Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics
Abstract: Despite chain-of-thought (CoT) playing crucial roles in LLM reasoning, directly rewarding it is difficult: training a reward model demands heavy human labeling efforts, and static RMs struggle with evolving CoT distributions and reward hacking. These challenges motivate us to seek an autonomous CoT rewarding approach that requires no human annotation efforts and can evolve gradually. Inspired by recent self-evolving training methods, we propose \textbf{RLCER} (\textbf{R}einforcement \textbf{L}earning with \textbf{C}oT Supervision via Self-\textbf{E}volving \textbf{R}ubrics), which enhances the outcome-centric RLVR by rewarding CoTs with self-proposed and self-evolving rubrics. We show that self-proposed and self-evolving rubrics provide reliable CoT supervision signals even without outcome rewards, enabling RLCER to outperform outcome-centric RLVR. Moreover, when used as in-prompt hints, these self-proposed rubrics further improve inference-time performance.
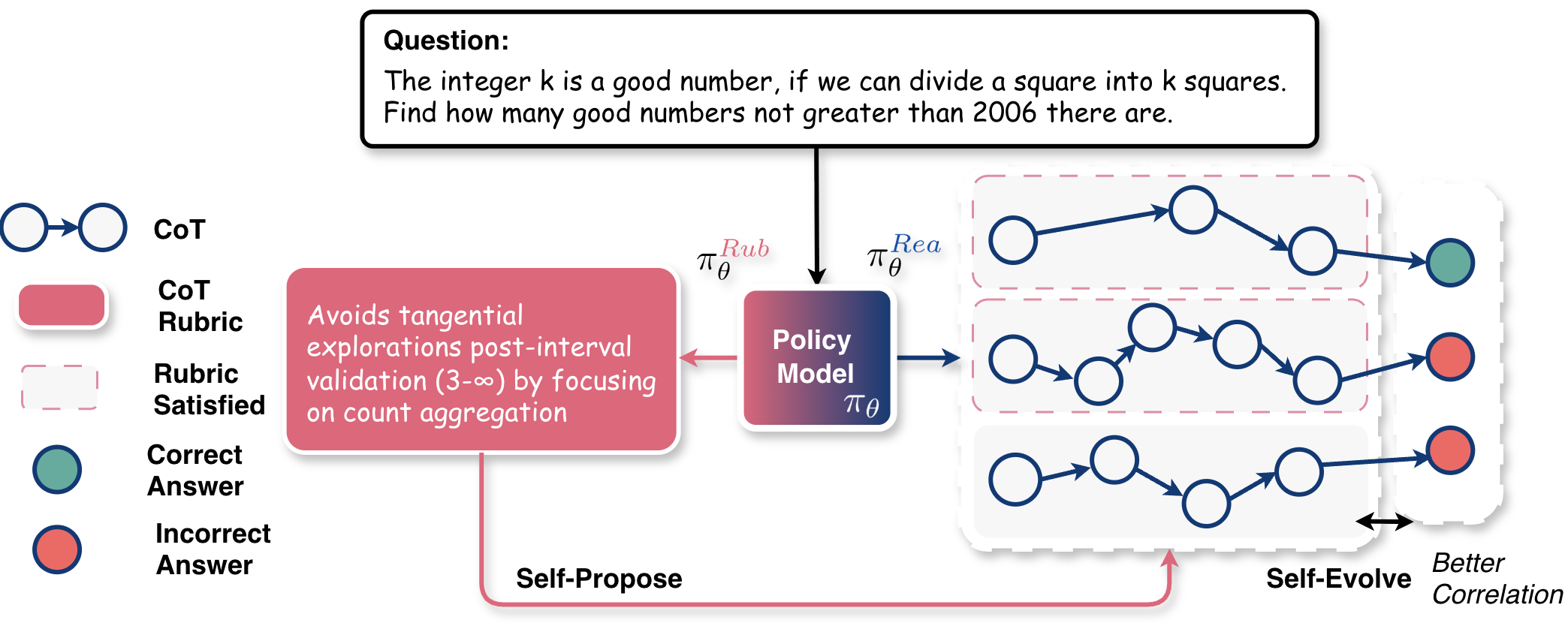
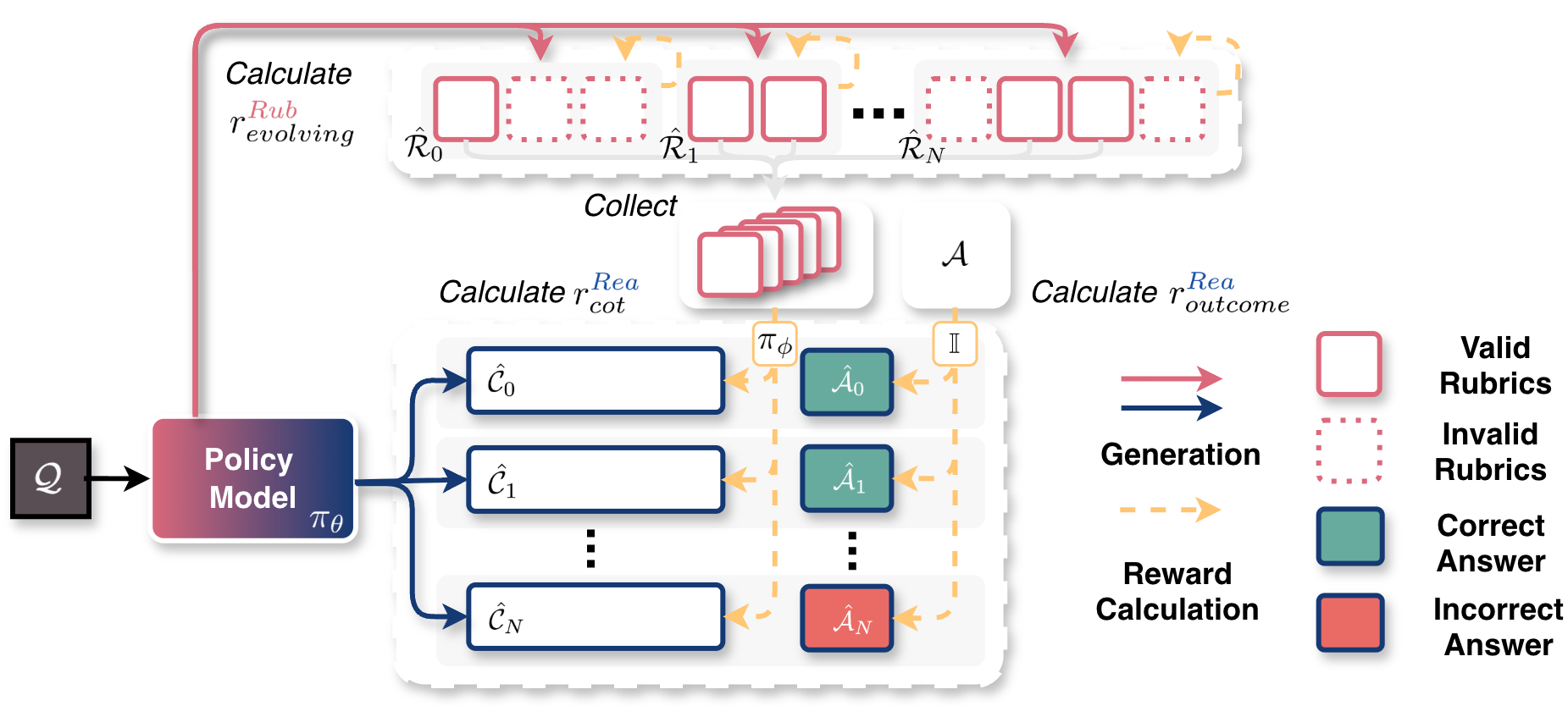
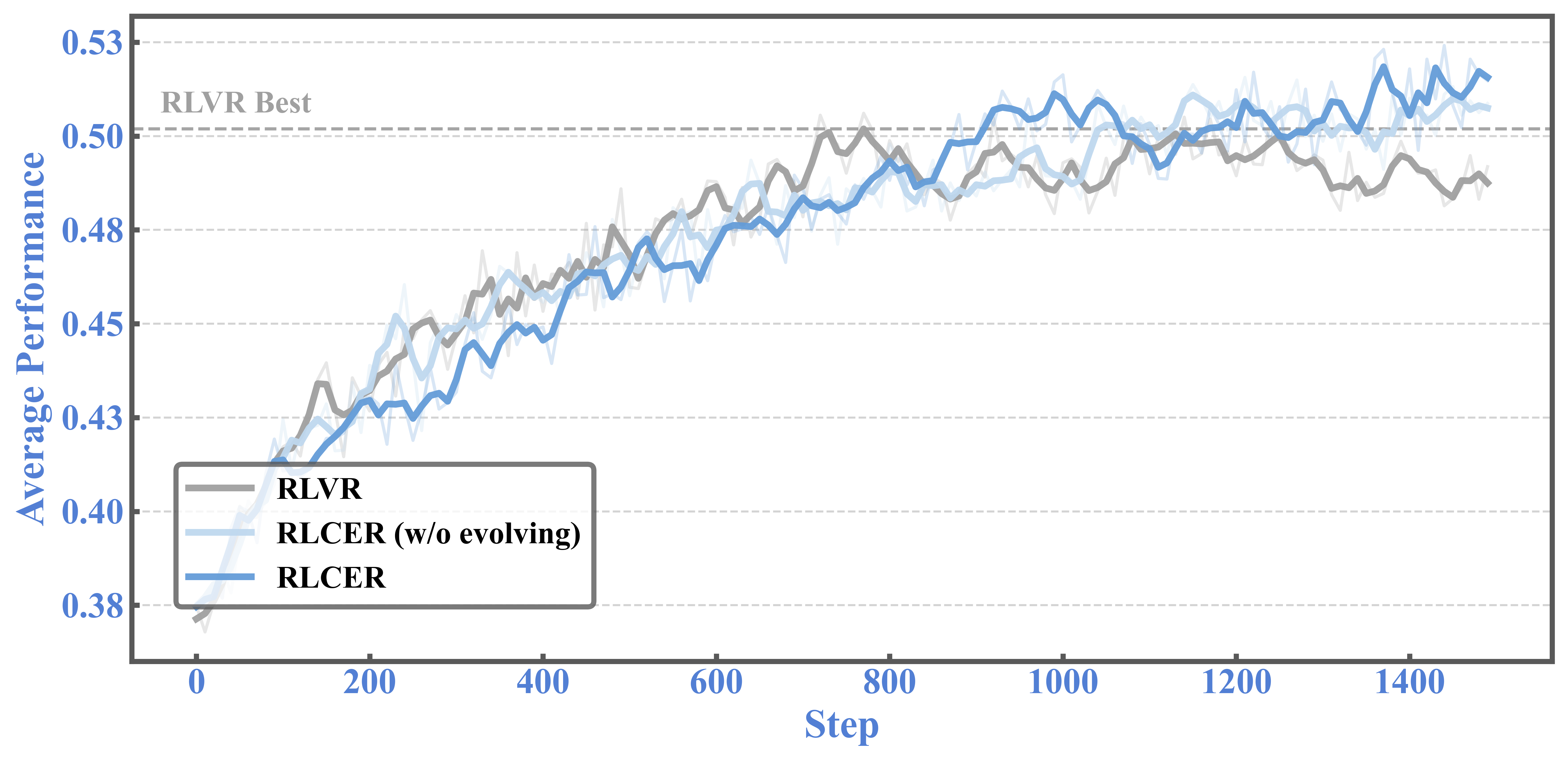
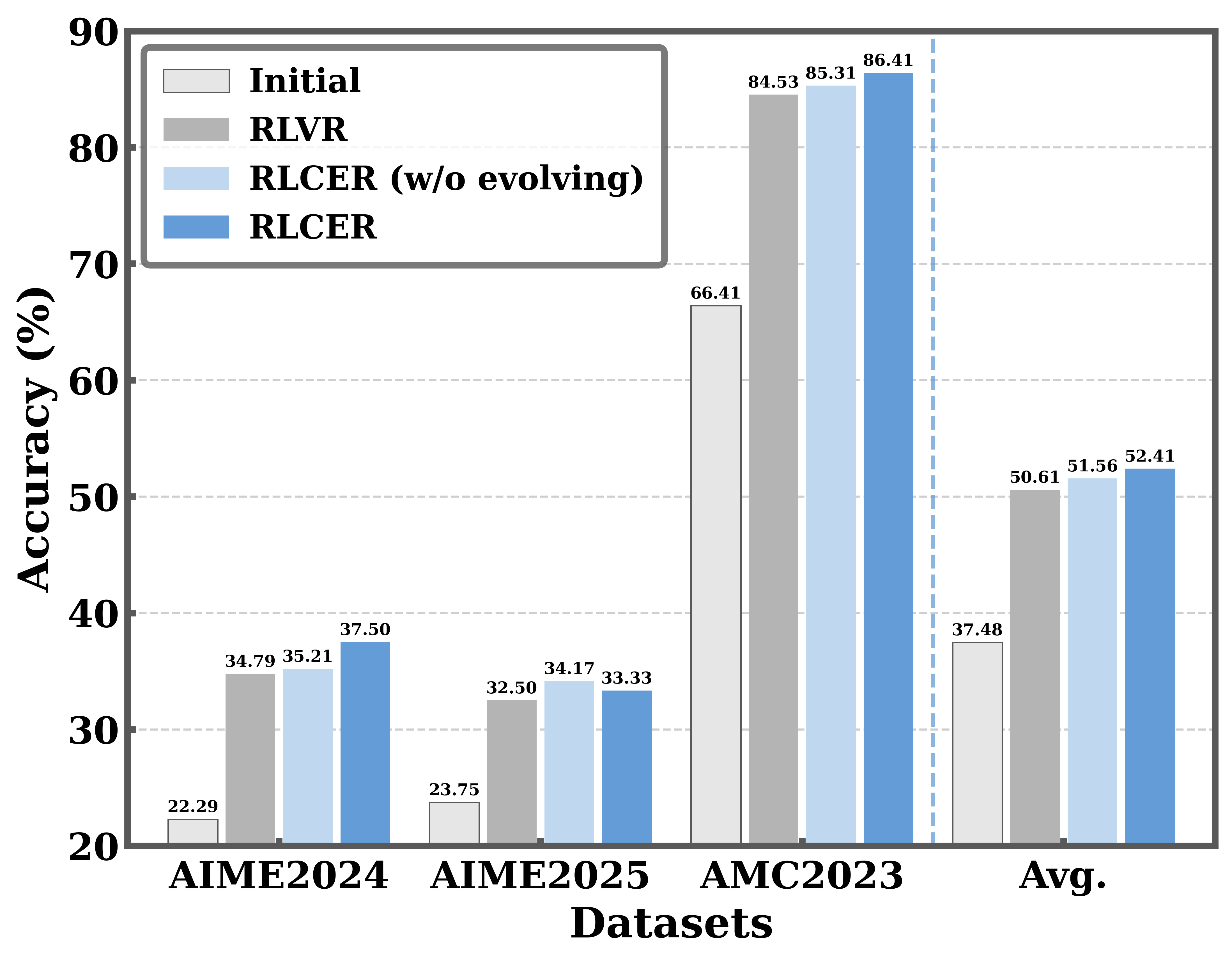
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about teaching AI models to “think better,” not just to “get the right answer.” It focuses on chain-of-thought (CoT) reasoning, which is like showing your work step by step in math or explaining your reasoning in words. The authors introduce a new training method called RLCER that lets an AI make its own checklists (called rubrics) for good thinking, use those checklists to judge its own reasoning, and improve those checklists over time—all without needing humans to write the rules.
Key questions the paper asks
The researchers wanted to find out:
- Can an AI create helpful rules (rubrics) that guide its own step-by-step reasoning?
- Will rewarding good reasoning steps (not just correct final answers) make the AI think more clearly and reliably?
- Can these self-made rules get better over time as the AI trains?
