ResearchCodeBench: Benchmarking LLMs on Implementing Novel Machine Learning Research Code (2506.02314v1)
Abstract: LLMs have shown promise in transforming machine learning research, yet their capability to faithfully implement novel ideas from recent research papers-ideas unseen during pretraining-remains unclear. We introduce ResearchCodeBench, a benchmark of 212 coding challenges that evaluates LLMs' ability to translate cutting-edge ML contributions from top 2024-2025 research papers into executable code. We assessed 30+ proprietary and open-source LLMs, finding that even the best models correctly implement less than 40% of the code. We find Gemini-2.5-Pro-Preview to perform best at 37.3% success rate, with O3 (High) and O4-mini (High) following behind at 32.3% and 30.8% respectively. We present empirical findings on performance comparison, contamination, and error patterns. By providing a rigorous and community-driven evaluation platform, ResearchCodeBench enables continuous understanding and advancement of LLM-driven innovation in research code generation.
Summary
- The paper introduces ResearchCodeBench, a benchmark evaluating LLMs on converting novel ML research into executable code with a best success rate below 40%.
- It employs a rigorous evaluation methodology combining fill-in-the-blank code tasks, contextual code analysis, and hybrid equivalence-unit tests with a scaled pass metric.
- The analysis highlights significant challenges in semantic alignment and functional code synthesis, underscoring gaps in current LLM capabilities for scientific research.
ResearchCodeBench: Evaluating LLMs on Research Code Implementation
The paper "ResearchCodeBench: Benchmarking LLMs on Implementing Novel Machine Learning Research Code" (2506.02314) introduces ResearchCodeBench, a benchmark designed to evaluate the ability of LLMs to translate novel ideas from recent ML research papers into executable code. This benchmark addresses the challenges of evaluating AI in scientific research, particularly in implementing novel ideas that may be outside the models' pretraining data. The paper assesses over 30 proprietary and open-source LLMs on 212 coding challenges derived from 20 top-tier research papers. The key finding is that even the best models achieve a success rate of less than 40%, highlighting the gaps in scientific reading and research code synthesis capabilities of current LLMs.
Benchmark Construction and Evaluation Methodology
The construction of ResearchCodeBench involves a rigorous process to ensure the benchmark is representative, rigorous, and grounded in real research implementations. The process includes paper selection, identification of core contributions, contextualizing dependencies, snippet annotation, and task construction (Figure 1).

Figure 1: Overview of the ResearchCodeBench task setup. An LLM is given access to a research paper, a target code snippet containing a TODO marker, and surrounding context code from the same project. The model is prompted to fill in the missing code based on the paper’s content and the available implementation context.
The paper selection process focuses on recent ML papers from top-tier conferences and arXiv, covering diverse topics. The core innovative contribution of each paper is identified by examining the paper’s contribution list, focusing on the most implementation-relevant aspects. Contextual code, which is additional code required for the implementation of core contributions, is identified by analyzing import statements. The benchmark employs a fill-in-the-blank style code completion task, where LLMs are tasked with generating missing code based on the paper and relevant contextual files. To verify the correctness of the generated code, the code is inserted back into the original file and evaluated using correctness tests provided by the original paper authors or domain experts. A hybrid evaluation strategy is adopted, using equivalence tests as the default check and unit tests as a complementary high-precision signal. The primary evaluation metric is the scaled pass rate, which weights each code snippet by its number of executable lines of code.
Experimental Results and Analysis
The paper presents a comprehensive evaluation of 32 popular commercial and open-source models. The models were evaluated using greedy decoding, and performance was measured using the Scaled Pass@1 score. The results indicate that the latest Gemini models achieve the highest scores, followed by OpenAI’s frontier models and Claude (Figure 2).
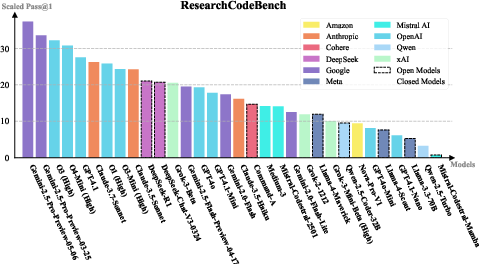
Figure 2: Scaled Pass@1 results of 32 LLMs on ResearchCodeBench with greedy decoding. Models from different companies are noted with different shades. Open models are wrapped with dotted lines.
