MBPP+, Cruxeval) or FIM benefit ablations are presented; quantify code generation, repair, and fill-in rates.
- Long-context mid-training benefits: 32K mid-training is claimed to help, but no controlled comparison vs. no-mid-training or shorter windows is shown; report gains on long-context tasks and any catastrophic forgetting on short-context tasks.
- Knowledge distillation (DTK) objective evaluation: the decoupled, tempered Top-K KL formulation is introduced without empirical ablations vs. standard KD/forward-KL, Top-K size (K=16/32/64), temperature sweeps, or loss weighting against NTP; provide controlled studies and calibration metrics (ECE, NLL).
- DTK support mismatch avoidance needs evidence: demonstrate that the Bernoulli mass term reliably prevents support mismatch at temperature >1 with Top-K truncation through stress tests (rare-token tails, multilingual tails).
- Curriculum learning implementation details: the difficulty predictor features, model architecture, and scheduling policy (e.g., pace and mixing) are unspecified; quantify curriculum impact via A/B tests and include ablations on ordering and pacing.
- SFT mixture’s LLM-judge bias: reliance on LLM juries for quality scoring can imprint stylistic and content biases; compare against human-rated subsets, cross-judge ensembles, and multilingual judge robustness.
- Safety and refusal behavior: refusal pattern filtering is applied, but there is no safety evaluation (e.g., jailbreak robustness, toxicity, sensitive topics, hallucination rates) or trade-off analysis with helpfulness; add standardized safety benchmarks and human red-teaming.
- Preference alignment objective is incomplete: the generalized loss is truncated in the paper; fully specify Δ and δ terms, functions f and g, normalization choices, and length normalization constants, then provide training hyperparameters and stability observations.
- Offline preference dataset composition: approximately 700k conversations are used, yet the proportion of on-policy vs. off-policy, domain distribution, and language breakdowns are not reported; include these distributions and analyze their impact on alignment.
- CLAIR incorporation details: Contrastive Learning from AI Revisions is mentioned, but the revision generation, anchor selection, and weighting strategy are not specified; ablate CLAIR’s contribution to instruction following and reasoning.
- Stage 3 model merging methodology: merging is cited without describing merge operators (e.g., weighted sum, task-space LoRA merge), selection criteria, or regression testing; document procedures and their impact on robustness.
- Tokenizer efficacy analysis: a 65,536-token byte-level BPE is trained, but per-language tokenization efficiency, code/JSON structural token coverage, and compression ratios vs. common tokenizers are not reported; provide token-per-character statistics and downstream accuracy impact.
- Tool/function calling evaluation: special tokens are included, but there is no quantitative function calling accuracy, schema adherence, argument extraction fidelity, or latency overhead for tool-use loops; add standardized tool-calling benchmarks.
- Retrieval variant (LFM2-ColBERT) details: claims of high-performance multilingual retrieval are not accompanied by metrics (MRR/NDCG@k), latency per query, index memory footprint, or cross-lingual transfer; provide benchmarks and index-building recipes.
- Vision–LLM (LFM2-VL) specifics: “token-efficient visual processing” and tunable trade-offs are asserted without detailing the connector architecture, token pruning strategy, or accuracy–latency curves on standard VLM suites (e.g., VQAv2, TextCaps, DocVQA); include these.
- Audio–LLM (LFM2-Audio) real-time claims: speech-to-speech interaction is claimed competitive with 3× larger models, but no WER, CER, latency budget, streaming chunking strategy, or MOS scores are reported; provide ASR/TTS metrics and end-to-end latency decomposition.
- Edge deployment breadth: only Android smartphone and a single laptop CPU are benchmarked; add iOS devices, diverse Android SoCs, and Windows/macOS desktops, and report OS/runtime-specific performance variability.
- Memory footprint of quantized checkpoints: quantized file sizes, peak RSS distribution, and storage/IO constraints (e.g., SD card/flash read bandwidth) on devices are not provided; include deployable artifact sizes and loading times.
- Robustness across prompts and workloads: variance across prompt shapes (code blocks, JSON, long lists) and streaming generation stability are not characterized; add stress tests and failure case catalogues.
- Carbon/compute cost of training: total GPU-hours, energy consumption, and emissions are not reported; quantify training cost to contextualize efficiency claims and facilitate responsible scaling.
- Licensing and data governance: proprietary/licensed datasets are used but not described in terms of consent, PII handling, and privacy protections; provide governance documentation and PII-memorization audits.
- Open-source assets: weights are released, but training scripts, preprocessing pipelines, curriculum scorer, DTK implementation, and deployment configs are not released; publishing these would materially improve reproducibility and community uptake.
