AfroXLMR-Social: Adapting Pre-trained Language Models for African Languages Social Media Text
Abstract: LLMs built from various sources are the foundation of today's NLP progress. However, for many low-resource languages, the diversity of domains is often limited, more biased to a religious domain, which impacts their performance when evaluated on distant and rapidly evolving domains such as social media. Domain adaptive pre-training (DAPT) and task-adaptive pre-training (TAPT) are popular techniques to reduce this bias through continual pre-training for BERT-based models, but they have not been explored for African multilingual encoders. In this paper, we explore DAPT and TAPT continual pre-training approaches for African languages social media domain. We introduce AfriSocial, a large-scale social media and news domain corpus for continual pre-training on several African languages. Leveraging AfriSocial, we show that DAPT consistently improves performance (from 1% to 30% F1 score) on three subjective tasks: sentiment analysis, multi-label emotion, and hate speech classification, covering 19 languages. Similarly, leveraging TAPT on the data from one task enhances performance on other related tasks. For example, training with unlabeled sentiment data (source) for a fine-grained emotion classification task (target) improves the baseline results by an F1 score ranging from 0.55% to 15.11%. Combining these two methods (i.e. DAPT + TAPT) further improves the overall performance. The data and model resources are available at HuggingFace.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about teaching computer programs to better understand African languages on social media. The authors build a special training set called AfriSocial (made from posts on X/Twitter and news articles) and use it to improve an existing LLM so it can do things like spot emotions, tell if a post is positive or negative, and detect hate speech.
What questions the researchers asked
- Can a general-purpose LLM be improved if we “re-train” it on social media and news text from African languages?
- Is it better to adapt the model to the “domain” (social media/news style) or directly to the “task” (like sentiment or emotion) — or both?
- How much do these adaptations help across many African languages and different tasks?
How they approached it (in simple terms)
Think of a LLM like a student who already read a lot of books and websites in many languages. That’s helpful, but it might not be great at understanding slang, short posts, or the way people write on social media. The authors tried two ways to “top up” the student’s knowledge without giving it new answers, just more reading practice that fits the goal:
- Domain-Adaptive Pre-Training (DAPT): Like giving the student a big pile of texts from a specific place — here, social media and news in African languages — so they get used to the style, vocabulary, and tone. No answer keys, just reading practice.
- Task-Adaptive Pre-Training (TAPT): Like giving the student practice texts from the same kind of tasks they will be tested on (for example, posts from an emotion dataset), but still without the labels or answers. It’s smaller than DAPT but very focused.
They combined both ideas:
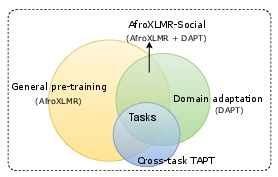
- Start with a strong multilingual model tuned for African languages (AfroXLMR).
- Do DAPT using their new AfriSocial corpus (3.56 million sentences across 14 African languages from X/Twitter and news). This creates AfroXLMR-Social.
- Do TAPT by letting the model read unlabeled texts from the exact kinds of tasks it will do (sentiment, emotions, hate speech), sometimes even using data from one task to help another (cross-task TAPT).