- Do these rules help even when used as hints during problem solving?
How did they do it?
To make this simple, think of the AI playing two roles—like being both a student and a teacher:
- The “student” role (called the reasoner) solves problems and writes its chain of thought (its steps and final answer).
- The “teacher” role (called the rubricator) writes rubrics—plain-language rules or checklists for what good reasoning looks like (for example, “check your assumptions,” “don’t go off-topic,” or “verify each calculation”).
Here’s the training idea in everyday terms:
- The student solves a problem and shows its steps.
- The teacher creates a set of rubrics (rules). Each rubric can be “checked” on the student’s solution by a separate judge model (a verifier).
- A rubric is considered a “good” rule if following it is often linked with getting the right answer. In simple words: if students who follow this rule more often get the problem right, it’s probably a useful rule. The paper measures this with correlation: stronger correlation means a better rule.
- The student is rewarded in two ways:
- Outcome reward: Did it get the final answer right?
- Process reward: Did its chain of thought satisfy the valid rubrics?
- The teacher is also rewarded: the more of its proposed rubrics turn out to be “valid” (strongly linked to correct answers and not trivially satisfied), the bigger the reward. This pushes the teacher to improve and propose better rules next time.
- Over time, both roles improve: the student learns to think better, and the teacher learns to write better rubrics. This is why they call it “self-evolving rubrics.”
Analogy:
- Imagine a class where students learn not just by grading the final answer, but also by grading their work steps using a checklist. Now imagine the class itself figures out which checklist items are actually helpful, and keeps updating the checklist as everyone learns. That’s what this system does—automatically.
Main findings and why they matter
Here are the main results the paper reports:
- Rewarding the chain of thought works: Even when they only rewarded the reasoning steps (without using the final answer reward), the AI’s accuracy improved over time. This shows the rubrics provide useful guidance.
- RLCER beats standard training: Compared to a common method that only rewards correct final answers (often called RLVR), RLCER (which rewards both final answers and good reasoning steps) achieved higher scores on multiple math and general knowledge benchmarks.
- Self-evolving rubrics help: When the AI was rewarded for proposing rubrics that truly relate to getting correct answers, the rubrics became more informative over time. This led to better reasoning and more stable learning.
- Rubrics help at inference time too: Using these rubrics as hints in the prompt (like giving the student the checklist before solving) boosted performance further. It’s like handing students a smart study guide that was learned automatically.
Why it matters:
- The AI isn’t just trying to be right—it’s learning how to think clearly. That makes it more reliable, less likely to use shortcuts, and better at tough problems.
- Because the rubrics are generated by the model itself, this reduces the need for humans to write detailed rules, saving time and effort.
- The approach shows a path toward AI systems that can improve their own thinking strategies, not just their answers.
Implications and impact
In simple terms:
- This could lead to AI that explains itself better and reasons more like a careful student—checking steps, avoiding detours, and verifying work.
- It points to a future where AI can invent and refine its own learning rules, making training more scalable and less dependent on human labels.
- The rubrics can be reused as helpful tips during problem solving, which may improve real-world performance.
Limitations to keep in mind:
- Training takes longer because the AI is doing extra work (making and checking rubrics).
- The paper mostly tests tasks where answers can be automatically checked (like math). Using this method in open-ended tasks (where there isn’t a clear right answer) still needs more research.
Overall, this research suggests a powerful idea: if we teach AI “how to think” using self-made and self-improving checklists, we can get better results than just grading “what it answers.”
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, organized to help future researchers take action.
- Verifier training and reliability are unspecified: how
π_φis trained, on what data, with what objective, and its accuracy/robustness in judging rubric satisfaction across domains and CoT styles. - No sensitivity analysis to verifier quality: the method’s dependence on
π_φ(e.g., if the verifier is weak or biased) and how errors propagate to rubric validity and policy updates are unexamined. - Binary satisfaction from the verifier may be too coarse: the impact of using graded/continuous rubric satisfaction (vs 0/1) on learning stability and performance is not studied.
- Validity criterion lacks statistical rigor: the choice of correlation threshold
α = 0.2, the correlation metric used (Pearson/phi/Spearman), sample size per question (N), and multiple-testing control acrossKrubrics are not justified or ablated. - Potential spurious correlations: with small
Nper question, rubric validity may be noisy; no analysis of false positives/negatives in rubric validity decisions or confidence intervals on correlations. - Reward hacking risks remain: the rubricator or reasoner could learn to propose/shape rubrics that are trivially satisfiable or exploit verifier quirks; no defenses (e.g., anti-leakage constraints, adversarial checks) are evaluated.
- Degenerate rubric design is not prevented: no mechanism/analysis to avoid tautological rubrics (e.g., “include token X”) or rubrics that key off superficial features rather than reasoning quality.
- Role interference is unaddressed: sharing a single set of parameters for reasoner and rubricator may cause gradient interference; no exploration of separate heads, adapters, or orthogonal optimization to mitigate cross-role conflicts.
- Reward weighting is ad hoc:
r_outcomein [-1, 1] is simply added to normalized CoT reward in [0,1]; the relative scaling/weighting and its impact on training dynamics are not studied. - Negative rubric scores (
ŝ_k < 0) and normalization are under-specified: how min/max are computed with mixed-sign weights per question, and whether normalization yields stable gradients, is not analyzed. - Sensitivity to key hyperparameters is missing: number of rubrics
K, rolloutsNper question, temperature,α, correlation metric, clippingε, and rubric importance scoring are not ablated. - Scalability and compute costs are not quantified: the rollout burden from two roles, additional verifier calls, long response lengths (e.g., max 20,480 tokens), and total training/inference costs are not reported or optimized.
