Motif 2 12.7B technical report
Abstract: We introduce Motif-2-12.7B, a new open-weight foundation model that pushes the efficiency frontier of LLMs by combining architectural innovation with system-level optimization. Designed for scalable language understanding and robust instruction generalization under constrained compute budgets, Motif-2-12.7B builds upon Motif-2.6B with the integration of Grouped Differential Attention (GDA), which improves representational efficiency by disentangling signal and noise-control attention pathways. The model is pre-trained on 5.5 trillion tokens spanning diverse linguistic, mathematical, scientific, and programming domains using a curriculum-driven data scheduler that gradually changes the data composition ratio. The training system leverages the MuonClip optimizer alongside custom high-performance kernels, including fused PolyNorm activations and the Parallel Muon algorithm, yielding significant throughput and memory efficiency gains in large-scale distributed environments. Post-training employs a three-stage supervised fine-tuning pipeline that successively enhances general instruction adherence, compositional understanding, and linguistic precision. Motif-2-12.7B demonstrates competitive performance across diverse benchmarks, showing that thoughtful architectural scaling and optimized training design can rival the capabilities of much larger models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Motif‑2‑12.7B, a mid‑sized LLM that tries to do more with less. Instead of just making a model huge, the team designed smart architecture changes and clever training tricks so a 12.7‑billion‑parameter model can perform like much bigger ones. It’s open‑weight (the model’s “brain” files are shared), so researchers and developers can use and study it.
What questions were the researchers asking?
- Can a medium‑sized model learn to follow instructions and reason well (in math, science, and code) if we train it in a smarter way?
- Does a new attention method—called Grouped Differential Attention (GDA)—help the model focus on useful information and ignore noise?
- Can system‑level engineering (special math tricks and faster GPU code) cut training time and memory while keeping accuracy high?
- Can a careful training schedule—from general reading to more math and code—boost reasoning without breaking language fluency?
How did they build and train the model?
Think of building a model like growing a brain, then giving it a good education, and finally polishing its skills for real conversations.
Building the model (architecture)
- Starting point: They took a smaller model (Motif‑2.6B) and “widened and deepened” it to 12.7B parameters without losing what it already knew. This is like copying strong parts of a brain and adding more layers on top so it can think more deeply.
- Grouped Differential Attention (GDA): Attention is how a model decides what words to pay attention to. GDA splits attention heads into two groups: most heads amplify important signals, and a smaller group suppresses noise. Imagine a study group where most students highlight key facts while a few erase distractions—together, they stay focused and efficient.
- Other parts kept or extended: They kept helpful components (like RoPE positional info and a special “PolyNorm” activation function) and increased the number of layers. The model can handle very long inputs—up to 32,768 tokens (long documents, code files, etc.).
Pre‑training (the big “education” phase)
- Massive reading: The model read 5.5 trillion tokens across many areas—general English, Q&A, chat, multiple languages, math, science, and programming.
- Curriculum schedule: Early on, it read mostly general text to build strong language skills. Over time, they gradually mixed in more math and code so it learned structured reasoning without getting confused early.
- Large‑batch training and optimizer: They used a custom version of an optimizer called MuonClip (like a coach that adjusts training intensity) to handle huge batches efficiently and stably.
- Longer contexts later: Near the end, they slowly increased the maximum input length (from ~4K to 16K tokens during pre‑training) so the model could learn to understand longer documents.
System engineering (making training fast and memory‑friendly)
- Fused kernels: They combined several small GPU steps into single, faster steps (like doing all your errands in one trip). A key example is a fused version of their PolyNorm activation, which ran much faster than standard code.
- Parallel Muon: They reworked how the optimizer shares and computes big matrices across GPUs. Instead of every GPU repeating the same work, GPUs split the job, swap pieces, and work in parallel—like an assembly line that trades parts to finish faster. With pipelining and smart workload balancing, this cut step time and memory use significantly.
