- The paper introduces interleaved reasoning, an RL-based technique that alternates between thinking and answering, reducing time-to-first-token by over 80%.
- The paper demonstrates a 12.5% improvement in Pass@1 accuracy using conditional intermediate rewards to mitigate error propagation.
- The paper shows that interleaved reasoning decreases response token length by up to 37%, streamlining multi-hop question solving with enhanced efficiency.
Interleaved Reasoning for LLMs via Reinforcement Learning
Standard approaches to enhancing the reasoning capability of LLMs depend on chain-of-thought (CoT) prompting, where models generate the entire reasoning trace before emitting a final answer. This paradigm presents two significant bottlenecks: first, it leads to high time-to-first-token (TTFT) due to the strictly sequential nature of thought and answer, rendering LLMs sluggish for interactive use; second, it exacerbates issues in RL-based optimization, since errors in early reasoning propagate forward and the delayed reward impairs credit assignment, resulting in inefficiencies and error accumulation.
The paper introduces interleaved reasoning—a training paradigm using reinforcement learning to induce LLMs to alternate between "thinking" and "answering" phases. This approach can be viewed as decomposing multi-hop question answering into a sequence of intermediate sub-answers, each finalized when the model has high confidence, and each producing independent, verifiable reward signals.

Figure 1: Comparison between the standard think-answer CoT and interleaved reasoning, emphasizing TTFT and the structure for credit assignment.
Methodology
The authors reformulate multi-hop reasoning tasks as trajectories interleaving internal thoughts ("thinking" segments) and explicit intermediate responses ("answer" segments), leveraging a templated instruction format and RL-driven credit assignment. The key design principle is to provide structured, user-facing sub-answers, each immediately after a solvable sub-problem is resolved, yielding improved transparency and efficiency.
Interleaved reasoning is instantiated via RL over trajectories with three reward components: format reward (structure adherence), final accuracy reward (final answer correctness), and a conditional intermediate reward (sub-answer correctness). Notably, simple rule-based reward schemes suffice for all credit signals—no neural reward models or process-based reward annotation are required. Intermediate rewards are applied conditionally, only when the model demonstrates primary skill and responsiveness, to encourage early correct steps without inducing local-optima overfitting.
Experimental Results
Extensive empirical validation is carried out on five datasets: K&K (Knights and Knaves), Musique, MATH, GPQA, and MMLU, using multiple RL algorithms (PPO, GRPO, REINFORCE++) and two LLM scales (Qwen2.5 1.5B/7B). The baselines include direct inference, classic CoT, supervised fine-tuning, and RL-trained think-answer methods.
The results reveal several critical findings:
- Efficiency: Interleaved reasoning reduces TTFT by over 80% compared with think-answer reasoning, facilitating immediate, incremental feedback in interactive deployments.
- Accuracy: The proposed conditional intermediate reward scheme yields a 12.5% average improvement in Pass@1 accuracy over conventional RL think-answer methods, and these gains hold across in-domain and out-of-domain evaluation.
- Reasoning Length: Total response token length is reduced by up to 37%, with successful samples consistently shorter—suggesting more direct problem-solving, less overthinking, and reduced irrelevant exploration.
