AutoNeural: Co-Designing Vision-Language Models for NPU Inference
Abstract: While Neural Processing Units (NPUs) offer high theoretical efficiency for edge AI, state-of-the-art Vision--LLMs (VLMs) tailored for GPUs often falter on these substrates. We attribute this hardware-model mismatch to two primary factors: the quantization brittleness of Vision Transformers (ViTs) and the I/O-bound nature of autoregressive attention mechanisms, which fail to utilize the high arithmetic throughput of NPUs. To bridge this gap, we propose AutoNeural, an NPU-native VLM architecture co-designed for integer-only inference. We replace the standard ViT encoder with a MobileNetV5-style backbone utilizing depthwise separable convolutions, which ensures bounded activation distributions for stable INT4/8/16 quantization. Complementing this, our language backbone integrates State-Space Model (SSM) principles with Transformer layers, employing efficient gated convolutions to achieve linear-time complexity. This hybrid design eliminates the heavy memory I/O overhead of Key-Value caching during generation. Our approach delivers substantial efficiency gains, reducing quantization error of vision encoder by up to 7x and end-to-end latency by 14x compared to conventional baselines. The AutoNeural also delivers 3x decoding speed and 4x longer context window than the baseline. We validate these improvements via a real-world automotive case study on the Qualcomm SA8295P SoC, demonstrating real-time performance for cockpit applications. Our results highlight that rethinking model topology specifically for NPU constraints is a prerequisite for robust multi-modal edge intelligence.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows how to redesign a vision–LLM (a model that understands pictures and text together) so it runs fast and reliably on the small AI chips inside cars and phones. These chips are called NPUs (Neural Processing Units). The new model is called AutoNeural. It’s built to work with the way NPUs like to compute: using small whole numbers (integers) and low memory traffic. The result is a model that keeps good accuracy but is much faster and more stable on real devices, especially for in-car assistants.
The main questions the paper asks
- Why do today’s vision–LLMs, usually built for GPUs (the big chips in servers), run slowly or break when moved to NPUs in edge devices?
- Can we change the model’s design so it:
- Handles low-precision numbers (like 4-bit or 8-bit) without losing accuracy?
- Reduces waiting time before the first response appears?
- Uses less memory while generating text, so the NPU isn’t slowed down by constant memory access?
- Will these changes still keep the model smart enough for real automotive tasks?
How the researchers approached it
To understand their choices, here are the key ideas explained with plain language:
Why NPUs require a different design
- Think of an NPU as a very fast calculator that loves doing the same simple operation many times on small whole numbers (like 4-bit or 8-bit integers). It’s great at math but slower when it has to keep running back and forth to memory to fetch data.
- Many modern models use “attention” everywhere (in both vision and language parts), which often:
- Struggle when numbers are shrunk to low-precision (called quantization).
- Constantly read and write big “notes” about what’s been seen so far (called the KV cache), which costs a lot of time moving data in and out of memory.
Two model changes that make a big difference
- Replacing the Vision Transformer (ViT) with a MobileNet-style vision encoder
- ViTs let every patch of an image “talk to” every other patch (global attention). That’s powerful but slow and not friendly to low-precision numbers.
- Instead, AutoNeural uses depthwise separable convolutions (from MobileNet). Imagine sliding a small window across the image and processing small parts at a time. This:
- Is much cheaper for NPUs.
- Keeps the “activation values” more stable, so shrinking numbers to 8-bit or 16-bit works well.
- They also fuse information at multiple scales and turn a 768×768 image into just 256 “visual tokens,” which cuts the time spent preparing the text model.
- Mixing Transformers with State-Space Model (SSM) layers in the language part
- Transformers are great at reasoning but can be memory-hungry because they keep long histories (KV caches).
- SSM/gated-convolution layers work more like keeping a running summary of the past. They update a compact “state” instead of reading everything again. This makes text generation faster and uses much less memory.
- AutoNeural combines both: 10 lightweight SSM/gated-convolution layers + 6 attention layers. You still get strong reasoning, but with much less memory traffic.
