SR-Eval: Evaluating LLMs on Code Generation under Stepwise Requirement Refinement
Abstract: LLMs have achieved remarkable progress in code generation. However, existing benchmarks mainly formalize the task as a static, single-turn problem, overlooking the stepwise requirement changes and iterative workflows in real-world software development. This mismatch limits the understanding of how well LLMs can support real-world development workflows. Constructing such iterative benchmarks is challenging due to the lack of public interaction traces and the difficulty of creating discriminative, turn-specific test cases. To bridge this gap, we present SR-Eval, a benchmark specifically designed to assess LLMs on iterative code generation under Stepwise requirements Refinement. SR-Eval spans both function-level and repository-level tasks in Python and Java, enabling fine-grained and progressive evaluation across evolving requirements. The construction of SR-Eval follows a carefully designed pipeline that first leverages a multi-agent-based requirement generation method to simulate the development process and recover the multi-round interaction process from final requirements, then employs a semantic-aware discriminative test case generation component to ensure discriminative and consistent evaluation at each turn. SR-Eval comprises 443 multi-turn tasks and 1,857 questions at both function and repository levels. Using SR-Eval, we evaluate 11 representative LLMs with three prompting strategies that simulate different usage patterns. Results show that iterative code generation under stepwise requirement refinement remains highly challenging: the best-performing model achieves only 22.67% completion rate on function-level tasks and 20.00% on repository-level tasks. We further observe that prompting strategies substantially influence performance, highlighting the need for the development of advanced methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
SR-Eval: A plain-English guide to a new way of testing code-writing AIs
1) What this paper is about
This paper introduces SR-Eval, a new “obstacle course” (benchmark) for code-writing AIs, also called LLMs. Unlike most tests that give the AI one big, complete instruction and expect a finished program in one go, SR-Eval checks how well an AI handles real-life coding, where instructions change step by step. Think of it like building an app where your teacher keeps adding new rules every round. The AI must update its code each time and keep everything working.
2) The key questions the paper asks
The paper asks a few simple questions:
- Can today’s AIs handle coding tasks that get refined over multiple steps, like in real software projects?
- Which ways of talking to the AI (prompting strategies) help it do better in these multi-step tasks?
- Can the authors build a fair, high-quality test that checks the AI correctly at every step, not just at the end?
3) How they built and ran the tests (in simple terms)
To make SR-Eval, the authors needed realistic, step-by-step coding tasks and matching tests for each step.
Here are the main ideas, explained with everyday analogies:
- Two sizes of tasks:
- Function-level: small tasks (like writing one helper function).
- Repository-level: big tasks inside real projects with many files (like editing a feature in a real app).
- Two programming languages: Python and Java.
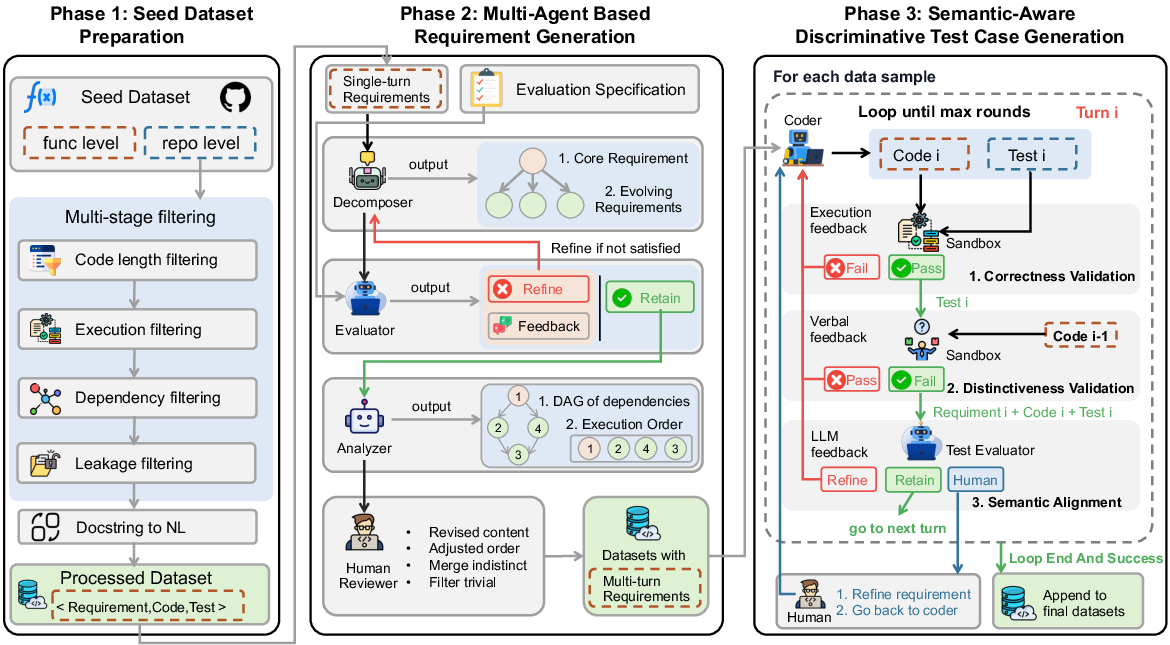
- How they created multi-step tasks without private chat logs:
- They started with good single-step coding tasks from existing datasets (these are their “seeds”).
