Language Models that Think, Chat Better
Abstract: Reinforcement learning with verifiable rewards (RLVR) improves LLM reasoning by using rule-based rewards in verifiable domains such as mathematics and code. However, RLVR leads to limited generalization for open-ended tasks -- such as writing outline essays or making meal plans -- where humans reason routinely. This paper shows that the RLVR paradigm is effective beyond verifiable domains, and introduces RL with Model-rewarded Thinking (RLMT) for general-purpose chat capabilities. Using diverse real-world prompts, RLMT requires LMs to generate long CoT reasoning before response, and optimizes them with online RL against a preference-based reward model used in RLHF. Across 40 training runs on Llama-3.1-8B and Qwen-2.5-7B (both base and instruct) and multiple optimization algorithms (DPO, PPO, and GRPO), RLMT consistently outperforms standard RLHF pipelines. This includes substantial gains of 3-7 points on three chat benchmarks (AlpacaEval2, WildBench, and ArenaHardV2), along with 1-3 point improvements on other tasks like creative writing and general knowledge. Our best 8B model surpasses GPT-4o in chat and creative writing and rivals Claude-3.7-Sonnet (Thinking). RLMT can also be applied directly to base models without an SFT stage, akin to R1-Zero training. Remarkably, with only 7K prompts, Llama-3.1-8B base trained with our RLMT recipe outperforms Llama-3.1-8B-Instruct post-trained with a complex multi-staged pipeline with 25M+ examples. We close with qualitative and quantitative analyses of how trained models plan their responses. Our results rethink the post-training pipeline and call upon future work to understand and employ thinking more broadly.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explain-it-like-I'm-14: “LLMs that Think, Chat Better”
What is this paper about?
This paper is about teaching AI chatbots to “think” before they answer—like showing their work on a test—so they can handle everyday questions and conversations better, not just math and code. The authors introduce a training method called RLMT (Reinforcement Learning with Model-rewarded Thinking) that makes LLMs write out a plan or chain of thought first, then give the final answer. They show this makes chatbots noticeably better at chatting, writing, and following instructions.
What questions are the researchers trying to answer?
- Can we get AI to think step-by-step (not just in math) for open-ended tasks like chatting, writing, and planning?
- Will this kind of thinking help more than standard methods that don’t require thinking out loud?
- Can this work even with small models and little training data?
- Which training strategies and “reward judges” work best?
How did they do it? (Methods in everyday language)
Think of training an AI like training a student:
- Standard approach (RLHF): The student answers a question; a coach (a “reward model” trained from human preferences) gives a score; the student learns to answer in ways people like. This does not require “showing work.”
- Math-focused approach (RLVR): The student solves math or code; the teacher can check if the final answer passes a test (right/wrong). This encourages showing work but only in subjects with clear answers.
This paper combines the best of both:
- RLMT: The AI must first write a “reasoning trace” (its step-by-step thinking), then produce the final answer. A coach (a reward model trained on human judgments) scores the final answer. So the model practices “showing its work” on everyday tasks, not just math.
Key parts of their setup:
- Reasoning first: Models are required to generate a long chain of thought before responding.
- Reward model as judge: They use a strong, publicly available judge called Skywork to score answers by preference (what people would prefer).
- Real-world prompts: They train on a small but diverse set of about 7,000 realistic chat prompts (e.g., from WildChat), which better reflect what people actually ask.
- Two starting options:
- Warm start: First teach the model the “thinking format” with supervised examples (from teacher AIs like Gemini or GPT-4.1-mini), then do RLMT.
- Zero start: Skip that step entirely; just give the model a template and train with RLMT from scratch.
- Training algorithms: They tried three coaching styles (DPO, PPO, GRPO). GRPO worked best overall, but the method helped with all three.
Simple analogy:
- Imagine a writing class where students must outline ideas, group themes, note constraints (like tone or word count), refine, and then produce the final essay. A skilled coach grades how good the essay is (not whether it’s “correct”), and the student learns to plan and write better over time.
What did they find, and why does it matter?
Main takeaways:
- Thinking helps a lot for chat: Models trained to think before answering scored 3–7 points higher on major chat tests (AlpacaEval2, WildBench, ArenaHardV2) than standard methods that skip the thinking step.
- Better writing and knowledge use: They also improved by 1–3 points on creative writing and general-knowledge tasks.
