When Instructions Multiply: Measuring and Estimating LLM Capabilities of Multiple Instructions Following
Abstract: As LLMs are increasingly applied to real-world scenarios, it becomes crucial to understand their ability to follow multiple instructions simultaneously. To systematically evaluate these capabilities, we introduce two specialized benchmarks for fundamental domains where multiple instructions following is important: Many Instruction-Following Eval (ManyIFEval) for text generation with up to ten instructions, and Style-aware Mostly Basic Programming Problems (StyleMBPP) for code generation with up to six instructions. Our experiments with the created benchmarks across ten LLMs reveal that performance consistently degrades as the number of instructions increases. Furthermore, given the fact that evaluating all the possible combinations of multiple instructions is computationally impractical in actual use cases, we developed three types of regression models that can estimate performance on both unseen instruction combinations and different numbers of instructions which are not used during training. We demonstrate that a logistic regression model using instruction count as an explanatory variable can predict performance of following multiple instructions with approximately 10% error, even for unseen instruction combinations. We show that relatively modest sample sizes (500 for ManyIFEval and 300 for StyleMBPP) are sufficient for performance estimation, enabling efficient evaluation of LLMs under various instruction combinations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how well LLMs—like ChatGPT—can follow several instructions at the same time. In real life, people don’t just say “write code” or “summarize a text.” They add extra rules like “use bullet points,” “keep it short,” or “follow our team’s style guide.” The researchers built two tests to measure this skill and showed that LLMs get worse as you add more instructions. They also created simple models to predict how much performance will drop without having to test every possible instruction combination.
Key questions
The paper asks simple, practical questions:
- If we give an LLM more rules at once, how much does its performance drop?
- Can we fairly measure this ability using clear, automatic checks (not other models judging)?
- Is there a way to estimate performance on new sets of instructions without testing everything?
How they did it
The team made two special benchmarks (organized tests) that keep the main task the same but change how many instructions are added:
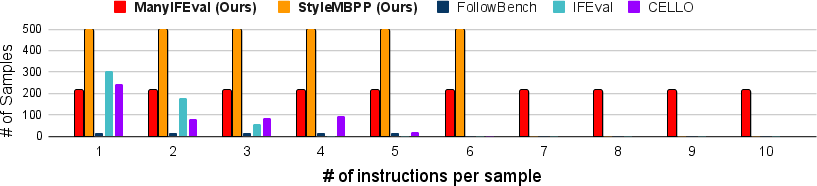
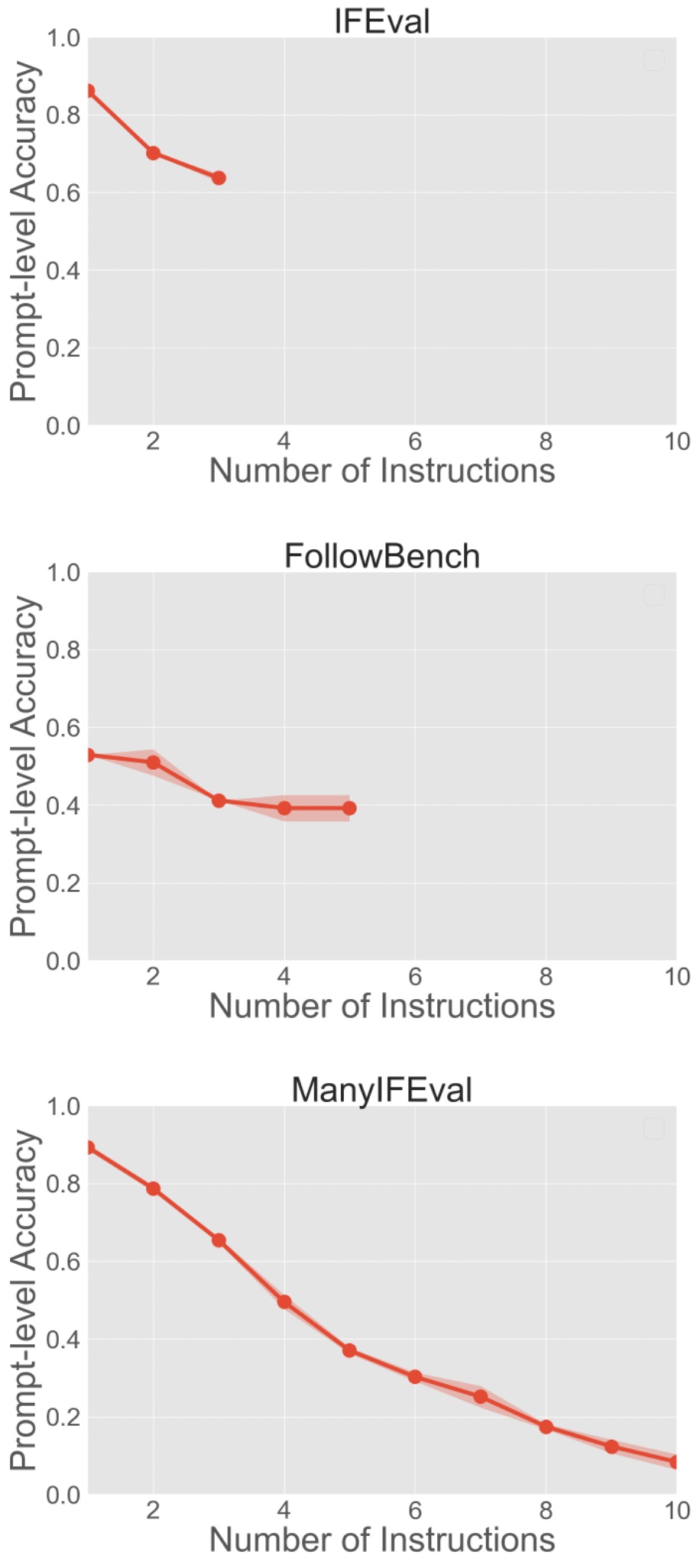
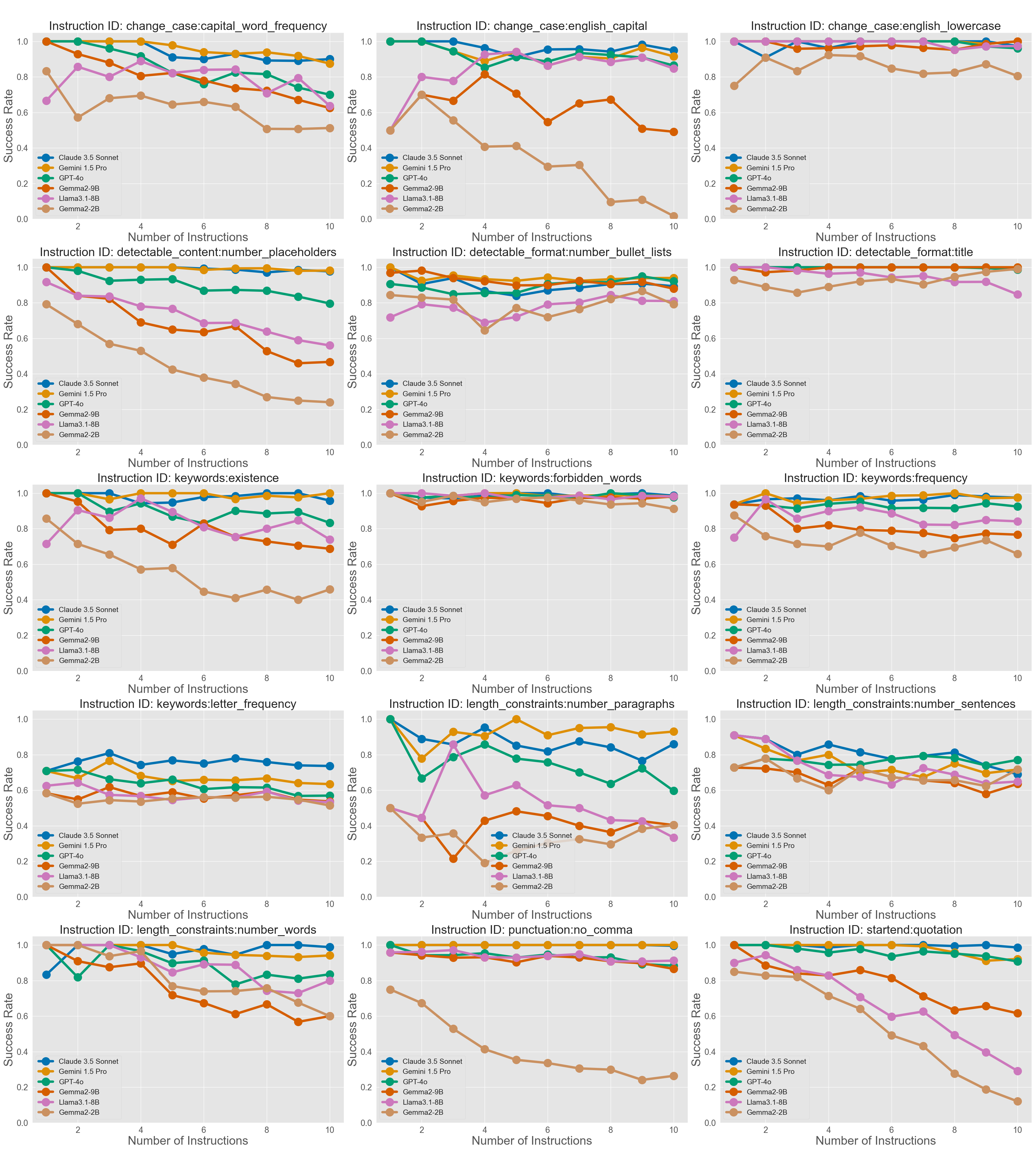
- ManyIFEval (text): Up to 10 instructions for writing tasks, such as “Write a blog post” plus rules like “use bullet points,” “include a specific word,” or “write in uppercase.”
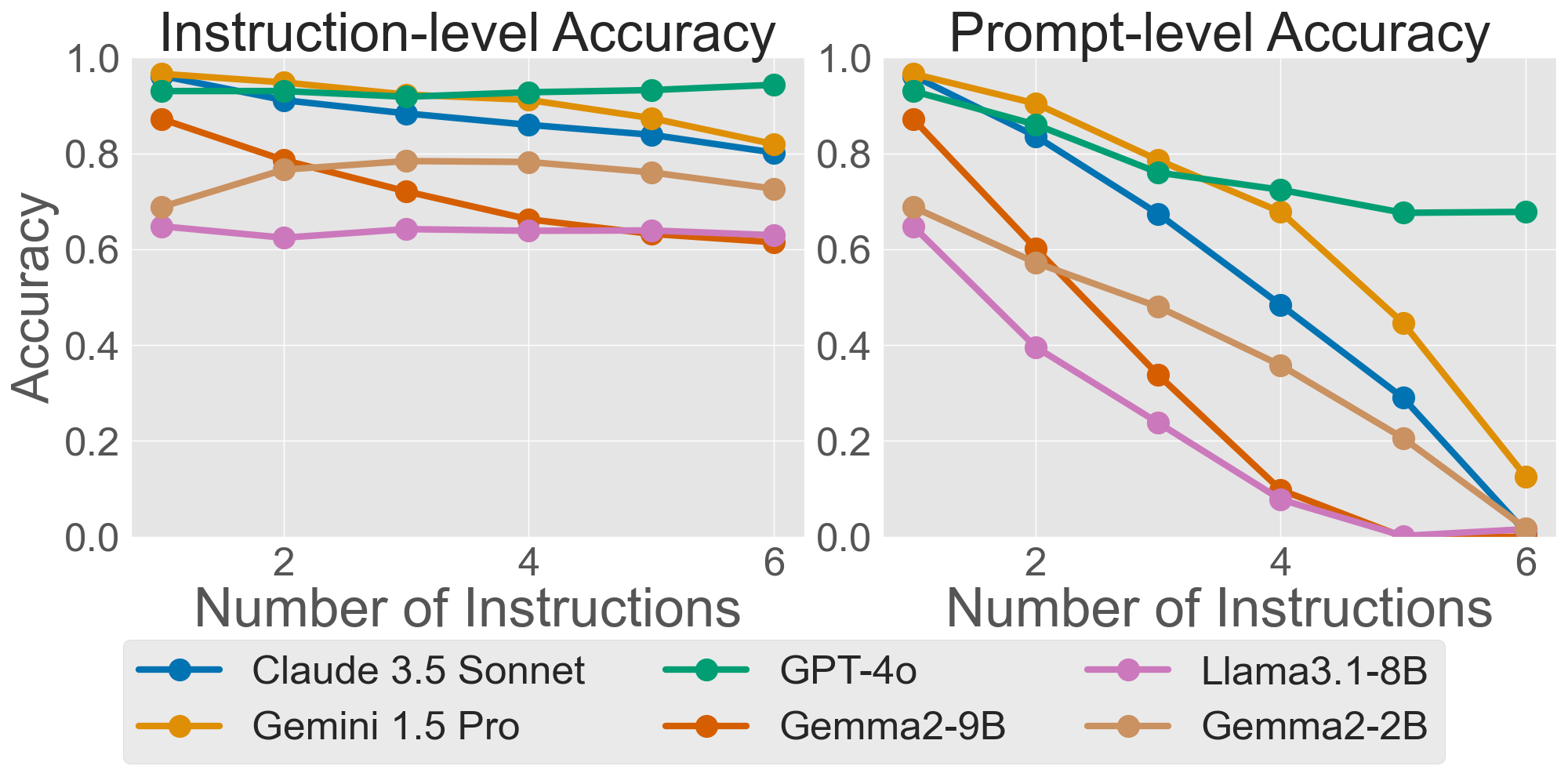
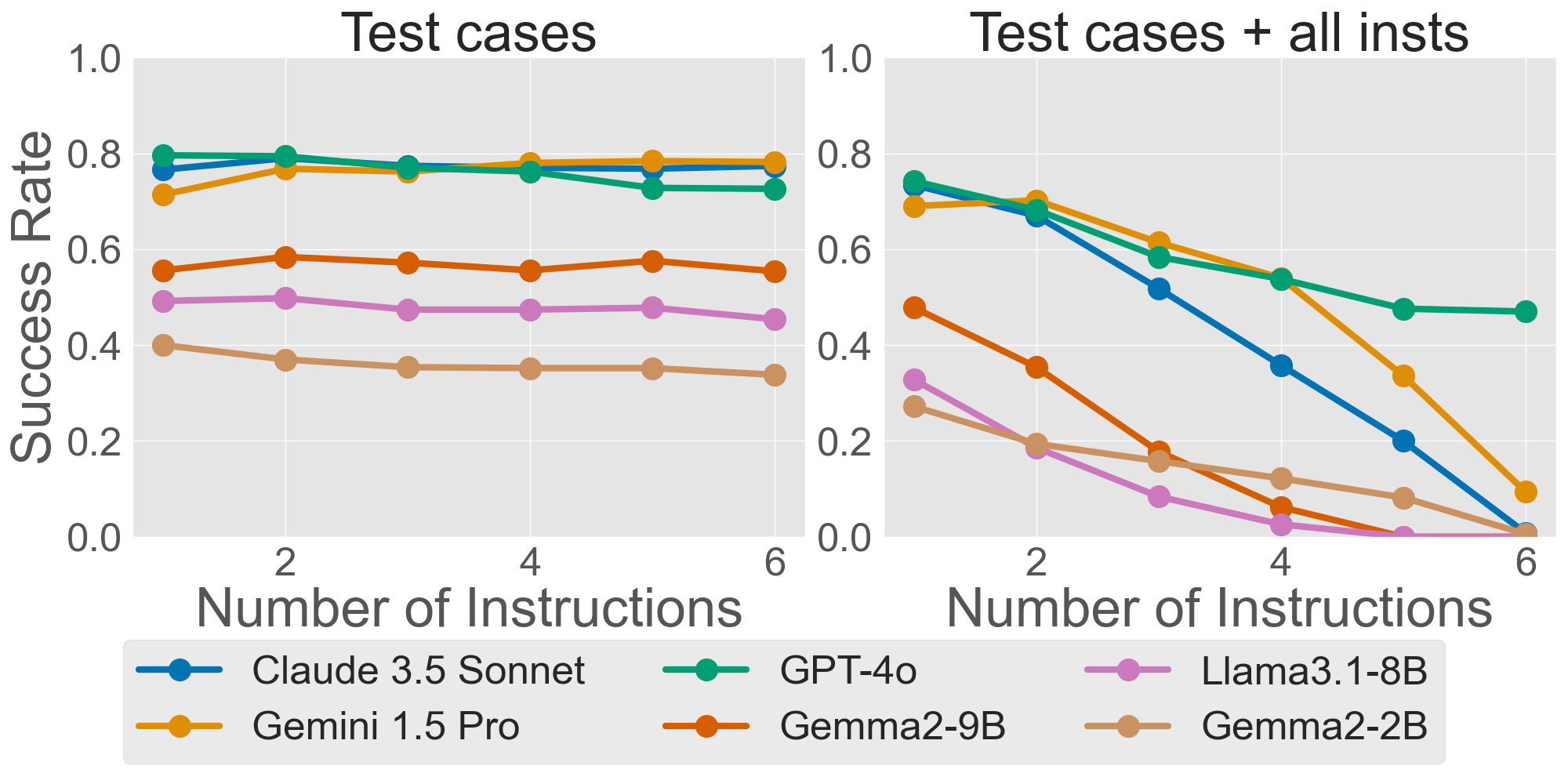
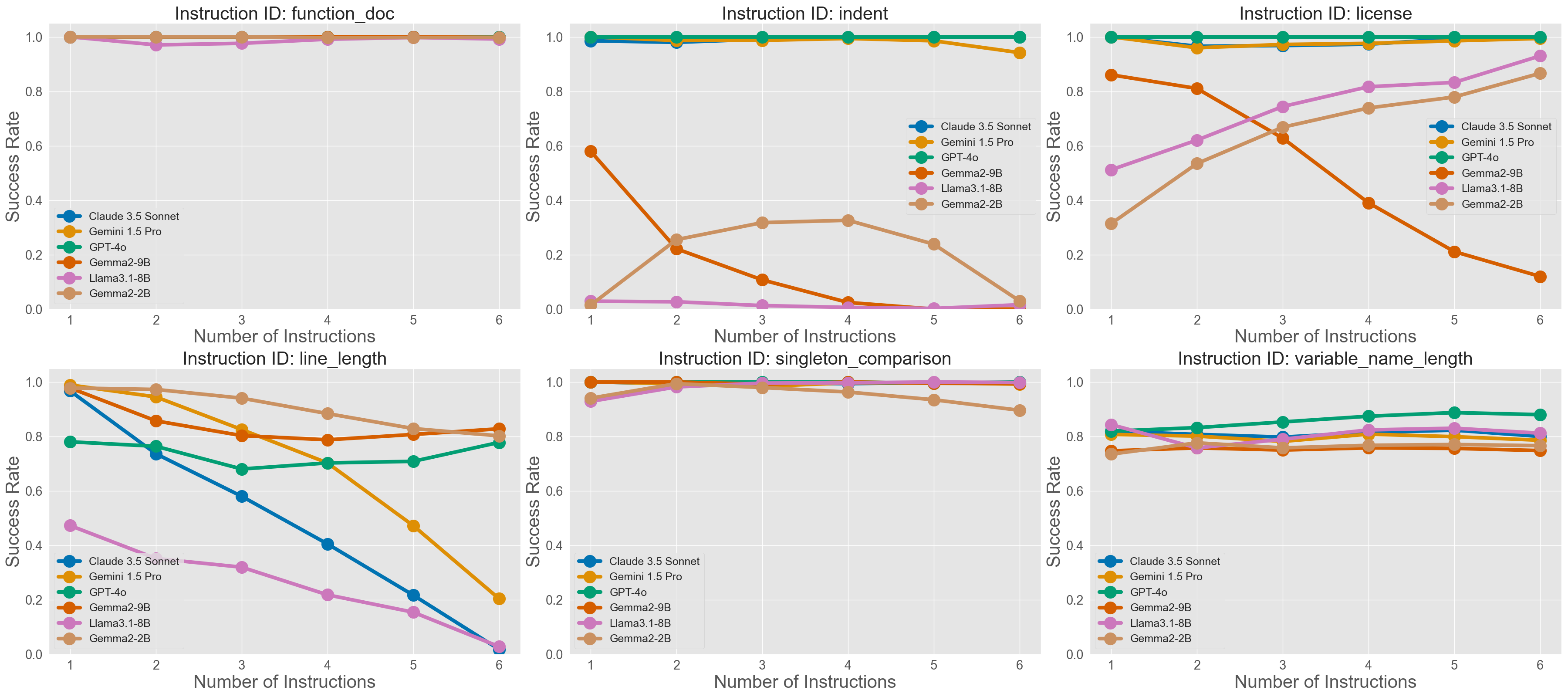
- StyleMBPP (code): Up to 6 style instructions added to basic Python programming problems (from MBPP), such as “use spaces for indentation,” “add docstrings,” “keep lines short,” or “include an MIT License notice.” The code still has to pass test cases.
