Concerto: Joint 2D-3D Self-Supervised Learning Emerges Spatial Representations
Abstract: Humans learn abstract concepts through multisensory synergy, and once formed, such representations can often be recalled from a single modality. Inspired by this principle, we introduce Concerto, a minimalist simulation of human concept learning for spatial cognition, combining 3D intra-modal self-distillation with 2D-3D cross-modal joint embedding. Despite its simplicity, Concerto learns more coherent and informative spatial features, as demonstrated by zero-shot visualizations. It outperforms both standalone SOTA 2D and 3D self-supervised models by 14.2% and 4.8%, respectively, as well as their feature concatenation, in linear probing for 3D scene perception. With full fine-tuning, Concerto sets new SOTA results across multiple scene understanding benchmarks (e.g., 80.7% mIoU on ScanNet). We further present a variant of Concerto tailored for video-lifted point cloud spatial understanding, and a translator that linearly projects Concerto representations into CLIP's language space, enabling open-world perception. These results highlight that Concerto emerges spatial representations with superior fine-grained geometric and semantic consistency.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Concerto: What this paper is about
This paper is about teaching computers to understand space (like rooms, streets, and objects) better by learning from both pictures (2D images) and 3D point clouds at the same time, without using human-written labels. The authors call their method “Concerto” because it combines two “instruments” (2D and 3D data) so they work together in harmony.
What questions the paper tries to answer
The paper focuses on two simple, big questions:
- Can a computer learn a stronger, more useful understanding of the world if it studies 2D images and 3D point clouds together, instead of separately?
- If the computer learns a good combined “concept” of objects (like an apple) from vision alone, can that concept be connected to language later so it understands words about those objects?
How the researchers approached the problem
Think of how you learn what an apple is: you see it (2D), hold it (3D shape), and taste it. All these senses together help build a single idea of “apple.” Concerto imitates that idea using two learning steps that happen at the same time:
1) Learning from 3D alone (intra-modal self-distillation)
- The model looks at 3D point clouds (a point cloud is like a set of dots in space that outline objects and rooms).
- It uses a “teacher–student” setup: the student model tries to match the teacher’s output. The teacher is just a slowly updated copy of the student.
- This process is called “self-distillation.” No labels are needed; the student learns to produce stable, meaningful features for points in 3D.
- The backbone (main engine) is a Point Transformer V3 (PTv3), which is good at handling point clouds.
Everyday analogy: The student practices drawing the same scene from slightly different viewpoints until their drawings match the teacher’s style. Over time, the student learns what shapes and structures matter.
2) Connecting 2D and 3D (cross-modal joint embedding prediction)
- The model also learns to line up 3D points with 2D image patches from photos of the same scene.
- Using camera information (like where the camera was and how it was angled), the model figures out which 3D points appear in which parts of the image.
- It tries to predict image features from 3D features using a simple similarity rule (cosine similarity), so the two “sides” agree.
- This encourages the 3D model to pick up texture and fine details that images are good at, while keeping solid geometry understanding from 3D.
Everyday analogy: Imagine matching spots on a room’s 3D map to squares in a photograph of the room. If the 3D and 2D versions agree, the computer gets a clearer, richer picture of what’s really there.
Extra pieces
- The model is trained on lots of raw 3D point clouds and images from several scene datasets.
- A variant lifts 3D point clouds from videos using a reconstruction method, so the model can learn from moving scenes too.
- A simple “translator” projects Concerto’s learned features into a language space (like CLIP’s) so the model can recognize objects by text names even without labeled training—this is called open-world or zero-shot recognition.
What do “linear probing” and “segmentation” mean?
- Linear probing: Freeze the main model and train a tiny “quiz layer” on top to see how good the learned features already are. If performance is high with this simple layer, the features are strong and general.
- Semantic segmentation: Color each point (or pixel) with a class label (like “chair,” “wall,” “table”).