- Finally, fine-tune on the labeled datasets for three tasks:
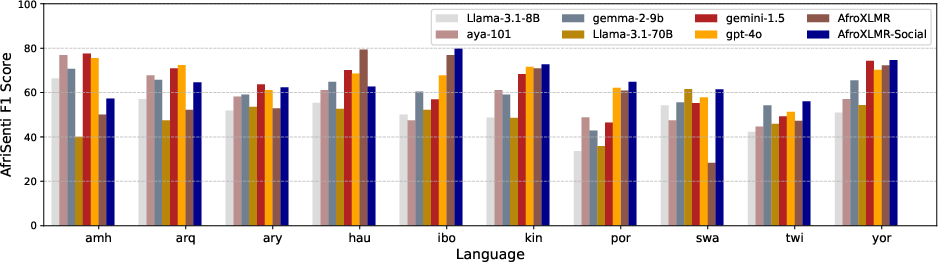
- AfriSenti (sentiment: positive/negative/neutral; ~14 languages)
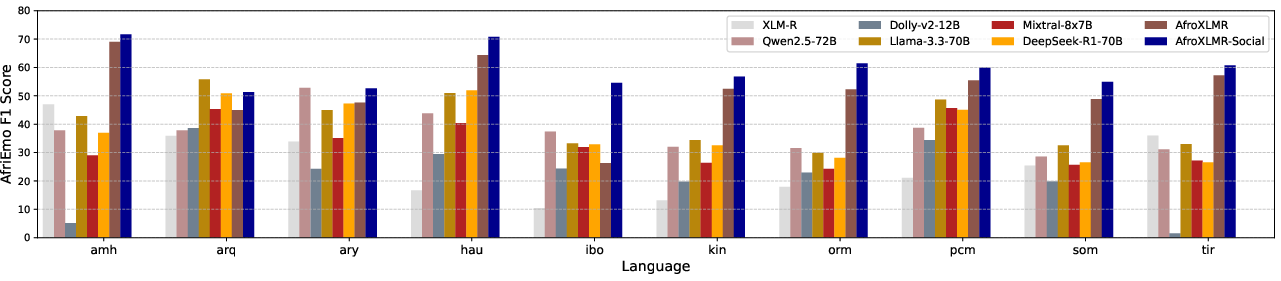
- AfriEmo (multi-label emotions: anger, disgust, fear, joy, sadness, surprise; ~17 languages)
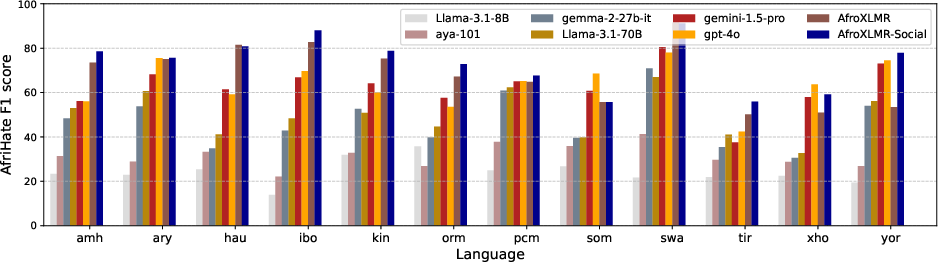
- AfriHate (hate/abusive/neutral; ~15 languages)
To keep data clean and fair, they:
- Checked each sentence is really in the right language.
- Split text into sentences properly for each language.
- Removed very short lines, usernames, and personal info.
- Avoided duplicates so the model wasn’t “seeing” test examples beforehand.
What they found and why it matters
Here are the main takeaways, explained plainly:
- Adapting to the domain (DAPT) helps a lot: After reading AfriSocial, the model did better on all three tasks in most languages, often by noticeable margins (about 1% to 30% higher Macro-F1 scores, a common accuracy-like metric for balanced evaluation). This means just getting used to social-media/news style pays off.
- Task-focused practice (TAPT) also helps, even across tasks: Letting the model read unlabeled texts from one task boosted performance on another related task. For example, using unlabeled sentiment posts improved emotion detection by about 0.55% to 15.11% F1. This shows that similar tasks share useful patterns.
- Combining DAPT + TAPT is usually best: Doing both steps (first domain, then task) often gave the strongest results on average. There were a few cases where gains didn’t stack perfectly (a known issue called “forgetting”), but overall it worked well.
- Strong against big-name LLMs: When compared to LLMs like GPT-4o, Gemini, and Llama in zero-shot mode (no extra training), the adapted AfroXLMR-Social model matched or beat them on these African-language social media tasks. This is important because it shows that targeted training can outperform much larger models when data is scarce.
Why it matters: Many African languages don’t have huge, clean datasets. This study shows you can get big improvements by carefully adapting existing models with the right kind of unlabeled text. It’s a practical, cost-effective way to boost performance across languages and tasks that matter for online safety and understanding.
What this could lead to
- Better tools for African languages: Moderation, sentiment tracking, and emotion analysis can become more accurate for many languages, improving user safety and understanding online discussions.
- Practical blueprint for low-resource languages: Collecting a focused, high-quality domain corpus (like AfriSocial) and applying DAPT + TAPT is an efficient recipe others can reuse.
- Open resources for the community: The authors released both the AfriSocial dataset and the adapted model (AfroXLMR-Social) on HuggingFace, so researchers and developers can build on their work.
- Future improvements: The same approach can be tried for other domains (like health or education) and more tasks (like question answering), and can be refined to avoid “forgetting” when chaining training steps.
