Vibe Checker: Aligning Code Evaluation with Human Preference
Abstract: LLMs have catalyzed vibe coding, where users leverage LLMs to generate and iteratively refine code through natural language interactions until it passes their vibe check. Vibe check is tied to real-world human preference and goes beyond functionality: the solution should feel right, read cleanly, preserve intent, and remain correct. However, current code evaluation remains anchored to pass@k and captures only functional correctness, overlooking the non-functional instructions that users routinely apply. In this paper, we hypothesize that instruction following is the missing piece underlying vibe check that represents human preference in coding besides functional correctness. To quantify models' code instruction following capabilities with measurable signals, we present VeriCode, a taxonomy of 30 verifiable code instructions together with corresponding deterministic verifiers. We use the taxonomy to augment established evaluation suites, resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness. Upon evaluating 31 leading LLMs, we show that even the strongest models struggle to comply with multiple instructions and exhibit clear functional regression. Most importantly, a composite score of functional correctness and instruction following correlates the best with human preference, with the latter emerging as the primary differentiator on real-world programming tasks. Our work identifies core factors of the vibe check, providing a concrete path for benchmarking and developing models that better align with user preferences in coding.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
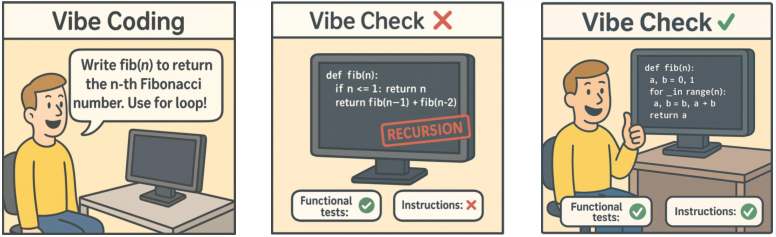
This paper looks at how we judge code written by AI. Today, most tests only check if the code “works” by passing tests. But real people also care about how the code feels: Is it clean? Easy to read? Does it follow the project’s rules? Does it keep the original idea? The authors call this overall judgment a “vibe check.” They build new tools to measure both: whether the code works and whether it follows the kinds of non-functional instructions humans actually care about.
What questions did the researchers ask?
They focus on a few simple questions:
- How can we measure whether AI code follows non-functional instructions (like style, structure, and documentation), not just whether it passes tests?
- Do these non-functional instructions affect whether the code still works?
- Are AI models better at following many instructions in one shot or step-by-step?
- Which matters more to people choosing code they like: pure correctness or also following instructions?
- Can a combined score (correctness + instruction-following) match human preferences better than either one alone?
How did they study it?
To answer these questions, the authors created two main things:
- VeriCode: a set of 30 common, real-world, checkable code instructions (for Python), plus automatic checkers for each one. Think of these like rules a teacher could grade quickly and fairly. Examples include:
- Keep lines under a certain length.
- Limit how many branches (ifs/elses) a function has.
- Use a specific docstring format (like Google or NumPy style).
- Handle errors using the right exceptions.
- Prefer certain libraries or APIs (e.g., use pathlib instead of os.path).
- Each rule has a “verifier” that gives a simple pass/fail, using linters and code analysis tools.
- Vibe Checker: a test setup that adds VeriCode instructions on top of popular coding benchmarks. It measures:
- Functionality: does the code pass the unit tests?
- Instruction Following (IF): does the code pass the rule verifiers?
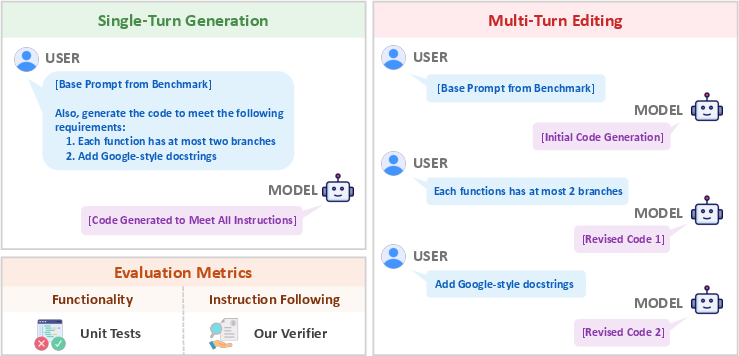
They tested models in two realistic ways:
- Single-turn generation: give the problem and all instructions at once; the model writes code in one go.
- Multi-turn editing: give the problem first, then add one instruction at a time, asking the model to revise its code each round.
They evaluated 31 strong AI models on two kinds of tasks (real-world programming and algorithmic/contest problems) and tracked both correctness and instruction-following.
What did they find?
Here are the main takeaways, explained simply:
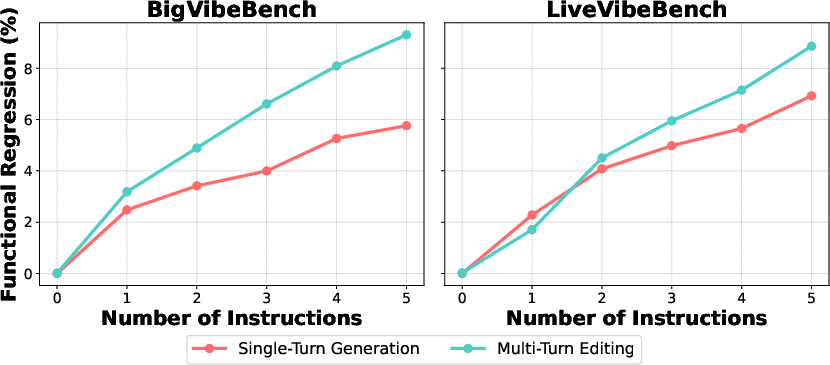
- Non-functional rules can break functionality a bit. Even though the extra instructions aren’t about correctness, adding them still made code pass fewer tests. On average, adding five rules caused noticeable drops (often around 5–10%) in how often solutions passed tests, especially on harder, algorithmic problems.
