- The paper introduces a comprehensive HisRubric framework and benchmark to systematically assess deep research agents in corporate financial analysis.
- The paper outlines a four-step pipeline combining automated LLM generation with two-round expert verification to ensure high-quality, machine-readable reports.
- The paper finds that while deep research agents meet structural requirements, they lag in precise information retrieval and complex interpretation, especially in multilingual settings.
FinDeepResearch: Rigorous Evaluation of Deep Research Agents in Financial Analysis
Introduction
FinDeepResearch introduces a comprehensive framework and benchmark for evaluating Deep Research (DR) agents in the domain of corporate financial analysis. The work addresses the lack of systematic, fine-grained evaluation protocols for DR agents, which are increasingly powered by advanced LLMs and deployed in high-stakes analytical tasks. The proposed HisRubric framework integrates an expert-designed hierarchical analytical structure with a detailed grading rubric, enabling the assessment of both structural rigor and information precision. The benchmark spans 64 companies across 8 financial markets and 4 languages, resulting in 15,808 grading items, and supports robust cross-model and cross-market evaluation.
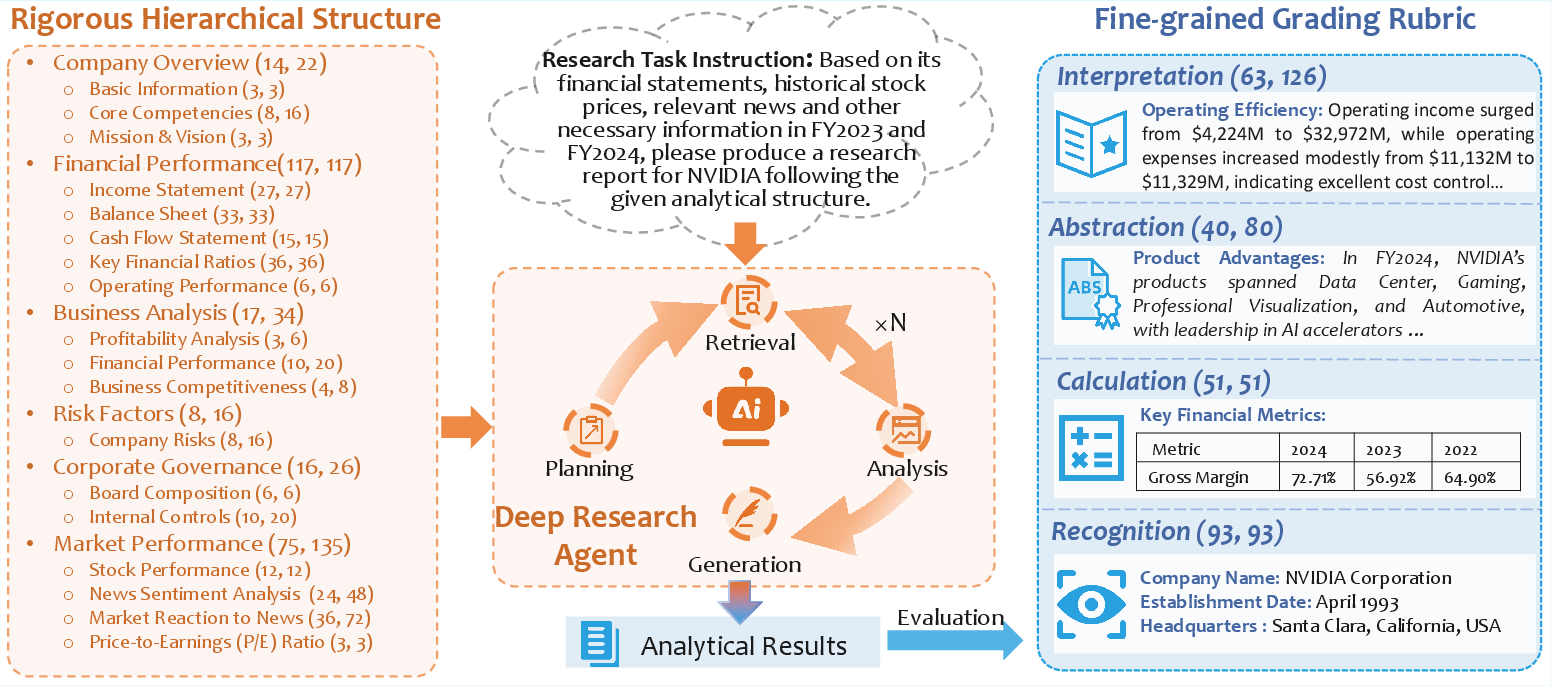
Figure 1: Overview of the HisRubric evaluation framework, showing the hierarchical structure and grading item distribution.
HisRubric Evaluation Framework
HisRubric is designed to mirror the workflow of professional financial analysts, progressing from data recognition to metric calculation, strategic summarization, and interpretation. The framework consists of:
- Hierarchical Analytical Structure: Six major sections (Company Overview, Financial Performance, Business Analysis, Risk Factors, Corporate Governance, Market Performance) subdivided into 18 subsections, each with explicit schema and markdown formatting requirements.