- Instance segmentation: Group points into separate object instances (not just “chair,” but “chair #1,” “chair #2,” etc.).
- mIoU (mean Intersection-over-Union): A score that measures how well the predicted “colored areas” match the true areas. Higher means better.
What the researchers found and why it matters
The authors tested Concerto against leading 2D-only and 3D-only self-supervised models and against simply gluing their features together. Concerto did best overall.
Here are the key takeaways:
- Better than 2D-only and 3D-only: On a common 3D benchmark (ScanNet), Concerto’s frozen features with just a linear layer scored about 77.3% mIoU, beating a top 2D model (DINOv2 ~63.1%) and a top 3D model (Sonata ~72.5%).
- Better than just concatenating features: Concerto beat the performance of simply combining 2D and 3D features (which was ~75.9%).
- New state of the art with full training: When fully fine-tuned, Concerto reached 80.7% mIoU on ScanNet and also led on other datasets with many classes (like ScanNet200), showing strong geometry and fine-texture understanding.
- Works well with limited data: Even when training on fewer scenes or fewer labeled points, Concerto stays strong. Sometimes the simple linear probe even outperforms deeper tuning when data is scarce, meaning the learned features are very general and robust.
- Handles instances and videos: Concerto also improved instance segmentation (finding separate objects), and its video-based variant learned well from reconstructed 3D scenes from videos.
- Speaks some “language”: By linearly projecting features into CLIP’s text space, Concerto did zero-shot segmentation (labeling without seeing any labeled examples) at about 44.6% mIoU—promising progress toward linking vision and language.
Why it matters: 2D images are great at texture and appearance; 3D point clouds are great at shape and structure. Concerto learns a single feature space that blends both strengths. This helps machines better understand complex scenes for tasks like robots navigating rooms, AR headsets recognizing furniture, or self-driving cars spotting objects accurately.
What this research could lead to
Concerto suggests a few important directions:
- Stronger, more general scene understanding: By training 2D and 3D together, models can “think” about space more like humans do—recalling shape when seeing a picture and recalling appearance when seeing geometry.
- Better performance with fewer labels: Strong self-supervised features make it easier and cheaper to build high-performing systems with less human annotation.
- Scaling and real-time use: The video-lifted variant shows promise for learning from moving scenes and scaling to bigger models and datasets.
- Bridging to language: Even a simple linear translator toward language embeddings enables open-world recognition (naming things the model hasn’t been explicitly trained to label). Future work could tighten this link so models can follow text instructions in 3D scenes more reliably.
In short, Concerto shows that teaching computers using both 2D and 3D—like learning by seeing and touching—creates a richer understanding of the world. That understanding helps across many tasks and brings us closer to machines that can learn and reason about space more naturally.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address.
- Jointly training the 2D encoder: Concerto keeps the 2D image encoder fixed (DINOv2). Does co-training or partial fine-tuning of the 2D encoder alongside the 3D encoder improve synergy or introduce instability? Compare fixed vs. jointly updated vs. adapter-based 2D branches.
- Directionality and symmetry of cross-modal objectives: The method predicts 2D patch embeddings from 3D points (one-way). Would bidirectional prediction (2D→3D and 3D→2D), cycle-consistency, or shared latent spaces yield stronger or more robust representations?
- Correspondence fidelity between pixels and points: Current aggregation averages point features within image patches using camera parameters. How do occlusion handling, visibility tests, ray-casting, per-point depth ordering, or attention-weighted pooling affect alignment and performance?
- Robustness to camera/depth errors: Evaluate sensitivity to noisy or missing intrinsics/extrinsics, monocular depth estimates, rolling shutter distortions, fish-eye lenses, and multi-camera setups. How does performance degrade under realistic calibration noise?
- Dataset diversity and domain generalization: Pretraining and evaluation are heavily indoor-centric (ScanNet, S3DIS, HM3D, Structured3D, etc.). Test on outdoor LiDAR datasets (e.g., SemanticKITTI, nuScenes), CAD/synthetic scenes, and varied sensors to assess generalization under different geometry, density, and noise regimes.
