- The paper presents a domain-adaptive pre-training approach using a depression lexicon and guided masking to improve Chinese mental health text analysis.
- It uses 3.36 million Chinese social media posts to fine-tune Chinese-BERT-wwm-ext, achieving a 2% F1-score improvement over previous baselines.
- The study sets a benchmark for mental health NLP by demonstrating significant quantitative gains and qualitative improvements in detecting psychological cues.
Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis
Introduction
The study "Chinese MentalBERT: Domain-Adaptive Pre-training on Social Media for Chinese Mental Health Text Analysis" (2402.09151) addresses a critical niche in natural language processing by focusing on the mental health domain, specifically targeting Chinese social media text. This work seeks to bridge the gap between general-purpose pre-trained models and the nuanced requirements of psychological text analysis. By leveraging a substantial dataset sourced from Chinese social media and integrating a specialized lexicon, this model aims to more accurately detect and interpret psychological signals within text data.
Methodology
A significant portion of the paper is dedicated to explaining the domain-adaptive pre-training process employed in Chinese MentalBERT. The process begins with Chinese-BERT-wwm-ext as the foundational model. Domain-specific adaptations are then integrated, using data from various Chinese social media sources, capturing a plethora of mental health expressions (Figure 1). To further enhance domain relevance, a guided masking strategy informed by a depression lexicon is employed. This strategy biases the learning process towards key vocabulary within the psychological domain, allowing the model to capture subtle emotional nuances often missed by general-purpose LLMs.
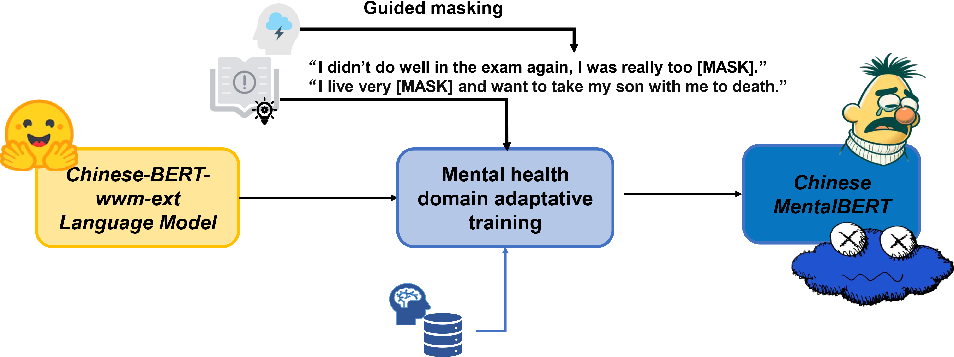
Figure 1: Overview of the domain adaptive pretraining process. The process initiates with the foundational pretrained LLM (Chinese-BERT-wwm-ext), followed by further pretraining with 3.36 millions mental health tweets/comments sourced from social media. The pretraining phase integrates the knowledge from depression lexicon to guide the masking process.
Experimental Results
The paper presents extensive evaluations of Chinese MentalBERT using four public mental health datasets. The results indicate that this model consistently surpasses general LLMs and baselines specific to domains such as financial and medical fields. Notably, the model achieves superior performance in tasks involving cognitive distortion multi-label classification, suicide risk classification, and sentiment analysis. The implementation of the guided masking strategy notably enhances the model's performance compared to traditional random masking methods. This highlights the significant gains achieved by tailoring pre-training processes to specific lexical domains within Chinese text, showcasing an F1-score improvement by approximately 2% over previous baselines.
Qualitative Evaluation
Beyond quantitative analysis, the study explores qualitative evaluation to further establish the model's efficacy. The emphasis is on evaluating the ability of the model to predict psychologically relevant masked words, especially words indicating emotional distress or cognitive distortions. The results provide compelling evidence that the lexicon-guided strategy significantly refines the model's predictions of such masked words, aligning them more closely with the psychological undertones present in context, compared to the outputs from models applying random masking.
Implications and Future Work
The implications of this research stretch across both practical applications in mental health interventions and theoretical advancements in domain-specific model training. By making pre-trained models and code publicly accessible, this work facilitates further research and development in the domain of Chinese mental health. Future developments could see the application of similar strategies across other languages and specific domains, potentially expanding the scope of domain-adaptive pre-training methodologies to new tasks and datasets, thereby enriching AI's capacity to support mental health initiatives globally.
Conclusion
The paper presents a meticulous approach to developing a pre-trained LLM tailored for the Chinese mental health domain. By integrating domain-specific data and adopting a novel lexicon-guided masking mechanism, Chinese MentalBERT sets a new benchmark in psychological text analysis, providing valuable insights into the early detection and understanding of mental health signals from social media data. This work represents a significant step towards improving the applicability of AI in sensitive domains, paving the way for more personalized and accurate interventions.