A small but important piece: the connector
- A tiny 2-layer MLP (a simple neural network) connects vision features to the LLM.
- They purposely avoid certain layers (like RMSNorm) here because those can cause problems when using fixed, low-precision numbers on NPUs.
Training and data
- Training happens in stages, starting simple and getting more complex:
- Learn basic image–text matching.
- Train on general visual tasks (like answering questions about images).
- Practice instruction following (explaining charts, documents, diagrams, OCR).
- Finish with quantization-aware training (teach the model while already using low-precision numbers) plus a custom 200,000-sample automotive dataset for real cockpit tasks such as:
- AI Sentinel: spot damage or threats to a parked car.
- AI Greeter: recognize known people and help unlock the car.
- AI Car Finder: read parking signs and help owners find their car.
- Safety checks: spot hazards when getting in or out.
Deployment setup (what runs on the chip)
- Vision runs with 8-bit weights and 16-bit activations (W8A16).
- Language runs with 4-bit weights and 16-bit activations (W4A16).
- All tests were done on an actual automotive chip: Qualcomm SA8295P NPU.
What they found and why it matters
Here are the big results:
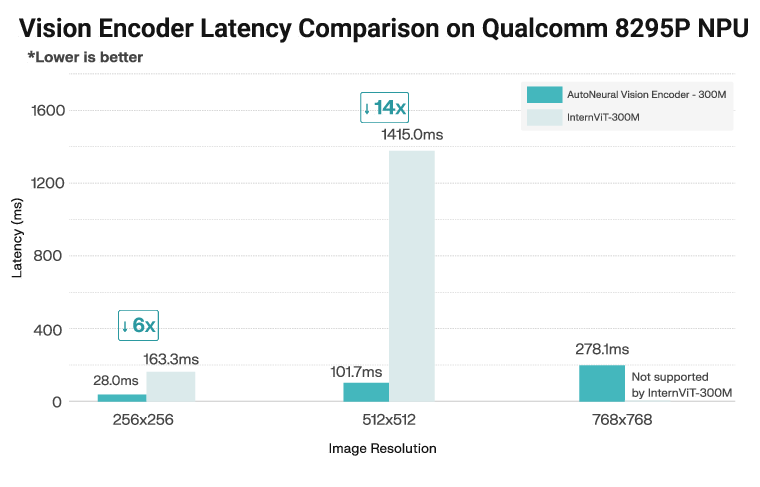
- Much faster in practice:
- Up to 14× lower end-to-end latency than standard ViT + Transformer models on the same NPU.
- About 3× faster text decoding speed.
- Lower time-to-first-token (the model starts replying much sooner), which feels more responsive.
- More stable with low-precision numbers:
- Up to 7× lower quantization error in the vision encoder.
- For the LLM, quality barely changes when weights are shrunk to 4-bit.
- Less memory pressure during generation:
- Up to 60% less memory bandwidth use because most layers don’t need heavy attention history reads/writes.
- Longer memory for context:
- About 4× longer context window, so it can handle longer inputs or conversations.
- Real-world win:
- The model processes large images (768×768) in real time on the car NPU, which is crucial for reading dashboard symbols, traffic signs, or parking information. A similarly sized ViT often runs out of memory or is too slow at these resolutions.
- Accuracy is competitive:
- On standard multimodal tests, AutoNeural performs close to or better than several models of similar or larger size designed for GPUs, while being much faster on NPUs. In short: small speed-focused changes didn’t ruin its smarts.
Why this research is important
- For cars and phones, speed and reliability matter as much as accuracy. Drivers can’t wait seconds for help, and devices have strict power and memory limits.
- This paper shows a clear recipe: if you co-design the model with the NPU in mind (choose ops that like integers and avoid memory-heavy patterns), you can get the best of both worlds—fast and capable.
- Beyond cars, the same idea applies to any edge AI: smart home devices, AR glasses, robots, and more. Rethinking model structure for the hardware unlocks practical, real-time AI without needing a big server GPU.
Quick glossary (in plain words)
- NPU: A chip that’s very good at doing lots of simple math with small numbers quickly and efficiently.
