DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
Abstract: Deep research models perform multi-step research to produce long-form, well-attributed answers. However, most open deep research models are trained on easily verifiable short-form QA tasks via reinforcement learning with verifiable rewards (RLVR), which does not extend to realistic long-form tasks. We address this with Reinforcement Learning with Evolving Rubrics (RLER), in which we construct and maintain rubrics that co-evolve with the policy model during training; this allows the rubrics to incorporate information that the model has newly explored and to provide discriminative, on-policy feedback. Using RLER, we develop Deep Research Tulu (DR Tulu-8B), the first open model that is directly trained for open-ended, long-form deep research. Across four long-form deep research benchmarks in science, healthcare and general domains, DR Tulu substantially outperforms existing open deep research models, and matches or exceeds proprietary deep research systems, while being significantly smaller and cheaper per query. To facilitate future research, we release all data, models, and code, including our new MCP-based agent infrastructure for deep research systems.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new AI system called DR Tulu-8B. Its job is “deep research”: answering tough, open-ended questions with a well-structured, long explanation and clear citations to reliable sources. The main idea is a new training method, Reinforcement Learning with Evolving Rubrics (RLER), which teaches the AI using checklists that change and improve as the AI learns. This helps the AI handle real research tasks much better than models trained only on short, simple questions.
Goals
The researchers wanted to solve two big problems:
- How to train an AI to do real, long-form research, not just short answers.
- How to fairly judge its long answers when the “right answer” isn’t obvious and depends on current knowledge online.
In simple terms: they wanted an AI that can think like a careful researcher—plan, search the web and scientific papers, evaluate what it finds, write a clear report, and cite the exact parts of sources that back up every claim.
How it works (Methods)
Think of training like a coach guiding a team:
- Supervised fine-tuning (warm-up practice):
- They first taught DR Tulu how to plan, search, and cite by showing it lots of high-quality example “research journeys” created by a strong model. These journeys included the thinking steps, the tool calls (like web search), the results from those tools, and the final answer. This gives the model basic skills so it knows how to start.
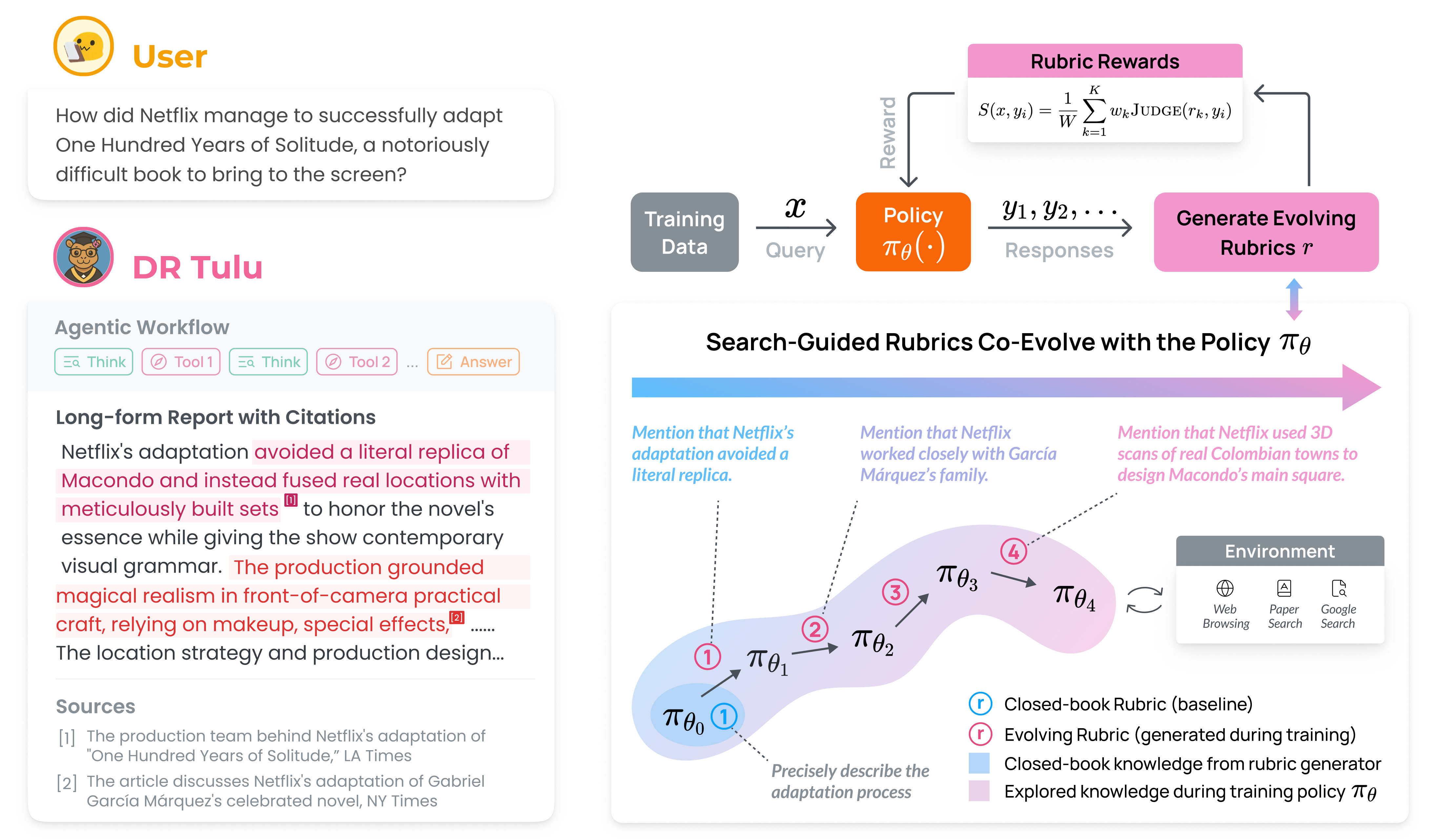
- Reinforcement Learning with Evolving Rubrics (main training):
- Rubrics are like the teacher’s checklist for grading: “Did you answer the question?”, “Did you cite correctly?”, “Is your reasoning solid?”