- They used a “virtual team” of AI agents to turn a complete requirement into a series of evolving steps:
- Decomposer: breaks the big requirement into a core goal plus extra steps (new features, edge cases, design tweaks).
- Evaluator: checks if each step is testable, unique, realistic, and complete enough. If not, it asks for fixes.
- Analyzer: figures out the best order to do the steps, like making a plan that avoids conflicts.
- This is like taking a finished recipe and rewriting it into a mini cooking class with rounds: first boil pasta, then add sauce, then add spices, then handle allergies, and so on.
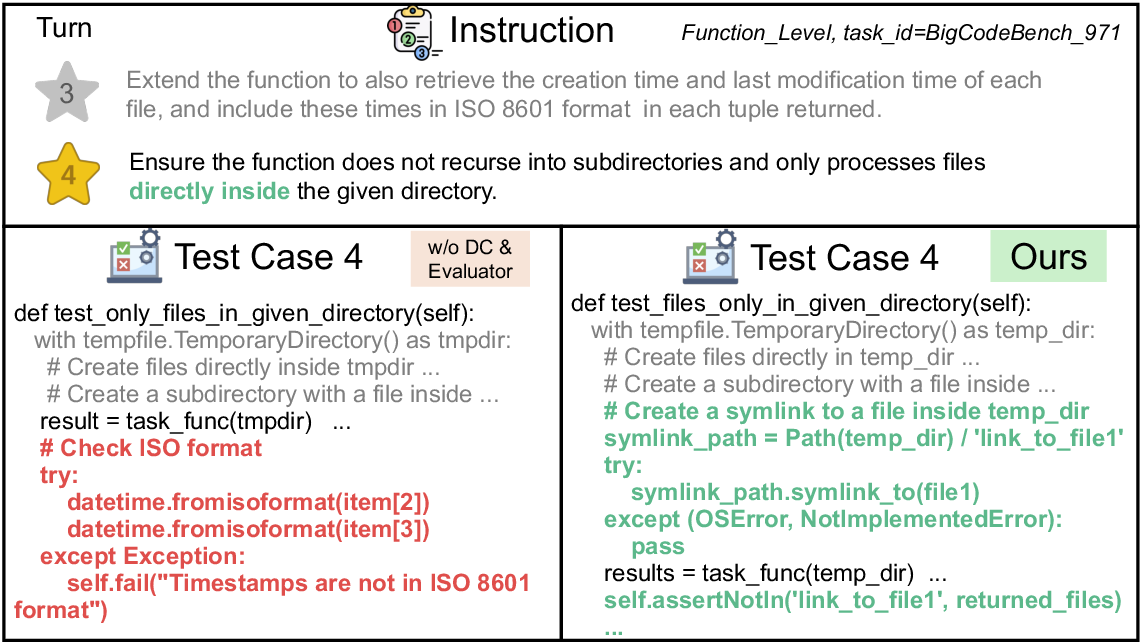
- Smarter test cases for every step: The authors designed a three-stage test-making process to make sure tests really match each new requirement: 1) Correctness: Do the code and tests actually run and make sense? If not, try again with feedback. 2) Distinctiveness: Do the new tests catch the new rule, not just re-check old stuff? They run the new tests on last round’s code; if they still pass, the tests aren’t specific enough and must be improved. 3) Semantic alignment: Do the tests truly match the written requirement (names, messages, expected behavior), instead of assuming things that weren’t asked for?
