POMA-3D: The Point Map Way to 3D Scene Understanding
Abstract: In this paper, we introduce POMA-3D, the first self-supervised 3D representation model learned from point maps. Point maps encode explicit 3D coordinates on a structured 2D grid, preserving global 3D geometry while remaining compatible with the input format of 2D foundation models. To transfer rich 2D priors into POMA-3D, a view-to-scene alignment strategy is designed. Moreover, as point maps are view-dependent with respect to a canonical space, we introduce POMA-JEPA, a joint embedding-predictive architecture that enforces geometrically consistent point map features across multiple views. Additionally, we introduce ScenePoint, a point map dataset constructed from 6.5K room-level RGB-D scenes and 1M 2D image scenes to facilitate large-scale POMA-3D pretraining. Experiments show that POMA-3D serves as a strong backbone for both specialist and generalist 3D understanding. It benefits diverse tasks, including 3D question answering, embodied navigation, scene retrieval, and embodied localization, all achieved using only geometric inputs (i.e., 3D coordinates). Overall, our POMA-3D explores a point map way to 3D scene understanding, addressing the scarcity of pretrained priors and limited data in 3D representation learning. Project Page: https://matchlab-imperial.github.io/poma3d/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “POMA-3D: The Point Map Way to 3D Scene Understanding”
Overview: What is this paper about?
This paper introduces POMA-3D, a new way for computers to understand 3D spaces (like rooms or buildings). Instead of using regular 3D data formats, it uses “point maps,” which are like special images where every pixel carries its exact position in the real world. The big idea is to teach a 3D model using knowledge from powerful 2D models (that understand pictures and text) so it can handle many 3D tasks—even without color—just using geometry.
Goals: What questions did the researchers ask?
The researchers wanted to know:
- Can we train a strong 3D model using “point maps” that are easier to connect with 2D image models?
- Can we transfer the rich knowledge from 2D image–text models (like CLIP) to 3D understanding?
- Will this help with different 3D tasks, such as answering questions about a room, navigating, finding the right scene from a description, or locating where an agent is based on a text hint?
Methods: How did they do it?
Think of their approach as teaching the model in two steps, with smart data and training tricks.
What is a “point map”?
- Imagine a photo of a room. Normally, each pixel just shows color. In a point map, each pixel also knows its real 3D position (x, y, z) in the world.
- So you get the best of both worlds: a 2D grid (like an image) with accurate 3D geometry. This makes it much easier to align with 2D models while keeping full 3D structure.
What is “self-supervised” learning?
- It’s learning without needing a teacher to label everything. The model learns patterns from the data itself, like figuring out how different views of the same room relate to each other.
Training data: ScenePoint
- They built a new dataset called ScenePoint:
- About 6,500 real indoor rooms (from RGB-D videos—color plus depth).
- 1,000,000 single images from an image–caption dataset, converted into point maps using a 3D reconstruction model (VGGT).
- Each view has captions, and scenes also have longer descriptions. This lets the model connect 3D geometry with text.
Connecting 3D with 2D: Vision–language alignment
- The model learns that a point map (3D), an image (2D), and a caption (text) all describe the same thing.
- It uses a powerful 2D foundation model (FG-CLIP, like CLIP) to “align” the 3D point map features with image and text features. Think of it as teaching the 3D model the meanings understood by 2D models.