- Evolving rubrics means the checklist changes as the model learns. After the model tries several answers to a question, another model creates new, targeted rubric items based on what the model did well or poorly, using real information found online. This keeps feedback up-to-date and specific.
- Positive rubrics reward good behaviors (like carefully checking facts against reliable sources).
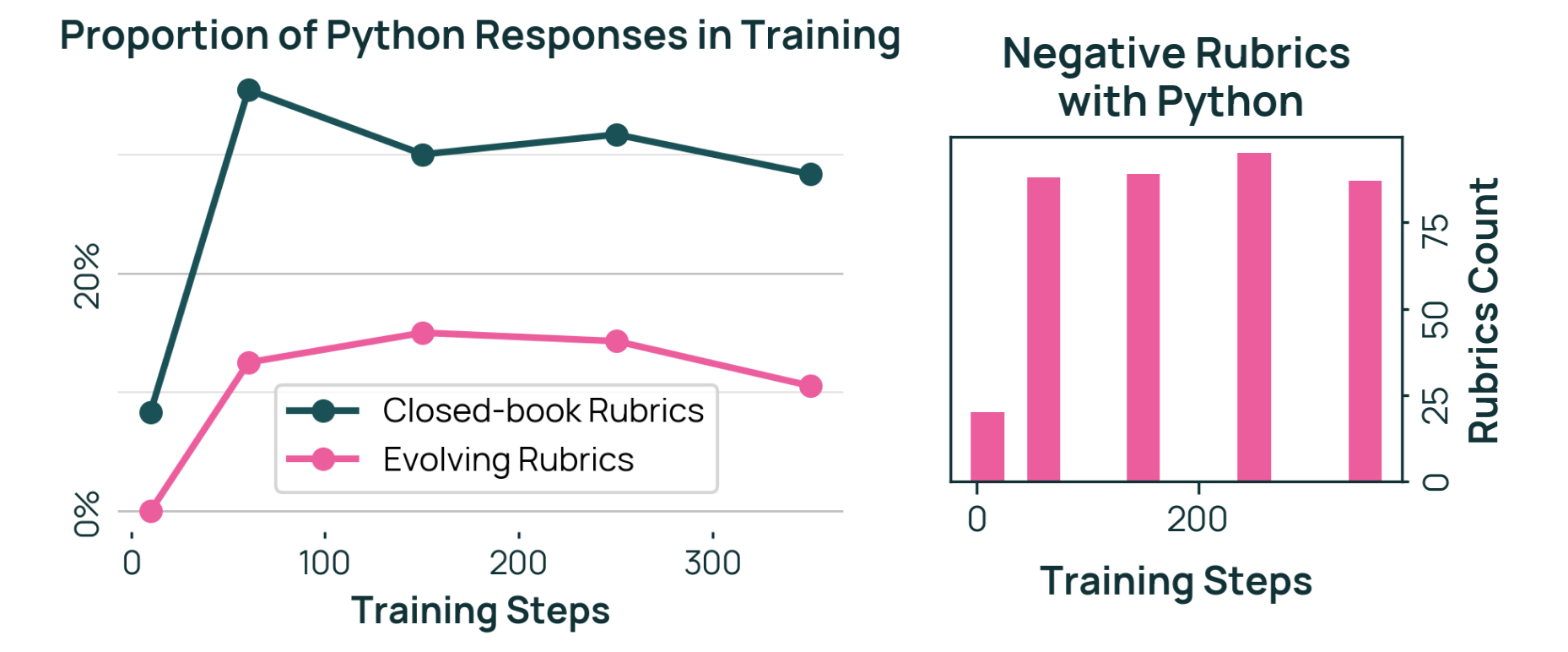
- Negative rubrics penalize bad behaviors (like copying text verbatim, adding unnecessary fluff, or slipping in irrelevant code).
- The system keeps a “rubric buffer” and automatically keeps only the rubric items that best separate strong from weak answers. It measures which rubrics give scores with the biggest spread across answers, and keeps those.
- The training uses a trial-and-error loop (a technique called GRPO): the model tries multiple answers, gets scored by the rubrics, and updates itself to do better next time.
- Tools and infrastructure (the AI’s toolkit and workflow):
- The AI can call search and browse tools during its answer:
- google_search: finds top web snippets.
- web_browse: fetches and reads web pages.