- Small models can punch above their weight: Their best 8B-parameter model beat much larger open-source models and even outperformed GPT-4o on key chat and writing benchmarks.
- Less data, better results: With only about 7,000 training prompts, their “Zero” setup (no initial supervised fine-tuning) made a base Llama-3.1-8B model outperform a heavily post-trained Llama-3.1-8B-Instruct created using 25+ million examples.
- Not just math: “Thinking models” trained only on math don’t generalize well to chat. RLMT—thinking with a preference-based judge—works far better for open-ended conversations.
- GRPO is strong: Among the training algorithms, GRPO consistently gave the best results, though the thinking approach helped with DPO and PPO too.
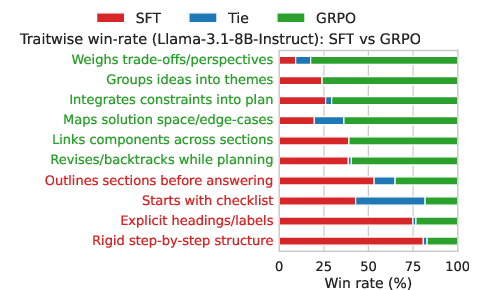
- The model’s thinking style improved: After training, the model started listing constraints, grouping themes, and iteratively refining plans—more like how good writers plan their work.
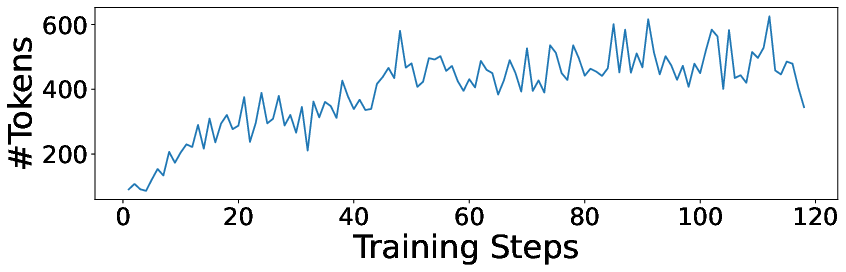
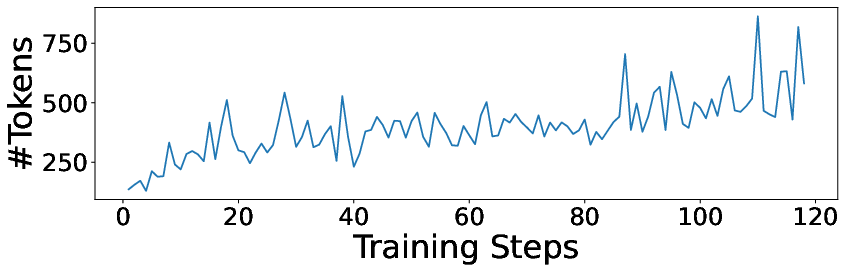
- The model learned to think longer: Over training, both the reasoning and the final answers grew longer and more thorough.
Why this matters: Everyday AI use is mostly open-ended (chatting, planning, writing, explaining). Getting models to “show their work” in these areas leads to clearer, more thoughtful, and more helpful answers.
What could this change in the future? (Implications)
- Rethinking the training pipeline: You may not need massive datasets or complicated multi-stage processes to get great chat models. Teaching models to think with a good judge and realistic prompts can be enough—even from a base model.
- Quality over quantity: The choice of prompts and the quality of the reward model matter a lot. Good, “chatty” prompts and a strong judge yield better improvements.
- Better everyday assistants: Expect more helpful planning, clearer writing, and more careful reasoning in AI assistants for tasks like emails, outlines, study plans, and creative projects.
- Research directions: Understand which kinds of thinking help which tasks, build better reward models (judges), and explore safe, robust ways to encourage thinking without making answers too long or off-topic.
- Open resources: The authors release code and models, making it easier for others to build and test thinking-based chatbots.
In short: Making AI “think first, answer second,” and rewarding it based on human preferences—not just right/wrong answers—can make chat models smarter, clearer, and more useful in everyday life.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of concrete gaps and open questions the paper leaves unresolved. Each item is phrased to enable actionable follow-up by future researchers.