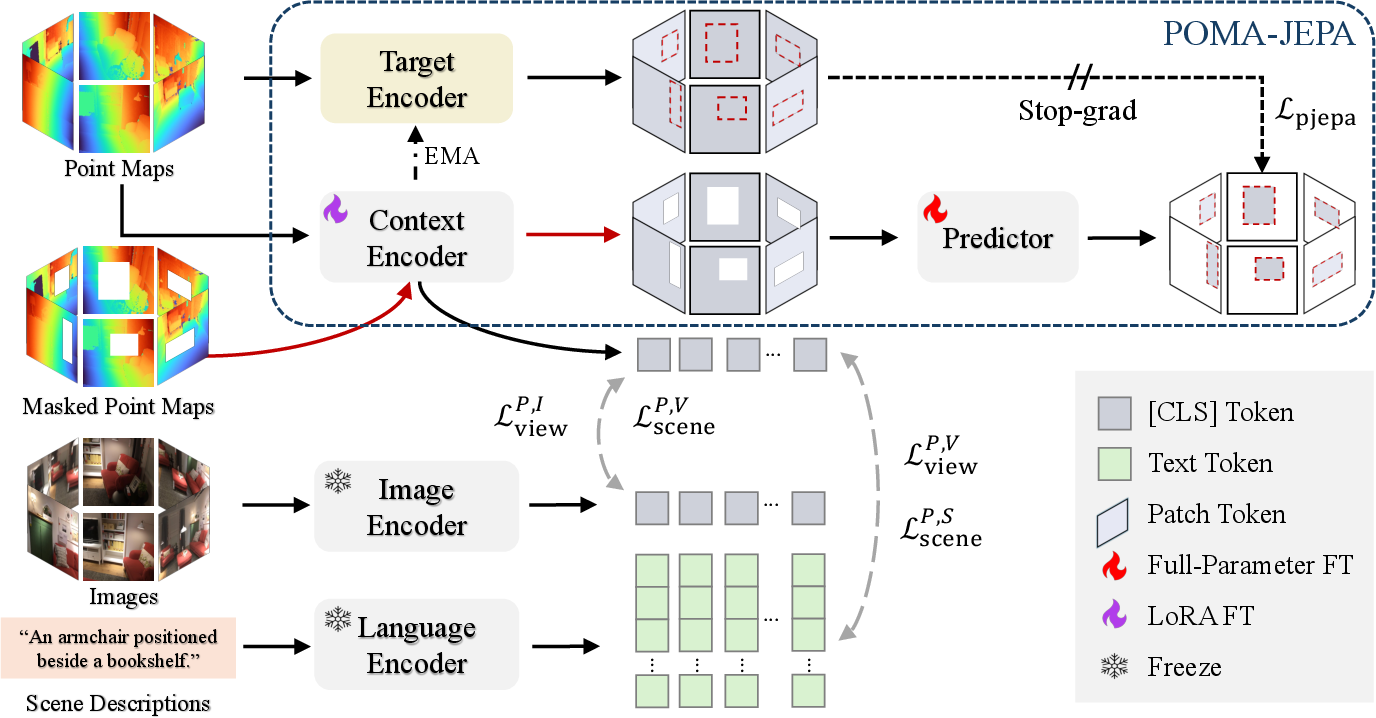
Making different views agree: POMA-JEPA
- Rooms are seen from multiple views (like different camera angles). The model must keep its understanding consistent across these views.
- POMA-JEPA is a training step where the model predicts the features of hidden patches (masked parts) by looking at visible ones from other views.
- Important detail: 3D points don’t have a fixed order like pixels in an image. To avoid confusion, they compare sets of features in a way that doesn’t care about exact ordering (using a “Chamfer distance,” which is like measuring how close two clouds of points are overall).
Two-stage training
- Warm-up stage: Train on single-view point maps from images to learn basic 3D–2D alignment.
- Main stage: Train on multi-view room data to learn strong scene-level understanding and view consistency.
Results: What did they find and why it matters?
POMA-3D turned out to be a strong backbone (starting point) for many 3D tasks, often beating previous methods—even when it only used 3D coordinates (no colors).
- 3D Question Answering: The model did especially well on tasks that require understanding spatial relationships and common sense in 3D rooms.
- Embodied Navigation: Given a room and an instruction, it chose good directions to move, and performed best or near-best in both simpler (4 directions) and harder (8 directions) settings.
- Scene Retrieval: Given a description (like “a room with three footstools and bookshelves”), it found the correct 3D scene much more reliably than other methods.
- Embodied Localization: From a simple text like “I am standing between two blackboards,” it retrieved the views that highlight the agent’s likely location in the room.
Why this is important:
- It shows that knowledge learned from huge 2D datasets (images and captions) can be reused to help 3D models—solving the problem that 3D data is limited and expensive to collect.
- Point maps act as a “bridge” between 2D and 3D, making alignment easier and more effective.
- The model works well without color—just from geometry—which is handy in cases where color is missing or unreliable.
Implications: What could this lead to?
This research points toward scalable, general-purpose 3D models that:
- Help robots and AR systems understand and navigate real spaces more reliably (e.g., find the kitchen from a description, or locate a bed from “I’m sitting on the bed”).
- Make it easier to build 3D “foundation models” by reusing existing large 2D datasets, saving time and resources.
