Step-DeepResearch Technical Report
Abstract: As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
First 10 authors:

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Step-DeepResearch, an AI system designed to do “deep research” on the internet—more than just finding facts. Instead of acting like a fast search engine, it works like a careful researcher: it plans what to do, gathers information from multiple sources, checks facts, and writes clear reports. The main goal is to build these skills directly into the model so it can think and self-correct while it works, without needing lots of complicated external tools.
Key Questions
The paper focuses on simple, practical questions:
- How can we train an AI to research, not just search?
- What basic skills (the paper calls them “atomic capabilities”) does a good research agent need?
- Can a medium-size model (32B parameters) perform well and be cost-effective?
- How should we fairly test whether the AI’s research is actually useful to people?
How They Did It (Methods)
Building core skills (“atomic capabilities”)
The authors break research into four core skills. Think of these like the basic moves a good player learns before playing a full game:
- Planning and task breakdown: Turning a vague question into clear steps and adjusting the plan when new information appears.
- Deep information seeking: Finding hidden, hard-to-get facts by following links and connecting dots across sources.
- Reflection and verification: Spotting mistakes, checking facts from multiple places, and fixing errors along the way.
- Report writing: Organizing what was found into a structured, well-cited, readable report.
To teach these skills, the team creates special training data:
- They “reverse engineer” plans from real research reports, using the report’s title and summary to generate realistic tasks and high-level plans.
- They build complex question sets using knowledge graphs (like maps of topics and their connections), which forces the AI to follow multi-step paths to find answers.
- They include “error-reflection loops,” where the model tries, makes mistakes, reflects, and tries again until it gets the right answer—like practicing with feedback.