In short: Giving a multilingual model the right kind of reading practice — texts from social media and task-related sources — makes it much better at understanding feelings and harmful content in African languages. This helps build fairer, safer, and more useful language technology for everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Domain composition effects: No ablation isolating X-only vs news-only DAPT; unclear which source drives gains per task/language and whether source–task alignment matters.
- Topic sensitivity: No analysis of how topic distributions (e.g., politics, sports, health) within AfriSocial affect downstream performance and robustness.
- Temporal drift: Lack of evaluation across time (older vs newer social posts) to assess robustness to evolving social media language and whether periodic re-DAPT is needed.
- Data filtering impact: Hate/offensive content was removed from AfriSocial; it is unknown if this filtering harms hate/abuse detection adaptation or biases lexical coverage.
- Code-switching handling: Although code-switching is retained in pre-training, there is no evaluation on code-switched test sets or analysis of how much it contributes to gains.
- LID/segmentation noise: No error analysis or quantitative estimate of language identification and sentence segmentation errors and their impact on model quality.
- Per-language imbalance: Large disparity in sentence counts (e.g., Twi ~8.6k vs Zulu ~866k) is not systematically tied to performance; minimal-data thresholds for effective DAPT/TAPT remain unknown.
- Scaling laws: No study of how improvements scale with unlabeled corpus size per language; unclear diminishing returns or optimal data budgets for DAPT/TAPT.
- Sampling strategy: The multilingual continual pre-training sampling schedule is not analyzed (e.g., language weighting); the effect of balanced vs proportional sampling remains unexplored.
- Tokenizer adequacy: No investigation of vocabulary/tokenizer adaptation for underrepresented scripts (e.g., Ge’ez) or diacritics (e.g., Yorùbá), nor impact of vocabulary augmentation.
- Cross-language interference: Adaptation for 14 languages may benefit some while harming others or non-target languages; no evaluation on languages outside AfriSocial to quantify catastrophic interference.
- Task–task similarity: Cross-TAPT is shown helpful on average, but there is no diagnostic linking task similarity (label space, lexical overlap) to gains; selection criteria for the best TAPT source remain open.
- Order and scheduling: Only DAPT→TAPT is tested; alternatives (interleaving, rehearsal buffers, elastic weight consolidation, adapters/LoRA) to mitigate catastrophic forgetting are not evaluated.
- Objective variants: Only masked LM is used; no comparison to alternative pre-training objectives (e.g., RTD, span corruption, contrastive objectives) for social-domain adaptation.
- Hyperparameter sensitivity: No ablations on continual pre-training steps, batch sizes, learning rates, or early stopping criteria to determine stability and cost–performance trade-offs.
- Metrics and significance: Reliance on macro-F1 without statistical significance testing, calibration analysis, per-class performance, or multilabel-specific metrics (e.g., Jaccard, micro-F1) limits interpretability.
- Robustness to social noise: No tests for robustness to spelling variation, slang, emoji, elongations, or adversarial typos common in social media.
- Generalization beyond social: Effects of DAPT/TAPT on out-of-domain tasks (e.g., QA, NER, MT) are untested; potential negative transfer is unknown.
- Fine-grained error analysis: Lacking per-language confusion patterns (e.g., neutral vs negative) and failure modes to guide targeted improvements.
- Data contamination audits: While duplicates were removed, there is no quantitative audit for residual leakage or overlap across sources/languages.
- Ethical/legal provenance: Data licensing, consent, and jurisdictional considerations for scraped social and news text are not discussed.
- Fairness and bias: No analysis of demographic or dialectal biases introduced or amplified by DAPT/TAPT; no subgroup performance comparisons.
- LLM comparisons: Only zero-shot LLMs are considered; few-shot, in-context learning, Chain-of-Thought prompting, or light supervision for LLMs remain unevaluated baselines.
- Efficiency and footprint: Claims of cost-effectiveness are not quantified (compute time, energy/carbon); no comparison with parameter-efficient tuning (adapters, LoRA, prefix-tuning).
- Per-language vs unified models: No comparison of a single multilingual adapted model vs per-language or language-cluster DAPT/TAPT models.
- Source quality variation: News and X corpora may differ in noise and quality across languages; the effect of quality-controlled subsets is not studied.