Important details about the setup:
- The core task stays the same while the number of instructions changes. This makes it fair to see the effect of adding more instructions.
- The rules are checked by programs (rule-based verification), not by another LLM acting as a judge. This is more reliable because it avoids inflated scores.
- They tested 10 different LLMs, both closed (like GPT-4o, Claude 3.5, Gemini 1.5) and open-source models (like Llama and Gemma), using the same clear prompts.
Two simple ways they measured performance:
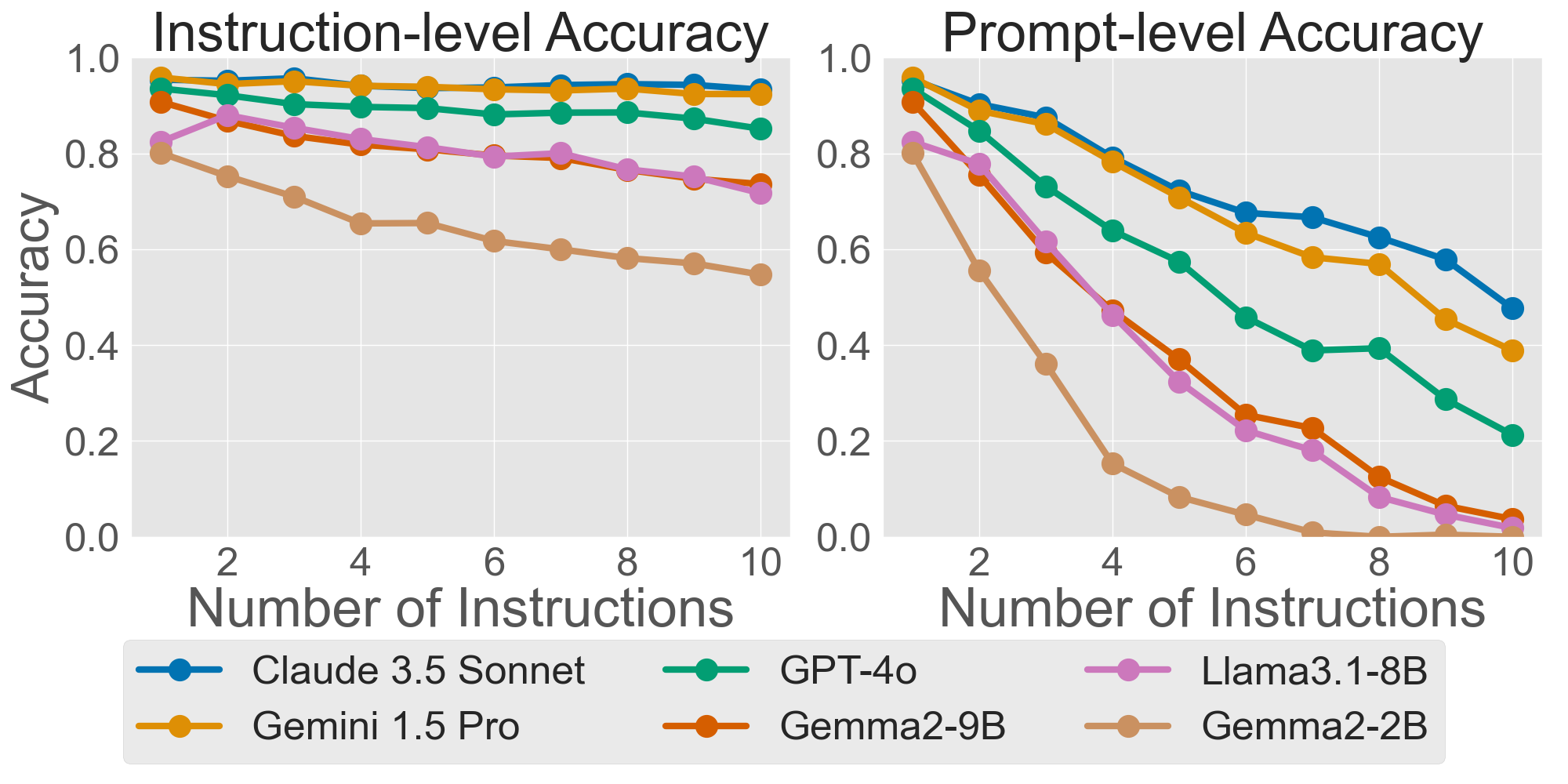
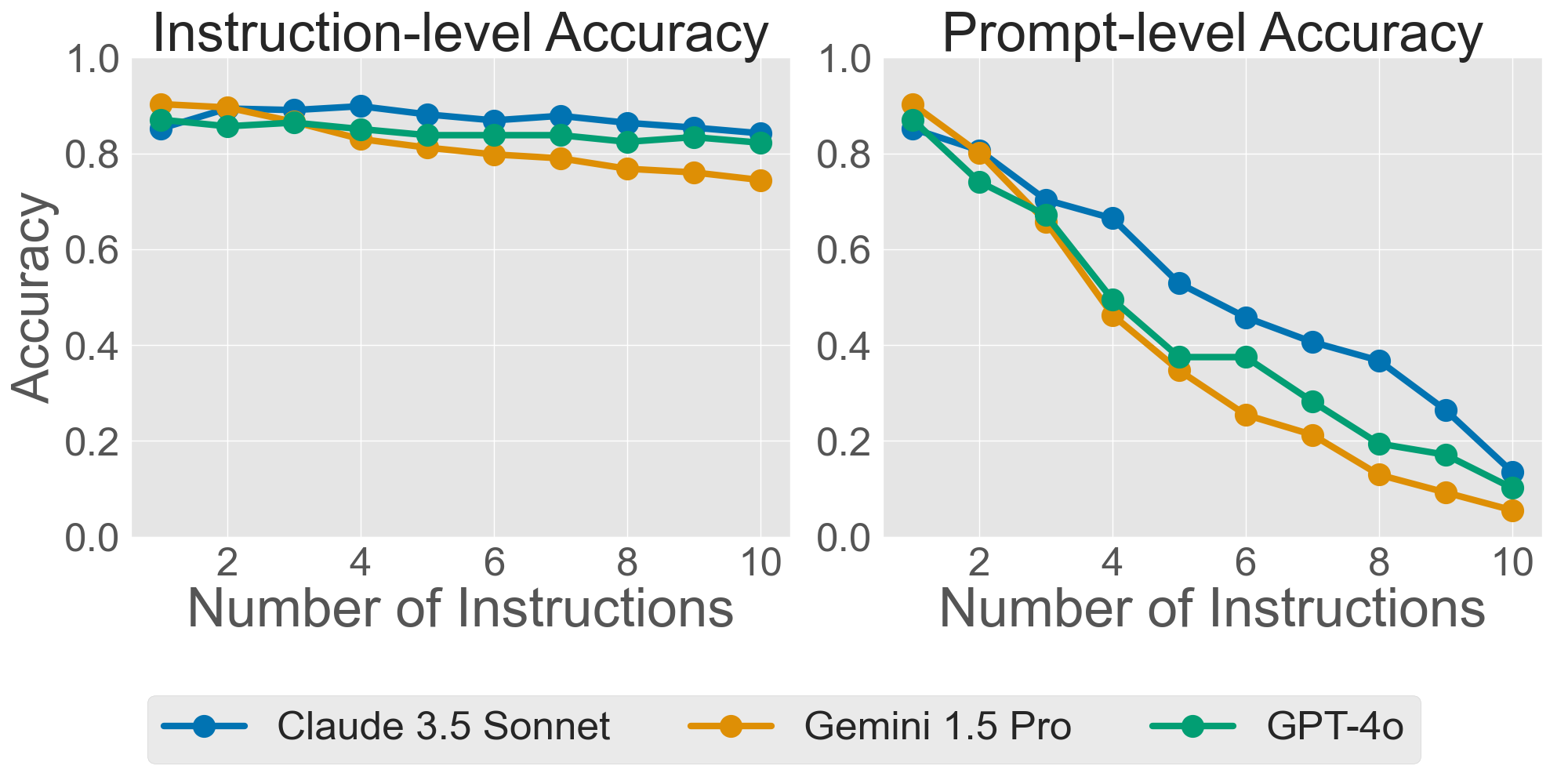
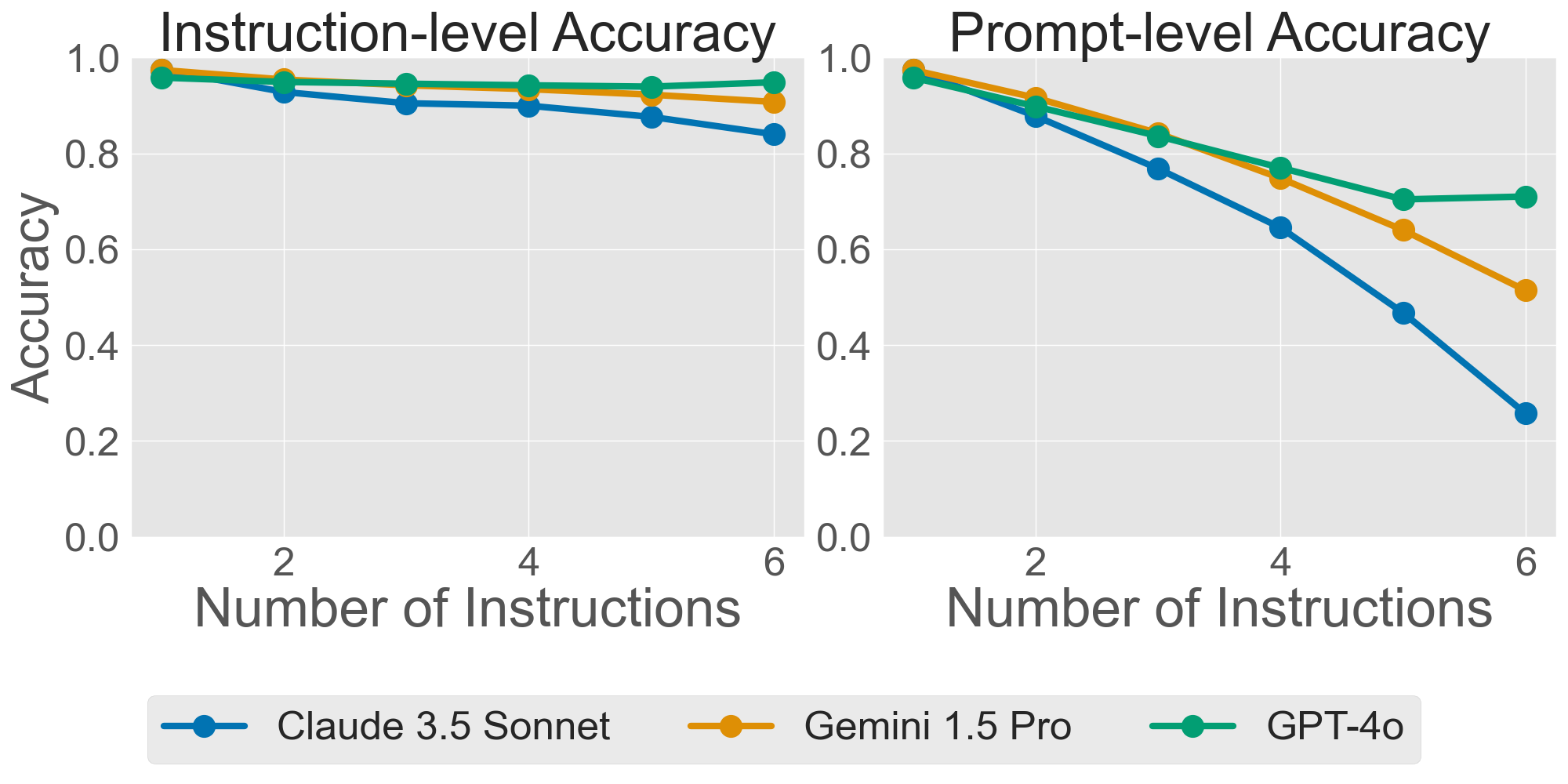
- Instruction-level accuracy: Like grading each rule separately—did the model follow Rule 1? Rule 2? and so on.