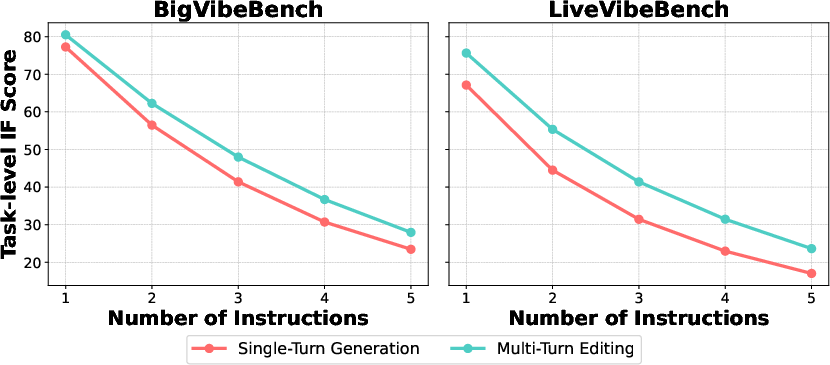
- Following many instructions at once is hard. Even top models often failed when asked to follow several rules together. With five instructions, success (meeting all rules at the same time) was often below 50%, and sometimes far lower on tough tasks. It’s like trying to juggle more balls—each extra rule makes it much easier to drop one.
- Single-turn vs. multi-turn behaves differently:
- Single-turn (all rules at once) tends to keep functionality better (code keeps passing tests more often).