Post‑training (polishing the model for instructions)
After pre‑training, they built an “Instruct” version (Motif‑2‑12.7B‑Instruct) with three supervised fine‑tuning stages:
- Stage 1: General instruction following at large scale—learn to be helpful, clear, and safe across many topics.
- Stage 2: Add curated and synthetic (model‑generated) data to practice multi‑step reasoning, algorithms, math, and code.
- Stage 3: Prune lower‑value data and refine for diversity, fluency, and stable reasoning.
What did they find, and why is it important?
- Strong overall performance for its size:
- General knowledge and reasoning: Competitive on MMLU, MMLU‑Redux, and MMLU‑Pro, sometimes matching or beating models that are bigger.
- Math: Very high scores on math tests (for example, top results on GSM8K and strong performance on MATH). This shows robust multi‑step problem solving.
- Code: High accuracy on coding tasks like HumanEval and MBPP, among the best for open models of similar or even larger size.
- Long context: Handles long inputs (up to 32K tokens), useful for big documents or codebases.
- Data and compute efficiency:
- Trained on 5.5T tokens, yet rivals models trained on much more data. This suggests the mix of GDA, a smart curriculum, and systems optimizations makes learning more efficient.
- System boosts: Their fused GPU kernels and Parallel Muon optimizer made training much faster and lowered memory needs. In some comparisons, the parallel approach offered about 7× higher throughput than a common baseline, and fusion sped up key operations dramatically.
- Instruct model results:
- After the three‑stage fine‑tuning, the model reached strong scores on difficult reasoning (like AIME) and coding benchmarks (like LiveCodeBench), often matching or surpassing larger open models—without needing extra reinforcement‑learning tricks.
Why this matters: It shows you don’t always need a giant model and enormous compute to get high performance. Smart design and training can close much of the gap, making advanced AI more accessible and affordable.
What’s the bigger impact?
- Better, cheaper AI: Efficient models lower cost and carbon footprint, making powerful tools available to more researchers, startups, and classrooms.
- Open foundation: Because the weights and training ideas are shared, others can build on this work, try new attention designs like GDA, or reuse the training system improvements.
- Strong reasoning at smaller scale: The results suggest a path to AI that’s good at step‑by‑step thinking (math, logic, code) without relying only on massive size.
- Future direction: The team plans a “Reasoning” version trained with reinforcement learning to push multi‑step reasoning even further, while keeping conversation quality high.
In short, Motif‑2‑12.7B is a carefully engineered model that proves smarter architecture plus smarter training can rival much larger systems—an important step toward powerful, efficient, and widely usable AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete items future researchers could address:
- Lack of ablation studies isolating the contribution of Grouped Differential Attention (GDA): no comparisons against standard attention, head pruning, or alternative routing mechanisms; no sensitivity analysis of the signal-to-noise head ratio (e.g., 3:1, 2:1, dynamic ratios).
- No formal theory or interpretability analysis of “noise-control heads” in GDA: absence of definitions, metrics, and diagnostics demonstrating how “noise suppression” is quantified and how it impacts gradient flow, attention patterns, or information routing.
- Missing latency and memory profiling for GDA at inference-time: the paper claims no extra compute cost, but provides no end-to-end latency, memory, or throughput measurements across different sequence lengths and batch sizes.
- Absent robustness evaluation for GDA under long context (≥32k) and adversarial prompts: unclear whether head specialization degrades recall, exacerbates attention drift, or causes instability in extreme contexts.
- No comparison of hypercloning width-scaling vs alternative scaling strategies (e.g., reinitialization, progressive growing, tensorized expansions): unclear impacts on convergence speed, representational redundancy, or catastrophic forgetting.
- Hypercloning’s effect on optimization dynamics is unexamined: no evidence whether replicated widths create dead or redundant channels, alter gradient noise scale, or change loss landscapes.
- Depth scaling via LLaMA-Pro lacks empirical validation in this setting: no ablation on layer counts, residual scaling configuration, or RMSNorm placements; no analysis of scale-induced training instabilities.
