ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Abstract: Evaluating progress in LLMs is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9\% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ProfBench, a new way to test how well LLMs—AI systems like advanced chatbots—handle real-world, professional tasks. Instead of short, quiz-like questions (like math problems), ProfBench asks models to read professional documents and write detailed reports in fields such as physics, chemistry, finance, and consulting. It also builds fair, low-cost “LLM-Judges” that grade these reports using expert-made checklists (called rubrics).
Key Questions the Paper Tries to Answer
To make this accessible, think of the paper as trying to answer three simple questions:
- Can we create a realistic, expert-level test that AI models must pass to be useful in the real world?
- How can we grade long, complex AI-written reports fairly and cheaply?
- Which kinds of AI models do best on professional tasks, and what helps them improve?
What Methods Did the Researchers Use?
To keep things simple, imagine a teacher grading a long essay using a checklist. ProfBench works much like that—except the “teacher” can be either a human expert or an AI judge.
Building the ProfBench Benchmark
- Human experts with advanced degrees (PhDs and MBAs) designed 80 challenging tasks across four domains: Chemistry, Physics, Finance, and Consulting.
- For each task, they wrote a detailed rubric—a checklist of 15–60 criteria that a good answer should meet. Each criterion has:
- A clear description (what to look for)
- A justification (why it matters)
- An importance level (from “additional” to “critical”)
- They then scored sample AI responses from top models, marking each criterion as “Yes” (met) or “No” (not met), with short explanations.
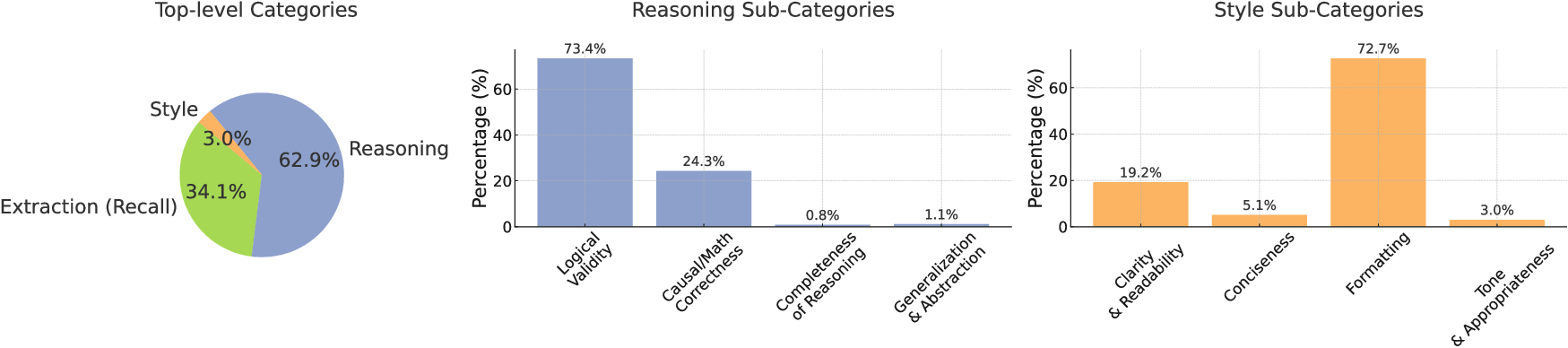
In total, ProfBench includes 7,347 “response-criterion” pairs (one model response evaluated against one rubric item). Most criteria check reasoning (about 63%), many check information extraction (about 34%), and some check writing style and clarity (about 3%).
How AI Judges Grade Responses
- The AI judge is given:
- One model’s response
- One rubric criterion (e.g., “Does the response explain the main risk clearly?”)
- It must answer “Yes” or “No.”
- The paper checks how often the AI judge agrees with human experts using a balance-focused score called Macro-F1. You can think of it like: “How fair and accurate is the judge across both ‘Yes’ and ‘No’ decisions?”
- They also measure bias. Some AI judges tend to favor responses from their own “family” (like a brand rooting for its own team). The paper tracks a “bias index” to see if a judge unfairly boosts one provider’s models compared to others.
- Finally, they measure cost—how many tokens (like word-pieces) are used and how many dollars it takes to run judging at scale.