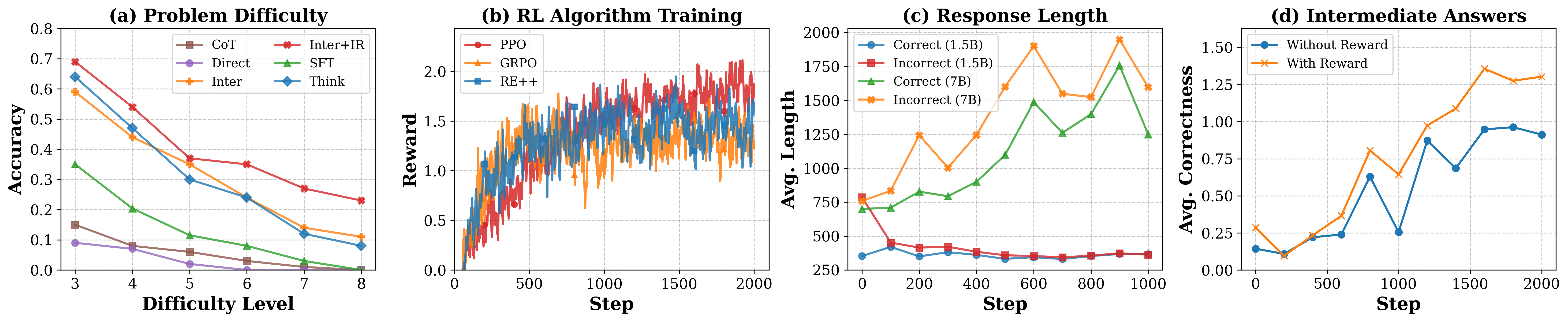
Figure 2: (a) Pass@1 accuracy gap versus difficulty, (b) RL algorithm convergence, (c) length versus correctness, (d) impact of intermediate rewards on step-wise accuracy.
Intermediate sub-answers are shown to have high information sufficiency—external LLMs can infer the final answer from them with 94% accuracy, significantly above random CoT snippets. This demonstrates that the model is not simply producing superficial or arbitrary sub-steps, but indeed meaningful, verifiable conclusions.
Analysis and Insights
The interleaved paradigm exhibits several important characteristics:
- Scalability: The advantage of interleaved reasoning widens as task difficulty increases, notably on harder logical reasoning problems, due to better error localization and robust credit signal propagation.
- RL Stability and Sample Efficiency: While PPO yields the most stable and highest final accuracy, GRPO and REINFORCE++ are more sample efficient but less robust to hyperparameters.
- Reward Engineering: Naive, always-on intermediate rewards can degrade final task performance due to premature local optimization and misaligned credit assignment—a result consistent with reward-hacking phenomena. Conditional (gated) rewards based on batch-level curriculum are necessary for maximizing both intermediate and final answer quality.
- Generalization: Training solely on datasets with intermediate labels, models generalize effectively to tasks with no accessible intermediate ground truth or supervision, demonstrating high transferability and the potential for rapid scaling across domains.
- Timeliness: Timely, incremental feedback is essential—delaying all intermediate answers until after the final thought trace (as in delayed CoT) erases the accuracy and TTFT gains, despite identical reward signals.
Implications and Future Outlook
Practical: Interleaved reasoning systematically improves both efficiency and accuracy for LLMs in user-facing, multi-step tasks. This makes these models more viable for interactive assistants, agentic workflows, or high-latency-sensitive applications without reliance on external tool augmentation or slow, unwieldy CoT traces.
Theoretical: By structuring RL optimization around explicit, early, and verifiable intermediate conclusions, interleaved reasoning advances solution interpretability, enables finer-grained credit assignment, mitigates error propagation, and supports research into process reward modeling without the complexity, fragility, or annotation load of existing PRMs.
Future Developments: Scaling interleaved reasoning to larger architectures, more complex domains, and incorporating confidence-indexed reward signals or automatic intermediate annotation/supervision are promising avenues. Additionally, integrating process-level rewards with curriculum learning and program induction could yield further advances in LLM agent viability, robustness, and adaptability.
Conclusion
This study demonstrates that LLMs are inherently capable of interleaving step-wise reasoning and user-facing answers, and that RL-based training with simple, conditional reward structures leads to marked improvements in both accuracy and downstream efficiency. Tightly aligning model reward structure with the stepwise nature of complex reasoning tasks yields a substantive reduction in TTFT and response length with simultaneous generalization to out-of-domain settings. The interleaved paradigm provides a scalable foundation for the next generation of LLM reasoning systems and agentic AI.