- Multi-turn (rules added step-by-step) tends to follow instructions better but causes more functionality drop. Iterating helps the model focus on each rule, but it sometimes breaks what was working before.
- Models show a “position bias” for instructions. They tend to handle instructions at the beginning and the end better than ones in the middle.
- In single-turn, the first instruction gets the most attention.
- In multi-turn, the last (most recent) instruction gets the most attention.
- This is similar to how people often remember the first and last items in a list better than the middle ones.
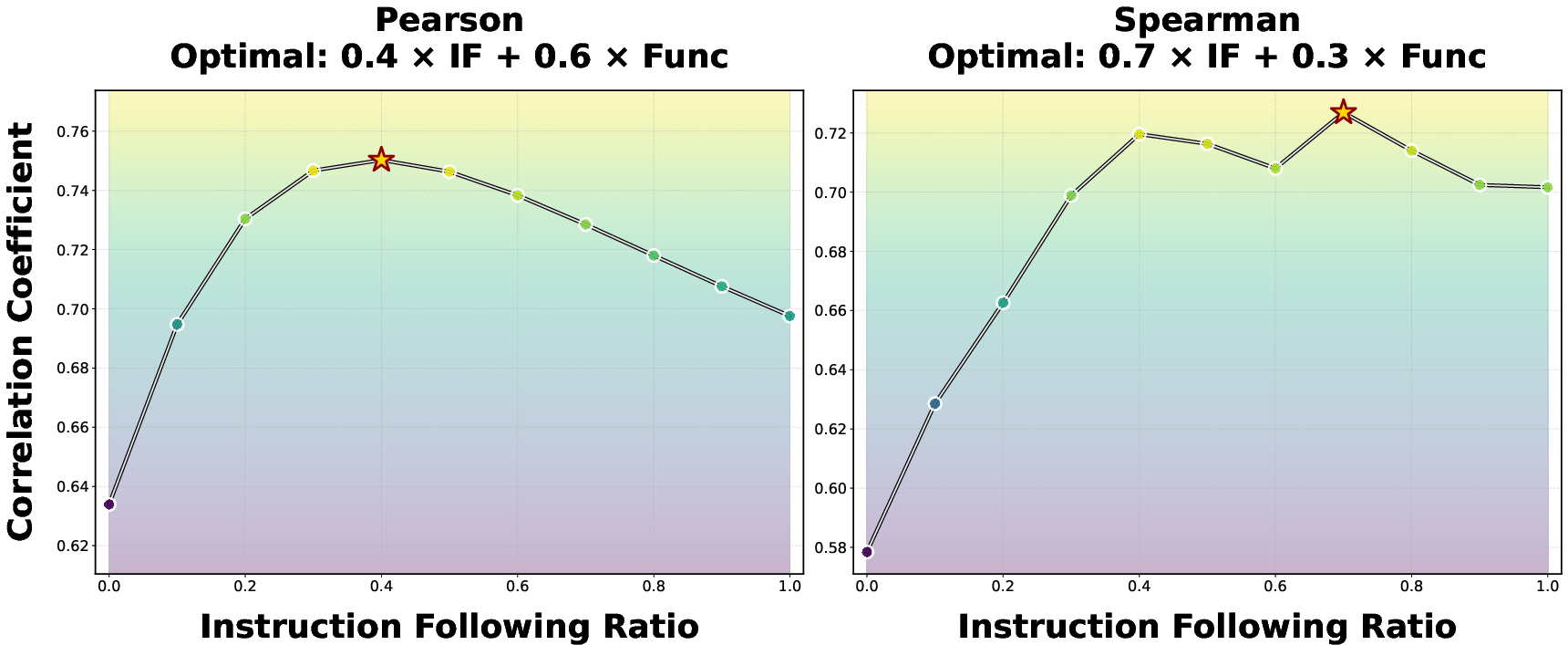
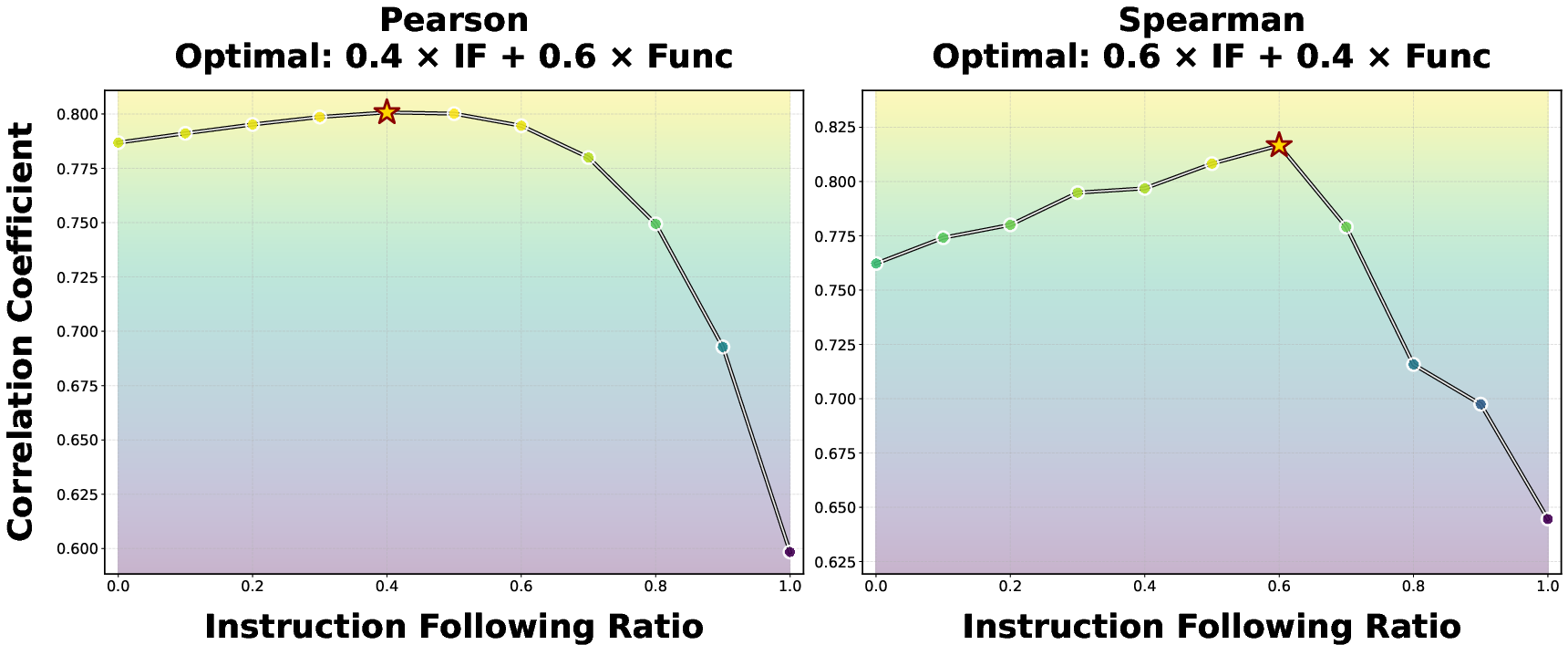