- Encourage future work to combine 3D coordinates with color and texture for even richer understanding.
- Support both specialist tools (for a single job) and generalist systems (that can do many 3D tasks) with the same powerful 3D features.
In short, POMA-3D shows a practical and effective “point map” path to 3D scene understanding, helping computers learn from the vast knowledge already available in 2D image–text models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research.
- Limited modality scope (geometry-only): POMA-3D uses only point-map coordinates (no color/texture). Quantify how much performance is lost/gained by adding appearance features; design and evaluate principled fusion (e.g., late fusion with RGB CLIP embeddings, joint geometric–photometric encoders, colorized point maps) across color-dependent tasks such as ScanQA.
- Reliance on 2D foundation models without scaling analysis: The point-map encoder is initialized from FG-CLIP ViT-B/16 and LoRA-tuned. Evaluate scaling laws (ViT-L/14, ViT-H/14), training from scratch versus 2D-initialization, and whether stronger 2D backbones materially change 3D performance or alignment stability.
- POMA-JEPA loss design not ablated: JEPA uses Chamfer Distance over patch embeddings to avoid order constraints. Test alternative permutation-invariant objectives (e.g., Earth Mover’s Distance/optimal transport, contrastive-set matching, Sinkhorn) and report failure modes (e.g., mode collapse) under different losses, predictor depths, and mask ratios.
- Patch-level versus [CLS]-level alignment: Current view/scene alignment uses [CLS] embeddings; it is unclear if local semantics are captured. Explore fine-grained patch-level or region-level alignment (e.g., cross-attention to text tokens), and measure improvements on fine-grained tasks (grounding, spatial relationships).
- Multi-view aggregation is simplistic: Scene embeddings are mean-pooled across views. Compare attention pooling, transformer-based cross-view fusion, or geometry-aware pooling (e.g., pose-weighted, visibility-aware) to improve holistic scene representations.
- Embodied localization lacks quantitative evaluation: Only qualitative results are shown. Establish a benchmark with ground-truth agent positions/regions and report metrics (IoU, Top-K recall/precision, localization error) to quantify performance.
- Generalization to outdoor, large-scale, and dynamic scenes is unknown: ScenePoint focuses on indoor RGB-D; assess transfer to LiDAR, outdoor datasets (e.g., KITTI, nuScenes), large spaces (malls, airports), and scenes with dynamic objects. Investigate gravity alignment or canonical axes for cross-scene comparability.
- Sensitivity to camera calibration and depth noise: Room point maps depend on accurate intrinsics/extrinsics; single-view point maps use VGGT predictions. Quantify robustness to pose/depth errors (synthetic perturbations), scale ambiguities, and occlusions; propose pose/noise-robust training (e.g., uncertainty-aware losses).
- Warm-up with pseudo point maps from 2D images is under-characterized: Single-view point maps have unconstrained scales/orientations. Measure their metric fidelity, how mis-specified frames affect downstream alignment, and whether normalization (e.g., unit-sphere scaling, gravity alignment) improves warm-up transfer.
- Caption quality and bias unchecked: View-level captions are LLM-generated and filtered by FG-CLIP similarity; scene-level captions are sourced externally. Audit caption correctness, bias, and diversity; evaluate how caption quality affects alignment and downstream performance (e.g., via controlled noise or adversarial perturbations).
- Dataset coverage remains modest for 3D scenes: Only ~6.5K room-level scenes (though supplemented with 1M images). Explore scaling with more real scenes, richer sensor modalities (LiDAR, stereo), and diverse layouts; report data–performance scaling curves and sample-efficiency.
- No direct evaluation on standard 3D visual grounding: Due to point cloud vs point-map misalignment, VG is repurposed to scene retrieval. Develop an evaluation protocol that bridges point-map grids to point-cloud annotations (e.g., reprojecting masks, voxel alignment, learned map–cloud registration) to test object-level grounding.
- Cross-lingual and long-text handling not studied: FG-CLIP is chosen for longer text capacity, but multilingual alignment and very long scene narratives are not evaluated. Test multilingual datasets (e.g., Jina-CLIP-v2), code-switching, and long-instruction robustness.
- Hard negative mining and curriculum are absent: Negatives are drawn within-batch under maximum coverage sampling. Investigate hard-negative mining (cross-scene, near-duplicate scenes), curriculum strategies, and their effect on retrieval/localization robustness.