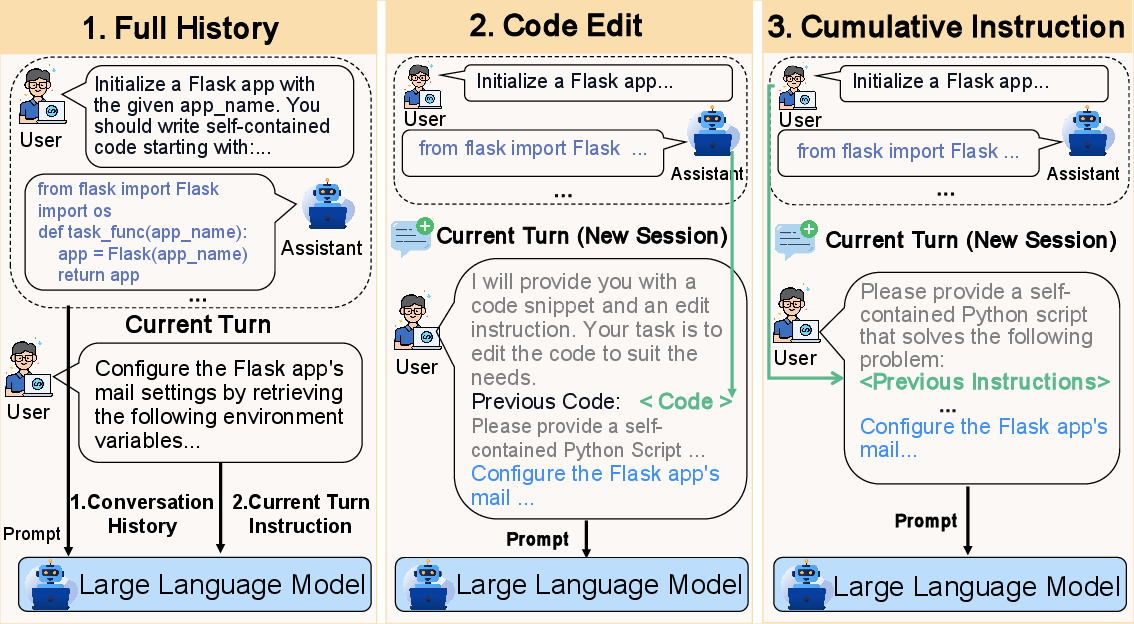
- Ways to prompt the AI (how we talk to it):
- Full History: give the whole conversation so far (all instructions and AI answers).
- Code Edit: give only the latest instruction and the code from last round (like editing an existing file).
- Cumulative Instruction: give all instructions so far, but not previous AI code (like a cleaned-up requirement list).
- Two context settings when testing:
- Basic: keep feeding the AI its own previous code (which might have mistakes), like real life.
- Golden: feed the AI the correct previous code (a best-case scenario), to see the upper limit of performance.
- How success is measured (plain terms):
- Per-turn accuracy: how often the AI passes the tests at each step.
- Average accuracy: the average of those per-turn scores across all steps.
- Completion rate: the percent of tasks where the AI succeeds at every step from start to finish.
- Token cost: how many AI tokens (words/pieces) were used per task.
4) What they found and why it matters
The authors tested 11 well-known AIs across 443 tasks (1,857 step-by-step questions total), in both Python and Java, and at both function and repository level.
Here are the big takeaways:
- It’s hard for today’s AIs. Even the best model only finished all steps for about 22.67% of function-level tasks and 20.00% of repository-level tasks. That shows multi-step, changing requirements are much tougher than one-shot problems.
- How you prompt the AI matters a lot. Different ways of giving context (like Full History vs Code Edit) can change results noticeably. Good “interaction design” helps.
- “Reasoning mode” alone isn’t a magic fix. Simply turning on a model’s thinking/reasoning mode didn’t guarantee better multi-step coding; the setup and prompts still matter.
- Their test-building method works. The three-stage test process (correctness, distinctiveness, semantic alignment) produced stronger, clearer tests that can tell whether the AI actually handled each new requirement.
Why this matters: Most real software isn’t built in one perfect pass. It’s built in rounds, with changing needs, bug fixes, and edge cases. These results show that current AIs still struggle with that realistic process, so we shouldn’t assume an AI will “just handle it.” We need better tools, prompts, and models.