The team tested different styles of judges:
- Non-reasoning judges: give quick “Yes/No” decisions cheaply.
- Reasoning judges: think through problems step-by-step (internally) before deciding; more accurate but more expensive.
Testing AI Models as Report Writers
- Models were asked to read task prompts and supporting documents (“grounding documents”), then write a comprehensive report.
- The best-performing AI judge (chosen for fairness and cost) graded each report by checking how many rubric criteria it met, weighted by importance (critical criteria count more).
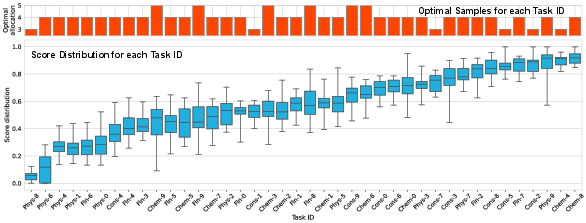
- To get stable results, each model generated 16 responses per task, and the scores were averaged.
- To reduce cost, they used a smart strategy: give more tries to tasks where scores vary a lot and fewer tries to tasks where scores are stable. This is like spending more practice time where you struggle and less where you’re already consistent.
Main Findings and Why They Matter
Here are the main takeaways, explained simply:
- ProfBench is hard, even for top AI models.
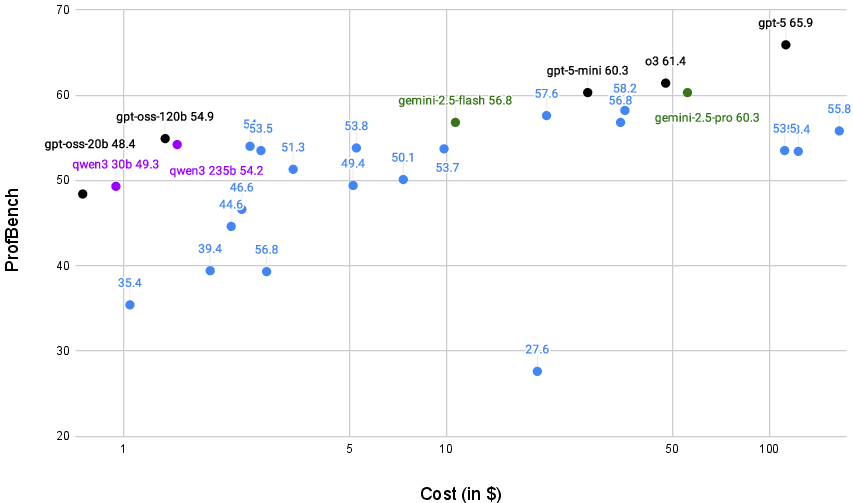
- The best model reached about 66% overall. That’s much lower than scores on math or coding tests, meaning real-world professional tasks are tougher.
- Closed-source (proprietary) models generally perform better than open-weight (open-source) ones.
- The gap depends on the field. It’s small in physics, bigger in chemistry and consulting, and largest in finance. This shows some domains need more targeted training, especially for open-source models.
- “Thinking” (step-by-step internal reasoning) helps—up to a point.
- Enabling thinking usually improves grading and report quality a bit, but the boost varies and can increase bias (favoring certain model families). Moderate thinking effort often works best.
- Bigger models often do better—but size alone isn’t enough.
- Improvements slow down as models get much larger. Training methods and post-training fine-tuning matter a lot.
- The AI judges can be both fair and cheap.
- The team found an open-weight judge configuration that matched top proprietary judges in accuracy while being about 50–60 times cheaper.
- Overall, their judging method reduced evaluation costs by 100–1000× compared to similar benchmarks, making it accessible to more researchers and teams.
- Longer answers aren’t always better.
- Writing extremely long reports doesn’t guarantee higher scores. Good coverage and clear reasoning matter more than just length.
What Does This Mean for the Future?
- Real-world testing: ProfBench shifts AI evaluation toward the kinds of tasks professionals do—reading complex materials, synthesizing information, and writing detailed reports.
- Fairer grading: The paper shows how to build AI judges that are accurate, less biased, and affordable, so more people can evaluate and improve their models.