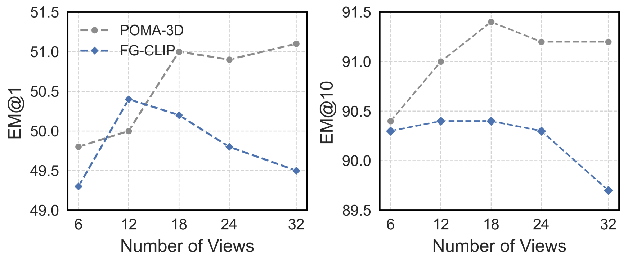
- View selection policy effects are unknown: 32-view maximum coverage sampling is used. Analyze the impact of view count, selection strategy (random vs coverage vs diversity), and redundancy; optimize selection for compute–accuracy trade-offs.
- Compute efficiency and memory footprint unreported: Point maps scale with image resolution (H×W×3), potentially heavy for multi-view training. Report throughput, memory usage, latency, and trade-offs across resolutions; explore compression (e.g., sparse grids, learned downsampling).
- Coordinate-frame consistency across scenes: Multi-view point maps share a world frame per scene, but cross-scene frames are arbitrary. Study normalization (e.g., canonical orientation via gravity/floor plane, scale alignment) to improve cross-scene retrieval and zero-shot transfer.
- Limited integration with generalist 3D LLMs: Due to resource constraints, only lightweight LoRA is used for one epoch. Evaluate deeper instruction tuning, full-model finetuning, and using POMA-3D as primary 3D backbone in scratch-trained 3D LLMs; report sample efficiency and stability.
- Comparison breadth across 3D modalities: While depth maps and point clouds are compared, analysis remains limited. Include stronger baselines (fused point clouds, meshes, voxels, NeRFs, 3DGS with geometry-aware encoders) under identical training recipes to isolate the benefits of point maps.
- Robustness to occlusion and visibility across views: POMA-JEPA masks per-view patches and reconstructs across views, but does not explicitly model visibility. Add visibility-aware masking, occlusion handling, and test performance under heavy occlusions or limited overlap.
- Explainability and geometry–semantics disentanglement: It is unclear which geometric cues drive predictions. Provide attribution (e.g., token/patch saliency maps, text-to-geometry attention visualizations) and measure whether embeddings encode metric properties (distances, angles) versus coarse layout.
- Failure-case analysis is minimal: Document cases where POMA-3D underperforms (e.g., color-dependent queries, cluttered scenes, repetitive layouts), and derive targeted remedies (appearance fusion, hard negatives, local alignment).
- Hyperparameter sensitivity is underreported: No ablations for predictor depth, mask aspect ratios, temperature τ, LoRA ranks, or EMA decay. Provide systematic sensitivity analyses and guidelines for stable training.
- Integration with SR-3D and related point-map approaches not compared: Directly benchmark against SR-3D’s positional-encoding strategy and hybrid encoders to quantify the gains of dedicated point-map pretraining.
- Safety, fairness, and privacy considerations: Indoor datasets may encode socioeconomic or cultural biases. Audit for bias, ensure privacy-preserving data handling, and evaluate fairness across room types and object distributions.
Practical Applications
Practical Applications Derived from POMA-3D
POMA-3D introduces a self-supervised 3D representation learned from point maps and aligned with 2D foundation models via view-to-scene vision–language alignment and the POMA-JEPA objective. It demonstrates transfer to 3D QA, embodied navigation, scene retrieval, and embodied localization, using only geometric inputs. Below are actionable applications, categorized by deployment horizon, with sector tags, workflows/products that could emerge, and feasibility notes.
Immediate Applications
- 3D scene search and retrieval across scan repositories
- Sector: software, AEC (architecture/engineering/construction), facilities, real estate
- What: Build a “3D search engine” to query large libraries of building scans (ScanNet/ARKitScenes-like) using natural language (e.g., “conference room with two whiteboards and six chairs”).
- Tools/products/workflow: PointMap Indexer service to embed point-map scenes; text-to-scene retrieval API; UI for scene ranking with preview.
- Dependencies/assumptions: Access to room-level scans or RGB-D videos; ScenePoint-like curation; reliable view-to-scene embeddings; domain LoRA fine-tuning improves precision.
