- The paper demonstrates that SOTA embedding performance is achieved using only 6 million open-source, non-synthetic data samples.
- It introduces a simplified, single-stage finetuning pipeline leveraging hard negative mining and in-batch contrastive loss.
- Empirical results on MTEB reveal that F2LLM models excel in clustering and resource efficiency across various model sizes.
F2LLM: Efficient State-of-the-Art Embedding Models with Open-Source Data
Overview and Motivation
The F2LLM technical report presents a family of embedding models—Foundation to Feature LLMs (F2LLM)—that achieve state-of-the-art (SOTA) performance on the Massive Text Embedding Benchmark (MTEB) using only 6 million open-source, non-synthetic training samples. The work addresses two major limitations in the current embedding model landscape: the reliance on large-scale synthetic data and complex multi-stage training pipelines, and the lack of reproducibility due to closed-source data and code. F2LLM demonstrates that competitive embedding performance can be achieved with a streamlined, fully open-source approach, providing a strong baseline for both academic and industrial applications.
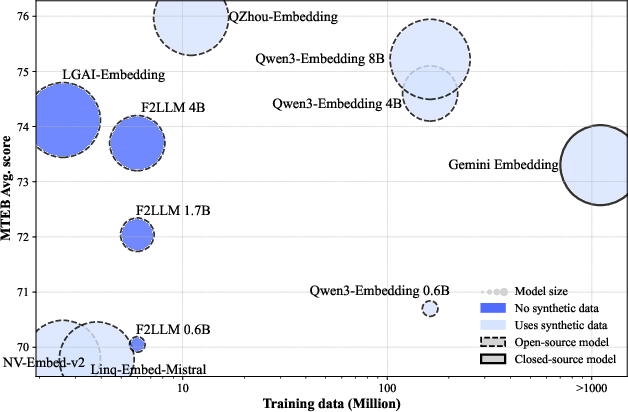
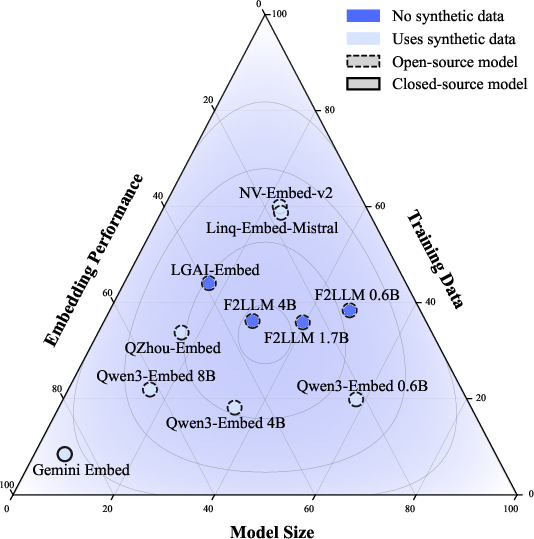
Figure 1: (Left) MTEB performance comparison between LLM-based embedding models. (Right) F2LLM achieves a strong balance between embedding performance, training data, and model size, using only open-source non-synthetic data.
Recent advances in LLM-based embedding models have been driven by large-scale contrastive pretraining, often involving hundreds of millions of weakly supervised or synthetic samples, and multi-stage pipelines that blend retrieval, classification, and clustering objectives. Notable models such as GTE, BGE-M3, NV-Embed, and Qwen3-Embedding have set new benchmarks but at the cost of significant computational and data resources, and often with limited reproducibility due to proprietary data or code. Some recent efforts (e.g., LGAI-Embedding) have shown that careful curation of open-source datasets can rival synthetic data approaches, but these remain exceptions.
F2LLM distinguishes itself by:
- Eschewing synthetic data entirely in favor of a large, diverse, open-source dataset.
- Employing a single-stage finetuning pipeline directly from foundation models, without architectural modifications or input format changes.