Glossary
- Active parameters: The subset of model parameters actually used per token in a sparse architecture; reduces per-token compute vs. total parameters. "LFM2-8B-A1B (8.3B total, 1.5B active) targets the on-device regime"
- AdamW: A variant of Adam optimizer with decoupled weight decay for better generalization. "For optimization, we use the AdamW optimizer configured with β1 = 0.9, β2 = 0.95, and weight decay λ = 0.1"
- Adaptive routing biases: Adjustments to expert routing in MoE layers to balance load and improve stability. "with a normalized sigmoid router and adaptive routing biases for load balancing"
- Bernoulli: A probability distribution over two outcomes (success/failure), used here in a binary KL term. "where denotes the Bernoulli distribution with success probability ."
- bfloat16: A 16-bit floating-point format that retains exponent range of FP32 for efficient mixed-precision training. "The training utilizes mixed precision arithmetic with bfloat16 for both activations and gradients"
- Byte-level BPE tokenizer: A tokenizer that operates on bytes using Byte Pair Encoding to build subword units. "We use a byte-level BPE tokenizer~\citep{sennrich2016neural} with a 65{,}536-token vocabulary."
- CfC: Closed-form Continuous-time neural network, a Liquid-Time Constant variant for sequence modeling. "Liquid-Time Constant networks such as CfC~\citep{hasani2022closed}"
- ChatML: A conversation formatting template defining special tokens and roles for chat data. "The tokenizer includes special tokens for fill-in-the-middle training objectives \citep{bavarian2022efficient}, tool calling, and the ChatML chat template."
- CMinHash locality-sensitive hashing: An LSH technique for detecting near-duplicate text efficiently. "near-duplicate detection using CMinHash locality-sensitive hashing"
- ColBERT: A late-interaction retrieval model using token-level embeddings and max-similarity for efficient search. "LFM2-ColBERT adds a dense module on top of the backbone, yielding a low-latency encoder for both queries and documents."
- Cosine decay: A learning-rate schedule that decreases following a cosine curve. "The learning rate schedule employs cosine decay"
- Curriculum learning: Training by ordering data from easy to hard to stabilize and improve learning. "We implement a data-driven curriculum learning strategy across the entire dataset"
- Decoupled Top-K knowledge distillation: A KD objective that separates Top-K mass matching from temperature-scaled conditional KL to avoid support mismatch. "we introduce a tempered, decoupled Top-K distillation objective that avoids support mismatch."
- Decode latency: Time per generated token during inference; a key efficiency metric on-device. "p50/p95 decode latency (ms/token) at batch"
- Depthwise 1D convolution: A convolution applied independently per channel along the sequence dimension. "is a depthwise 1D convolution along the sequence with kernel size "
- Direct alignment: Preference optimization methods that directly optimize policy to match chosen responses without RL rollouts. "We leverage direct alignment methods to achieve a strong trade-off between model capabilities and iteration speed."
- ExecuTorch: A deployment runtime for running neural networks efficiently on edge devices. "deployment packages for ExecuTorch, llama.cpp, and vLLM"
- Fill-in-the-middle (FIM) objective: A code training objective predicting a missing middle segment given prefix and suffix. "For code data, 50\% of examples use a fill-in-the-middle (FIM) objective~\citep{bavarian2022efficient}."
- Gated short convolution block: A local mixing operator applying input-dependent gates around a small-kernel depthwise convolution. "each gated short convolution block applies input-dependent multiplicative gating around a depthwise short convolution"
- Grouped-query attention (GQA): An attention variant that shares keys/values across groups while keeping multiple query heads to reduce KV traffic. "grouped-query attention (GQA)~\citep{ainslie2023gqa} with varying group counts and head dimensions"
- Hypervolume improvement: A multi-objective ranking metric measuring improvement of a solution’s Pareto hypervolume. "The remaining candidates are ranked by hypervolume improvement on the quality–latency–memory Pareto frontier."
- KV-cache: Cached keys and values from prior tokens used to speed up autoregressive decoding. "lower peak RSS at long context (4K/32K), consistent with reduced KV-cache versus attention-heavy layouts."
