- The paper introduces Logic-RL, a novel approach that augments LLM reasoning through rule-based reinforcement learning with synthetic logic puzzles.
- The methodology employs a modified REINFORCE++ algorithm with KL loss integration to ensure stable convergence and mitigate reward hacking.
- Empirical results show that Logic-RL significantly boosts model performance on both controlled logic puzzles and challenging mathematical benchmarks like AIME and AMC.
Logic-RL: Unleashing LLM Reasoning with Rule-Based Reinforcement Learning
Abstract
The paper introduces "Logic-RL," a novel framework aimed at enhancing the reasoning capabilities of LLMs through rule-based reinforcement learning (RL). The approach is inspired by DeepSeek-R1 and leverages synthetic logic puzzles for controlled training and evaluation. Key features include a system prompt emphasizing reflection, verification and summarization, technical enhancements for stable RL training, and remarkable cross-domain generalization to mathematical benchmarks such as AIME and AMC.
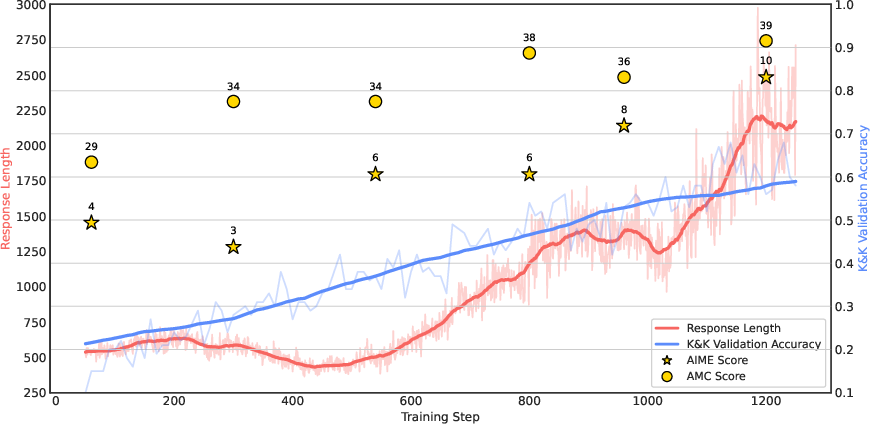
Figure 1: Validation accuracy and mean response length during RL training, illustrating autonomous compute allocation for improved reasoning.
Introduction
Recent advancements in post-training reinforcement techniques have demonstrated the emergent reasoning capabilities of LLMs. Models like DeepSeek-R1 introduced simple rule-based reinforcement without complex scaffolding like MCTS or PRMs. Logic-RL further investigates these emergent capabilities in smaller-scale models using controlled logic puzzles as training data. Despite the procedural generation’s simplicity, it enables detailed reasoning analysis and has shown promising generalization to complex mathematics benchmarks.
Methodology
Data Synthesis
The Knights and Knaves logic puzzle dataset serves as the foundation for training, characterized by:
- Procedural Generation: Ensures consistent variability and difficulty modulation by adjusting character numbers and logical complexity.
- Controlled Difficulty Levels: Customizable complexity levels allow structured curriculum learning.
- Ease of Verification: Simple ground truth answers facilitate accurate reward evaluation, minimizing reward hacking risks.
Rule-Based Reward Modeling
Rewards in the RL framework are bifurcated into:
- Format Reward: Enforces output structure within designated tags, mitigating potential reward hacking tactics.
- Answer Reward: Assesses content accuracy against ground truth, with varied penalties for partial or incorrect answers.
Reinforcement Learning Algorithm
Adopts a modified REINFORCE++ paradigm with enhancements such as KL loss integration to strengthen learning dynamics and address high variability, demonstrating stable convergence across training iterations. The practical training regimen includes constant learning rates and temperature settings to ensure balanced complexity exposure.
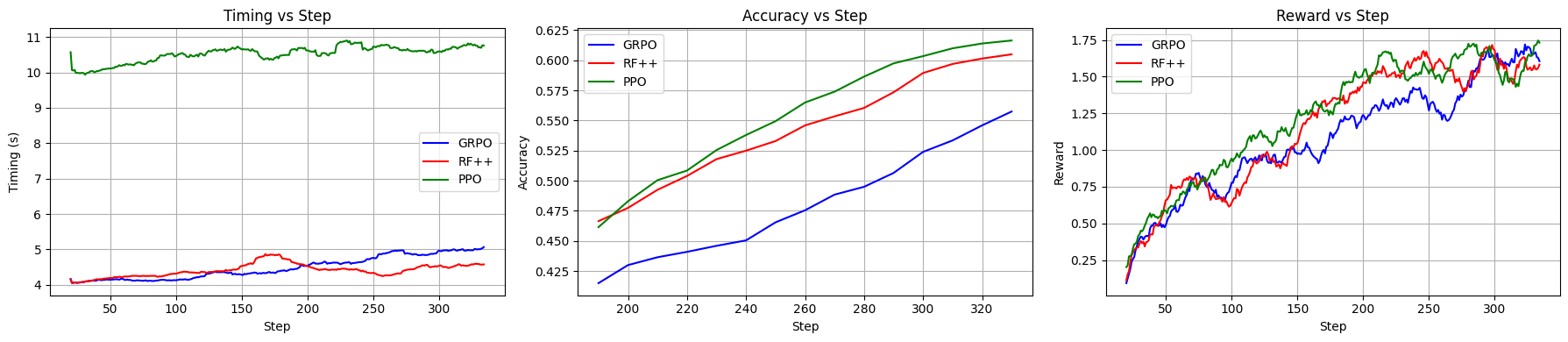
Figure 2: GRPO (Blue), REINFORCE++ (Red), and PPO (Green) performance comparison.
Experimentation and Results
Extensive testing across multiple LLM configurations, including Qwen2.5 series, validated model robustness beyond intradomain logic puzzles to out-of-distribution scenarios like AIME and AMC benchmarks, where the trained model exhibited exceptional generalization.
Emergent Reasoning Behaviors
Logic-RL promotes self-initiated advanced reasoning behaviors seldom found in baseline models, including:
- Hesitation and Self-Verification: Encourages reflective reconsideration, raising reasoning accuracy.
- Multi-Path Exploration: Model conducts simultaneous solution testing, resembling human strategic thinking.
- Formula Application: Emergence of formal logical reasoning without explicit training adjustments.
Conclusion
Logic-RL effectively enhances reasoning abilities in LLMs by structuring training around procedurally generated logical datasets. The emergent reasoning skills successfully translate into increased generalization over mathematical problem sets, suggesting RL-trained models achieve deeper abstract reasoning capabilities. Future endeavors should extend investigation to more diverse and complex datasets to ascertain scalable efficacy across broader domains.