- Dynamic scenes and temporal modeling: The video-lifted variant reconstructs static point clouds with VGGT but does not model temporal dynamics. How does joint 2D–3D SSL behave on dynamic scenes, moving objects, and long-range temporal consistency? Explore explicit spatiotemporal objectives.
- Predictor design and objective choice: The JEPA-like predictor uses cosine similarity. Systematically compare predictor architectures (MLP vs. transformer vs. permutation-equivariant models) and losses (contrastive InfoNCE, cross-entropy clustering, MSE with whitening, probabilistic matching) for stability and downstream gains.
- Quantifying the source of improvements: Disentangle gains due to multi-modal synergy from gains due to additional data/compute. Control experiments with matched data volume, matched augmentation, and matched training budget across single- and multi-modal baselines.
- Statistical reliability: Report variance across seeds, confidence intervals, and per-class breakdowns to establish statistical significance and pinpoint where synergy helps or hurts, especially on fine-grained categories.
- Compute and memory cost: Provide training time, GPU hours, peak memory, and throughput for Concerto vs. Sonata/DINOv2 and feature concatenation. Assess the cost–performance trade-offs and scalability limits.
- Inference-time modality independence: The paper claims representations can be recalled from a single modality; quantify this by measuring how well 2D-only or 3D-only inference recovers the “joint” semantics across tasks, and whether performance degrades in the absence of the other modality at test time.
- Open-vocabulary and language alignment: The CLIP-space translator is linear and evaluated only on ScanNet zero-shot segmentation via LSeg alignment. Evaluate on more datasets (ScanNet200, S3DIS, outdoor benchmarks), different prompt sets, non-English text, and per-class performance. Investigate non-linear translators and joint language–vision–3D training.
- Bias, fairness, and safety: Assess whether CLIP and image encoders’ known biases propagate into 3D representations. Test demographic, cultural, and domain biases; propose mitigation strategies (e.g., debiasing losses, balanced datasets).
- Handling negative transfer: Identify conditions where 2D signals harm 3D learning (e.g., severe domain mismatch between images and point clouds). Develop diagnostics and curricula/adaptive weighting to avoid negative transfer.
- Loss-weight scheduling: Ablations show sensitivity to cross-modal vs. intra-modal loss weights (e.g., 2:2 best for linear probing). Explore adaptive schedules, task-specific weighting, or meta-learning to select weights across tasks and datasets.
- Paired-data requirements: Image-usage ablations are limited to 0–100% ratios; test extreme low-pairing regimes (e.g., 1–5%), semi/pseudo-paired settings, and fully unpaired training at scale to understand how little pairing is needed for benefits.
- Multi-view aggregation: Scenes with many images are chunked into “one point cloud + four images.” Analyze how the number, distribution, and viewpoint diversity of images per scene influence performance; study multi-view fusion strategies beyond chunking.
- Alternative 2D encoders: Only DINOv2 is used. Compare iBOT, MAE, MoCo v3, supervised ViTs, and multi-scale 2D encoders to understand how 2D representation properties (texture vs. shape bias) impact 3D learning.
- Granularity of alignment: Patch-level alignment may miss fine textures and small objects. Explore sub-patch alignment, superpixel/segments, or geometry-aware tiling to better capture fine-grained correspondences.
- Per-task coverage: Evaluation focuses on semantic/instance segmentation. Test additional downstream tasks (3D detection, panoptic segmentation, registration, pose estimation, SLAM, scene graph construction, affordance prediction, robotic manipulation) to validate generality.
- Failure modes and analyses: Provide qualitative/quantitative error analysis (e.g., transparent surfaces, specular materials, repetitive textures, clutter) to guide improvements in correspondence, augmentations, and predictor robustness.
