- The paper introduces a novel dual-reward RL tuning framework that integrates Thinking and Judging rewards to improve reasoning quality in MLLMs.
- It employs a two-stage pipeline—Chain-of-Thought supervised fine-tuning and RL tuning—achieving state-of-the-art results on multimodal reasoning benchmarks.
- The dual-reward system reduces hallucinations and adapts reasoning depth based on task complexity, enhancing both robustness and efficiency.
SAIL-RL: Dual-Reward RL Tuning for Adaptive Reasoning in Multimodal LLMs
Introduction
SAIL-RL introduces a reinforcement learning (RL) post-training framework for Multimodal LLMs (MLLMs) that explicitly addresses two persistent limitations in current RL-tuned MLLMs: (1) the lack of supervision over the reasoning process, and (2) the inefficiency of uniform reasoning strategies across tasks of varying complexity. The framework is built on a dual-reward system—Thinking Reward and Judging Reward—enabling models to learn both when to engage in deep reasoning and how to produce sound, coherent reasoning traces. This approach is implemented atop the SAIL-VL2 architecture, yielding SAIL-VL2-Thinking, which demonstrates state-of-the-art performance on both reasoning and general multimodal understanding benchmarks at the 8B scale.
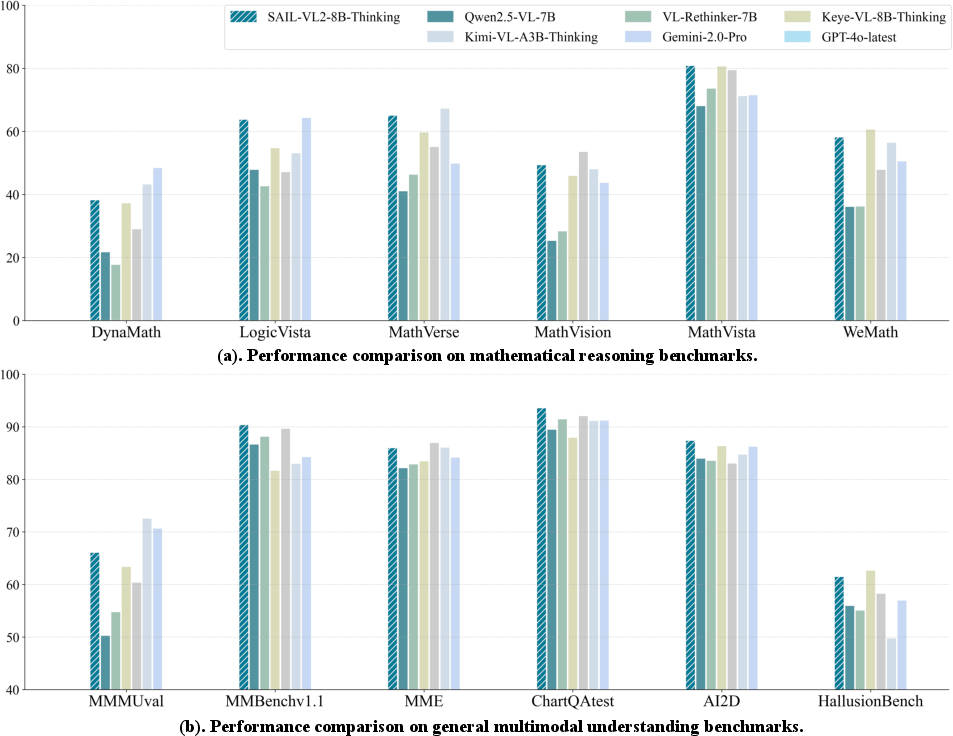
Figure 1: SAIL-VL2-Thinking outperforms open-source baselines and is competitive with closed-source models on both general understanding and mathematical reasoning benchmarks.
Limitations of Conventional RL-Tuned MLLMs
Traditional RL post-training for MLLMs relies on outcome-only supervision, rewarding models solely for correct answers. This paradigm fails to penalize flawed or hallucinated reasoning, leading to two critical issues: (1) models may produce correct answers via spurious or logically inconsistent reasoning, and (2) uniform reasoning strategies result in overthinking on simple tasks and underthinking on complex ones. These behaviors compromise both robustness and efficiency.

Figure 2: Current MLLMs may reach correct answers through flawed reasoning (left) or apply unnecessarily complex reasoning to simple problems, resulting in errors (right).
SAIL-RL Framework and Dual-Reward System
SAIL-RL is structured as a two-stage post-training pipeline: (1) Chain-of-Thought (CoT) augmented supervised fine-tuning (SFT), and (2) RL tuning with a multi-dimensional reward system. The dual-reward system comprises:
- Thinking Reward: Evaluates the reasoning trace for factual grounding, logical coherence, and answer consistency. Each dimension is scored by a judge model (Gemini), and the aggregate reward is the mean of the three binary scores.
- Judging Reward: Incentivizes the model to decide whether a question requires deep reasoning or can be answered directly, based on ground-truth complexity labels.
The total reward is a cascading product of Judging, Thinking, and Answer rewards, regularized by a format compliance term. This logical AND-gate formulation ensures that only responses with correct judgment, sound reasoning, and correct answers are rewarded, mitigating reward hacking and reinforcing robust cognitive processes.