- Thresholding for multilabel: For AfriEmo, threshold choice and calibration strategies are not detailed or optimized across languages.
- Vocabulary normalization: No discussion of diacritic normalization (e.g., Yoruba, Igbo) or orthographic variants and their influence on tokenizer coverage and performance.
- Release granularity: AfriSocial is provided combined; separate releases by time, topic, and source would enable controlled, reproducible ablations that are currently not possible.
Practical Applications
Immediate Applications
The following applications can be deployed now using the released AfriSocial corpus and AfroXLMR-Social models (available on HuggingFace: tadesse/AfroXLMR-Social), along with the paper’s DAPT/TAPT recipe.
- Content moderation for African languages on social platforms
- Sectors: software, media, online safety
- Use: Deploy AfroXLMR-Social to classify hate/abusive content and filter toxicity in Amharic, Hausa, Igbo, Swahili, Yoruba, Zulu, and other covered languages; triage flags for human review.
- Tools/Workflows: REST API microservice for hate speech classification; moderator dashboard with per-language thresholds; automated escalation queues.
- Assumptions/Dependencies: Domain fit to social/news text; performance benefits observed (1–30% macro-F1 gains via DAPT) hold for platform’s content mix; language identification pipeline for code-switched inputs; periodic re-adaptation to domain drift.
- Brand and PR sentiment tracking across African markets
- Sectors: marketing, finance, telecom, e-commerce, media
- Use: Real-time sentiment classification of user posts/comments to monitor campaigns, product launches, service outages, and competitor mentions across 14+ African languages.
- Tools/Workflows: Stream processor + sentiment classifier; campaign dashboards; alerting on negative spikes; integration with CRM/ticketing.
- Assumptions/Dependencies: Access to social streams/news; the sentiment label space (positive/neutral/negative) maps to business KPIs; calibration per language and domain.
- Emotion analytics for customer voice and community health
- Sectors: customer experience, public health, education, civic tech
- Use: Multi-label emotion detection (anger, joy, sadness, etc.) on feedback, forum posts, or student/community channels to identify distress, satisfaction, or emerging concerns.
- Tools/Workflows: Batch scoring jobs; emotion heatmaps by region/language; trigger playbooks (e.g., outreach to at-risk groups).
- Assumptions/Dependencies: Emotion categories match intervention policies; privacy-preserving data handling; differences in cultural expression across languages considered.
- Election and civic-risk monitoring (toxicity + sentiment + emotion)
- Sectors: public policy, NGOs, media monitoring
- Use: Track spikes in hate speech, negative sentiment, and anger around elections or sensitive events to support rapid response and fact-checking.
- Tools/Workflows: Event-focused monitoring stack; risk scoring; weekly reports for civil society partners.
- Assumptions/Dependencies: Local-language coverage is sufficient for the region; careful thresholding to minimize false positives; human-in-the-loop validation.
- Newsroom and community comment moderation
- Sectors: media, publishing
- Use: Moderate comment sections in local languages (remove abuse/hate, surface constructive feedback).
- Tools/Workflows: CMS plugin using AfroXLMR-Social; queue for moderator review; policy-aligned rule sets.
- Assumptions/Dependencies: Policies localized per outlet; minimal latency requirements achievable.
- Customer support triage in local languages
- Sectors: telecom, banking/fintech, e-commerce, utilities
- Use: Classify incoming messages by sentiment/emotion to prioritize escalations and route to language-appropriate agents.
- Tools/Workflows: Inbox classifier; priority queues; agent-assist panels with predicted labels.
- Assumptions/Dependencies: Accurate language ID for code-switched inputs; integration with existing ticketing systems.
- Data-efficient adaptation to a new but related task (TAPT)
- Sectors: software, academia, ML platform teams
- Use: Apply TAPT on small unlabeled task data (e.g., using unlabeled sentiment data to boost emotion classification) to get competitive gains without large corpora.
- Tools/Workflows: “Cross-TAPT Trainer” that accepts unlabeled data and outputs adapted checkpoints; guardrails for data leakage.
- Assumptions/Dependencies: Availability of minimal in-domain unlabeled data; task similarity holds; deduplication against evaluation sets.
- Rapid bootstrap for new African-language classifiers
- Sectors: startups, research labs, NGOs
- Use: Start with AfroXLMR-Social, fine-tune quickly for custom subjective tasks (e.g., harassment taxonomy, misinformation flags).