5) What this could change in the future
- Better AI coding assistants: SR-Eval gives developers and researchers a fair way to measure whether new models are actually good at real-world, step-by-step coding, not just toy problems.
- Smarter prompting and workflows: Teams building tools like AI copilots can use these results to design better chat flows and editing modes that help models succeed across multiple rounds.
- Stronger training targets: Model makers can train and tune AIs on SR-Eval-style tasks so they learn to keep context straight, update code safely, and handle evolving requirements.
- More trustworthy automation: As tests become more precise for each step, developers can rely on AI help without losing track of what changed and why.
In short: SR-Eval is like upgrading a driving test from a straight, empty road to real city traffic with turns, lights, and surprises. It shows that today’s AIs can drive, but still have a lot to learn before they handle rush-hour software development.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed at guiding future research.
- Authenticity of simulated requirement refinement: Validate the multi-agent–generated requirement sequences against real developer–LLM dialogues; collect small-scale real traces to quantify “scenario authenticity” and alignment with actual agile workflows.
- Human intervention statistics: Report how often “QUESTION REFINE” was triggered, what kinds of ambiguities occurred, and the impact of human edits on final dataset quality and consistency.
- Generation-model bias and circularity: Assess bias introduced by using Qwen3 for decomposition/evaluation and Claude for reference coding; re-generate subsets with different LLMs and compare task styles and test difficulty.
- Function-level contamination checks: Conduct contamination audits for BigCodeBench-Hard and AutoCodeBench similar to the repository-level process to rule out dataset leakage for evaluated models.
- Test case reliability and coverage: Measure coverage (e.g., statement/branch), mutation score, and flakiness; provide quantitative evidence that “distinctiveness” tests robustly detect spec changes rather than overfit golden code.
- Implicit requirement leakage in tests: Quantify the prevalence of tests asserting outputs not explicitly specified; build automatic detectors and guidelines to reduce unintended spec creep.
- Repository-level realism constraints: Expand beyond single-function edits to multi-file changes and cross-file dependencies; evaluate retrieval/tool-use strategies required for realistic repository evolution.
- Limited language and ecosystem coverage: Extend beyond Python and Java to JavaScript/TypeScript, Go, Rust, C/C++; include diverse build systems, dependency managers, and frameworks.
- Turn count cap and order sensitivity: Investigate longer iterative chains (>5 turns), provide multiple valid turn orders per task, and measure performance sensitivity to instruction sequencing.
- Dependency DAG verification: Validate DAGs with human experts; study alternative orderings and their impact on model performance and error propagation.
- Prompting strategy breadth: Evaluate additional strategies (planner/tool-use, unit-test-first/TDD prompts, code-run feedback loops, chain-of-thought/scratchpad, code-diff prompts, retrieval-augmented summaries).
- Metrics beyond pass@1: Report pass@k, self-consistency with sampling, edit distance from reference, compile/runtime error rates, regression preservation across turns, and time/latency in addition to token cost.
- Early error propagation analysis: Provide causal analysis of how failures at early turns affect later turns; measure state retention, constraint preservation, and cumulative drift.
- Realism of Golden vs Basic settings: Study hybrid developer-in-the-loop workflows (partial acceptance/correction of model outputs); quantify how human corrections change outcomes versus purely golden histories.
- Context-window effects: Quantify performance degradation with growing prompt/repo context; evaluate retrieval/summarization policies to manage long contexts without losing prior constraints.
- Dataset scale and domain diversity: Increase repository count (especially Java, currently only five) and include domains like web frameworks, data processing, concurrency, GUI, and networking.
- Non-functional requirements: Incorporate measurable proxies for performance, memory use, security, readability, and API stability; design testable NFR tasks and metrics.
- Backward compatibility and regression: Add regression suites that ensure prior behavior is retained unless explicitly changed; adjust distinctiveness checks to avoid incentivizing breaking changes.
- Reference implementation validity: Independently audit reference implementations for correctness and hidden assumptions; disclose audit outcomes and known limitations.
- Execution environment reproducibility: Document exact runtime environments (OS, interpreter/compiler versions); assess test flakiness across platforms and provide containerized setups.
- Failure taxonomy: Provide a categorized error analysis (spec misinterpretation, API misuse, state/context loss, edge-case handling failures) to guide targeted method development.