- paper_search: finds relevant paragraphs from scientific papers.
- Tool calls are asynchronous, like multitasking: while waiting for one tool to respond, the AI can continue generating other parts. This makes training faster and more practical.
- They built a library (dr-agent-lib) to easily plug in, manage, and scale these tools, and to cache repeated queries.
- The AI can call search and browse tools during its answer:
- Extra rewards:
- The model also gets small rewards for:
- Following the required answer format.
- Using search when needed.
- Providing high-quality, precise citations that match the specific claims.
- The model also gets small rewards for:
Key ideas in everyday language:
- “Parametric knowledge” = what the AI already “remembers” from training.
- “Retrieved knowledge” = fresh facts found online or in papers during the research.
- Evolving rubrics ensure the AI is judged using retrieved, up-to-date information, not only its memory.
Main findings
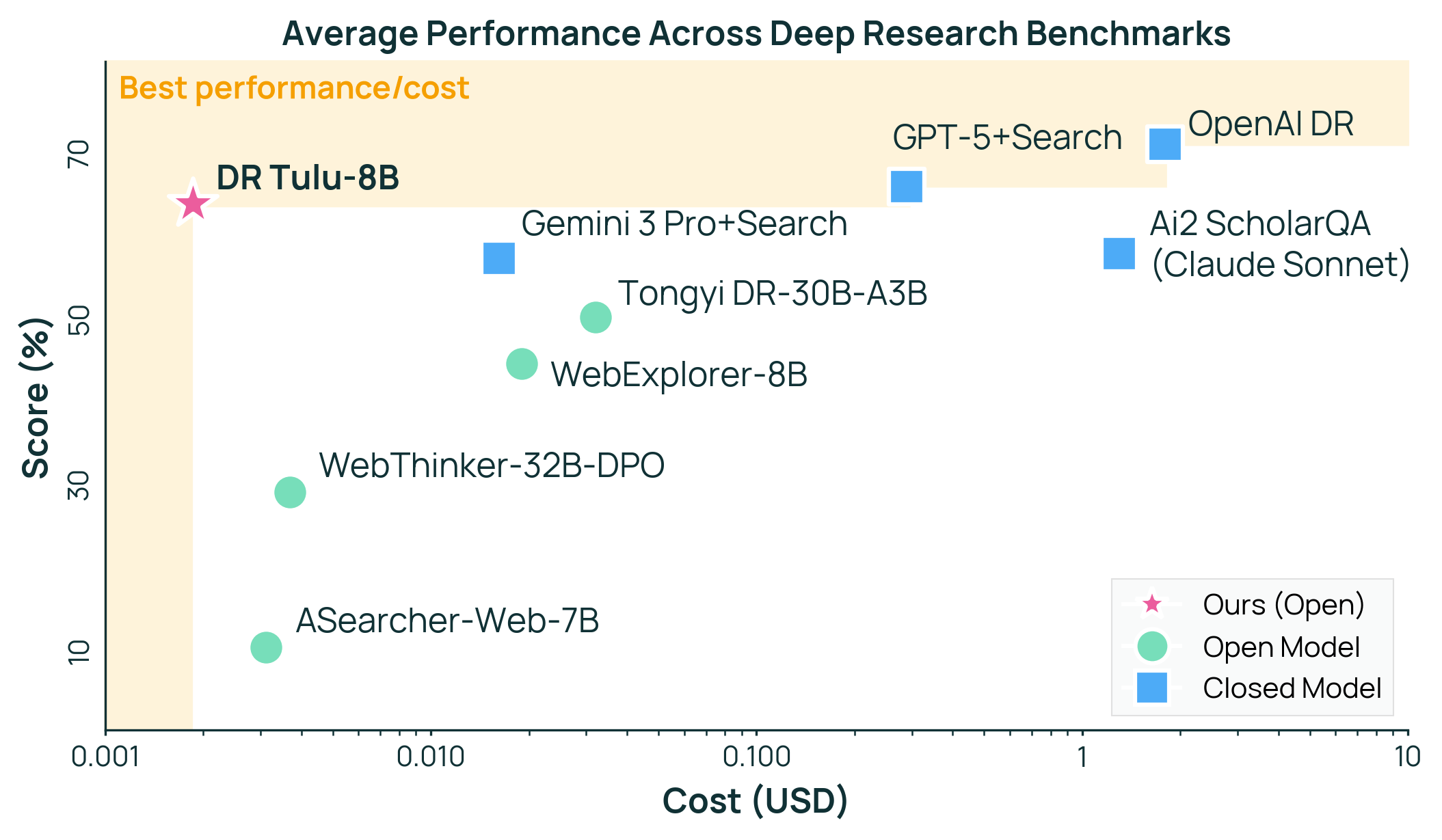
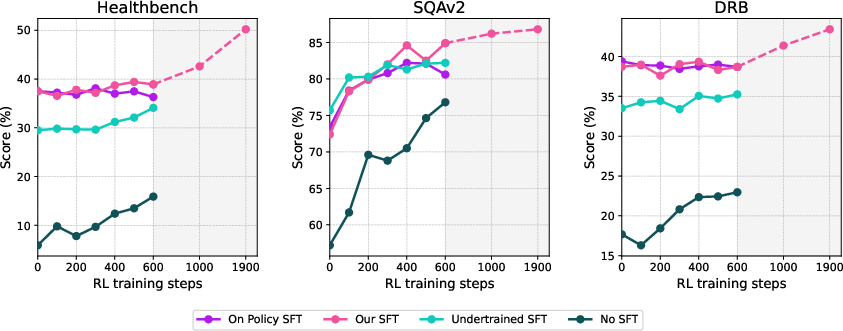
Across four long-form research tests—about science, health, and general topics—DR Tulu-8B did extremely well:
- It beat all open-source deep research models, even ones much larger (30B parameters), by large margins.