- Text-to-region embodied localization for mobile robots and AR
- Sector: robotics, AR/VR, smart home
- What: Localize an agent’s current area from a situational text (“I’m standing between two blackboards”), highlight top-K views, and plan movements towards the inferred region.
- Tools/products/workflow: Embodied Localization API; robot planner consumes top-K localized views and computes navigation waypoints; AR overlay that highlights regions satisfying a query.
- Dependencies/assumptions: Multi-view point maps covering the agent’s surroundings; consistent world-frame coordinates; simple path planners; may need object cues beyond geometry in some cases.
- Directional decision-making for navigation tasks from language
- Sector: robotics, logistics, healthcare operations
- What: Use POMA-3D’s improved 4-/8-directional navigation (MSNN benchmark) to decide movement based on text instructions (“go towards the bed”), all on geometry-only inputs.
- Tools/products/workflow: Lightweight navigation module plugged into mobile robots; instruction-to-direction classifier; integration with SLAM stacks to maintain global frame.
- Dependencies/assumptions: Geometry coverage of the environment; downstream fine-tuning on domain-specific layouts; possible benefit from limited color fusion (signage recognition).
- 3D question answering assistants for indoor environments
- Sector: education, retail, facilities management, robotics
- What: Query scenes for spatial, situated, and hypothetical reasoning (e.g., “Is there enough space to place a wheelchair next to the bed?”) using point-map features, outperforming prior 3D VLL baselines on SQA3D/Hypo3D.
- Tools/products/workflow: 3D QA engine backed by POMA-3D; LoRA-tuned LLM front-end; domain prompt templates; deployment for floor plan assessments and staff training.
- Dependencies/assumptions: Accurate camera calibration or reliable depth/pose prediction; geometric-only inputs may miss color-dependent cues (e.g., signage colors).
- Rapid dataset bootstrapping from image corpora
- Sector: academia, simulation, software
- What: Convert existing image-caption datasets to single-view point maps using VGGT (depth/pose prediction) for pretraining and task transfer in low-data 3D regimes.
- Tools/products/workflow: ScenePoint-style converter CLI; batching pipeline to produce point maps at scale; metadata consistency checker for camera parameters.
- Dependencies/assumptions: Quality of VGGT predictions; domain gap between pseudo-depth and real RGB-D; verification protocols for noisy geometry.
- Scene compliance pre-screening (geometry-focused)
- Sector: facilities, policy, safety/EHS
- What: Basic checks using geometric cues (clearances, doorway widths, obstacle-free paths) from point maps to flag potential compliance issues (ADA/OSHA geometries).
- Tools/products/workflow: Geometry rules engine; text-to-checklists QA (“Is the corridor ≥ 36 inches wide?”); batch scanning of building areas.
- Dependencies/assumptions: Reliable metric scale in point maps; limited without semantics (materials, colors); human-in-the-loop verification advised.
- Academic benchmarking and backbone replacement
- Sector: academia
- What: Use POMA-3D as a drop-in 3D backbone for studies on scene-level QA, grounding via retrieval, and embodied tasks; compare modalities (point maps vs depth maps vs point clouds).
- Tools/products/workflow: Open-sourced pretrained weights; training scripts for warm-up and main stages; ablation templates; Chamfer-based POMA-JEPA implementation.
- Dependencies/assumptions: Compute availability (A100-class recommended); access to FG-CLIP and LLaVA-OV for alignment baselines; consistent coordinate conventions.
- Privacy-preserving scene analytics
- Sector: policy, compliance, software
- What: Analytics using coordinate-only point maps to avoid storing raw RGB imagery, reducing PII exposure; apply scene retrieval and QA without faces/textures.
- Tools/products/workflow: Privacy mode pipeline that drops color channels; audit logs documenting coordinate-only storage; legal guidance integration.
- Dependencies/assumptions: Some tasks still need appearance cues (labels/signage); policy acceptance requires risk analyses and DPIA documentation.
Long-Term Applications
- Generalist 3D foundation models spanning perception, language, and action
- Sector: robotics, software, education
- What: Train full-scale 3D LLMs from scratch using point-map encoders for broader task unification (QA, planning, manipulation, multi-agent coordination).
- Tools/products/workflow: Multi-task instruction tuning across 3D QA, navigation, grounding, manipulation; large-scale ScenePoint-like corpora; end-to-end policy heads.