- Training priorities: The results suggest that models need stronger domain knowledge and better training in chemistry, consulting, and especially finance—beyond just math and coding practice.
- Better tools for the community: Because ProfBench is public and cost-effective, it can help the open-source world catch up and innovate in professional domains.
- Smarter evaluation: Using rubrics (checklists) makes complex tasks verifiable, which can feed into better training methods that reward models for meeting real-world criteria (not just getting one “right answer”).
Simple Summary
- ProfBench is like a tough, real-world exam for AI models, created by experts and graded with detailed checklists.
- It tests whether AI can do grown-up jobs: read complicated documents, think clearly, and write strong reports.
- The paper also builds AI “judges” that grade fairly, avoid favoritism, and keep costs low.
- Even the best AI today scores around two-thirds—good, but with lots of room to improve.
- This benchmark will help researchers focus on what matters: professional skills, fair evaluation, and making high-quality AI more accessible to everyone.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Domain scope: The benchmark only covers four domains (Chemistry PhD, Physics PhD, Finance MBA, Consulting MBA); it is unclear how well rubrics and judges generalize to other professional fields (e.g., law, medicine beyond patient-chat, engineering, public policy).
- Language constraint: All tasks and evaluations are in English; cross-lingual robustness and performance (e.g., Chinese, Spanish, Arabic) remain untested.
- Modality limitation: The benchmark is text-only, while many professional tasks require multimodal reasoning (tables, figures, diagrams, spreadsheets, code). How to design and verify multimodal rubrics is left open.
- Grounding documents transparency: The process for selecting, curating, and standardizing grounding documents per task is insufficiently specified (e.g., source lists, document versions, length constraints, retrieval strategy). Reproducibility of the document sets needs to be established.
- Prompt omission in judging: Judges do not receive the original task prompt, assuming criteria are self-contained. The effect of including the prompt (or partial context) on judge accuracy and bias is not analyzed.
- Binary criterion scoring: Criteria are judged Yes/No, which cannot capture partial fulfillment or degree of adequacy. The utility of graded scales (e.g., 0–3) and their impact on reliability, calibration, and fairness remains unexplored.
- Importance weights validity: Criterion importance weighting (1–4) used for report scoring lacks validation beyond a small three-model check. There is no inter-annotator agreement study on importance assignment or exploration of alternative weighting schemes (e.g., learned weights, IRT-based).
- Rubric quality assurance: Inter-annotator agreement is reported for response-criterion fulfillment (Fleiss’ κ=0.912 on 1,127 pairs), but there is no reliability study for rubric creation itself (e.g., agreement on criterion definitions, justifications, importance).
- Annotator bias and diversity: The paper does not quantify how annotator demographics, backgrounds, or vendor processes may bias prompt and rubric design. Methods to detect and mitigate such biases are not presented.
- Bias-index generalization: The self-enhancement bias metric is computed using only three model responses (o3, Grok4, R1-0528). Whether the bias-index remains stable across a broader, more diverse set of model providers and families is unknown.
- Judge debiasing methodology: Bias-reduction is achieved via model selection and effort-level tuning rather than principled debiasing algorithms (e.g., ensemble judges, adversarial calibration, cross-provider anchoring). Systematic methods to train neutral judges are not evaluated.
- Reliance on LLM judges: Robustness of judges to specification gaming (e.g., rubric keyword parroting, adversarial formatting), hallucinations, and distribution shifts is not tested. No adversarial stress tests or human-in-the-loop checks are provided.
- Public/private split and contamination: Only half the dataset is public to mitigate test contamination; there is no plan for rotating fresh test sets, contamination audits, or measures for sustained benchmark integrity as models are trained on the public half.
- Retrieval and evidence verification: Judges do not perform web search or source verification; extraction criteria may be incorrectly marked fulfilled based solely on the response. Evidence-anchored judging (e.g., citation checking) is not implemented.
- Effect of extended thinking on bias: While increased “thinking” often improves alignment with humans, it can raise bias toward certain providers. The causal mechanisms, trade-offs, and normalization strategies (e.g., bias-aware reasoning limits) are not established.