- Generalization beyond verifiable tasks is open: rubric validity is tied to outcome verifiers; methods to adapt RLCER to non-verifiable/open-ended domains (e.g., with preferences, weak signals, or self-consistency) are not explored.
- Limited baselines: comparisons against process reward models (e.g., PRM8K, PRIME) and other self-rewarding methods (e.g., SRLM, SPIN) are absent, making it unclear if RLCER offers advantages over established process-supervision approaches.
- Statistical rigor of evaluation is lacking: no confidence intervals, significance tests, or multi-seed runs; rolling averages are reported without variance or reproducibility checks.
- Rubrics-as-hints are not dissected: which rubric types (e.g., error-avoidance vs planning) help most, the optimal number
K, selection strategies (top-importance vs diverse), and prompt formatting choices are not evaluated. - Rubric semantics and evolution are opaque: no qualitative/quantitative analysis of rubric diversity, novelty, redundancy, drift over training, or alignment with human-understandable reasoning principles.
- Difficulty calibration is missing: evolving rubrics appear to reduce CoT rewards over time; mechanisms to adapt rubric difficulty (curriculum, annealing) to avoid over-challenging the reasoner are not studied.
- Transfer to larger/finer-tuned models is unknown: results are limited to 4B/8B; behavior, stability, and gains for 30B–70B+ models are untested.
- Domain transfer of the verifier and rubrics is unclear: the same
π_φand rubric generation prompts may not generalize to non-math reasoning (e.g., GPQA); cross-domain calibration is not assessed. - Formatting failures and parser robustness are not quantified: rate of rubric parse errors and how format reward reduces real-world ingestion failures remain unmeasured.
- Safety/ethics considerations are unaddressed: self-evolved rubrics could encode biased or unsafe criteria; no safeguards or audits of rubric content.
- CoT style effects are unmeasured: impacts on CoT length, diversity, step validity, or error-type reduction are not reported; it is unclear how reasoning behavior changes qualitatively.
- Data leakage and contamination checks are missing: no discussion of training/test leakage (especially with teacher-assisted SFT) or verifier exposure to test distributions.
- Cold-start dependency is underexplored: success relies on SFT via reject sampling from a stronger teacher; the minimal cold-start requirements and robustness without such assistance are not studied.
Practical Applications
Practical Applications of “Reinforcing Chain-of-Thought Reasoning with Self-Evolving Rubrics (RLCER)”
Below are concrete applications derived from the paper’s findings, methods, and innovations. They are grouped by deployment horizon and reference applicable sectors, likely tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- Application: Plug-in module for RLVR training on verifiable tasks (math, code, data QA)
- Sectors: Software/AI, Education
- What it does: Augments existing RL with verifiable rewards (e.g., math answer checking, unit tests) by adding self-generated, self-evolving rubrics that reward CoT quality; improves robustness and final accuracy.
- Tools/Workflows: “Rubricator” role prompt + PPO/DAPO trainer; external verifier for rubric satisfaction; correlation-based rubric selection; logging and normalization utilities.
- Assumptions/Dependencies: Availability of a verifiable outcome signal (tests, exact answer matching); an SFT cold-start to ensure role-following; compute capacity for multi-rollout sampling and rubric generation.
- Application: Inference-time “rubrics as hints” to boost performance without retraining
- Sectors: Education (math prep, tutoring), Daily-life assistants, Software/AI
- What it does: Inserts top-K self-generated rubrics into prompts to steer reasoning at test time; empirically improves pass@1 and BoN on reasoning tasks.
- Tools/Workflows: Prompt preprocessor that fetches or generates rubrics conditioned on question and early CoT; budget-aware prompt length manager.
- Assumptions/Dependencies: Sufficient context window; rubric quality generalizes to the task; minimal prompt injection risk.
- Application: Internal QA gates that check “how” the model reasoned (process QA)
- Sectors: Software/AI, Business Intelligence/Analytics
- What it does: Uses rubrics to automatically judge whether reasoning followed key steps (e.g., source grounding, numerical checks) before accepting outputs.
- Tools/Workflows: Verifier microservice scoring rubric satisfaction; CI/CD guardrails for LLM apps; auto-retry when rubrics are not satisfied.
- Assumptions/Dependencies: Domain-specific rubric templates; a reliable verifier model; controllable latency overhead.
- Application: Reduced dependence on human-labeled process reward models (PRMs)
- Sectors: Software/AI, Academia
- What it does: Replaces or complements static PRMs with self-evolving rubrics, cutting annotation costs and tracking distribution shifts during training.
- Tools/Workflows: RLCER trainer; rubric validity monitor; scheduled re-validation with correlation filtering.
- Assumptions/Dependencies: High-quality verifier of rubric satisfaction; careful thresholding (e.g., α for correlation) to avoid reward hacking.
- Application: Code reasoning enhancement with unit-test-linked rubrics
- Sectors: Software Engineering
- What it does: Encourages step-by-step debugging, specification checking, and edge-case exploration with rubrics, combined with pass/fail unit tests.
- Tools/Workflows: Runner for unit tests; rubric generator specialized on code reasoning patterns; CoT reward normalization.