- Tokenizer choice (Motif-2.6B’s tokenizer, vocab size 219,520) is not evaluated for multilingual coverage, compression efficiency, or code/mathematics tokenization quality; no trade-off analysis vs smaller vocabularies or byte-level tokenizers.
- RoPE hyperparameter choice () is not justified empirically: no long-context recall tests (e.g., LongBench, L-Eval, Needle-in-a-Haystack), or examination of short-range accuracy trade-offs.
- Pre-training data mixture is insufficiently specified: missing per-domain token proportions, schedule parameters over 5.5T tokens, duplication rates, data quality scores, and license/source hygiene for in-house and synthetic corpora.
- No contamination analysis across benchmarks: the paper does not report decontamination checks for MMLU, GSM8K, MATH, HumanEval/MBPP, GPQA, LiveBench, AIME, etc., nor the applied filtering methodology.
- Multilingual claims (including Korean) lack evaluation: no standardized multilingual benchmarks (e.g., XNLI, FLORES, MGSM, multilingual MMLU variants), and no per-language breakdown or cross-lingual transfer assessments.
- Safety, bias, and toxicity are not measured: no red-teaming, refusal behavior tests, bias audits, toxicity benchmarks, jailbreak robustness, or safety alignment methodology beyond generic SFT claims.
- Privacy and PII handling are unaddressed: no discussion of data anonymization, PII filtering, privacy risks in open weights, or compliance protocols.
- Training stability metrics are missing: no loss curves, gradient norm statistics, optimizer stability diagnostics, or failure mode reports (e.g., divergence events) for FP8 training and large-batch schedules.
- FP8 training details are incomplete: no calibration strategy, per-layer scaling policies, overflow/underflow handling, or quality impacts vs BF16/FP16; no cross-hardware reproducibility analysis.
- The Muon-Clip optimizer is under-specified: no algorithmic description, clipping scheme, hyperparameter sensitivity, convergence comparisons vs AdamW/Muon, or downstream quality impacts.
- Parallel Muon evaluation is limited: results only on single-node 8×H200; no multi-node scaling, different interconnects (NVLink vs InfiniBand), cross-GPU (H100 vs A100) comparisons, or fault-tolerance/resilience behavior.
- Parallel Muon correctness is not established: no equivalence tests vs Distributed Muon on numerical updates, convergence parity on real training runs, or impact on final model quality.
- Chunk-size selection (32) lacks generalization evidence: no sensitivity sweep across models, batch sizes, sequence lengths, hardware, or interconnect topologies; no auto-tuning strategy.
- Fused PolyNorm kernels are benchmarked on H200, but training used 400×H100: missing performance results on H100 and other GPUs, and absent end-to-end training speedups (tokens/sec) attributable to the fusion.
- Sequence packing to 16,384 during SFT is unexamined: no analysis of packing-induced context interference, training stability trade-offs, or impact on instruction-following quality vs un-packed training.
- Three-stage SFT pipeline lacks quantitative attribution: no ablations per stage to measure marginal gains in reasoning, code, or fluency; no data quantity/quality breakdown for each stage.
- Synthetic data generation procedures are opaque: missing model sources, prompts, sampling parameters, filtering criteria, automatic quality scoring methods, and measures to prevent synthetic artifacts or stereotype amplification.
- Instruction alignment is under-described: no preference modeling or policy shaping details, no evaluation of instruction adherence under adversarial or ambiguous tasks (e.g., IFEval variants beyond strict/soft prompt).
- Evaluation fairness issues remain: the paper uses official reported scores for baselines with heterogeneous settings (shots, CoT, “Think” mode), while Motif uses greedy decoding or specific temperatures; no standardized re-evaluation to ensure comparability.
- Statistical robustness is unreported: no confidence intervals, multiple-run variance, or significance testing across benchmarks; unclear sensitivity to decoding hyperparameters (temperature/top-p/beam).