- Tools/Workflows: Fine-tuning templates; small labeled sets plus TAPT with unlabeled domain text; evaluation harness by language.
- Assumptions/Dependencies: Label schema alignment; enough unlabeled domain text; compute for brief fine-tuning.
- Benchmarking and curriculum design in NLP courses
- Sectors: academia, training programs
- Use: Course labs on DAPT vs. TAPT vs. combined DAPT+TAPT; analysis of code-switching and language imbalance effects; reproduction of reported F1 gains.
- Tools/Workflows: Teaching notebooks; HuggingFace datasets/models; standardized evaluation splits (AfriSenti, AfriEmo, AfriHate).
- Assumptions/Dependencies: Access to compute; institutional data-use policies; student familiarity with MLOps basics.
- Auditing LLM pipelines with a strong encoder baseline
- Sectors: software, safety, compliance
- Use: Use AfroXLMR-Social as a control model to audit zero-shot/few-shot LLM moderation or analytics pipelines, highlighting gaps for African languages.
- Tools/Workflows: Side-by-side evaluation harness; threshold calibration; error analysis by language and dialect.
- Assumptions/Dependencies: Comparable prompts and data; careful handling of differences in label spaces and evaluation protocols.
Long-Term Applications
The following applications require further research, scaling to more languages/domains, stronger multimodal integration, or policy/process development.
- National/regional online safety stacks for African languages
- Sectors: policy, regulators, platforms, telcos
- Use: End-to-end “safety stack” combining language ID, toxicity/hate detection, sentiment/emotion, and escalation pathways across platforms and languages.
- Tools/Workflows: Federated model governance; standardized APIs; transparent reporting per language.
- Assumptions/Dependencies: Regulatory frameworks; cross-platform data-sharing agreements; bias/fairness audits; continuous re-adaptation to domain drift.
- Domain-specialized adaptations beyond social/news (health, legal, finance)
- Sectors: healthcare, legal-tech, finance
- Use: DAPT for clinical forums (mental health signals), legal consultations (harassment/abuse detection), or fintech support (distress, fraud cues) in African languages.
- Tools/Workflows: New domain corpora; privacy-preserving training; expert-informed label taxonomies.
- Assumptions/Dependencies: High-quality, compliant domain data; ethics approvals; robustness to jargon and sensitive content.
- Real-time, low-resource, on-device moderation and analytics
- Sectors: mobile, telecom, messaging apps
- Use: Distilled/quantized AfroXLMR-Social variants for on-device moderation in low-connectivity settings (e.g., community apps, local forums).
- Tools/Workflows: Model compression toolchain; CPU/mobile inference optimization; offline sync.
- Assumptions/Dependencies: Acceptable accuracy after compression; device capability constraints; privacy-by-design requirements.
- Multimodal civic-risk early warning (text + speech + images)
- Sectors: public safety, NGOs, media
- Use: Fuse speech-to-text (local languages), text classifiers, and image signals to better detect coordinated abuse or incitement.
- Tools/Workflows: ASR for African languages; cross-modal fusion; event-level risk scoring.
- Assumptions/Dependencies: Mature ASR for target languages; multimodal dataset availability; governance of false positives and community impact.
- Human-in-the-loop active learning for low-resource languages
- Sectors: research, platform safety, NGOs
- Use: Iterative annotation loops where model uncertainty guides labeling; TAPT leverages newly collected unlabeled data to rapidly improve models.
- Tools/Workflows: Uncertainty sampling; annotator tools localized per language; continual training pipelines.
- Assumptions/Dependencies: Sustained annotation capacity; fair compensation and training for local annotators; robust deduplication and PII handling.
- Standardized evaluation frameworks and fairness diagnostics
- Sectors: academia, policy, platforms
- Use: Create shared benchmarks and bias tests covering dialects/code-switching to ensure equitable performance across communities.
- Tools/Workflows: Dialect-stratified test sets; error taxonomy; fairness dashboards.
- Assumptions/Dependencies: Community partnerships to source diverse data; consensus on fairness metrics and remediation steps.
- Integration with LLM agents as specialized classifiers (“expert adapters”)
- Sectors: software, enterprise AI
- Use: Route African-language text to AfroXLMR-Social “expert” heads for safety/sentiment/emotion, while LLMs handle generation/summarization.