- Prompt-level accuracy: Like grading the whole assignment—did the model follow all the rules at the same time?
An everyday analogy: Imagine baking cookies with multiple rules—no nuts, exactly 12 per tray, each the same size, and wrapped neatly. “Instruction-level” asks if you met each rule individually. “Prompt-level” asks if you met all rules at once. The more rules, the harder it is to meet them all at the same time.
They also built simple prediction models to estimate performance without testing every combination:
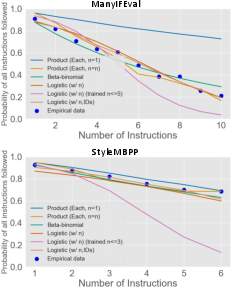
- Naive product: If you think each rule is like flipping a coin with some chance of success, multiply those chances to estimate success on all rules together.
- Beta-binomial: Similar to coin flips, but it first estimates how “fair” the coin is from data.
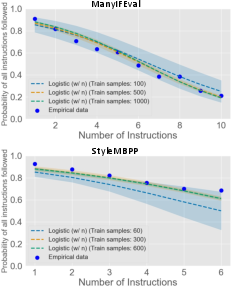
- Logistic regression: Draws a smooth curve that predicts performance based mostly on the number of instructions. Surprisingly, just knowing “how many rules there are” was enough to predict performance quite well.
Main findings
Here are the key results and why they matter:
- Performance drops steadily as you add more instructions. This is true for both text and code. Even if models can follow single rules pretty well, handling many at once is tough.
- For code, passing the test cases (the program works) stays fairly stable. But passing test cases and following all style rules at the same time drops a lot as you add more rules. This shows style + correctness together is harder than correctness alone.
- Rule-based checking is more trustworthy than using an LLM as a judge. LLM judges tend to give higher (over-optimistic) scores, which can hide real problems.
- “Reasoning” models or settings help. Models that plan or step through instructions one by one tend to follow more rules correctly.
- You don’t need huge datasets to estimate performance. With about 500 text samples or 300 code samples, a simple logistic regression (using only the number of instructions as input) can predict performance with roughly 10% error—even for instruction combinations the model hasn’t seen before.
Why it matters
This research has practical impact for anyone using LLMs in real workflows:
- Expect performance to drop as you stack more rules. If you need many constraints, consider breaking tasks into steps or adding reasoning to help the model plan.
- Use programmatic, rule-based checks to measure instruction-following reliably.
- Save time and money: Instead of testing every possible mix of rules, you can estimate performance with small sample sizes and simple prediction models.
- Build better prompts and systems: Knowing which rules cause the biggest drops helps teams design clearer instructions, improve model training, and choose models that handle multi-rule tasks more robustly.
In short, the paper shows that “more rules = harder for LLMs,” provides fair ways to measure this, and offers simple tools to predict performance without exhaustive testing. This helps teams create realistic, efficient, and reliable LLM-powered applications.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions that the paper leaves unresolved. Each item is phrased to guide actionable follow-up research.
- Benchmark scope is restricted to simple, programmatically verifiable constraints; it does not cover semantic instructions (e.g., tone, topical relevance), conditional logic (if/then), multi-step procedures, or nested/ordered constraints—evaluate whether the observed degradation trends hold under these richer instruction types.
- The benchmarks intentionally avoid conflicting or ambiguous instructions; real-world prompts often contain conflicts, ambiguities, or priorities—study models’ ability to detect, negotiate, and resolve conflicting/ambiguous instructions and to respect instruction priority.
- ManyIFEval lacks rule-based verification for the core task description (content quality/goal fulfillment)—add objective checks (e.g., content classifiers, templates, constraint satisfaction on topicality) to measure trade-offs between instruction adherence and task completion.
- Effects of instruction phrasing variability and paraphrase robustness are unexamined—test whether slight rewordings, added verbosity, or noise (typos, formatting) change multi-instruction adherence.
- Instruction order effects are not controlled—randomize and systematically vary ordering to quantify whether and how instruction sequence impacts compliance.
- Multi-turn dynamics are not studied—evaluate instruction retention, updating, and consistency across turns (e.g., instruction drift, overwrites, and adherence over longer dialogues).
- Cross-lingual generalization is not assessed—replicate ManyIFEval and StyleMBPP in other languages (for prompts and instructions) to measure language-specific degradation patterns.
- Code generation is limited to Python and Pylint-style constraints—extend to other languages (e.g., JavaScript/TypeScript, Java, C++) and alternate linters/formatters (e.g., flake8, Black, ESLint) to test generality of style-adherence degradation.
- Tooling dependence and version sensitivity (e.g., specific Pylint versions) are not analyzed—quantify how verifier choice and versioning affect measured performance and reproducibility.
- Dataset curation may bias difficulty (removal of very hard instructions)—perform ablations that re-introduce harder instructions to assess robustness and true capability under realistic distributions.
- Interaction among instructions is not modeled beyond count and IDs—measure pairwise and higher-order interactions (synergy/interference), and incorporate interaction features into predictive models.
- Token budget and sampling confounds are not isolated—control and vary context length, output length, temperature/top‑p, and system prompts to quantify their causal impact on adherence as instruction count grows.
- The estimation approaches do not assess calibration (confidence vs accuracy)—evaluate calibration metrics (e.g., Brier score, reliability diagrams) and propose calibrated predictors for instruction-following success.
- Generalization of estimation models across LLMs is unknown—test transfer: train an estimator on one model’s data and predict performance for different models, and identify features enabling cross-model generalization.
- Scaling to substantially larger instruction counts (>10 for text, >6 for code) is unexplored—probe scaling laws by extending instruction counts and modeling non-linear breakdown or threshold effects.
- Failure-mode analyses are largely aggregate—perform systematic per-instruction and per-sample audits to characterize recurrent error patterns and root causes (e.g., which constraints are most frequently dropped as counts increase).
- The causal mechanisms of degradation are not investigated—conduct mechanistic studies (attention to instruction tokens, activation steering, representational tracking over generation) to link internal signals to missed constraints.
- Mitigation strategies are not systematically tested—evaluate scaffolds like explicit checklists, constraint planning, self-verification loops, tool-based lint/fix cycles, and structured output schemas for improving multi-instruction adherence.