- Length vs. quality causality: The analysis of verbosity suggests limited gains, but causality is unclear. Per-criterion content coverage controls, compression/summarization strategies, and length-normalized scoring are not investigated.
- Criterion taxonomy gaps: Extraction lacks meaningful subcategories, and Style is underrepresented (3%). A richer taxonomy (e.g., evidence, citation, data quality, structure, formatting, tone) could improve interpretability and targeted training but is not developed.
- Item difficulty/discrimination: No psychometric analysis (e.g., item response theory) quantifies criterion difficulty or discriminative power across domains; without this, optimization of task mixes and learning curricula is hindered.
- Training with ProfBench: The paper does not study whether fine-tuning or RL with ProfBench rubrics improves model performance, reduces bias, or generalizes to other professional tasks; overfitting risks and transfer are open questions.
- Outcome validity: It is not shown that higher rubric fulfillment correlates with real-world utility (e.g., expert end-user ratings of decision quality, actionable correctness). External validation with professional practitioners is needed.
- Fairness across context windows: Models have differing context limits (32k–64k tokens), potentially confounding performance comparisons. Normalized evaluation regimes (or stratified analyses by window size) are missing.
- Cross-task aggregation: The overall score aggregation across tasks/domains may obscure uneven task difficulty and criterion density; alternative aggregation methods (e.g., domain-balanced weighting, variance-aware weighting) are not evaluated.
- Optimal allocation details: The dynamic programming approach for sample allocation is referenced but lacks formal problem specification, constraints, and code. Generalizability across models and tasks and sensitivity to budget changes remain untested.
- Prompt template sensitivity: Judge prompt template selection via early experiments with GPT-4.1 is mentioned but not documented; sensitivity analyses across templates and instruction formats are absent.
- Licensing and ethics: While annotator compensation is described, the licensing status of collected grounding documents and downstream usage constraints (copyright, compliance) are not detailed; an ethics and licensing audit is needed.
- Adversarial robustness: There are no experiments with deliberately adversarial or deceptive responses (e.g., confident but wrong narratives, rubric-targeted exploits) to determine judge susceptibility and benchmark resilience.
- Class imbalance and metrics: Macro-F1 is used for judging, but class balance, confusion matrices, and alternative metrics (balanced accuracy, MCC, calibration curves) are not reported; judge calibration remains unassessed.
- Update cadence and maintenance: Plans for benchmark updates (new domains, fresh rubrics, refreshed document sets) and governance (versioning, leaderboards, test-set rotation) are not specified.
Practical Applications
Immediate Applications
The following applications can be implemented now, using the paper’s dataset, code, and evaluation methods to improve real-world AI systems and workflows.
- Enterprise model evaluation and selection for professional workflows
- Sector: finance, consulting, scientific R&D (chemistry, physics), software
- What to do: use ProfBench’s expert rubrics and the low-bias, low-cost LLM-Judge to benchmark candidate models against tasks that mirror professional deliverables (e.g., investment memos, client strategy write-ups, literature reviews).
- Tools/products/workflows: Evaluation harness (ProfBench repo), “Judge API” with GPT-OSS-120B mixed reasoning, Bias-Index Audit Dashboard (Macro-F1 minus Bias-Index), price–performance model selection dashboard.
- Assumptions/dependencies: English, text-only tasks; access to model endpoints and token budgets; rubrics representative of target domain; acceptance of Bias-Index as a fairness metric.
- Quality gates for AI-generated reports and client deliverables
- Sector: finance (risk, securitization, ratings), consulting (memo style, structured reasoning), chemistry/physics (units, citations, methodological rigor)
- What to do: insert rubric checks as pre-delivery gates; automatically verify extraction (facts, figures), reasoning (logical validity), and style (formatting and clarity) before releasing outputs.
- Tools/products/workflows: “Rubric QA Gate” microservice; CI/CD integration for LLM content; RAG-output validation against extraction criteria; importance-weighted scoring (critical/minor).
- Assumptions/dependencies: judge reliability on target content; curated rubrics that reflect regulatory or client requirements; grounding documents available for RAG tasks.
- Vendor-neutral model governance and procurement
- Sector: finance, healthcare, public sector, enterprise IT
- What to do: standardize AI procurement and audits using Bias-Index thresholds and Macro-F1 agreement with human annotations; avoid self-enhancement bias.