- Tools/Workflows: Router/orchestrator; latency-optimized inference; policy-constrained generation conditioned on classifier outputs.
- Assumptions/Dependencies: Reliable interop between encoder models and LLMs; careful latency and cost management; guardrails for failure modes.
- Cross-country public health surveillance (privacy-preserving)
- Sectors: healthcare, public policy
- Use: Aggregate emotion/sentiment signals (e.g., vaccine hesitancy, mental health cues) across languages to inform outreach.
- Tools/Workflows: Differential privacy; federated analytics; ethical oversight boards.
- Assumptions/Dependencies: Strong privacy/legal frameworks; validated mappings from linguistic signals to health indicators; mitigation of sampling bias.
- Educational wellbeing monitoring and interventions
- Sectors: education, student services
- Use: Detect distress or bullying-related toxicity in student forums or feedback (with consent), trigger pastoral care workflows.
- Tools/Workflows: Consent-first data collection; localized lexicons; escalation policies involving counselors.
- Assumptions/Dependencies: Institutional approvals; cultural adaptation of policies; strict data minimization and access controls.
- Pan-African language expansion and dialect robustness
- Sectors: research, platforms, public sector
- Use: Scale corpus coverage to more languages/dialects; address imbalance (e.g., Twi vs. Zulu volumes) to reduce performance gaps.
- Tools/Workflows: Community data partnerships; balanced sampling; semi-/weak supervision for scarce languages.
- Assumptions/Dependencies: Sustainable data collection; equitable representation; evaluation that reflects dialect diversity.
- Misinformation and narrative dynamics analysis
- Sectors: media, policy, civic tech
- Use: Combine emotion/sentiment trends with hate speech markers to map narrative spread and polarization in local languages.
- Tools/Workflows: Topic modeling layered with classifier outputs; timeline and network views; analyst-in-the-loop verification.
- Assumptions/Dependencies: Access to relevant data streams; disinformation-sensitive safeguards; avoidance of overreach or censorship risks.
- Compliance tooling for platform regulation (risk assessments, transparency)
- Sectors: policy, legal, platforms
- Use: Generate per-language risk metrics, detection coverage, and error profiles to support Digital Services-style risk reporting in Africa.
- Tools/Workflows: Reporting pipelines; audit logs; standardized metrics per task (macro-F1, coverage, drift).
- Assumptions/Dependencies: Regulatory clarity; third-party audits; shared taxonomies of harmful content.
Notes on feasibility and dependencies that cut across applications:
- Domain and task fit: Gains are strongest for social/news-like text; out-of-domain use likely requires new DAPT/TAPT.
- Data availability: TAPT depends on small in-domain unlabeled data; DAPT requires larger domain corpora (AfriSocial provides a starting point).
- Language imbalance and bias: Performance varies with data volume; fairness audits and rebalancing needed.
- Code-switching and LID: Robust language identification and mixed-language handling are essential.
- Privacy and ethics: PII handling, consent, and appropriate use policies must be enforced.
- Compute and MLOps: Even though TAPT is relatively cheap, productionization requires inference optimization, monitoring, and periodic re-adaptation.
Glossary
- AfriEmo: A multi-label emotion recognition dataset for African languages. "AfriEmo Macro F1 results from AfroXLMR-Social and LLMs."
- AfriHate: A multilingual hate and abusive speech detection dataset for African languages. "AfriHate Macro F1 results from AfroXLMR-Social and LLMs."
- AfriSenti: A sentiment analysis dataset across African languages. "AfriSenti Macro F1 results from AfroXLMR-Social and LLMs."
- AfriSocial: A social domain–specific corpus (X and news) for African languages used for continual pre-training. "We create AfriSocial, a social domain-specific corpus comprising X and news for 14 African languages"
- AfroXLMR: A multilingual African-centric encoder model continually pre-trained from XLM-RoBERTa. "AfroXLMR is a continually pre-trained model for African languages based on XLM-RoBERTa"
- AfroXLMR-Social: The AfroXLMR model adapted to the social domain via DAPT. "resulting in AfroXLMR-Social"
- BERT-based models: Models derived from the BERT architecture used for transfer learning in NLP. "continual pre-training for BERT-based models"
- catastrophic forgetting: Degradation where a model forgets previously learned information when trained sequentially on new data. "would be susceptible to catastrophic forgetting of the domain-relevant corpus"
- Chain-of-Thought (CoT) reasoning: A prompting strategy that elicits step-by-step reasoning in LLMs. "prompting strategies such as Chain-of-Thought (CoT) reasoning"
- code-switching: The practice of mixing multiple languages or dialects within a text. "We did not perform further processing on the code-switching text"
- continual pre-training: Further pre-training of a LLM on new unlabeled data after initial pre-training. "continual pre-training approaches for African languages social media domain."