- Assumptions/Dependencies: Executable environments; reliable mapping between rubric satisfaction and eventual test outcomes.
- Application: RAG system grounding checks via rubrics
- Sectors: Knowledge Management, Enterprise AI
- What it does: Applies rubrics like “cite retrieved evidence,” “avoid speculation,” and “triangulate across sources” to constrain reasoning before final answer.
- Tools/Workflows: Rubrics referencing retrieved chunks; evidence-verifier (e.g., string match/embedding-based checks); gating before response finalization.
- Assumptions/Dependencies: Access to retrieval metadata; acceptable false-positive/negative rates in evidence verification.
- Application: Math tutoring with transparent, adaptive checklists
- Sectors: Education
- What it does: Generates task-specific rubrics/checklists (e.g., validate domain, show substitution) shown to students as hints; improves learning transparency.
- Tools/Workflows: Student-facing UI that surfaces rubrics; teacher dashboard to review rubrics and control hinting.
- Assumptions/Dependencies: Content safety; appropriate difficulty calibration; alignment with curricula.
- Application: Agentic workflows with rubric-based step gating
- Sectors: Automation/Agents, Robotics (software-level), Ops
- What it does: Before advancing stages (plan → gather → reason → act), require rubric satisfaction (e.g., “constraints compiled,” “risks enumerated”).
- Tools/Workflows: Orchestrator that requests rubric scores at stage boundaries; failure recovery logic; audit logs.
- Assumptions/Dependencies: Well-defined stage-specific rubrics; tolerance for extra tokens/latency.
- Application: Research instrumentation for reasoning analysis
- Sectors: Academia/AI Evaluation
- What it does: Uses correlation-filtered rubrics to diagnose and compare CoT quality across models and training regimes; yields interpretable error analyses.
- Tools/Workflows: “Rubric Validity Monitor” dashboard; rollouts+correlation pipelines; dataset of valid rubrics and satisfaction traces.
- Assumptions/Dependencies: Multi-sample rollouts per question; compute and storage budget for logs.
Long-Term Applications
- Application: Process supervision in non-verifiable domains via proxy verifiers
- Sectors: General AI, Creative/Knowledge Work
- What it does: Extends RLCER to tasks without hard verifiers using strong LLM-judges or weak signals (consistency, citations) as proxies for correctness.
- Tools/Workflows: Judge ensembles; uncertainty-aware correlation thresholds; active learning to refine proxy verifiers.
- Assumptions/Dependencies: Reliability and bias control of LLM judges; robustness against reward hacking and spurious correlations.
- Application: Safety alignment with self-evolving safety rubrics
- Sectors: Policy/Compliance, Platform Safety
- What it does: Maintains dynamic safety checklists (e.g., leak avoidance, harmful content avoidance) whose satisfaction correlates with safety outcomes; shapes reasoning paths.
- Tools/Workflows: Safety rubric library; red-teaming pipelines; governance dashboards tracking rubric validity over time.
- Assumptions/Dependencies: High-precision safety verifiers; cross-domain generalization; human oversight for fail-safe operation.
- Application: Clinical decision support with outcome-linked checklists
- Sectors: Healthcare
- What it does: Evolves clinical reasoning rubrics (e.g., differential diagnosis completeness, guideline adherence) correlated with measured outcomes or expert panels.
- Tools/Workflows: Offline retrospective trials; EHR-integrated auditing; staged deployment with human-in-the-loop.
- Assumptions/Dependencies: Access to de-identified outcome data; strict regulatory approvals; rigorous bias and safety evaluations.
- Application: Financial risk analysis and underwriting rubrics
- Sectors: Finance/FinTech
- What it does: Guides due diligence (data completeness, assumptions disclosure, scenario testing) with rubrics correlated to realized defaults/returns.
- Tools/Workflows: Backtesting on historical portfolios; audit logs for regulators; rubric-based gating for credit proposals.
- Assumptions/Dependencies: High-quality historical labels; compliance constraints (model risk management); explainability requirements.
- Application: Legal research and drafting with precedent-grounded rubrics
- Sectors: LegalTech
- What it does: Enforces rubrics such as “cite controlling authority,” “distinguish adverse precedent,” “fact consistency,” improving reliability and auditability.
- Tools/Workflows: Case law retrieval integration; citation verifiers; drafting assistants with rubric-hinting.
- Assumptions/Dependencies: Up-to-date legal databases; jurisdictional nuance; professional oversight.
- Application: Robotics/task planning with rubric-shaped rewards
- Sectors: Robotics/Autonomy
- What it does: Uses checklists (pre-conditions satisfied, safety margins met, state estimation validated) as process rewards correlated with task success.
- Tools/Workflows: Simulator-first training; sensor-data verifiers; hybrid CoT + control stack.
- Assumptions/Dependencies: Reliable success metrics; sim-to-real transfer; latency constraints for on-robot inference.
- Application: Multi-role self-evolving systems (planner, reasoner, critic, rubricator)
- Sectors: Advanced AI Systems
- What it does: Generalizes the 2-role design to richer multi-agent roles under one policy; co-trains roles with role-specific rewards.
- Tools/Workflows: Role-specific prompts and rewards; stability-aware training schedulers; curriculum design.
- Assumptions/Dependencies: Training stability at scale; avoidance of emergent collusion or degenerate strategies.
- Application: Compliance-grade audit trails for process transparency
- Sectors: RegTech, Enterprise AI
- What it does: Stores signed CoTs, rubric sets, satisfaction vectors, and outcome scores for explainability, reproducibility, and audits.