- Systematic test-time scaling (TTS) ablations: Vary “thinking” levels, deliberation steps, and planning tokens across models; measure benefits and costs under iterative scenarios.
- Cost–accuracy trade-offs: Relate accuracy and completion rates to token cost, latency, and dollar cost; publish Pareto fronts to inform practical deployments.
- Tool-augmented agents: Evaluate integration with code search, documentation retrieval, static analysis, linters, and build systems; measure gains on repository-level tasks.
- Release articulation: Clarify dataset licensing, full reproducibility scripts, environment specs, and per-task scorecards; provide granular annotations (requirements, dependencies, test rationales).
- Security and safety evaluation: Add checks for insecure patterns (e.g., injection, insecure file handling); provide security-focused iterative tasks with verifiable tests.
- Cross-language transfer: Align analogous tasks across languages to study transfer effects and language-specific failure modes.
- Benchmark calibration vs real-world difficulty: Collect human developer baselines on SR-Eval tasks to calibrate difficulty and contextualize LLM performance.
- Handling ambiguity and clarification behaviors: Include controlled ambiguous requirements; measure models’ ability to ask clarifying questions and converge to correct specs.
- Multi-file refactoring and API migration: Design tasks requiring concurrent edits across multiple files (e.g., refactorings, API upgrades) under iterative refinement.
- Test overfitting defenses: Evaluate whether models exploit test-specific artifacts; add adversarial test variants and minimum adequate test sets to reduce overfitting risks.
- Distinctiveness criterion side-effects: Ensure that “fail previous code” does not unintentionally encourage breaking prior behavior; combine distinctiveness with regression-preservation checks.
Practical Applications
Immediate Applications
The following applications can be deployed now using the SR-Eval benchmark and its components. Each item notes relevant sectors, potential tools/workflows, and key assumptions or dependencies.
- Model selection and benchmarking for AI coding assistants (software)
- Use case: Evaluate and compare LLMs for IDE-integrated assistants (e.g., Copilot-like tools) under realistic multi-turn workflows to inform procurement and deployment.
- Tools/workflows: Internal evaluation harnesses using SR-Eval metrics (per-turn accuracy, completion rate, average token cost), dashboards, A/B testing across prompt strategies (Full History, Code Edit, Cumulative Instruction).
- Assumptions/dependencies: Current benchmark focuses on Python/Java; organizations may need domain adaptation and repository-context alignment; licensing for model APIs and dataset use.
- Prompting strategy optimization in production assistants (software)
- Use case: Choose cost/accuracy trade-offs among Full History, Code Edit, and Cumulative Instruction for specific teams or tasks; decide when to use “golden context” vs “basic context” to minimize compounding errors.
- Tools/workflows: Prompt orchestration layer, policy rules to prefer golden-context when feasible, telemetry on accuracy vs token cost.
- Assumptions/dependencies: Requires prompt router integration and developer buy-in; golden context assumes human-verified code between turns.
- CI/CD regression and feature-validation test generation (software; cross-domain IT)
- Use case: Apply SR-Eval’s distinctiveness validation to auto-generate tests that fail on the previous implementation and pass on the new one, improving regression safety when adding features or handling edge cases.
- Tools/workflows: A “test generation bot” leveraging
UnifiedCheckand the semantic-aware pipeline; repository snapshot/restore harness for in-repo execution; pre-merge checks. - Assumptions/dependencies: Stable execution environments; mapping natural-language requirement changes to concrete tests; managing test flakiness in CI.
- Training data augmentation for code LLMs (software; academia)
- Use case: Synthesize multi-turn, requirement-evolution datasets (Python/Java) for supervised fine-tuning, RLAIF/RLHF reward modeling using discriminative tests and pass/fail signals.
- Tools/workflows: Replicate SR-Eval’s multi-agent “Decomposer–Evaluator–Analyzer” pipeline and semantic-aware test generation; integrate reward signals from tests.
- Assumptions/dependencies: Human-in-the-loop review for ambiguous or misaligned instructions; compute and licensing; control of data contamination.
- Agile requirement engineering education and autograding (education; daily life for learners)
- Use case: Teach iterative development with progressively refined tasks; autograde student solutions per turn using discriminative tests aligned to evolving specs.
- Tools/workflows: Course assignments built from SR-Eval-style tasks; autograders with sandboxed execution; feedback using semantic alignment checks.