- Sensitivity to reward model choice and training data
- Quantify how RLMT outcomes change across diverse reward models (architectures, training corpora, rubrics), beyond Skywork (v1/v2) and ArmoRM—especially under domain shift and adversarial prompts.
- Diagnose and measure reward hacking specific to “thinking style” (e.g., verbosity, template compliance, checklist artifacts) versus genuine quality improvements in responses.
- Establish principled criteria for selecting or combining reward models (multi-reward, ensemble, uncertainty-aware RM) for open-ended chat.
- Evaluation reliability and judge bias
- Provide human evaluation (with inter-rater agreement) to corroborate LLM-as-a-judge results on AE2, WildBench, ArenaHardV2, and CreativeWriting, and quantify judge biases toward explicit reasoning or longer outputs.
- Audit length-control procedures and their impact on scores for models that produce long CoT; isolate length effects from content quality.
- Check benchmark contamination risks (prompt or style overlap) with SFT/RL datasets and teacher outputs; publish contamination analyses.
- Generalization scope and robustness
- Test RLMT across more model scales (≤3B, 13–70B+) and families (Mixtral, Gemma, Phi, Mistral) to determine scaling laws and family-specific behaviors.
- Evaluate multilingual and cross-cultural generalization (non-English chat, localized norms) and measure RM biases across languages.
- Assess robustness to distribution shifts: technical support dialogues, legal/medical domains, non-conversational tasks (planning with constraints, research synthesis), and multi-turn sessions with memory.
- Safety, alignment, and misuse
- Measure jailbreak resistance, toxicity, bias, and deception post-RLMT compared to RLHF baselines; include standardized safety suites (e.g., AdvBench, SAFEBench).
- Study whether long CoT increases unsafe content exposure (e.g., intermediate steps detailing harmful actions) and design suppression/guardrails for thoughts at inference.
- Mechanistic understanding of “thinking” gains
- Causally isolate which aspects of CoT (structure, constraint enumeration, theme grouping, iterative refinement) drive judge and user preference gains via controlled interventions (e.g., ablations of thought sections, randomized templates).
- Evaluate whether improvements persist when thoughts are hidden versus shown, and whether users prefer visible planning traces in real interactions.
- Rewarding the thought process vs. only final answers
- Explore RM designs that score both the thought trace z and the final answer y (e.g., thought quality, plan validity, consistency checks) and compare against current “reward final y only” objective.
- Investigate thought-aware regularization (penalizing redundancy, contradictions, or unsupported claims within z) and its effect on reliability.
- Efficiency and deployment costs
- Quantify inference-time latency, token cost, and energy overhead from longer CoT; develop adaptive thinking strategies (decide-when-to-think, early-exit, budgeted planning).
- Report training compute, wall-clock, and sample efficiency versus matched RLHF pipelines to support practical adoption.
- Stability and reproducibility
- Provide variance across seeds/runs, learning curves, and hyperparameter sensitivity (especially for GRPO vs PPO/DPO), including failures and mode-collapse cases.
- Release full training prompts, preference datasets, and RM APIs/checkpoints used (including Skywork-V2 experiments), enabling end-to-end reproducibility.
- Algorithmic questions about GRPO’s edge
- Analyze why GRPO outperforms PPO/DPO for RLMT (credit assignment, on-policy diversity, KL control, variance reduction) and formalize conditions under which GRPO is preferable.
- Compare on-policy DPO (as used here) with standard off-policy DPO on matched data; characterize theoretical and empirical trade-offs.
- Warm-start dependency on closed teachers
- Replicate warm-start SFT using only open-source teachers (e.g., Llama-3.1-70B, Mixtral-8x22B) and compare to Gemini/GPT-based distillation to rule out closed-model artifacts.
- Assess how SFT teacher choice and prompt formatting influence downstream RLMT gains, including potential style overfitting.
- Zero-training generality and limits
- Verify whether RLMT-Zero results generalize across more base models and pretraining recipes; identify minimal instruction prefixes that reliably elicit useful thought structure.
- Determine how many prompts and RL steps are needed for Zero training to surpass strong instruct models; derive scaling curves and diminishing returns.
- Retention of non-chat capabilities
- Track catastrophic forgetting or trade-offs in math/coding/tool-use after RLMT; evaluate on broader reasoning suites (GSM8K, Humaneval, LogiQA, BIG-Bench reasoning).