- Tools/Workflows: Immutable logs (e.g., WORM storage); lineage tracking; privacy-preserving CoT redaction.
- Assumptions/Dependencies: Data governance policies; legal acceptance of process evidence; secure infrastructure.
- Application: Sector standards and shared “rubric libraries”
- Sectors: Standards Bodies, Industry Consortia
- What it does: Curates validated rubrics for domains (safety, model risk management, education) and publishes versioned libraries with benchmarks.
- Tools/Workflows: Open repositories; continuous validation suites; certification programs.
- Assumptions/Dependencies: Community buy-in; IP/licensing clarity; periodic re-validation to avoid drift.
- Application: Personalized education with adaptive rubrics and coaching
- Sectors: EdTech
- What it does: Learner-specific rubrics that evolve with mastery profiles to guide step-by-step reasoning and provide formative feedback.
- Tools/Workflows: Student modeling; learning analytics; teacher controls for scaffolding.
- Assumptions/Dependencies: Privacy-preserving telemetry; equity considerations; content alignment.
- Application: On-device/edge variants for privacy-sensitive settings
- Sectors: Mobile/IoT, Healthcare/Finance (edge sites)
- What it does: Lightweight rubricator and verifier components that run locally, enabling process supervision without cloud data sharing.
- Tools/Workflows: Distilled judge models; token/latency budgets; hardware-aware schedulers.
- Assumptions/Dependencies: Efficient model architectures; acceptable performance trade-offs.
- Application: Scientific discovery and formal reasoning aids
- Sectors: Science/Academia
- What it does: Rubrics that encode proof discipline, experimental design checks, and error analysis; correlation with formal verifiers or replication success.
- Tools/Workflows: Integration with proof assistants; experiment simulators; lab notebook-style audit trails.
- Assumptions/Dependencies: Access to formal tools; ground-truth signals (proof checkers, replication data); domain expertise in-the-loop.
Cross-cutting assumptions and risks to monitor
- Verifier quality is pivotal: rubric satisfaction must be judged reliably; weak verifiers can induce reward hacking or spurious correlations.
- Compute costs: multi-rollout sampling and rubric generation increase tokens and time; careful budgeting and batching are required.
- Data shifts: rubrics can become stale; the self-evolving mechanism should run periodically with monitoring (correlation, discriminativeness).
- Safety and privacy: revealing CoT may expose sensitive reasoning; implement redaction and access controls.
- Governance: in regulated sectors, rubrics and process supervision need validation, documentation, and auditability to meet compliance requirements.
Glossary
- AIME24: A math reasoning benchmark from the American Invitational Mathematics Examination 2024. "For math reasoning, we evaluate math-reasoning benchmarks including AIME24 \cite{AIME}, AIME25 \cite{AIME}, and AMC23 \cite{aimo_amc_2023}."
- AIME25: A math reasoning benchmark from the American Invitational Mathematics Examination 2025. "For math reasoning, we evaluate math-reasoning benchmarks including AIME24 \cite{AIME}, AIME25 \cite{AIME}, and AMC23 \cite{aimo_amc_2023}."
- AlphaZero: A self-play reinforcement learning framework demonstrating self-evolving capabilities without human intervention. "self-evolving training methods \cite{self-evolving-survey, AlphaZero}"
- AMC23: A math competition benchmark (AMC 2023) used to evaluate reasoning. "For math reasoning, we evaluate math-reasoning benchmarks including AIME24 \cite{AIME}, AIME25 \cite{AIME}, and AMC23 \cite{aimo_amc_2023}."
- Advantage (policy-gradient): The estimated relative value of actions used to guide policy updates in reinforcement learning. "role-specific advantages $\hat{A}^{\text{\textcolor{reasoner}{$Rea$}_t$ and $\hat{A}^{\text{\textcolor{rubricator}{$Rub$}_t$"
- Best-of-N (BoN): An evaluation strategy selecting the best answer from N samples to improve accuracy. "Additionally, the performance of BoN (N=16) improved even further on the AIME datasets"
- Chain-of-thought (CoT): The explicit step-by-step reasoning process generated by an LLM to solve complex tasks. "Chain-of-thought (CoT) \cite{CoT} reasoning is essential for LLMs to solve complex tasks"
- Clipping hyperparameter: The parameter ε controlling the clipping range in PPO-style objectives to stabilize training. "and is the clipping hyperparameter (e.g., $0.2$)."
- Cold-start: Initializing a model to follow instructions by supervised fine-tuning before reinforcement learning. "We first cold-start the pre-trained models (i.e., Qwen3-8B-Base and Qwen3-4B-Base)"
- CoT reward: A reward signal based on how well the generated reasoning steps satisfy rubrics. "The CoT reward is computed by aggregating the scores of the satisfied rubrics:"
- DAPO: A training method/dataset used to set binary outcome rewards in math reasoning tasks. "Following DAPO \cite{DAPO}, we assign a binary outcome reward"
- DAPO-Math-17k: A 17k-question math dataset used for training reinforcement learning models. "We train models based on the DAPO-Math-17k dataset \cite{DAPO}"
- Distribution shift: A change in the model’s output distribution during training that can bias supervision. "the policy’s CoT distribution shifts during training, yielding non-stationary and potentially biased supervision."