- Quantization: Shrinking numbers (like rounding) so the model uses fewer bits (e.g., 8-bit or 4-bit) and runs faster.
- Vision Transformer (ViT): A vision model that uses “attention” so every image patch can interact with all others; powerful but heavy.
- Depthwise separable convolution: A lightweight way to process images by focusing on small local areas efficiently.
- Transformer attention + KV cache: During text generation, Transformers keep a “notebook” of what’s been said (keys and values). Reading that notebook repeatedly slows things down.
- SSM/gated convolution: Keeps a compact running summary instead of a huge notebook, which speeds up generation.
- Time-To-First-Token (TTFT): How long you wait before the model starts responding. Lower is better.
- W8A16, W4A16: Short for “weights 8-bit, activations 16-bit” and “weights 4-bit, activations 16-bit”—ways of running the model with small numbers to go faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research:
- Quantized accuracy reporting: Benchmark results are presented in full precision; task-level accuracy under on-device mixed-precision settings (e.g., vision W8A16 and language W4A16) is not reported for MMStar, HallusionBench, MathVista_MINI, AI2D_TEST, and OCRBench. Provide quantized accuracy deltas relative to FP baselines on-device.
- Domain-specific evaluation: The automotive dataset (AI Sentinel, Greeter, Car Finder, Safety) lacks end-to-end task metrics (e.g., detection/identification recall/precision, false alarm rates, latency budgets per scenario). Add scenario-specific KPIs and stress testing under adverse conditions.
- Hardware portability: Validation is limited to Qualcomm SA8295P. Assess portability across other NPUs (Apple ANE, MediaTek APU, Huawei Ascend, NVIDIA DLA) with different operator sets, integer precisions, SRAM hierarchies, and compiler stacks; quantify performance, quantization robustness, and feature parity.
- Energy and thermal characterization: No measurements of power, energy per inference/token, or thermal behavior. Report watts, joules per image and per generated token, and thermal throttling thresholds under continuous operation.
- Memory I/O profiling methodology: The claimed 60% memory bandwidth reduction during generation lacks instrumentation details. Provide per-layer memory traffic, cache traces, and measurement methodology (counters, profilers, tooling) to enable replication.
- SSM–Transformer layer ratio: The fixed 10 SSM / 6 attention layer split is not justified. Perform architecture search across ratios and layer placements; quantify impacts on decode throughput, TTFT, reasoning accuracy, and quantization stability.
- Sparse MQA bottleneck ablation: The vision encoder introduces sparse MQA bottlenecks but lacks ablations on their presence, sparsity configuration, and head count. Evaluate their contribution to accuracy, latency, and quantization sensitivity.
- Normalization choice under quantization: RMSNorm is cited as brittle, yet it is used in MSFA and the language backbone. Systematically compare RMSNorm vs LayerNorm, ScaleNorm, batch/group norms, or norm-free designs under integer-only constraints for both vision and language components.
- Vision–language connector design space: The MLP-only connector (without normalization) is motivated by quantization robustness, but alternatives are not explored. Compare cross-attention, low-rank adapters, gated MLPs, and normalized projectors under NPU quantization.
- Visual token budgeting: The choice of 256 visual tokens (16×16) is not justified. Ablate token counts, downsampling strides, and MSFA fusion strategies; analyze trade-offs for fine-grained tasks (e.g., OCR) vs TTFT and NPU memory footprint.
- Long-context capability verification: The claimed 4× larger context window (4096 vs 1024) is not evaluated on long-context multimodal tasks (multi-image threads, long documents, extended dialogs). Provide accuracy vs context length curves and failure modes.
- KV cache handling in hybrid model: While most layers avoid KV caching, 6 attention layers still require KV. Quantify KV cache size, bandwidth, and latency; compare with paged/block KV compression, rotary cache pruning, and attention sinks under NPU constraints.
- Quantization details and sensitivity: The QAT/calibration pipeline lacks specifics (per-channel vs per-tensor scales, clipping strategies, activation observers, calibration set composition). Release configuration and analyze sensitivity to calibration data selection.
