- The paper introduces a benchmark to assess code generation models based on developer-preferred adjustments, moving beyond mere functional correctness.
- It employs a developer-driven instruction catalog categorizing tasks into cosmetic, structural, and semantic, supported by rule-based and LLM assessments.
- Results reveal marked performance disparities among models, highlighting the need for improved handling of multi-turn and follow-up instructions in real-world scenarios.
CodeAlignBench: Assessing Code Generation Models on Developer-Preferred Code Adjustments
CodeAlignBench introduces a nuanced benchmark designed to evaluate code generation models' abilities to follow developer-preferred instructions. The paper outlines a framework that moves beyond functional correctness and explores the alignment of generated code with developers' nuanced preferences, addressing both predefined and follow-up instructions.
Introduction to CodeAlignBench
CodeAlignBench is presented to tackle the inadequacy of existing benchmarks that primarily focus on functionality while neglecting the subtleties of real-world coding tasks. This benchmark provides a comprehensive evaluation of instruction-following capabilities across multiple programming languages.
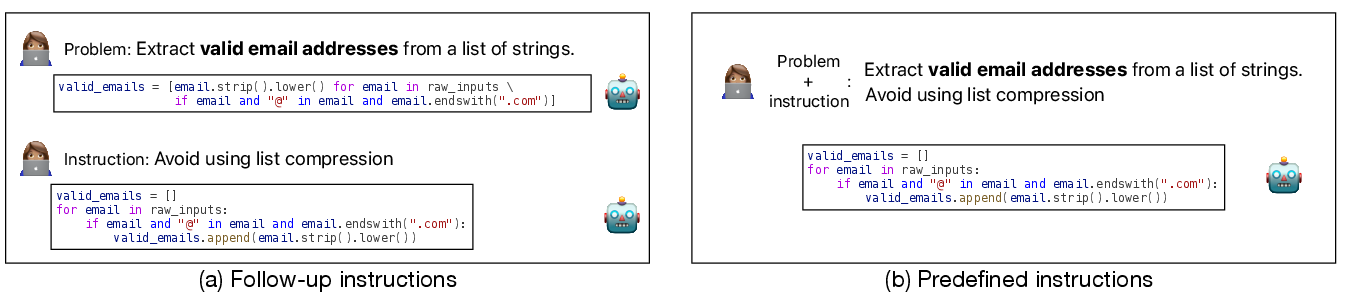
Figure 1: Illustration of two instruction settings in CodeAlignBench: (a) Follow-up Instructions, (b) Predefined Instructions.
The benchmarking process evaluates how models adhere to predefined constraints versus refining code based on follow-up instructions, providing insights into their capability to produce developer-aligned code.
Instruction Catalog Construction
The paper describes a meticulous process of constructing an instruction catalog through a developer-driven user study across Python, Java, and JavaScript. Participants preferred code solutions and provided natural language instructions to convert less preferred solutions into more desirable ones. The subsequent analysis using manual and LLM-assisted coding revealed a structured taxonomy of instructions.
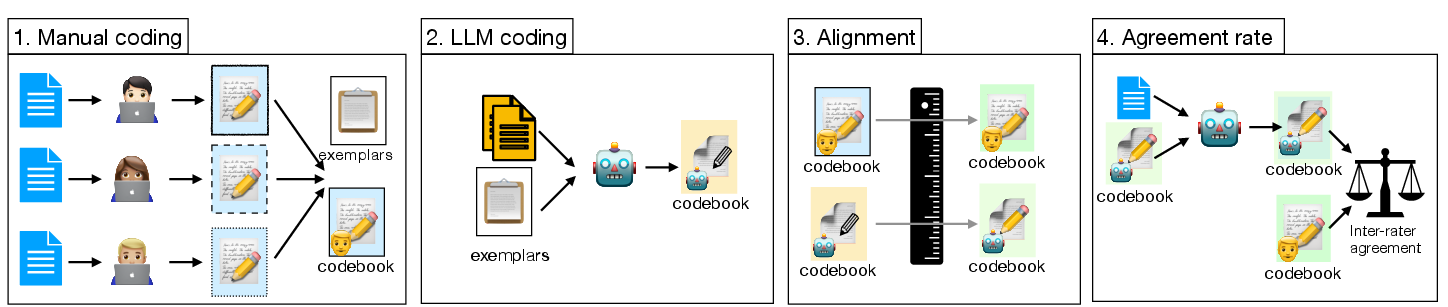
Figure 2: LLM-Assisted Coding Procedure.