- It matched or sometimes exceeded expensive, proprietary deep research systems.
- It’s far cheaper per query. For example, on one benchmark, OpenAI’s system cost about $1.80 per question, while DR Tulu cost about$0.0019—almost 1,000 times cheaper.
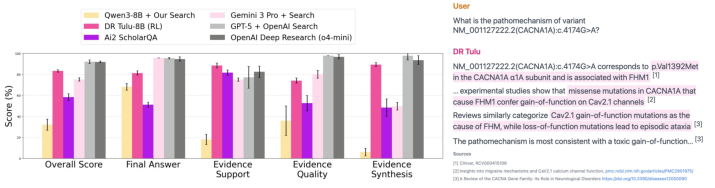
- It provided better long-form answers with more accurate, well-targeted citations. On citation-focused tests, its precision and recall were strong—meaning its sources actually supported its claims, and it cited all the claims that needed support.
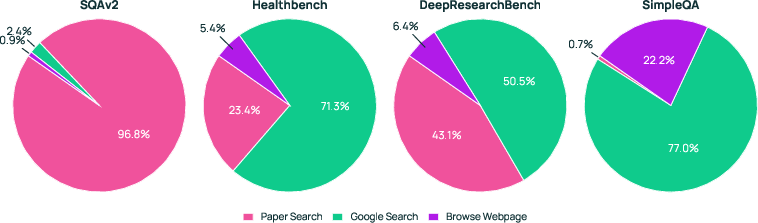
- It learned to choose the right tool for the task: more paper search for research-heavy questions, more web search for general topics.
- The evolving rubrics helped it avoid “reward hacking” (gaming the scoring system), for example by penalizing irrelevant code or fluff.
They also built a new real-world medical dataset, GeneticDiseasesQA, where the AI must judge if a genetic variant qualifies for certain therapies using cited evidence. DR Tulu handled this well and competed with closed systems.
Why this matters
In short:
- Evolving rubrics are a practical way to train AI for complex, messy, real-world research tasks where the best answer isn’t a single short fact.
- DR Tulu shows you can get strong performance with a smaller, open model, making deep research more accessible and affordable.
- Reliable, snippet-level citations make it easier for humans to verify the AI’s claims—an important step toward trustworthy AI research assistants.
- The open release of data, models, and the agent infrastructure makes it easier for others to build and improve deep research systems.
Takeaway
This work moves beyond training on short trivia-like questions. By training with evolving, search-grounded rubrics and giving the AI real tools to look things up, the authors built an open, cost-efficient model that can plan, search, reason, and write well-cited, long-form reports. It’s a step toward helpful, verifiable AI research assistants that can operate in fast-changing, knowledge-rich environments.
Knowledge Gaps
Below is a consolidated list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address.
- Dependence on closed models for reward shaping: RLER relies on GPT-4.1/4.1-mini to generate and judge rubrics and on GPT-5 to produce SFT trajectories, raising questions about reproducibility without proprietary LMs and about judge-induced biases and reward hacking under different judges.
- Judge robustness and transfer: The paper does not quantify how performance or training stability changes when swapping judges/rubric generators (e.g., across open vs. closed LMs, smaller vs. larger models, non-English judges), nor whether the learned policy generalizes to new judge distributions.
- Co-evolution stability and convergence: There is no analysis of theoretical or empirical convergence properties of co-evolving rubrics (e.g., oscillations, myopic overfitting to current rollouts, or catastrophic forgetting of earlier desiderata).
- Rubric buffer design choices: The variance-based filtering and top-K selection are not ablated; it remains unclear how Kmax, the variance thresholding, merging strategies, or alternative ranking criteria affect learning signal, stability, and final performance.
- Reward granularity and signal: Rubric satisfaction is scored at {0, 0.5, 1} and only on the final answer, not the search/reasoning traces; the effect of finer-grained or process-based rewards (e.g., per-step verification, tool call quality, claim-by-claim evidence sufficiency) is unexplored.
- Evolving rubrics’ factual grounding risk: Rubrics are generated from on-policy rollouts and retrieved content; the paper does not examine the risk that rubrics incorporate incorrect or low-quality evidence discovered by the model, potentially enshrining false criteria.
- Negative rubric dynamics: While negative rubrics can suppress spurious behaviors (e.g., emitting Python code), there is no systematic study of unintended consequences (e.g., suppressing legitimate behaviors, decreasing exploration, creating brittle heuristics).
- Sensitivity to tool APIs and configurations: The system uses specific tools (Serper, Jina, Semantic Scholar, Crawl4AI) and caps calls at 10; the paper lacks ablations on different search engines, browsing backends, tool budgets, snippet counts, and summarization/truncation strategies.