- Dependencies/assumptions: Significant compute; robust datasets beyond indoor rooms; broader sensor diversity; safety evaluation protocols.
- Geometry+appearance fusion for holistic 3D understanding
- Sector: AR/VR, retail, safety/EHS
- What: Combine point-map geometry with color/texture features to improve tasks that depend on appearance (signage, material identification).
- Tools/products/workflow: Dual-stream encoder with late fusion; contrastive training aligning fused embeddings with text; adapters for domain-specific cues (e.g., fire safety symbols).
- Dependencies/assumptions: New datasets with synchronized RGB and geometry; careful calibration; deployment trade-offs for privacy and performance.
- Standardization of point-map formats and APIs
- Sector: policy, interoperability, AEC
- What: Industry standards governing point-map grids, world-frame conventions, and metadata for camera intrinsics/extrinsics to ensure cross-tool compatibility.
- Tools/products/workflow: Open specifications; validation suites; schema registries; compliance certification for vendors.
- Dependencies/assumptions: Multi-stakeholder governance; alignment with existing BIM/IFC standards; backward compatibility with point clouds and Gaussian splats.
- Digital twin analytics with language-driven querying
- Sector: energy, facilities, smart buildings
- What: Integrate POMA-3D embeddings into building digital twins to query space utilization, accessibility, and energy-related geometry (zoning, airflow paths).
- Tools/products/workflow: Twin-wide embedding store; QA/retrieval over live scans; coupling with HVAC/BMS data; alerting for reconfigurations.
- Dependencies/assumptions: Continuous scanning or SLAM updates; accurate metric scale; multi-sensor integration (IoT, occupancy).
- Outdoor adaptation for autonomous systems
- Sector: autonomous driving, public safety
- What: Extend point-map learning to outdoor scenes for pedestrian/vehicle navigation, disaster response, and infrastructure inspection.
- Tools/products/workflow: Dataset generation with multi-view outdoor imagery; robust VGGT depth/pose under diverse lighting; domain-adaptive POMA-JEPA masks.
- Dependencies/assumptions: Handling dynamic objects, weather, scale; safety-critical validation; integration with maps (GIS).
- Language-driven scene graph construction and spatial reasoning pipelines
- Sector: robotics, analytics, education
- What: Construct scene graphs (objects, relations, affordances) from point maps and align them with language for complex tasks (e.g., “place the box under the shelf facing the window”).
- Tools/products/workflow: 3D graph generators; relational QA modules; planning algorithms that leverage graph constraints.
- Dependencies/assumptions: Improved object grounding without color; possibly requires semantic segmentation or multi-modal fusion.
- Compliance automation and policy auditing at scale
- Sector: policy, EHS, healthcare
- What: Automated checking against building codes and hospital policies using geometric thresholds and language rules; continuous compliance monitoring.
- Tools/products/workflow: Policy-to-geometry compilers; dashboards showing pass/fail regions; audit trail generation.
- Dependencies/assumptions: Formalization of standards into machine-readable rules; validated measurement accuracy; legal acceptance.
- Real-time, on-device POMA-3D inference for mobile XR
- Sector: consumer software, hardware
- What: Optimize and compress point-map encoders for smartphones/AR headsets to enable on-device text-to-region search and navigation prompts.
- Tools/products/workflow: Distilled encoders; quantization; on-device CLIP-aligned text encoders; efficient multi-view aggregation.
- Dependencies/assumptions: Hardware constraints; battery/performance trade-offs; privacy requirements; user experience considerations.
- Warehouse/retail robotics with natural-language tasking
- Sector: logistics, retail
- What: Language-driven item pick-and-place and aisle navigation in complex indoor layouts based on geometry-first representations that generalize across stores/warehouses.
- Tools/products/workflow: Retrieval-guided path planning; shelf geometry reasoning; multilingual instruction support.
- Dependencies/assumptions: Object identity often requires appearance; fusion with barcode/RFID systems improves reliability.
- Cultural heritage and museum curation
- Sector: culture, education
- What: Index and retrieve exhibit spaces and artifacts in 3D with language queries for digital tours and curator workflows.
- Tools/products/workflow: Embedding catalogs per gallery; curator QA tools; visitor AR experiences with text-to-region guides.
- Dependencies/assumptions: High-fidelity scanning; fusion for material/color; rights management and preservation policies.