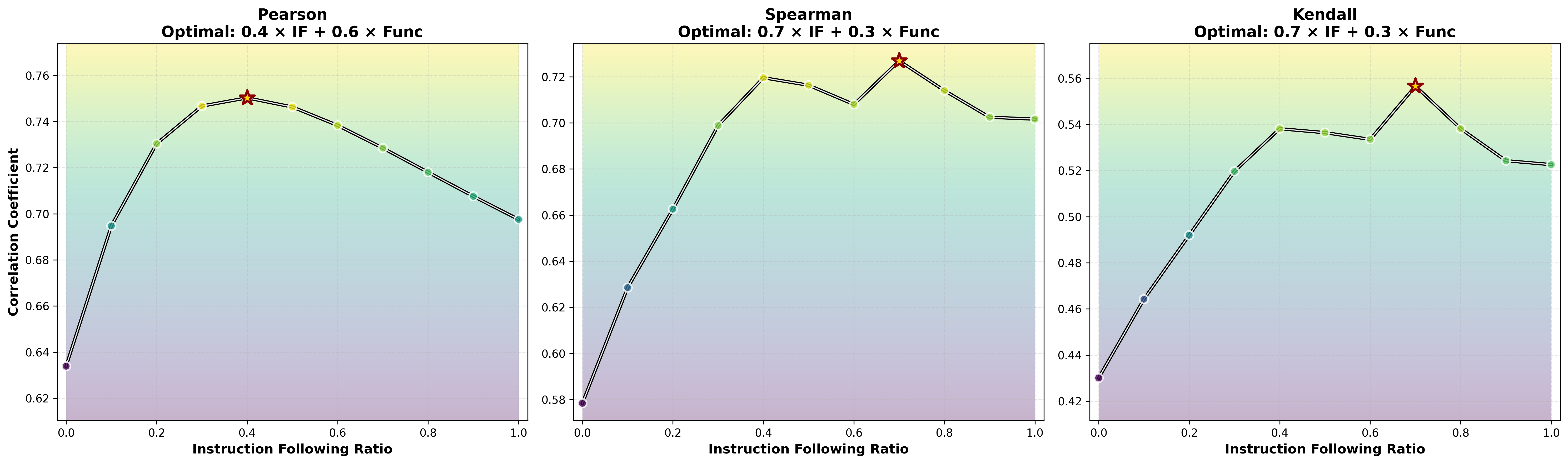
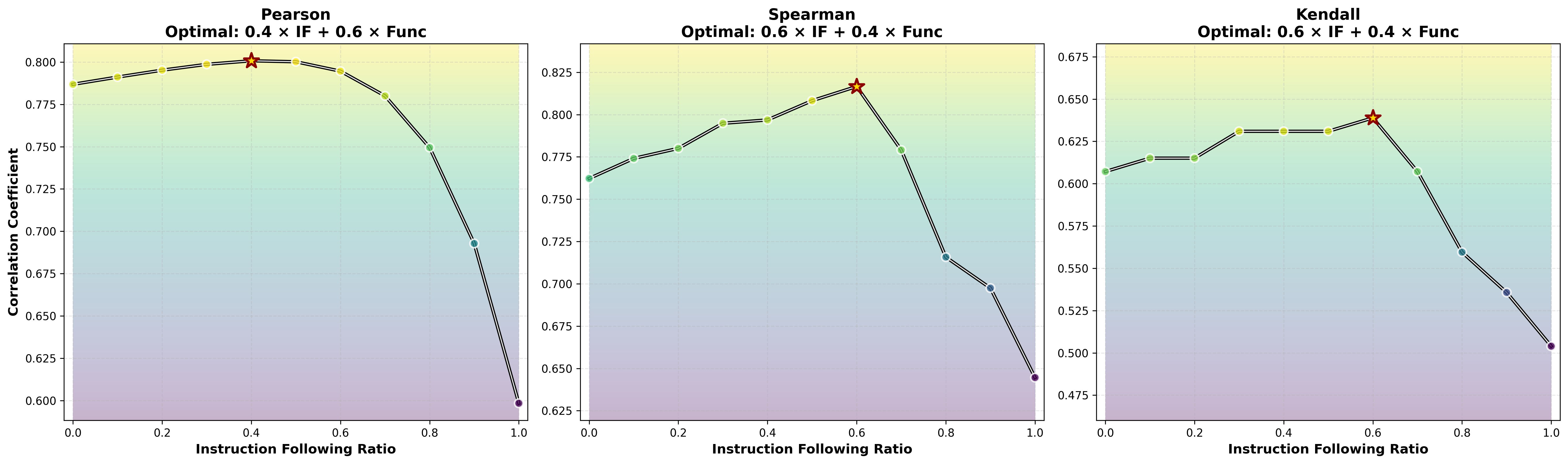
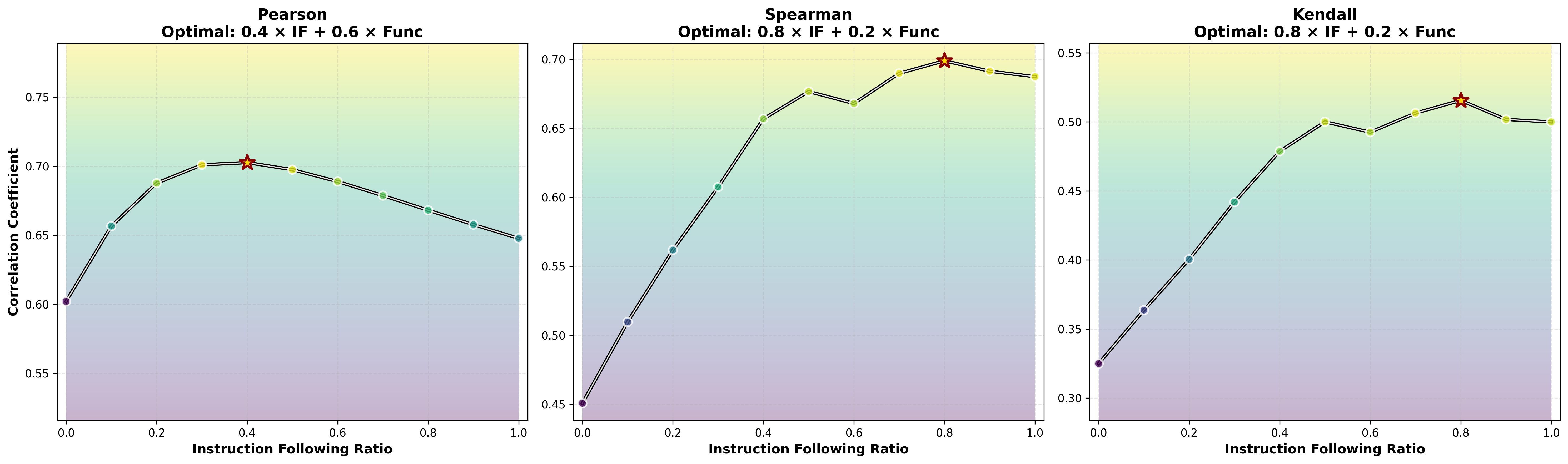
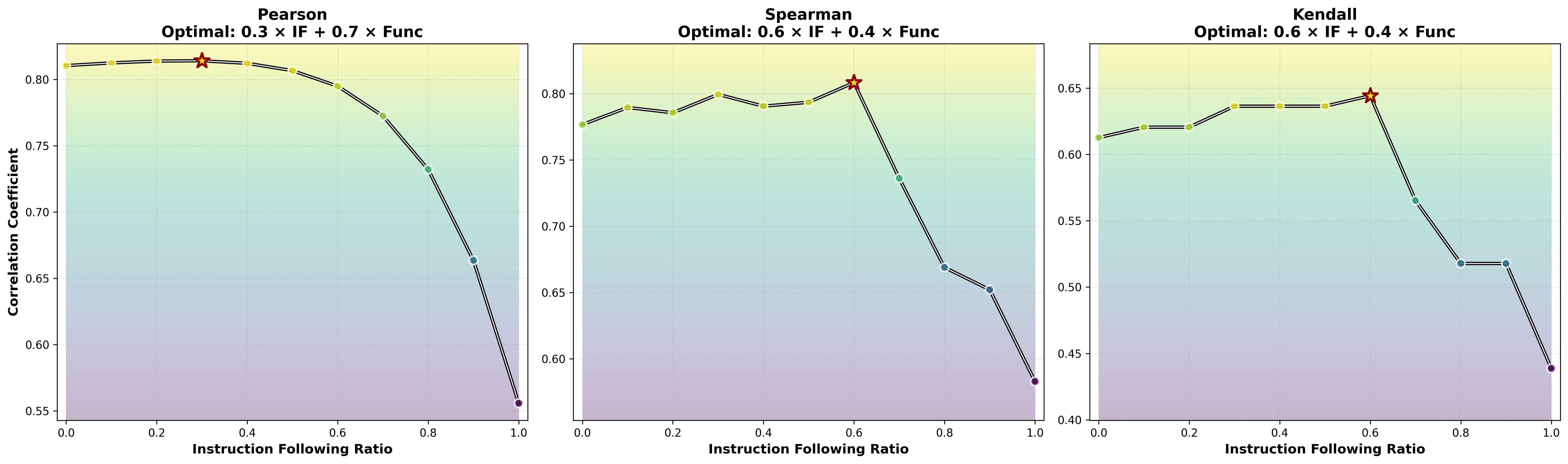
- What people prefer is a mix of “works” and “follows rules.” When the authors compared their scores with a huge set of human votes from a coding arena, the best match came from combining two things: functional correctness + instruction following. Neither one alone explained human choices as well as the mix. Also:
- For real-world coding tasks, instruction-following mattered a lot (style, clarity, staying on-spec).