- Reasoning helps but is not rigorously quantified—run controlled experiments comparing reasoning modes (e.g., “plan-then-generate,” chain-of-thought, verification passes) and measure statistical significance and cost-benefit trade-offs.
- Instruction priority, partial credit, and trade-offs are not modeled—introduce weighted metrics and evaluate models’ ability to satisfy higher-priority constraints when all cannot be met.
- Multi-modal instruction following (text+image/audio/code) is untreated—extend benchmarks to multi-modal prompts where constraints span modalities (e.g., layout rules, caption style, code embedded in docs).
- Robustness to real-world prompt composition (templates, UI forms, system messages) is not addressed—test adherence under common deployment settings (chat agents, RAG contexts, long system prompts, tool-augmented environments).
- LLM-as-a-judge limitations are shown for one judge setting only—compare rule-based verifiers to stronger, calibrated judges (e.g., multi-judge ensembles, rubric-guided/CoT judges) and quantify remaining evaluation gaps.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that leverage the paper’s benchmarks (ManyIFEval, StyleMBPP), findings (performance degrades with instruction count; reasoning helps), and estimation methods (logistic regression with small-sample evaluation).
- Industry – Software Engineering
- CI/CD “style + instruction” gate for LLM codegen: Add a StyleMBPP-inspired check to CI that verifies both unit tests and style constraints (indentation, docstrings, line length, license header) on any LLM-generated patches before merge. Tools: a “StyleMBPP plugin” for GitHub Actions/GitLab CI that runs Pylint-style rules plus task tests. Assumptions: style rules are programmatically checkable; target languages have linters; instructions are non-conflicting.
- Prompt linter for engineering teams: A preflight check that scores a prompt’s “instruction complexity” and predicts prompt-level success probability using the paper’s logistic regression approach. It flags risky instruction counts and suggests simplifications or step-wise decomposition. Tools: IDE extension (VS Code/JetBrains), Slack/ChatOps bot. Assumptions: model-specific curves must be fit once with 300–500 examples per model and periodically refreshed.
- Model routing by instruction count: Automatically route high-instruction prompts to a “reasoning” model or enable higher reasoning effort, while using a faster model for low-instruction prompts. Workflow: infer instruction count → look up predicted success → choose model/inference settings. Assumptions: access to multiple models; curves are model-specific; privacy/compliance constraints allow routing.
- Industry – Content Operations and Marketing
- Template design with instruction budgets: Standardize prompt templates (e.g., summaries, blogs, product descriptions) with a cap on simultaneous instructions (bulleting, tone, length, keyword inclusion), or split constraints across sequential calls to increase reliability. Tools: CMS-integrated prompt templates with embedded “ManyIFEval curve” thresholds. Assumptions: constraints can be decomposed across steps without losing context or fidelity.
- Industry – LLM Procurement, Vendor Management, and MLOps
- Low-cost, high-confidence model evaluation: Use the paper’s sample-efficient estimation (≈500 samples for text, ≈300 for code) and rule-based verifiers to build a “Multi-Instruction Readiness Score” per model. Use cases: RFPs, model upgrades, A/B tests, and SLA definition. Tools: “Benchmark-in-a-box” harness using ManyIFEval/StyleMBPP plus logistic regression fit. Assumptions: representative sampling of organization-specific instructions; results are model- and domain-specific.
- Capacity and compute planning for evaluation: Replace exhaustive evaluation of all instruction combinations with predictive curves; plan evaluation budgets while maintaining reliable ranking. Assumptions: curve stability over time; retraining curves on drift.
- Academia – Benchmarking and Curriculum
- Reproducible instruction-following labs: Adopt ManyIFEval/StyleMBPP and their rule-based evaluators for coursework and research, avoiding LLM-as-a-judge bias. Tools: ready-to-use dataset and verification code from the paper’s repo. Assumptions: course objectives align with programmatically verifiable constraints.
- Policy, Compliance, and Auditing
- Evidence-based testing guidelines: Encourage rule-based, programmatic verification for instruction compliance in audits (e.g., formatting, disclaimers, disclosure lines). Use predictable degradation curves to set safe “instruction budgets” in regulated workflows. Sectors: finance (disclosures), healthcare (sectioned notes), legal (required clause inclusion). Assumptions: constraints are checkable; tasks remain non-conflicting.
- Education – Teaching and Assessment
- Auto-grading of multi-constraint assignments: Grade formatting, structure, and length constraints objectively with rule-based checks; reduce reliance on subjective rubric matching. Tools: LMS plugin using ManyIFEval-style checks (e.g., bullet count, specific phrases, heading schema). Assumptions: assignment constraints are programmatically verifiable.
- Daily Life – Power Users and Teams
- Stepwise prompt assistant: A lightweight tool that warns when “too many instructions” are combined and offers to split them into sequential prompts with verification between steps. Tools: browser extension for chat UIs. Assumptions: user is willing to run multi-step flows; session memory is sufficient to carry context across steps.
Long-Term Applications
These require additional research, scaling, or domain adaptation beyond the current benchmarks and scope.
- Sector-Specific, Programmatic Verifiers
- Healthcare: Structured clinical note generation with verifiable section requirements, mandatory phrases, length thresholds, and privacy disclaimers. Tools: domain verifiers akin to ManyIFEval for EHR notes (H&P, discharge), validated against hospital policies. Dependencies: domain-specific rules; strong PHI handling; bias and safety reviews.
- Finance: Regulatory report drafting with deterministic checks for required sections, terminologies, disclosure sentences, and formatting. Tools: compliance verifiers aligned to SEC/ESMA templates. Dependencies: evolving regulations; legal sign-off; rigorous change control.
- Legal: Contract drafting verifiers (clause presence, section ordering, defined terms) that act as guardrails around LLM outputs. Dependencies: high-quality clause libraries; conflict detection beyond simple rules.
- Robust Multi-Instruction Model Design
- Architecture/training upgrades for constraint tracking: Train models to internally represent and satisfy “instruction sets” (explicit constraint memory, attention steering, activation steering, or reward shaping for prompt-level accuracy). Tools: curriculum learning with growing instruction counts; contrastive feedback on missed constraints. Dependencies: access to model weights or training loops; data of compatible, high-quality multi-instruction prompts.
- Inference-time planning agents: Systems that parse instructions into a checklist, plan generation order, self-verify each constraint, and revise until all pass. Tools: “checklist planner” + rule-based verifier loops. Dependencies: latency tolerance; reliable verifiers for semantic constraints; cost controls.