- Video lifting quality and artifacts: VGGT reconstructions can be noisy. Quantify how reconstruction quality affects training; compare with SfM/MVS pipelines; evaluate dynamic objects and motion blur; explore training directly on raw videos without lifting.
- Scaling laws: Early scaling results (T/S/B/L variants) show modest gains. Establish scaling curves vs. data size, image/point ratios, and model capacity; analyze saturation points and whether additional video/image data meaningfully expands representational capacity.
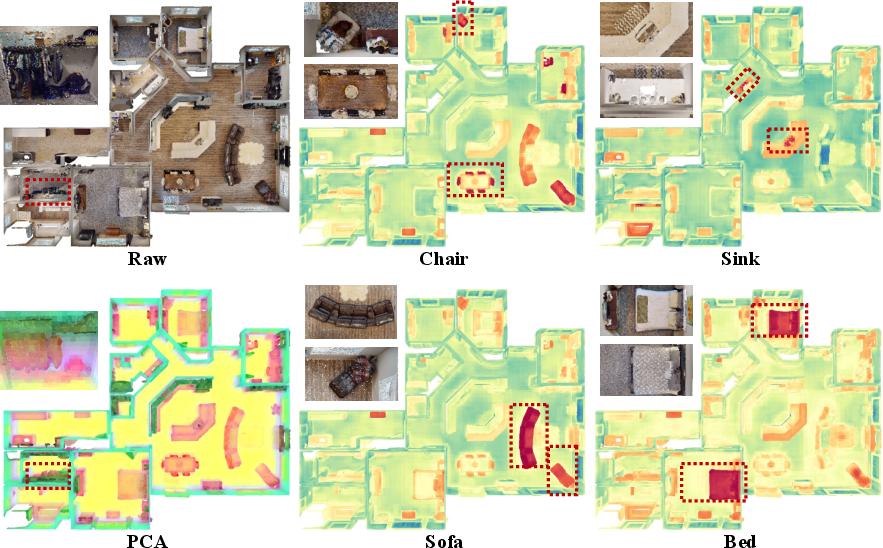
- Representation diagnostics: Go beyond PCA visualizations to quantify geometry/semantics disentanglement, invariance/equivariance to transformations, and shape-vs-texture bias with controlled probes.
- Reproducibility and implementation details: Core correspondence and aggregation steps are “in the Appendix.” Provide ablation-ready code toggles for camera handling, patching, visibility, and augmentations; release scripts to replicate cross-modal mapping decisions.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging Concerto’s joint 2D–3D self-supervised representations, strong linear probing performance, and practical data/parameter efficiency.
- Indoor scene segmentation and instance segmentation for AR/MR and robotics (sectors: software, robotics, mixed reality)
- Use Concerto-pretrained PTv3 encoders as drop-in backbones for semantic/instance segmentation in indoor environments (e.g., ScanNet-like spaces) with minimal labels via linear heads or LoRA adapters.
- Workflows/tools: Concerto PTv3 checkpoints; lightweight linear/decoder probing; ROS/Isaac integration; on-device inference for AR occlusion and physics-aware placement.
- Assumptions/dependencies: GPU inference; alignment between camera and point cloud streams; indoor domain similarity to training data; limited fine-tuning for custom objects.
- Video-to-3D environment mapping for rapid deployment and scanning (sectors: software, construction/BIM, real estate, facilities)
- Capture smartphone or head-mounted video and lift to point clouds via feed-forward reconstruction (e.g., VGGT), then run Concerto features for semantic labeling and floorplan generation.
- Workflows/tools: “Video-lift” pipeline with VGGT; batch processing to point clouds; Concerto encoder for tagging rooms, furniture, fixtures; export to IFC/BIM.
- Assumptions/dependencies: video quality and camera intrinsics/extrinsics; reconstruction reliability; controlled indoor lighting; privacy-aware data handling.
- Low-label adaptation with LoRA/few-shot heads (sectors: robotics, construction/BIM, retail operations)
- Adapt Concerto features to new sites with very limited scenes or sparse annotations using LoRA or linear heads, preserving pretrained generalization and avoiding overfitting.