- They simulate a fact-checking workflow with mini “teacher agents” that extract claims, plan checks, verify, and then write conclusions with evidence.
Training in three steps
To help the model grow its skills in a stable way, training happens in stages—like learning drills, then coached practice, then real games with scoring:
- Mid-training (practice drills):
- Stage I (32K context): Teach the core skills using text only (no tools). Focus on planning, seeking information, self-correcting, and writing.
- Stage II (128K context): Add real-world tasks with tool use (like web browsing and searching). The model learns when to use tools and how to include results in its reasoning.
- Supervised fine-tuning (coached practice):
- The model studies high-quality “full journeys” from question to final report.
- Data is cleaned to reward short, efficient solutions and proper citations, and to include some realistic errors so the model learns to recover.
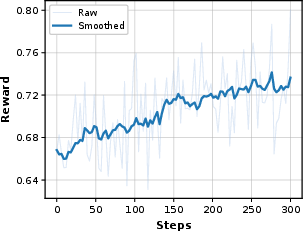
- Reinforcement learning (learning by rewards):
- The model works in a live environment with tools and writes a final report.
- A “Rubrics Judge” scores the report based on clear criteria (like accuracy, reasoning, structure, and citations).
- Rewards are given only when rubrics are fully met, discouraging sloppy partial answers.
- The model updates its policy using PPO (an algorithm that safely improves decisions based on rewards), steadily learning better planning, tool use, and writing.
Testing and scoring
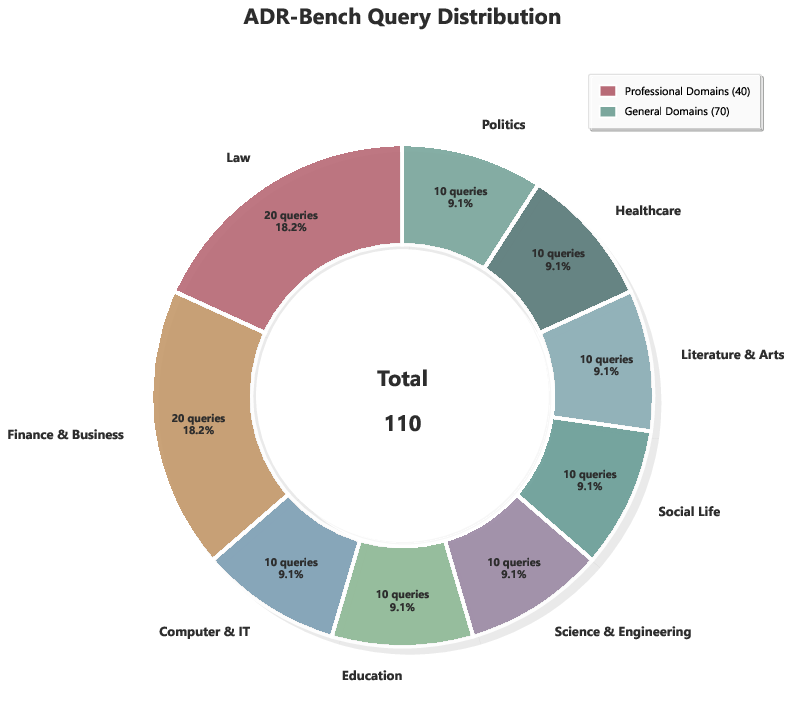
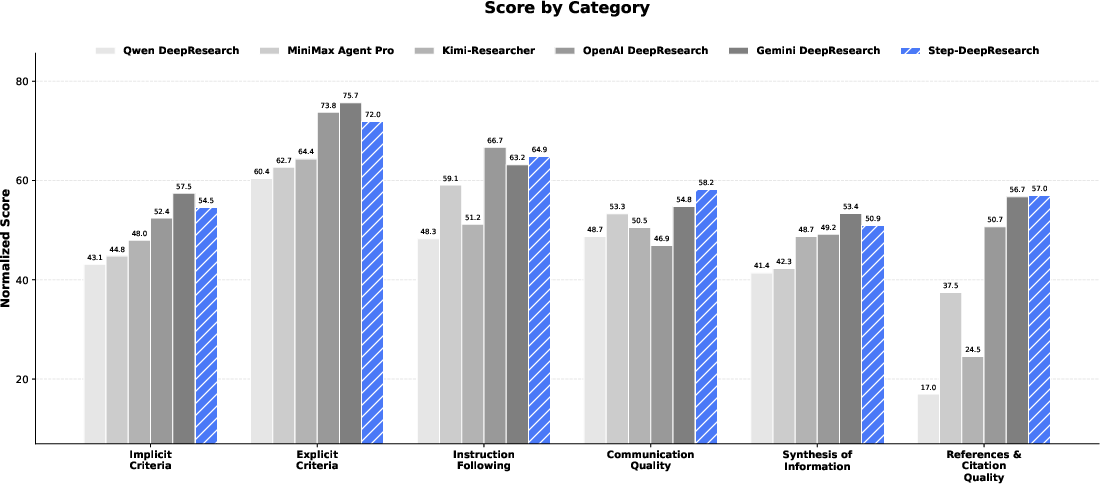
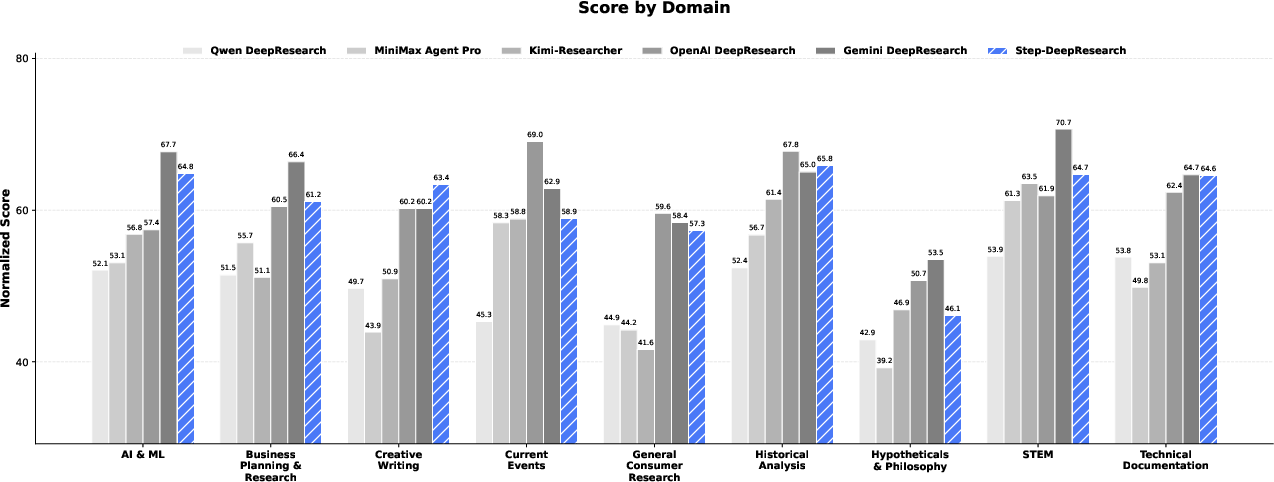
Because typical benchmarks focus too much on simple Q&A, the team built ADR-Bench (Application-driven Deep Research Benchmark). It tests useful real-world tasks (like business research, policy analysis, software topics) and uses Elo ratings (like chess rankings) judged by experts across multiple dimensions. They also report results on Research Rubrics, a benchmark that scores reports against detailed expert criteria.
What They Found
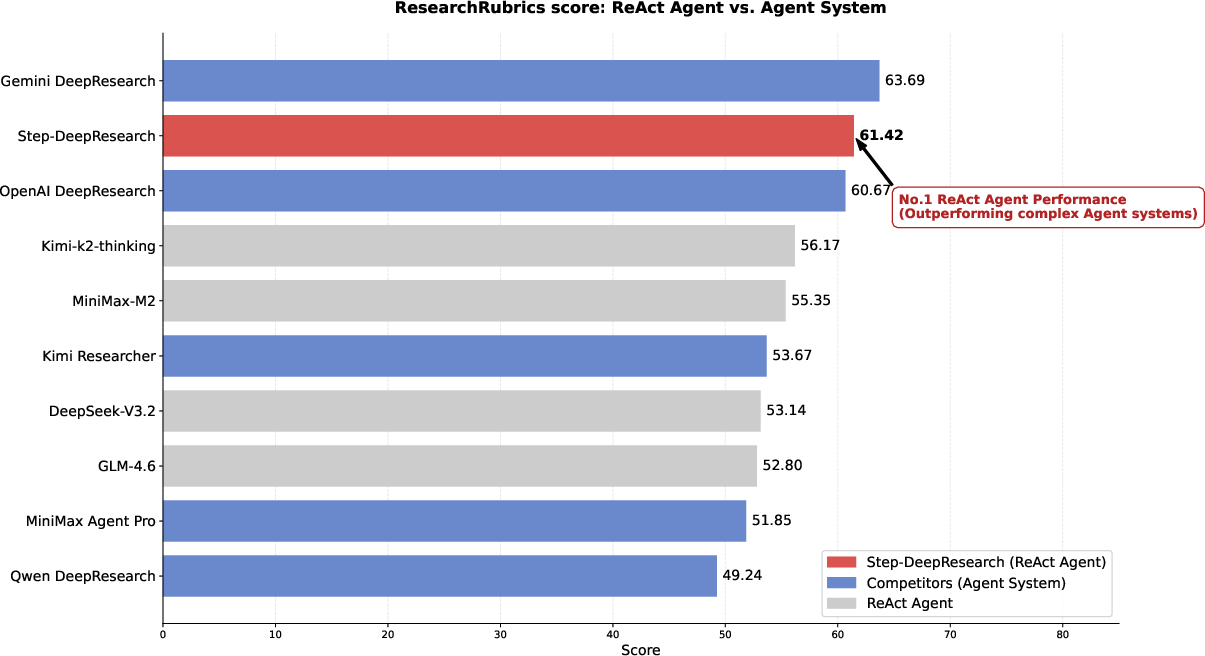
- Strong performance at lower cost: Step-DeepResearch reaches about 61.4% compliance on Research Rubrics—comparable to leading closed-source systems—while being much cheaper to run.