A contamination analysis was conducted by comparing each model’s knowledge cutoff date with the timeline of codebase availability for each paper (Figure 3). The results suggest that most benchmark tasks were not accessible to the evaluated LLMs during pretraining, confirming minimal contamination risk.
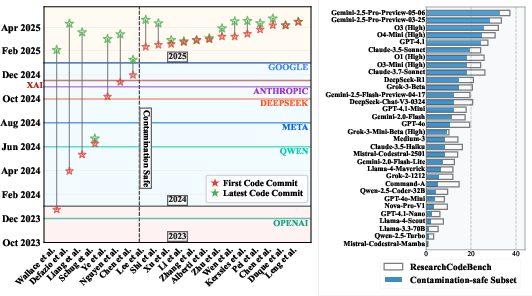
Figure 3: Left: Most recent model knowledge cutoff dates by company (horizontal colored lines) compared to repository commit dates (first code commit = red star, most recent code commit = green star). Right: Success rates on the full 20-paper benchmark vs. a contamination-safe 13-paper subset, where all repositories postdate the latest model cutoffs.
The impact of access to the research paper on model performance was also evaluated (Figure 4). Higher-performing models benefit substantially from having access to the paper, while smaller models show little to no improvement. Interestingly, LLaMA-based models perform worse when given the paper, suggesting potential context dilution or confusion.
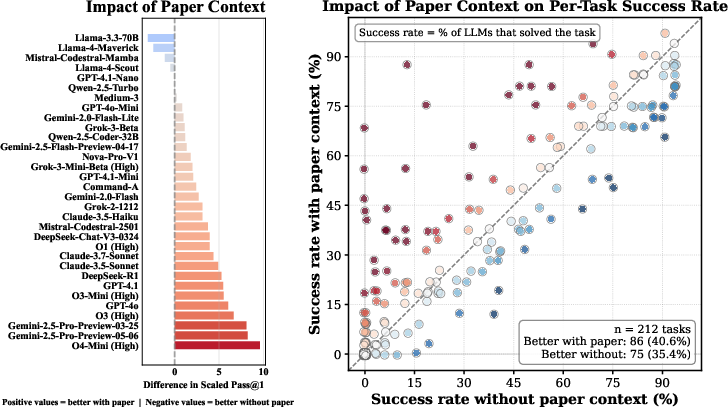
Figure 4: Left: Difference in LLM performance with vs. without access to the paper. Higher-performing models benefit significantly from paper context. Right: Per-task success rate across models. Each dot represents a task; the success rate is the percentage of LLMs that solve it. Tasks above the diagonal benefit uniquely from having the paper.
Error Analysis and Community-Driven Expansion
Error analysis reveals that functional errors dominate, accounting for 58.6% of all failures (Figure 5). This highlights that the primary challenge for LLMs is semantic alignment with the intended algorithmic contributions described in the paper, rather than low-level syntax.
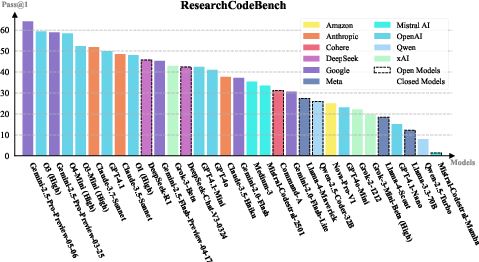
Figure 6: Pass@1 results of 32 LLMs on ResearchCodeBench with greedy decoding. Models from different companies are noted with different shades. Open models are wrapped with dotted lines.
The benchmark is designed to be community-driven, with a web-based submission pipeline for researchers to propose new papers and repositories. This ensures that ResearchCodeBench continually reflects the latest ML code.