- Coverage of sources and paywalled content: Paper_search relies on open-access sources (Semantic Scholar paragraphs); questions remain about performance on paywalled literature, non-indexed sources, or domain-specific repositories (e.g., clinical guidelines behind paywalls).
- Multilingual and cross-domain generalization: All experiments appear English-centric; the model’s ability to conduct deep research in other languages or low-resource domains is not assessed.
- Citation quality beyond SQAv2: Fine-grained citation precision/recall is only reported for SQAv2; systematic citation metrics are missing for the other benchmarks, limiting insights on evidence localization and claim support across domains.
- Comparability with proprietary systems’ citation formats: DR Tulu uses snippet-level citations while many proprietary systems use URLs; the paper does not normalize or benchmark citation quality across systems to enable fair comparison.
- Impact of turning off citation reward: The citation reward was disabled after 650 steps for speed; the paper does not analyze its long-term effect on citation behavior, nor whether alternative efficient citation rewards could maintain benefits without API bottlenecks.
- RL training bottlenecks and scalability: Training was limited by external API rate limits; scaling strategies (e.g., local indexing, batched retrieval, synthetic corpora) and their impact on both reward quality and model behavior are unstudied.
- Cost-performance trade-offs at inference: The paper provides per-query cost for ScholarQA-CSv2 but does not analyze cost sensitivity across tasks, tool budgets, or failure modes (e.g., when more calls improve citations but worsen latency/cost).
- SFT trajectory authenticity: Teacher-generated “mock thinking” tokens may not reflect real reasoning; the paper does not assess whether these tokens distort learning or whether using transparent tool-augmented teachers changes outcomes.
- SFT data quality and filtering: Prompt quality filtering is LM-based; there is no human audit or error analysis of retained prompts/trajectories, nor quantification of residual noise or biases introduced by filtering.
- Data distribution mismatch: The RL prompts are described as out-of-distribution relative to downstream tasks; the impact of this mismatch on generalization is not characterized, and strategies for distributionally robust training are not explored.
- Safety and domain-specific risk: HealthBench includes negative rubrics for harmful responses, but the paper lacks a broader safety audit (e.g., medical misinformation, privacy, potentially harmful advice) and a cross-benchmark harm analysis.
- Robustness to adversarial or noisy web content: The system’s resilience to misleading, adversarial, or low-quality sources (e.g., SEO spam, misinformation) is not evaluated; defenses and detection mechanisms are not discussed.
- Failure mode taxonomy and detection: Beyond the Python artifact example, the paper does not provide a systematic taxonomy of failure modes (e.g., superficial coverage, citation padding, copy-paste behavior, stale sources) or automated detectors.
- Tool selection learning: Although usage patterns are reported (e.g., paper search vs. web search), the paper does not quantify whether tool selection is optimal, nor whether explicit tool-choice supervision or bandit-style optimization would help.
- Process transparency: Rewards ignore the search trace; open questions remain about integrating trace-level evaluation (e.g., verifying intermediate claims, penalizing ungrounded steps) to improve process reliability and auditability.
- Human vs. LM judge alignment: The assertiveness/factuality analysis uses LMs; the paper does not validate rubric quality or judge decisions with human raters to establish alignment and reduce judge artifacts.
- Benchmark coverage and consistency: Some proprietary results are reused from leaderboards or run on 100-sample subsets; the paper does not address comparability issues (e.g., prompt versions, tool access differences) or provide unified re-evaluation.
- Generalization to more tools and workflows: DR Tulu uses a single auto-search workflow with three tools; extensions to multi-step planning with heterogeneous tool ecosystems (e.g., structured databases, code execution, calculators, citation managers) remain unexplored.
- Theoretical framing of RLER: There is no formal analysis of RLER as an RL objective (e.g., reward shaping bias, variance properties, sample complexity), making it hard to reason about when evolving rubrics improve learning vs. induce drift.
- Open-judge alternatives: It remains unclear whether a fully open pipeline (open rubric generator and judge) can achieve similar performance, and what trade-offs arise in accuracy, speed, and cost.
- Ethical and legal considerations of web browsing: The agent’s use of web crawling/browsing and citation of snippets raises open questions about copyright, robots.txt compliance, and responsible sourcing that are not discussed.
Practical Applications
Overview
Below are actionable applications that flow directly from the paper’s findings, methods (RLER), model (DR Tulu-8B), and infrastructure (dr-agent-lib). Each item notes likely sectors, potential products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Evidence-backed long-form research assistant for academia
- Sector: Education, Research
- Use cases: Rapid literature reviews; related-work drafting; annotated bibliographies; survey article outlines; citation verification; formatting compliance for reports with snippet-level citations.
- Tools/products/workflows: Deploy DR Tulu-8B via dr-agent-lib with google_search, web_browse, paper_search; Overleaf “Auto-Review” plugin; “Citation Checker” service; workflow: plan → search → browse → synthesize → cite.
- Assumptions/dependencies: Access to search APIs (Serper, Jina, Semantic Scholar); judge-LM availability for rubric scoring; ongoing human oversight for scholarly quality.