- Integer-only operator coverage: Clarify whether all activations and nonlinearities (e.g., GELU(tanh) variants, RMSNorm) are executed via integer kernels on SA8295P, and quantify any FP fallbacks. Provide operator-wise mapping and performance impact of fallbacks.
- Reproducibility and availability: The proprietary automotive dataset is not released; model checkpoints and deployment scripts are not referenced. Provide release plans or surrogate datasets, seeds, training budgets, and NPU compilation artifacts to enable independent validation.
- Safety and reliability testing: No quantitative safety assessment (e.g., miss/false-alarm rates under edge cases, time-to-warning constraints, user intervention success rates). Establish safety metrics and conduct stress tests across illumination, temperature, vibration, and occlusion.
- Bias and fairness analysis: The dataset spans diverse demographics but lacks fairness reporting. Evaluate performance stratified by age, gender, skin tone, and attire for identity recognition and driver monitoring; implement and measure bias mitigation strategies.
- Camera and sensor variability: Robustness to camera intrinsics/extrinsics, lens distortion, noise, HDR pipelines, and ISP variations is untested. Provide cross-sensor generalization experiments and calibration/adaptation methods.
- Multimodal fusion beyond images: Real cockpit systems often require audio, depth, radar, or CAN bus signals. Investigate co-design for multi-sensor fusion under integer-only constraints and quantify NPU resource trade-offs.
- Quantization-induced failure analysis: Provide qualitative/quantitative error audits linking mispredictions to specific layers or operators post-quantization; propose targeted mixed-precision upgrades where they yield maximal accuracy per latency cost.
- Adversarial robustness and privacy: Identity recognition and driver monitoring introduce security/privacy risks. Evaluate physical adversarial attacks (patches, occlusions), spoofing, and privacy-preserving deployment (on-device only, encrypted buffers) under NPU constraints.
- Baseline optimization parity: Ensure ViT–Transformer baselines are equally optimized for NPU (operator fusion, tiling, scheduling). Re-run comparisons with NPU-friendly ViT variants to rule out unfairness due to suboptimal compilation.
- Runtime scheduling transparency: The paper references NPU-aware scheduling without specifying tiling strategies, buffer sizing, double-buffering, or operator fusion patterns. Document the runtime plan and quantify its contribution to TTFT and decode throughput.
- Scalability across model sizes: Only a ~1.2–1.5B range is studied. Evaluate smaller and larger variants to map latency/accuracy Pareto fronts; determine the parameter-efficiency sweet spot under automotive NPU constraints.
Practical Applications
Immediate Applications
The following items can be deployed now on NPUs with integer-only inference (e.g., Qualcomm SA8295P), leveraging AutoNeural’s MobileNet-based vision encoder, hybrid Transformer–SSM language backbone, and the provided NPU-aware training and quantization recipes.
- Real-time cockpit assistant with multimodal understanding [Automotive]
- Use cases: AI Sentinel (vehicle security monitoring), AI Greeter (identity-aware access), AI Car Finder (parking localization), Safety monitoring when boarding/exiting.
- Tools/products/workflows: “Cockpit VLM SDK” built on W8A16 (vision) and W4A16 (language) pipelines; integration with in-vehicle HMI and camera streams; token budgeting to reduce TTFT; MSFA-based visual tokenization.
- Assumptions/dependencies: In-car NPU availability (SA8295P or equivalent), calibrated quantization (QAT) per vehicle model and camera stack, privacy and consent for identity features, ISO 26262/UNECE compliance process for safety-related functions.
- Low-latency driver state monitoring and alerts [Automotive, Healthcare]
- Use cases: Fatigue/distraction detection with contextual explanations; escalation workflows (audio prompts, seat vibration, climate adjustments).
- Tools/products/workflows: On-device inference with bounded activation ranges for robust INT8/16; hybrid SSM layers for fast decode; event-driven alert pipeline.
- Assumptions/dependencies: Robust domain fine-tuning for varied lighting and demographics; clear human factors design; regulatory approvals for safety claims.