- Examine knowledge calibration (TruthfulQA, FactScore/EvidenceScore) and whether longer thoughts reduce or amplify hallucinations.
- Planning-trait measurement validity
- Replace GPT labeling of planning traits with human or rubric-based coding and test inter-annotator agreement; tie traits to measurable outcome deltas.
- Build quantitative proxies for traits (e.g., constraint coverage, revision cycles) and correlate with user satisfaction and task success.
- Personalization and preference heterogeneity
- Study whether RLMT can adapt to diverse user preferences (brevity, tone, formatting) without collapsing to a “one-size” thinking style; explore multi-objective RL with user-specific rewards.
- Combining RLMT with RLVR and tools
- Investigate hybrid reward schemes that use verifiable checks when available and RM otherwise, including tool-use (search, calculator, code execution) during the thinking phase.
- Evaluate whether tool-augmented thinking improves correctness without sacrificing chat quality.
- Disclosure and product UX
- Explore when and how to present or hide thoughts to end-users; measure trust, perceived helpfulness, and cognitive load trade-offs in real product settings.
- Ethical and policy considerations
- Assess whether RLMT-trained “thinking” increases persuasive but inaccurate content, affects user autonomy, or introduces new forms of dark patterns through structured planning.
- Establish governance for releasing models that produce explicit thinking traces, including privacy and misuse mitigation.
Practical Applications
Overview
The paper introduces Reinforcement Learning with Model-rewarded Thinking (RLMT), a post-training recipe that makes LLMs generate and optimize long chain-of-thought (CoT) before producing final answers, using preference-based reward models (as in RLHF) rather than rule-based verifiers (as in RLVR). Key empirical findings:
- RLMT consistently improves open-ended chat and creative writing over standard RLHF across families (Llama-3.1-8B, Qwen-2.5-7B), algorithms (DPO, PPO, GRPO), and settings (with and without SFT).
- GRPO yields the strongest gains; RLMT with GRPO can upgrade base models with as few as ~7K real-world prompts, rivaling or surpassing much larger models trained with extensive pipelines.
- The prompt mixture and reward-model quality critically affect outcomes; RLMT induces richer planning behaviors (constraint enumeration, theme grouping, iterative refinement) and longer thought length.
- RLMT unifies “thinking-first” training for non-verifiable, open-ended tasks, extending the RLVR paradigm beyond math/code.
Below are practical, real-world applications derived from these findings. Each application notes its sector(s), plausible tools/products/workflows, and key assumptions/dependencies.
Immediate Applications
These can be deployed now with available open-source models, modest data (5–10K prompts), and standard training infrastructure.
Industry
- Customer support and service chatbots with better planning and answer quality
- Sectors: Software, e-commerce, telecom, travel, public utilities
- Tools/workflows: Fine-tune existing assistants via RLMT on company-specific support prompts and preference data; use GRPO with a strong reward model (e.g., Skywork-V2) and a WildChat-like prompt mixture; hide the internal CoT at inference
- Dependencies: Availability and alignment of a domain-adapted reward model; safety filters; compute for on-policy RL; legal review of CoT logging
- Creative content studios (campaign strategy, outlines, copy, storytelling)
- Sectors: Marketing, media, entertainment
- Tools/products: “Thinking-first” content ideation assistants; outline-to-draft generators; iterative refinement modules reflecting RLMT planning traits
- Dependencies: Reward models tuned to brand voice and creative goals; style constraints encoded in prompts/reward; human-in-the-loop review
- Product and project planning assistants
- Sectors: Software, hardware, professional services
- Tools/workflows: PRD/requirements drafting, milestones/checklists, risk/constraint enumeration; embedded in PM suites (e.g., Jira, Notion)
- Dependencies: Preference data reflecting internal templates and standards; governance to avoid hallucinated commitments; integration with org knowledge bases