- Large-context capability is asserted (32,768) but not validated: no long-context benchmarks, retrieval tests, sliding-window recall, or degradation curves vs length.
- Code evaluations miss pass@k and runtime constraints: no pass@k for HumanEval/MBPP/EvalPlus, resource budgets, or robustness to execution environment changes; limited error analysis of failure types.
- Missing domain coverage in medical, legal, and scientific writing: apart from GPQA variants, no MedQA/MedMCQA, PubMedQA, legal reasoning (e.g., LegalBench) or academic writing tasks; unclear professional-domain readiness.
- Energy, cost, and carbon footprint are not quantified: 400×H100 for ~272k hours is reported but ambiguous (GPU-hours?), with no energy/carbon accounting or cost/performance comparisons vs baselines.
- Scaling laws and data efficiency are not analyzed: despite claims of efficiency, there is no empirical scaling analysis (loss vs tokens/parameters), returns to data/compute, or optimal mixture scheduling curves.
- Inference-time compute and memory efficiency are not measured: no throughput, memory, and latency metrics across batch sizes and sequence lengths, nor comparisons vs similarly sized open-weight baselines.
- Generalization under distribution shift is untested: no evaluations on out-of-domain reasoning, noisy inputs, or adversarial paraphrases; no stress tests for robustness in real-world settings.
- Error analysis is absent: no qualitative breakdown of typical failure modes (math, code, commonsense, long-context), nor targeted mitigations.
- Reproducibility is incomplete: although some kernels/optimizer are released, training recipes (exact data mixtures, schedules, seeds), full data manifests, and end-to-end scripts are not provided to recreate reported results.
- Future RL variant (“Motif-2-12.7B-Reasoning”) lacks a research plan: no objective definition, reward design, safety constraints, or evaluation protocols to assess trade-offs between reasoning quality and general fluency/alignment.
Practical Applications
Immediate Applications
Below are concrete, deployable applications that can be built directly on Motif‑2‑12.7B’s released weights, post‑training recipe, and open-source systems (fused kernels and Parallel Muon).
- Software engineering assistants (sector: software)
- Use Motif‑2‑12.7B‑Instruct for in‑IDE code completion, test-driven code synthesis, bug localization, and refactoring (validated by strong results on HumanEval, MBPP, LiveCodeBench, EvalPlus).
- Integrate into CI pipelines to propose fixes that pass unit tests automatically, or to generate migration scaffolds (e.g., Python 3.x upgrades, framework updates).
- Assumptions/Dependencies: 12.7B inference typically requires GPU or aggressive quantization (e.g., 4–8 bit); safety/secure coding filters and sandboxed execution for test-based validation recommended.
- Long-context document and codebase analysis (sector: enterprise software, legal, compliance)
- Exploit 32,768‑token context for enterprise RAG: summarize contracts, specs, SLAs, and large code repositories; produce cross-document comparisons and change impact analyses.
- Reduce chunking/fragmentation in RAG systems, improving retrieval accuracy for long files and mixed modalities (docs + code).
- Assumptions/Dependencies: Actual training exposure to 16k sequences; performance beyond 16k relies on RoPE scaling and may need validation on your corpora; high-quality retrievers and chunking heuristics still matter.
- Math tutoring and assessment tooling (sector: education)
- Deploy math-solvers and tutors for K‑12 to Olympiad prep using strong GSM8K/MATH/AIME performance; generate step-by-step reasoning and grading rubrics; auto‑create problem variants and solutions.
- Embed into LMS platforms to provide immediate feedback with worked solutions and hints.
- Assumptions/Dependencies: Pedagogical guardrails (e.g., not just final answers but method checks); ensure content alignment to curricula; monitor for occasional hallucinations and arithmetic slips.
- STEM and technical writing copilot (sector: academia, R&D)
- Draft and refine technical summaries of papers, lab protocols, and experimental plans; assist in equation derivations and code snippets for data analysis.