- NPU porting and latency optimization for existing VLMs [Software, Edge AI]
- Use cases: Replace ViT encoders with MobileNet-style backbone and incorporate SSM layers to remove KV-cache I/O bottlenecks; achieve 14× TTFT reduction and 3× decode speed.
- Tools/products/workflows: Quantization-aware training (LoftQ, EfficientQAT), mixed-precision calibration (W8A16/W4A16), NPU-runtime scheduling respecting buffer hierarchies.
- Assumptions/dependencies: Vendor SDK support (e.g., Qualcomm AI Engine), retraining/fine-tuning budgets, acceptance of modest accuracy shifts for throughput gains.
- On-device document, chart, and OCR assistance [Enterprise, Education]
- Use cases: Forms processing, receipt capture, textbook diagram interpretation, chart reasoning, and instruction-following without cloud upload.
- Tools/products/workflows: Infinity-MM style curricula for instruction tuning; MobileNet encoder with MSFA; SSM-backed longer context windows for multi-step explanations.
- Assumptions/dependencies: Domain adaptation for local document formats; privacy-by-design workflows; acceptable accuracy under W4A16/W8A16 quantization.
- Retail/industrial smart cameras with captioning and anomaly triage [Industrial, Retail]
- Use cases: Shelf state descriptions, equipment anomaly reporting, signage interpretation; edge deployment with energy-efficient integer-only inference.
- Tools/products/workflows: Depthwise separable convolution encoder for stable activations; linear-time gated convolutions for streaming sequences; lightweight visual-language connector without normalization.
- Assumptions/dependencies: Scenario-specific data and QAT; environmental robustness (lighting, vibration); integration with facility operations.
- Robotics and drones: fast perception-to-language loops [Robotics]
- Use cases: Real-time scene description, instruction following, and operator prompts with tight control-loop latency.
- Tools/products/workflows: KV-cache-free generation via SSM layers; compact rolling state; predictable memory access patterns aligning with NPU SRAM.
- Assumptions/dependencies: Platform NPUs and power budgets; safety envelopes; domain-specific tuning for motion blur, occlusions.
- Smartphone multimodal assistant (privacy-preserving on-device) [Mobile]
- Use cases: Explaining UI states, reading dashboards/meters, translating signage, step-by-step visual guides without cloud.
- Tools/products/workflows: MobileNet encoder at 512×512 or 768×768; token budgeting to reduce TTFT; hybrid backbone for decode throughput on mobile NPUs.
- Assumptions/dependencies: OS-level NPU access, battery profiling, QAT for device camera stack; consent and privacy guarantees.
- Automotive-specific dataset utilization in OEM pipelines [Industry, Academia]
- Use cases: Benchmarking cockpit tasks across demographics and environments; transfer learning for new vehicle models and regions.
- Tools/products/workflows: Four-task dataset (0.2M samples) integrated into Stage 4 QAT; synthetic data mixture (60%) + domain data (40%) for robustness.
- Assumptions/dependencies: Licensing/access for non-proprietary use; continuous data curation; annotation quality control.
- NPU-aware training and calibration services [Software, Consulting]
- Use cases: Vendor-neutral services to harden VLMs for INT4/8/16 (SQNR improvement, RMS error reduction).
- Tools/products/workflows: Hardware-aligned calibration, mixed-precision recipes, operator fusion plans, TTFT telemetry dashboards.
- Assumptions/dependencies: Access to target NPUs and profiler APIs; engineering investment to retool pipelines; customer acceptance of trade-offs.
- Benchmarks and measurement protocols for integer-only VLMs [Academia]
- Use cases: Evaluate TTFT, decode speed, context length, SQNR, perplexity under W8A16/W4A16 across devices.
- Tools/products/workflows: Reproducible on-device measurement scripts; controlled vision encoder latency comparisons; ablation suites (encoder/backbone).
- Assumptions/dependencies: Cross-lab access to NPUs; standardized datasets; community agreement on metrics.
Long-Term Applications
These items require further research, scaling, validation, or ecosystem development to reach production maturity.
