- The paper introduces a unified transformer framework that jointly learns geometric reconstruction and instance-level semantic representations.
- The paper utilizes the novel InsScene-15K dataset and a multi-task loss strategy, achieving state-of-the-art performance on benchmarks like ScanNet.
- The paper demonstrates significant improvements in instance spatial tracking, open-vocabulary segmentation, and QA scene grounding through effective cross-modal fusion.
Introduction and Motivation
The IGGT framework addresses the persistent challenge in 3D scene understanding: the integration of geometric reconstruction and instance-level semantic reasoning. Prior approaches typically decouple these tasks, resulting in error propagation and limited mutual enhancement between geometry and semantics. Recent attempts to align 3D models with specific vision-LLMs (VLMs) suffer from over-smoothing, restricted adaptability, and poor instance discrimination. IGGT proposes a unified transformer-based architecture that jointly learns geometric and instance-grounded semantic representations, enabling robust 3D reconstruction and contextual understanding from multi-view 2D images.
InsScene-15K Dataset and Data Curation
IGGT is trained on the InsScene-15K dataset, which comprises high-quality RGB images, depth maps, camera poses, and 3D-consistent instance-level mask annotations. The data curation pipeline integrates synthetic, video-captured, and RGBD-captured scenes. For synthetic data, perfect ground-truth masks are used directly. For real-world data, a novel annotation engine based on SAM2 propagates and refines instance masks across views, ensuring multi-view ID consistency and high mask quality.
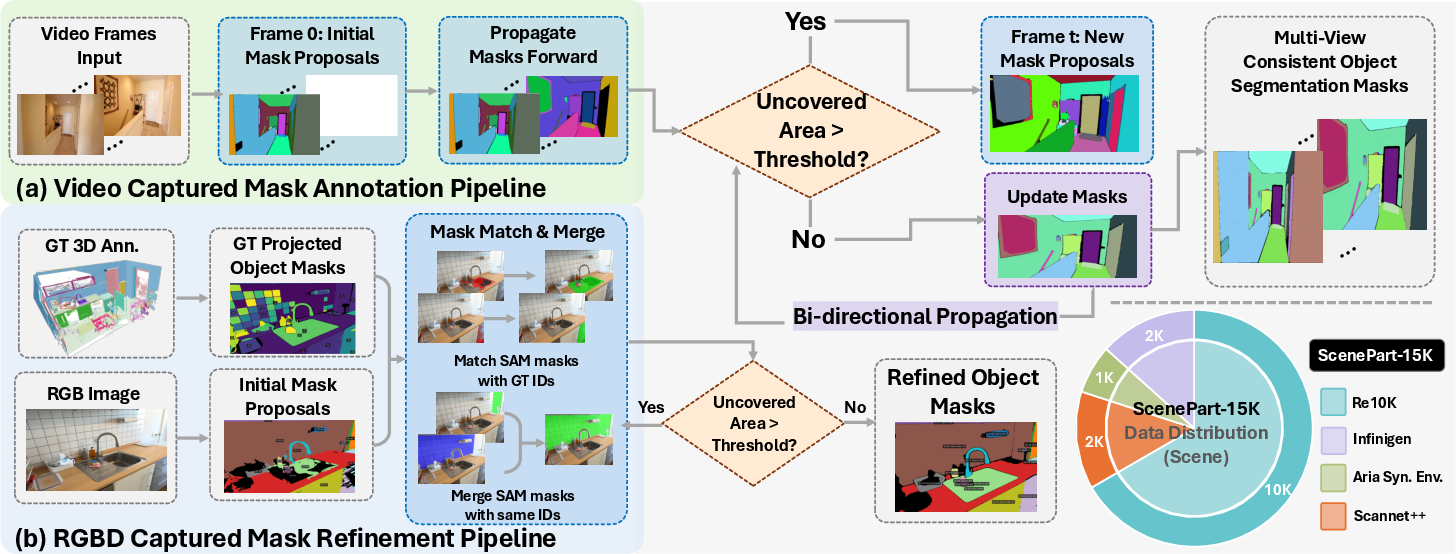
Figure 1: The data curation pipeline leverages SAM2 for scalable, multi-view consistent mask annotation across diverse sources.