- Support multilingual settings (English/Korean coverage in pretraining) for literature review and translation of technical content.
- Assumptions/Dependencies: Domain adaptation via light SFT/LoRA on in‑house corpora improves quality; human-in-the-loop review is essential for claims and citations.
- Enterprise knowledge assistants (sector: finance, consulting, operations)
- Build assistants for policy/Q&A over internal handbooks, SOPs, and financial reports; generate analytic memos and scenario models with improved quantitative reasoning.
- Assumptions/Dependencies: RAG/grounding required for factual reliability; compliance review and role‑based access controls needed; careful prompt templates for tabular reasoning.
- Training efficiency upgrades for existing model pipelines (sector: AI infra, ML platforms)
- Adopt Parallel Muon to accelerate large-batch training with FSDP/TP/HSDP; benefit from 5–7×+ optimizer throughput and reduced memory (as reported) vs. Distributed Muon.
- Drop in fused PolyNorm kernels to boost activation throughput where PolyNorm is used.
- Assumptions/Dependencies: Requires H100/H200‑class GPUs (FP8 preferred), high‑speed interconnects for All‑to‑All; integration with PyTorch/TorchTitan-like stacks; PolyNorm applicability depends on your model’s activation choice.
- Cost‑effective model scaling via hypercloning (sector: AI model development)
- Use width-preserving hypercloning to scale smaller internal models to larger sizes while preserving function for easier A/B rollouts and faster convergence.
- Assumptions/Dependencies: Access to base weights and retraining budget for post‑clone adaptation; correctness depends on architecture compatibility and careful depth scaling.
- Curriculum‑based pretraining and “reasoning annealing” recipes (sector: AI model development, academia)
- Apply the dataset-mixture scheduler to gradually shift from general text to STEM/math/code to improve reasoning without sacrificing fluency.
- Assumptions/Dependencies: Requires curated data mixers, deduplication, and synthetic data generation; monitoring to avoid mode collapse and distributional overfit.
- Three‑stage SFT pipeline for instruction models (sector: AI product teams, ed‑tech, code tools)
- Replicate the SFT stages: general instruction → synthetic reasoning/code/math → data-pruned refinement to achieve strong reasoning without RL.
- Assumptions/Dependencies: Data IP and licensing compliance; quality filters and validation harnesses; may need domain‑specific safety and style constraints.
- On‑premise and sovereign deployments (sector: public sector, regulated industries)
- Use open weights for data‑residency‑compliant assistants in government, healthcare admin, and banking: on‑prem summarization, redaction, and drafting.
- Assumptions/Dependencies: Additional alignment/safety layers required; healthcare/medical decision support needs domain fine‑tuning and regulatory validation (not provided here).
- Developer tools and plugins
- Ship a VS Code/JetBrains plugin powered by Motif‑2‑12.7B‑Instruct for code explanations, test authoring, and docstring generation; add an internal chat service using the provided endpoint.
- Assumptions/Dependencies: Latency constraints imply quantized inference or GPU serving; telemetry and privacy policies for code.
- Sustainable AI and cost control (sector: policy, corporate sustainability, academia)
- Leverage FP8 training, high-throughput kernels, and large‑batch methods to reduce compute hours and energy for research labs and startups.
- Assumptions/Dependencies: Hardware and software readiness for FP8; robust monitoring to manage stability; carbon accounting depends on datacenter mix.
Long-Term Applications
These opportunities require further research, scaling, adaptation, or ecosystem maturation before reliable broad deployment.
- Architecture‑level efficiency transfer (GDA adoption across model families) (sector: AI model development)
- Generalize Grouped Differential Attention to other transformer families and modalities (multimodal, speech, RL agents) to reduce compute while improving signal/noise routing.
- Potential tools: GDA-aware attention modules in major frameworks; head‑group auto‑tuning utilities.