- Cross-vendor portability and standards for NPU-native VLMs [Policy, Software]
- Use cases: Common quantization profiles, operator sets, and TTFT reporting across Qualcomm, MediaTek, Apple NPUs.
- Tools/products/workflows: “Integer-only AI” standards; certification suites for memory-I/O behavior; vendor-neutral IRs and compilers.
- Assumptions/dependencies: Multi-stakeholder alignment; shared benchmarks; commitment to edge privacy/security norms.
- Functional safety certification of multimodal cockpit AI [Policy, Automotive]
- Use cases: ISO 26262-aligned hazard analyses for assistant features (fatigue detection, safety reminders); post-quantization reliability audits.
- Tools/products/workflows: Safety cases covering quantization drift, corner cases, and environmental extremes; explainability logs; audit trails.
- Assumptions/dependencies: Expanded in-vehicle trials; third-party validation; regulatory guidance for VLMs.
- Hardware-conditioned automated architecture search (NAS) [Academia, Software]
- Use cases: Auto-discover MobileNet/SSM layer ratios, kernel sizes, token budgets optimized for specific NPU buffer hierarchies and bandwidth.
- Tools/products/workflows: Hardware-in-the-loop NAS; memory-I/O cost models; mixed-precision search spaces.
- Assumptions/dependencies: Accurate hardware simulators; compute budgets; transferability across workloads.
- Multi-camera and sensor fusion VLMs at the edge [Automotive, Robotics, Industrial]
- Use cases: Simultaneous cabin and exterior understanding; radar/LiDAR + vision + language integration for situational narratives.
- Tools/products/workflows: Streamed state-space fusion layers; synchronized tokenization strategies; spatiotemporal adapters.
- Assumptions/dependencies: Time sync across sensors; more training data; tight latency budgets.
- Privacy-preserving personalization on-device [Mobile, Healthcare]
- Use cases: Adaptive assistants fine-tuned locally to user routines and environments without cloud; PII-aware reasoning.
- Tools/products/workflows: Federated/QAT hybrids; differential privacy tuning under integer-only constraints; secure calibration pipelines.
- Assumptions/dependencies: New training toolchains; regulatory acceptance; battery and thermal management.
- Energy labeling and procurement guidelines for edge AI [Policy]
- Use cases: Standardized energy-efficiency and responsiveness labels (TTFT, tok/s, SQNR); public-sector procurement criteria favoring integer-only inference.
- Tools/products/workflows: Test harnesses; reporting templates; compliance monitoring programs.
- Assumptions/dependencies: Policy collaboration; industry adoption; labs for certification.
- Sector-specific datasets and robustness suites beyond automotive [Academia, Industry]
- Use cases: Healthcare imaging assistants, industrial inspection, retail audits, education diagrams—each with quantization-aware annotations.
- Tools/products/workflows: Domain QAT curricula; adversarial/edge-case generation; latency–accuracy Pareto tracking.
- Assumptions/dependencies: Ethical approvals (e.g., healthcare); diverse demographic coverage; funding for data collection.
- Extended-context edge VLMs for workflows with memory [Enterprise, Industrial]
- Use cases: In-device audit trails, multi-step troubleshooting, maintenance logs with 4×+ context windows and fast recall.
- Tools/products/workflows: SSM state management APIs; memory-aware prompt engineering; streaming adapters.
- Assumptions/dependencies: Further tuning to avoid degradation with longer contexts; interface standards for logs.
- KV-cache-free generative control loops in autonomous systems [Robotics, Drones]
- Use cases: Instruction following with deterministic latency; safer reactive behaviors in cluttered environments.
- Tools/products/workflows: Gated-convolution layer scheduling; deterministic timing guarantees; fail-safe controllers.
- Assumptions/dependencies: Formal verification of timing; redundancy planning; robust edge power profiles.
- Edge-first multimodal education and accessibility tools [Education, Public Sector]
- Use cases: Diagram tutors, signage translation, meter-reading for accessibility in low-connectivity regions.
- Tools/products/workflows: Localized QAT; culturally adapted datasets; deployment kits for schools and municipal services.