- Assumptions/dependencies: Course focus on Python/Java; moderate compute to run tests; test stability across student environments.
- Vendor evaluation and procurement policy for AI coding tools (policy; enterprise IT)
- Use case: Require vendors to report SR-Eval metrics (per-turn accuracy, completion rate, token cost) for transparent multi-turn performance during procurement.
- Tools/workflows: Policy checklists, acceptance criteria, contract SLAs referencing SR-Eval-like evaluation suites.
- Assumptions/dependencies: Benchmarks may need domain-specific extensions (frameworks, languages); governance alignment with risk and compliance teams.
- Repository-context iterative test harness (software)
- Use case: Productize SR-Eval’s snapshot/restore and test-injection mechanism to safely validate patches within real repositories during iterative development.
- Tools/workflows: IDE plugin or CI component that replaces target functions, injects turn-specific tests, and restores the repo state automatically.
- Assumptions/dependencies: Repository build reproducibility; accurate function localization; coverage of cross-file dependencies in larger codebases.
- Research benchmarking for multi-turn code generation (academia)
- Use case: Adopt SR-Eval as a standardized multi-turn benchmark to study LLM behavior under iterative requirements, prompting, and test-time scaling modes.
- Tools/workflows: Reproducible experiment pipelines; reporting per-turn metrics; controlled contamination checks.
- Assumptions/dependencies: Access to evaluated models/APIs; alignment with peer benchmarks; extension to more languages as needed.
- “Golden-context” workflow policies to mitigate error accumulation (software)
- Use case: Introduce rules where LLM outputs are reviewed/edited by humans between turns, then fed back as golden context to raise multi-turn success rates.
- Tools/workflows: Code-review gates; “apply and audit” workflow plugins; policy toggles per repository or feature criticality.
- Assumptions/dependencies: Developer bandwidth; cultural adoption; cost/latency trade-offs versus pure automation.
- Bug triage and iterative fix evaluation (software)
- Use case: Adapt SR-Eval’s turn-based structure to evaluate and guide multi-turn bug fixes, ensuring new tests differentiate fixes from pre-fix states and prevent regressions.
- Tools/workflows: Triage assistant using distinctiveness checks; fix-validation tests per iteration; turn-aware reporting in issue trackers.
- Assumptions/dependencies: Mapping defects to concrete test specifications; integration with issue-tracking (e.g., Jira, GitHub Issues).
Long-Term Applications
The following applications will benefit from further research, broader language and framework coverage, scaling, and/or regulatory development before widespread deployment.
- AI requirement engineer and scrum assistant (software)
- Use case: Multi-agent system decomposes epics into coherent DAGs of implementable stories, proposes acceptance tests per turn, and sequences work to avoid conflicts.
- Tools/workflows: “AI product manager” integrated with Jira/Azure DevOps; automated acceptance test generation with semantic alignment; turn-aware backlog management.
- Assumptions/dependencies: Rich domain knowledge, constraint handling, and human oversight; robust conflict resolution; explainability and auditability.
- Certification and compliance for safety-critical LLM-generated code (healthcare, automotive, finance, energy; policy)
- Use case: Standardize multi-turn evaluation suites to certify robustness under evolving requirements; enforce regression and edge-case coverage before deployment in regulated environments.
- Tools/workflows: SR-Eval-like conformance tests; audit trails; integration with formal methods; external certification bodies adopting multi-turn standards.
- Assumptions/dependencies: Broader language support (C/C++, Rust), integration with formal verification, and regulatory endorsement; rigorous test coverage guarantees.
- Automated refactoring and migration assistants with regression guards (software; enterprise IT)
- Use case: Guide codebase upgrades (e.g., library/API changes) through iterative requirement changes while generating discriminative tests to guard against regressions and performance loss.
- Tools/workflows: “Migration assistant” that maintains a requirement DAG, generates turn-specific tests, and runs repo-level checks; change impact analysis.
- Assumptions/dependencies: Handling large repos, cross-file and cross-service dependencies; accurate retrieval/context; performance and compatibility testing.
- Curriculum learning and reinforcement for multi-turn code reasoning (academia; industry)
- Use case: Train models explicitly on iterative requirement refinement with reward shaping from discriminative tests; optimize test-time scaling and “thinking mode” control.