- Format reward: A reward enforcing that rubric outputs follow a required parseable format. "Additionally, to ensure the proposed rubrics can be stably parsed, we reward the rubricator with a format reward"
- GPQA-Diamond: A challenging general knowledge reasoning benchmark subset of GPQA. "For general knowledge reasoning, we evaluate on GPQA-Diamond \cite{GPQA}"
- GRPO: Group Relative Policy Optimization, a training scheme unsuitable here due to differing contexts. "It is worth noting that GRPO is unsuitable for our algorithm"
- LiveCodeBench: A benchmark for code execution tasks used to provide verifiable rewards. "code execution \cite{LiveCodeBench}"
- LLMs: LLMs capable of generating text and reasoning chains. "Chain-of-thought (CoT) \cite{CoT} reasoning is essential for LLMs to solve complex tasks"
- Min–max normalization: Scaling values to [0, 1] based on minimum and maximum attainable scores. "conducts the min–max normalization as "
- Multi-agent reinforcement learning: Training where multiple roles interact to improve learning signals. "via techniques such as multi-agent reinforcement learning \cite{AbsoluteZero}"
- Multi-role RL framework: A reinforcement learning setup where one policy is prompted to play multiple roles. "we introduce two key roles in the multi-role RL framework for optimization"
- Outcome-centric RLVR: A training paradigm optimizing only for final-answer correctness without supervising the reasoning process. "most RLVR training remains outcome-centric and provides no direct supervision over the CoT itself"
- Outcome reward: A reward based solely on whether the final answer matches the ground truth. "The CoT reward $r_{cot}^{\text{\textcolor{reasoner}{$Rea$}$ can be used as an auxiliary reward alongside the outcome reward"
- Pass@1: An accuracy metric indicating the fraction of correct first attempts among sampled responses. "We report pass@1 as the accuracy metric (i.e., the average pass rate among 16 responses)."
- Policy likelihood ratio: The ratio between new and old policy probabilities used in PPO-style objectives. "where is the policy likelihood ratio between and $\pi_{\theta_{\text{old}$ at step "
- Policy-gradient objective: The optimization objective that updates a policy using gradients of expected rewards. "and use them to update the policy via a standard policy-gradient objective."
- Reasoner: The role of the policy that generates the reasoning chain and final answer. "The reasoner answers the question by generating a CoT and a final answer ."
- Reject sampling: A data filtering approach that discards low-quality outputs from a teacher model. "obtained via reject sampling from a stronger teacher model"
- Reinforcement Learning with CoT Supervision via Self-Evolving Rubrics (RLCER): The proposed method that rewards reasoning steps with self-generated rubrics. "we propose RLCER (Reinforcement Learning with CoT Supervision via Self-Evolving Rubrics)"
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL paradigm using task-specific verifiers to reward correct outcomes. "reinforcement learning with verifiable rewards (RLVR) \cite{DeepSeekMath, O1, Deepseek-R1}"
- Reward hacking: Exploiting the reward function to gain rewards without genuinely solving the task. "static RMs struggle with evolving CoT distributions and reward hacking."
- Reward model (RM): A learned model that assigns process-level rewards, typically requiring human annotations. "training additional reward models (RMs) for CoT supervision typically requires labor-intensive and fine-grained annotations"
- Rollout: A sampled trajectory consisting of the reasoning chain and final answer for a given question. "Rollout. Given a question , the policy model attempts to solve it by generating a response"
- Rubricator: The role of the policy that generates rubrics used to evaluate CoT quality. "Rubricator $\pi_{\theta}^{\text{\textcolor{rubricator}{$Rub$}$."
- Rubrics: Structured, checkable evaluation criteria used to assess output or reasoning quality. "Here, rubrics are structured, checkable evaluation criteria (i.e., explicit requirements for assessing outputs)"
- Rubrics satisfaction indicator: A binary signal denoting whether a CoT satisfies a specific rubric. "its satisfaction indicator is strongly correlated with final-answer correctness "
- Rubrics self-evolving: Continually improving rubric-generation quality based on correlation with correctness. "we further propose to self-evolve the rubric generation capability"
- Sampling temperature: A parameter controlling randomness in generation during evaluation. "For each testing question, we sample =16 responses with sampling temperature as 0.7."
- Self-evolving training: Methods where a single model improves by generating data and rewards without human labels. "Inspired by recent self-evolving training methods"
- Self-play: A training approach where a model learns by interacting with itself to generate training signals. "Recent work has made progress via self-training and self-play"
- SFT (Supervised Fine-Tuning): Training on labeled data to align a model with instructions before RL. "Here, both RLCER and RLVR start from the SFT checkpoint."
- SuperGPQA: A large general knowledge reasoning benchmark, with subsets across domains. "For the large size of SuperGPQA, we evaluate on three subsets, each including 100 questions, namely SuperGPQA-Eng, SuperGPQA-Med, and SuperGPQA-Sci."
- Verifier: An auxiliary model that judges rubric satisfaction for a given CoT. "Additionally, a verifier is used for judging the satisfaction of rubrics"
- Verifiable tasks: Problems with objective checks (e.g., math, puzzles, code) used for outcome rewards. "trained on verifiable tasks such as math problems \cite{AIME}, puzzle solving \cite{ARC-AGI-2}, and code execution \cite{LiveCodeBench}"
- Valid rubrics: Rubrics that correlate with correct answers and are discriminative across different CoTs. "a rubric is considered valid if it is informative as a rewarding criterion"
Collections
Sign up for free to add this paper to one or more collections.