- Enterprise knowledge assistants with better query planning
- Sectors: Enterprise SaaS, consulting, legal ops
- Tools/products: RLMT-enhanced RAG that plans retrieval steps and synthesizes evidence before answering; rubric-aware reward models for “trace-and-cite”
- Dependencies: Robust reward models that value citations, coverage, and non-fabrication; content governance; retrieval quality; privacy controls for CoT
- Low-cost post-training pipelines for smaller teams
- Sectors: AI startups, SMEs, research labs
- Tools/workflows: “RLMT Zero” kits to turn base 7B–8B models into competitive chat/writing assistants with ~7K prompts; GRPO training templates; reward model “zoo”
- Dependencies: Access to suitable reward models and diverse prompt mixtures; modest GPU hours; licensing compatibility (teacher model outputs, RM weights)
- Localization and UX-writing assistants
- Sectors: Global software, gaming, consumer apps
- Tools/products: RLMT-tuned style guardians optimizing clarity, consistency, and tone; locale-specific reward shaping
- Dependencies: Locale-specific preference data; careful reward design to avoid over-sanitization; editorial oversight
Academia
- Reproducible teaching modules on alignment and preference optimization
- Sectors: Education, CS/ML programs
- Tools/workflows: Course labs comparing RLHF vs RLMT (DPO/PPO/GRPO), prompt mixture ablations, reward-model swaps, qualitative plan-trace analysis
- Dependencies: Open weights (models + reward models), curated prompt sets, evaluation harnesses (AE2, WildBench, IFBench, PopQA)
- Research on reasoning strategies and interpretability
- Sectors: ML research, cognitive science
- Tools/workflows: Automatic trait extraction from thinking traces; metrics for constraint enumeration, theme grouping, iterative refinement
- Dependencies: Access to thinking traces; ethical protocols for data handling; robust judges
- Lightweight institutional writing assistants
- Sectors: Universities, grant offices
- Tools/products: RLMT-tuned assistants for syllabus design, grant outlines, IRB drafts with domain-aware reward models
- Dependencies: Institutional style/preferences; content governance; human review
Policy and Government
- Higher-quality public-service chatbots with auditable reasoning
- Sectors: Public administration, social services
- Tools/products: RLMT-tuned virtual agents that keep internal thinking logs for audit while delivering concise final answers
- Dependencies: Privacy controls for CoT storage; FOIA/compliance guidance; reward models reflecting statutory correctness and tone
- Procurement and evaluation guidance for reward models
- Sectors: GovTech, standards bodies
- Tools/workflows: RM audit criteria (bias, safety, compliance), prompt mixture requirements, length-control, and refusal behavior checks
- Dependencies: Transparent RM documentation; third-party audits; standardized benchmarks
Daily Life
- Planning and organization assistants
- Sectors: Consumer productivity, wellness
- Tools/products: Meal plans, fitness routines, itineraries, study plans using explicit constraint enumeration and checklists
- Dependencies: Personalized constraints and preferences; safety filters; simple mobile inference with hidden CoT
- Writing and communications helpers
- Sectors: Personal productivity
- Tools/products: Email drafting, essay outlining, thread/tweet planning with iterative refinement
- Dependencies: Brand/personal style preferences; privacy for user content; guardrails to avoid over-disclosure in CoT
Long-Term Applications
These require further research, scaling, domain-specific reward models, or additional safety and compliance work.
Industry
- Safety-critical decision support with domain-verified reward models
- Sectors: Healthcare (triage suggestions), finance (risk narratives), legal (drafting support), energy (incident playbooks)
- Tools/products: RLMT guided by expert-validated, regulator-aligned reward models; hybrid RLMT+RLVR where partial verification is possible (checklists, tests)
- Dependencies: High-quality, audited reward models; clinical/legal sign-off; robust disclaimers and human-in-the-loop controls; liability frameworks
- Continual, privacy-preserving preference learning
- Sectors: Consumer and enterprise software
