LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Abstract: LLMs applied to code-related applications have emerged as a prominent field, attracting significant interest from both academia and industry. However, as new and improved LLMs are developed, existing evaluation benchmarks (e.g., HumanEval, MBPP) are no longer sufficient for assessing their capabilities. In this work, we propose LiveCodeBench, a comprehensive and contamination-free evaluation of LLMs for code, which continuously collects new problems over time from contests across three competition platforms, namely LeetCode, AtCoder, and CodeForces. Notably, our benchmark also focuses on a broader range of code related capabilities, such as self-repair, code execution, and test output prediction, beyond just code generation. Currently, LiveCodeBench hosts four hundred high-quality coding problems that were published between May 2023 and May 2024. We have evaluated 18 base LLMs and 34 instruction-tuned LLMs on LiveCodeBench. We present empirical findings on contamination, holistic performance comparisons, potential overfitting in existing benchmarks as well as individual model comparisons. We will release all prompts and model completions for further community analysis, along with a general toolkit for adding new scenarios and model
- Juice: A large scale distantly supervised dataset for open domain context-based code generation. arXiv preprint arXiv:1910.02216.
- Santacoder: don’t reach for the stars! arXiv preprint arXiv:2301.03988.
- code2seq: Generating sequences from structured representations of code. arXiv preprint arXiv:1808.01400.
- Multi-lingual evaluation of code generation models. arXiv preprint arXiv:2210.14868.
- Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Antonio Valerio Miceli Barone and Rico Sennrich. 2017. A parallel corpus of python functions and documentation strings for automated code documentation and code generation. arXiv preprint arXiv:1707.02275.
- Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954.
- Barry Boehm. 2006. A view of 20th and 21st century software engineering. In Proceedings of the 28th International Conference on Software Engineering, ICSE ’06, page 12–29, New York, NY, USA. Association for Computing Machinery.
- Multipl-e: A scalable and extensible approach to benchmarking neural code generation. arXiv preprint arXiv:2208.08227.
- Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397.
- Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128.
- Cocomic: Code completion by jointly modeling in-file and cross-file context. arXiv preprint arXiv:2212.10007.
- Incoder: A generative model for code infilling and synthesis. preprint arXiv:2204.05999.
- Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805.
- Shahriar Golchin and Mihai Surdeanu. 2023. Time travel in llms: Tracing data contamination in large language models. arXiv preprint arXiv:2308.08493.
- Cruxeval: A benchmark for code reasoning, understanding and execution. arXiv preprint arXiv:2401.03065.
- Deepseek-coder: When the large language model meets programming–the rise of code intelligence. arXiv preprint arXiv:2401.14196.
- Codesc: A large code-description parallel dataset. arXiv preprint arXiv:2105.14220.
- Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874.
- Competition-level problems are effective llm evaluators. arXiv preprint arXiv:2312.02143.
- Summarizing source code using a neural attention model. In 54th Annual Meeting of the Association for Computational Linguistics 2016, pages 2073–2083. Association for Computational Linguistics.
- Jigsaw: Large language models meet program synthesis. In Proceedings of the 44th International Conference on Software Engineering, pages 1219–1231.
- Llm-assisted code cleaning for training accurate code generators. arXiv preprint arXiv:2311.14904.
- Swe-bench: Can language models resolve real-world github issues? arXiv preprint arXiv:2310.06770.
- xcodeeval: A large scale multilingual multitask benchmark for code understanding, generation, translation and retrieval. arXiv preprint arXiv:2303.03004.
- Spoc: Search-based pseudocode to code. Advances in Neural Information Processing Systems, 32.
- Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles.
- Ds-1000: A natural and reliable benchmark for data science code generation. In International Conference on Machine Learning, pages 18319–18345. PMLR.
- A neural model for generating natural language summaries of program subroutines. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 795–806. IEEE.
- Explaining competitive-level programming solutions using llms. arXiv preprint arXiv:2307.05337.
- Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Taco: Topics in algorithmic code generation dataset. arXiv preprint arXiv:2312.14852.
- Textbooks are all you need ii: phi-1.5 technical report. arXiv preprint arXiv:2309.05463.
- Competition-level code generation with alphacode. Science, 378(6624):1092–1097.