- Assumptions/dependencies: Funding and device distribution; language/localization coverage; training for educators.
- Integer-only compliance frameworks for safety-critical AI [Policy, Industry]
- Use cases: Mandating quantization robustness proofs (e.g., SQNR thresholds) before field deployment in safety contexts.
- Tools/products/workflows: Compliance checklists; third-party audits; standardized drift metrics under mixed precision.
- Assumptions/dependencies: Consensus on metrics; pathway from research to regulation; pilot programs.
- General-purpose NPU-native multimodal assistants for home IoT [Consumer, Energy]
- Use cases: Appliance status interpretation, energy usage narratives, home security triage—all on-device.
- Tools/products/workflows: Consumer-grade NPUs; app SDKs using MobileNet+SSM backbone; low-power scheduling.
- Assumptions/dependencies: Affordable hardware; UX maturity; domain-specific fine-tuning for household variability.
Notes on cross-cutting assumptions and dependencies
- Hardware: Availability of NPUs with strong integer operator support and sufficient on-chip SRAM; vendor SDKs for deployment and profiling.
- Software: QAT pipelines aligned to target hardware, mixed-precision calibration (e.g., W8A16/W4A16), and runtime schedulers that minimize TTFT and memory I/O.
- Data: Domain-specific datasets (beyond the proprietary automotive set), synthetic augmentation for edge cases, demographic and environmental diversity to reduce bias.
- Safety and compliance: Functional safety processes (automotive), privacy-by-design practices (identity features, OCR), and transparent performance reporting under quantization.
- Performance trade-offs: Acceptance of modest accuracy shifts for substantial latency/throughput gains; systematic benchmarking on target tasks and devices.
Glossary
- Arithmetic throughput: The rate at which a processor can perform arithmetic operations; often used to assess compute capacity. "the high arithmetic throughput of NPUs"
- Autoregressive attention: An attention mechanism used in generative decoders that conditions each token on previously generated tokens. "I/O-bound nature of autoregressive attention mechanisms"
- Autoregressive generation: Token-by-token generation where each new token depends on prior outputs. "The autoregressive generation process necessitates repeated Key-Value (KV) cache access"
- Calibration: The process of determining activation/weight scales for quantized deployment to minimize error drift. "hardware-aligned calibration"
- Context length: The maximum number of tokens a model can consider in its input/history. "supports 4× larger context length (4096 vs 1024)"
- Decode throughput: The speed of token generation during inference, typically measured in tokens per second. "achieves 2.9× higher decode throughput"
- Depthwise separable convolutions: A factorized convolution that applies channel-wise spatial filtering followed by pointwise mixing to reduce computation. "utilizing depthwise separable convolutions"
- Gated convolutions: Convolutional layers augmented with gating mechanisms to modulate information flow efficiently. "employing efficient gated convolutions to achieve linear-time complexity"
- GELU: Gaussian Error Linear Unit; a smooth, probabilistic activation function. "GELU (Gaussian Error Linear Units) activation"
- I/O-bound: A performance regime dominated by data movement rather than arithmetic computation. "I/O-bound nature of autoregressive attention mechanisms"
- INT4/8/16: Integer precisions (4-, 8-, or 16-bit) commonly used in quantized inference. "stable INT4/8/16 quantization"
- Inverted residual (IR) blocks: MobileNet-style blocks with an expand–depthwise–project structure and residual connections for efficiency. "inverted residual (IR) blocks"
- Key-Value (KV) cache: Stored key/value tensors from attention layers to accelerate decoding by avoiding recomputation. "Key-Value (KV) cache access"
- Key-Value caching: The practice of retaining attention keys/values across decoding steps to reduce compute. "eliminates the heavy memory I/O overhead of Key-Value caching during generation"
- Linear-time complexity: Computational cost that scales linearly with sequence length, improving efficiency over quadratic attention. "achieve linear-time complexity"