- Tools/workflows: Multi-turn training datasets; RL loops using pass/fail and semantic alignment rewards; inference-time strategy controllers.
- Assumptions/dependencies: Significant compute budgets; stable rewards; avoidance of data leakage; careful evaluation of generalization beyond synthetic tasks.
- Cross-language and framework expansion (software; robotics; embedded systems)
- Use case: Extend SR-Eval to JavaScript/TypeScript, C#, Go, C/C++, Rust, and domain frameworks (robotics middleware, embedded RTOS, cloud microservices) with repository-scale tasks.
- Tools/workflows: New benchmarks and harnesses per ecosystem; hardware-in-the-loop simulation for robotics/embedded; domain-specific test generation.
- Assumptions/dependencies: Ecosystem-specific execution environments; reliable sandboxing/simulation; well-curated seed datasets.
- Turn-aware IDE copilots with requirement DAG memory (software; daily life for developers)
- Use case: Copilots track evolving requirements, attach tests per turn, warn when “distinctiveness” fails, and prevent accidental regressions as features are added.
- Tools/workflows: Memory layers storing DAGs of requirements and tests; interactive visualizations of turn histories; automatic test suite maintenance.
- Assumptions/dependencies: UI ergonomics, inference cost management, context window limits, privacy and repository access controls.
- Regression-aware DevOps and change-impact analytics (software; enterprise IT)
- Use case: Continuous monitoring and automated test generation for changes; map requirement dependencies to risk; prioritize reviews where distinctiveness gaps suggest fragile features.
- Tools/workflows: DevOps analytics dashboards; change-impact DAGs; automatic test suite evolution with semantic alignment checks.
- Assumptions/dependencies: Integration with CI/CD, code ownership models, consistent test flakiness mitigation, data governance.
- Domain-specific assistants for robotics, energy, and bioinformatics (robotics; energy; healthcare research)
- Use case: Build stepwise requirement pipelines for controllers, data pipelines, or analyses where specs evolve with experimental feedback; generate edge-case tests to verify safety and reliability.
- Tools/workflows: Domain templates for requirement decomposition; simulators/hardware-in-the-loop test generation; semantic alignment tuned to domain conventions.
- Assumptions/dependencies: Accurate domain models and simulators, access to specialized libraries/hardware, safety constraints and auditing.
- Governance and audit dashboards for multi-turn model performance (policy; enterprise risk)
- Use case: Track multi-turn metrics over time to detect drift, maintain audit trails for AI-generated code, and enforce policy gates before production merges.
- Tools/workflows: Governance dashboards anchored in SR-Eval-like metrics; policy engines requiring minimum multi-turn performance on representative tasks; periodic re-certification.
- Assumptions/dependencies: Continuous benchmarking infrastructure; standardized task suites representative of organizational code; alignment with legal/compliance requirements.
Glossary
- Agile development practices: Iterative software development methodology emphasizing incremental delivery and collaboration. "agile development practices~\citep{manifesto2001manifesto}"
- Average Accuracy: The mean accuracy across all turns in iterative evaluation. "Average Accuracy (Avg Acc): the mean of the per-turn accuracies across all turns."
- Average Token Cost (ATC): The average tokens (input and output) consumed per task across all turns. "Average Token Cost (): the mean total number of tokens (input and output) consumed per task across all turns."
- Basic Setting: Prompt context that includes model-generated code from previous turns. "Basic Setting: In each turn, the prompt includes the model-generated code from the previous rounds (as dictated by the chosen prompt strategy)."
- Code Edit: Prompting strategy where only the previous code and the new instruction are provided. "Code Edit: The prompt {solely contains} %consists solely of the code generated in the previous turn along with the new user instruction."
- Competitive programming problems: Algorithmic problems reflecting real-world logical reasoning and problem-solving demands. "incorporate competitive programming problems, better reflecting real-world requirements for logical reasoning and problem-solving."
- Complete Task Rate (CR): Proportion of tasks completed across all required turns. "Complete Task Rate (CR): the proportion of tasks where the model successfully completes all required turns."
- Cumulative Instruction: Prompting strategy that accumulates user instructions across turns without intermediate outputs. "Cumulative Instruction: This strategy accumulates all user instructions across turns but omits any intermediate model outputs."
- Data contamination: Training or evaluation leakage that inflates performance by prior exposure to data. "Crucially, both datasets mitigate data contamination."