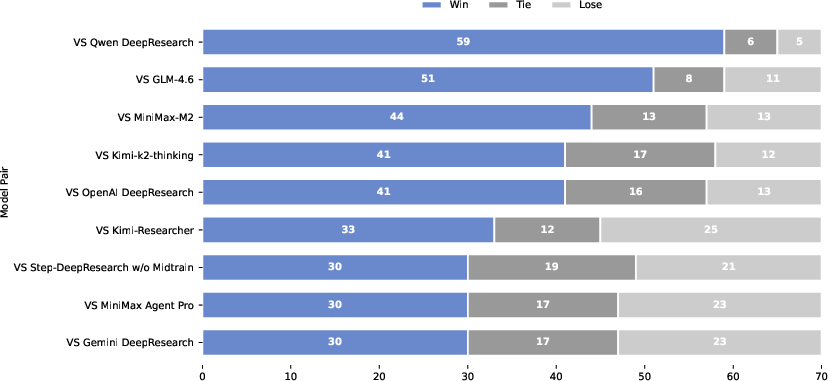
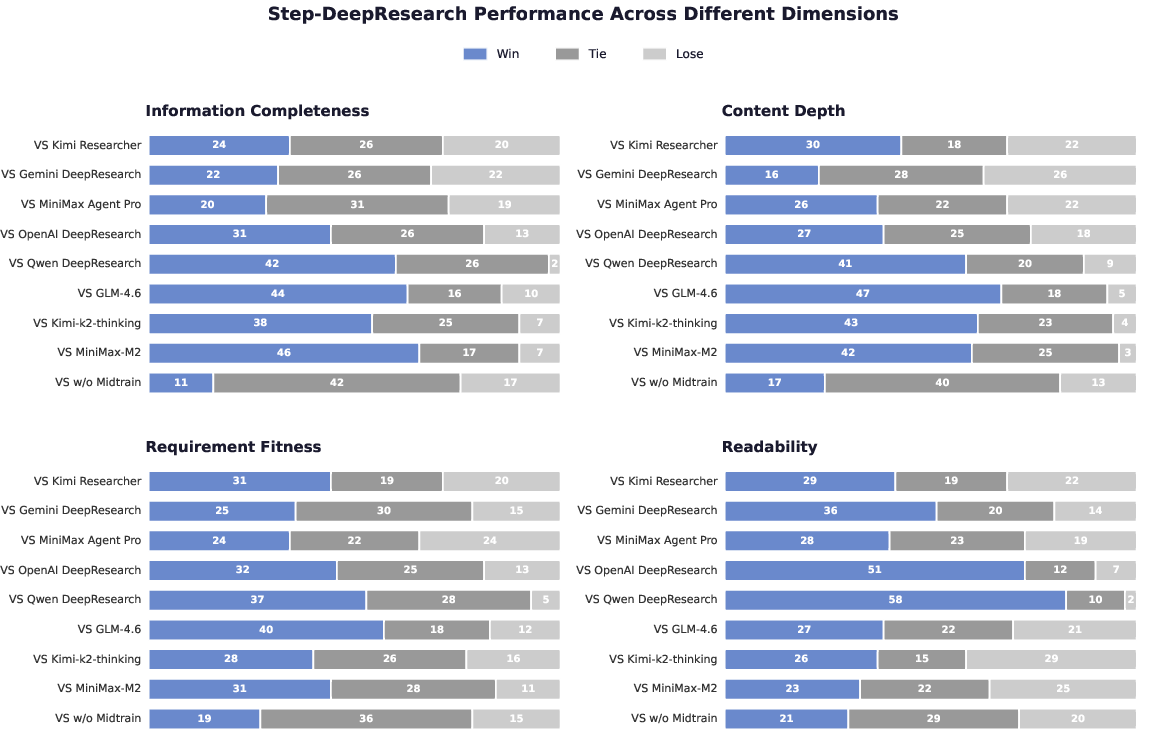
- Top expert ratings: On ADR-Bench, experts consistently rate Step-DeepResearch at or near the top across different skills, with Elo scores rivaling or beating bigger, more expensive models and specialized research agents.
- Medium model, big results: Even with 32 billion parameters, it outperforms some larger models and specialized systems, thanks to its carefully trained core skills and streamlined single-agent design.
- Better real-world behavior: By training the model to decide the “next action” (not just predict the next word), it becomes more robust, plans better, checks facts more reliably, and writes clearer reports.
Why It Matters
This work shows that:
- Research needs more than good search. AI agents become truly useful when they can plan, verify, and write high-quality reports.
- Smart training beats brute force. By teaching the right basic skills and using practical training steps, a medium-size model can match or beat bigger ones.
- Clear evaluation helps progress. ADR-Bench and rubrics-based scoring connect model scores to what real users care about: accuracy, reasoning, structure, and usefulness.
- Cheaper, reliable AI research is possible. This can make high-quality research assistance more accessible to students, startups, journalists, analysts, and more.
In short, Step-DeepResearch moves AI closer to being a careful, trustworthy research assistant that thinks through problems, checks its work, and explains its findings clearly—without needing complicated, costly setups.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps that remain unaddressed and can guide future research.
- Data transparency and reproducibility: Missing full dataset statistics (sample counts per capability/task type, domain/language mix, trajectory lengths, tool-call distributions), cleaning rules, prompts, seeds, and release status for all synthesized datasets and ADR-Bench.
- Benchmark construction details: ADR-Bench’s task generation process, rubric definitions, domain coverage, difficulty calibration, and leakage safeguards (e.g., overlap with training data) are not described in sufficient detail to ensure fair replication and external validation.