- Tools/products/workflows: Governance playbook; periodic fairness/accuracy audits; audit-ready reports showing bias-index across multiple vendor responses.
- Assumptions/dependencies: agreement on fairness KPIs; multi-vendor response sampling; consistent evaluation templates.
- Cost-optimized continuous evaluation and monitoring
- Sector: AIOps, enterprise AI platforms, MLOps
- What to do: apply the paper’s dynamic programming sample-allocation to reduce evaluation cost by allocating more samples to high-variance tasks and fewer to stable ones.
- Tools/products/workflows: “Cost Optimizer” service; evaluation scheduler with caching; variance-aware sampling policy.
- Assumptions/dependencies: per-task variance estimation; stable task mix; token pricing and caching behavior as assumed; may need periodic re-estimation.
- RAG pipeline tuning with rubric-based metrics
- Sector: software (search/RAG), knowledge management, data platforms
- What to do: use extraction rubrics to score retrieval quality and selection; use reasoning rubrics to assess synthesis quality; iterate on retriever/query transforms and chain-of-thought settings.
- Tools/products/workflows: RAG evaluator module; retrieval diagnostics (precision/coverage against extraction criteria); synthesis scoring tied to reasoning rubric fulfillment.
- Assumptions/dependencies: availability of grounding documents; rubrics decomposed cleanly into extraction vs reasoning checks.
- Rubric-driven RLVR training and evaluation
- Sector: ML engineering, enterprise AI training
- What to do: treat rubric fulfillment as verifiable rewards for reinforcement learning (RLVR), enabling training on complex, multi-criterion professional tasks beyond math/code.
- Tools/products/workflows: RLVR trainer with rubric rewards; evaluation harness for trained checkpoints; curriculum built from rubric categories (extraction/reasoning/style).
- Assumptions/dependencies: reliable judges for reward signals; sufficient compute; licensing and data governance for continued training.
- Academic research and reproducible benchmarking
- Sector: academia, research labs
- What to do: study extended thinking effects, judge bias, model-size/recipe trade-offs; reproduce price–performance comparisons; validate alignment techniques.
- Tools/products/workflows: ProfBench dataset/code; open-weight judges; standardized prompts/templates; low-cost runs via caching.
- Assumptions/dependencies: English-only benchmarking; half-dataset public (contamination controls); token pricing stability.
- Graduate-level education support and automated feedback
- Sector: higher education (MBA, STEM graduate programs)
- What to do: use rubric-based judging for writing assignments (investment memos, technical reviews); provide criterion-level feedback (importance-weighted) to students.
- Tools/products/workflows: LMS plugin integrating rubric checks; assignment-scoring dashboards; iterative feedback loops using reasoning/extraction rubrics.
- Assumptions/dependencies: institutional acceptance; alignment of rubrics with course objectives; safeguards against bias and over-reliance on automated grading.
- Consumer and freelancing checklist assistants
- Sector: daily life, gig work, content creation
- What to do: define user rubrics for complex tasks (e.g., trip planning constraints, client deliverable checklists) and use judge-style checks to verify outputs.
- Tools/products/workflows: “Checklist Copilot” that verifies constraints (opening times, dietary options, formatting requirements) before finalizing recommendations or deliverables.
- Assumptions/dependencies: user-specified rubrics; simplified criteria compared to professional domains; minimal judge bias at consumer scales.
Long-Term Applications
These applications require further research, scaling, domain expansion, standardization, or regulatory integration before broad deployment.
- Standardized certification for AI in professional services
- Sector: healthcare, finance, public sector, legal
- What to do: develop certification and compliance frameworks grounded in rubric-based verification for domain-critical outputs; regulators adopt Bias-Index/fairness thresholds and importance-weighted scoring as acceptance tests.
- Tools/products/workflows: Certification suites, accredited auditor training, compliance APIs.
- Assumptions/dependencies: consensus among regulators and industry; legal codification of rubric standards; ongoing judge bias monitoring.