- Clinical evidence synthesis for care teams
- Sector: Healthcare
- Use cases: Eligibility assessments for genetic variant therapies (akin to GeneticDiseasesQA); patient education handouts with citations; rapid evidence summaries for complex cases.
- Tools/products/workflows: Integrate paper_search with Semantic Scholar/PubMed; hospital intranet “Evidence Brief” generator with snippet-level citations; rubric-based safety filters.
- Assumptions/dependencies: Clinical governance and sign-off; HIPAA/PHI considerations; up-to-date medical sources; explicit harm-avoidance rubrics.
- Corporate and finance research memos
- Sector: Enterprise, Finance
- Use cases: Market and competitor intelligence; due-diligence reports; risk briefs; ESG updates—all with verified sources.
- Tools/products/workflows: BI dashboard integration; “Research API” powered by dr-agent-lib; workflows combining web search + browsing + synthesizing + citation tagging.
- Assumptions/dependencies: Licensed data feeds; rate-limit management and caching; compliance with content licenses and robots.txt.
- Policy and regulatory brief generation
- Sector: Public policy, Legal/Compliance
- Use cases: Evidence-backed policy option appraisals; regulatory summaries; compliance checklists with citations.
- Tools/products/workflows: “Policy Brief Studio” using evolving rubrics; checklist-style evaluation of memos via rubric judges; repository of domain-specific negative rubrics (e.g., penalize hedging without evidence).
- Assumptions/dependencies: Access to legal/regulatory databases; human review; audit trails for sources.
- Newsrooms and fact-checking desks
- Sector: Media/Journalism
- Use cases: Backgrounders; claim verification; source triangulation; story prep packages with snippet-level evidence.
- Tools/products/workflows: CMS-integrated “Fact-Check Assist” extension; citation-injection for articles; evolving rubrics flagging unsupported assertions.
- Assumptions/dependencies: Strong browsing tools; editorial standards; guardrails against source bias.
- Internal QA for long-form content production
- Sector: Software, Knowledge Management
- Use cases: Automatically score and improve drafts using evolving rubrics; detect reward-hacking (e.g., padding, irrelevant citations).
- Tools/products/workflows: “Rubric QA” service hooked to CI pipelines for docs; negative rubrics suppress undesirable patterns (e.g., code in prose).
- Assumptions/dependencies: Judge-LM reliability; domain-specific rubric authoring; integration into content workflows.
- Educational study aids with citations
- Sector: Education
- Use cases: Study guides; evidence-mapped reading lists; course notes with source excerpts.
- Tools/products/workflows: LMS add-on that produces annotated syllabi; rubric-driven checks for coverage and accuracy; student-facing “Evidence Explorer.”
- Assumptions/dependencies: Instructor oversight; age-appropriate source curation; clarity/readability rubrics.
- Developer and product research inside IDEs and docs
- Sector: Software
- Use cases: Technology comparisons; standards and RFC summaries; dependency risk assessments—all cited.
- Tools/products/workflows: IDE extension “Research as You Code”; doc authoring assistant that injects citation tags and supports snippet-level backing.
- Assumptions/dependencies: Access to tech knowledge bases; rate limits; domain tool adapters via MCP.
- Personal decision support for consumers
- Sector: Daily life
- Use cases: Evidence-backed product comparisons; travel planning with reliable constraints; health/wellness information seeking with sources.
- Tools/products/workflows: Browser extension for “Cite-as-you-go” research; simplified rubrics for consumer domains; onboard caching to reduce API costs.
- Assumptions/dependencies: Source licensing and accuracy; simplifying rubrics for non-experts; privacy-safe logging.
- Agent platform provisioning for customized research agents
- Sector: Software Platforms
- Use cases: Build domain-specific agents using dr-agent-lib with MCP; swap in sector tools (e.g., legal DBs, scientific corpora).
- Tools/products/workflows: “Agent SDK” with asynchronous tool calling, caching, and prompt layers; dashboards for rubric variance and citation precision/recall.
- Assumptions/dependencies: MCP tool ecosystem; infrastructure to manage concurrency; monitoring and observability.
Long-Term Applications
- Enterprise “Rubric Engine” for dynamic, on-policy evaluation
- Sector: Enterprise Software
- Use cases: Organization-wide evolving rubrics that adapt to team outputs; continuous learning from on-policy rollouts; reduction of reward hacking across departments.
- Tools/products/workflows: Central rubric buffer management; SD-based ranking of rubric discriminativity; domain-specific judge-LMs replacing general judges.
- Assumptions/dependencies: Governance for rubric evolution; secure model-judge coupling; scalable judge inference.
- RL with evolving rubrics beyond research (coding, planning, autonomy)
- Sector: Software, Robotics (planning), Education
- Use cases: Train agents for open-ended tasks where static rewards fail; penalize emergent undesirable behaviors via negative rubrics.
- Tools/products/workflows: GRPO + RLER pipelines adapted to coding assistants, schedule planners, or classroom tutors; multi-tool orchestration via MCP.
- Assumptions/dependencies: Task-specific judge design; robust retrieval grounding; guaranteed access to relevant external knowledge.
- Living systematic reviews and continuous evidence surveillance in healthcare
- Sector: Healthcare
- Use cases: Auto-updating clinical guidelines; pharmacovigilance literature monitoring; evidence maps for rare diseases.