- Cross-lingual generalization: The approach centers on Chinese scenarios; there is no systematic evaluation of cross-lingual performance, cross-language evidence integration, or transfer to English/other languages.
- Contamination and leakage controls: Reverse-engineered tasks from abstracts and reports risk hindsight leakage; no quantitative checks are reported to ensure training data do not inadvertently encode answer paths used in evaluation.
- Atomic capability formalization: The action-subspace concept and error terms (, ) are introduced but not operationalized or measured; the trade-off between action-space pruning and downstream learnability remains theoretical without empirical ablations.
- Optimal granularity of atomic actions: No ablation studies compare different atomic capability taxonomies/granularities or assess how action granularity impacts planning efficiency, stability, or generalization.
- Composition of atomic capabilities: The paper does not show how capabilities interact (e.g., planning ↔ verification ↔ reporting) under distribution shift, nor does it quantify compounding errors across stages in end-to-end tasks.
- Difficulty filtering biases: Using QwQ-32B as a gatekeeper may bias the training set against problems solvable by similar model families; the effect on domain coverage, novelty, and downstream generalization is untested.
- Quality and fidelity of synthetic supervision: Heavy reliance on LLM-generated (teacher) trajectories and rubrics risks “teacher-student collapse” and propagation of teacher biases; no human-audited error rates or calibration analyses are provided.
- Verification pipeline reliability: The multi-agent teacher workflow for fact-checking lacks ground-truth benchmarking (precision/recall on verification points, false positive/negative rates) and analysis of failure modes under noisy or conflicting sources.
- Adversarial and robustness testing: No evaluation against prompt injection, misleading websites, conflicting sources, or adversarial evidence; robustness to dynamic, changing web content is unassessed.
- Tool ecosystem scope: The RL environment is described as multi-tool/multimodal, but the exact tool set, modalities, APIs, and their failure profiles are unspecified; capabilities for code execution, data analysis, or structured retrieval are not clarified.
- Long-context utilization: While 128K context is supported, there is no analysis of how much context is effectively used, context management strategies (e.g., memory pruning, chunking), or degradation with very long inputs.
- Cost and latency accounting: “Cost-efficiency” claims lack a transparent cost model (hardware, token prices, tool fees, caching efficiency), inference latency metrics, and trade-offs under real user budgets and SLAs.
- RL reward alignment: The rubrics-judge training and binary reward mapping may encourage over-optimization to the learned judge; there is no evaluation of reward hacking, overfitting to rubric artifacts, or generalization to human judges unseen during training.
- Judge model validity: The trained Rubrics Judge’s agreement with diverse human experts (not just the strong LLM) is unreported; inter-rater reliability, calibration curves, and robustness across task types are missing.
- Sparse, terminal rewards: The RL formulation uses terminal rubric rewards with but does not present techniques for credit assignment in long horizons or compare alternative reward-shaping/auxiliary objectives.
- PPO configuration and stability: Key RL hyperparameters (learning rates, KL constraints, value loss weights, rollout lengths), sample efficiency, training stability indicators, and comparisons to alternative algorithms (e.g., GRPO, DPO, critic-free methods) are absent.
- Safety and governance in RL: There are no safety constraints, off-policy filtering, or guardrails reported for tool use during on-policy exploration; risk of producing unsafe or non-compliant web interactions is not addressed.
- Generalization to unseen domains: The model’s performance on domains not represented in mid-training/SFT (e.g., biomedical, legal, or niche industry verticals) and under temporal shift (e.g., rapidly evolving topics) is unreported.
- Human-centered evaluation: Beyond Elo ratings, there is no user study on usability, trust, calibration, or citation traceability; the link between rubric scores and perceived usefulness is not empirically validated with end users.
- Statistical rigor in comparisons: Elo evaluation lacks details on annotator pool, inter-rater agreement, match sampling, tie handling, and significance tests; fairness of comparisons across models with different toolsets and context limits is unclear.
- Ablations on training stages: The contribution of each stage (mid-training vs SFT vs RL) and each data component (planning vs deep search vs reflection vs reporting) is not quantified via controlled ablations.
- Hallucination and citation accuracy: Claims of reduced hallucination and improved cross-source verification are not backed by standardized hallucination/citation-accuracy metrics or error analyses.
- Scalability and transfer: How the approach scales to smaller/larger base models, and the compute–performance trade-offs (tokens, GPU-hours, energy) across stages, are not reported.
- Continual learning and freshness: There is no mechanism for updating the model with new web knowledge, handling concept drift, or preventing catastrophic forgetting while preserving learned capabilities.
- Single-agent limitations: The choice of a streamlined single-agent (ReAct-style) design is motivated, but scenarios where multi-agent parallelism or specialized roles outperform single-agent are not explored.
- Privacy and compliance: Use of “desensitized real data” and live web tools raises unanswered questions about data privacy, licensing, and compliance; auditing and redaction procedures are not specified.
- Ethical and citation practices: The system’s handling of plagiarism, attribution fidelity, and fair-use compliance (e.g., automated citation verification, quotation boundaries) is not evaluated.
- Tool-budgeted planning: Although budgets are imposed, there is no analysis of budget-aware planning policies, optimal allocation across subgoals, or sensitivity to budget changes.
- Domain-specific capabilities: For software engineering and data-heavy tasks, the presence of code execution, test harnesses, or dataset analysis tools is unclear; performance on tasks requiring executable verification is untested.
- Open-sourcing plan: The availability of the model, ADR-Bench, data synthesis pipelines, prompts, and code is not stated; without releases, community verification and adoption are hindered.
- Failure case taxonomy: The paper lacks a systematic error taxonomy or qualitative case studies highlighting where the agent fails (e.g., planning collapse, verification blind spots), limiting targeted improvements.