- For contest-style problems, pure correctness mattered more.
Why does this matter?
- Better way to judge AI code: This work shows that only checking “does it pass tests?” misses a big part of what humans care about. Adding verifiable instruction-following gives a fair, scalable way to measure “vibe.”
- Training models that people like more: Because these instruction checks are automatic and reliable, they can be used not just for testing but also for training, nudging models to produce code that feels right to users.
- Practical guidance for tools: If you’re designing AI coding assistants, support multi-turn editing to follow instructions better, and add safeguards to avoid breaking functionality while revising. Also, be mindful of instruction order—important rules might need to come first or last to be followed reliably.
- A path toward human-aligned coding AI: The paper’s message is simple but powerful—great AI code isn’t only about being correct; it should also follow the user’s “vibe” rules. Measuring and optimizing both is the way to build coding models people actually prefer to use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Language coverage: VeriCode is instantiated only for Python. How well does the taxonomy and verifier design generalize to other languages (e.g., JavaScript/TypeScript via ESLint, Java via Checkstyle, C++ via clang-tidy)? Build and validate cross-language verifier suites and evaluate cross-language IF and functional regression.
- Verifier reliability: AST, linter, and regex-based checks may produce false positives/negatives, especially for documentation outside code blocks. Quantify per-instruction verifier precision/recall against human-labeled ground truth and report measurement error.
- Instruction selection validity: The LLM-based selector decides relevance and non-conflict, but its accuracy is not measured. Create a labeled set for “relevance” and “conflict” and benchmark selectors (LLM vs. rule-based baselines), including inter-annotator agreement.
- Parameterization effects: The taxonomy allows tunable parameters (e.g., line_length, max_branches), yet their impact on difficulty and regression is unstudied. Systematically vary parameters to produce difficulty curves and calibrate “easy/medium/hard” settings per instruction.
- Instruction count and composition: All instances are augmented with exactly five instructions. Explore variable k (including >5), category-specific mixes, and realistic bundles drawn from production style guides to assess scaling behavior and interaction effects.
- Category-level impact: Which categories (Style, Logic, Documentation, Error Handling, API) most drive functional regression or IF failures? Provide per-category and per-instruction breakdowns, plus interactions among categories.
- Conflicting and trade-off instructions: Real workflows include conflicting constraints (e.g., minimal edits vs. large refactors). Explicitly inject controlled conflicts to study model behaviors, resolution strategies, and evaluator policies.
- Intent preservation measurement: Functional regression is a coarse proxy for “preserving prior intent.” Develop edit-based metrics (diff size, edit locality, behavioral equivalence tests) that isolate intent preservation from pure functionality.
- Minimal-change constraints: Users value targeted edits. Add verifiable instructions such as “minimize diff size,” “do not rename existing identifiers,” or “do not reorder public API,” with diff-based verifiers.
- Prompt formatting and instruction salience: Position bias (“lost-in-the-middle”) is observed but unaddressed. Evaluate formatting interventions (numbered lists, headings, highlighting, instruction-to-checker mapping in prompt) and measure their effect on IF and regression.
- Pass@k vs. pass@1: Evaluation uses pass@1 only. Assess pass@k (sampling or beam search) to approximate real usage and measure whether IF and functionality trade-offs change with k.
- Training with verifiable rewards: VeriCode is proposed as a scalable reward source, but no training experiments (SFT/RLVR) are reported. Test whether IF-focused rewards improve human preference and functional robustness, with ablations on reward shaping and curriculum.
- Human preference validation beyond LMArena: The correlation study relies on LMArena. Validate the composite metric against other preference sources (e.g., Copilot Arena, IDE-in-situ user studies, PR acceptance/merge rates, code review outcomes).
- Repository-level tasks: Benchmarks are function/problem-level. Extend Vibe Checker to multi-file, repository-level scenarios (e.g., SWE-bench variants) with project-wide verifiers (naming conventions, module structure, dependency usage) and measure scalability.
- Runtime, memory, and security: Non-functional quality includes performance and safety, yet current instructions focus on style/logic/docs/errors/API. Add verifiable constraints for time/space bounds, I/O side-effects, taint flows, and common CWE patterns.
- Documentation quality: Current doc verifiers check format/conventions, not semantic correctness or helpfulness. Design verifiers (or human+LLM hybrid) for doc accuracy, parameter coverage, examples, and alignment with code behavior.
- Instruction dependency modeling: Task-level decay assumes near-independence. Quantify dependency structure (synergistic vs. antagonistic instruction pairs) and model joint satisfaction to better predict multi-instruction success.
- Explaining position bias: The U-shape appears on BigVibeBench but not LiveVibeBench. Analyze causes (context length, instruction type, prompt layout, code length, solution strategy) and generalize interventions.
- Selector prompting quality: Parameter invalid rates are reported but not reduced. Investigate prompt engineering, constrained decoding, and schema validation to minimize invalid parameters and irrelevant instructions.