- Tools/workflows: On-device or federated RLMT to adapt assistants to individuals/orgs without sharing raw data; secure enclaves for CoT
- Dependencies: Efficient GRPO variants; privacy tech (federated learning, DP); device constraints; opt-in consent flows
- Multi-modal thinking agents
- Sectors: Robotics, assistive tech, automotive
- Tools/products: RLMT extended to vision/audio (e.g., plan with diagrams, reason about scenes) and tool use (APIs, simulators)
- Dependencies: Multi-modal reward models; tool-grounded rubrics; safety around action execution; real-time constraints
- RLMT Ops platforms
- Sectors: MLOps
- Tools/workflows: End-to-end platforms offering prompt mixture curation, RM selection/benchmarking, GRPO training, evaluation dashboards, CoT governance
- Dependencies: Interoperable model/RM formats; standardized evals; policy-compliant logging
Academia
- Unified training across verifiable and open-ended tasks
- Sectors: ML research
- Tools/workflows: Blended RLMT+RLVR curricula that switch between reward models and verifiers; meta-RMs that value truthfulness, coverage, and reasoning quality
- Dependencies: Task routing policies; stability/variance control; mixed-domain benchmarks
- Grounded study of “thinking” in LMs
- Sectors: Cognitive science, HCI
- Tools/workflows: Longitudinal studies of planning style changes, human–AI co-reasoning patterns, and pedagogy benefits
- Dependencies: IRB approvals; diverse participant cohorts; standardized trait taxonomies
Policy and Governance
- Standards for reward-model audits and thinking-trace retention
- Sectors: Regulators, standards bodies
- Tools/workflows: Certification for RM datasets/processes; policies on when/how CoT can be retained, summarized, or deleted; red-team protocols for planning traces
- Dependencies: Cross-industry consensus; legal harmonization across jurisdictions; enforcement mechanisms
- Public-sector AI with transparent, contestable reasoning
- Sectors: Justice, benefits, tax
- Tools/products: Systems that generate citizen-viewable summaries of internal planning while preserving privacy; appeals and oversight tooling
- Dependencies: Robust summarization of CoT; bias and fairness audits; citizen UX design
Daily Life
- Personalized cognitive prostheses
- Sectors: Health/wellness, accessibility
- Tools/products: Assistants that learn a user’s planning style over time (e.g., executive function support, ADHD scaffolding), with safe iterative refinement
- Dependencies: Clinical validation; safety policies; on-device adaptation; strong privacy protections
- Lifelong learning companions
- Sectors: Education
- Tools/products: RLMT tutors that plan study paths, build concept maps, and iterate explanations based on preference signals
- Dependencies: Pedagogical reward models; content licensing; safeguards against over-reliance
Cross-cutting Assumptions and Dependencies
- Reward model quality and fit are pivotal; weak or misaligned RMs can degrade non-chat capabilities or encode bias.
- Prompt mixture matters; realistic, diverse, “chatty” prompts drive better generalization than math/jailbreak-heavy mixes.
- GRPO showed the strongest gains in this work; organizations should validate stability, compute budgets, and safety with GRPO vs PPO/DPO.
- Chain-of-thought should typically be hidden at inference and handled under strict privacy/security policies; consider “reasoning summaries” for user-facing transparency.
- Legal and licensing constraints may apply to teacher model outputs (for warm-start SFT) and to reward model weights/datasets.
- Safety guardrails (refusal policies, toxicity filters, hallucination mitigation) remain necessary; RLMT improves structure and quality but is not a safety guarantee.
Glossary
- Ablation study: A controlled experiment that removes or varies components to assess their impact on performance. "Ablation studies reveal that the choices of both the prompt mixture and the reward model are critical to the final performance."
- AlpacaEval2: An automatic chat benchmark that evaluates dialogue quality via pairwise comparisons with length control. "scores 58.7 on AlpacaEval2"
- ArmoRM: A reward model used for alignment and preference optimization tasks. "ArmoRM~\citep{wang2024interpretable}, another popular reward model used in alignment research~\citep{meng2024simpo}."