Notes on feasibility across applications:
- POMA-3D is strongest for geometry-driven tasks; color-dependent reasoning (e.g., signage interpretation) requires fusion with appearance features.
- Reliable multi-view coverage and world-coordinate consistency are critical; single-view conversions via VGGT introduce noise and benefit from domain adaptation.
- CLIP-aligned text/image priors are foundational; licensing and model access (FG-CLIP, LLaVA-OV, VGGT) affect deployment.
- Privacy gains from coordinate-only inputs are balanced by potential loss of semantic detail; enterprise policies should explicitly cover data retention and DPIA.
Glossary
- 3D Gaussian splatting: A representation/rendering technique that models a scene with Gaussian kernels in 3D to enable efficient view synthesis and alignment. "The key reason is that these methods primarily utilize point clouds~\cite{jia2024sceneverse,zhu20233d}, depth maps~\cite{mao2024opendlign,huang2023clip2point}, or 3D Gaussian splatting~\cite{li2025scenesplat,thai2025splattalk} for alignment"
- AdamW: An optimizer that decouples weight decay from gradient updates to improve training stability and generalization. "We adopt the AdamW~\cite{loshchilov2017decoupled} optimizer ( = 0.9, = 0.98) with a learning rate of , a warm-up of 500 steps, and cosine decay scheduling."
- Canonical world coordinates: A fixed global coordinate frame that ensures multiple views share the same geometric reference. "Moreover, multi-view point maps are defined in canonical world coordinates, preserving the same global geometry as point clouds."
- Chamfer Distance: A symmetric distance between two point sets used to measure reconstruction alignment without requiring point-wise correspondence. "Here, we define the POMA-JEPA loss $\mathcal{L}_{\text{pjepa}$ using the Chamfer Distance~\cite{fan2017point}, a widely used metric in masked point cloud modeling~\cite{pang2023masked} for its robustness to minor order misalignments, defined as:"
- CLIP: A large-scale vision–LLM that learns aligned image–text embeddings via contrastive training. "Early 3D VLL methods align trainable 3D encoders with frozen 2D vision-LLMs (e.g., CLIP~\cite{radford2021learning})."
- Contrastive objectives: Training losses that pull matched pairs together and push mismatched pairs apart in embedding space. "3D vision-language learning (VLL) provide them through contrastive objectives without relying on downstream annotations."
- Context encoder: The trainable encoder that processes visible inputs to produce embeddings used for alignment and prediction. "Frozen image and language encoders are aligned with a trainable point map context encoder."
- CLS token: A special token embedding used to summarize the content of a sequence or image for downstream tasks. "where , , and denote the [CLS] token embeddings of the point map, image, and per-view caption, respectively."
- Cosine decay scheduling: A learning rate schedule that decays the rate following a cosine curve to stabilize late-stage training. "We adopt the AdamW~\cite{loshchilov2017decoupled} optimizer ( = 0.9, = 0.98) with a learning rate of , a warm-up of 500 steps, and cosine decay scheduling."
- Embodied localization: Identifying the agent’s active region in a scene from language descriptions of its state. "After pretraining, POMA-3D gains the ability to accurately locate the agentâs active region from textual queries in a zero-shot setting, a task we term embodied localization (see Fig.~\ref{fig:1})."
- Embodied navigation: Inferring actions or directions for an agent within a 3D environment based on multimodal context. "including 3D question answering, embodied navigation, scene retrieval, and embodied localization, all achieved using only geometric inputs (i.e., 3D coordinates)."
- Exact Match (EM@1, EM@10): Accuracy metrics counting whether the predicted answer exactly matches the ground truth among top-k outputs. "For LLM-based models, we report exact match (EM@1) scores, and for specialist models, we report both EM@1 and EM@10 metrics."
- Exponential Moving Average (EMA): A parameter update that averages model weights over time to stabilize targets. "the target encoder is updated as the EMA of the context encoder after each iteration."
- Extrinsic parameters: Camera pose parameters (rotation and translation) that map camera coordinates to world coordinates. "using the intrinsic matrix and the extrinsic parameters , where and represent rotation and translation, respectively."
- Feed-forward 3D reconstruction models: Networks that directly predict 3D structure from images without iterative optimization. "This is enabled by recent advances in feed-forward 3D reconstruction models~\cite{wang2024dust3r,wang2025vggt,leroy2024grounding,huang2025no}."
