- The paper introduces an adaptive CogER framework that stratifies queries into four complexity levels for tailored reasoning.
- The framework models strategy allocation as an MDP and uses Group Relative Policy Optimization to balance accuracy with efficient compute usage.
- The integration of Cognitive Tool-Assisted Reasoning (CoTool) enables selective external tool use, achieving notable EM gains across benchmarks.
Cognitive-Inspired Elastic Reasoning for LLMs
The computational cost of LLM inference grows substantially with model scale and context length, yet end-user queries span a broad complexity distribution. Traditional approaches employ uniform reasoning pathways for all inputs, ignoring the efficiency-accuracy trade-off presented by trivial versus demanding queries. The predominant paradigm, inspired by dual-process theory, frames LLM reasoning as “fast” (direct answers) or “slow” (full chain-of-thought) modes, but lacks dynamic adaptation to unobservable query difficulty, resulting in wasted resources or inadequate reasoning depth.
The paper introduces Cognitive-Inspired Elastic Reasoning (CogER), a framework for per-query adaptive routing informed by cognitive science. CogER decomposes queries into four complexity levels (L1–L4), each associated with tailored inference strategies: direct answer, light reasoning, multi-step reasoning, or tool-augmented reasoning. This stratification, reminiscent of Bloom’s Taxonomy, enables cost-optimized allocation of reasoning resources and addresses the challenges of difficulty estimation and dynamic compute scaling.
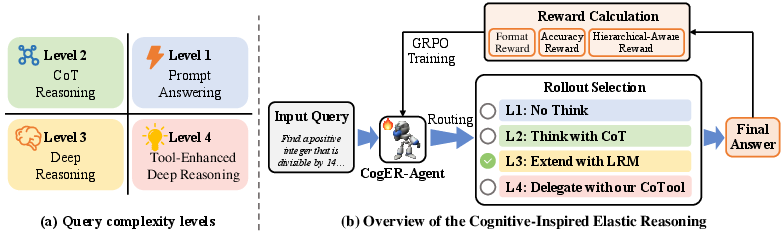
Figure 1: (a) Query complexity levels. (b) Overview of the CogER. Given an input query, the CogER-Agent selects a complexity level (L1−L4) and routes it to the corresponding reasoning strategy, including direct answering, light to multi-step reasoning, and Cognitive Tool-Assisted Reasoning. The CogER-Agent is trained via GRPO with a composite reward that combines Format Reward R.
CogER: Architecture and Training
Query Complexity Assessment. Incoming queries are classified by a policy network (CogER-Agent) into four complexity levels, with each level mapped to a reasoning strategy: immediate output (L1, No Think), chain-of-thought using a moderate LLM (L2, Think), extended chain-of-thought via a LRM (L3, Extend), and tool-augmented inference (L4, Delegate with CoTool). The classification draws on heuristics inspired by educational psychology, operationalized in prompts and explicit tags for each query.
Markov Decision Process Formulation. The dynamic allocation of reasoning strategies is modeled as an episodic MDP, where the state encodes the query, reasoning history, and predicted complexity; the action space comprises both generation and high-level reasoning strategies; and the reward balances answer accuracy, format correctness, and penalizes unnecessary compute via a hierarchical-aware term.
Reinforcement Learning and Objective. The CogER-Agent is trained with Group Relative Policy Optimization (GRPO), a PPO-style variant that employs normalized groupwise advantage for improved credit assignment over sampled outputs. The reward signal integrates format compliance, answer accuracy, and penalizes over-utilization of higher cognitive levels, explicitly guiding the policy toward minimal sufficient computation.
For L4 queries exceeding in-model knowledge or requiring verification/calculation, the system integrates an orchestrated tool-calling mechanism called CoTool. Here, the LLM autonomously decides when to issue tool queries (e.g., search API, calculator, or code execution), leverages parser-generated scaffolding, integrates tool responses, and resumes step-wise generation with enriched context. The CoTool mechanism is robust, with strict constraints on invocation count and interplay with reasoning turns to prevent tool overuse and manage resource caps.
Practically, CoTool supports arbitrary function calls for knowledge, computation, and code execution by wrapping tool queries and outputs within explicit tokens and bridging the gap between internal knowledge and external APIs.
Empirical Evaluation
CogER is benchmarked on a spectrum of in-domain (GSM8K, MATH, CommonsenseQA, MedQA) and out-of-domain (MAWPS, CollegeMath) tasks. Strong numerical outcomes are reported:
- In-domain (ID): CogER achieves a 13% relative improvement in average EM versus SOTA TTS baselines and nearly 10% versus the strongest LLM baseline. Specific gains include 84.52% EM on Com-QA and 81.23% on MedQA.
- Out-of-domain (OOD): CogER yields an 8% relative gain in EM, surpassing both regular LLMs and the best adaptive test-time scaling methods. Notably, on the difficult CollegeMath benchmark, the EM improvement over hierarchical LLM ReasonFlux-32B is 13.21%.
Crucially, these accuracy gains are obtained with a sharp reduction in average parameters employed, end-to-end latency (by up to 76.58% compared to DeepSeek-R1), and output length. Ablation shows that RL-driven routing outperforms both random and supervised classifier-based dispatch and that both hierarchical and format-based reward terms are critical for robust, balanced policy learning. Tool invocation is observed to be judicious: CoTool achieves a notable improvement (11.24% EM on MATH) with <6% actual tool invocation rate, evidencing efficient tool integration and minimal overhead.
Theoretical and Practical Implications
The work demonstrates that formulating reasoning resource control as an MDP and adopting complexity-aware dispatch produces dual benefits: simultaneously minimizing unnecessary computation and maximizing answer reliability for complex queries. The explicit policy learning approach sidesteps the need for brittle heuristics, instead assigning computation adaptively based on learned representations of query difficulty.
Introducing explicit cognitive stratification (beyond the traditional “fast/slow” dichotomy) lays a foundation for future AI systems capable of granular, data-driven metareasoning. The robust empirical gains across datasets and substantial compute savings position CogER as a practical solution for real-world deployment, where cost, latency, and reliability are paramount.
The successful integration of external tools points to a future in which LLMs fluidly bridge model-based reasoning with declarative access to symbolic knowledge, computation, and action, further blurring the lines between language modeling and agentic problem solving.
Limitations and Future Directions
CogER, while comprehensive in single-turn, text-only settings, is not directly evaluated for interactive or multimodal scenarios such as vision-language or dialogue contexts. The sparseness of reward signals for complex reasoning steps could inhibit policy optimization in tasks requiring deep, creative synthesis. Extending the framework with multi-objective reward learning, richer feedback (including human preference), and generalization to continuous, multi-modal task settings are compelling avenues for further research. Additionally, better alignment and avoidance of “reward hacking” in creative tasks remain important open challenges.
Conclusion
The CogER framework substantiates the efficacy of adaptive, cognitive-inspired meta-reasoning for LLMs, substantiating strong gains in efficiency and accuracy via explicit complexity-level-aware reasoning orchestration and robust RL-based policy learning. The principled use of tool integration further augments the versatility and reliability of reasoning on complex, knowledge- or computation-intensive queries. This paradigm defines a scalable pathway for large-scale AI deployment in production settings, as well as motivates further work on combining learned reasoning policies, external knowledge, and agentic action.