The constructed catalog distinguishes instructions into cosmetic, structural, and semantic categories, which are essential for curating diverse instruction-following (IF) tasks.
Benchmarking Framework
The benchmarking framework involves a dual-stage process of task construction and IF evaluation. Tasks are curated from code problems and categorized using the developed instruction catalog. The evaluation stage assesses the models’ performance in executing these instructions under different scenarios.
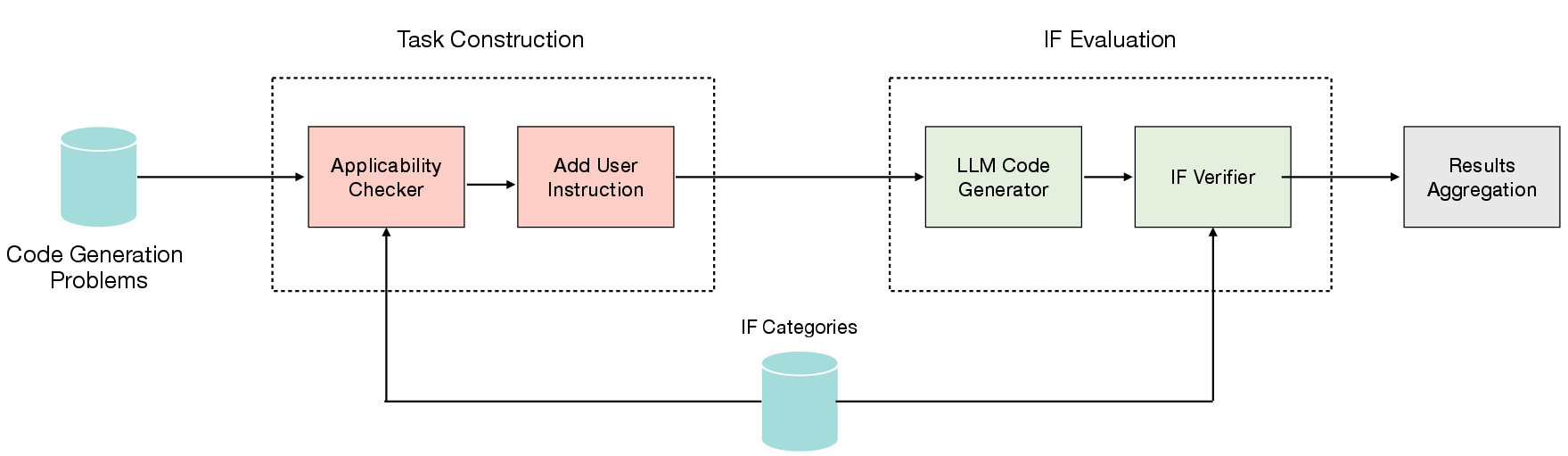
Figure 3: Instruction-following benchmarking framework for code generation.
Instruction adherence is verified through a binary judgment process, supported by both rule-based metrics and LLM assessments to ensure accurate applicability and verification.
Experimental Setup and Results
The experiments extended the LiveBench dataset to support multiple languages. Evaluated on a local machine using a resource-efficient setup, the benchmark involved ten models across diverse families like GPT, Gemini, and Sonnet. A distinct generational improvement was observed, with follow-up tasks consistently outperforming predefined tasks, underscoring the importance of contextual history in instruction execution.