- Assumptions/Dependencies: Requires retraining or careful retrofitting; optimal group ratios may vary by domain and scale; extensive ablations needed.
- RL‑enhanced reasoning models (sector: education, software, scientific computing)
- Build Motif‑2‑12.7B‑Reasoning variants for verifiable multi‑step math, theorem proving, and code synthesis with test‑time adaptation and tool‑use.
- Products: “Proof assistant lite,” verified coding copilots that learn from execution traces and self‑play.
- Assumptions/Dependencies: High‑quality reward models/feedback channels, sandboxed tool integration; safeguards against reward hacking and reasoning brittleness.
- Edge and on‑device reasoning assistants (sector: mobile, robotics, automotive)
- Quantize and distill Motif‑2‑12.7B into 3–7B tier models with retained GDA benefits for local, low‑latency assistants (navigation explanations, maintenance guides, offline coding help).
- Assumptions/Dependencies: Advanced quantization/distillation pipelines; memory and power budgets; potential accuracy trade‑offs.
- Automated data curriculum designers (sector: AI tooling)
- Turn the paper’s mixture scheduling and reasoning annealing into auto‑curriculum tools that optimize data composition for a target capability profile under a fixed compute budget.
- Assumptions/Dependencies: Reliable data quality metrics, closed‑loop evaluation harnesses, and governance for synthetic data.
- Domain‑certified assistants for regulated sectors (sector: healthcare, legal, finance)
- Create assistants that combine Motif‑2 family models with domain corpora, verifiers, and provenance tracking to meet regulatory standards (e.g., clinical guidelines summary with citations, compliance checks).
- Assumptions/Dependencies: Extensive domain fine‑tuning, auditing, calibration, and post‑hoc verification; legal/clinical approval cycles.
- Foundation model training templates for smaller labs and nations (sector: public policy, academia)
- Package the FP8 + Parallel Muon + SkyPilot/TorchTitan flow into reproducible, budget‑aware blueprints enabling national labs and universities to train competitive open models.
- Assumptions/Dependencies: Access to modern GPUs/interconnects; skilled MLOps; sustained funding and open data pipelines.
- Verifiable reasoning and self‑correction workflows (sector: enterprise analytics, safety)
- Combine Motif‑2 with external verifiers (symbolic math tools, compilers, constraint solvers) for high‑stakes decision support that logs intermediate steps and justifications.
- Assumptions/Dependencies: Tool orchestration, function‑calling APIs, formal verification kernels; robust failure handling.
- Attention routing analytics for interpretability (sector: AI safety and research)
- Use GDA’s signal/noise head specialization to develop diagnostics for information flow, aiding debugging, bias detection, and safety case building.
- Assumptions/Dependencies: New interpretability tooling and benchmarks; consensus on metrics for “noise suppression” effectiveness.
- Energy‑aware training schedulers (sector: sustainability, cloud)
- Extend the system optimizations into schedulers that co‑optimize data mixture, batch size, and energy/price signals (spot markets), targeting minimal carbon per token trained.
- Assumptions/Dependencies: Cloud APIs for real‑time carbon intensity, robust checkpointing and elasticity, queueing policies.
- Cross‑lingual STEM education and workforce upskilling (sector: education, government)
- Leverage multilingual pretraining (incl. Korean resources) to deliver STEM tutoring and code learning in under‑served languages, with local hosting for data sovereignty.
- Assumptions/Dependencies: Localization, cultural/terminology adaptation, assessment alignment; sustainable funding and teacher training.
- Standardized, open benchmarking and compute‑efficiency reporting (sector: policy, research)
- Inform policy with transparent benchmarks on “accuracy per T‑token” and “energy per T‑token,” using Motif‑2 as a reference for efficient scaling strategies.
- Assumptions/Dependencies: Community adoption of reporting standards; trustworthy auditing; comparable hardware disclosures.
Notes on feasibility and deployment
- Licensing and usage: Confirm the Hugging Face license and acceptable use policies before commercial deployment.