Figure 2: Mask annotation quality comparison, showing refined multi-view masks with improved mIoU and ID consistency over vanilla ground-truth.
IGGT Architecture
IGGT consists of a large unified transformer backbone, a geometry head, and an instance head. The transformer encodes multi-view images into unified token representations, capturing both local and global scene context. The geometry head regresses camera parameters, depth maps, and point clouds, while the instance head predicts instance-level features. A cross-modal fusion block with window-shifted attention enables the instance head to leverage fine-grained geometric features, enhancing spatial awareness and boundary sensitivity.
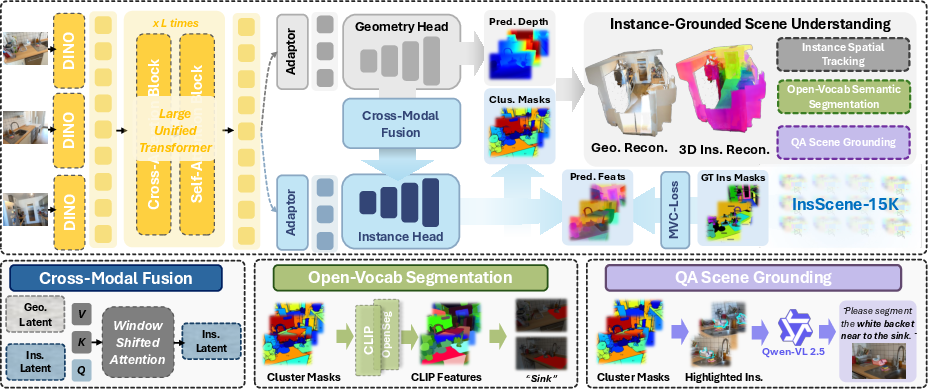
Figure 3: IGGT architecture overview, illustrating unified token encoding and dual-head decoding for geometry and instance clustering.
The model is trained with a multi-task loss combining pose, depth, point map, and a 3D-consistent contrastive loss. The contrastive loss enforces feature consistency for the same instance across views and discriminates between different instances, improving generalization and multi-view coherence.
Instance-Grounded Scene Understanding
IGGT introduces an instance-grounded paradigm for scene understanding, decoupling the model from specific VLMs. Instance masks derived from clustering the instance features serve as prompts for downstream VLMs and LMMs, enabling plug-and-play integration for open-vocabulary segmentation and object-centric QA.
- Instance Spatial Tracking: HDBSCAN clusters multi-view instance features, yielding 3D-consistent masks for robust tracking under large viewpoint changes.
- Open-Vocabulary Segmentation: Instance masks guide VLMs (e.g., CLIP, OpenSeg) for semantic assignment, improving boundary sharpness and category discrimination.
- QA Scene Grounding: Instance masks interact with LMMs for object-centric QA, supporting complex queries and multi-view consistency.
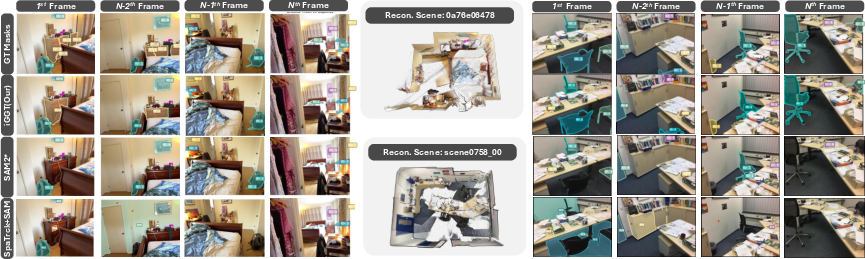
Figure 4: Qualitative results for instance spatial tracking, demonstrating robust multi-view tracking and segmentation compared to baselines.