- Domain and modality expansion (law, medicine, engineering; multimodal)
- Sector: healthcare, law, engineering, design, energy
- What to do: extend ProfBench-style rubrics to multi-modal tasks (text+tables+figures+images), add domain-specific criteria (e.g., legal citations, clinical safety protocols), and integrate web-search/file-upload contexts.
- Tools/products/workflows: ProfBench++ (multimodal datasets), multimodal judges, retrieval policies tailored to domain artifacts.
- Assumptions/dependencies: expert recruitment at scale; data privacy and provenance controls; robust multimodal judge reliability.
- Semi-automated rubric authoring with human-in-the-loop
- Sector: enterprise knowledge ops, education, standards bodies
- What to do: create AI tools that draft criteria from standards and exemplar documents; SMEs refine and approve; maintain rubric libraries over time.
- Tools/products/workflows: Rubric Authoring AI, versioning and approval workflows, rubric marketplaces.
- Assumptions/dependencies: trustworthy rubric generation; auditability; SME availability; governance for updates and drift.
- Bias-resistant judging with formal guarantees
- Sector: model evaluation, governance, fairness research
- What to do: develop ensembles/calibrated judges and debiasing protocols with provable bounds on self-enhancement bias across vendors and domains.
- Tools/products/workflows: FairJudge library, cross-vendor calibration suites, audit trails with statistical guarantees.
- Assumptions/dependencies: methodological advances; diversified response sets; formal bias quantification accepted by stakeholders.
- Rubric-driven training to close domain gaps in open-weight models
- Sector: open-source ML, enterprise AI
- What to do: invest in training data and RLVR curricula for finance/chemistry/consulting to narrow performance gaps with proprietary models; measure gains with ProfBench.
- Tools/products/workflows: domain corpora curation, rubric-reward RLVR, periodic benchmark releases to track progress.
- Assumptions/dependencies: access to high-quality domain data; compute resources; open licensing; long-term community coordination.
- Continuous assurance platforms for AI outputs
- Sector: enterprise software, regulated industries
- What to do: build real-time services that grade, flag, and auto-correct AI outputs in production using rubric checks; enforce gating, escalation, and human review loops.
- Tools/products/workflows: Assurance platforms with streaming evaluation, corrective feedback controllers, policy-driven gates.
- Assumptions/dependencies: latency and cost budgets; robust observability; integration with existing workflows; high judge reliability at scale.
- Accreditation and adaptive learning powered by rubrics
- Sector: education and professional training
- What to do: institutionalize rubric-based, criterion-level feedback and mastery tracking; enable adaptive curricula and competency-based credentials for professional writing and analysis.
- Tools/products/workflows: Accreditor dashboards, adaptive learning pathways, mastery-based grading systems.
- Assumptions/dependencies: institutional buy-in; fairness monitoring; human oversight; standardization across programs.
- Personalized co-pilots that learn user-specific rubrics
- Sector: knowledge work, daily life
- What to do: co-pilots that continuously learn and enforce user/team-specific criteria (style guides, compliance checklists), leveraging bias-aware judges to refine outputs.
- Tools/products/workflows: Personal Rubric Copilot, team style-guide enforcers, collaborative rubric libraries.
- Assumptions/dependencies: privacy and data governance; UX for rubric editing; safe continual learning; on-device or secure cloud execution.
- Policy and sustainability analysis of “thinking” vs. verbosity in AI
- Sector: policy, sustainability, digital infrastructure
- What to do: inform guidelines on when extended thinking is justified versus costly verbosity; balance performance, fairness, and energy consumption in procurement and deployment.
- Tools/products/workflows: policy briefs grounded in ProfBench data, lifecycle assessments for reasoning modes, procurement recommendations.
- Assumptions/dependencies: updated benchmarking across evolving models; reproducible energy/cost metrics; multi-stakeholder consensus.
Glossary
- AIME 25: A prestigious U.S. high-school mathematics competition with fixed-answer problems often used as a target for verifiable evaluation. "such as AIME 25"
- Bias-Index: A fairness metric defined as the difference between the maximum and minimum model bias (relative to human labels) across compared systems. "We formulate a bias-index by first calculating the bias for each model"
- Closed-source model: A proprietary model whose weights and training artifacts are not publicly released. "Are Closed Source Models better than Open Weight ones?"