- Safety and alignment: Motif‑2‑12.7B‑Instruct uses SFT (no RLHF in this report). High‑risk domains need additional alignment, red‑teaming, and guardrails.
- Hardware: Many systems benefits (FP8, Parallel Muon) assume H100/H200‑class GPUs and fast interconnects; inference can be CPU/GPU with quantization.
- Long‑context: Training included sequences up to 16k; evaluate your tasks at 32k to verify retention and retrieval accuracy.
- Data governance: Reproduce the paper’s deduplication, filtering, and synthetic data checks to avoid contamination and quality regressions.
Glossary
- 3D/4D parallelism: Multi-dimensional distributed training that combines data, tensor, pipeline, and context parallel strategies. "a PyTorch-native distributed training platform that provides modular 3D/4D parallelism (data, tensor, pipeline, and context)"
- Activation checkpointing: A memory-saving technique that recomputes activations during backpropagation instead of storing them. "advanced optimizations such as FP8 all-gather and activation checkpointing."
- All-gather: A collective communication operation that gathers shards from all ranks to reconstruct full tensors on each rank. "performing an all-gather to reconstruct the full matrix before each Newton–Schulz iteration"
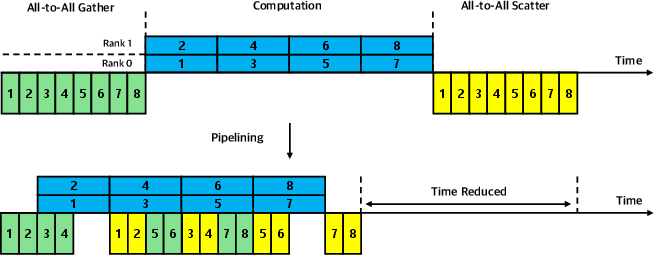
- All-to-All communication: A collective operation where each rank exchanges data with all other ranks, often used to re-shard tensors efficiently. "they propose employing All-to-All communication to re-shard gradients across ranks"
- Annealing phase: A staged training phase where a quantity (e.g., data ratio or learning rate) is gradually adjusted to refine model behavior. "In the final annealing phase, we gradually increased the proportion of reasoning data"
- BF16: Brain Floating Point 16-bit format used to store gradients or activations with wider dynamic range than FP16. "keeps gradients in BF16 precision during the backward pass."
- Cosine learning rate scheduler: A learning-rate schedule that follows a cosine decay curve, often with warmup. "A cosine learning rate scheduler was employed with a warm-up phase"
- Cross-layer residual scaling: A stabilization technique that scales residual (skip) connections across layers to control signal magnitude. "preserving RMS normalization, Rotary Positional Embedding, and cross-layer residual scaling inherited from Motif-2.6B."
- Curriculum scheduler: A mechanism that modulates the training data composition over time to guide learning. "We employed a linear curriculum scheduler to modulate the data composition throughout training."
- Dataset mixture scheduling: Gradually adjusting the proportions of different datasets during pre-training to improve stability and capability. "We adopted a progressive dataset mixture scheduling strategy"
- Distributed Muon: A distributed implementation of the Muon optimizer that uses ZeRO-style parameter sharding. "Liu et al. introduced Distributed Muon, which applies a ZeRO-1–based parameter partitioning scheme to the Muon algorithm."
- Flash Muon: An optimized kernel implementation that accelerates Muon’s matrix operations. "extended with Flash Muon\cite{lin2025flash} for fair comparison with Parallel Muon."
- FP8: 8-bit floating-point precision used to increase training throughput and reduce memory. "using FP8 precision to maximize computational efficiency."
- FSDP (Fully Sharded Data Parallel): A training strategy that shards parameters, gradients, and optimizer states across data-parallel ranks. "using Fully Sharded Data Parallel (FSDP) with eight ranks."
- FSDP2: A newer variant of FSDP with extended capabilities, often used alongside tensor parallelism. "does not support hybrid configurations such as FSDP2 combined with tensor parallelism (TP)."