- Directed acyclic graph (DAG): A directed graph with no cycles, used to represent dependencies. "constructing a directed acyclic graph (DAG) to represent dependency relationships"
- Distinctiveness: Requirement property ensuring each turn introduces a unique modification. "Distinctiveness: Each requirement should introduce a unique modification or extension, avoiding redundancy or overlap with other requirements in the sequence."
- Distinctiveness validation: Check that current tests fail against previous-turn implementations to ensure discriminative power. "Distinctiveness validation ensures that tests meaningfully differentiate successive implementations."
- Docstrings: In-code documentation strings describing functions and expected behavior. "function signatures and Docstrings as inputs."
- Execution-based metrics: Metrics determined by running generated code against tests. "We employ execution-based metrics to quantify the performance of LLMs in iterative code generation."
- Full History: Prompting strategy that includes all prior user instructions and model responses. "Full History: In this setting, all preceding user instructions and model responses are included in the prompt."
- Golden Setting: Prompt context constructed from ground-truth reference code from earlier rounds. "Golden Setting: In contrast, the prompt is constructed using the ground-truth reference code from earlier rounds."
- Greedy decoding: Deterministic generation method selecting the highest-probability token at each step. "we utilize a greedy decoding strategy during inference."
- Grounding context: Reference implementations and tests provided to prevent fabrication of non-existent APIs. "we provide the reference implementation and tests as grounding context."
- Intra-function dependencies: Dependencies confined within a single function, not requiring repository context. "we exclude samples with intra-function dependencies, which do not require repository-level context"
- Logical Coherence: Consistency and clarity of the multi-turn instruction trajectory. "Logical Coherence: The instructions should form a clear and logically consistent development trajectory."
- Message Inconsistency: Mismatch where tests assert natural language outputs not specified by requirements. "and Message Inconsistency, where the tests assert natural language outputs not required by the requirements."
- Multi-agent-based requirement generation: Process using specialized agents to decompose and refine evolving instructions. "we first leverage %applies a multi-agentâbased requirement generation process that simulates real-world iterative development"
- Pass@1: Metric indicating whether the generated code passes the test suite on the first attempt. "Our primary metric is pass@1"
- Per-turn Accuracy: Success rate of the model at each individual iteration/turn. "Per-turn Accuracy (): the success rate of the model at each individual turn."
- Reasoning level: Model mode controlling the extent of chain-of-thought reasoning during generation. "we regard reasoning level
medium'' as the thinking mode and reasoning levellow'' as the non-thinking mode." - Repository context: The broader codebase information required to implement functions correctly. "Since all 140 tasks inherently require repository context, any model-generated code that nevertheless passed the reference test cases was considered as a strong indicator of data leakage."
- Repository-level tasks: Programming tasks requiring understanding of multi-file project structures and inter-module dependencies. "SR-Eval spans both function-level and repository-level tasks in Python and Java"
- Sandbox: Isolated execution environment for running code and tests safely. "For function-level tasks, we execute both in an isolated sandbox and collect execution results."
- Scenario Authenticity: Realism of decomposed requirements relative to practical development. "Scenario Authenticity: The decomposed requirements should reflect realistic software development practices and align with scenarios commonly encountered in real-world projects."
- Semantic-aware discriminative test case generation: Method ensuring test cases are correct, distinctive, and aligned with evolving requirements. "semantic-aware discriminative test case generation component to ensure discriminative and consistent evaluation at each turn."
- Stepwise requirement refinement: Iterative evolution of requirements across turns during development. "Results show that iterative code generation under stepwise requirement refinement remains highly challenging"
- Test suite: Collection of tests used to validate correctness of generated code. "which measures whether the generated code passes the test suite on the first attempt."
- Test-time scaling (TTS): Techniques that enhance model capabilities at inference time via reasoning processes. "known as test-time scaling (TTS)"
- Topological sorting: Ordering of graph nodes respecting dependencies (no node appears before its prerequisites). "applies topological sorting to determine a conflict-free execution order."
- Unit tests: Fine-grained tests verifying specific, well-defined behaviors of code units. "allows verification through explicit unit tests"
- Waterfall-like development methodology: Sequential development model assuming complete and static requirements upfront. "waterfall-like development methodology~\citep{DBLP:conf/icse/Royce87}"
Collections
Sign up for free to add this paper to one or more collections.