- Generation setting confounds: Models were run with heterogeneous temperatures and “thinking modes” due to API constraints. Ablate temperature, chain-of-thought visibility, and context limits to isolate their effects on IF and functionality.
- Ambiguous/vague instructions: Real instructions can be underspecified. Introduce controlled ambiguity and measure the model’s propensity to ask clarifying questions, defer, or overcommit; evaluate resolution strategies.
- Tool feedback integration: Multi-turn editing did not include runtime feedback (failing tests, linter outputs). Study IF and functionality when models iteratively react to concrete tool feedback within the loop.
- Release and reproducibility: The taxonomy and verifiers are promised but not yet available. Provide full artifacts (code, prompts, selectors, seeds), dataset cards, licenses, and versioning to enable exact replication and extension.
- Verification cost and scalability: No analysis of compute/time cost per verifier or end-to-end evaluation. Profile and optimize the pipeline to support larger-scale training and live IDE integration.
- API replacement side-effects: Some API constraints (e.g., pathlib over os.path) can change behavior or environment requirements, confounding “non-functional” claims. Isolate pure style changes from behavior-altering constraints or adjust tests/environments accordingly.
- Difficulty normalization: Functional regression depends on base problem difficulty. Normalize regression and IF across problem difficulty strata to avoid confounding comparisons.
- Composite score design: The α-weighted mixture is heuristic. Learn weights (e.g., via regression against human preferences), test non-linear combinations, and evaluate generalization across task types and user segments.
- Per-model error analyses: Beyond aggregate curves, provide qualitative and quantitative error taxonomies per model (common IF failures, typical regression triggers) to guide targeted model improvements.
- Order scheduling strategies: Instruction order is random or sequential; study optimized scheduling (easy-to-hard, category grouping, prerequisite-first) to maximize IF while minimizing regression.
- Multi-language taxonomy blueprint: Provide a concrete methodology for porting VeriCode to new languages (mapping linters, verifier construction, parameter schema, selection policies) and a cross-language evaluation plan.
- Environment/version constraints: Some instructions require specific language or library versions. Track and control environment metadata, and study portability and reproducibility across versions.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage the paper’s findings, methods, and innovations. Each item names the sector(s), the potential tool/product/workflow, and key assumptions or dependencies.
- Instruction-aware CI/CD “vibe gates” alongside unit tests (software, finance, healthcare)
- What: Add VeriCode’s deterministic verifiers to CI to enforce non-functional constraints (style, logic limits, docstrings, error handling, API usage) before merging.
- Tools/Workflows: GitHub Actions/Bitbucket Pipelines/CI plugins; pre-commit hooks; repo-level config of VeriCode parameters; “Vibe Compliance” badge in PRs.
- Assumptions/Dependencies: Strongest support today in Python; availability of taxonomy + verifier releases; tuning thresholds to minimize false positives; existing unit tests.
- IDE assistant prompt-wrapping for instruction following (software, education)
- What: Extend Copilot/Cursor/VS Code assistants with a lightweight wrapper that selects relevant VeriCode instructions per task and verifies outputs locally.
- Tools/Workflows: VS Code extension; LLM-based selector from the paper; single-turn and multi-turn workflows that surface constraints to the model; post-generation verifier feedback loop.
- Assumptions/Dependencies: Low-latency verifier invocation; clear mapping from repo policies to VeriCode parameters; users accept occasional functional trade-offs.
- Procurement and vendor evaluation using a composite “vibe score” (industry, IT governance)
- What: Use the paper’s composite metric (functionality + instruction following) to compare LLMs for enterprise coding assistants.
- Tools/Workflows: Internal bake-offs on BigVibeBench/LiveVibeBench; scorecards for model selection; weighted IF/Func tuning per org priorities.
- Assumptions/Dependencies: Access to the testbed; agreement on weighting; tasks representative of org codebase.
- Education autograding that rewards style and maintainability, not only correctness (education)
- What: Grade student code with functional tests and VeriCode IF checks (e.g., docstring conventions, branch limits, line length).
- Tools/Workflows: LMS integrations (Gradescope, nbgrader); rubric with parameterized instructions; instant feedback explaining failed verifiers.
- Assumptions/Dependencies: Python-centric courses; maintainable parameter sets per assignment; students informed of expected conventions.
- Targeted refactoring and modernization tasks with deterministic verification (software, data engineering)
- What: Use LLMs to perform safe, verifiable refactors (e.g., replace os.path/open/glob with pathlib; unify OSError aliases), validated by VeriCode verifiers and unit tests.
- Tools/Workflows: CLI “vibe-refactor” tool; batch migration scripts; AST diffs limited to targeted edits; rollback if functional regression detected.
- Assumptions/Dependencies: Adequate test coverage; scope-limited refactors; careful parameterization to match project conventions.
- Compliance-oriented quality gates for regulated software (finance, healthcare, public sector)
- What: Enforce error handling and documentation requirements via verifiers, produce audit-ready reports combining IF and functional results.
- Tools/Workflows: CI compliance dashboards; periodic “vibe audits”; repo policies mapped to VeriCode instructions (e.g., docstring convention, max complexity).
- Assumptions/Dependencies: Alignment between regulatory guidance and selected instructions; acceptance of linter-backed checks as evidence.
- Research training pipelines with verifiable reward signals (academia, AI labs)
- What: Replace pass@k-only RL rewards with joint rewards (unit tests + VeriCode IF signals) to better align model optimization with human preferences.
- Tools/Workflows: RLVR/SFT datasets augmented with instruction constraints; reward shaping based on binary verifiers; ablation studies on single-turn vs. multi-turn.
- Assumptions/Dependencies: Access to training compute; robust verifier coverage for targeted languages; clear metrics tracking functional regression.