- Late-interaction paradigm: Retrieval approach computing token-level similarities at query time rather than early aggregation. "It follows a late-interaction paradigm that uses a max-similarity operator"
- Liquid-Time Constant networks: Continuous-time neural architectures with adaptable time constants for sequence processing. "Liquid-Time Constant networks such as CfC~\citep{hasani2022closed}"
- LLM jury: An ensemble or judge LLMs used to score and select preferred responses in preference datasets. "We then score individual responses via an LLM jury"
- Long-context mid-training: A training phase using extended context windows to adapt models for long sequences. "We then perform a mid-training phase on an additional 1T higher-quality tokens, including sources with naturally long context, using a 32,768-token context window"
- Mamba: A state space model architecture for efficient sequence modeling. "Mamba~\citep{gu2022efficiently}, and Mamba2~\citep{dao2024transformers}"
- Mamba2: A refined Mamba variant with improved efficiency and capabilities. "Mamba2~\citep{dao2024transformers}"
- Mixture-of-Experts (MoE): An architecture that routes tokens to a subset of expert modules to increase capacity at fixed compute. "an MoE variant (LFM2-8B-A1B) cover a range of quality-latency-memory targets"
- Off-policy responses: Preference or instruction data not generated by the current model, used to diversify alignment. "on-policy samples generated from the SFT checkpoint and off-policy reference responses"
- On-policy samples: Data generated by the current model used to align it to its own distribution. "on-policy samples generated from the SFT checkpoint"
- Pareto optimization: Multi-objective optimization aiming for non-dominated solutions across competing metrics. "We frame architecture selection as a Pareto optimization over three axes:"
- Peak memory (RSS): Maximum resident set size; the peak memory footprint during inference. "Peak memory: measured as maximum resident set size (RSS) during prefill and decode"
- Preference alignment: Post-training step optimizing model outputs to match preferred responses. "Preference Alignment: Enabling efficient preference optimization through direct alignment"
- Prefill throughput: Tokens processed per second when ingesting the prompt before generation. "prefill throughput (tokens/s) on representative prompts."
- Q4_0 quantization: A 4-bit quantization scheme used in llama.cpp for efficient CPU inference. "All models are run with llama.cpp~\citep{gerganov_llama_cpp} using the Q4_0 quantization format."
- QK-Norm: Normalization applied to queries and keys to stabilize attention scaling. "augmented with QK-Norm~\citep{dehghani2023scaling}."
- Retrieval-Augmented Generation (RAG): Technique that injects retrieved context into generation to improve factuality and recall. "retrieval augmented generation (RAG)"
- RoPE: Rotary position embeddings that encode relative positions via complex rotations in attention. "attention blocks use RoPE~\citep{su2024roformer}"
- RMSNorm: Root Mean Square LayerNorm variant with simpler statistics and pre-norm application. "All layers use pre-norm RMSNorm~\citep{zhang2019root}"
- SigLIP2: A vision encoder (Successor to SigLIP) used for vision–language integration. "LFM2-VL, augments the language backbone with a SigLIP2~ \citep{tschannen2025siglip} vision encoder"
- State space models (SSMs): Sequence models using linear dynamical systems for long-range dependencies with sub-quadratic compute. "state space models (SSMs)~\citep{dao2024transformers, yang2025gated}"
- SwiGLU: A gated feed-forward activation combining SiLU and GLU for efficient MLPs. "Position-wise MLPs use SwiGLU~\citep{shazeer2020glu}"
- Time-to-first-token (TTFT): Latency from request to the first generated token; crucial for user-perceived responsiveness. "time-to-first-token (TTFT)"
- Top-k experts: The subset of MoE experts selected per token based on routing scores. "selects the Top-k experts per token"
- Top-K set: The top-K tokens/logits retained from a teacher distribution for efficient distillation. "using only the Top-K teacher logits per token"
- vLLM: A high-throughput inference engine supporting batching and efficient memory management. "vLLM for single-request and online batching"
- ZeRO-2 sharding: Distributed training technique that shards optimizer states and gradients to reduce memory. "The distributed training infrastructure leverages ZeRO-2 sharding"
Practical Applications
Immediate Applications
Below are applications that can be deployed with the released LFM2 models and toolchains (open weights, quantized variants, and deployment packages for ExecuTorch, llama.cpp, and vLLM). Each bullet highlights sectors, potential products/workflows, and practical caveats.