- Tools/products/workflows: Scheduled research agents maintaining evergreen reviews; domain rubrics balancing coverage, recency, and risk; integration with EHR decision support.
- Assumptions/dependencies: Regulatory compliance; high-recall literature access (PubMed, paywalled publishers); clinician governance.
- Auditing, certification, and governance of AI-generated content
- Sector: Policy, Compliance
- Use cases: Standardized, evolving rubric frameworks for certifying evidence-backed outputs; audit trails tied to citations and judge decisions.
- Tools/products/workflows: “Evidence Audit Kit” with rubric logs; sector-specific negative rubrics for safety and fairness; dashboards for citation-quality KPIs.
- Assumptions/dependencies: Accepted standards; third-party judge validation; legal agreements for source use.
- Next-gen search engines with long-form, snippet-cited answers
- Sector: Search/Knowledge Platforms
- Use cases: Answer pages that plan, search, and synthesize with fine-grained citation tags; “living answers” updated through evolving rubrics.
- Tools/products/workflows: Search + browse + paper search orchestration; rubrics tuned to user intents (depth, completeness); caching and rate-limit-aware infrastructure.
- Assumptions/dependencies: Publisher licensing; cost-effective judge models; scalable asynchronous tool calls.
- Peer-review triage and reproducibility assistance
- Sector: Academic Publishing
- Use cases: Screening submissions for unsupported claims; mapping claims to sources; reproducibility checklists powered by evolving rubrics.
- Tools/products/workflows: Editorial dashboard; negative rubrics penalizing vague assertions; auto-suggested corrections and missing citations.
- Assumptions/dependencies: Access to full texts and data/code artifacts; community acceptance; careful handling of biases.
- Continuous risk and compliance monitoring in finance and enterprise
- Sector: Finance, Enterprise Risk
- Use cases: Ongoing surveillance of regulatory, market, and geopolitical signals; evolving rubric criteria for materiality and risk thresholds.
- Tools/products/workflows: Agent pipelines tied to premium data feeds; rubric drift detection; alerting with source-backed briefs.
- Assumptions/dependencies: Licensed feeds; scalable streaming retrieval; governance for threshold updates.
- Curriculum engines and adaptive tutors with evidence grounding
- Sector: Education
- Use cases: Personalized curricula that cite sources; rubrics steering depth and difficulty; bias/safety rubrics for equitable instruction.
- Tools/products/workflows: Tutor agents that plan reading and practice; citation-aware explanations; evolving rubrics tuned to learner models.
- Assumptions/dependencies: Reliable child-safe sources; fairness audits; instructor oversight.
- Domain-extended dr-agent-lib ecosystems
- Sector: Software Platforms
- Use cases: Integration with additional MCP tools (legal, biomedical, engineering standards); local/offline corpora for secure retrieval; improved caching and concurrency controls.
- Tools/products/workflows: Tool adapters for premium APIs; offline retrieval engines; rubric-aware scheduling to minimize judge costs.
- Assumptions/dependencies: Tool vendor participation; enterprise security requirements; performance tuning for large corpora.
- Methodological advances in reward design and safety
- Sector: AI Research, Governance
- Use cases: Formalizing negative rubric design to suppress harmful or non-compliant behaviors; standardized evaluation of citation precision/recall; robust anti-hacking judges.
- Tools/products/workflows: Open benchmarks (SQAv2, DRB, HealthBench, ResearchQA) extended with safety rubrics; public “Rubric Marketplace.”
- Assumptions/dependencies: Community consensus; reproducible judge behaviors; transparency around judge models.
Notes on feasibility across applications:
- DR Tulu-8B’s cost-efficiency enables immediate deployment on modest hardware, but high-quality rubric generation and judging may currently depend on proprietary judge LMs.
- Tool orchestration is sensitive to API rate limits and licensing; caching, asynchronous calling, and MCP integration are essential.
- For high-stakes domains (healthcare, policy, finance), human oversight and domain-specific rubrics are mandatory to mitigate errors and ensure safety.
Glossary
- Action space: The set of discrete actions a policy can choose at each step in an agentic process. "we define the model's action space as {oc-cyan-8, oc-pink-8, oc-yellow-8, oc-lime-8}"
- Agentic rollouts: Full trajectories generated by an agent interacting with tools or an environment, used for training or evaluation. "we iteratively generate agentic rollouts using real tool calls"
- Assertive rubric: A rubric item that is specific and concrete about required content, enabling precise evaluation. "We define a rubric as assertive if it is specific and concrete about what the response should contain"
- Asynchronous tool calling: Issuing tool requests without blocking the ongoing generation, overlapping computation and I/O to improve throughput. "we use an asynchronous tool call setup similar to \citet{jiang2025verltool}"
- Asynchronous training: A training setup that overlaps generation and optimization steps to reduce wall-clock time. "use 1-step asynchronous training"
- Autoregressive: A generation process where the model produces tokens sequentially, conditioning on previously generated tokens. "operates autoregressively over a sequence of text "
- Checklist-style evaluations: Rubric-driven, itemized assessments where each criterion is checked and scored explicitly. "perform checklist-style evaluations based on those rubrics"
- Citation precision: The fraction of cited statements whose sources actually substantiate the claims. "citation precision checks whether the cited sources actually support statements with citations"
- Citation recall: The fraction of citation-worthy statements that are supported by provided citations. "citation recall checks whether valid citations back all citation-worthy statements"
- Citation tags: Structured markers in an answer that link claims to specific supporting sources. "wrap claims in citation tags that point to the supporting source."