- Bug-fix and code-review bots that enforce “minimal, targeted edits” (software, open source)
- What: Multi-turn agents propose diffs that satisfy explicit non-functional constraints (e.g., limited branches, docstrings) and verify the patch deterministically.
- Tools/Workflows: GitHub PR bots; AST-based diff limits; post-patch unit test + verifier run; auto-comment with concrete failures.
- Assumptions/Dependencies: Sufficient granularity in verifiers to detect over-edits; stable CI environment.
- Open-source maintainers’ policy enforcement (open source)
- What: Repository-level VeriCode parameter files articulate accepted conventions; PRs must pass the verifiers and unit tests to merge.
- Tools/Workflows: Policy files (e.g., .vericode.yml); contributor docs linking to the taxonomy; automated checks on PRs.
- Assumptions/Dependencies: Community buy-in; reasonable default parameters to welcome new contributors.
- Notebook and low-code “vibe presets” for non-experts (daily life, education)
- What: Enable presets like “readable + documented + safe” that invoke verifiers in notebooks and low-code tools, guiding novices to clean solutions.
- Tools/Workflows: Jupyter extensions; Colab/VS Code notebooks; stepwise multi-turn guidance; immediate feedback on violations.
- Assumptions/Dependencies: Python-first users; willingness to trade speed for clarity; clear error messages.
Long-Term Applications
These applications require further research, scaling, taxonomy expansion, or ecosystem development before widespread deployment.
- Cross-language VeriCode suites and standardized instruction packs (software, robotics, embedded)
- What: Extend the taxonomy and verifiers to Java, C/C++, JavaScript/TypeScript, Rust, Go; build language-specific packs aligned with industry linters and static analyzers.
- Tools/Workflows: Community-maintained instruction registries; standard interfaces for verifiers; cross-language CI plugins.
- Assumptions/Dependencies: Availability of deterministic, high-quality linters/AST tooling; harmonization across languages.
- Autonomous code agents trained on composite rewards (software, DevOps)
- What: Train agents to optimize for both correctness and IF, reducing real-world “vibe failures” in complex tasks (SWE-bench-style repositories, multi-modal contexts).
- Tools/Workflows: Multi-objective RL; curriculum that increases instruction load; position-aware instruction scheduling to mitigate “lost-in-the-middle.”
- Assumptions/Dependencies: Robust long-context handling; scalable reward computation; benchmark realism.
- “Vibe Quality” certifications and procurement standards (policy, industry consortia)
- What: Establish certs and RFP guidelines that require evidence of instruction following alongside functionality for AI coding tools used in critical systems.
- Tools/Workflows: Third-party audits with Vibe Checker-like suites; published threshold scores; continuous monitoring.
- Assumptions/Dependencies: Consensus among standards bodies; reproducible public benchmarks; governance around test updates.
- Personalized “vibe profiles” and org-level preference learning (software, enterprise IT)
- What: Learn per-user and per-team preferences (e.g., style, complexity, error handling) and fine-tune assistants to adhere to them across projects.
- Tools/Workflows: Preference capture UIs; secure storage of policies; adaptive model routing or fine-tuning; telemetry with opt-in privacy.
- Assumptions/Dependencies: Privacy-preserving data collection; stability of preferences; safe on-device/in-tenant adaptation.
- Security- and safety-informed IF (security, safety-critical systems)
- What: Enrich instructions with secure coding rules (e.g., input validation, safe APIs) and static analysis signals to produce “secure-by-vibe” outputs.
- Tools/Workflows: Integration with security linters (Semgrep, CodeQL); composite risk scores; CI gating for critical paths.
- Assumptions/Dependencies: High-precision security verifiers; minimizing false positives that impede velocity.
- DevOps analytics for IF vs. functionality trade-offs (software operations)
- What: Dashboards tracking functional regression and IF adherence over time; detect regressions when new policies or tools roll out.
- Tools/Workflows: Observability pipelines; cohort analysis across repos/teams; automated recommendations (e.g., switch to multi-turn for instruction-heavy tasks).
- Assumptions/Dependencies: Data instrumentation; agreed KPIs; change-management processes.
- Position-bias-aware interaction orchestration (agent frameworks, IDEs)
- What: Use the paper’s U-shaped position effect to order constraints strategically (primacy for single-turn, recency for multi-turn) and schedule edits to maximize IF while minimizing functional regression.
- Tools/Workflows: Instruction schedulers; IDE UX to stage constraints; agent planners that chunk instructions across turns.
- Assumptions/Dependencies: Generalization of position effects across tasks and languages; user acceptance of staged workflows.
- Large-scale education assessments across languages and modalities (education, MOOCs)
- What: Multi-language IF + functionality grading for millions of learners; badges/certificates reflecting maintainability and readability, not just correctness.
- Tools/Workflows: MOOC-scale graders; dynamic rubrics by course level; cross-language verifier libraries.
- Assumptions/Dependencies: Broad taxonomy coverage; fair scoring across diverse learner populations.
- Robotics and embedded software generation with safety-constrained IF (robotics, automotive, aerospace)
- What: Encode verifiable safety patterns (finite-state logic limits, error recovery policies) into instruction packs; enforce via static analysis and simulation.
- Tools/Workflows: Domain-specific verifiers; hardware-in-the-loop tests; composite reward training tailored to safety regimes.
- Assumptions/Dependencies: Industry-grade analyzers; domain expertise for instruction design; strict validation pipelines.
- Ecosystem marketplaces for instruction packs and verifier plugins (software tooling)
- What: Curated, shareable sets of instructions (framework- or org-specific) and verifier plugins that teams can adopt off the shelf.
- Tools/Workflows: Registry, versioning, provenance; compatibility layers across CI/IDEs; community ratings.
- Assumptions/Dependencies: Sustainable governance; trust in third-party packs; compatibility with diverse toolchains.
Notes on Global Assumptions and Dependencies
- Current taxonomy is Python-first; cross-language expansion is needed for broad industry impact.