- Theoretical grounding: Beyond high-level framing, there is no principled analysis (e.g., sample complexity, action-space reduction bounds, or convergence guarantees) linking atomic-action design to learning efficiency in long-horizon RL.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s internalized “atomic capabilities,” streamlined single-agent ReAct-style design, cost-control techniques, and rubric-aligned training. Each item names potential sectors and products/workflows, and notes key dependencies.
- Industry: Evidence-grounded market and competitor research
- Sectors: Finance, enterprise strategy, consulting, marketing
- What: Generate structured, citation-rich reports (market sizing, competitor deep dives, pricing analyses, vendor risk assessments) with cross-source verification and reflection to reduce hallucinations.
- Tools/products/workflows: “Research Ops” assistant integrated with web search, internal knowledge bases, and report templates; auto-citation insertion in analyst briefs; cached queries and tool-call budgets to cut cost.
- Dependencies: Reliable web/search APIs and access rights; internal document connectors; governance for citation standards; monitoring for tool failures and reflection loops.
- Finance: Drafting and validating investment theses and research notes
- Sectors: Sell-side/buy-side research, PE/VC, corporate finance
- What: Rapidly draft investment notes and due-diligence memos with explicit rubrics (thesis clarity, risks, catalysts) and hard constraints (source traceability, sensitivity to assumptions).
- Tools/products/workflows: Rubric-guarded report generator; “shortest-correct-trajectory” retrieval patterns for efficient evidence gathering; ADR-Bench-style Elo evaluations in-house to rank agents.
- Dependencies: Compliance approval for external content use; proprietary data entitlements; domain rubrics authoring; human-in-the-loop for material nonpublic information risks.
- Software engineering: Architecture and design documentation assistance
- Sectors: Software, IT services
- What: Generate ADRs (Architecture Decision Records), RFCs, and design reviews from heterogeneous sources (issue trackers, READMEs, API docs), with plan-first decomposition and verification of conflicting references.
- Tools/products/workflows: Single-agent research bot in dev portals; “verification points” extraction for requirements; cached doc queries; plan consistency checks during SFT-style inference.
- Dependencies: Access to internal repos and documentation; PII/security filtering; robust long-context inference for large code/design artifacts.
- Policy and public sector: Fact-checking and rapid evidence briefs
- Sectors: Government, think tanks, media
- What: Fact-check claims via the “Deep Verification Workflow” (extract-plan-verify-replan-report), produce concise briefs on legislation, budgets, or geopolitical events with explicit support/refute labels and evidence bundles.
- Tools/products/workflows: Fact-checking desks with verification-point triplets and a trained rubrics judge; audit trails for each claim.
- Dependencies: Up-to-date sources; adjudication for ambiguous claims; transparency requirements; secure handling of sensitive materials.
- Academia: Literature review and survey drafting with robust citations
- Sectors: Higher education, R&D labs
- What: Generate domain-style survey sections (background, taxonomy, gaps) using the paper’s mid-training approach for report structure and terminology, and enforce style/rubric compliance.
- Tools/products/workflows: “Survey writer” with plan-alignment checks; automatic bibliography; source triangulation to reduce mis-citation.
- Dependencies: Access to publisher APIs/preprints; discipline-specific rubrics; human validation for nuanced interpretations.
- Enterprise knowledge management: Internal wiki consolidation and Q&A
- Sectors: Cross-industry
- What: Synthesize multi-source internal documents into authoritative pages with verifiable citations and versioned evidence; answer complex internal queries with cross-source checks.
- Tools/products/workflows: Research bot integrated with document stores; reflection/error loops on tool errors; doc freshness checks.
- Dependencies: Connectors to ECM/knowledge bases; access control; content governance; retention and provenance policies.
- Consumer and daily life: Source-backed decision guides
- Sectors: Consumer internet
- What: Produce transparent, cited guides (appliance buying, travel planning, learning roadmaps), clearly flagging doubtful/conflicting information.
- Tools/products/workflows: “Evidence-first” personal research assistant; budgeted web calls; simplified rubrics (coverage, recency, neutrality).
- Dependencies: Clear disclaimers for medical/financial/legal topics; safe browsing; periodic re-verification as content changes.
- Agent evaluation and procurement: ADR-Bench-style testing for Chinese scenarios
- Sectors: AI vendors, enterprises adopting agents
- What: Use the ADR-Bench protocol (Elo, multi-dimensional criteria) to compare deep-research agents on commercial research, policy analysis, and software engineering tasks.
- Tools/products/workflows: Internal benchmarking harness; rubric templates; human adjudication tie-breakers.
- Dependencies: Task curation for organizational domains; evaluator training; coverage for non-Chinese locales if needed.
- Data generation for model improvement: Atomic-capability data synthesis
- Sectors: AI/ML engineering, MLOps
- What: Reproduce reverse-engineered planning data from expert reports; graph-based multi-hop task synthesis; error-reflection loop logs; verification trajectories for SFT.
- Tools/products/workflows: Data pipelines that implement seed collection, difficulty filtering (e.g., QwQ-32B-style gate), plan-consistency filters, and trajectory deduplication.
- Dependencies: Rights to use source materials; compute budget; safety filters; domain adaptors.
- Cost optimization of agent deployments
- Sectors: All deploying agentic systems
- What: Apply caching for high-cost retrievals, explicit tool-call and token budgets, and “correct-and-shortest” trajectory pruning to lower inference costs without degrading outcomes.
- Tools/products/workflows: Centralized cache service; per-episode budget policies; telemetry dashboards on tool efficiency.
- Dependencies: Observability stack; cache invalidation policies; rate-limit management with search providers.
Long-Term Applications
These applications are enabled by the paper’s rubric-based RL in real tool environments, medium-scale cost efficiency, and atomic-capability internalization, but require further domain adaptation, scaling, safety, or integration work.