- Closed-book rubrics: Rubrics generated solely from an LM’s internal parameters without retrieval, potentially missing external evidence. "We refer to these rubrics as closed-book rubrics"
- Cold-start problem: The difficulty of training an agent from scratch when it lacks initial skills for planning, tool use, or formatting. "to resolve the cold-start problem"
- DAPO: A reinforcement learning method for LMs that aggregates losses at the token level to improve optimization. "using token-level loss aggregation like DAPO"
- Deep research (DR) models: Agents that plan, search, and synthesize information across sources to produce well-attributed, long-form answers. "Deep research (DR) models aim to produce in-depth, well-attributed answers"
- Descriptive rubric: A rubric item that is general or vague about required content, making verification less precise. "and descriptive otherwise (e.g., “The response should discuss benchmarks.”)."
- Evolving rubrics: Instance-specific, search-grounded criteria that are updated online to reflect the current policy’s behaviors and newly found evidence. "Generate evolving rubrics by contrasting rollouts"
- GRPO: A group-based relative policy optimization algorithm used to train LLMs via reinforcement learning. "we optimize this objective using the GRPO~\citep{shao2024deepseekmath} algorithm"
- Judge LM: A LLM used to score responses against rubrics, often providing discrete satisfaction levels. "we use a separate judge LM that returns $0$, $0.5$, or $1$"
- KL penalty: A regularization term that limits divergence from a reference policy to stabilize RL training. "We find using a small KL penalty (0.001) useful for stabilizing training."
- Model Context Protocol (MCP): A standard interface for connecting LMs to external tools and data sources. "based on the Model Context Protocol (MCP)."
- On-policy feedback: Evaluation signals derived from the current policy’s own rollouts, reducing mismatch between training signals and behavior. "provide discriminative, on-policy feedback."
- Out-of-distribution (OOD): Data or questions that differ significantly from the distribution seen during training. "often still out-of-distribution (OOD) relative to those in downstream benchmarks."
- Pareto frontier: The set of solutions that are not dominated in a multi-objective trade-off (e.g., performance vs. cost). "DR Tulu-8B lies on the Pareto frontier"
- Parametric knowledge: Information stored in a model’s learned parameters rather than retrieved from external sources. "relying solely on the modelâs parametric knowledge"
- Policy model: The parameterized function that maps states to actions in an RL-trained agent. "co-evolve with the policy model during training"
- Policy update: The process of adjusting a policy’s parameters based on feedback or rewards. "co-evolve with the policy update"
- Positive rubrics: Criteria that reward desired behaviors or inclusion of relevant, newly explored knowledge. "positive rubrics, which capture strengths or new, relevant knowledge"
- Rejection sampling: A filtering technique where generated trajectories are discarded if they fail specified checks. "apply lightweight rejection sampling to filter them."
- Reinforcement Learning with Evolving Rubrics (RLER): A training method where rubrics co-evolve with the policy and are grounded in searched evidence. "Reinforcement Learning with Evolving Rubrics (RLER)"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL training using rewards that can be automatically verified, often on short-form QA tasks. "via Reinforcement Learning with Verifiable Rewards (RLVR)"
- Reward hacking: Exploiting weaknesses in the reward or judge to score highly without genuinely solving the task. "suffers from reward hacking"
- Rubric buffer management: Strategies to maintain a compact, discriminative set of rubrics by filtering and ranking them. "a rubric buffer management strategy"
- Rubric-based scoring function: A formal function that aggregates rubric item scores (often via an LM judge) into a training reward. "we assess the quality of the response with the rubric-based scoring function"
- Sample packing: Efficient batching that packs multiple sequences into a single training pass with minimal padding. "we use sample packing to pack multiple rollouts into single training passes"
- Search traces: Logged sequences of tool queries and retrieved content used during a rollout. "we sample several responses and search traces from the model"
- Search-based rubrics: Rubrics generated using retrieved documents so evaluation criteria are grounded in external evidence. "initial search-based rubrics"
- Standard deviation: A variability measure used to rank rubrics by how well they differentiate rollouts. "We then compute the standard deviation for each remaining rubric"
- Token-level loss aggregation: Summing or averaging losses at the token level to shape sequence-level optimization in RL for LMs. "using token-level loss aggregation like DAPO"
- Tool-augmented trajectories: Rollouts that include calls to external tools (search, browse, paper retrieval) within the reasoning process. "RLER relies on meaningful exploration over tool-augmented trajectories"
- Tool call: An invocation of an external API or capability by the agent during generation. "When performing tool calls during RL training"
- Tool output tokens: Text returned by tools that may be excluded from loss computation to avoid training on external content. "mask out tool output tokens from the loss"
- Variance among rollouts: The variability of rubric rewards across generated responses, used to select discriminative rubrics. "retain only a fixed number of rubrics with the highest variance among rollouts."
Collections
Sign up for free to add this paper to one or more collections.