- Deterministic verifiers depend on mature linters/AST tooling; gaps will require custom analysis.
- Multi-turn editing improves IF but can increase functional regression; workflows must balance both (possibly with staged verification).
- Composite scoring reflects human preference better than functionality alone, but optimal IF/Func weights vary by scenario (e.g., real-world vs. competitive programming).
- Low-latency verification and clear failure feedback are critical for developer adoption.
- Organizational acceptance (policy, compliance, education) hinges on transparent, explainable checks and manageable false-positive rates.
Glossary
- Abstract Syntax Tree (AST): A tree-structured representation of source code used for static analysis and program transformation. "Abstract Syntax Tree (AST) analysis"
- BigCodeBench: A large-scale benchmark of real-world coding tasks used to evaluate code generation models. "BigCodeBench (1,140 instances)"
- BigVibeBench: An augmented version of BigCodeBench that adds verifiable non-functional instructions to assess instruction following. "BigVibeBench, adapted from BigCodeBench to cover real-world programming tasks."
- Copilot Arena: A platform where human programmers compare and choose preferred code snippets, capturing real-world preference signals. "platforms such as Copilot Arena~\citep{copilot_arena}, a large-scale vibe-checking scenario"
- deterministic verifier: An automated checker that returns a consistent binary pass/fail outcome for a specific instruction. "together with corresponding deterministic verifiers."
- DiffBLEU: A metric that measures similarity of code edits to a reference by applying BLEU to diffs rather than raw text. "They typically compare to ground truth with DiffBLEU~\citep{nofuneval}"
- E501 Rule: A Ruff linter rule enforcing maximum line length in Python code for readability. "E501 Rule"
- Elo rating: A pairwise comparison-based scoring system that aggregates human votes into skill rankings for models. "aggregated into Elo ratings for each model"
- functional correctness: Whether generated code behaves as intended, typically judged by passing unit tests. "functional correctness"
- functional regression (FR_k): The relative decrease in functional score after adding k instructions. "functional regression "
- Instruction Following (IF): The extent to which a model complies with explicit non-functional constraints, measured by verifiable checks. "Instruction Following: We report IF"
- LLM-as-a-judge: An evaluation setup where an LLM grades outputs instead of deterministic tests or human annotators. "LLM-as-a-judge~\citep{followbench, infobench}"
- LiveCodeBench: A benchmark of algorithmic and competitive programming problems for evaluating code generation. "LiveCodeBench v1–v6 (1,055 problems, May 2023 to May 2025)"
- LiveVibeBench: An augmented version of LiveCodeBench that adds verifiable instructions to simulate real interactions. "LiveVibeBench, adapted from LiveCodeBench to cover algorithmic/contest problems."
- linter: A static analysis tool that flags style issues, code smells, and other violations based on rules. "an industry-standard Python linter"
- LMArena: A large-scale leaderboard aggregating human preference votes across tasks, including coding, to rank LLMs. "On the coding subset of LMArena~\citep{lmarena},"
- lost-in-the-middle: A context effect where models under-attend to information appearing mid-sequence compared to the beginning or end. "the classic ``lost-in-the-middle'' pattern"
- multi-turn editing: An interaction protocol where constraints are introduced stepwise and the model iteratively revises code. "Multi-Turn Editing"
- pass@1: The probability that a single generated solution passes all tests for a task. "pass@1 decreases across all models."
- pass@k: The probability that at least one of k generated solutions passes tests for a task. "anchored to pass@k"
- Pearson correlation: A linear correlation coefficient quantifying the strength of association between two continuous variables. "the optimum for Pearson correlation places a 40\% weight on IF"
- PEP 257: The Python Enhancement Proposal specifying conventions for docstrings. "PEP 257"
- PLR0912 Rule: A Ruff rule that flags functions with too many branches, encouraging simpler control flow. "PLR0912 Rule"
- primacy bias: A tendency to favor earlier items in a sequence, leading to better adherence to first-listed instructions. "single-turn generation shows a primacy bias"
- PTH Rule: A Ruff rule family that encourages using pathlib instead of os, os.path, glob, and open. "PTH Rule"
- recency bias: A tendency to favor the most recent items, leading to better adherence to last-introduced instructions. "multi-turn editing displays a clear recency bias"
- RLVR (Reinforcement Learning from Verifiable Rewards): A training paradigm that optimizes models using deterministic signals like test passes. "RLVR training"
- Ruff: A fast, consolidated Python linter that aggregates rules from multiple tools. "We source our initial candidate pool from Ruff"
- single-turn generation: An interaction protocol where all constraints are given in one prompt and the model returns a single solution. "Single-Turn Generation"
- Spearman correlation: A rank-based correlation coefficient assessing monotonic relationships without assuming linearity. "for Spearman correlation, the weight on IF rises to 70\%"
- thinking mode: A model inference setting that enables extended reasoning traces or internal deliberation during generation. "We enable thinking mode on all models that support it."
- UP024 Rule: A Ruff rule standardizing exception usage by replacing aliases with the canonical OSError. "UP024 Rule"
- VeriCode: A curated taxonomy of 30 verifiable non-functional code instructions, each with a deterministic checker. "We first introduce VeriCode, a taxonomy of verifiable code instructions"
- verifiable reward signal: An objective, automatically computed training signal (e.g., test pass) used to guide optimization. "verifiable reward signal in RLVR training"
- Vibe Checker: A unified testbed combining unit tests and instruction verifiers to evaluate both functionality and IF. "resulting in Vibe Checker, a testbed to assess both code instruction following and functional correctness."
- vibe check: A human preference-based acceptance criterion that goes beyond functionality to how code feels and reads. "what we call the ``vibe check,''"
- vibe coding: A workflow where users iteratively co-create and refine code with LLMs via natural language until it meets preferences. "have catalyzed vibe coding"
Collections
Sign up for free to add this paper to one or more collections.