- Cross-Language and Multi-Language Codegen Governance
- From Python to polyglot style/compliance: Extend StyleMBPP to TypeScript, Java, C/C++ with linters and safety/compliance standards (e.g., MISRA C, AUTOSAR, DO-178C artifacts). Tools: multi-language CI guardrails for LLM-generated code. Dependencies: linters/compilers/tests per language; organizational adoption of style/standard rules.
- Standardization & Certification
- Multi-instruction capability standards: Define a common “Instruction Complexity Index” and “Degradation Curve” reporting for model cards and enterprise certifications. Policy use: procurement checklists, regulated deployment approvals. Dependencies: consensus bodies; reproducible benchmarks; avoidance of LLM-judge bias.
- Human-in-the-Loop UX Patterns
- Guided, form-based prompting: Product UIs that turn many free-form instructions into structured fields and staged steps, minimizing simultaneous instruction count while preserving fidelity. Sectors: customer support content, knowledge base authoring, training material production. Dependencies: product integration; user acceptance; workflow redesign.
- Robotics and Task Planning
- Natural-language tasking with multiple constraints: Convert user instructions into a constraint set with feasibility checks and plan synthesis; estimate success risk from the instruction count and select fallback strategies (e.g., staging tasks). Dependencies: grounded execution verifiers; safety constraints; multimodal state understanding.
- Research and Diagnostics
- Mechanism-level explanations: Use attention/activation analyses to identify why constraints are dropped as instruction counts grow; design neuron/attention steering methods that prioritize instruction tokens. Dependencies: introspection tooling; access to internal activations or open weights.
- Risk Management and Governance
- Complexity-aware guardrails: Enterprise policies that cap simultaneous constraints per use case and require stepwise flows when predicted success drops below a threshold. Tools: risk dashboards plotting success probability vs. instruction count; automatic workflow branching. Dependencies: accurate, maintained model-specific curves; change management when models update.
Assumptions and Dependencies (cross-cutting)
- Programmatic verification coverage: Immediate gains rely on constraints that can be checked deterministically (formatting, keywords, structure). Many semantic or conditional instructions remain challenging to verify automatically.
- Non-conflicting instruction sets: The paper’s results assume compatible instructions; real workflows may have subtle conflicts that need detection/resolution.
- Model- and domain-specific curves: The logistic regression estimator is fit per model and instruction distribution; transferring curves across models/domains can reduce accuracy.
- Sample representativeness: The recommended 300–500 sample sizes assume representative prompts/instructions for your workload.
- Language and modality scope: Findings are demonstrated on English text and Python code; extension to other languages/modalities (multimodal, speech) needs validation.
- Zero/few-shot settings: Results are primarily from zero-shot prompting; fine-tuning or specialized prompting could shift curves and must be re-estimated.
- Cost/latency trade-offs: Planner/verification loops and reasoning modes improve adherence but increase latency and cost; routing and budgets must account for this.
Glossary
- Beta distribution: A continuous probability distribution on [0,1], often used as a prior for probabilities in Bernoulli processes. "but treats itself as a random variable drawn from a Beta distribution , and estimates , via maximum likelihood from the training data."
- Beta-Binomial: A hierarchical model where the success probability of Bernoulli trials is drawn from a Beta distribution to capture variability. "Specifically, we explore three modeling approaches: naive estimators, beta-binomial, and logistic regression."
- Bernoulli trial: A single experiment with two outcomes (success/failure), used to model instruction-following success. "We model the success or failure of following a single instruction as a Bernoulli trial with probability ."
- Docstring: A string literal in Python that documents a function, class, or module. "Functions must include docstrings."
- Explanatory variable: An independent variable used in regression to explain or predict an outcome. "a logistic regression model using instruction count as an explanatory variable can predict performance with approximately 10\% error, even for unseen instruction combinations."
- Hard Satisfaction Rate (HSR): A metric from FollowBench indicating whether all constraints in a prompt are simultaneously satisfied. "This is Hard Satisfaction Rate (HSR) in FollowBench."
- Instruction identifiers: Unique numerical labels for instruction types used as features in modeling. "incorporates both the instruction count and instruction identifiers, unique numerical labels assigned to each distinct type of instruction, as features."
- Instruction-level Accuracy: The proportion of individual instructions satisfied across prompts. "Instruction-level Accuracy is the success rate of following individual instructions in its response (\autoref{eq:inst_level_accuracy})."
- LLM-as-a-Judge: Using a LLM to evaluate outputs instead of rule-based checks. "LLM-as-a-Judge tends to inflate accuracy scores, particularly as instruction count increases."
- Logistic regression: A statistical model for binary outcomes that estimates success probabilities from input features. "We train logistic regression models that predict the probability of following all instructions successfully, based on features such as the number of instructions and instruction identifiers."
- Maximum likelihood: An estimation method that chooses parameters maximizing the likelihood of observed data. "and estimates , via maximum likelihood from the training data."
- Mean absolute error: The average absolute difference between predicted and observed values. "achieving a mean absolute error of 0.03 ± 0.04 when predicting performance on 10 instructions using training data from up to 9 instructions."
- Pearson correlation: A measure of linear correlation between two variables, denoted r. "Mean absolute error ± standard deviation and Pearson correlation (r) of Prompt-level Accuracy predictions by various performance estimation models."
- Programmatic verification: Automated rule-based checking to objectively assess compliance with instructions. "reinforcing the importance of objective, programmatic verification for reliable benchmark evaluation."
- Prompt-level Accuracy: The rate at which all instructions in a prompt are satisfied simultaneously. "Prompt-level Accuracy is the the success rate of following all given instructions simultaneously for a particular prompt (\autoref{eq:prompt_level_accuracy})."
- Pylint: A Python static analysis tool for enforcing coding style and detecting errors. "We selected common Python coding style guidelines, primarily focusing on those verifiable using Pylint~\citep{pylint}."
- Reasoning traces: Intermediate model-generated plans or explanations used during reasoning. "In reasoning traces, DeepSeek-R1 explicitly checks each given instruction one by one to formulate a plan of approach as shown in \autoref{tab:example_reasoning_trace}."
- Rule-based verification: Deterministic evaluation based on explicit rules, rather than model judgments. "Comparison of Prompt-level Accuracy on ManyIFEval using rule-based verification vs. LLM-as-a-Judge (GPT-4o zero-shot)."
- Soft Satisfaction Rate (SSR): A FollowBench metric measuring average per-instruction compliance across prompts. "This is Soft Satisfaction Rate (SSR) in FollowBench."
- Zero-shot prompting: Evaluating models by providing tasks without in-context examples or fine-tuning. "All models were evaluated using zero-shot prompting presenting the task description along with varying numbers of instructions."
Collections
Sign up for free to add this paper to one or more collections.