- Liquid AI: A hybrid sequence-modeling architecture that interleaves Transformer layers with liquid/state-space inspired modules. "the Liquid AI 1.2B hybrid backbone"
- Memory I/O: The reading/writing of data to and from memory; a key bottleneck in on-device inference. "reducing memory I/O by up to 60% during generation"
- Memory-bound operations: Computations whose performance is limited by memory bandwidth rather than compute units. "creating memory-bound operations that saturate on-chip bandwidth"
- Mixed-precision: Using multiple numeric precisions within a single model to balance accuracy and efficiency. "mixed-precision constraints"
- MobileNetV5: A MobileNet family variant used as an efficient vision backbone. "MobileNetV5-style backbone"
- Multi-Query Attention (MQA): An attention variant where multiple query heads share a set of keys/values to reduce memory traffic. "sparse multi-query attention (MQA) bottlenecks"
- Multi-Scale Fusion Adapter (MSFA): A module that fuses features from different resolutions to produce compact tokens. "Multi-Scale Fusion Adapter (MSFA)"
- Neural Processing Unit (NPU): A hardware accelerator specialized for neural network workloads, optimized for integer arithmetic and on-chip memory. "Neural Processing Units (NPUs) have emerged as the default compute substrate for mobile and edge intelligence"
- Operator fusion: Combining multiple primitive operations into a single kernel to reduce memory traffic and overhead. "operator fusion"
- Per-tensor quantization: Quantization scheme that applies one scale/zero-point to an entire tensor (as opposed to per-channel). "static per-tensor quantization"
- Perplexity: A language modeling metric measuring how well a model predicts a sequence; lower is better. "1.6% perplexity increase"
- Prefilling: The initial phase where all input tokens (e.g., prompts and visual tokens) are processed before generation begins. "the LLM prefilling phase"
- Quantization-aware training (QAT): Training with simulated quantization to improve robustness after deployment at low precision. "quantization-aware training (QAT)"
- Quantization brittleness: Sensitivity of a model to accuracy degradation when executed at low numeric precision. "quantization brittleness"
- RMS Error: Root-mean-square error; a measure of average magnitude of errors. "RMS Error"
- RMSNorm: Root Mean Square Layer Normalization; a normalization technique using RMS instead of mean/variance. "RMSNorm applied before both types of layers"
- Rolling state cache: A compact, fixed-size state maintained across timesteps in state-space or convolutional sequence layers. "maintain a rolling state cache that operates with bounded memory during inference"
- Signal-to-quantization-noise ratio (SQNR): The ratio of signal power to quantization noise, indicating quantization fidelity. "Signal-to-quantization-noise ratio (SQNR)"
- SoC (System on Chip): An integrated chip containing multiple subsystems (CPU, GPU, NPU, memory controllers, etc.). "Qualcomm SA8295P SoC"
- SRAM: Static Random-Access Memory; fast on-chip memory used to buffer activations/weights efficiently. "on-chip SRAM"
- State-Space Model (SSM): A sequence modeling approach representing dynamics with latent states, enabling linear-time inference. "State-Space Model (SSM) principles"
- SwiGLU: A gated MLP activation combining SiLU (Swish) with a gating mechanism for expressiveness and stability. "SwiGLU activation"
- Time-To-First-Token (TTFT): Latency from input submission to the emission of the first generated token. "Time-To-First-Token (TTFT)"
- TOPS: Tera Operations Per Second; a throughput metric for accelerators. "delivering high TOPS and energy efficiency"
- Vision Transformer (ViT): A transformer-based architecture for vision tasks using patch embeddings and global self-attention. "Vision Transformers (ViTs)"
- Vision–LLM (VLM): A model jointly trained to understand and generate across visual and textual modalities. "Vision--LLMs (VLMs)"
- Visual instruction tuning: Fine-tuning with image-text instruction data to align vision and language behaviors. "visual instruction tuning"
- W4A16: A mixed-precision format with 4-bit weights and 16-bit activations for inference. "W4A16 (4-bit weights, 16-bit activations)"
- W8A16: A mixed-precision format with 8-bit weights and 16-bit activations for inference. "W8A16 (8-bit weights, 16-bit activations)"
Collections
Sign up for free to add this paper to one or more collections.