- FG-CLIP: A CLIP variant with extended token capacity, used here as the frozen 2D backbone for alignment. "FG-CLIP~\cite{xie2025fg} is chosen as the backbone for view-to-scene visionâlanguage alignment due to its extended text token capacity, enabling effective modeling of long scene descriptions."
- Intrinsic matrix: Camera parameters (focal lengths and principal point) mapping pixel coordinates to camera rays. "using the intrinsic matrix and the extrinsic parameters , where and represent rotation and translation, respectively."
- JEPA (Joint Embedding-Predictive Architecture): A self-supervised framework that predicts masked/target embeddings from visible context embeddings. "Unlike traditional JEPAs~\cite{assran2023self, bardes2023v,assran2025v}, POMA-JEPA explicitly handles the order-agnostic nature of point maps in the world coordinate frame by enforcing permutation-invariant embedding prediction."
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects trainable low-rank matrices. "A context point map encoder , initialized from and LoRA-finetuned, is used to bridge 3D and 2D modalities."
- Maximum sampling coverage: A frame selection strategy that chooses views covering the largest spatial extent of a scene. "Following the maximum sampling coverage strategy of Video-3D-LLM~\cite{zheng2025video}, the selected frames capture the maximum spatial extent of each scene."
- Mean pooling: Aggregating feature vectors by averaging them to form a single representation. "For scene-level alignment, point map and image embeddings and within each scene are mean-pooled into scene embeddings and ."
- Permutation-invariant: A property where the output does not depend on the ordering of input elements. "by enforcing permutation-invariant embedding prediction."
- Point cloud: A set of 3D points representing scene geometry without explicit connectivity. "Moreover, multi-view point maps are defined in canonical world coordinates, preserving the same global geometry as point clouds."
- Point map: A 2D grid where each pixel stores its corresponding 3D coordinate, preserving geometry while matching image-like input. "Point maps encode explicit 3D coordinates on a structured 2D grid, preserving global 3D geometry while remaining compatible with the input format of 2D foundation models."
- POMA-3D: The proposed self-supervised model that learns 3D scene representations from point maps. "In this paper, we introduce POMA-3D, the first self-supervised 3D representation model learned from point maps."
- POMA-JEPA: The paper’s JEPA variant tailored to point maps, enforcing multi-view geometric consistency. "we introduce POMA-JEPA, a joint embedding-predictive architecture that enforces geometrically consistent point map features across multiple views."
- R@M-N (Recall@N): Retrieval metric denoting the probability the correct item is in the top-N when composing queries from M texts. "The metric R@M-N denotes recall@N for retrieving the correct 3D scene from M referring texts."
- Scene retrieval: Selecting the correct 3D scene from a database given a language description. "including 3D question answering, embodied navigation, scene retrieval, and embodied localization"
- Visual grounding: Linking language expressions to specific objects or regions in a visual scene. "Early 3D understanding models were specialist, targeting specific 3D tasks such as instance segmentation~\cite{jiang2020pointgroup,hou20193d}, visual grounding~\cite{chen2020scanrefer,achlioptas2020referit3d}, or visual question answering (QA)~\cite{azuma2022scanqa,ma2022sqa3d}."
- Vision–Language Learning (VLL): Training paradigms that align visual and textual modalities to transfer semantic priors. "3D vision-language learning (VLL) provide them through contrastive objectives without relying on downstream annotations."
- ViT-B/16: A Vision Transformer variant (Base, 16-pixel patch size) used as the vision backbone. "The vision encoders are ViT-B/16 from FG-CLIP-Base~\cite{xie2025fg}."
- Voxelized patch aggregation: Converting 3D data into voxel patches to aggregate features for transformer-based models. "LLaVA-3D~\cite{zhu2024llava} extends 2D visual instruction tuning to 3D via voxelized patch aggregation"
- Zero-shot: Performing tasks without task-specific fine-tuning by leveraging aligned multimodal representations. "This cross-modal alignment enables 3D encoders to inherit rich knowledge from 2D counterparts, enabling zero-shot tasks such as object classification, retrieval, and detection~\cite{liu2023openshape, xue2023ulip, mao2024opendlign, zhou2023uni3d, xue2024ulip, qi2024shapellm}."
Collections
Sign up for free to add this paper to one or more collections.