- Healthcare: Clinical evidence synthesis and guideline drafting
- Sectors: Healthcare, pharma
- What: Systematically synthesize RCTs/observational studies, rate evidence quality, and draft guideline sections with explicit verification points and adverse evidence.
- Tools/products/workflows: “Evidence-to-recommendation” pipeline with medical rubrics and judge models; integration with PubMed, trial registries.
- Dependencies: Regulatory clearance; medical expert oversight; domain-specific rubrics and judge calibration; robust handling of retractions and updates.
- Legal research and compliance automation
- Sectors: Legal, compliance, regtech
- What: Multi-jurisdictional statute/case-law synthesis with conflict detection; draft memos with provenance trails; ongoing regulatory change monitoring.
- Tools/products/workflows: Legal-grade rubrics (precedent relevance, jurisdiction, holdings); authenticated legal databases; audit-ready verification workflows.
- Dependencies: Licensed legal corpora; privilege and confidentiality controls; liability frameworks; conservative guardrails.
- Scientific discovery copilots
- Sectors: Materials science, chemistry, bioinformatics
- What: Generate research blueprints (hypotheses, protocols, measurement plans), chain-of-thought verification against literature, and negative-result-aware planning.
- Tools/products/workflows: Lab-in-the-loop RL with tool APIs (ELNs/LIMS); domain KG augmentation; reflection loops for experimental failures.
- Dependencies: High-fidelity lab integration; safety for suggested procedures; domain-specific rubrics and simulators for reward shaping.
- Government horizon scanning and risk analysis
- Sectors: National security, public policy
- What: Autonomous monitoring of policy/tech trends, early-warning briefs with cross-lingual sources, and scenario planning with explicit evidence weights.
- Tools/products/workflows: Multi-source ingestion (media, think tank, social platforms); “implicit/negative rubric” penalties to avoid sensationalism; provenance dashboards.
- Dependencies: Access to diverse data streams; disinformation robustness; human governance and escalation processes.
- Enterprise-wide “ResearchOps Platform”
- Sectors: Large enterprises, BPO/KPO
- What: Shared platform standardizing plan–seek–verify–report workflows, rubric libraries per function (marketing, finance, legal), and judge models for QA and SLA enforcement.
- Tools/products/workflows: Rubric RL service; report conformance scoring; template catalogs; cost-governed tool orchestration.
- Dependencies: Change management; rubric authoring/maintenance; integration with identity, data catalogs, and DLP.
- Education: Personalized research tutors and assessment
- Sectors: EdTech, higher education
- What: Tutor agents that teach research method (decomposition, verification, synthesis), and automated grading of research reports via rubric-aligned judges with formative feedback.
- Tools/products/workflows: Course-specific rubric banks; explainable judge feedback; plagiarism/provenance checks.
- Dependencies: Academic integrity policies; bias/false feedback mitigation; content access constraints.
- Misinformation forensics and provenance standards
- Sectors: Media, platforms, cybersecurity
- What: Industrial-scale triage of viral claims, with structured verification points, weighted evidence, and machine-auditable provenance trails.
- Tools/products/workflows: Open rubric schemas for evidentiary standards; cross-platform evidence linking; appeals/review workflows.
- Dependencies: Platform cooperation; legal processes; adversarial robustness; multilingual coverage.
- Sector-specific “atomic capability” SDKs
- Sectors: AI platform providers
- What: Exportable libraries/templates for planning, verification, and report composition tailored to domains (e.g., ESG, supply chain, safety engineering).
- Tools/products/workflows: Capability modules, plan-consistency checkers, and judge fine-tuning kits; synthetic data blueprints (reverse-engineered plans, KG-based tasks).
- Dependencies: Domain SMEs for rubric authoring; dataset curation; licensing for pretrained bases.
- Multimodal and on-device research agents
- Sectors: Field operations, robotics, mobile
- What: Agents that incorporate PDFs, tables, images, and sensor data into research loops; compressed/distilled variants for edge devices with offline caching.
- Tools/products/workflows: Multimodal tool APIs; context management for 128K-equivalent memory; cost-aware tool selection.
- Dependencies: Model compression/distillation to sub-10B scales; energy constraints; privacy-by-design for local data.
- Standardized evaluation ecosystems (beyond ADR-Bench)
- Sectors: AI evaluation, standards bodies
- What: Cross-lingual, multi-domain benchmarks with Elo + rubric scoring, including real-world tasks (policy analysis, engineering design, compliance audits).
- Tools/products/workflows: Community-driven rubric repositories; judge model leaderboards; reproducible agent traces.
- Dependencies: Broad task coverage; human–LLM alignment for scoring; open data licensing and red-teaming.
Assumptions and cross-cutting dependencies for feasibility:
- Model and infrastructure: Access to a medium-scale 32B model with 128k context (or equivalent via retrieval), and sufficient inference throughput; secure tool-call orchestration with observability.
- Data and rights: Licenses to crawl/use web and proprietary data; PII/compliance controls; ongoing source freshness and re-verification.
- Rubric quality: Domain-specific rubric authoring and maintenance critically determine judge reliability and RL signal quality.
- Human oversight: Expert-in-the-loop for high-stakes domains (healthcare, legal, finance); clear escalation and accountability.
- Generalization and safety: Synthetic data coverage must match target domains; adversarial robustness, bias, and hallucination controls remain active areas for further research.
Glossary
- Action Subspace: A reduced set of permissible actions the model operates in to simplify decision-making during training. "form a compact action subspace"
- ADR-Bench: An application-driven benchmark for evaluating deep research systems in realistic Chinese scenarios. "We therefore build ADR-Bench (Application-driven Deep Research Benchmark), spanning commercial research, policy analysis, and software engineering."
- Agent Trace: The recorded sequence of agent actions and decisions throughout a verification or research process. "recording the complete execution path as an Agent Trace."