- On-device private chat assistants
- Sectors: software, consumer electronics, enterprise IT, public sector
- What to build: privacy-preserving mobile and laptop assistants that run fully offline with fast TTFT and stable token latency; MDM-provisioned enterprise copilots that summarize documents locally (32K context), draft emails, and answer FAQs without sending data to cloud
- Tools/workflows: LFM2-700M/1.2B for phones; LFM2-2.6B or LFM2-8B-A1B for laptops; llama.cpp Q4_0 quantization; tool-calling via SFT/post-training hooks
- Assumptions/dependencies: device CPU budget, proper prompt templates (ChatML), guardrails; for MoE, current CPU kernels are improving—expect best latency on dense models
- Real-time speech assistant and transcription/translation
- Sectors: accessibility, customer support, education, field operations
- What to build: on-device speech-to-text note-takers, live captioning/translation for meetings and classrooms, customer-service kiosks that run offline; speech-to-speech dialogs using LFM2-Audio’s discrete audio tokens
- Tools/workflows: LFM2-Audio with separate audio input/output paths; streaming decode; voice activity detection; optional RAG for context
- Assumptions/dependencies: a compatible neural codec/vocoder pipeline for audio token synthesis; on-device mic/speaker I/O latency; safety filters for open mics
- On-device document and scene understanding
- Sectors: finance, logistics, retail, education, automotive, public sector
- What to build: mobile OCR and form understanding for receipts/invoices (PII stays on device), shelf-label checkers, driver-assist captioning, study aids that explain textbook figures
- Tools/workflows: LFM2-VL with SigLIP2 vision encoder; tunable token-efficient visual processing for accuracy/latency trade-offs; post-processing for structured JSON
- Assumptions/dependencies: camera pipeline; domain-tuned prompts; quality varies with lighting and document quality; consider LFM2-Nanos for data extraction
- Local semantic search and RAG
- Sectors: enterprise IT, legal, healthcare, research, government
- What to build: offline knowledge copilots that index personal or departmental documents and answer questions with citations; multilingual intranet search
- Tools/workflows: LFM2-ColBERT for low-latency query/doc encoders; late-interaction retrieval with max-sim operator; small local indexes on device; RAG orchestration with the LFM2 LLM
- Assumptions/dependencies: index building pipeline; storage footprint of late-interaction indexes; freshness/update workflow; domain safety and access controls
- Developer-local coding assistants
- Sectors: software engineering, DevOps, data science
- What to build: on-laptop code copilots that suggest snippets, explain diffs, and draft tests without sending source to cloud; CLI bots that summarize logs
- Tools/workflows: LFM2-1.2B/2.6B or 8B-A1B for improved code comprehension; long-context window for multi-file repositories; tool calling to run linters/tests
- Assumptions/dependencies: repository indexing; instruction-tuned prompts; guardrails to avoid unsafe code suggestions
- Edge agent loops with tools and sensors
- Sectors: robotics, IoT, manufacturing, agriculture
- What to build: local agents that read sensors, plan simple tasks, call functions, and operate in tight latency loops; voice-controlled robots in connectivity-constrained settings
- Tools/workflows: small LFM2 (350M/700M) for embedded CPUs; function/tool calling from post-training; deterministic execution budget; structured outputs (JSON)
- Assumptions/dependencies: robust tool schemas; safety interlocks; deterministic scheduling; bounded action spaces
- Multilingual assistants for low-connectivity contexts
- Sectors: humanitarian aid, public sector, travel, education
- What to build: offline translation and Q/A across Arabic, Chinese, French, German, Japanese, Korean, Spanish; field guides and compliance checkers in multiple languages
- Tools/workflows: multilingual coverage from tokenizer and training mix; retrieval for domain content; length-normalized alignment improves consistency for longer replies
- Assumptions/dependencies: domain adaptation for specialized terminology; cultural/safety review of outputs
- Privacy-first data extraction on mobile
- Sectors: finance (KYC), insurance, logistics, healthcare admin
- What to build: on-device extraction of names, totals, policy numbers, shipment IDs from photos/PDFs; auto-filling forms
- Tools/workflows: LFM2-VL or LFM2-Nanos specialized for extraction; JSON-constrained generation; post-validation rules
- Assumptions/dependencies: document format variance; error handling and human-in-the-loop verification for critical workflows
- Academic/industrial training efficiency improvements
- Sectors: ML research, model productization
- What to build: small-model distillation pipelines that only store Top-K teacher logits; curriculum learning that orders data by empirical difficulty for better SFT
- Tools/workflows: decoupled, tempered Top-K KD objective to avoid support mismatch; difficulty ordering via ensemble scoring; mid-training long-context stage
- Assumptions/dependencies: availability of teacher checkpoints; logging of Top-K logits in data pipelines; evaluation to tune temperature and Top-K
- Secure meeting and document summarization
- Sectors: legal, finance, defense, healthcare
- What to build: laptop-local summarizers of lengthy contracts, board decks, and multi-hour transcripts using 32K context, ensuring data stays under org control
- Tools/workflows: LFM2-2.6B/8B-A1B; chunking + retrieval; templated summaries with citations
- Assumptions/dependencies: long-context memory and power budgets; citation integrity checks; redaction policies
Long-Term Applications
These opportunities likely require further research, domain validation, optimized kernels/NPUs, or regulatory approvals before broad deployment.