- Fine-grained Grading Rubric: 247 grading items per report, mapped to four core capabilities: Recognition, Calculation, Abstraction, and Interpretation. Items in Abstraction and Interpretation are weighted more heavily due to their complexity, yielding a total possible score of 350 per report.
The evaluation protocol applies three distinct scoring methods: accuracy (for factual items), claim-based (for summary/abstraction items), and criterion-based (for nuanced reasoning and qualitative analysis). Structural rigor is assessed via rule-based validation of markdown compliance.
Benchmark Construction and Quality Control
The construction of FinDeepResearch follows a four-step pipeline:
- Company Selection: 64 companies from 8 markets, covering 10 industries and 4 languages.
- Financial Corpus Preparation: Aggregation of data from Bloomberg, Alpha Vantage, Google News, Yahoo Finance, and official corporate sources.
- Section-based Auto Generation: Multiple LLMs generate candidate results for each section; predominant results are selected and synthesized.
- Two-round Human Verification: Section-based expert review followed by cross-sectional panel verification ensures consistency and accuracy.
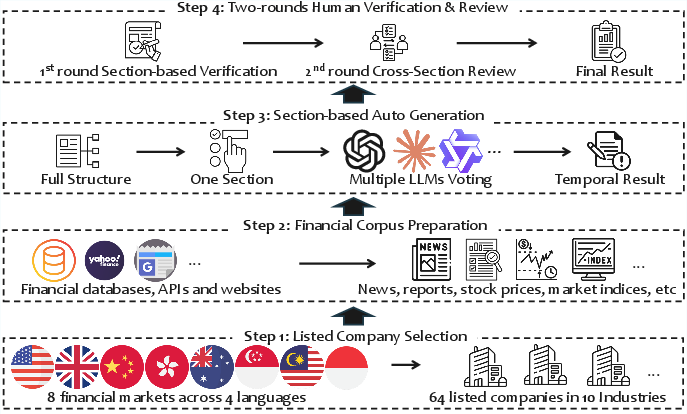
Figure 2: Pipeline for constructing the FinDeepResearch benchmark, from company selection to expert verification.
Quality control is enforced via cross-source data validation, rigorous structure guidance, and two-round expert verification, involving over 30 financial professionals and academics.
Comparative Analysis with Existing Benchmarks
FinDeepResearch distinguishes itself from prior benchmarks in three aspects:
- Structured Output Requirement: Mandates analytically structured, markdown-formatted reports.
- Multilingual Coverage: Supports English, Simplified Chinese, Traditional Chinese, and Bahasa Indonesia.
- Scale: 15,808 grading items, far exceeding the coverage of previous financial and general DR benchmarks.
Experimental Results
DR agents consistently outperform LLMs with only reasoning or reasoning plus search capabilities. OpenAI o3-deep-research achieves the highest accuracy score (37.9/100), followed closely by Grok-4 DeepSearch (37.3). All models struggle with information precision, with the best scores well below 50, indicating the persistent difficulty of the benchmark.
Structural Rigor
Most advanced models adhere strictly to the hierarchical structure, with 7 methods achieving perfect formatting and 5 with minor errors. Poor structural compliance correlates with low information precision, as seen in DeepSeek-v3.2 and Mistral Deep Research.
Market and Capability Analysis
Performance varies significantly across markets and capabilities:
- Market Variation: DR agents lead in all markets, but scores are lower in non-Latin language markets (CN, HK). No method approaches perfect accuracy in any market.
- Capability Spectrum: Recognition is the most tractable (max score 59.5), followed by Calculation and Abstraction (~44), while Interpretation remains the most challenging (max score 20.3).
Section 6 (Market Performance) is the most difficult, with a maximum score of 17.0, due to the need for integrated analysis of heterogeneous data sources. DR agents dominate across all sections, but the gap narrows for Abstraction and Interpretation.
Three performance regimes are identified:
- T (Thinking) < T+S (Thinking+Search) ≈ DR: T fails due to lack of retrieval, while T+S and DR succeed by leveraging external data.
- T ≈ T+S < DR: Only DR succeeds, attributed to iterative retrieval and reasoning.
- T ≈ T+S ≈ DR (All Fail): All methods fail on items requiring precise historical data or complex integration.
Implications and Future Directions
The results highlight a fundamental challenge: while DR agents can follow complex analytical structures, they struggle to produce precise, source-grounded information, especially in multilingual and high-complexity scenarios. The persistent gap in Interpretation capability and integrated analysis suggests that future research should focus on agent architectures that support iterative, multi-modal reasoning and robust retrieval across diverse data sources.
The HisRubric framework and FinDeepResearch benchmark set a new standard for evaluating DR agents in professional domains. Extending this approach to other fields (e.g., legal, clinical) and refining agentic workflows for deeper reasoning and evidence synthesis are promising directions.
Conclusion
FinDeepResearch provides a rigorous, scalable, and multilingual benchmark for evaluating DR agents in financial analysis. The dual focus on structural rigor and information precision exposes critical limitations in current agentic systems and offers a pathway for systematic improvement. The benchmark and framework are poised to drive advances in reliable, high-quality autonomous research agents for professional applications.