- Agentic Mid-Training: A training phase that injects agent-specific capabilities before supervised fine-tuning. "synthesize targeted data for agentic mid-training"
- Agentic Reinforcement Learning: RL setup tailored for autonomous agents operating with tools and long-horizon tasks. "Agentic Reinforcement Learning"
- Atomic Action: A discrete, high-level operation the model selects instead of next-token prediction. "deciding the next Atomic Action,"
- Atomic Capabilities: Transferable high-level skills (e.g., planning, verification) that underpin agent behavior. "We define ``Atomic Capabilities'' as a set of transferable, high-level action abstractions"
- BM25: A classic term-frequency based retrieval function used for ranking documents. "combining BM25 and dense vector reranking."
- Breadth-First Search (BFS): A graph traversal strategy expanding nodes level by level from a starting seed. "Subsequently, we perform BFS expansion centered on the seed"
- BrowseComp: A benchmark of multi-hop, fact-finding questions assessing retrieval depth. "BrowseComp~\cite{wei2025browsecomp} contains 1,266 fact-finding questions requiring multi-hop reasoning"
- CN-DBpedia: A Chinese knowledge graph used for building complex reasoning tasks. "open-source knowledge graphs such as Wikidata5m~\cite{wang2021KEPLER} and CN-DBpedia~\cite{2017CN}."
- Context-Length Scheduling: A curriculum strategy that gradually increases the maximum context window during training. "through carefully constructed data distributions and context-length scheduling"
- Cross-Source Verification: Validating information by checking consistency across multiple independent sources. "information gathering and cross-source verification"
- Curriculum Learning: Structuring training progression from simpler to more complex tasks to stabilize learning. "autonomous curriculum learning"
- DeepResearch Bench: A dataset of PhD-level open-ended research tasks evaluating report and retrieval quality. "DeepResearch Bench~\cite{du2025deepresearch} comprises 100 PhD-level research tasks spanning 22 domains"
- Dense Vector Reranking: Using embeddings-based similarity to refine retrieval results after initial ranking. "combining BM25 and dense vector reranking."
- Elo Ratings: A comparative scoring system to evaluate model performance via head-to-head judgments. "Step-DeepResearch consistently leads in Elo ratings across all dimensions"
- Error-Reflection Loop: A synthesis pipeline where the model reflects on errors and iteratively corrects its trajectory. "The Error-Reflection Loop"
- FACT framework: An evaluation framework focusing on information retrieval capability. "evaluating report quality through the RACE framework and information retrieval capabilities through the FACT framework."
- Few-shot Prompt: A prompting technique that supplies a handful of examples to guide behavior. "use a Few-shot Prompt to guide a Web Search Agent"
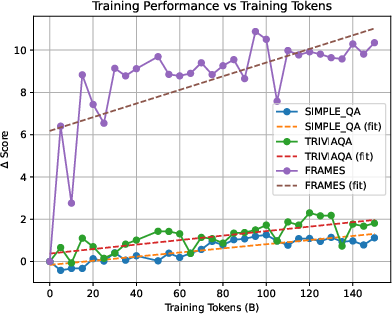
- FRAMES: A benchmark measuring agent-related and structured reasoning capabilities. "with particularly significant gains on FRAMES"
- GAE (Generalized Advantage Estimation): A method for estimating advantages in RL to reduce variance and stabilize training. "For advantage estimation, we use Generalized Advantage Estimation (GAE):"
- GRPO: A specific reinforcement learning approach applied to end-to-end web environments. "conducts end-to-end RL training via GRPO in real web environments"
- HLE (Humanity's Last Exam): A multidisciplinary benchmark of expert-level questions emphasizing knowledge testing. "HLE (Humanity's Last Exam)~\cite{hendrycks2025hle} includes 2,500 expert-level questions"
- Hindsight: Using the final output or abstract structure of a report to guide plan synthesis. "utilizing the abstract structure as a form of ``Hindsight,''"
- Importance Ratio: The probability ratio used in PPO to measure policy update magnitude. "Among these, the importance ratio is"
- KL-constrained Policy Updates: RL updates bounded by Kullback–Leibler divergence to ensure stable policy changes. "KL-constrained policy updates"
- Knowledge Graph: A structured representation of entities and relations used for complex reasoning tasks. "triplets in knowledge graphs are often lossy"
- Mid-training: An intermediate training stage between pre-training and SFT to inject agent capabilities. "mid-training follows a curriculum"
- Multi-Agent Teacher Workflow: A coordinated set of specialized agents (Extract, Plan, Verify, Replan, Report) for verification. "We constructed a Multi-Agent Teacher Workflow to simulate the verification process of human experts"
- Multi-hop Reasoning: Chaining multiple inference steps or sources to answer complex queries. "requiring multi-hop reasoning"
- Objective Consistency Verification: A check ensuring synthesized tasks, rubrics, and hidden summaries align. "we implement an objective consistency verification step"
- On-policy RL: Reinforcement learning that updates the policy using data generated by the current policy. "with on-policy RL."
- Pareto Optimality: Balancing trade-offs to achieve optimal retention of skills and planning clarity simultaneously. "To achieve Pareto optimality between
retention of key skills'' andclarity of planning logic,''" - PPO (Proximal Policy Optimization): A stable on-policy RL algorithm using clipped objective functions. "using the clipped Proximal Policy Optimization (PPO) objective:"
- QwQ-32b: A baseline model used to filter out tasks that are too easy under a default framework. "we use QwQ-32b~\cite{qwq32b} as a difficulty filtering model."