- Certified on-device medical scribe and triage assistant
- Sectors: healthcare
- What to build: ambient clinical documentation and triage suggestions entirely on clinician devices; integration with local EHR retrieval (LFM2-ColBERT)
- Dependencies: clinical validation, FDA/CE approvals, robust hallucination mitigation, domain-tuned safety; higher-accuracy speech and medical NER
- In-car offline multimodal copilot
- Sectors: automotive, mobility
- What to build: camera-aware assistant that explains dash warnings, reads signs, controls infotainment by voice, and summarizes trips offline
- Dependencies: optimized NPU/CPU kernels for continuous vision + speech; automotive-grade safety; robust wake-word VAD; low-power operation
- Smart glasses and assistive vision
- Sectors: accessibility, consumer electronics, industrial safety
- What to build: on-device captioning, text-to-speech guidance for the visually impaired, and real-time instruction following for assembly tasks
- Dependencies: efficient continuous LFM2-VL streaming; battery/thermal constraints; domain-specific models for low-vision contexts
- Enterprise-wide multilingual retrieval + edge RAG
- Sectors: enterprise IT, legal, public sector
- What to build: secure BYOD knowledge search with on-device query encoding and confidential client-side RAG grounded in local indexes
- Dependencies: index compression and synchronization at scale; access control, auditing; robust multi-tenant policy enforcement
- Federated or on-device continual learning
- Sectors: healthcare, finance, consumer apps
- What to build: client-side preference alignment or personalization updates without centralizing data; privacy-preserving aggregation
- Dependencies: safe on-device fine-tuning (PEFT/LoRA) within power/memory budgets; drift detection; DP guarantees; lifecycle tooling
- CPU-optimized MoE assistants
- Sectors: software, enterprise, robotics
- What to build: 1.5B-active-parameter MoE (8B total) assistants with 3–4B-class quality but mobile-class latency
- Dependencies: significantly improved CPU MoE kernels, routing efficiency, memory locality; NPU offload paths
- On-device safety moderation and audit trails
- Sectors: policy/compliance, platforms
- What to build: client-side content filters, refusal classification, and immutable audit logs to meet data-minimization norms
- Dependencies: calibrated safety classifiers; on-device cryptographic logging; policy updates distribution
- Cross-modal sensor fusion agents
- Sectors: robotics, smart homes, industrial IoT
- What to build: agents that jointly process audio, images, and tabular sensor feeds to plan and act locally
- Dependencies: steady-state latency across modalities; task-specific datasets; formal verification for critical operations
- Domain marketplaces of LFM2-Nanos
- Sectors: finance, law, logistics, education, security
- What to build: curated, small, domain-tuned variants (extraction, math, tool use) with signed performance profiles and deployment recipes
- Dependencies: evaluation standards; licensing and update channels; reproducible post-training/merging pipelines
- Privacy-by-design public services
- Sectors: government, NGOs
- What to build: field translators, FOIA summarizers, and regulatory checkers that run fully offline on standard-issue devices
- Dependencies: language coverage expansion; public-data decontamination; procurement and accessibility compliance
- High-fidelity speech-to-speech with expressive prosody
- Sectors: media/localization, education, accessibility
- What to build: on-device S2S assistants that preserve speaker identity, emotion, and prosody across languages
- Dependencies: advanced discrete audio tokenizers and neural vocoders; bias/consent controls; robust latency under prosody modeling
- Energy-aware edge analytics for smart grids and remote sites
- Sectors: energy, mining, maritime
- What to build: localized anomaly explanation and instruction following for operators without connectivity
- Dependencies: power-aware scheduling; ruggedized hardware; domain RAG and incident taxonomies
Notes on feasibility and adoption
- Deployment stacks: immediate paths via ExecuTorch and llama.cpp on CPU; NPU acceleration would further reduce latency/power but may require vendor-specific kernels.
- Model selection: choose by device and task—350M/700M for embedded/phones, 1.2B/2.6B for higher quality on laptops, 8B-A1B when MoE kernels mature or where storage is available and active-parameter cost dominates latency.
- Safety and alignment: length-normalized preference alignment and merging help, but high-stakes domains require additional domain tuning, adversarial evaluation, and human oversight.
- RAG quality: late-interaction retrieval (ColBERT) boosts precision but index footprint and refresh cadence must be engineered for each device class.
- Audio and vision: real-time S2S and streaming VLM require careful pipeline engineering (VAD, chunking, async I/O) and, for S2S, a vocoder compatible with discrete audio tokens.
Collections
Sign up for free to add this paper to one or more collections.