- Can we generate shellcodes via natural language? an empirical study. Automated Software Engineering, 29(1):30.
- Codemind: A framework to challenge large language models for code reasoning. arXiv preprint arXiv:2402.09664.
- Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv preprint arXiv:2304.03439.
- Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. arXiv preprint arXiv:2305.01210.
- Repobench: Benchmarking repository-level code auto-completion systems. arXiv preprint arXiv:2306.03091.
- Starcoder 2 and the stack v2: The next generation.
- Repoagent: An llm-powered open-source framework for repository-level code documentation generation. arXiv preprint arXiv:2402.16667.
- Wizardcoder: Empowering code large language models with evol-instruct. arXiv preprint arXiv:2306.08568.
- Learning performance-improving code edits. arXiv preprint arXiv:2302.07867.
- Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Nl2type: inferring javascript function types from natural language information. In 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), pages 304–315. IEEE.
- Type4py: Practical deep similarity learning-based type inference for python. In Proceedings of the 44th International Conference on Software Engineering, pages 2241–2252.
- L2ceval: Evaluating language-to-code generation capabilities of large language models. arXiv preprint arXiv:2309.17446.
- Codegen: An open large language model for code with multi-turn program synthesis. In The Eleventh International Conference on Learning Representations.
- Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114.
- Demystifying gpt self-repair for code generation. arXiv preprint arXiv:2306.09896.
- R OpenAI. 2023. Gpt-4 technical report. arxiv 2303.08774. View in Article.
- Proving test set contamination for black-box language models. In The Twelfth International Conference on Learning Representations.
- Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334.
- Asleep at the keyboard? assessing the security of github copilot’s code contributions. In 2022 IEEE Symposium on Security and Privacy (SP), pages 754–768. IEEE.
- Check your facts and try again: Improving large language models with external knowledge and automated feedback. arXiv preprint arXiv:2302.12813.
- ToolLLM: Facilitating large language models to master 16000+ real-world APIs. In The Twelfth International Conference on Learning Representations.
- Quantifying contamination in evaluating code generation capabilities of language models.
- Code generation with alphacodium: From prompt engineering to flow engineering. arXiv preprint arXiv:2401.08500.
- To the cutoff… and beyond? a longitudinal perspective on LLM data contamination. In The Twelfth International Conference on Learning Representations.
- Phind.
- Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950.
- Did chatgpt cheat on your test?
- An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering, 50(1):85–105.
- Detecting pretraining data from large language models. arXiv preprint arXiv:2310.16789.
- Reflexion: Language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems.
- Repository-level prompt generation for large language models of code. In International Conference on Machine Learning, pages 31693–31715. PMLR.
- Nofuneval: Funny how code lms falter on requirements beyond functional correctness. arXiv preprint arXiv:2401.15963.
- Reinforcement learning from automatic feedback for high-quality unit test generation. arXiv preprint arXiv:2310.02368.
- Sql-palm: Improved large language modeladaptation for text-to-sql. arXiv preprint arXiv:2306.00739.
- Gemini Team. 2024. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.
- Llmseceval: A dataset of natural language prompts for security evaluations. arXiv preprint arXiv:2303.09384.
- Methods2test: A dataset of focal methods mapped to test cases. In Proceedings of the 19th International Conference on Mining Software Repositories, pages 299–303.
- Recode: Robustness evaluation of code generation models. arXiv preprint arXiv:2212.10264.
- Codet5+: Open code large language models for code understanding and generation. arXiv preprint arXiv:2305.07922.
- Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 8696–8708.
- Execution-based evaluation for open-domain code generation. arXiv preprint arXiv:2212.10481.
- On learning meaningful assert statements for unit test cases. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering, pages 1398–1409.
- Typet5: Seq2seq type inference using static analysis. arXiv preprint arXiv:2303.09564.
- Magicoder: Source code is all you need. arXiv preprint arXiv:2312.02120.
- ” according to…” prompting language models improves quoting from pre-training data. arXiv preprint arXiv:2305.13252.
- Rethinking benchmark and contamination for language models with rephrased samples.
- Large language models as analogical reasoners. arXiv preprint arXiv:2310.01714.
- Natural language to code generation in interactive data science notebooks. arXiv preprint arXiv:2212.09248.