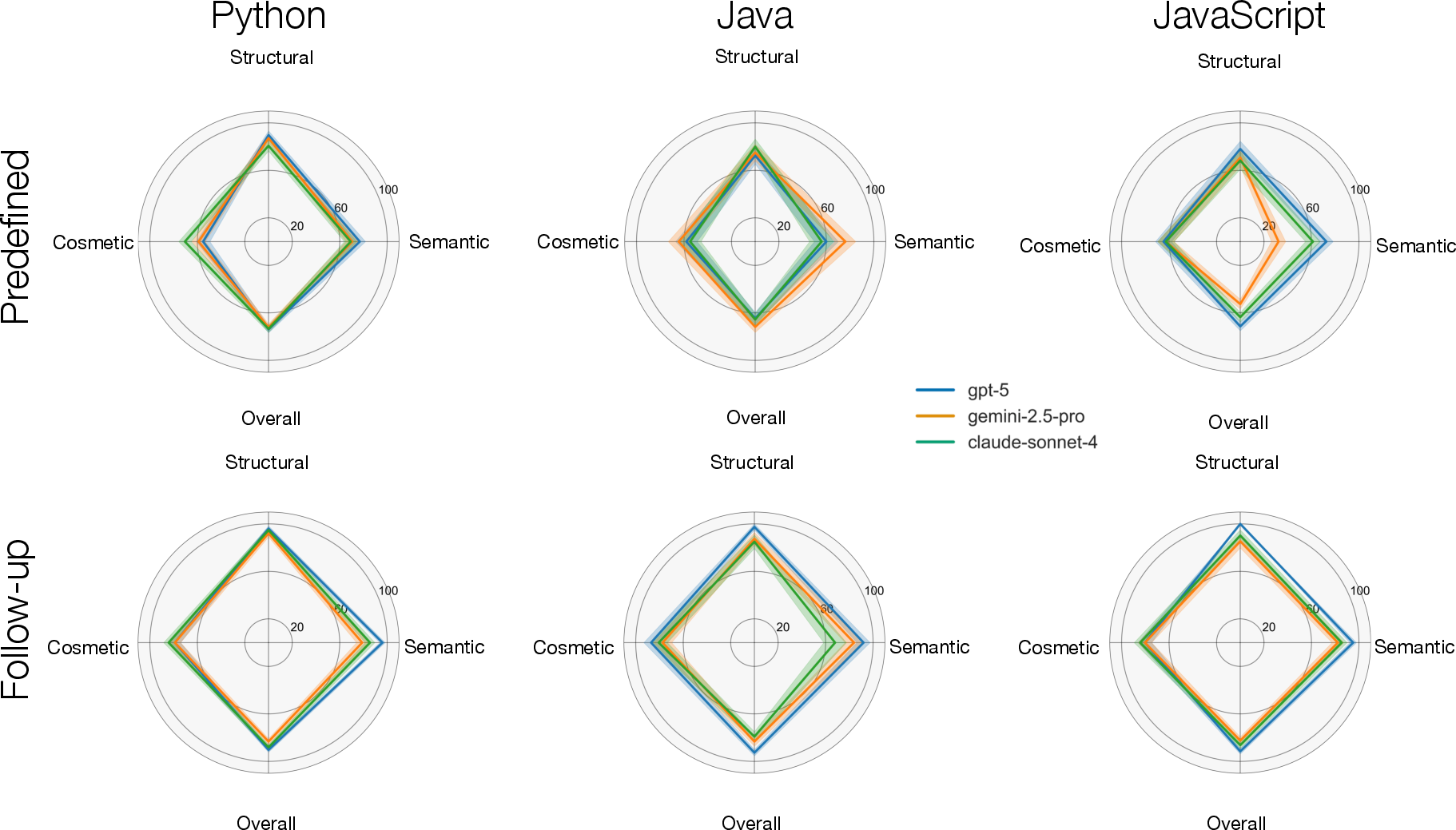
Figure 4: Radar plots of top models showing performance across instruction categories.
The results highlighted significant performance disparities within task types, with structural tasks achieving the highest scores. Despite variances, no model achieved consistent high performance across all categories, indicating substantial room for further development.
Implications and Future Directions
CodeAlignBench represents a pivotal step toward refining code generation models by emphasizing developer-prioritized adjustments over mere functional correctness. While the current benchmark provides substantial insights, future work could involve expanding the instruction catalog and integrating more complex tasks, potentially involving multi-turn interactions to further enhance model evaluation.
Conclusion
The paper offers a formidable contribution to code generation benchmarking by incorporating developer insights into instruction-following evaluations. As the benchmark evolves, it promises to drive advancements in developing models that not only generate functionally correct code but also align closely with nuanced developer preferences, promoting greater applicability in real-world settings.
Through CodeAlignBench, the research community gains a crucial tool for assessing and refining the capabilities of LLMs in tailoring code generation to human expectations, pushing the envelope towards more sophisticated and human-aligned AI systems.