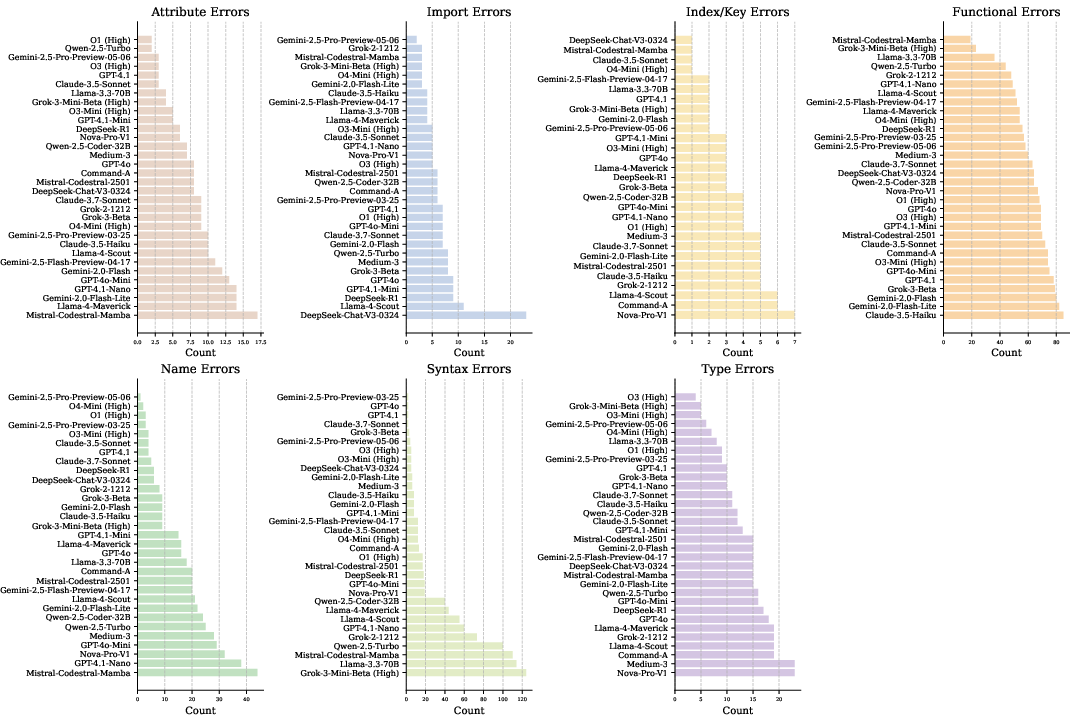
Figure 5: Breakdown of error types across LLMs. The figure shows the distribution of seven different error categories encountered during benchmark evaluation. Each subplot represents a specific error type (Attribute Errors, Import Errors, Index/Key Errors, Functional Errors, Name Errors, Syntax Errors, and Type Errors), with horizontal bars indicating the frequency of occurrence for each model. Models are sorted by error count within each category, revealing which LLMs are more prone to specific types of errors.
Implications and Future Directions
The ResearchCodeBench benchmark provides a rigorous and objective evaluation of LLMs' ability to implement novel research ideas. The results indicate that current LLMs still have significant limitations in this area, particularly in semantic understanding and functional code generation. The benchmark facilitates continuous understanding and advancement of LLM-driven innovation in research code generation by providing a challenging and community-driven evaluation platform. Future work includes expanding the benchmark with more papers and tasks, automating test case generation, and including human baselines for performance comparison.
Conclusion
The ResearchCodeBench benchmark offers a valuable tool for evaluating and advancing the capabilities of LLMs in scientific research. By focusing on the implementation of novel ideas from research papers, the benchmark highlights the challenges and opportunities in using AI to assist researchers with executing novel ideas through programming. The community-driven nature of the benchmark ensures its relevance and adaptability to the evolving landscape of machine learning research.
Follow-up Questions
- How does ResearchCodeBench differ from traditional code synthesis benchmarks in evaluating LLM performance?
- What specific evaluation metrics were used to quantify LLM success in implementing novel research code?
- In what ways does the benchmark mitigate contamination risks from pretraining data?
- How can the findings from ResearchCodeBench inform future improvements in LLM architectures for research applications?
- Find recent papers about LLM code generation challenges.
Related Papers
- ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code (2023)
- InfiBench: Evaluating the Question-Answering Capabilities of Code Large Language Models (2024)
- Long Code Arena: a Set of Benchmarks for Long-Context Code Models (2024)
- BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions (2024)
- Top General Performance = Top Domain Performance? DomainCodeBench: A Multi-domain Code Generation Benchmark (2024)
- CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings (2025)
- MLGym: A New Framework and Benchmark for Advancing AI Research Agents (2025)
- MLR-Bench: Evaluating AI Agents on Open-Ended Machine Learning Research (2025)
- LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming? (2025)
- The Automated LLM Speedrunning Benchmark: Reproducing NanoGPT Improvements (2025)