- Workflows/tools: LoRA adapters for PTv3; human-in-the-loop quality checks; incremental fine-tuning per site.
- Assumptions/dependencies: access to small labeled samples; consistent sensor calibration; monitoring for distribution shifts.
- 3D data annotation assistants and auto-labeling (sectors: software, academia, construction/BIM)
- Pre-annotate scans with Concerto; present suggestions to annotators to accelerate dataset creation and reduce labeling costs.
- Workflows/tools: annotation UI with Concerto pre-labels; confidence thresholds; open-vocabulary mapping via CLIP translator for custom taxonomies.
- Assumptions/dependencies: human review for accuracy; taxonomy alignment; CLIP-based translator currently moderate (zero-shot mIoU ~45% on ScanNet).
- Open-vocabulary 3D queries for asset inventory and compliance (sectors: facilities, safety/compliance, education)
- Use Concerto’s language-space translator to enable text queries (e.g., “fire extinguisher”, “exit sign”, “whiteboard”) over building scans for inventory or compliance checks.
- Workflows/tools: CLIP/LSeg-aligned linear translator; semantic search interface; audit logs and export reports.
- Assumptions/dependencies: open-vocabulary accuracy is not safety-grade yet; requires domain-specific calibration; manage false positives via human validation.
- Academic baselines and research workflows (sectors: academia)
- Adopt Concerto as a strong baseline for 3D scene perception; evaluate cross-modal JEPA-style training; use language probing into CLIP as a diagnostic for concept alignment.
- Workflows/tools: reproducible training scripts; linear/decoder probing benchmarks; data-efficient protocols for limited scenes/annotations.
- Assumptions/dependencies: access to compute; availability of pretraining datasets or equivalents; adherence to dataset licensing.
Long-Term Applications
These applications will benefit from further research, scaling, domain adaptation, or robustness improvements before production use.
- Outdoor autonomous driving sensor fusion with self-supervised pretraining (sectors: automotive, software)
- Extend Concerto’s 2D–3D synergy to LiDAR–camera fusion in dynamic, outdoor scenes to reduce annotation needs and improve long-tail object understanding.
- Potential products: pretraining suites for AD stacks; open-vocab hazard detection in complex traffic.
- Assumptions/dependencies: domain shift from indoor to outdoor; dynamic scene modeling; sensor-specific augmentation; regulatory validation for safety-critical deployment.
- Robust open-world 3D perception and text-driven interaction (sectors: robotics, mixed reality, software)
- Achieve high-accuracy text-conditioned 3D segmentation and grounding across diverse environments, enabling voice/LLM-driven spatial tasks (e.g., “find the screwdriver on the third shelf”).
- Potential products: open-world AR assistants; natural language robotic manipulation.
- Assumptions/dependencies: stronger language alignment and grounding; improved zero-shot performance; latency constraints for real-time use.
- Warehouse and logistics automation in unstructured spaces (sectors: robotics, supply chain)
- Use Concerto features for inventory localization, aisle navigation, and dynamic pick-place in varied warehouses with minimal labeling and open-vocab queries.
- Potential tools: warehouse digital twins; adaptive grasping pipelines; anomaly detection.
- Assumptions/dependencies: domain adaptation for industrial objects; safety and reliability benchmarks; integration with fleet management systems.
- Hospital logistics and navigation, asset tracking, and AR guidance (sectors: healthcare, robotics, mixed reality)
- Assist staff and mobile robots with navigation, asset finding, and room-level semantics using video-lifted scans and open-vocab queries.
- Potential tools: hospital AR wayfinding; sterile-zone mapping; patient-room inventory.
- Assumptions/dependencies: accuracy and privacy requirements; HIPAA-compliant data pipelines; domain-specific object vocabularies and rigorous validation.