- Cross-task TAPT: Applying task-adaptive pre-training using unlabeled data from a related but different task. "This model then undergoes Cross-task TAPT using sentiment analysis, emotion, and hate speech data without the labels for further fine-tuning."
- cross-lingual adaptation: Adapting models or techniques across different languages. "the dynamics of cross-lingual adaptation."
- DAPT (Domain Adaptive Pre-training): Continuing pre-training on unlabeled text from a target domain to reduce domain mismatch. "Domain Adaptive pre-training (DAPT) is straightforward, continuing pre-training a model on a corpus of unlabeled domain-specific text"
- data leakage: Unintended inclusion of evaluation or test information in training data, biasing results. "to prevent data leakage."
- de-duplication: Removing duplicate or near-duplicate instances from a dataset. "De-duplication is applied if a near-similar instance is present"
- domain adaptation: Improving performance on a target domain by leveraging knowledge from a source domain. "Domain adaptation in NLP refers to enhancing the performance of a model using similar domain data (target domain) by leveraging knowledge from an existing domain (source domain)"
- domain-specific corpus: A dataset curated from a particular domain for specialized training. "continual pre-training using a domain-specific corpus"
- encoder-only pretrained LLMs: Transformer models composed of encoder stacks (no decoder) used for understanding tasks. "Multilingual encoder-only pretrained LLMs (PLMs) such as XLM-R"
- Ethiopic script: A writing system used for languages like Amharic and Tigrinya. "Ethiopic script languages (Amharic and Tigrinya)"
- few-shot settings: Evaluation or prompting scenarios with only a few labeled examples. "particularly in few-shot settings"
- fine-tuning: Supervised adaptation of a pre-trained model to a specific downstream task. "Traditional fine-tuning often yields suboptimal results"
- In-context learning: Having an LLM perform a task by conditioning on examples in the prompt without parameter updates. "In-context learning evaluations"
- LAFT (language-adaptive fine-tuning): Another name for LAPT focusing on adapting to specific languages. "LAPT is also called language-adaptive fine-tuning (LAFT)"
- LAPT (Language Adaptive Pre-training): Adapting a pre-trained model to one or more specific languages using language-specific corpora. "Language Adaptive Pre-training (LAPT) LAPT is also called language-adaptive fine-tuning (LAFT)"
- Language Identification (LID): Automatically determining the language of a text segment. "Language Identification (LID)"
- LLMs: High-capacity neural LLMs capable of general-purpose NLP tasks. "LLMs"
- macro-F1: The unweighted average F1 score across classes, treating each class equally. "Reported results are macro-F1."
- mBERT: Multilingual BERT, a transformer pre-trained on multiple languages. "mBERT"
- multi-label annotation: Labeling where instances can have zero, one, or multiple labels simultaneously. "in a multi-label annotation (an instance may have none, one, two, some, or all targeted emotion labels)"
- multilingual encoders: Language encoders trained to process multiple languages. "have not been explored for African multilingual encoders."
- personally identifiable information (PII): Sensitive data that can identify an individual. "personally identifiable information (PII)"
- PLMs (Pre-trained LLMs): Models trained on large corpora to learn general language representations. "Pre-trained LLMs (PLMs) are initially trained on vast and diverse corpora"
- TAPT (Task-adaptive pre-training): Continuing pre-training on unlabeled data that closely matches the target task. "Task-adaptive pre-training (TAPT) refers to pre-training on the unlabeled training set for a similar task-specific data"
- XLM-RoBERTa (XLM-R): A multilingual transformer model used as a base for adaptations like AfroXLMR. "XLM-RoBERTa"
- zero-shot evaluations: Testing models without any task-specific training or examples. "The results for LLMs are based on zero-shot evaluations"
Collections
Sign up for free to add this paper to one or more collections.