- Contradiction: In NLI/RTE, a label indicating the hypothesis contradicts the premise; here, that a response does not fulfill a criterion. "Entailment or Contradiction"
- Dynamic programming: An optimization method that solves problems by combining solutions to overlapping subproblems. "we solve it efficiently using dynamic programming."
- Entailment: In NLI/RTE, a label indicating the hypothesis logically follows from the premise; here, that a response fulfills a criterion. "Entailment or Contradiction"
- Fleiss' kappa: A statistical measure of inter-annotator agreement for categorical ratings across multiple raters. "Fleiss' = 0.912"
- Gavi (GAVI): The Global Alliance for Vaccination and Immunization, a public–private global health partnership. "defining what Gavi and IFFIm are"
- GPQA: Graduate-level Google-Proof Question Answering, a challenging academic QA benchmark. "GPQA"
- GPQA-Diamond: The hardest subset of GPQA focused on expert-level questions. "GPQA-Diamond (GPT-5 reaches 87.0%)"
- Greedy decoding: A deterministic generation method that selects the highest-probability token at each step. "greedy decoding"
- Grounding documents: External reference materials provided with a prompt to guide or substantiate generated responses. "given a prompt alongside grounding documents"
- HLE: Humanity’s Exam, a benchmark evaluating broad human-like knowledge and reasoning. "HLE"
- IFBench: A benchmark for verifiable instruction following, emphasizing programmatically checkable outputs. "IFBench"
- IFFIm (International Finance Facility for Immunization): A financing mechanism that raises funds for immunization programs by issuing bonds backed by donor pledges. "International Finance Facility for Immunization (IFFIm)"
- Integer programming: An optimization framework where some or all decision variables are constrained to integers. "in integer programming"
- Inter-annotator agreement: The degree of consistency among different human annotators labeling the same items. "inter-annotator agreement"
- Issuances: Offerings of new financial instruments (e.g., bonds) to investors on capital markets. "past issuances"
- Liquidity policy: Rules ensuring an entity maintains sufficient liquid assets to meet obligations. "a breach of IFFIm's liquidity policy"
- LLM-Judge: A LLM used to evaluate whether responses meet specified criteria or rubrics. "We build robust and affordable LLM-Judges to evaluate ProfBench rubrics"
- Macro-F1: The average F1 score computed independently per class and then averaged, giving equal weight to each class. "Macro-F1"
- MMLU-Pro: An expanded, robust version of the Massive Multitask Language Understanding benchmark. "MMLU-Pro"
- Natural Language Inference (NLI): The task of determining whether a hypothesis is entailed by, neutral with, or contradicts a premise. "Natural Language Inference/Recognizing Textual Entailment"
- Open-weight model: A model whose learned parameters (weights) are publicly released for use and research. "open-weight models"
- Rating profile: The overall credit-rating characteristics and outlook of an issuer or instrument. "rating profile"
- Recognizing Textual Entailment (RTE): A formulation of NLI focusing on whether one text entails another. "Natural Language Inference/Recognizing Textual Entailment"
- Reinforcement Learning with Verified Rewards (RLVR): RL where rewards are derived from programmatically verifiable checks of outputs. "RLVR is restricted to settings with a unique correct answer"
- Rubric-guided benchmark: An evaluation framework where responses are graded against a predefined set of expert-written criteria. "a rubric-guided benchmark"
- Securitization: The process of pooling financial assets and issuing tradable securities backed by those assets. "How did IFFIm apply securitization?"
- Self-enhancement bias: The tendency of a model to overrate its own (or same-family) outputs when judging. "self-enhancement bias"
- Subscribed (capital markets): Investors committing to purchase a security offering. "what investors subscribed"
- SWEBench Verified: A software engineering benchmark with verification to check solution correctness. "SWEBench Verified"
- Test contamination: Undesired overlap between evaluation data and training or tuning data that inflates scores. "test contamination"
- Top-p sampling: Nucleus sampling where tokens are drawn from the smallest set whose cumulative probability exceeds p. "top-p 0.95"
- Unit tests: Automated tests that verify code behavior against specified cases. "unit tests such as LiveCodeBench"
Collections
Sign up for free to add this paper to one or more collections.