Figure 5: PCA visualization of instance features and clustered masks, showing discriminative, 3D-consistent instance representations.

Figure 6: Qualitative open-vocabulary segmentation results, highlighting improved multi-view consistency and fine-grained semantic assignment.


Figure 7: QA scene grounding applications, comparing IGGT's instance-grounded querying with Gemini 2.5 Pro.
Experimental Results
IGGT achieves state-of-the-art performance on ScanNet and ScanNet++ across spatial tracking, reconstruction, and open-vocabulary segmentation tasks. Notably, IGGT attains T-SR of 98.66% and T-mIoU of 69.41% on ScanNet, outperforming all baselines. In 2D/3D segmentation, IGGT surpasses previous methods by up to 8.34% mIoU and 7.88% mAcc. The joint training of geometry and semantics yields superior depth estimation and 3D mIoU, with improvements of 4.31% and 4.97% over prior art.
Ablation studies confirm the necessity of cross-modal fusion for high-resolution instance features and demonstrate the flexibility of IGGT in integrating different VLMs. LSeg and OpenSeg excel in background classes, while CLIP provides better text alignment for complex categories.
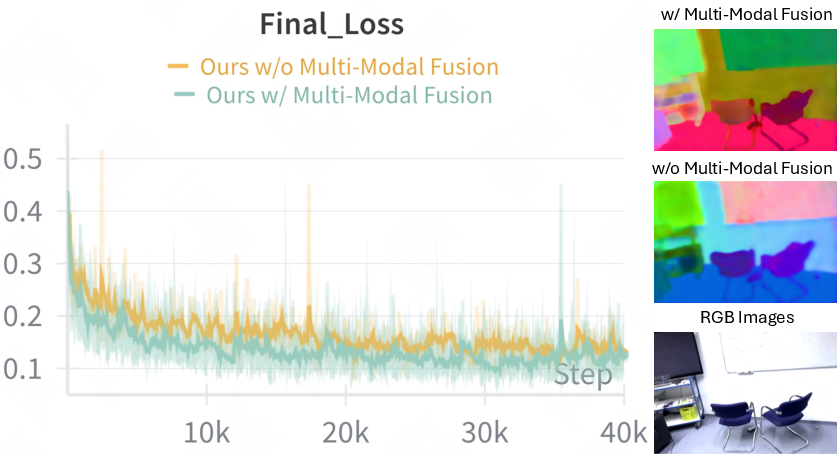
Figure 8: Ablation on cross-modal fusion, showing improved convergence and edge sharpness in instance features.
Implementation and Scalability
IGGT is initialized from VGGT weights and fine-tuned on InsScene-15K using 8 NVIDIA A800 GPUs. The transformer backbone and heads are trained with AdamW, with batch sampling strategies designed for spatial coverage and cross-view consistency. The unsupervised clustering post-processing enables scalable instance mask generation, though boundary accuracy is currently limited by the clustering algorithm.
Limitations and Future Directions
The reliance on unsupervised clustering for instance mask generation constrains boundary accuracy compared to state-of-the-art segmentation models. Future work may incorporate DETR-based instance heads and larger annotated datasets to enhance segmentation precision. The instance-grounded paradigm opens avenues for integrating emerging VLMs and LMMs, supporting more sophisticated scene understanding and interaction.

Figure 9: Comparison of vanilla ScanNet++ ground-truth masks and IGGT-refined masks, demonstrating improved coverage and alignment.
Conclusion
IGGT presents a unified transformer-based framework for semantic 3D reconstruction, jointly learning geometric and instance-level semantic representations. The instance-grounded paradigm enables flexible integration with diverse VLMs and LMMs, supporting robust tracking, segmentation, and QA in complex 3D scenes. IGGT sets a new benchmark for multi-view consistency and semantic understanding, with strong empirical results and extensibility for future research in spatial intelligence and multimodal scene analysis.