- Urban planning, emergency response, and municipal digital twins (sectors: policy, public sector, energy/infrastructure)
- Create large-scale indoor/outdoor digital twins from videos and scans; enable rapid assessment and open-vocab search for critical assets (e.g., “AED”, “fire escape”) during emergencies.
- Potential tools: city-scale mapping services; compliance audits; resilience planning dashboards.
- Assumptions/dependencies: scalability of video-lift pipelines; data governance and privacy; inter-agency standards and procurement processes.
- Industrial inspection and safety analytics (sectors: energy, manufacturing)
- Use 2D–3D joint embeddings to detect equipment, pipes, valves, and signage in complex facilities; open-vocab queries for hazards or PPE compliance.
- Potential tools: inspection copilots; anomaly detections over digital twins; maintenance planning.
- Assumptions/dependencies: domain-specific fine-tuning; robustness in harsh environments; integration with CMMS/EAM systems.
- Property risk assessment and insurance claims automation (sectors: finance/insurance, real estate)
- Automate 3D assessment from customer-provided videos/scans for claims and underwriting; open-vocab detection for risk factors (e.g., “exposed wiring”, “water damage”).
- Potential products: claims triage engines; underwriting pre-checks; fraud detection overlays.
- Assumptions/dependencies: high-precision requirements; standardized capture protocols; regulatory compliance and explainability.
- Education and training in 3D spatial reasoning (sectors: education)
- Develop curricula and virtual labs that teach 3D perception and concept grounding using Concerto as a hands-on framework; create annotated educational digital twins.
- Potential tools: classroom AR kits; coding labs; 3D concept search.
- Assumptions/dependencies: accessible compute; curated datasets for K–12/higher ed; ease-of-use tooling.
Cross-cutting assumptions and dependencies
- Camera–point cloud calibration and reliable correspondence: Concerto’s cross-modal predictor uses camera parameters; poor calibration degrades performance.
- Data availability and scaling: reproducing SOTA requires significant 2D/3D pretraining data (e.g., ~40k point clouds, ~300k images) or access to strong public checkpoints.
- Compute budgets: training and inference with PTv3 backbones may need modern GPUs; mobile/edge optimization will be needed for AR/robotics.
- Domain shift and safety: indoor-trained models may require adaptation for outdoor/industrial/medical domains; safety-critical use cases need thorough validation and monitoring.
- Privacy and governance: video-lifted mapping raises privacy concerns; policy and compliance frameworks must be established for capture, storage, and use.
Glossary
- Ablation Study: Systematic experiments to assess the impact of design choices or components. Example: "Ablation study."
- allAcc: Overall accuracy metric across all classes, often used in segmentation benchmarks. Example: "allAcc"
- Camera Parameters: Intrinsic and extrinsic properties of a camera used to relate 2D pixels to 3D points. Example: "camera parameters"
- CLIP: A multimodal model that aligns images and text in a shared embedding space. Example: "CLIP’s language space"
- Conditional Predictor: A model that predicts target representations conditioned on auxiliary information. Example: "using a conditional predictor"
- Cosine Similarity: A measure of similarity between vectors based on the cosine of the angle between them, used as a loss or alignment criterion. Example: "cosine similarity"
- Cross-Modal Joint Embedding: Learning a shared representation that aligns features from different modalities (e.g., 2D and 3D). Example: "cross-modal joint embedding"
- Decoder Probing: Evaluating frozen representations by training a lightweight decoder on top of them for a downstream task. Example: "decoder probing"
- DINOv2: A self-supervised vision transformer model for learning image representations. Example: "DINOv2"
- Downstream Tasks: Tasks used to evaluate learned representations, such as segmentation or classification. Example: "downstream tasks"
- Feed-Forward Reconstruction: Inferring 3D structure from video frames in a single pass without iterative optimization. Example: "feed-forward reconstruction"
- Feature Concatenation: Combining feature vectors from different sources or modalities by stacking them. Example: "their feature concatenation"
- Feature-Level Fusion: Integrating features from different modalities at the representation level. Example: "feature-level fusion"
- Fine-Tuning: Updating all or part of a pretrained model on a specific task to improve performance. Example: "full fine-tuning"
- Geometric Shortcut: A failure mode where models rely on trivial geometric cues rather than learning robust features. Example: "geometric shortcut"
- Joint Embedding Predictive Architecture (JEPA): A framework for learning by predicting representations across modalities. Example: "Joint Embedding Predictive Architecture (JEPA)"
- Joint 2D-3D Self-Supervised Learning: Training that simultaneously leverages image and point cloud data without labels to learn unified spatial representations. Example: "Concerto: Joint 2D-3D Self-Supervised Learning"
- Joint Embedding Prediction: Predicting one modality’s embeddings from another to enforce cross-modal alignment. Example: "joint embedding prediction"
- Language Probing: Mapping learned visual/3D representations into a language embedding space to evaluate semantic alignment. Example: "Language probing."