- GEMM: General Matrix-Matrix Multiply, core linear algebra operation used in neural network training and inference. "all communication and GEMM operations are performed in BF16 precision."
- GDA (Grouped Differential Attention): An attention mechanism that partitions heads into signal-amplifying and noise-suppressing groups to improve efficiency. "We introduce Grouped Differential Attention (GDA), a new mechanism that reorganizes attention computation"
- Greedy decoding: Deterministic generation strategy that selects the highest-probability token at each step. "All evaluations for Motif-2-12.7B-Base were conducted using greedy decoding."
- Hypercloning (Scaling Smart Hypercloning): A model-scaling method that expands width by replicating weights to preserve function and initialization statistics. "through the Scaling Smart Hypercloning procedure"
- HSDP (Hybrid Sharded Data Parallel): A hybrid sharding approach that mixes parallel strategies for scalability and efficiency. "(e.g., TP + HSDP)"
- Kernel fusion: Combining multiple GPU operations into a single kernel to reduce memory traffic and launch overhead. "kernel fusion, which reduces redundant memory traffic and kernel launch overhead."
- LLaMA-Pro framework: A methodology for depth scaling that increases layers while preserving normalization and embeddings. "we expanded the model depth using the LLaMA-Pro framework"
- Mode collapse: A training pathology where a model overly concentrates on a narrow output distribution, losing diversity. "to prevent overfitting and mode collapse toward narrow reasoning distributions."
- Muon-Clip optimizer: A Muon-based optimizer variant with clipping/adaptive scaling designed for stability in large-batch settings. "We employed the Muon-Clip optimizer"
- Newton–Schulz iterations: An iterative matrix method used by Muon to compute updates requiring full gradient matrices. "Muon requires access to the full gradient matrices to perform the Newton–Schulz iterations."
- Parallel Muon: A distributed, pipelined implementation of Muon that parallelizes computation across ranks with All-to-All communication. "Parallel Muon distributes computational workloads across shard ranks and executes them concurrently."
- Pipelining: Scheduling overlapping communication and computation stages to hide latency and improve throughput. "pipelining its execution enables better performance through communication–computation overlap."
- PolyNorm activation: A polynomial normalization-based activation function optimized with fused kernels for efficiency. "PolyNorm, a polynomial activation function introduced at Motif-2.6B"
- RoPE (Rotary Positional Embedding): A positional encoding method that rotates embeddings in a complex plane to encode positions. "preserving RMS normalization, Rotary Positional Embedding"
- RMS normalization: Root Mean Square normalization that scales activations by their RMS to stabilize training. "preserving RMS normalization"
- Row-wise scaling: Scaling factors applied per row (e.g., of weight or activation tensors) to stabilize low-precision training. "we applied row-wise scaling and keeps gradients in BF16 precision during the backward pass."
- Sequence packing: Concatenating multiple short sequences into longer ones within a batch to improve utilization of long context windows. "Training was conducted with sequence packing up to 16,384 tokens"
- SkyPilot: A cloud orchestration framework for provisioning multi-node, multi-cluster training jobs across environments. "We employed SkyPilot as the orchestration framework"
- Tensor Parallelism (TP): Splitting tensor dimensions across devices to parallelize large matrix operations. "such as TP or TP + HSDP"
- TorchTitan: A PyTorch-native distributed training system offering modular parallelism and advanced optimizations. "we adopted TorchTitan, a PyTorch-native distributed training platform"
- Warmup–Stable–Decay scheduler: A learning-rate schedule with phases of warmup, steady training, and decay. "using the WarmupâStableâDecay scheduler"
- ZeRO-1: A sharded optimizer state partitioning strategy that reduces memory by distributing parameters and states across ranks. "applies a ZeRO-1–based parameter partitioning scheme to the Muon algorithm."
Collections
Sign up for free to add this paper to one or more collections.