- No more manual tests? evaluating and improving chatgpt for unit test generation. arXiv preprint arXiv:2305.04207.
- Parsel: A unified natural language framework for algorithmic reasoning. arXiv preprint arXiv:2212.10561.
- Repocoder: Repository-level code completion through iterative retrieval and generation. arXiv preprint arXiv:2303.12570.
- Toolcoder: Teach code generation models to use apis with search tools. arXiv preprint arXiv:2305.04032.
- Self-edit: Fault-aware code editor for code generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 769–787, Toronto, Canada. Association for Computational Linguistics.
- Algo: Synthesizing algorithmic programs with generated oracle verifiers. arXiv preprint arXiv:2305.14591.
- Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x. arXiv preprint arXiv:2303.17568.
- Opencodeinterpreter: Integrating code generation with execution and refinement. https://arxiv.org/abs/2402.14658.
- Codegen-test: An automatic code generation model integrating program test information. arXiv preprint arXiv:2202.07612.
- Don’t make your llm an evaluation benchmark cheater. arXiv preprint arXiv:2311.01964.
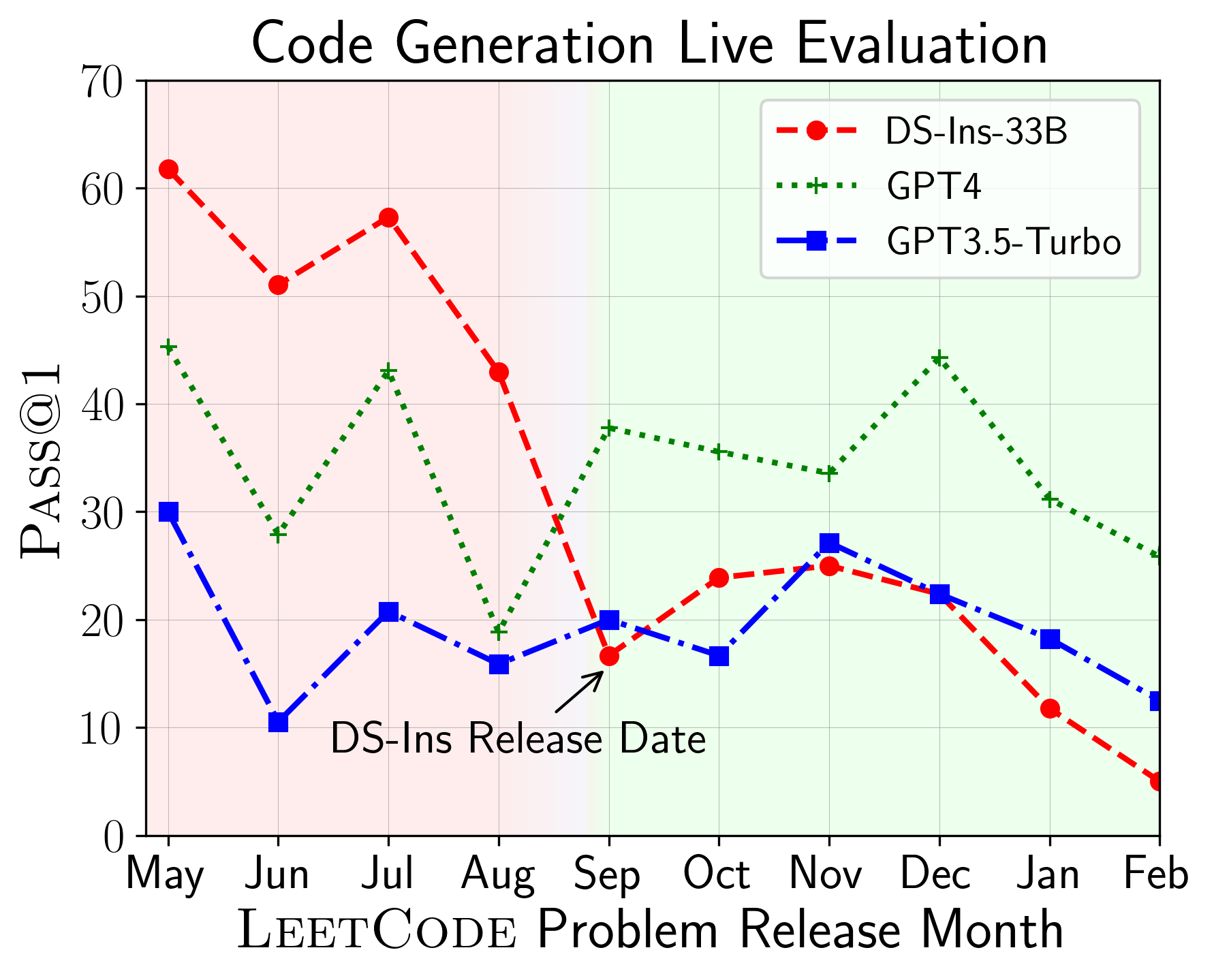
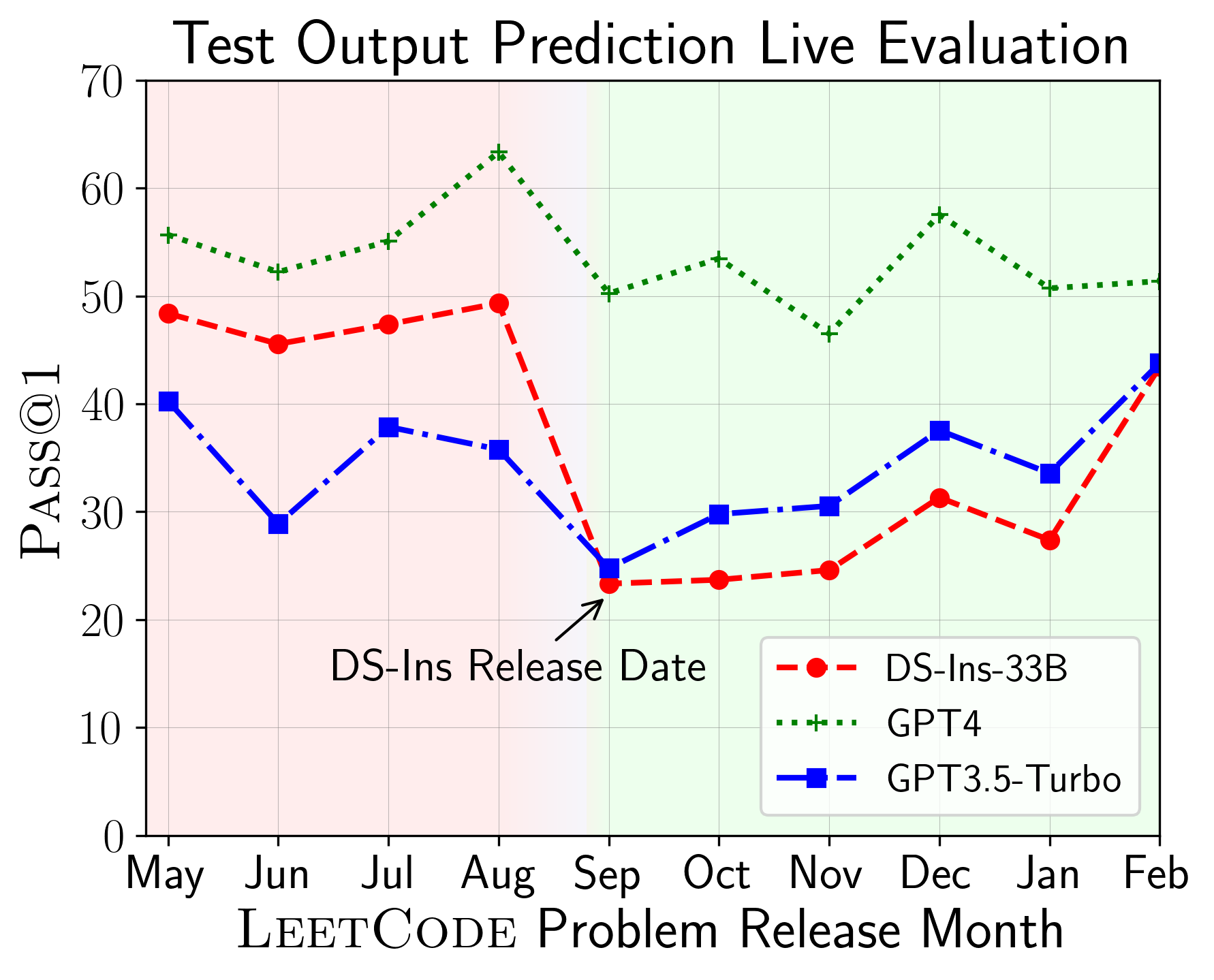
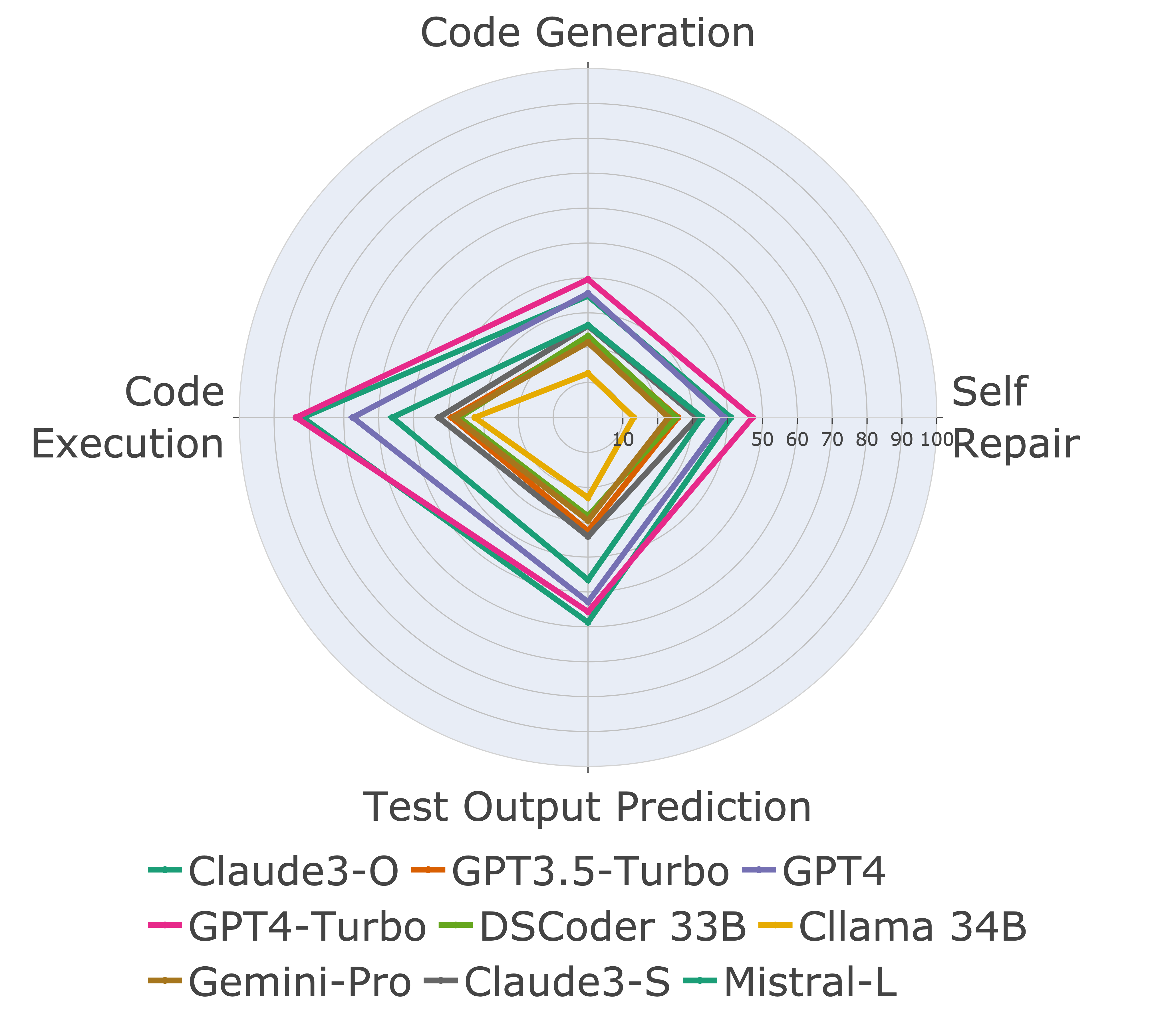
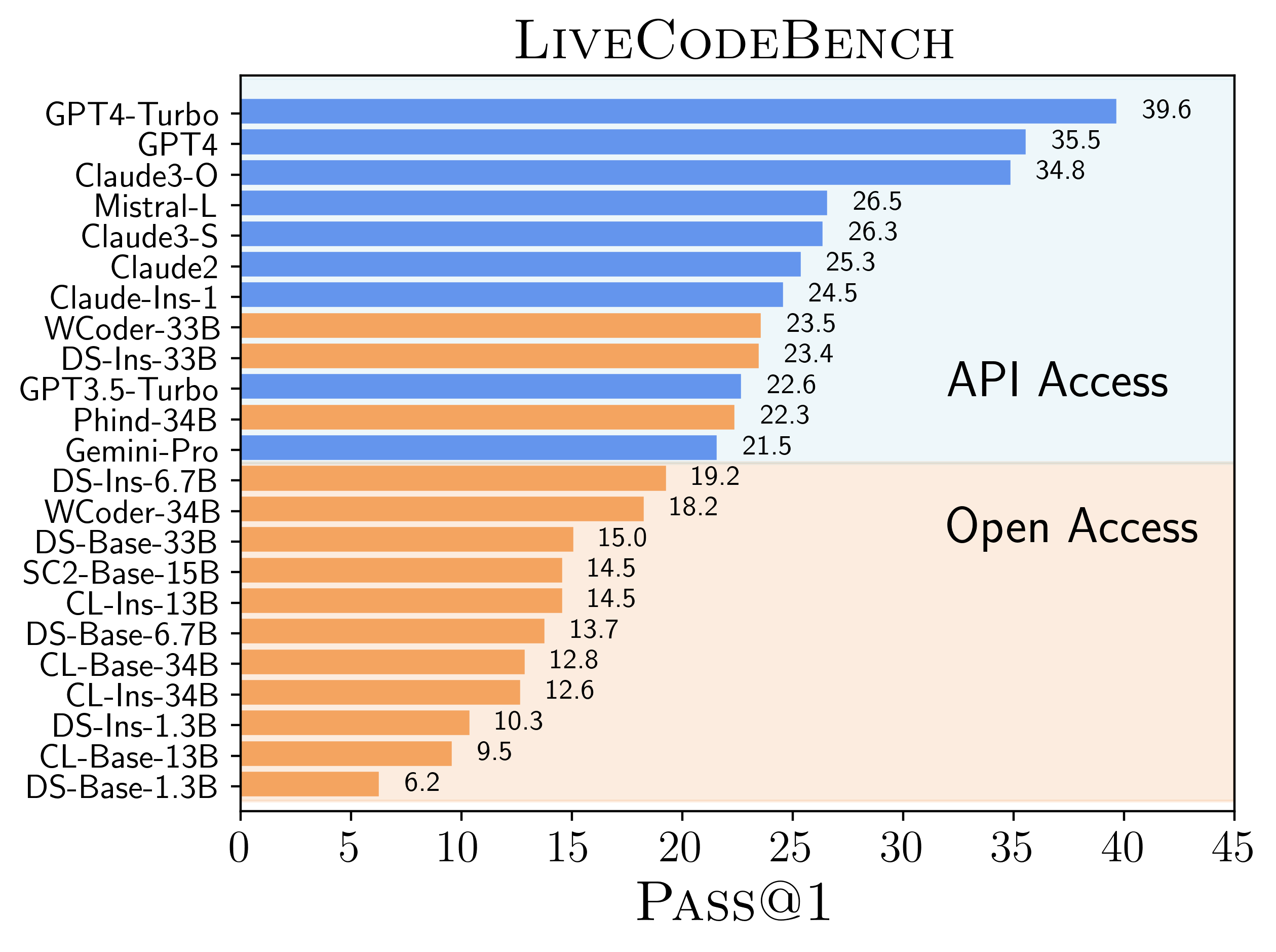
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.