- RACE framework: An evaluation framework focusing on research report quality. "evaluating report quality through the RACE framework"
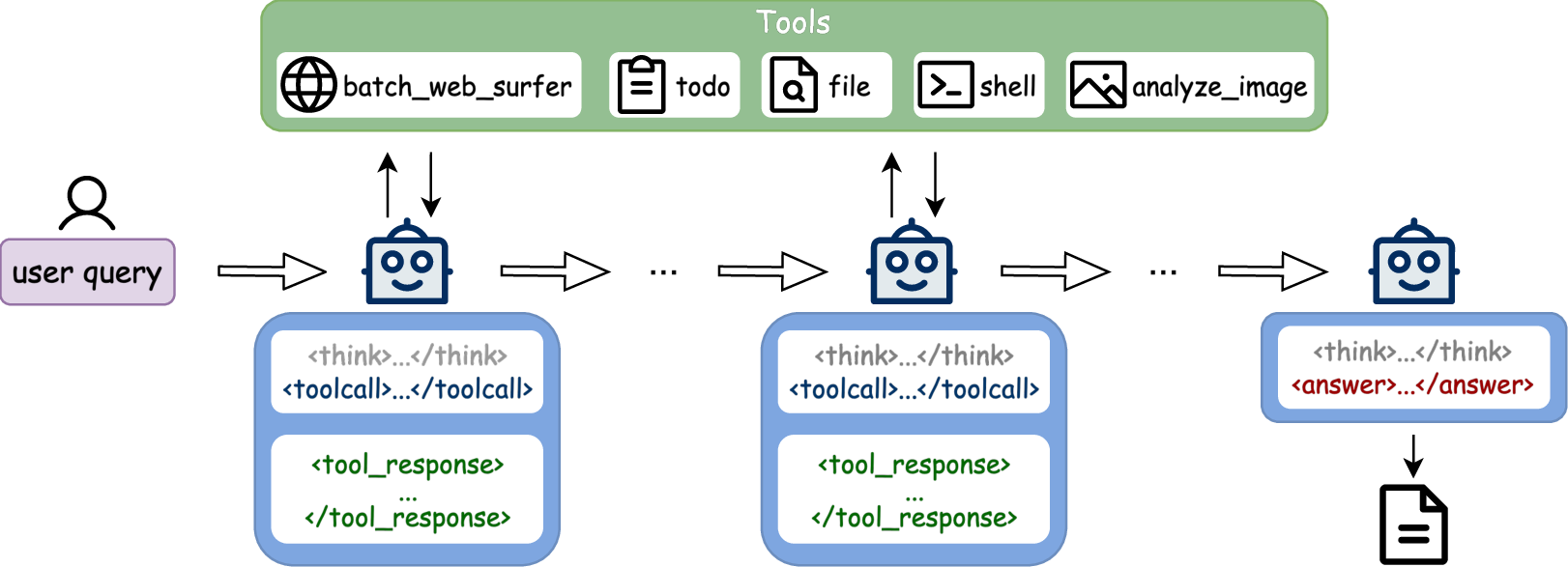
- ReAct: A single-agent approach combining reasoning and acting with tool calls in sequence. "For agents implemented using approaches like ReAct"
- Reinforcement Learning (RL): Optimization via trial-and-error interactions with an environment to improve decision policies. "and then to reinforcement learning."
- ReportBench: A benchmark reverse-engineered from expert survey papers to assess citation and consistency. "ReportBench~\cite{li2025reportbench} reverse-engineers research questions"
- ResearchRubrics: A benchmark with fine-grained expert rubrics for scoring research tasks. "ResearchRubrics~\cite{sharma2025researchrubrics} contains 101 domain-diverse research tasks"
- Rubric-based Reinforcement Learning: Using rubric-derived scores as reward signals to optimize report quality. "This rubric-based reinforcement learning enhances the model's abilities in active planning"
- Rubrics Judge: A trained model that scores reports against rubrics and provides rewards for RL. "training the Rubrics Judge model."
- Seed Nodes: Selected low-degree entities used as starting points for subgraph construction. "screen non-generic entities with small degrees (3-10) as ``seed nodes''"
- Semantic Drift: Deviation from intended meaning during expansion or traversal in graphs or retrieval. "To prevent semantic drift, we enforce truncation on super nodes"
- Sparse Terminal Rewards: RL settings where rewards are received only at the end of long sequences. "long-horizon sequence generation and sparse terminal rewards."
- Strict Reward Mapping: A binary conversion of rubric judgments to reduce noise and stabilize optimization. "Strict Reward Mapping."
- Subgraph Sampling: Selecting a subset of nodes and edges from a larger knowledge graph to build tasks. "we performed controlled subgraph sampling on open-source knowledge graphs"
- Super Nodes: Extremely high-degree nodes that can cause drift; truncated to maintain coherence. "super nodes with degrees exceeding a threshold"
- System Prompt: A specialized instruction to enforce formatting and structure in generated reports. "we employ a specialized System Prompt to regenerate the report"
- Ternary Grading: A three-level judgment scheme (fully/partially/not satisfied) used in rubric evaluation. "under ternary grading"
- Tool-augmented Reasoning: Integrating external tools into reasoning steps to handle complex tasks. "tool-augmented reasoning"
- Topology Walk: Traversing document hyperlinks to discover related information without a predefined target. "perform a Topology Walk within the document index."
- Trajectory Consistency Filtering: Removing trajectories that deviate from a preset plan despite task completion. "we apply trajectory consistency filtering to the generated data."
- Verification Point: A decomposed factual unit (time, location, subject, data) to be validated. "converting them into independent Verification Points."
- WebRL: A methodology proposing curriculum learning and KL-constrained updates for web environments. "WebRL~\cite{webrl2025}, which proposes autonomous curriculum learning and KL-constrained policy updates"
- Wiki-doc: A custom index library leveraging natural hyperlinks for associative retrieval. "a custom index library, Wiki-doc."
- Wikidata5m: A large-scale knowledge graph used to construct multi-hop reasoning tasks. "open-source knowledge graphs such as Wikidata5m~\cite{wang2021KEPLER}"
Collections
Sign up for free to add this paper to one or more collections.