- Latent Representations: Hidden feature vectors learned by models that capture abstract properties of data. Example: "latent representations"
- Linear Probing: Evaluating representations by training a single linear layer on top of a frozen encoder. Example: "linear probing"
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning method that inserts low-rank adapters into pretrained models. Example: "LoRA"
- LSeg: A model that produces language-aligned image features for semantic segmentation. Example: "LSeg"
- mAP: Mean average precision, a detection/instance segmentation metric summarizing precision across recall thresholds. Example: "mAP"
- mIoU: Mean Intersection over Union, a segmentation metric averaging IoU across classes. Example: "mIoU"
- Momentum-Updated Teacher: A teacher network whose parameters are an exponential moving average of the student’s, used in self-distillation. Example: "momentum-updated teacher"
- Multisensory Synergy: The integration of information across multiple senses/modalities to form richer representations. Example: "multisensory synergy"
- Online Clustering: A self-supervised objective that groups features into clusters during training to structure representations. Example: "online clustering objective"
- Open-Vocabulary: Capability to recognize or segment categories beyond a fixed training label set by leveraging language embeddings. Example: "open-vocabulary capabilities"
- Open-World Perception: Perception that can generalize to unseen categories and environments using broad, language-aligned representations. Example: "open-world perception"
- PCA: Principal Component Analysis; used to visualize feature variance by projecting features to principal components. Example: "PCA-colored visualizations"
- Point Transformer V3 (PTv3): A transformer-based architecture specialized for point cloud processing. Example: "Point Transformer V3"
- Restricted Online Clustering Objective: A constrained clustering loss used during self-distillation to stabilize and refine features. Example: "restricted online clustering objective"
- Self-Distillation: A self-supervised training method where a student network learns from a teacher network’s outputs. Example: "self-distillation"
- Self-Supervised Learning: Learning representations from data without human-provided labels using auxiliary objectives. Example: "self-supervised learning"
- Semantic Segmentation: Assigning a class label to each pixel/point in an image/point cloud. Example: "Semantic segmentation."
- Sparse Point Clouds: Point cloud data with low sampling density, common in real-world 3D sensing scenarios. Example: "sparse point clouds"
- SOTA: State-of-the-art; the best-performing methods or results at the time. Example: "SOTA"
- Teacher-Student Paradigm: A training setup where a student network learns to match a teacher’s representations. Example: "teacher-student paradigm"
- Upcast Level: The concatenation depth or level used when aggregating multi-scale features for cross-modal learning. Example: "Upcast level."
- Video-Lifted Point Clouds: 3D point clouds reconstructed from videos to enable spatial understanding. Example: "video-lifted"
- VGGT: A feed-forward video-to-geometry reconstruction method used to lift point clouds from video. Example: "VGGT"
- Zero-Shot: Evaluation without task-specific training, relying on general pretrained representations or language alignment. Example: "zero-shot segmentation"
Collections
Sign up for free to add this paper to one or more collections.