Figure 3: SAIL-RL's reward system evaluates responses across Format, Answer, Thinking, and Judging dimensions, with semantic rewards provided by Gemini.
Implementation Details
Data Curation
- LongCoT SFT Dataset: 400K samples, unified in a judge-think-answer format, curated from diverse sources and filtered for redundancy, correctness, and reasoning complexity.
- RL Dataset: 100K samples, balanced between 50K STEM problems and 50K general QA, reformatted to free-response and filtered for optimal difficulty.
Training Protocol
- SFT Stage: Full-parameter fine-tuning for one epoch on LongCoT data, sequence length up to 20K, batch size 1024, learning rate 1e-6.
- RL Stage: Three epochs of RL using DAPO, sequence length 20K (16K input, 4K output), batch size 256, learning rate 1e-6, 5 rollouts per sample, dynamic PPO clipping ε∈[0.20,0.28], KL regularization removed.
Empirical Results
Reasoning and Multimodal Understanding Benchmarks
SAIL-VL2-8B-Thinking achieves an average score of 59.3 on multimodal reasoning benchmarks, surpassing all open-source models and outperforming closed-source models such as GPT-4o and Gemini-2.0-Pro on several tasks. On general multimodal understanding, it attains an average score of 80.8, with notable improvements in hallucination reduction and chart comprehension.
Ablation Studies
- Thinking Reward: Yields a +1.3% average gain across eight benchmarks, with significant improvements on multi-step reasoning tasks. Training dynamics show consistent improvement in logic, consistency, and hallucination metrics, whereas answer-only reward baselines stagnate or degrade.
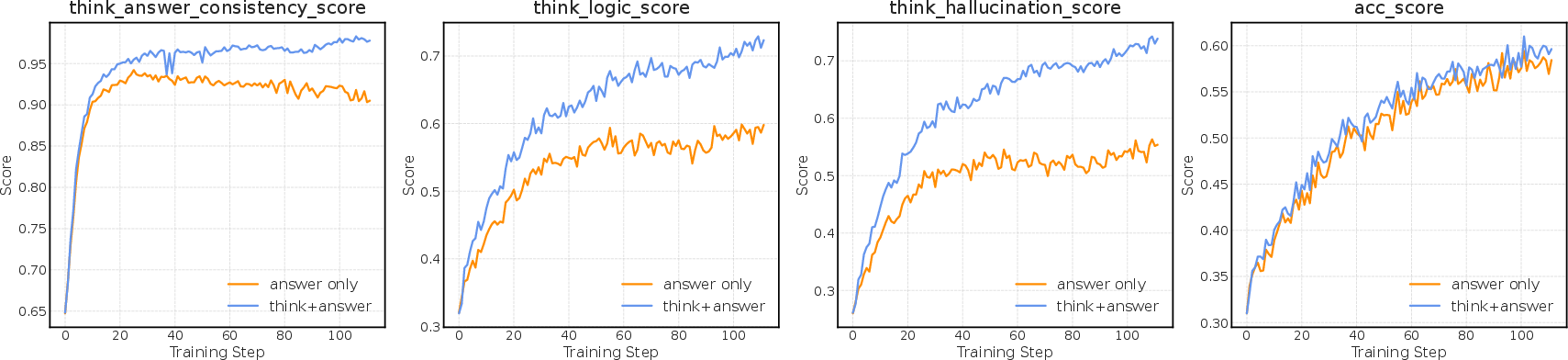
Figure 4: Training dynamics demonstrate that the thinking reward consistently improves logic, consistency, and hallucination scores over the answer-only baseline.
- Judging Reward: Delivers a +0.6% average gain, with efficiency gains concentrated in perception-heavy tasks. The model dynamically adjusts its reasoning trigger rate, activating deep reasoning only when necessary.

Figure 5: On an OCR task, the Judge Reward enables the model to bypass unnecessary reasoning, avoiding hallucinations and improving accuracy.
Case Studies
Practical and Theoretical Implications
SAIL-RL establishes a principled framework for post-training MLLMs, directly addressing the limitations of outcome-only supervision and static reasoning strategies. The dual-reward system enforces a strong coupling between sound reasoning and correct answers, while adaptively allocating cognitive resources. This results in models that are both more reliable and efficient, with reduced hallucinations and improved performance on complex reasoning tasks.
From a practical perspective, SAIL-RL's reward system can be integrated into existing RLHF pipelines for MLLMs, leveraging LLM-based judge models for reward computation. The cascading product reward formulation is robust against reward hacking and can be extended to other domains requiring process-level supervision. The adaptive reasoning strategy is particularly beneficial for deployment in resource-constrained environments, where efficiency is critical.
Theoretically, SAIL-RL advances the field by formalizing the supervision of reasoning quality and adaptivity, paving the way for future research on meta-cognitive skills in MLLMs. The framework's modularity allows for the incorporation of additional reward dimensions, such as interpretability or fairness.
Future Directions
Potential avenues for future work include scaling SAIL-RL to larger model sizes, exploring more granular reward dimensions (e.g., step-wise reasoning trace evaluation), and integrating human-in-the-loop feedback for reward calibration. Further research may investigate the transferability of the dual-reward system to other modalities and tasks, as well as its impact on long-term generalization and robustness.
Conclusion
SAIL-RL introduces a dual-reward RL post-training framework that significantly enhances the reasoning capabilities and efficiency of MLLMs. By supervising both the quality and adaptivity of reasoning, SAIL-RL achieves state-of-the-art results among open-source models and competitive performance with leading closed-source systems. The framework provides a scalable and principled approach for building more reliable, adaptive, and efficient multimodal LLMs.