- Fully releasing model checkpoints, training data, and code, ensuring reproducibility and transparency.
Data Curation and Preprocessing
F2LLM's training corpus comprises 6 million (query, positive, hard negative) tuples, unified across retrieval, classification, and clustering tasks. The data is sourced from a wide array of open datasets, including MTEB, and is decontaminated to avoid test set leakage. The retrieval data is constructed by mining hard negatives using the Sentence Transformers library and Qwen3-Embedding-0.6B as the retriever, with careful filtering to avoid false negatives and ensure challenging negative samples. For classification and clustering, positive and negative pairs are constructed following established best practices, with task-specific instructions prepended to queries to enable multitask learning.
The unified data format and instruction-based queries facilitate efficient multitask training and ensure that the model can generalize across diverse embedding tasks.
Training Pipeline and Loss Functions
F2LLM models are finetuned from Qwen3 foundation models in three sizes: 0.6B, 1.7B, and 4B parameters. The training objective is a sum of hard negative contrastive loss and in-batch contrastive loss:
- Hard Negative Loss: For each query, the model maximizes the similarity to the positive and minimizes it to up to 24 hard negatives, using a temperature-scaled softmax over cosine similarities.
- In-Batch Loss: For retrieval tasks, the model also maximizes the similarity between each query and its positive within the batch, treating other positives as additional negatives.
A custom multitask dataloader ensures that each micro-batch contains samples from a single data source, enabling efficient computation of in-batch loss for retrieval and hard negative loss for all tasks. The models are trained for two epochs with AdamW, cosine learning rate decay, ZeRO stage 2, Flash Attention 2, and gradient checkpointing to optimize memory usage and throughput.
Empirical Results
F2LLM models are evaluated on 41 English tasks from MTEB, covering retrieval, classification, clustering, semantic textual similarity, and summarization. The key findings are:
- F2LLM-4B ranks 2nd among models of similar size and 7th overall on the MTEB leaderboard, despite being trained on orders of magnitude less data than most competitors.
- F2LLM-1.7B achieves the highest score among all models in the 1B–2B parameter range.
- F2LLM-0.6B is 2nd among sub-1B models.
- Clustering performance is particularly strong, with F2LLM-4B setting a new record (68.54) among all models.
- The models achieve a favorable trade-off between performance, data efficiency, and model size, as visualized in Figure 1.
Practical and Theoretical Implications
F2LLM demonstrates that SOTA embedding performance is attainable without reliance on synthetic data or complex multi-stage pipelines. This has several implications:
- Reproducibility: The full release of data, code, and models enables rigorous benchmarking and fair comparison in future research.
- Accessibility: The 1.7B and 0.6B models provide strong performance for resource-constrained environments, broadening the applicability of high-quality embeddings.
- Data Efficiency: The results challenge the prevailing assumption that massive synthetic datasets are necessary for SOTA performance, suggesting that careful curation and hard negative mining from open data can suffice.
- Simplicity: The single-stage finetuning approach reduces engineering complexity and training cost, making it easier to adapt or extend the models for new domains or languages.
Future Directions
The F2LLM approach opens several avenues for further research:
- Multilingual and cross-lingual extensions: Applying the same methodology to non-English or multilingual datasets.
- Domain adaptation: Investigating the transferability of F2LLM embeddings to specialized domains (e.g., biomedical, legal).
- Instruction tuning: Exploring more sophisticated instruction engineering or dynamic task conditioning to further improve multitask generalization.
- Scaling laws: Systematic study of the relationship between data quality, data quantity, and model size in embedding performance.
Conclusion
F2LLM establishes a new paradigm for efficient, reproducible, and high-performing embedding models by leveraging only open-source, non-synthetic data and a streamlined training pipeline. The strong empirical results, especially in clustering and across model sizes, underscore the viability of this approach as a robust baseline for future embedding research and deployment. The full release of models, data, and code will facilitate further advances in the field and promote more transparent and accessible development of embedding technologies.