- ArenaHardV2: A challenging chat benchmark emphasizing reasoning-heavy prompts (often math/coding-heavy). "ArenaHardV2 (AH2)"
- Base model: A pretrained LLM before any instruction tuning or RL-based post-training. "applied directly to base models without an SFT stage"
- Chain-of-Thought (CoT): An approach where a model generates intermediate reasoning steps before the final answer. "encouraging them to reason with a long chain-of-thought"
- CreativeWritingV3 (CWv3): A benchmark designed to evaluate creative writing abilities of LLMs. "CreativeWritingV3 (CWv3)"
- DeepSeek-R1: A family of reasoning models; often used for distillation or comparison in thinking-style training. "distilled from DeepSeek-R1 on math prompts"
- Direct Preference Optimization (DPO): A preference-learning algorithm that optimizes a policy directly from pairwise human or model preferences. "on-policy DPO, PPO, and GRPO"
- Distillation (knowledge distillation): Transferring capabilities or behaviors from a teacher model to a student model via supervised data. "approaches that distill reasoning behavior from reasoning models"
- Group Relative Policy Optimization (GRPO): An on-policy RL algorithm that optimizes a model relative to grouped baselines, effective for reasoning tasks. "online RL algorithms such as GRPO"
- IFBench: An instruction-following benchmark measuring compliance and fidelity to complex instructions. "IFBench (IF\textsubscript{Ben)}"
- Instruct model: A model post-trained to follow instructions conversationally (e.g., via SFT and/or RLHF). "Llama-3.1-8B-Instruct"
- Iterative preference optimization: Repeatedly refining a policy with cycles of preference data collection and optimization. "rejection sampling, and iterative preference optimization"
- MMLU-Redux: A knowledge benchmark (revision of MMLU) assessing broad academic and world knowledge. "MMLU-Redux (MMLU\textsubscript{R)}"
- On-policy learning: Preference or RL training where data is sampled from the current policy being optimized. "on-policy preference learning algorithms"
- Online RL: Reinforcement learning performed while continually sampling from and updating the current policy, rather than a fixed dataset. "optimizes them with online RL"
- PopQA: A dataset evaluating long-tail factual question answering. "PopQA~\citep{mallen2022when}"
- Preference pairs: Paired outputs labeled by relative preference, used to train reward models or preference-optimized policies. "we build preference pairs sampled from the policy model to be optimized."
- Preference-based reward model: A model predicting scalar rewards from human or proxy preferences over outputs. "a preference-based reward model used in RLHF"
- Proximal Policy Optimization (PPO): A stable on-policy RL algorithm that constrains policy updates via clipping. "DPO, PPO, and GRPO"
- Qwen-2.5-7B: A 7B-parameter model family used as a backbone for SFT/RL experiments. "Qwen-2.5-7B (both base and instruct)"
- R1-Zero: A training approach that elicits reasoning capabilities directly from base models without SFT. "akin to R1-Zero training"
- Rejection sampling: Sampling multiple candidates and selecting those that meet a criterion (e.g., higher reward) for further training. "involving millions of examples, rejection sampling, and iterative preference optimization"
- Reinforcement Learning from Human Feedback (RLHF): Aligning models with human preferences via a learned reward model and RL. "Unlike RLHF"
- Reinforcement Learning with Model-rewarded Thinking (RLMT): Training LMs to produce explicit reasoning traces while optimizing against a reward model over open-ended tasks. "introduces RL with Model-rewarded Thinking (RLMT)"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL where rewards come from rule-based or programmatic verification against ground truth (e.g., math, code). "Reinforcement learning with verifiable rewards (RLVR)"
- Reward model: A learned model that assigns scalar scores to outputs to reflect preference alignment. "We adopt Skywork-v1-Llama-3.1-8B-v0.2 as our reward model "
- Skywork-v1-Llama-3.1-8B-v0.2: A specific reward model variant shown to perform strongly on reward benchmarks. "Skywork-v1-Llama-3.1-8B-v0.2"
- Skywork-V2: An improved version of the Skywork reward model with curated training data. "Skywork-V2~\citep{liu2025skyworkrewardv2}, a newer version of the Skywork reward model"
- Supervised fine-tuning (SFT): Fine-tuning on curated prompt–response pairs to teach formats, styles, or behaviors. "supervised fine-tuning (SFT)"
- T\"ulu 3 SFT mixture: A large curated dataset mixture used for instruction-tuning and related training stages. "T\"ulu 3 SFT mixture"
- UltraFeedback: A preference dataset popular for training reward models and preference-optimized policies. "UltraFeedback~\citep{cui2024ultrafeedback}"
- Verification function: A rule-based check that programmatically verifies output correctness (e.g., unit tests, equality). "a verification function; for example, the indicator function $\mathbbm{1}\{y = y^*\}$"
- Verifiable domains: Tasks where answers can be automatically checked (e.g., math, code) to provide precise rewards. "verifiable domains such as mathematics and code"
- WildBench: A chat benchmark with rubric-based judgments over diverse real-world prompts. "WildBench~\citep{lin2025wildbench}"
- WildChat-IF: A conversational subset emphasizing realistic user prompts, used as an RL prompt mixture. "WildChat-IF subset"
- Zero training: Applying RL directly to base models without any SFT warm-start. "Zero Training (No SFT)"
Collections
Sign up for free to add this paper to one or more collections.

